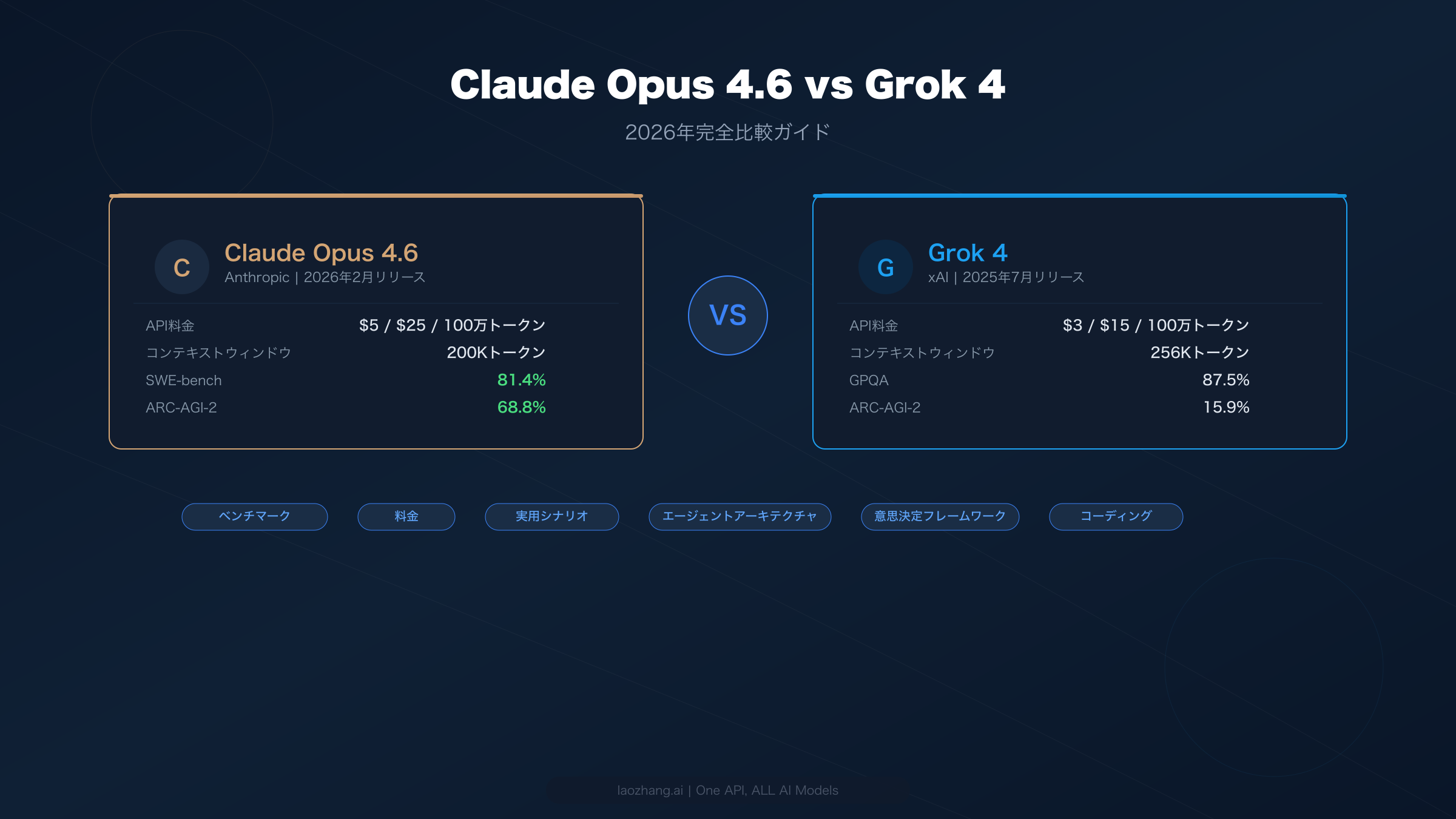
Claude Opus 4.6はほとんどのベンチマークでGrok 4を上回っています。SWE-bench(81.4% vs 同等レベル)、ARC-AGI-2(68.8% vs 15.9%)、推論タスクなどで優位に立ちますが、100万トークンあたり$5/$25とGrok 4の$3/$15と比べて67%高いコストがかかります。予算を重視する開発者にとっては、Grok 4 Fastバリアントが100万トークンあたりわずか$0.20/$0.50で、200万トークンのコンテキストウィンドウとともにAPIアクセスを提供しており、2026年で最もコストパフォーマンスに優れたフロンティアモデルの選択肢の一つとなっています。
まとめ — クイック比較表
Claude Opus 4.6とGrok 4のどちらを選ぶかは、最終的に何を優先するかによって決まります。純粋なコーディングと推論性能を重視するのか、それとも強力な数学的能力を備えたコスト効率を重視するのか。両モデルとも2026年のAI能力の最前線に位置していますが、対象とするユーザー層やユースケースは明確に異なります。以下の表では、API料金からベンチマーク性能、エコシステムの成熟度まで、最も重要な観点での比較をまとめています。まずこの表で全体像を把握し、その後ご自身のニーズに合ったセクションを詳しくお読みください。
| 機能 | Claude Opus 4.6 | Grok 4 | 優勢 |
|---|---|---|---|
| API入力料金 | $5.00/100万トークン | $3.00/100万トークン | Grok 4 |
| API出力料金 | $25.00/100万トークン | $15.00/100万トークン | Grok 4 |
| コンテキストウィンドウ | 200Kトークン | 256Kトークン | Grok 4 |
| SWE-bench | 81.4% | 約72%(推定) | Claude |
| ARC-AGI-2 | 68.8% | 15.9% | Claude |
| GPQA | 84.0% | 87.5% | Grok 4 |
| 数学指標 | 約88% | 92.7% | Grok 4 |
| 速度 | 約80トークン/秒 | 40.6トークン/秒 | Claude |
| コーディングCLI | Claude Code(ネイティブ) | なし | Claude |
| マルチエージェント | Agent Teams(API) | 4.20 Beta(コンシューマー) | Claude |
| サブスクリプション | $20/月(Pro) | $30/月(SuperGrok) | Claude |
| バジェットAPI | Haiku 4.5($1/$5) | Fast($0.20/$0.50) | Grok 4 |
パターンは明確です。Claudeはソフトウェアエンジニアリングと推論ベンチマークで優位に立ち、Grokはより良い料金設定と強力な数学性能を提供します。しかし、本当の話はどの表でも示せないほど細やかです。特に、各社がエージェントアーキテクチャや開発者ツールに対して取る根本的に異なるアプローチを考慮するとなおさらで、これについては以下で詳しく探っていきます。「バジェットAPI」の行について一つ重要な注意点があります。Grok 4 Fastは単にGrok 4の安価版ではなく、200万トークンという巨大なコンテキストウィンドウを持つ根本的に異なるモデルであり、フラグシップGrok 4とはまったく異なるユースケースに適しています。同様に、Claude Haiku 4.5もOpusとは異なる品質と速度のトレードオフを行っています。バジェットティア同士を比較することはコスト計画に有用ですが、性能が重要なアプリケーションではフラグシップの直接的な代替として扱うべきではありません。
2026年のモデル環境を理解する
Claude Opus 4.6とGrok 4を直接比較する前に、各モデルがそれぞれのファミリー内でどのような位置にあるかを理解することが重要です。これはGrok側で特に重要で、モデルラインナップが本当に混乱を招くものになっています。経験豊富な開発者でさえそうです。xAIは異なるアクセスティアにわたって複数のバリアントをリリースしており、どの「Grok 4」を実際にClaudeと比較評価しているのかを理解することが、公正な比較において大きな違いを生みます。
Claude Opus 4.6は、2026年3月時点でAnthropicのモデル階層の最上位に位置しています。2026年2月5日にリリースされ、Anthropicの最も高性能な推論モデルを代表しており、Claude Sonnet 4.6(100万トークンあたり$3/$15のバランス型オプション)とClaude Haiku 4.5(100万トークンあたり$1/$5の速度最適化オプション)の上に位置づけられています。命名体系はシンプルです。Opusは最大能力、Sonnetは性能とコストの最適なバランス、Haikuは速度と効率のためです。フロンティアAI能力の文脈で「Claude」と言えば、ほぼ常にOpusティアを指しています。ClaudeファミリーにおけるOpusとSonnetの比較については、Claude Opus vs Sonnet比較ガイドをご覧ください。
Grokモデルファミリー(重要な背景情報)
Grokの環境は最も混乱が生じるところであり、現在のTOP 10検索結果にある他の比較記事ではこの点を十分に説明していません。2026年3月時点のGrok 4ファミリーの完全な内訳を以下に示します(docs.x.aiで検証済み)。
Grok 4(grok-4-0709)はフラグシップモデルで、2025年7月9日にリリースされました。常時オンの推論機能(非推論モードはありません)、256Kのコンテキストウィンドウ、そして100万トークンあたり入力$3.00/出力$15.00の料金設定が特徴です。これがClaude Opus 4.6と直接競合するモデルです。重要な違いの一つは、Grok 4の推論は常にアクティブであり、常により深い思考プロセスに対して課金されるということです。一方、Claude Opus 4.6は拡張思考をオプション機能として提供しており、開発者にはよりきめ細かなコスト制御が可能です。
Grok 4 Fastバリアントには、推論モードと非推論モードの両方(grok-4-fast-reasoningとgrok-4-fast-non-reasoning)、およびその4.1バージョンがあります。これらは200万トークンの巨大なコンテキストウィンドウを共有し、100万トークンあたりわずか$0.20/$0.50のコストで、Claude Opus 4.6の15-25分の1の価格です。一部の能力を犠牲にして劇的なコスト削減を実現していますが、多くのアプリケーションでは十分以上の性能を発揮します。200万トークンのコンテキストウィンドウは、他のモデルではチャンク分割が必要になるコードベース全体や長大なドキュメントの処理に特に有用です。
Grok 4.20 Betaは、2026年2月17日に提供開始されたコンシューマー向けマルチエージェントシステムです。SuperGrok(月額$30)およびSuperGrok Heavy(月額$300)を通じて利用可能で、Captain、Research、Logic、Creativeという4つの専門エージェントが複雑なタスクで協力して作業します。これはClaudeのAgent Teamsに対するxAIの回答ですが、アーキテクチャセクションで探る根本的に異なる哲学に基づいています。注目すべきは、Grok 4.20 BetaにはまだAPIアクセスがないため、現時点では純粋にコンシューマー向け製品であることです。
この理解がなぜ重要なのか
オンラインでベンチマーク比較を見るとき、ほとんどの自動生成比較ツールはどのGrokバリアントかを明記せず、またAPI機能なのかコンシューマー機能なのか、それとも純粋なモデル性能なのかを区別せずに「Claude Opus 4.6」と「Grok 4」を比較しています。公正な比較では、ベンチマークと料金分析には標準のGrok 4 APIと照合し、Fastバリアントは魅力的なバジェット代替として、4.20 BetaはClaude Proに対する興味深いコンシューマー競合として認識すべきです。
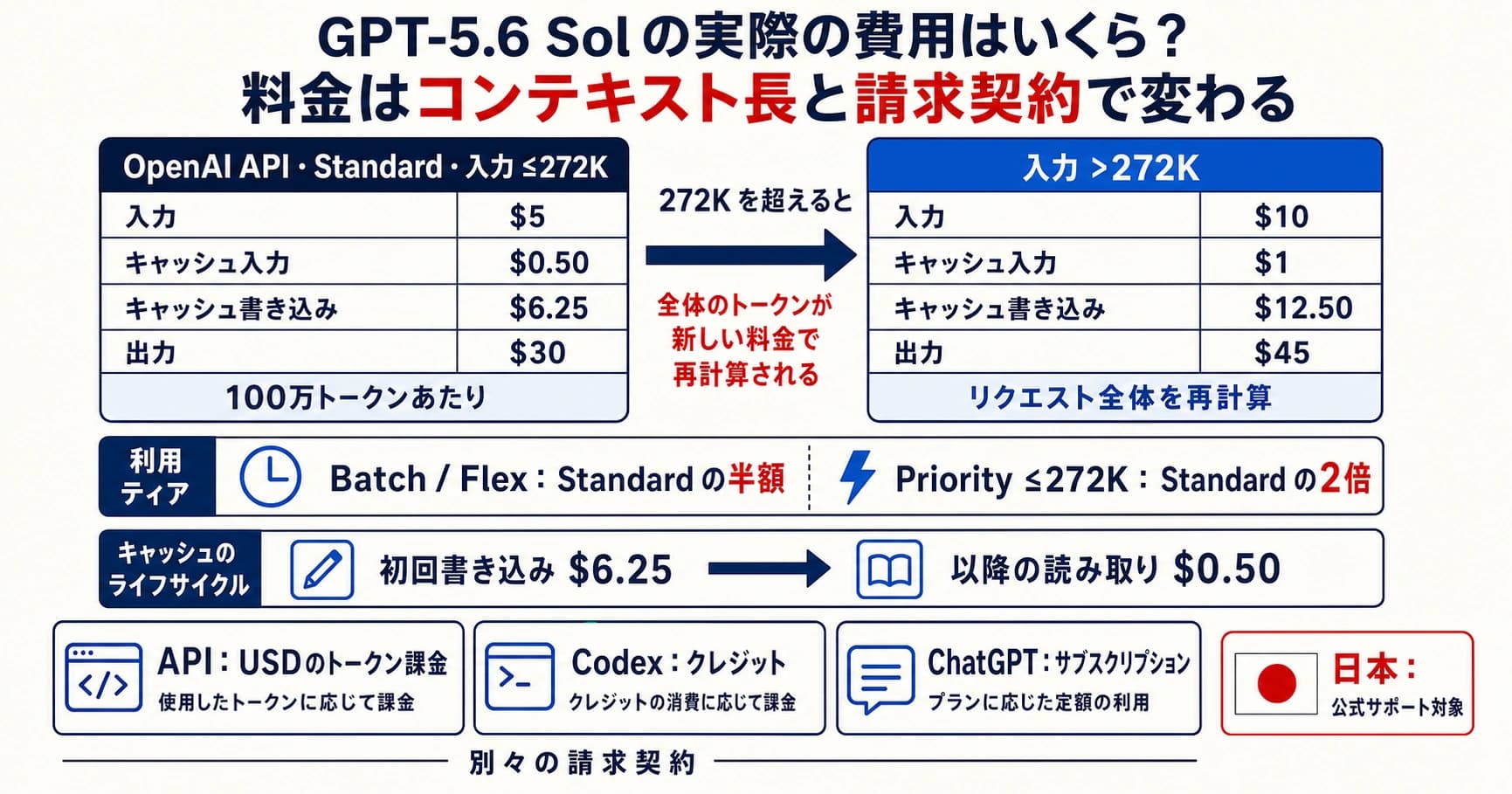
料金詳細分析 — すべてのコストが重要
これらのモデルの真のコストを理解するには、トークンあたりの料金だけでなく、実際の使用シナリオでいくらかかるかを検討する必要があります。見出しの数字 — Claudeの$5/$25対Grokの$3/$15 — はストーリーの一部に過ぎません。各モデルが推論トークン、キャッシング、ティアードアクセスをどのように処理するかによって、特定のユースケースに完全に依存する大きなコスト差が生まれます。Claudeの全ティアにわたる料金の包括的な解説は、Claude Opus 4.6料金ガイドをご覧ください。
API料金:全体像
コアAPI料金の比較では、Grok 4が入力・出力トークンの両方で40%のコスト優位性を持つことが分かります。しかし、いくつかの要因がこの単純な計算を複雑にします。Claude Opus 4.6は100万入力トークンあたり$5.00、100万出力トークンあたり$25.00を課金します(platform.claude.com、2026年3月確認)。Grok 4は100万トークンあたり入力$3.00、出力$15.00で、キャッシュ入力トークンは100万あたり$0.75で利用可能です(docs.x.ai、2026年3月確認)。Grok 4のプロンプトキャッシング割引は100万トークンあたり$0.75で、Claudeのキャッシングティアよりも積極的な設定であり、システムプロンプトや参照ドキュメントを複数のAPI呼び出しで再利用するアプリケーションではコストを大幅に削減できます。
バジェットティアの比較では、格差がさらに劇的になります。Anthropicの最も手頃なオプションはClaude Haiku 4.5で100万トークンあたり$1.00/$5.00です。これは堅実なバリュープロポジションですが、Grok 4 Fastの$0.20/$0.50と比べるとまだ5倍高価です。フロンティアレベルに近い能力をフロンティア料金なしで必要とする大量処理アプリケーションにとって、Grok 4 Fastバリアントは市場で最もコストパフォーマンスに優れた選択肢の一つです。また、Haikuのより控えめなコンテキストと比較して、200万トークンのコンテキストウィンドウも提供しています。
コンシューマーサブスクリプション料金
API統合よりもサブスクリプションアクセスを好むユーザーにとって、Claude Proは月額$20で、寛大な使用制限付きでOpus 4.6へのアクセスを提供します。xAIの同等のサービスであるSuperGrokは月額$30で、Grok 4に加えて4.20 Betaマルチエージェントシステムへのアクセスが含まれます。SuperGrok Heavyは月額$300で、より高いレート制限と優先アクセスを必要とするパワーユーザーや企業を対象としています。純粋なサブスクリプション価値の観点からは、Claude Proがより低い月額コストでフロンティアティアのアクセスを提供しますが、SuperGrokにはClaudeのサブスクリプションティアには含まれないマルチエージェント機能がバンドルされています。
タスクあたりのコスト分析:実際に支払う金額
生のトークン料金は実際のタスクにマッピングして初めて意味を持ちます。典型的なトークン消費パターンに基づく5つの一般的な開発タスクの実際のコストを以下に示します。500行のプルリクエストの標準的なコードレビュー(約4,000入力トークン、2,000出力トークン)は、Claude Opus 4.6で約$0.07、Grok 4で約$0.04です。個別のタスクレベルではほとんど気にならない約3セントの差です。50ページの技術文書の分析(約25,000入力トークン、5,000出力トークン)は、Claudeで約$0.25、Grokで約$0.15です。平均10ターンのチャットボット会話はClaudeで約$0.05、Grokで約$0.03です。拡張コンテキストを使用するバグデバッグセッションは通常、Claudeで$0.50-$1.00、Grokで$0.30-$0.60です。最大コンテキストウィンドウを使用した完全なコードベース分析は、Claude(200Kトークン)で約$1.00、Grok(256Kトークン)で約$0.77です。
コストの差はスケールで意味を持ちます。1日1,000回のAPI呼び出しを行う開発チームは、Claude Opus 4.6の代わりにGrok 4を選択することで1日あたり約$30-$50、月額では約$900-$1,500を節約できます。ただし、その呼び出しの一部にGrok 4 Fastで十分な場合、節約効果は劇的に複合します。タスクの80%にGrok 4 Fastを使用し、複雑な推論にはGrok 4を確保する方式では、月額請求額を$200未満に削減できる可能性があります。これは全てClaude Opusを使用した場合の$1,500以上と比較してのことです。
Anthropicもまた、Claudeファミリー内でティアード料金を提供していることに注目する価値があります。Claudeユーザーのための実用的なコスト最適化戦略は、単純なタスクにはClaude Haiku 4.5(100万トークンあたり$1/$5)を、中程度の複雑さのタスクにはSonnet 4.6($3/$15)を、そしてフロンティアレベルの推論が本当に必要なタスクにのみOpus 4.6を使用するというルーティングです。このアプローチにより、すべてにOpusを使用する場合と比べてClaudeファミリーのコストを60-70%削減できます。同じ原則はGrok側にも当てはまります。Fastバリアントをデフォルトとして使用し、必要な場合にのみ標準Grok 4にエスカレーションしましょう。
ベンチマーク詳細分析 — 数値の真の意味

ベンチマークスコアはAIモデル比較のあらゆるところに存在しますが、文脈のない生の数値は無意味どころか誤解を招きます。GPQAでの5パーセントポイントの差は、SWE-benchでの同じ差とはまったく異なる実用的な意味を持ちます。このセクションでは、各主要ベンチマークが実際に何を測定しているのか、スコアが実世界の能力についての何を示しているのか、そして各モデルが本当に優れている部分とその差が無視できる部分を解説します。
コーディングベンチマーク:Claudeがリードする領域
SWE-bench Verifiedは、実際のソフトウェアエンジニアリングタスクを解決するモデルの能力を評価するためのゴールドスタンダードです。人気のあるオープンソースPythonリポジトリから実際のバグを修正する能力を評価します。Claude Opus 4.6はこのベンチマークで81.4%を記録しており(Anthropic公式発表、2026年2月)、Grok 4の推定約72%に対して大幅なリードを示しています。これは些細な差ではありません。Claudeが、Grokでは失敗する実世界のコーディングタスクを約10件中1件多く正常に解決することを意味します。コード支援にこれらのモデルを評価する開発チームにとって、この差は手動介入の減少とイテレーションサイクルの高速化に直接つながります。
Terminal-Benchはエージェント型コーディング能力を測定します。ターミナル環境で自律的に操作し、コマンドを実行し、出力を解釈し、解決策を反復する能力です。Claude Opus 4.6はここで43.2%を記録していますが、Grok 4は公式結果を公表していないベンチマークです。この指標は、AIがコード補完ツールとしてだけでなく半自律的なペアプログラマーとして機能するエージェント型コーディングワークフローを開発者が採用するにつれて、ますます重要になっています。Terminal-BenchでGrok 4のスコアが欠如していること自体が示唆的です。xAIはGrokをエージェント型コーディングモデルとして位置づけておらず、一方AnthropicはこのCapability中心に製品全体(Claude Code)を構築しています。自律的な開発タスクにどちらのモデルを使用するかを検討するチームにとって、この戦略的焦点の違いはベンチマーク数値そのものと同じくらい重要です。
推論ベンチマーク:劇的な差
ARC-AGI-2は新規な推論能力をテストするために設計されています。パターンマッチングではなく、真の理解を必要とする流動的知性の一種です。ここでの差は驚異的です。Claude Opus 4.6は68.8%に対し、Grok 4は15.9%です。この4.3倍の差は、主要なベンチマークにおいてこの2つのモデル間で最大の性能差です。実用的に何を意味するのでしょうか。ARC-AGI-2のタスクでは、抽象的なパターンを識別し新しいコンテキストに適用する必要があります。これはまさに、複雑なソフトウェアアーキテクチャの決定、クリエイティブな問題解決、そして解決パスが明確に定義されていないタスクで重要な推論です。もしあなたの仕事が日常的に新規な推論の課題を伴うのであれば、このベンチマーク差は実世界の性能差を高く予測するものです。
知識と数学:Grokが優位な領域
GPQA(Graduate-level Professional Quality Assurance)は、複数の科学分野にわたる専門家レベルの知識をテストします。Grok 4はここで87.5%対Claudeの84.0%とリードしています。意味のある差ですが劇的ではありません。これはGrokが科学、医学、技術分野での深いドメイン知識を必要とするタスクでわずかに優位であることを示唆しています。数学指標も同様のストーリーを語ります。Grok 4の92.7%対Claudeの約88%は、より強力な数学的推論を示しています。数学的計算、統計分析、科学的推論に大きく依存するアプリケーションにとって、Grokの優位性は複数の数学系ベンチマークにわたって実在し一貫しています。
速度とレイテンシー:本番環境要因
本番アプリケーションでは、生のベンチマークスコアよりも品質と速度の組み合わせが重要です。Claude Opus 4.6は毎秒約80トークンを生成し、Grok 4の毎秒40.6トークンの約2倍です(pricepertoken.com、2026年3月)。最初のトークンまでの時間(TTFT)の差はさらに顕著です。Claudeのレスポンスは約1.5秒で始まるのに対し、Grok 4は10.79秒です。TTFTの約10秒の差は、インタラクティブなアプリケーション — チャットボット、コーディングアシスタント、リアルタイム分析ツールなど、ユーザーが即座のレスポンスを期待する場合に決定的です。Grok 4の常時オン推論はレイテンシーの高さに寄与しており、タスクが必要とするかどうかに関わらず、すべてのリクエストが深い推論パイプラインを通過します。
コーディングと開発:Claudeが際立つ領域

コーディングアシスタントとしてこれらのモデルを評価する開発者にとって、比較はベンチマークスコアをはるかに超え、各プラットフォームが提供するツール、統合、開発者体験のエコシステムにまで及びます。ここがClaudeとGrokの差が最も顕著になる部分です。Grok 4がコーディングモデルとして劣っているからではなく、AnthropicがClaude中心の包括的な開発ワークフロー構築に大きく投資してきたからです。
Claude CodeはAnthropicのネイティブコマンドラインツールで、Claudeにターミナル、ファイルシステム、開発環境への直接アクセスを提供します。単なるAPIラッパーではなく、コードベースを読み取り、ファイルを作成・編集し、テストを実行し、git操作を管理し、自律的にソリューションを反復するエージェント型コーディングシステムです。Grokエコシステムには同等のツールが存在しません。この単一の製品が、APIアクセスだけではGrokがまったく太刀打ちできない開発者体験のカテゴリーを創出しています。既にClaude Codeを使用しているチームにとって、Grokへの切り替えコストには、このエージェント型コーディングワークフロー全体の喪失が含まれます。
Agent TeamsはClaude 4.6で導入され、開発者が複数のClaudeインスタンスを並行してタスクの異なる側面に取り組むように編成することを可能にします。あるエージェントがコード記述を担当し、別のエージェントがテストを管理し、3番目のエージェントが品質レビューを行います。このマルチエージェント機能はAPIを通じて動作し、きめ細かな権限制御とエージェントごとの分離されたgitワークツリーをサポートし、並行ワークストリーム間の干渉を防ぎます。これらの機能の詳細については、Claude Agent Teamsガイドをご覧ください。
Grok 4のコーディング能力は、広範なベンチマークこそ少ないものの、独自の利点を持っています。常時オン推論により、すべてのコーディングリクエストがデフォルトで深い分析を受けます。これは、Grokの92.7%の数学指標の優位性がより良いソリューションに変換される複雑なアルゴリズム問題や数学的コードで有益です。Grok 4 Fastバリアントで利用可能な200万トークンのコンテキストウィンドウは、大規模なコード分析に真に有用です。Claudeの200K制限を超えるリポジトリ全体や長い依存関係チェーンの処理に最適です。さらに、Grok 4 Fastの$0.20/$0.50の料金設定により、Claude Opus 4.6では法外に高価になる自動化コード分析パイプラインの大規模実行が経済的に可能になります。
ほとんどの開発チームへの実用的な推奨事項は、マルチモデルアプローチを検討することです。インタラクティブなコーディングセッション、複雑なデバッグ、エージェント的な動作が必要なタスクにはClaude Opus 4.6(特にClaude Code)を使用しましょう。バッチ処理、数学的計算、コスト効率がピーク性能よりも重要な大量分析タスクにはGrok 4またはGrok 4 Fastを割り当てましょう。この混合アプローチは、コストを効果的に管理しながら各モデルの最良の機能を活用します。
エージェントアーキテクチャ — 二つの異なる哲学
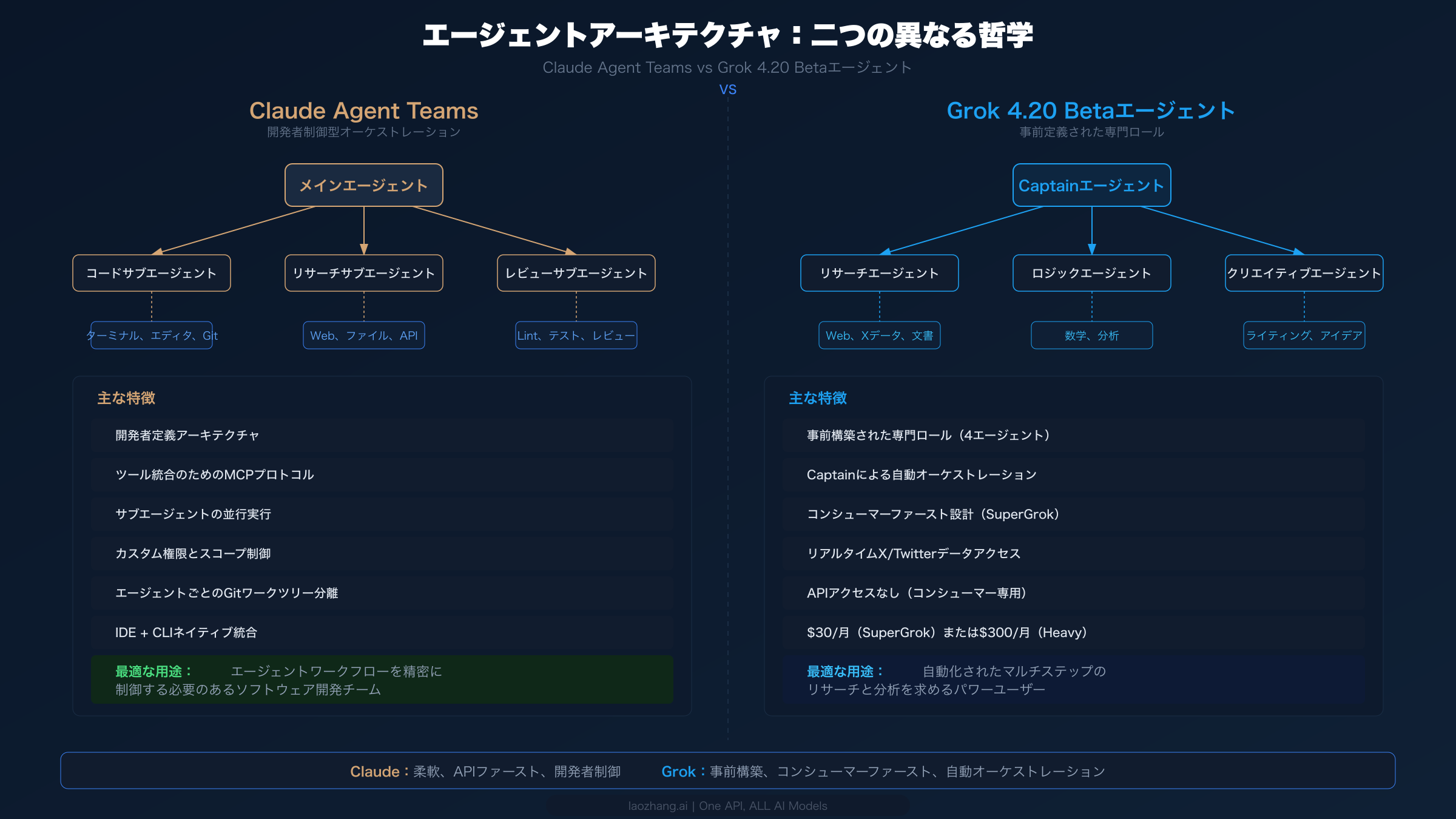
ClaudeとGrokの最も先進的な比較は、ベンチマークスコアや料金ではなく、各社がマルチエージェントAIシステムをどのように構想しているかにあります。AnthropicとxAIの両社は2026年初頭にマルチエージェント機能をリリースしましたが、そのアプローチは、オーケストレーションの制御者、エージェント間の通信方法、マルチエージェントシステムが解決すべき問題について根本的に異なる哲学を反映しています。これらのアーキテクチャの違いを理解することは、長期的にこれらのプラットフォーム上で構築を計画する方にとって非常に重要です。
Claude Agent Teams:開発者制御型オーケストレーション
Claude 4.6リリースの一部として登場したClaude Agent Teamsは、開発者ファーストの哲学に従っています。メインエージェント(または「リード」)は、特定の指示、ツール、権限スコープを持つサブエージェントを生成できます。開発者がアーキテクチャを定義します — どのエージェントが存在し、各エージェントがどのツールにアクセスでき、どのように連携するかです。システムは完全にAPIを通じて動作するため、オーケストレーションのあらゆる側面を完全にプログラム的に制御できます。サブエージェントは並行して実行でき、それぞれが分離されたgitワークツリーで動作して競合を防ぎ、メインエージェントが結果を統合します。Model Context Protocol(MCP)により、エージェントは標準化されたインターフェースを通じて外部ツール — データベース、API、ファイルシステム、IDE — と統合できます。この構成可能性は、開発者がユースケースに必要な正確なマルチエージェントワークフローを構築できることを意味します。シンプルな2エージェントのコード&レビューパイプラインから、大規模プロジェクトの異なる側面を処理する複雑な5エージェントシステムまで対応可能です。
トレードオフは複雑さです。効果的なAgent Teamsワークフローを構築するには、オーケストレーションパターンの理解、明確なエージェントスコープの定義、並行エージェント間のトークンバジェット管理、サブエージェントが矛盾する結果を生成した場合の障害モード処理が必要です。強力なツールですが、効果的に使用するには開発者の投資が求められます。その見返りは精度にあります。よく設計されたAgent Teamsワークフローは、各エージェントが適切なコンテキストとツールで特定の役割に最適化されるため、複雑なタスクで単一モデルのインタラクションを劇的に上回ることができます。
Grok 4.20 Betaエージェント:事前構築された専門ロール
Grokの4.20 Betaでのアプローチはコンシューマーファーストです。開発者にエージェントアーキテクチャの設計を要求する代わりに、xAIは4つの事前構築された専門エージェント — Captain、Research、Logic、Creative — を提供し、これらが複雑なタスクで自動的に連携します。Captainエージェントがオーケストレーターとして機能し、最も適した専門家にサブタスクをルーティングします。ユーザーはマルチエージェントアーキテクチャを理解する必要がなく、複雑なリクエストを送信するだけで、システムが内部で分解と連携を処理します。このアプローチはxAIのコンシューマー向けSuperGrokプラットフォームと整合しており、技術的な専門知識なしで高度なAI機能にアクセスできるようにすることが目標です。ResearchエージェントはX/Twitterデータへの直接アクセスを持ち、Claudeのエージェントがネイティブに持たないリアルタイム情報機能を提供します。Logicエージェントは数学的・分析的タスクを処理し、Grok 4の強力な数学性能を活用します。Creativeエージェントはコンテンツ生成とアイデア創出に焦点を当てています。
トレードオフは柔軟性です。参加するエージェントをカスタマイズしたり、新しい専門ロールを定義したり、オーケストレーションロジックを制御することはできません。汎用的な複雑タスクには適していますが、専門的なワークフローに開発者が必要とする精度には欠けています。そして決定的に重要なことに、まだAPIアクセスがありません。Grok 4.20 BetaエージェントはSuperGrokコンシューマーインターフェースを通じてのみ利用可能であり、本番アプリケーションでの有用性は限定的です。
どちらのアーキテクチャが勝つか
開発者やエンジニアリングチームにとって、2026年時点ではClaude Agent Teamsが明確な勝者です。APIを通じて利用可能で、完全なカスタマイズを提供し、MCPを通じて既存の開発ツールと統合できます。コードを書かずにマルチエージェント機能を必要とするパワーユーザーや研究者にとっては、Grok 4.20 Betaが柔軟性は劣るものの、アクセスしやすい代替手段を提供します。真の問題は、xAIがマルチエージェントシステムのAPIアクセスをリリースするかどうかであり、それが実現すればこの比較はより競争的になるでしょう。それまでは、プログラム的なマルチエージェントワークフローを必要とするチームには選択肢は一つだけ — Claudeです。
両社の軌跡を見ると、長期的な計画にとって重要なシグナルが明らかになります。Anthropicは体系的にClaudeの開発者エコシステムを拡張してきました — 最初のAPIから、Claude Code、Agent Teams、MCP統合へと、各層が前の層の上に構築されています。これは、エンジニアリングワークフロー内でClaudeをますますスティッキーにする開発者ツールへの継続的な投資を示唆しています。xAIの軌跡はよりコンシューマーに焦点を当てており、SuperGrokと4.20 Betaエージェントシステムがプログラマビリティよりもアクセシビリティを優先しています。どちらの軌跡も本質的に優れているわけではありませんが、異なるオーディエンスに対応しています。AIエージェント機能に依存する製品を構築しているなら、Claudeの開発者ファーストアプローチがより安定性と構成可能性を提供します。コンシューマー向けのAI体験を創出しているなら、Grokの事前構築エージェントシステムがカスタムエンジニアリングなしでより速いtime-to-valueを提供します。
どのモデルを選ぶべきか
Claude Opus 4.6とGrok 4の正しい選択は、どちらのモデルが絶対的に「優れている」かということよりも、特定のユースケース、予算、技術要件に最も適しているかによって決まります。ベンチマーク、料金、コーディング能力、アーキテクチャにわたる包括的な分析に基づき、自信を持って判断するための6つのシナリオ別推奨事項を以下に示します。
シナリオ1:ソフトウェア開発チーム(5-20名の開発者)。Claude Opus 4.6を選択してください。優れたSWE-benchパフォーマンス(81.4%)、エージェント型コーディングのためのClaude Code、並行ワークフローのためのAgent Teams、強力なIDE統合の組み合わせが、プロフェッショナルなソフトウェア開発に特化したエコシステムを創出しています。高いAPIコスト($5/$25 vs $3/$15)は生産性向上で相殺されます。Grokが見逃すバグを1日に1つ多く解決するだけで、コスト差は容易にカバーされます。予算のヒント:ルーティンタスクにはClaude Sonnet 4.6($3/$15)を使用し、複雑な推論にはOpusを確保しましょう。
**シナリオ2:予算を意識するスタートアップやソロ開発者。**Grok 4 Fast($0.20/$0.50)を選択してください。Claude Opus 4.6の25分の1の価格で、フロンティアに近い能力を提供します。200万トークンのコンテキストウィンドウは大規模コードベース処理のボーナスです。最大能力が必要なタスクの10-20%については、すべてのリクエストにプレミアムティアを支払うよりも、Claude Opus 4.6や標準Grok 4をスポット利用することを検討してください。
**シナリオ3:データサイエンスと数学的分析。**Grok 4を選択してください。92.7%の数学指標と87.5%のGPQAスコアは、数学的推論と科学的知識タスクでの強力なパフォーマンスを示しています。常時オンの推論モードはレイテンシーを追加しますが、すべてのリクエストに対して深い分析的厳密さを保証します。統計分析、モデル訓練、科学的計算を大量に行うチームにとって、Grokの数学的優位性は具体的な品質向上に変換されます。
**シナリオ4:マルチエージェントワークフローが必要な企業。**Claude Opus 4.6とAgent Teamsを選択してください。2026年3月時点で、APIからアクセス可能なマルチエージェントオーケストレーションを持つのはClaudeが唯一の選択肢です。企業のロードマップに自律ワークフロー、自動コードレビューパイプライン、複雑なマルチステップ分析システムの構築が含まれているなら、Claude Agent Teamsが必要なプログラム可能な基盤を提供します。Grok 4.20 Betaのマルチエージェントシステムはコンシューマー専用のままです。
**シナリオ5:リアルタイムアプリケーションとチャットボット。**Claude Opus 4.6を選択してください。2倍の速度優位(約80トークン/秒 vs 40.6トークン/秒)と劇的に高速なTTFT(約1.5秒 vs 10.79秒)により、レスポンスのレイテンシーが重要なアプリケーションではClaudeが唯一の現実的な選択肢です。最初のトークンまで10秒の待機は、ほとんどのインタラクティブなユースケースでは受け入れられません。
**シナリオ6:厳しい予算での大量処理。**Grok 4 Fastを主要モデルとする混合アプローチを選択してください。リクエストの80%をGrok 4 Fast($0.20/$0.50)で処理し、複雑なタスクは標準Grok 4($3/$15)にエスカレーションし、最大のコーディングまたは推論能力が必要なタスクにのみClaude Opus 4.6を使用します。このティアードアプローチにより、最も重要なタスクの高品質を維持しながら、全てClaude Opusを使用する場合と比べてコストを85-95%削減できます。
6つすべてのシナリオに共通するのは、最善の戦略は「すべてに1つのモデルを使う」ことではないということです。2026年のフロンティアAI環境は、インテリジェントなルーティング — モデルの能力とコストを特定のタスク要件に合わせること — に報います。単一の製品内でも、ユーザー向けのコーディング支援にはClaudeを、バックグラウンドのドキュメント処理やデータ抽出にはGrok 4 Fastを使うかもしれません。単一のAIプロバイダーに独占的にコミットする時代は終わりました。各タスクに適したモデルを活用するチームが競争優位を得ます。このマルチモデル戦略の実装には、モデルルーティングロジックと複数のAPI関係管理のための追加エンジニアリング作業が必要ですが、1日に数百回以上のAPI呼び出しを行うチームにとっては、コスト削減と品質向上がその投資を正当化します。
導入と最適化
ClaudeとGrokの両方が簡単なAPIアクセスを提供していますが、コストとパフォーマンスの実装最適化には各プラットフォームの特定機能の理解が必要です。以下では、どちらのモデルでも始める方法とAPI予算から最大限の価値を引き出す実用的なガイドを提供します。
Claude Opus 4.6の使い始め方では、console.anthropic.comからAnthropic APIキーが必要です。APIは標準的なRESTパターンに従い、PythonとTypeScriptのSDKが利用可能です。セットアッププロセスは簡単です。アカウントを作成し、APIキーを生成し、数分以内に最初のリクエストを行えます。深い推論が必要なタスクにのみ拡張思考を有効にしましょう。デフォルトで有効にすると、シンプルなタスクでは品質向上に比例しないコスト増加が生じます。繰り返し呼び出しの入力トークンコストを削減するために、システムプロンプトにcache_controlブロックを含めてプロンプトキャッシングを使用しましょう。コーディングワークフローについては、Claude Code(npm install -g @anthropic-ai/claude-code)をインストールして、カスタムAPI統合を書かずにフルエージェント開発体験を得ることができます。Claude Codeはコマンドラインから直接ターミナルアクセス、ファイル編集、git操作、マルチエージェントオーケストレーションをサポートしており、「APIキーを持っている」から「AI搭載の開発ワークフローがある」への最速の道筋です。
Grok 4の使い始め方では、console.x.aiからxAI APIキーが必要です。APIはOpenAI互換であるため、既にOpenAI SDKフォーマットを使用しているチームにとって移行は簡単です。Grok 4のキャッシュ入力料金(標準の$3.00/100万に対して$0.75/100万)を積極的に活用しましょう。呼び出し間で再利用されるシステムプロンプトや参照ドキュメントはすべてキャッシュすべきです。予算に敏感なアプリケーションではGrok 4 Fastから始め、タスクの複雑さが要求する場合にのみ標準Grok 4にエスカレーションしましょう。Fastバリアントの200万トークンコンテキストウィンドウは、ドキュメント処理タスクにフルGrok 4が必要になることはめったにないことを意味します。
コスト最適化戦略として、両モデルに共通して有効なものには、モデルティアを選択する前にタスクの複雑さを分析するインテリジェントルーティングの実装、キャッシュ利用率を最大化するための類似リクエストのバッチ処理、過剰な出力を生成するタスクのランナウェイコストを防ぐためのリクエストあたりのトークンバジェット上限の設定があります。よく設計されたルーティングシステムは、軽量な分類器(またはルールベースのヒューリスティック)を使用して、各受信リクエストにフロンティアレベルの能力が必要か、バジェットモデルで十分かを判断します。この単一の最適化で、ほとんどのアプリケーションの総API支出を50-70%削減できます。
GPT-4oやGeminiなど他のフロンティアモデルとの比較も含むより広い視点については、AI API比較ガイドをご覧ください。2026年のAIモデル環境は柔軟性に報います。最高のパフォーマンスを発揮するチームは、単一プロバイダーに独占的にコミットするのではなく、タスクにモデルをマッチさせるチームです。Claude Opus 4.6もGrok 4もどちらも優れたモデルであり、ほとんどの組織にとって理想的な戦略は、各モデルが優れている領域で両方を活用することです。
よくある質問
Claude Opus 4.6はGrok 4より優れていますか?
Claude Opus 4.6は、コーディングベンチマーク(SWE-bench 81.4% vs 約72%)、推論タスク(ARC-AGI-2 68.8% vs 15.9%)、レスポンス速度(約80 vs 40.6トークン/秒)でGrok 4を上回っています。しかし、Grok 4は数学的推論(数学指標92.7%)と知識タスク(GPQA 87.5%)でリードしており、コストは40%低くなっています。どちらのモデルも普遍的に「優れている」わけではなく、主なユースケースがコーディング/推論(Claude)か数学/知識を低コストで(Grok)かによって正しい選択は異なります。
Grok 4はClaude Opus 4.6よりどのくらい安いですか?
Grok 4のAPI料金は100万トークンあたり$3/$15で、Claudeの$5/$25と比較すると入力・出力ともに40%安価です。バジェット版のGrok 4 Fastバリアントは100万トークンあたり$0.20/$0.50で、Claude Opus 4.6の25分の1の価格であり、利用可能なフロンティアに近いモデルの中で最も手頃な選択肢の一つです。Grokはキャッシュ入力料金として100万トークンあたり$0.75も提供しています。
ClaudeとGrokを同じAPIで使用できますか?
はい。
Grok 4.20 Betaとは何で、Claude Agent Teamsとどう違いますか?
Grok 4.20 Betaは、SuperGrok(月額$30)を通じて利用可能な4つの専門エージェント(Captain、Research、Logic、Creative)を備えたxAIのコンシューマー向けマルチエージェントシステムです。Claude Agent Teamsは、APIを通じて利用可能なAnthropicの開発者向けマルチエージェントフレームワークです。主な違いは、Claudeのシステムが完全なプログラム制御とカスタマイズを提供するのに対し、Grokのシステムは事前構築されたコンシューマー専用でまだAPIアクセスがないことです。
本番アプリケーションにはどちらのモデルが速いですか?
Claude Opus 4.6が大幅に高速です。毎秒約80トークン対Grok 4の40.6トークンで、最初のトークンまでの時間は約1.5秒対Grok 4の10.79秒です。インタラクティブなアプリケーションやチャットボットでは、Claudeの速度優位は決定的です。Grok 4のレイテンシーが高いのは常時オンの推論モードによるもので、複雑さに関わらずすべてのリクエストが深い推論を通じて処理されます。