Gemini画像生成の429エラーは、アプリケーションがGoogleの4つのレート制限次元(Requests Per Minute(RPM)、Requests Per Day(RPD)、Tokens Per Minute(TPM)、見落とされがちなImages Per Minute(IPM))のいずれかを超過した際に発生します。最も迅速な修正方法は、ジッターを加えた指数バックオフの実装で、バーストトラフィック時の80%失敗率を99%以上の成功率に変換できます。ただし、無料版を使用している場合は、まず課金を有効にする必要があります。2025年12月に無料版のIPMが0に引き下げられたため、有料アカウントなしでは画像生成が事実上無効になっています。Tier 1では最低利用額なしで即座に10 IPMが利用可能です。
Gemini画像生成が429エラーを返す理由
すべてのAPIプロバイダーは、インフラストラクチャを不正利用から保護し、全ユーザー間で公平にリソースを分配するためにレート制限を実装しています。Gemini APIリクエストが課金ティアに割り当てられたクォータを超過すると、Googleのサーバーはステータスコード429とRESOURCE_EXHAUSTEDエラーメッセージを返します。これはコードのバグでもGeminiモデル自体の問題でもありません。APIゲートウェイがGoogleのプロジェクトに設定されたクォータ境界を強制しているのです。このエラーのメカニズムを理解することが、中断なく本番規模のワークロードを処理できる堅牢な画像生成パイプラインを構築するための第一歩です。
Gemini APIからの429レスポンスには、多くの開発者が見落とす特定の構造が含まれています。レスポンスボディにはステータスコードRESOURCE_EXHAUSTEDを含むerrorフィールドのJSONオブジェクトが含まれ、人間が読めるメッセージでどのクォータが超過されたかが説明されます。重要なのは、x-ratelimit-limit、x-ratelimit-remaining、x-ratelimit-resetといったメタデータヘッダーが含まれており、どの次元が制限をトリガーしたか、いつリセットされるかが正確にわかることです。多くの開発者は429をキャッチして盲目的にリトライしますが、これらのヘッダーを解析することで、ブルートフォースリトライではなく的を絞った修正を実装するためのインテリジェンスが得られます。x-ratelimit-remainingのIPMが0を示し、RPMにはまだ容量がある場合、ボトルネックは一般的なリクエストボリュームではなく、画像生成のスループットに特定されることがわかります。
4つのレート制限次元
Googleは4つの独立した次元でレート制限を適用しており、いずれか1つに達すると429エラーがトリガーされます。ほとんどの開発者はRPMとRPDに馴染みがありますが、2025年後半にGeminiのネイティブ画像生成機能とともに導入されたIPMは、多くのチームを不意打ちにしました。各次元は独立して動作するため、RPM制限内であってもIPMクォータが消尽されればスロットリングされる可能性があります。以下の表は各次元と画像生成ワークロードへの影響を解説します。
| 次元 | 正式名称 | 測定内容 | 画像生成への影響 |
|---|---|---|---|
| RPM | Requests Per Minute | 60秒間のAPI呼び出し総数 | テキストを含むすべてのGemini呼び出しに影響 |
| RPD | Requests Per Day | 24時間のAPI呼び出し総数(太平洋標準時の深夜にリセット) | すべての操作の日次ボリュームを制限 |
| TPM | Tokens Per Minute | 1分間に処理される入出力トークン合計 | 主にテキストに影響。画像は固定トークンブロックとしてカウント |
| IPM | Images Per Minute | 1分間に生成される画像数 | 隠れた要因。画像出力を直接制限 |
IPM:ほとんどの開発者が見落とす隠れた要因
Images Per Minuteは、Geminiの画像生成機能を統合する開発者の間で最も混乱を引き起こすレート制限次元です。テキスト補完を含むすべてのAPIリクエストを管理するRPMとは異なり、IPMはアプリケーションが60秒間のスライディングウィンドウ内で生成する画像数を特にカウントします。4枚の画像を生成する単一のAPI呼び出しは1 RPMではなく4 IPMを消費します。つまり、RPMクォータ内であっても、リクエストが頻繁に複数の画像を生成する場合、IPMの上限に達する可能性があるのです。問題はさらに深刻で、無料版のIPMが2025年12月に0に引き下げられたため、未払いアカウントでの画像生成はリクエストを処理することすらなく即座に429を返します。多くの開発者は初めての429エラーをデバッグする際、コードロジックのチェックに何時間も費やしますが、実際の問題は課金ティアが画像生成を一切許可していないという単純なことなのです。
2026年2月のゴースト429バグ
2026年2月初旬以降、有料Tier 1アカウントの複数の開発者が、使用量ダッシュボードでクォータに対する消費がゼロまたはほぼゼロであるにもかかわらず、429 RESOURCE_EXHAUSTEDエラーを受信すると報告しました。この「ゴースト429」バグは、Googleのクォータ追跡システムのサーバー側の問題で、レートリミッターが特定のプロジェクト構成の使用量を誤って計算するようです。このバグは主に無料版からTier 1に最近アップグレードしたアカウントに影響し、課金が有効になってから最初の24〜48時間に最も一般的に発生します。Googleは開発者フォーラムでこの問題を認め、エンジニアリングチームが調査する間の一時的な回避策として、別のモデルバリアント(例えばgemini-3.1-flashからgemini-3-pro)に切り替えることを推奨しました。Google Cloud Consoleのクォータダッシュボードで本当にゼロの使用量が表示されているにもかかわらず429エラーが発生している場合、このバグが最も可能性の高い原因であり、設定ミスではありません。Gemini APIのエラーコードとその解決策について幅広く理解するには、Gemini APIエラートラブルシューティング完全ガイドをご覧ください。レート制限システムの詳細を理解したい場合は、Gemini APIレート制限完全ガイドですべてのティアと次元を網羅しています。
迅速な診断 — どのレート制限に該当したか?
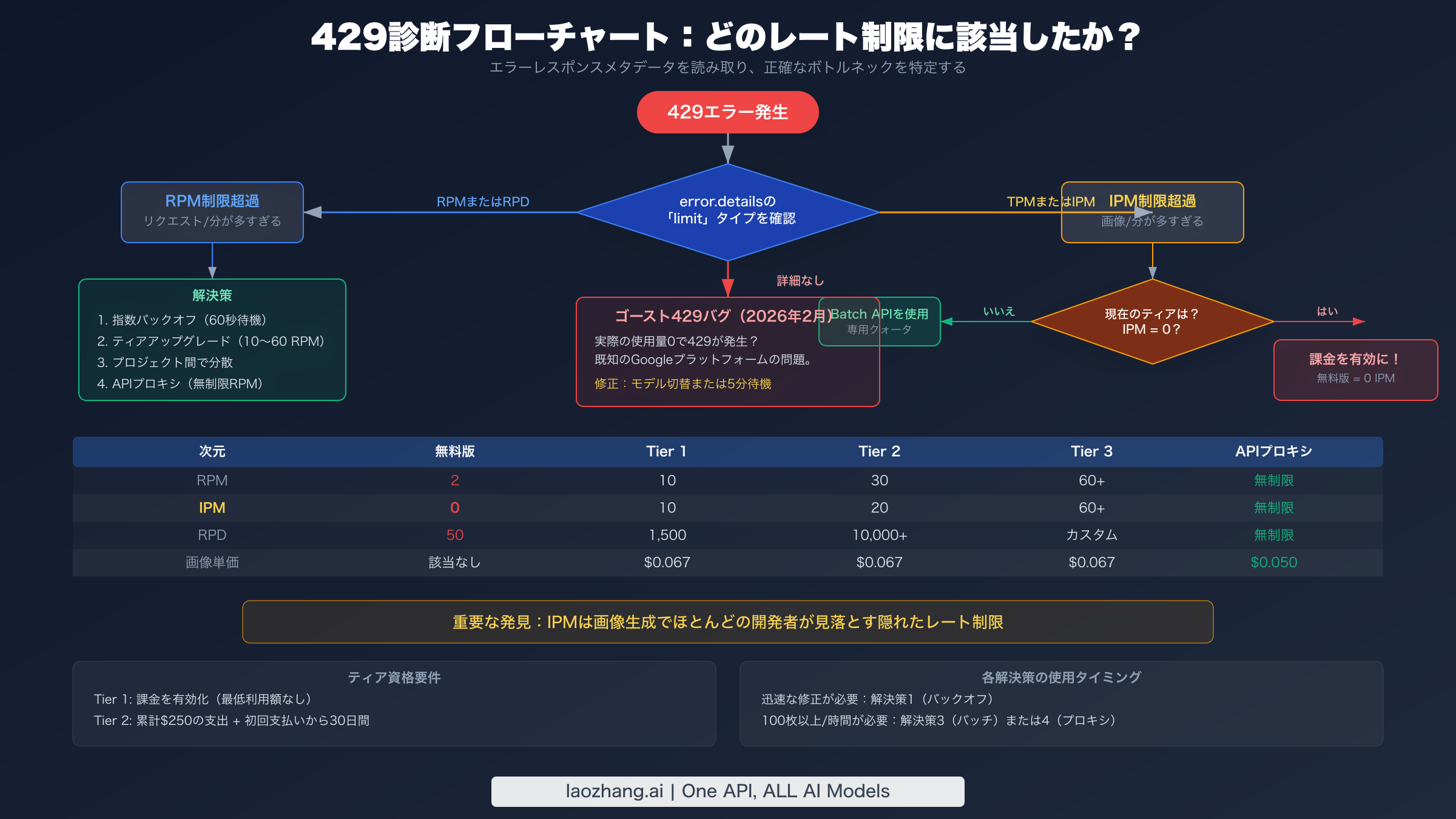
解決策に飛びつく前に、リクエストをブロックしている特定のレート制限次元を特定する必要があります。誤った修正を適用すると時間の無駄になります。指数バックオフはRPMの問題を解決しますが、ティアアップグレードが必要なIPMのボトルネックには何の効果もありません。診断プロセスでは、APIからのエラーレスポンスと時間の経過に伴う使用パターンの両方を調べる必要があります。Googleは常に429エラーボディに明示的な次元情報を含めるわけではないため、既知のリクエストパターンとエラーのタイミングを相関させて原因を絞り込む必要がある場合が多くあります。幸いなことに、各レート制限次元は体系的なアプローチで特定できる特徴的な障害パターンを生成します。
エラーレスポンスメタデータの読み取り
どのレート制限に該当したかを特定する最も直接的な方法は、429レスポンスのレスポンスヘッダーとエラーボディを解析することです。Googleはレスポンスヘッダーにレート制限メタデータを含めますが、存在する正確なヘッダーはどのクォータが消尽されたかによって異なる場合があります。以下のPythonスニペットは、失敗したリクエストからこの診断情報を抽出してログに記録する方法を示しています。このコードは429例外をキャッチし、すべてのレート制限関連ヘッダーを抽出し、どの次元がボトルネックかを即座に教えてくれる構造化診断レポートを出力します。
pythonimport google.generativeai as genai from google.api_core.exceptions import ResourceExhausted def diagnose_rate_limit(api_key: str, prompt: str): genai.configure(api_key=api_key) model = genai.GenerativeModel("gemini-3.1-flash") try: response = model.generate_content(prompt) return response except ResourceExhausted as e: print(f"429 RESOURCE_EXHAUSTED: {e.message}") # Parse error details for quota dimension if hasattr(e, 'errors') and e.errors: for error in e.errors: metadata = error.get('metadata', {}) print(f" Quota dimension: {metadata.get('quota_dimension', 'unknown')}") print(f" Quota limit: {metadata.get('quota_limit', 'unknown')}") print(f" Quota usage: {metadata.get('quota_usage', 'unknown')}") # Check for ghost 429 pattern if "usage: 0" in str(e) or "quota_usage: 0" in str(e.errors): print(" WARNING: Ghost 429 detected (usage=0).") print(" This matches the known Feb 2026 bug.") print(" Try switching model: gemini-3-pro or imagen-4") raise
3つの障害パターン
エラーメタデータの解析以外にも、障害の時間的パターンを観察することでレート制限次元を特定できます。RPM、RPD、IPMはそれぞれ異なる時間窓で動作するため、各次元は特徴的なシグネチャを生成します。エラーメタデータが不完全な場合や、ログしか利用できない本番環境でのデバッグ時に、これらのパターンを理解することは不可欠です。注目すべき3つのパターンは以下の通りです。
最初のパターンは「バースト後に成功」です。アプリケーションがリクエストを急速に送信し、いくつかの429エラーを受け、30〜60秒待った後に成功します。このパターンはRPM制限違反を強く示唆します。60秒間のスライディングウィンドウは連続的にリセットされるため、短い休止でクォータが回復します。2番目のパターンは「朝は動くが夜に失敗する」です。アプリケーションは日の早い時間帯は正常に動作しますが、後になると一貫して失敗し始めます。これはRPDの消尽を示しており、日次クォータが消費され太平洋標準時の深夜までリセットされません。3番目で最も厄介なパターンは「画像だけが失敗する」です。テキスト生成リクエストは完璧に成功しますが、すべての画像生成リクエストが429を返します。これはIPM消尽の特徴であり、RPM制限内にいるが画像固有のクォータを使い切った開発者にとって最も一般的な罠です。
有料アカウントで429エラーが表示されているが、Google Cloud Consoleでクォータに対する使用量がゼロと表示されている場合、上記のゴースト429バグに遭遇している可能性が高いです。これは正当なクォータ消尽とは別の問題です。無料版からTier 1に最近アップグレードした開発者は、このパターンに特に注意する必要があります。正当なレート制限と課金ティアの不一致を区別する方法の詳細については、有料ティアで無料ティアのリクエスト制限を受ける問題のガイドをご確認ください。
解決策1 — スマートリトライ付き指数バックオフ
指数バックオフは、429エラーに対して実装できる最もインパクトのある修正であり、インフラストラクチャの変更や課金の修正を一切必要としません。原則はシンプルです。リクエストが429で失敗した場合、リトライまでに指数関数的に増加する時間を待ちます。1秒、次に2秒、次に4秒、次に8秒というように増えていきます。これにより、レートリミッターが容量を解放する時間が確保され、クォータ回復ウィンドウ中にAPIを叩き続けることが防止されます。実際には、適切に実装された指数バックオフは、ピーク負荷時に80%の確率で失敗するアプリケーションを、最終的に99%以上のリクエストが成功するものに変換しますが、トレードオフとして複数回のリトライが必要なリクエストのレイテンシが増加します。
ジッターの重要性:Thundering Herd問題
シンプルな指数バックオフには、アプリケーションの複数インスタンスにデプロイされた場合に致命的な欠陥があります。10台のアプリケーションサーバーがすべて同じ瞬間に429に達し、同一の指数バックオフを実装した場合、すべてが全く同じタイミングでリトライします。1秒後、2秒後、4秒後という具合です。この同期化されたリトライ動作は、正確な間隔でレートリミッターを繰り返し圧倒する「Thundering Herd(雷鳴の群れ)」を発生させ、混雑を改善するどころか悪化させます。ランダムジッター(各待機時間への小さなランダムな変動)を追加すると、すべてのインスタンスでリトライの試行が非同期化されます。10台のサーバーがすべてt+1秒でリトライする代わりに、t+0.7秒、t+1.2秒、t+0.9秒というように、回復ウィンドウ全体に負荷を均等に分散させます。このシンプルな追加により、分散システムでの成功率が劇的に向上し、Google、AWS、Azureを含むすべての主要クラウドプロバイダーがベストプラクティスとして推奨しています。
Tenacityを使ったPython実装
tenacityライブラリは、Pythonで指数バックオフを実装する最もエレガントな方法を提供します。リトライロジック、ジッター、最大試行回数制限、例外フィルタリングのすべての複雑さを、クリーンなデコレータ構文で処理します。以下の実装は本番環境対応であり、ログ記録、設定可能なタイムアウト、リトライすべきでない他のAPI例外との429エラーの個別処理が含まれています。
pythonimport tenacity import google.generativeai as genai from google.api_core.exceptions import ResourceExhausted import logging logger = logging.getLogger(__name__) @tenacity.retry( retry=tenacity.retry_if_exception_type(ResourceExhausted), wait=tenacity.wait_exponential(multiplier=1, min=2, max=60) + tenacity.wait_random(0, 2), # jitter stop=tenacity.stop_after_attempt(8), before_sleep=tenacity.before_sleep_log(logger, logging.WARNING), reraise=True, ) def generate_image_with_retry(model, prompt: str): """429エラー時の自動指数バックオフ付き画像生成。""" response = model.generate_content( prompt, generation_config=genai.GenerationConfig( response_modalities=["image", "text"], ), ) return response genai.configure(api_key="YOUR_API_KEY") model = genai.GenerativeModel("gemini-3.1-flash") try: result = generate_image_with_retry(model, "A futuristic cityscape at sunset") # Process result.candidates[0].content.parts for image data except ResourceExhausted: logger.error("All retries exhausted. Consider upgrading tier.")
p-retryを使ったNode.js実装
Node.jsアプリケーションでは、p-retryパッケージがasync/awaitパターンにクリーンに統合されるPromiseベースのAPIで同等の機能を提供します。以下の実装はPythonバージョンと同じ動作をミラーし、同じ本番環境セーフガード(ジッター、最大試行回数、ログ記録、認証エラーや無効なプロンプトなどリトライ不可能なエラーの適切な分類)を含んでいます。
javascriptconst pRetry = require('p-retry'); const { GoogleGenerativeAI } = require('@google/generative-ai'); const genAI = new GoogleGenerativeAI('YOUR_API_KEY'); async function generateImageWithRetry(prompt) { const model = genAI.getGenerativeModel({ model: 'gemini-3.1-flash' }); return pRetry( async (attemptNumber) => { console.log(`Attempt ${attemptNumber} for image generation...`); const result = await model.generateContent({ contents: [{ role: 'user', parts: [{ text: prompt }] }], generationConfig: { responseModalities: ['image', 'text'] }, }); return result.response; }, { retries: 7, minTimeout: 2000, // 2 seconds initial wait maxTimeout: 60000, // 60 seconds maximum wait factor: 2, // exponential factor randomize: true, // adds jitter automatically onFailedAttempt: (error) => { if (error.status !== 429) { throw error; // don't retry non-429 errors } console.warn( `Rate limited. Attempt ${error.attemptNumber} failed. ` + `${error.retriesLeft} retries remaining.` ); }, } ); }
指数バックオフの本番環境向けヒント:最大リトライ回数を6〜10回に設定してください。ベース2秒でファクター2の場合、8回の試行で合計約8.5分の待機ウィンドウをカバーし、RPM制限のリセットには十分すぎるほどです。リクエストが無期限にハングすることを防ぐため、個別のリトライだけでなく操作全体に絶対タイムアウトを常に設定してください。本番ダッシュボードで429レートを監視し、リトライだけに頼るのではなくティアアップグレードのタイミングを知るために、試行回数と待機時間を含めてすべてのリトライをログに記録してください。
解決策2 — 課金ティアのアップグレード
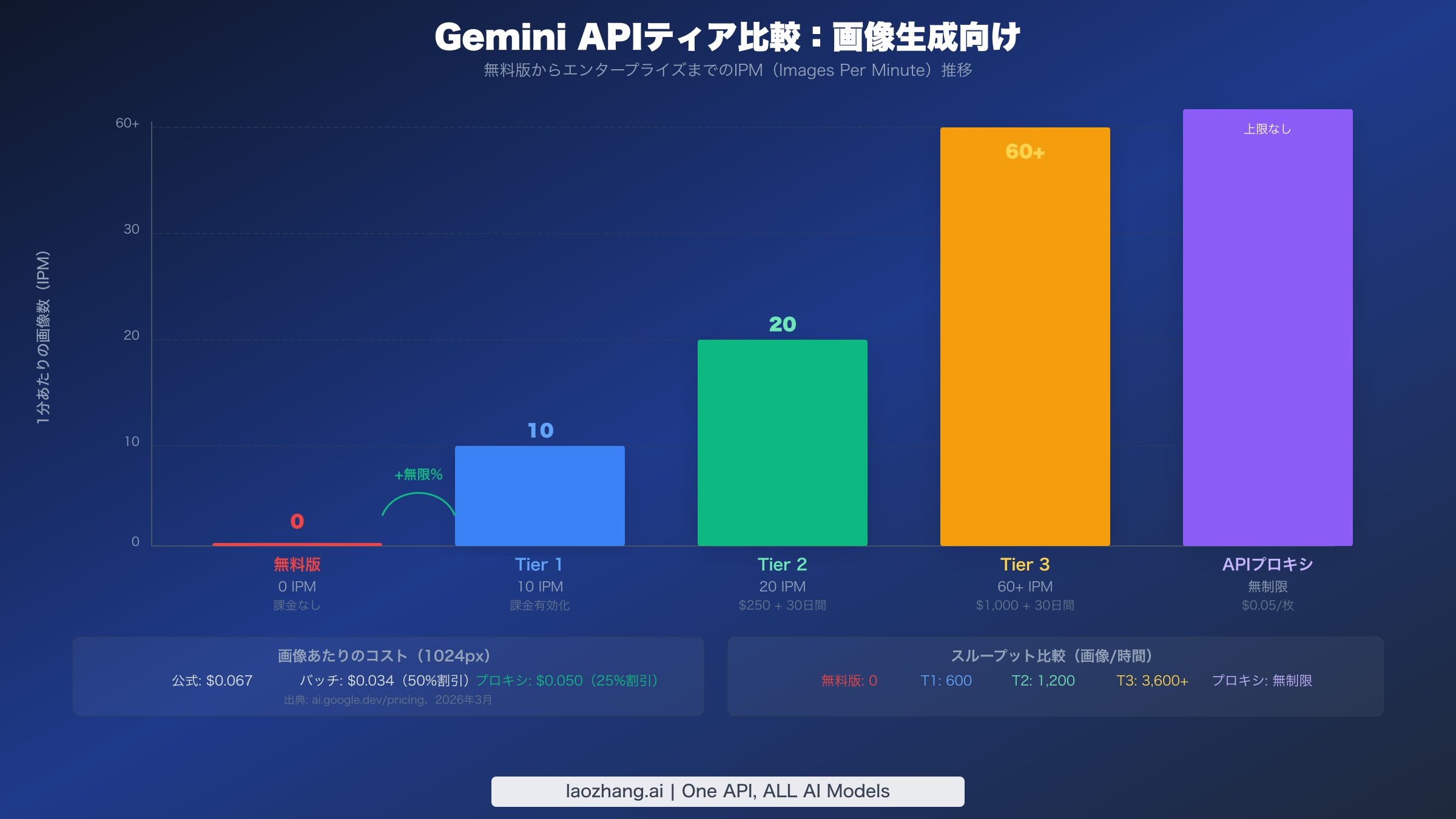
指数バックオフは一時的なレート制限スパイクを処理しますが、持続的な429エラーに対する最も信頼性の高い長期的ソリューションは、Google Cloudの課金ティアをアップグレードすることです。各ティアの引き上げにより、4つのレート制限次元すべてのクォータが倍増し、特に画像生成に関してはIPMの増加が最もインパクトのある変更です。多くの開発者は、無料版が画像生成を事実上完全に無効にしていることに気づいていません。IPMクォータは2025年12月に0に引き下げられました。Google Cloudプロジェクトで課金を有効にするだけで即座にTier 1に昇格し、最低利用額なしで10 IPMが解除されます。この単一のアクションだけで、初期の統合やテスト時に開発者が遭遇する429エラーの大半が解決されます。
画像生成のティア比較
ワークロードに適したレベルを選択するためには、各ティアの具体的なクォータを理解することが不可欠です。以下の表は、利用可能なすべてのティアにおいて画像生成に直接影響するレート制限を示しています。Tier 3の制限はGoogle Cloud営業を通じて交渉可能なため、表示されている数値はハードマキシマムではなく標準ベースラインを表しています。
| ティア | 月額支出要件 | 期間要件 | RPM | RPD | IPM | バッチTPD | 画像あたりコスト(1K) |
|---|---|---|---|---|---|---|---|
| 無料版 | なし | なし | 2 | 50 | 0 | 該当なし | 該当なし(ブロック) |
| Tier 1 | 課金有効化(最低額なし) | 即時 | 10 | 1,500 | 10 | 100万トークン | $0.067 |
| Tier 2 | 累計$250 | Tier 1から30日間 | 30 | 10,000以上 | 20 | 2.5億トークン | $0.067 |
| Tier 3 | 累計$1,000 | Tier 2から30日間 | 60以上 | 交渉可能 | 60以上 | 7.5億トークン | $0.067 |
無料版からTier 1への移行が圧倒的に最もインパクトのあるアップグレードです。0 IPM(画像生成不可)から10 IPMへの移行で、開発、テスト、低トラフィックの本番アプリケーションには十分です。1分間に10枚の画像は、1時間あたり600枚、連続稼働で1日あたり約14,400枚に相当し、ほとんどの中小規模のアプリケーションに十分すぎる量です。Tier 1からTier 2へのアップグレードではIPMが20に倍増し、RPDが1,500から10,000以上に劇的に増加するため、バーストではなく終日にわたって画像を生成するアプリケーションに重要です。
現在のティアの確認とアップグレード方法
現在の課金ティアを確認するには、Google Cloud Consoleに移動してプロジェクトの課金状況を調べる必要があります。Google Cloud Consoleを開き、プロジェクトを選択し、Billingに移動し、Generative Language APIセクションの「Quotas & System Limits」ページを確認してください。各クォータメトリクスの横に現在のティアが表示されます。IPMが0と表示されている場合、課金ページの表示に関係なく無料版です。これはよくある混乱の原因で、プロジェクトに課金アカウントがアタッチされていても、Generative AI APIに対して課金が有効になっているとは限らないためです。課金アカウントがプロジェクトにリンクされていること、かつAPIダッシュボードでGenerative Language APIの課金が有効になっていることの両方を確認する必要があります。有料アカウントが無料ティアの制限を受ける問題が続いている開発者向けに、すべての検証手順を説明したGemini画像生成の無料ティア制限ガイドを参照してください。
ティアアップグレードのタイムライン:Tier 1の有効化は課金を有効にした瞬間から即時です。Tier 2には累計$250の支出と30日間のアクティブなTier 1の利用の両方が必要です。1日で$250を使っても加速することはできません。同様にTier 3は累計$1,000の支出とTier 2で30日間が必要です。これらの期間制限はGoogle Cloudサポートチケットでは回避できないため、スケーリングニーズに先立ってティア昇進を計画してください。
解決策3 — 大量生成にBatch APIを使用する
Gemini Batch APIは、大量の画像を生成する必要があるがリアルタイムのレスポンスを必要としない開発者にとって、十分に活用されていないソリューションです。Batch APIの重要な利点は、リアルタイムAPIとは完全に分離されたクォータプールで動作するため、バッチ画像生成リクエストがRPM、RPD、IPMの制限にカウントされないことです。この分離により、Batch APIはリアルタイムパイプラインの強力な補完となります。緊急でない画像生成をバッチ処理にオフロードし、リアルタイムクォータはインタラクティブなユーザー向けリクエストに確保できます。さらに、GoogleはすべてのバッチAPIリクエストに50%のコスト割引を提供しており、大量ワークロードではリアルタイム生成よりも大幅に安価になります。
バッチ処理の仕組み
Batch APIは非同期のジョブベースモデルに従います。プロンプトのバッチを単一のジョブとして送信し、Googleが処理のためにキューに入れ、ジョブが完了するまで結果をポーリングします。サービスレベルアグリーメントでは24時間以内の完了が保証されていますが、実際にはほとんどのバッチジョブはボリュームと現在のシステム負荷に応じて2〜6時間で完了します。各バッチジョブには最大100件のリクエストを含めることができ、複数のバッチジョブを同時に送信できます。分離されたクォータプールにより、リアルタイムリクエストで10 IPMしかないTier 1アカウントでも、バッチ固有のトークン割り当て(Tier 1で1日100万トークン、Tier 2で2.5億、Tier 3で7.5億)によって制限されるだけで、Batch API経由で数千枚の画像を処理できます。一般的な画像生成リクエストは約1,000〜2,000トークンを消費するため、Tier 1のバッチ割り当てでもバッチパイプライン経由で1日500〜1,000枚の画像をサポートします。
Python実装:バッチ画像生成
以下のコードは、バッチ画像生成ジョブの作成、Gemini Batch APIへの送信、結果のポーリング方法を示しています。このパターンは、ECサイトのカタログ用商品画像の生成、SNSアセットの一括作成、A/Bテスト用の画像バリエーションの前処理などのワークフローに適しています。バッチジョブは内部でリトライを処理するため、バッチ送信に対して指数バックオフを実装する必要はありません。
pythonimport google.generativeai as genai import time import json genai.configure(api_key="YOUR_API_KEY") def batch_generate_images(prompts: list[str], model_name="gemini-3.1-flash"): """画像生成プロンプトのバッチを送信し、結果を待つ。""" # Prepare batch request batch_requests = [] for i, prompt in enumerate(prompts): batch_requests.append({ "custom_id": f"image-{i}", "request": { "model": model_name, "contents": [{"role": "user", "parts": [{"text": prompt}]}], "generation_config": { "response_modalities": ["image", "text"], }, }, }) # Submit batch job batch_job = genai.create_batch( requests=batch_requests, display_name=f"image-batch-{int(time.time())}", ) print(f"Batch job created: {batch_job.name}") print(f"Status: {batch_job.state}") # Poll for completion (24h SLA, typically 2-6h) while batch_job.state in ("QUEUED", "PROCESSING"): time.sleep(30) # Check every 30 seconds batch_job = genai.get_batch(batch_job.name) completed = sum(1 for r in batch_job.results if r.state == "COMPLETED") print(f" Progress: {completed}/{len(prompts)} completed") # Collect results results = {} for result in batch_job.results: if result.state == "COMPLETED": results[result.custom_id] = result.response else: print(f" Failed: {result.custom_id} - {result.error}") return results # 使用例 prompts = [ "A modern office workspace with natural lighting", "A coffee shop interior with warm ambiance", "A serene garden with Japanese maples", # ... up to 100 prompts per batch ] results = batch_generate_images(prompts) print(f"Successfully generated {len(results)} images")
コスト削減とティア別割り当て
50%のバッチ割引はすべての画像サイズに適用されるため、画像あたりのコストはリアルタイム生成よりも大幅に低くなります。1K解像度では、コストが1枚あたり$0.067から約$0.034に下がります。毎日数百または数千枚の画像を生成するチームにとって、この割引だけでバッチ処理インフラストラクチャへのアーキテクチャ投資を正当化できます。ティア別のバッチ固有トークン割り当ても注目に値します。これらはリアルタイムクォータとは独立して最大バッチスループットを決定するためです。
| ティア | バッチトークン割り当て(日次) | 概算画像容量 | 画像あたりコスト(1K、50%割引後) |
|---|---|---|---|
| Tier 1 | 100万トークン | 約500〜1,000枚 | $0.034 |
| Tier 2 | 2.5億トークン | 約12.5万〜25万枚 | $0.034 |
| Tier 3 | 7.5億トークン | 約37.5万〜75万枚 | $0.034 |
Tier 1からTier 2へのバッチ割り当ての劇的な増加(100万から2.5億トークン)は、バッチ処理を多用するワークロードにとってTier 2アップグレードを特に価値あるものにしています。アプリケーションが画像生成ニーズの大部分でバッチ処理の非同期的な性質を許容できる場合、インタラクティブリクエスト用のリアルタイムAPI呼び出しとバックグラウンドタスク用のバッチ処理を組み合わせることで、両方の利点を最大限に活用できます。バッチ処理によるコスト最適化の詳細な戦略については、Batch APIコスト最適化ガイドをご覧ください。
解決策4 — 無制限スループットのためのAPIプロキシ
アプリケーションがTier 3の制限を超えるスループットを必要とする場合、またはGoogle Cloud課金ティアとクォータ監視を管理する複雑さを回避したい場合、APIプロキシサービスはレート制限問題に対して根本的に異なるアプローチを提供します。APIプロキシは複数のAPIキーとGoogle Cloudプロジェクトを単一の統合エンドポイントの背後に集約し、リクエストをこのプール全体に分散して、プロジェクトごとのレート制限を効果的に排除します。アプリケーションの観点からは、単一のエンドポイントに単一のキーでAPI呼び出しを行い、プロキシがロードバランシング、クォータ追跡、自動フェイルオーバーを裏側で処理します。このアプローチは、複数のGoogle Cloudプロジェクトと課金アカウントを管理する運用オーバーヘッドなしに、本番環境レベルのスループットが必要なスタートアップや中規模企業にとって特に価値があります。
APIプロキシがレート制限を解決する仕組み
APIプロキシの根本的な洞察は、Googleのレート制限がユーザーや組織単位ではなく、プロジェクト単位で適用されるということです。プロキシサービスはN個のプロジェクトのプールを維持し、それぞれが独自の独立したクォータ割り当てを持ちます。リクエストが到着すると、プロキシは利用可能なクォータを持つプロジェクトにルーティングし、合計スループットをプール内のプロジェクト数で効果的に乗算します。各プロジェクトが10 IPMで、プールに20のプロジェクトが含まれる場合、実効制限は200 IPMとなり、単一のTier 3アカウントが提供できる限度をはるかに超えます。プロキシはまた、すべてのプロジェクトのクォータ使用状況をリアルタイムで監視し、制限に近いプロジェクトへのリクエスト送信を回避するインテリジェントルーティングを実装します。この分散アーキテクチャにより、プロキシには常に予備容量があるため、通常の運用条件下では429エラーが事実上不可能になります。
最小限のコード変更で済む
直接のGemini APIアクセスからプロキシエンドポイントへの切り替えは、ほとんどの実装で3行のコード変更のみで済みます。OpenAI互換インターフェースをサポートするAPIプロキシでは、多くの開発者がすでに慣れている標準のOpenAI SDKを使用できます。以下はPythonとNode.jsの変更前後の例です。
python# Before: Direct Gemini API import google.generativeai as genai genai.configure(api_key="YOUR_GOOGLE_API_KEY") model = genai.GenerativeModel("gemini-3.1-flash") # After: Through API proxy (OpenAI-compatible) from openai import OpenAI client = OpenAI( api_key="YOUR_PROXY_KEY", base_url="https://api.laozhang.ai/v1" # proxy endpoint ) response = client.chat.completions.create( model="gemini-3.1-flash", messages=[{"role": "user", "content": "Generate an image of a sunset"}], )
プロキシアプローチは、生のスループット以外にもいくつかの利点を提供します。まず、定額料金モデルが利用できます。laozhang.aiは解像度に関係なく1枚あたり$0.05を請求し、Googleのティアード価格設定(512px $0.045、1K $0.067、2K $0.101、4K $0.151)と比較できます。2Kまたは4K解像度で画像を生成するアプリケーションにとって、プロキシは実際には直接APIアクセスよりも安価です。次に、プロキシがすべてのリトライロジック、クォータ管理、エラーハンドリングを内部で処理するため、アプリケーションコードの複雑さが軽減されます。第三に、ティアアップグレードに必要な30日間の期間制限を回避し、初日から高スループットを提供します。
APIプロキシを使用すべきタイミング:60 IPM以上が必要なリアルタイムアプリケーション、Google Cloud課金の複雑さの管理を回避したいチーム、定額料金が公式のティアード価格よりも安い高解像度画像を生成するアプリケーション、ティアアップグレードの資格期間を待たずに迅速にスケールする必要があるプロジェクト。
解決策5 — マルチモデルフォールバック戦略
Gemini APIは画像生成が可能な複数のモデルを提供しており、各モデルバリアントは独立したレート制限を維持します。このアーキテクチャの詳細が、強力なフォールバック戦略の機会を生み出します。あるモデルがレート制限に達した場合、アプリケーションは利用可能なクォータを持つ代替モデルに自動的に切り替えます。このアプローチにより、ティアアップグレード、追加の課金アカウント、外部のプロキシサービスを必要とせずに実効スループットを倍増できます。トレードオフとして、異なるモデルは画像品質やスタイルがわずかに異なる場合があるため、すべての生成画像間の一貫性が重要でないアプリケーションに最適です。
フォールバックチェーンの構築
2026年初頭の画像生成で最も効果的なフォールバックチェーンは、優先順位で3つのモデルを使用します。gemini-3.1-flash-imageがプライマリモデル(最速、最安)、gemini-3-pro-imageがセカンダリモデル(高品質、やや遅い)、imagen-4が第三のフォールバック(専用画像モデル、異なるスタイル)です。各モデルはGoogleのレートリミッターによって独立に追跡される独自のRPM、IPM、RPDクォータを持ちます。プライマリモデルのIPMが消尽された場合、セカンダリモデルのIPMプールはリクエストを受信していないため、おそらく手つかずです。これにより、Tier 1での実効IPMは単一モデルの10 IPMではなく30(モデルあたり10 × 3モデル)になります。
以下のPython実装は、429エラーが発生した際に自動的にモデルをローテーションするModelFallbackClientクラスを作成します。解決策1の指数バックオフとモデルローテーションを組み合わせ、2層のレジリエンスを提供します。クライアントはどのモデルが現在レート制限されているかと推定回復時間を追跡し、スロットリングされていることがわかっているモデルへの無駄なリクエストを回避します。
pythonimport google.generativeai as genai from google.api_core.exceptions import ResourceExhausted import time import logging logger = logging.getLogger(__name__) class ModelFallbackClient: """429エラー時の自動モデルフォールバック付き画像生成クライアント。""" FALLBACK_CHAIN = [ "gemini-3.1-flash", # Primary: fast, cheap "gemini-3-pro", # Secondary: higher quality "imagen-4", # Tertiary: specialized image model ] def __init__(self, api_key: str): genai.configure(api_key=api_key) self.models = { name: genai.GenerativeModel(name) for name in self.FALLBACK_CHAIN } self.cooldowns = {} # model_name -> earliest_retry_time def generate_image(self, prompt: str, max_retries: int = 3): """画像を生成し、429エラー時にモデルチェーンをフォールバックする。""" for model_name in self.FALLBACK_CHAIN: # Skip models in cooldown if model_name in self.cooldowns: if time.time() < self.cooldowns[model_name]: logger.info(f"Skipping {model_name} (cooldown)") continue else: del self.cooldowns[model_name] for attempt in range(max_retries): try: logger.info(f"Trying {model_name} (attempt {attempt + 1})") response = self.models[model_name].generate_content( prompt, generation_config=genai.GenerationConfig( response_modalities=["image", "text"], ), ) return {"model": model_name, "response": response} except ResourceExhausted: wait = (2 ** attempt) + (time.time() % 1) # backoff + jitter logger.warning( f"{model_name} rate limited. " f"Waiting {wait:.1f}s before retry." ) time.sleep(wait) # All retries exhausted for this model — add cooldown and try next self.cooldowns[model_name] = time.time() + 60 logger.warning(f"{model_name} exhausted. Moving to next model.") raise ResourceExhausted("All models in fallback chain exhausted.") # 使用例 client = ModelFallbackClient("YOUR_API_KEY") result = client.generate_image("A photorealistic mountain landscape at dawn") print(f"Generated by: {result['model']}")
トレードオフと考慮事項
マルチモデルフォールバック戦略には限界がないわけではなく、これらのトレードオフを理解することがユースケースに適合するかどうかを判断する上で不可欠です。最も重大なトレードオフは視覚的一貫性です。gemini-3.1-flashとgemini-3-proは異なる基盤アーキテクチャとトレーニングデータを使用しているため、同じプロンプトでもモデル間で明らかに異なる結果を生成する可能性があります。各画像が独立するSNSコンテンツ生成のようなアプリケーションでは、この不一致は問題になりません。すべての画像間で視覚的一貫性が重要な商品カタログ生成のようなアプリケーションでは、別のモデルへのフォールバックが確立されたビジュアルスタイルと衝突する結果を生成する可能性があります。もう一つの考慮事項は、imagen-4がGeminiモデルとは異なるAPIコントラクトを使用することです。これはマルチモーダルLLMではなく専用の画像生成モデルであるため、最適な結果を得るにはプロンプトにわずかな調整が必要になる場合があります。上記のフォールバッククライアントはこれを透過的に処理しますが、この戦略を本番環境にデプロイする前に、3つのモデルすべてで特定のプロンプトをテストして品質の違いを理解することをお勧めします。
どのソリューションを選択すべきか?
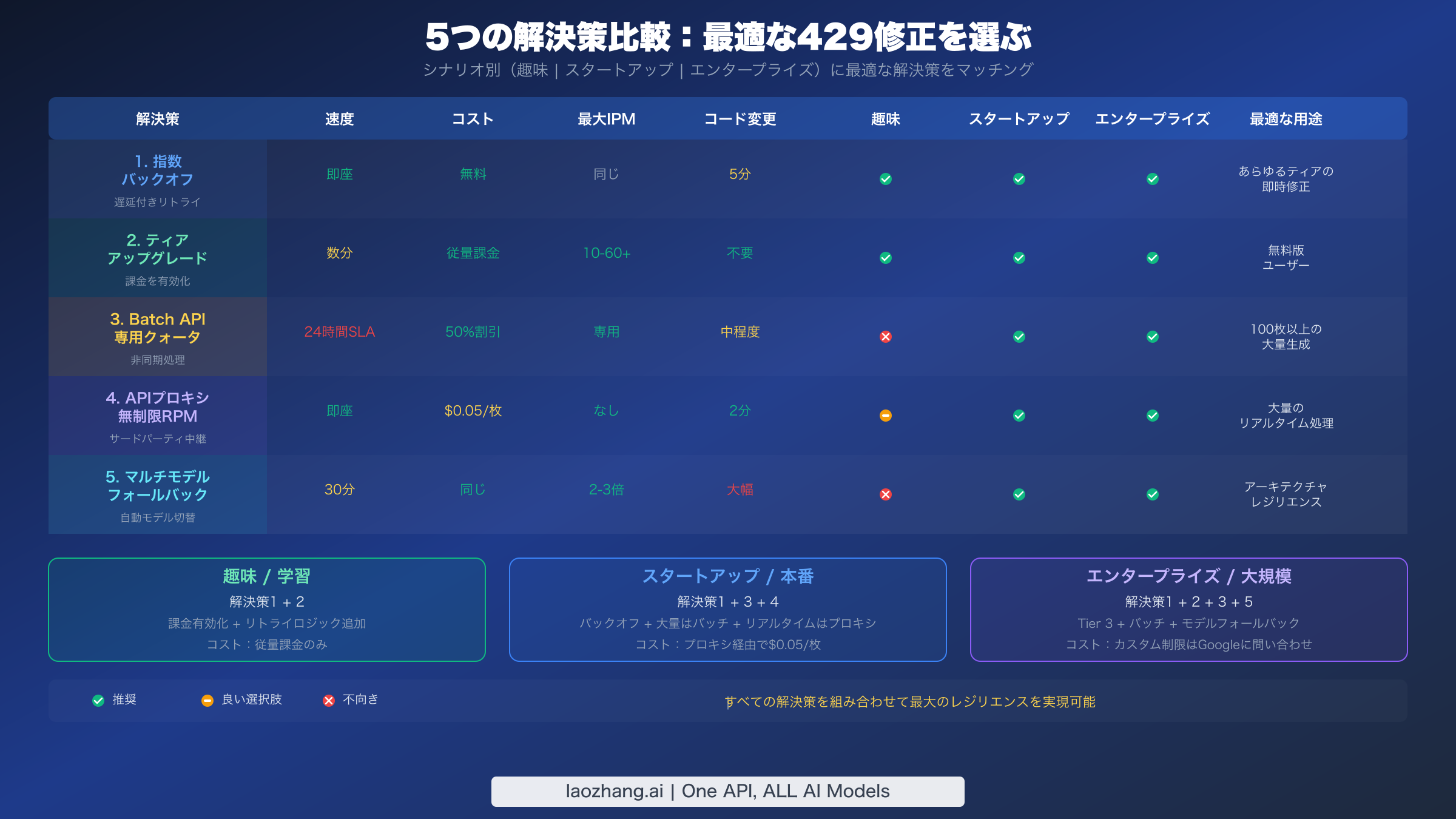
ソリューションの適切な組み合わせを選択するには、アプリケーションのスループット、レイテンシ、コスト、運用の複雑さに関する具体的な要件に依存します。万能なソリューションは存在しません。画像を時々生成する趣味のプロジェクトと、数百万のユーザーにサービスを提供するエンタープライズプラットフォームでは、根本的に異なるアプローチが必要です。以下の表は、3つの一般的な開発者プロファイルを推奨するソリューションの組み合わせにマッピングし、各推奨の根拠も示しています。実際には、ほとんどの本番アプリケーションは最大のレジリエンスのために2〜3のソリューションを組み合わせることになり、指数バックオフは規模に関係なくすべての実装が含めるべき普遍的な基盤として機能します。
| プロファイル | 推奨ソリューション | 月間画像ボリューム | 予想コスト | 根拠 |
|---|---|---|---|---|
| 趣味 / 個人プロジェクト | 解決策1(バックオフ)+ 解決策2(Tier 1) | 10,000枚未満 | $10未満 | Tier 1で10 IPM解除、バックオフでバーストを処理 |
| スタートアップ / 成長中のアプリ | 解決策1 + 解決策3(バッチ)+ 解決策4(プロキシ) | 1万〜50万枚 | $50〜$500 | バッチで大量処理、プロキシでリアルタイムのオーバーフロー対応 |
| エンタープライズ / 大規模 | 解決策1 + 解決策2(Tier 3)+ 解決策3 + 解決策5(フォールバック) | 50万枚以上 | $500以上 | 専用クォータによる多層レジリエンス |
初めて429エラーに遭遇するほとんどの開発者にとって、アクションプランは明確です。まず指数バックオフを即座に実装し(解決策1、15分で完了)、次に課金を有効にしてTier 1に到達する(解決策2、GCPコンソールで5分)。この2つの変更だけで、1分間に10枚未満の画像を生成するアプリケーションの429エラーの95%が解決されます。ニーズがそれを超えて増加した場合は、緊急でない生成にBatch APIを追加し、ティア制限を超えるリアルタイムワークロードにAPIプロキシを検討してください。
429レート制限はどのくらい続くのですか? 持続時間はどの次元に該当したかによって異なります。RPM制限は60秒間のスライディングウィンドウでリセットされるため、わずか1分待つだけで1分あたりの全クォータが回復します。RPD制限は太平洋標準時の深夜にリセットされるため、午後に日次制限に達すると数時間の待機が必要になります。IPM制限はRPMと同じ60秒ウィンドウに従います。ゴースト429バグには予測可能な持続時間がありません。数時間で解決したと報告する開発者もいれば、モデルの切り替えやAPIキーの再作成が必要だった開発者もいます。
60 IPM以上を取得できますか? はい。Tier 3の制限は「60+」と記載されており、交渉可能です。GCPコンソールを通じてGoogle Cloud営業に連絡し、より高いスループットの正当なビジネスニーズを証明できれば、数百または数千IPMに達するカスタムクォータ割り当てをGoogleがプロビジョニングします。コミットされた利用契約のエンタープライズアカウントは、通常、コミットされたボリュームに応じた価格割引を含むGoogle Cloud全体の契約の一部としてカスタム制限を交渉します。
APIプロキシの使用は安全ですか? 評判の良いAPIプロキシは透過的な転送レイヤーとして機能します。リクエストを受信し、管理された認証情報の1つを使用してGoogleのAPIにルーティングし、レスポンスを返します。プロキシはリクエストの完了に必要な時間を超えてプロンプト、生成された画像、APIレスポンスを保存しません。とはいえ、リクエストコンテンツをプロキシ運営者に委ねることになるため、明確なプライバシーポリシーと開発者コミュニティでの実績を持つ確立されたサービスを選択してください。セキュリティモデルはサードパーティのSaaS APIを使用する場合と同等です。機密性の高いプロンプトを送信する前に、プロバイダーの評判とデータ処理方法を評価する必要があります。
使用量0なのに429が出るのはなぜですか? これはほぼ確実に、最近アップグレードされたTier 1アカウントに影響する2026年2月のゴースト429バグです。即座の回避策はモデルバリアントの切り替えです。gemini-3.1-flashを使用している場合はgemini-3-proを試すか、その逆を試してください。同じプロジェクト内で新しいAPIキーを作成して解決した開発者もいますが、これは一貫して効果的ではありません。Googleはこの問題を認めており、恒久的な修正に取り組んでいます。ティアアップグレードから48時間以上問題が続く場合は、プロジェクトIDとヘッダー内のクォータメタデータを含む具体的なエラーレスポンスボディを添えて、Google Cloud Consoleからサポートチケットを開いてください。