Claude Opus 4.6 launched on February 5, 2026, delivering Anthropic's most capable model with a 1M-token context window and 128K output support — all at the same $5/$25 per million token price as its predecessor. But that headline number only tells part of the story. Fast mode charges six times more, long context requests double the input price, and US-only data residency adds a 10% surcharge on top of everything else. Whether you are deciding between the API and a Claude Pro subscription, scaling a production application, or comparing Claude against GPT-5 and Gemini 2.5 Pro, this guide gives you every number you need and five concrete strategies to keep your spending under control.
TL;DR
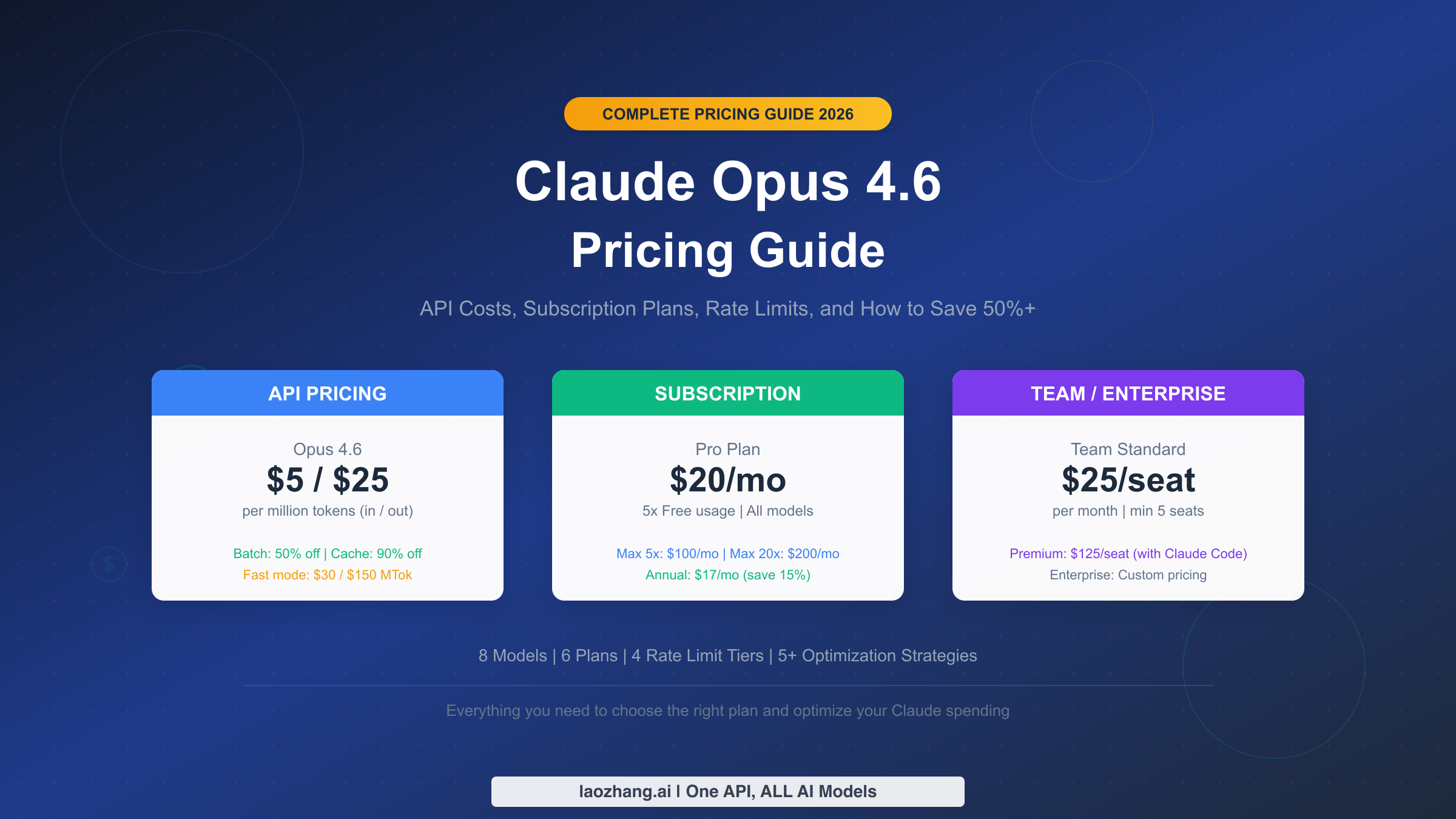
Opus 4.6 standard API pricing is $5 input / $25 output per million tokens (Anthropic official pricing, February 2026). Subscription plans range from Free ($0) through Max 20x ($200/month). Key savings: Batch API cuts 50%, prompt caching saves up to 90% on cached reads, and smart model mixing across Haiku-Sonnet-Opus can reduce average costs by 60-80%. Full rate limits, hidden costs, and a plan-selection decision tree are covered below.
Claude Opus 4.6 API Pricing: Every Model at a Glance
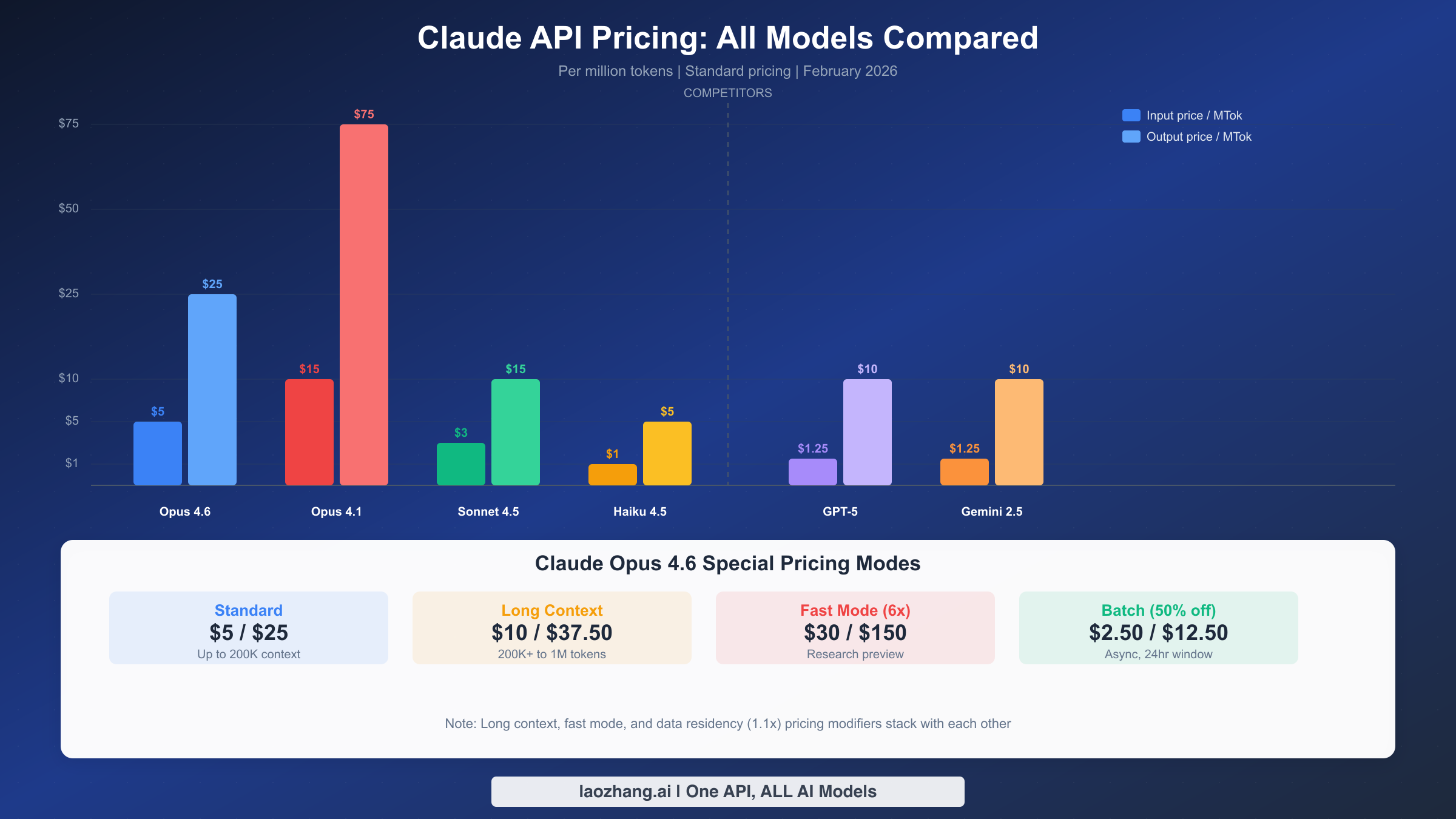
Anthropic's model lineup spans three tiers designed for different cost-performance trade-offs. Understanding where Opus 4.6 fits in the broader family is the first step toward making a smart purchasing decision. The table below reflects pricing pulled directly from Anthropic's official pricing page as of February 2026.
| Model | Input (per MTok) | Output (per MTok) | Context Window | Best For |
|---|---|---|---|---|
| Claude Opus 4.6 | $5.00 | $25.00 | 200K (1M beta) | Complex reasoning, coding, research |
| Claude Opus 4.5 | $5.00 | $25.00 | 200K (1M beta) | Same pricing, previous generation |
| Claude Opus 4.1 | $15.00 | $75.00 | 200K | Legacy, 3x more expensive |
| Claude Sonnet 4.5 | $3.00 | $15.00 | 200K (1M beta) | Balanced speed and quality |
| Claude Sonnet 4 | $3.00 | $15.00 | 200K (1M beta) | Previous gen Sonnet |
| Claude Haiku 4.5 | $1.00 | $5.00 | 200K | Fast tasks, classification, extraction |
| Claude Haiku 3.5 | $0.80 | $4.00 | 200K | Budget option |
The pricing story that matters here is the generational leap. Opus 4.1 and Opus 4 cost $15/$75 per million tokens — three times more than Opus 4.6. Anthropic effectively delivered a major performance upgrade while cutting the Opus-tier price by 67%. If you are still running on Opus 4.1, switching to Opus 4.6 saves you money immediately while getting better results. For a detailed comparison of Claude Opus and Sonnet models, including benchmark scores and use-case recommendations, see our dedicated comparison guide.
Prompt caching multipliers apply across all models using the same ratios. A five-minute cache write costs 1.25x the base input price, a one-hour cache write costs 2x, and cache reads cost just 0.1x. For Opus 4.6, that means cached reads drop from $5.00 to $0.50 per million tokens — a detail that becomes critical when you process the same documents or system prompts repeatedly.
Subscription Plans Compared: Free vs Pro vs Max vs Team
Anthropic offers six distinct subscription tiers for users who prefer a fixed monthly cost over pay-per-token API billing. Each tier unlocks progressively more usage, model access, and collaboration features. Here is the complete breakdown based on claude.com/pricing.
| Feature | Free | Pro | Max 5x | Max 20x | Team Standard | Team Premium |
|---|---|---|---|---|---|---|
| Price | $0 | $20/mo ($17 annual) | $100/mo | $200/mo | $25/seat/mo ($20 annual) | $125/seat/mo ($100 annual) |
| Usage | 30-100 msgs/day | ~5x Free | ~25x Free | ~100x Free | ~1.25x Pro | ~6.25x Pro |
| Models | Sonnet, Haiku | All (incl. Opus) | All | All | All | All |
| Claude Code | No | Web + CLI | Full | Full | No | Full |
| Extended Thinking | No | Yes | Yes | Yes | Yes | Yes |
| Priority Access | No | Peak-time priority | Maximum priority | Zero-latency guarantee | Standard | Priority |
| Min Seats | - | - | - | - | 5 | 5 |
| SSO/Admin | No | No | No | No | Yes | Yes |
The Free plan works for casual exploration but its 30-100 message daily cap and lack of Opus access make it impractical for professional use. Messages reset on a rolling basis (roughly every 4-8 hours depending on load), and heavy conversations with large attachments can eat through your quota in a single session. You also cannot access Claude Code or extended thinking on the Free tier, which limits its utility for development workflows.
Pro at $20 per month is the sweet spot for individual professionals. You get access to every Claude model including Opus 4.6, Claude Code in both web and terminal modes, extended thinking for complex problems, and roughly five times the Free tier's message allowance. The annual billing option at $17/month saves 15%, which adds up to $36/year — worth it if you plan to use Claude for more than a few months. Anthropic does not publish exact message limits for Pro, instead using dynamic caps that adjust based on server load and conversation complexity.
Max plans exist for power users who consistently hit Pro limits. Max 5x at $100/month gives you approximately 25 times the Free tier's capacity, which translates to roughly 2,000-2,500 messages per day under normal conditions. Max 20x at $200/month pushes that to around 8,000-10,000 messages daily, which is nearly impossible for a single user to exhaust. Both Max tiers include early access to new features and the highest priority during traffic spikes. If you are running automated workflows through Claude or coding for 8+ hours daily, Max makes sense. Otherwise, Pro handles most professional workloads comfortably.
Team plans add collaboration and administration features on top of individual usage. The Standard seat at $25/month provides roughly 1.25 times Pro-level usage plus SSO, centralized billing, admin dashboards, and domain capture. The Premium seat at $125/month upgrades usage to 6.25 times Pro and includes full Claude Code access with terminal integration — essentially combining Max-level individual usage with Team-level governance. Teams require a minimum of five seats. Enterprise plans negotiate custom pricing, usage levels, HIPAA-ready configuration, audit logging, SCIM provisioning, and compliance APIs directly with Anthropic's sales team.
The Hidden Costs Most Guides Skip
The $5/$25 per million token headline price for Opus 4.6 applies only to standard requests within a 200K-token context window. Several pricing modifiers can increase your actual costs significantly, and they stack with each other. Understanding these multipliers before you commit to a workload prevents budget surprises.
Fast mode charges a 6x premium. Opus 4.6 offers a research-preview fast mode that prioritizes output speed at $30 input / $150 output per million tokens. For requests exceeding 200K input tokens in fast mode, the price jumps further to $60/$225 per million tokens. Fast mode is useful for latency-sensitive applications like real-time coding assistants or interactive agents, but using it for batch workloads where speed does not matter is an expensive mistake. Fast mode is not available through the Batch API, so you cannot combine it with the 50% batch discount.
Long context pricing doubles the input cost. When you enable the 1M-token context window beta and send a request with more than 200K input tokens, all tokens in that request — not just the ones above 200K — are charged at premium rates: $10 input / $37.50 output per million tokens. The 200K threshold counts only input tokens (including cached reads and writes); output token volume does not affect which pricing tier applies. This long context pricing is currently available only to Tier 4 organizations and those with custom rate limits.
US-only data residency adds a 10% surcharge. Starting with Opus 4.6, specifying inference_geo: "us" to guarantee US-only processing incurs a 1.1x multiplier on all token categories. This applies to input tokens, output tokens, cache writes, and cache reads. If you do not need guaranteed US-only inference, using the default global routing avoids this charge entirely. Earlier models are not affected by this multiplier regardless of the inference_geo setting.
Tool usage adds hidden tokens. Every API request that includes tools adds a system prompt overhead. For all Claude 4.x models, the tool use system prompt consumes 346 tokens (auto/none) or 313 tokens (any/tool), plus the tokens for your tool definitions, tool_use blocks, and tool_result blocks. Web search costs an additional $10 per 1,000 searches on top of standard token costs. Code execution charges $0.05 per hour after 1,550 free hours per month per organization. These tool costs are easy to overlook when estimating monthly budgets.
The worst-case stacking scenario illustrates why understanding modifiers matters. Consider a fast-mode Opus 4.6 request with US-only inference that exceeds 200K input tokens. The input price becomes: base $5 x 6 (fast) x 2 (long context) x 1.1 (US) = $66 per million input tokens. The output price: $25 x 6 x 1.5 x 1.1 = $247.50 per million output tokens. That is 13x and 10x the standard price respectively. Knowing which modifiers apply to your workload is essential for accurate cost forecasting.
Real-World Monthly Cost Estimates
Abstract per-token pricing becomes meaningful only when you translate it into monthly bills for real usage patterns. The following estimates use Opus 4.6 standard pricing ($5/$25 per million tokens) and assume a mix of input and output tokens typical for each use case.
Light usage (individual developer, chatbot prototyping): Around 500K input tokens and 100K output tokens per day. Monthly cost: approximately $75 for input ($5 x 0.5 x 30) plus $75 for output ($25 x 0.1 x 30) = $150/month on Opus 4.6 standard API. At this volume, the Pro subscription at $20/month is overwhelmingly more economical — you would need to generate roughly 133K input tokens plus 44K output tokens daily before the API becomes cheaper than Pro. For most individual users doing conversational or coding tasks, the subscription wins.
Medium usage (small team, production chatbot, content pipeline): Around 5M input tokens and 1M output tokens per day. Monthly cost: $750 input + $750 output = $1,500/month on Opus 4.6. With smart model mixing — routing 70% of requests to Haiku ($1/$5), 20% to Sonnet ($3/$15), and only 10% to Opus ($5/$25) — the blended cost drops to approximately $450/month. Adding prompt caching for repeated system prompts cuts that further. At this scale, API pricing clearly beats subscriptions, and optimization strategies become worth the engineering investment.
Heavy usage (enterprise application, large-scale data processing): Around 50M input tokens and 10M output tokens per day. Monthly cost before optimization: $7,500 input + $7,500 output = $15,000/month on Opus 4.6 alone. Enterprises at this scale should combine all available discounts: Batch API (50% off for non-urgent tasks), prompt caching (90% savings on cached reads), model mixing (60-80% savings on average cost per request), and volume-based enterprise negotiations. With aggressive optimization, teams commonly reduce the $15,000 baseline to $2,000-$4,000/month.
The API-vs-subscription breakeven depends entirely on your usage pattern. For text-based conversation at roughly Sonnet quality, the Pro subscription breaks even against the Sonnet 4.5 API at about 222K input tokens plus 44K output tokens per day. Below that threshold, pay $20/month for Pro. Above it, switch to API billing with optimization. For Opus-level reasoning, the breakeven is even lower since Opus costs more per token, making the subscription relatively more valuable for moderate users.
Rate Limits and Usage Tiers: The Complete Reference
Anthropic enforces rate limits across four tiers that scale automatically as you spend more. Understanding these limits is critical for production applications — hitting a 429 rate limit error during peak traffic can disrupt your service. The following tables present the complete rate limit data from Anthropic's official documentation.
| Tier | Deposit Required | Max Monthly Spend | Opus 4.x RPM | Opus 4.x ITPM | Opus 4.x OTPM |
|---|---|---|---|---|---|
| Tier 1 | $5 | $100 | 50 | 30,000 | 8,000 |
| Tier 2 | $40 | $500 | 1,000 | 450,000 | 90,000 |
| Tier 3 | $200 | $1,000 | 2,000 | 800,000 | 160,000 |
| Tier 4 | $400 | $5,000 | 4,000 | 2,000,000 | 400,000 |
Tier advancement is automatic and immediate once you hit the cumulative credit purchase threshold. You do not need to contact Anthropic or wait for approval. However, you cannot deposit more than the Max Credit Purchase for your current tier in a single transaction (Tier 1: $100, Tier 2: $500, Tier 3: $1,000, Tier 4: $5,000), which prevents accidental overfunding.
Opus rate limits are shared across all Opus models. Traffic to Opus 4.6, 4.5, 4.1, and 4 draws from the same RPM/ITPM/OTPM pool. Similarly, Sonnet 4.x limits are shared across Sonnet 4.5 and Sonnet 4. However, Opus and Sonnet limits are separate — you can simultaneously use both model families up to their respective limits. Haiku 4.5 at Tier 4 provides the highest throughput: 4,000 RPM, 4,000,000 ITPM, and 800,000 OTPM.
Prompt caching dramatically increases your effective throughput. Anthropic's rate limits only count uncached input tokens (input_tokens + cache_creation_input_tokens) toward your ITPM limit. Cached reads do not count. With an 80% cache hit rate and a 2,000,000 ITPM limit at Tier 4, your effective throughput becomes 10,000,000 total input tokens per minute — five times the nominal limit. This makes prompt caching not just a cost optimization but a throughput multiplier, which is essential for high-traffic production applications.
The 1M context window requires Tier 4 and comes with dedicated long context rate limits: 1,000,000 ITPM and 200,000 OTPM, separate from standard limits. Fast mode also has its own dedicated rate limit pool, separate from standard Opus limits. These separation decisions mean that using fast mode or long context does not consume your standard rate limit budget, which helps in architectures that mix standard and specialized requests.
How to Choose the Right Claude Plan
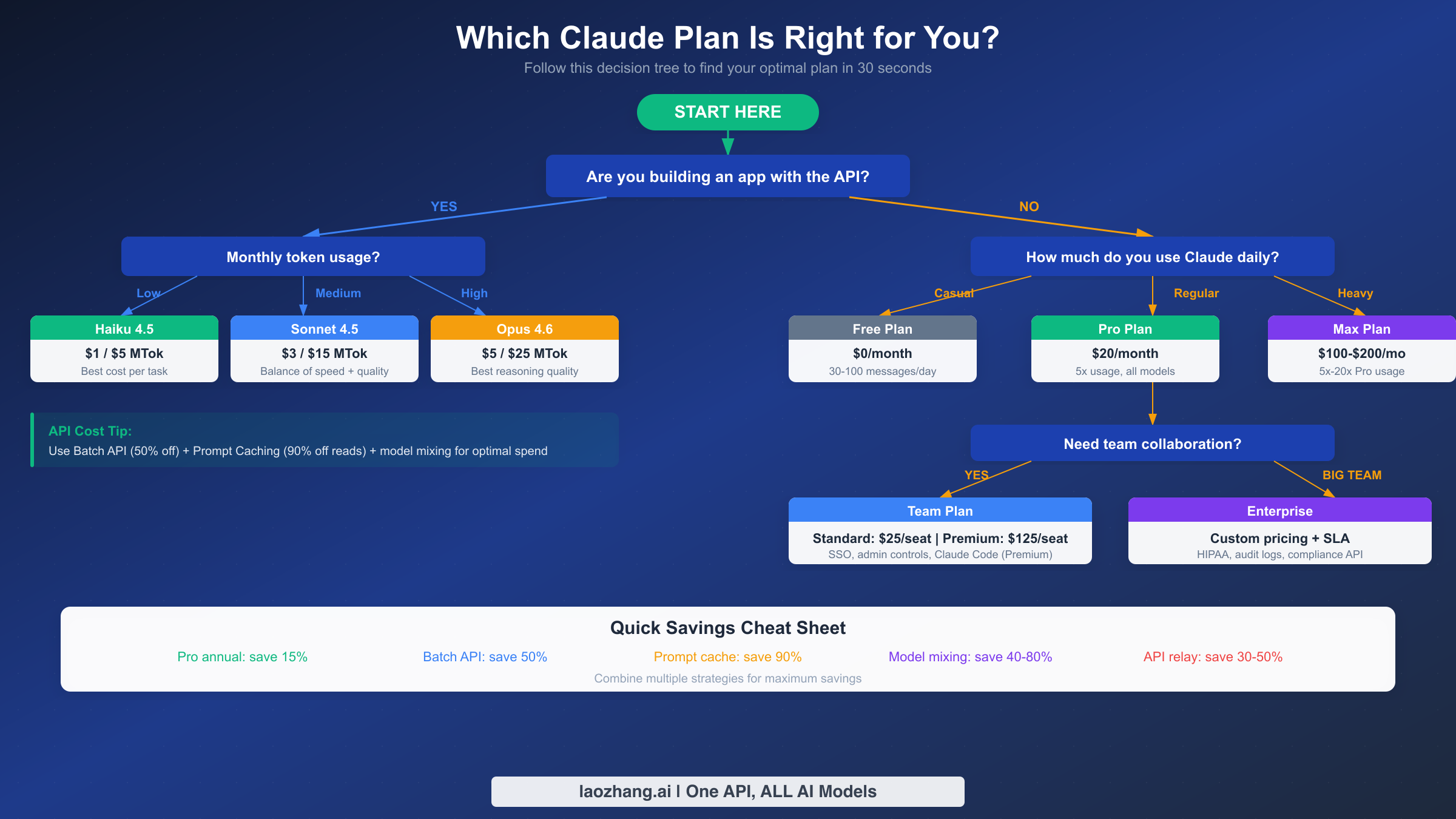
Selecting the right plan comes down to three questions: Are you building an application with the API or using Claude interactively? How much do you use it daily? And do you need team collaboration features? The decision tree above maps these questions to specific recommendations, but here is the reasoning behind each path.
For individual interactive use, start with Pro and upgrade only if you consistently hit limits. The $20/month Pro plan covers the vast majority of professional use cases — writing, coding, analysis, research — without worrying about per-token costs. If you find yourself hitting usage caps more than twice per week, Max 5x at $100/month eliminates that friction. Max 20x at $200/month is realistically only necessary if you run automated workflows through the Claude interface or code for 10+ hours daily with heavy Opus usage. The annual billing discount (15% for Pro, available for Team plans as well) is straightforward to calculate: if you plan to use Claude for three or more months, annual billing saves money.
For API-based applications, model selection matters more than plan selection. The API does not require a subscription — you fund your account directly starting at $5 for Tier 1. The key decision is which model to default to. Haiku 4.5 at $1/$5 per million tokens handles classification, extraction, and simple generation tasks at one-fifth the cost of Opus. Sonnet 4.5 at $3/$15 provides strong reasoning and coding ability for most production use cases. Reserve Opus 4.6 at $5/$25 for tasks where its superior reasoning truly matters: complex code generation, multi-step research, and agent orchestration. Building a routing layer that sends requests to the right model based on task complexity is the single highest-impact cost optimization for API users.
For teams, the Standard vs Premium decision hinges on Claude Code. If your developers need terminal-based Claude Code access (for coding, debugging, and repository-wide analysis), Team Premium at $125/seat/month is the only team tier that includes it. If your team primarily uses Claude through the web interface for content, analysis, and communication tasks, Team Standard at $25/seat saves $100/seat/month. The 5-seat minimum means your minimum Team commitment is $125/month for Standard or $625/month for Premium.
Five Proven Ways to Cut Your Claude Costs in Half

Reducing your Claude spending is not about using it less — it is about using it smarter. The five strategies below can be applied individually or combined for maximum impact. Each includes the specific savings percentage and the use cases where it delivers the most value.
Strategy 1: Prompt caching saves up to 90% on repeated context. Every time you send the same system prompt, tool definitions, or reference documents, you pay full input price. Enabling prompt caching lets subsequent requests read that cached content at just 10% of the base rate — $0.50 instead of $5.00 per million tokens for Opus 4.6. The initial cache write costs 1.25x for a 5-minute TTL or 2x for a 1-hour TTL, but the savings compound rapidly with volume. A customer support application processing 10,000 requests per day with a shared 2,000-token system prompt saves roughly $2.70/day on system prompt tokens alone — $81/month from a single optimization. Prompt caching also does not count toward your ITPM rate limit, effectively increasing your throughput for free.
Strategy 2: Batch processing provides a flat 50% discount. The Batch API processes requests asynchronously within a 24-hour window at half the standard price. Opus 4.6 batch pricing drops to $2.50/$12.50 per million tokens. This is ideal for content generation, data extraction, classification pipelines, document summarization, and any workload that does not require real-time responses. The batch discount stacks with long context pricing and data residency multipliers, so even premium requests benefit. You cannot combine batch processing with fast mode, but since these serve opposite use cases (latency-tolerant vs. latency-sensitive), this is rarely a limitation.
Strategy 3: Smart model mixing reduces average costs by 60-80%. Not every request needs your most capable model. Building a routing layer that dispatches requests to Haiku, Sonnet, or Opus based on task complexity is the most impactful optimization for multi-request applications. A typical enterprise pattern: route 70% of traffic (simple lookups, classification, extraction) to Haiku 4.5 at $1/$5, send 20% (drafting, moderate analysis) to Sonnet 4.5 at $3/$15, and reserve 10% (complex reasoning, code generation) for Opus 4.6 at $5/$25. The blended average becomes roughly $1.60/$7.50 per million tokens — a 68% reduction from all-Opus pricing. The routing logic can be as simple as keyword-based rules or as sophisticated as a lightweight classifier that scores task complexity.
Strategy 4: Token optimization cuts consumption by 20-40%. Beyond model-level pricing, the raw number of tokens per request affects your bill. Write concise system prompts that avoid repetitive instructions. Set max_tokens to realistic values rather than maximums, because OTPM rate limits estimate based on this parameter. Use the effort parameter (available on Opus 4.6: low, medium, high, max) to control how much internal reasoning the model performs — lower effort means fewer thinking tokens and faster responses for straightforward tasks. Truncate conversation history to include only recent relevant turns rather than the full thread.
The relay handles authentication, load balancing, and failover, eliminating the need to manage separate API keys and billing accounts across providers.
Combining these strategies yields dramatic results. Consider a workload spending $2,500/month on 10M tokens of all-Opus standard pricing. Applying model mixing (70/20/10 Haiku/Sonnet/Opus) reduces that to approximately $1,000. Adding batch processing for non-urgent tasks (assume 50% of volume) brings it to $500. Layering prompt caching on remaining real-time requests drives the total toward $250/month — a 90% reduction from the starting point. Even partial adoption of two or three strategies typically achieves 50-70% savings.
Claude Opus 4.6 vs GPT-5 vs Gemini 2.5 Pro: Price-Performance Showdown
Choosing between the three leading AI models requires comparing not just sticker prices but what you get per dollar. The table below uses pricing data from Anthropic, OpenAI, and Google as of February 2026.
| Dimension | Claude Opus 4.6 | GPT-5 | Gemini 2.5 Pro |
|---|---|---|---|
| Input price | $5.00/MTok | $1.25/MTok | $1.25/MTok |
| Output price | $25.00/MTok | $10.00/MTok | $10.00/MTok |
| Context window | 200K (1M beta) | 400K | 1M (2M beta) |
| Max output | 128K tokens | 64K tokens | 64K tokens |
| Batch discount | 50% | 50% | 50% |
| Free tier | Limited (API credits) | Limited | Yes (with rate limits) |
| Coding benchmarks | Highest (Terminal-Bench 2.0) | Strong | Strong |
| Reasoning | Highest (GDPval-AA, HLE) | Near-par | Good |
On raw per-token cost, Opus 4.6 is 4x more expensive. GPT-5 and Gemini 2.5 Pro both price at $1.25/$10 per million tokens, making them significantly cheaper per token than Opus 4.6's $5/$25. For workloads where model quality differences are marginal — simple classification, basic extraction, templated generation — GPT-5 or Gemini offer better cost efficiency.
On cost-per-quality-unit, the gap narrows significantly. Opus 4.6 outperforms GPT-5 by approximately 144 Elo points on GDPval-AA benchmarks and achieves the highest scores on Terminal-Bench 2.0 and Humanity's Last Exam. For complex coding tasks, multi-step research, and agent orchestration, Opus 4.6 often completes tasks in fewer iterations — meaning fewer total tokens consumed despite the higher per-token price. A task that takes Opus one pass might take a cheaper model three attempts, reversing the cost advantage.
Context window and output length are differentiators. Opus 4.6's 128K output token support is double what GPT-5 and Gemini currently offer, making it the clear choice for long-form generation tasks. Gemini 2.5 Pro leads on raw context window size with a 2M beta option. GPT-5's 400K context window sits between the two. If your workload involves processing very long documents, Gemini's free tier with generous context may be the most cost-effective starting point.
The practical recommendation is not to pick one model. Use a migration-ready architecture that can route between providers based on task requirements. Send complex reasoning to Opus, high-volume simple tasks to GPT-5 or Gemini (both at $1.25/$10), and latency-sensitive requests to whichever model responds fastest. This multi-provider approach — easily implemented through relay services with unified API endpoints — gives you the best of all three ecosystems while keeping costs optimized across the board.
Making the Most of Your Claude Investment
The Claude pricing landscape in 2026 offers more options than ever, which is both an opportunity and a challenge. The core decision framework is straightforward. Individual users who interact with Claude conversationally should start with the Pro subscription at $20/month and only upgrade to Max if they consistently hit limits. API developers should choose their default model tier carefully — Haiku for simple tasks, Sonnet for balanced workloads, Opus for complex reasoning — and invest in prompt caching and batch processing before spending on higher rate limit tiers. Teams should evaluate whether Claude Code access justifies the Premium seat upgrade over Standard.
The hidden costs section of this guide is worth revisiting before any major deployment. Fast mode at 6x standard pricing, long context at 2x input cost, and data residency at 1.1x are all multipliers that stack. A single request can cost 13x the headline price under worst-case conditions. Building cost monitoring into your application from day one — using the usage object in API responses and the /cost command in Claude Code — prevents surprises before they hit your invoice.
Finally, remember that Claude pricing is competitive within context. Opus 4.6 costs more per token than GPT-5 or Gemini 2.5 Pro, but its benchmark-leading reasoning capabilities mean you often need fewer tokens to accomplish the same task. The most cost-effective approach is rarely "use the cheapest model for everything" — it is to match model capability to task complexity while applying the optimization strategies outlined above. With prompt caching, batch processing, model mixing, and smart token management, teams routinely achieve 50-90% savings against naive all-Opus pricing without sacrificing output quality.