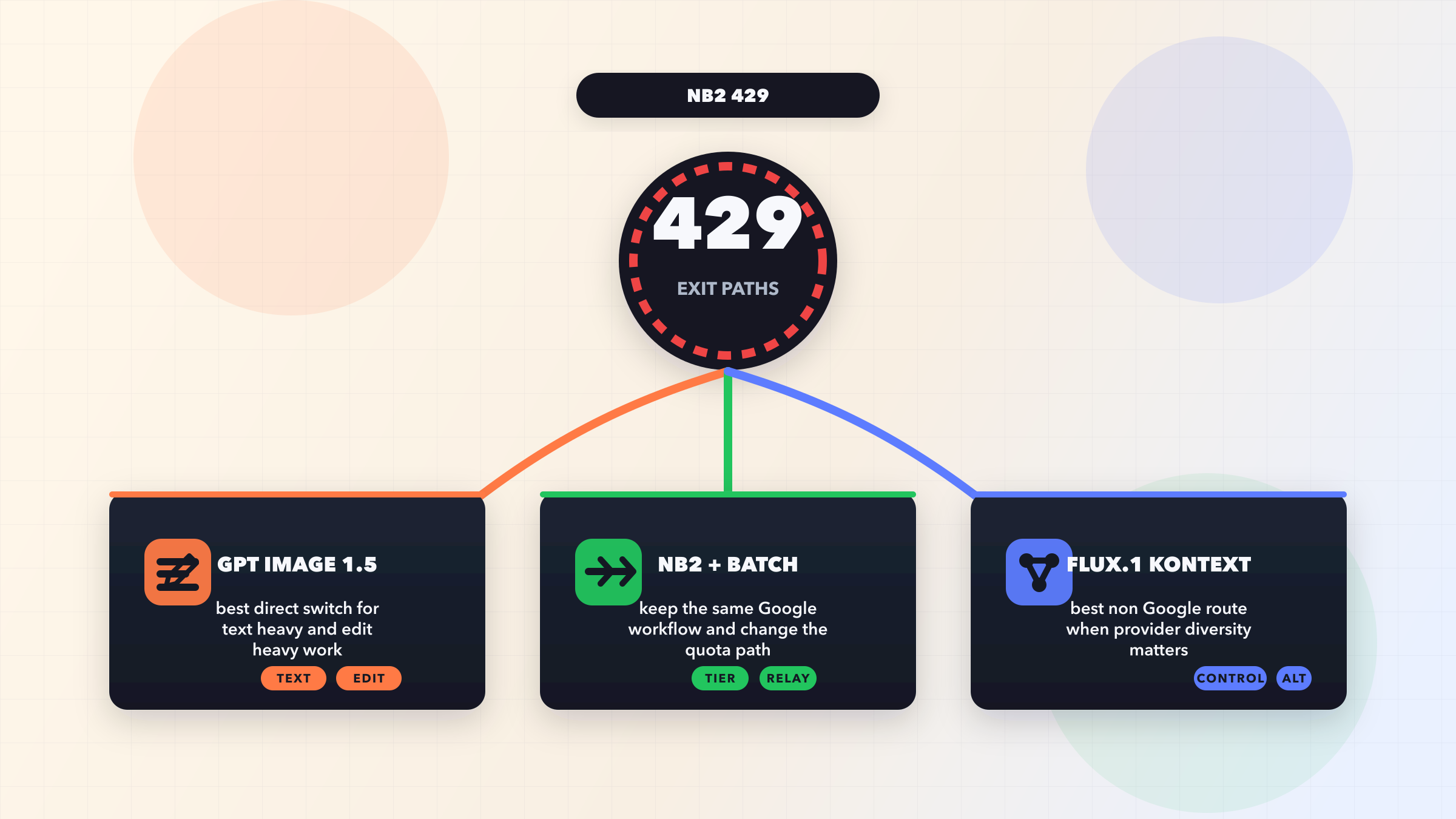
Los errores 429 en la generacion de imagenes con Gemini ocurren cuando tu aplicacion excede una de las cuatro dimensiones de limite de solicitudes de Google: Solicitudes Por Minuto (RPM), Solicitudes Por Dia (RPD), Tokens Por Minuto (TPM) o las frecuentemente ignoradas Imagenes Por Minuto (IPM). La solucion mas rapida es implementar backoff exponencial con jitter, que transforma una tasa de fallo del 80% en mas del 99% de exito para trafico en rafagas. Sin embargo, si estas en el nivel gratuito, primero debes activar la facturacion porque el IPM del nivel gratuito bajo a 0 en diciembre de 2025, lo que significa que la generacion de imagenes esta efectivamente deshabilitada sin una cuenta de pago. El Tier 1 te da 10 IPM inmediatamente sin gasto minimo.
Por que la generacion de imagenes de Gemini devuelve errores 429
Todos los proveedores de API implementan limites de solicitudes para proteger la infraestructura contra abusos y garantizar una distribucion justa de recursos entre todos los usuarios. Cuando tus solicitudes a la Gemini API exceden la cuota asignada para tu nivel de facturacion, los servidores de Google responden con el codigo de estado HTTP 429 y un mensaje de error RESOURCE_EXHAUSTED. Esto no es un error en tu codigo ni un problema con el modelo Gemini en si — es la pasarela de la API aplicando los limites de cuota que Google ha establecido para tu proyecto. Comprender la mecanica detras de este error es el primer paso para construir un pipeline de generacion de imagenes resiliente que pueda manejar cargas de trabajo a escala de produccion sin interrupciones.
La respuesta 429 de la Gemini API lleva una estructura especifica que muchos desarrolladores pasan por alto. El cuerpo de la respuesta contiene un objeto JSON con un campo error que incluye el codigo de estado RESOURCE_EXHAUSTED, un mensaje legible que describe que cuota fue excedida, y de manera critica, cabeceras de metadatos como x-ratelimit-limit, x-ratelimit-remaining y x-ratelimit-reset que te indican exactamente que dimension activo el limite y cuando se restablecera. Muchos desarrolladores simplemente capturan el 429 y reintentan a ciegas, pero analizar estas cabeceras te da la inteligencia para implementar soluciones dirigidas en lugar de reintentos por fuerza bruta. Si x-ratelimit-remaining para IPM muestra 0 mientras RPM aun tiene capacidad, sabes que el cuello de botella es especificamente el rendimiento de generacion de imagenes, no el volumen general de solicitudes.
Las cuatro dimensiones de limite de solicitudes
Google aplica limites de solicitudes en cuatro dimensiones independientes, y alcanzar cualquiera de ellas activa un error 429. La mayoria de los desarrolladores estan familiarizados con RPM y RPD, pero la introduccion de IPM junto con las capacidades nativas de generacion de imagenes de Gemini a finales de 2025 tomo por sorpresa a muchos equipos. Cada dimension opera de forma independiente — podrias estar bien dentro de tu limite RPM pero aun asi ser limitado porque tu cuota de IPM se agoto. Esta tabla desglosa cada dimension y su impacto en las cargas de trabajo de generacion de imagenes:
| Dimension | Nombre completo | Que mide | Impacto en la generacion de imagenes |
|---|---|---|---|
| RPM | Solicitudes Por Minuto | Total de llamadas API en una ventana de 60 segundos | Afecta todas las llamadas Gemini, incluyendo texto |
| RPD | Solicitudes Por Dia | Total de llamadas API en una ventana de 24 horas | Limita el volumen diario para todas las operaciones |
| TPM | Tokens Por Minuto | Total de tokens de entrada + salida procesados por minuto | Afecta principalmente al texto; las imagenes cuentan como bloques fijos de tokens |
| IPM | Imagenes Por Minuto | Numero de imagenes generadas por minuto | El factor oculto — limita directamente la salida de imagenes |
IPM: el factor oculto que la mayoria de los desarrolladores pasan por alto
Imagenes Por Minuto es la dimension de limite de solicitudes que causa mas confusion entre los desarrolladores que integran las funciones de generacion de imagenes de Gemini. A diferencia de RPM, que gobierna todas las solicitudes API incluyendo completaciones de texto, IPM cuenta especificamente el numero de imagenes que tu aplicacion genera dentro de una ventana deslizante de 60 segundos. Una sola llamada API que genera cuatro imagenes consume 4 IPM, no 1 RPM. Esto significa que puedes estar bien dentro de tu cuota RPM y aun asi alcanzar el techo de IPM si tus solicitudes frecuentemente producen multiples imagenes. El problema se agrava por el hecho de que el nivel gratuito bajo a 0 IPM en diciembre de 2025, lo que significa que cualquier intento de generacion de imagenes en una cuenta sin pago devuelve un 429 inmediato sin siquiera procesar la solicitud. Muchos desarrolladores que depuran su primer error 429 pierden horas revisando la logica de su codigo cuando el verdadero problema es simplemente que su nivel de facturacion no permite ninguna generacion de imagenes.
El bug fantasma 429 de febrero de 2026
A principios de febrero de 2026, multiples desarrolladores con cuentas pagadas de Tier 1 reportaron recibir errores 429 RESOURCE_EXHAUSTED a pesar de que sus paneles de uso mostraban consumo cero o casi cero contra sus cuotas. Este bug "fantasma 429" parece ser un problema del lado del servidor con el sistema de seguimiento de cuotas de Google, donde el limitador de velocidad calcula incorrectamente el uso para ciertas configuraciones de proyecto. El bug afecta principalmente a cuentas que fueron recientemente actualizadas de Free a Tier 1, y se manifiesta mas comunmente durante las primeras 24-48 horas despues de activar la facturacion. Google reconocio el problema en sus foros de desarrolladores y recomendo cambiar a una variante de modelo diferente (por ejemplo, de gemini-3.1-flash a gemini-3-pro) como solucion temporal mientras su equipo de ingenieria investiga. Si encuentras errores 429 con uso genuinamente cero mostrando en tu panel de cuotas de Google Cloud Console, este bug es el culpable mas probable en lugar de cualquier mala configuracion de tu parte. Para una comprension mas amplia de los codigos de error de Gemini API y sus soluciones, consulta nuestra guia completa de solucion de errores de Gemini API. Si deseas entender el sistema completo de limites de solicitudes en detalle, nuestra guia completa de limites de solicitudes de Gemini API cubre cada nivel y dimension.
Diagnostico rapido: ¿que limite de solicitudes alcanzaste?

Antes de saltar a las soluciones, necesitas identificar que dimension especifica de limite de solicitudes esta bloqueando tus solicitudes. Aplicar la solucion incorrecta desperdicia tiempo — el backoff exponencial resuelve problemas de RPM pero no hace nada para un cuello de botella de IPM donde necesitas una actualizacion de nivel. El proceso de diagnostico requiere examinar tanto la respuesta de error de la API como tus patrones de uso a lo largo del tiempo. Google no siempre incluye informacion explicita de dimension en el cuerpo del error 429, por lo que a menudo necesitas correlacionar el momento del error con tus patrones de solicitud conocidos para reducir la causa. La buena noticia es que cada dimension de limite de solicitudes produce un patron de fallo distintivo que puedes identificar con un enfoque sistematico.
Lectura de metadatos de respuesta de error
La forma mas directa de identificar que limite de solicitudes alcanzaste es analizar las cabeceras de respuesta y el cuerpo del error de la respuesta 429. Google incluye metadatos de limite de solicitudes en las cabeceras de respuesta, aunque las cabeceras exactas presentes pueden variar dependiendo de que cuota fue agotada. El siguiente fragmento de Python demuestra como extraer y registrar esta informacion de diagnostico de una solicitud fallida. Este codigo captura la excepcion 429, extrae todas las cabeceras relacionadas con limites de solicitudes e imprime un informe de diagnostico estructurado que te indica inmediatamente que dimension es el cuello de botella.
pythonimport google.generativeai as genai from google.api_core.exceptions import ResourceExhausted def diagnose_rate_limit(api_key: str, prompt: str): genai.configure(api_key=api_key) model = genai.GenerativeModel("gemini-3.1-flash") try: response = model.generate_content(prompt) return response except ResourceExhausted as e: print(f"429 RESOURCE_EXHAUSTED: {e.message}") # Parse error details for quota dimension if hasattr(e, 'errors') and e.errors: for error in e.errors: metadata = error.get('metadata', {}) print(f" Quota dimension: {metadata.get('quota_dimension', 'unknown')}") print(f" Quota limit: {metadata.get('quota_limit', 'unknown')}") print(f" Quota usage: {metadata.get('quota_usage', 'unknown')}") # Check for ghost 429 pattern if "usage: 0" in str(e) or "quota_usage: 0" in str(e.errors): print(" WARNING: Ghost 429 detected (usage=0).") print(" This matches the known Feb 2026 bug.") print(" Try switching model: gemini-3-pro or imagen-4") raise
Tres patrones de fallo
Mas alla de analizar los metadatos de error, puedes identificar la dimension de limite de solicitudes observando el patron temporal de tus fallos. Cada dimension produce una firma distintiva porque RPM, RPD e IPM operan en diferentes ventanas de tiempo. Comprender estos patrones es esencial cuando los metadatos de error estan incompletos o cuando estas depurando problemas en un entorno de produccion donde solo tienes registros para trabajar. Aqui estan los tres patrones a vigilar:
El primer patron es "rafagas y luego exito" — tu aplicacion envia una rafaga rapida de solicitudes, obtiene varios errores 429, y luego tiene exito despues de esperar 30-60 segundos. Este patron indica fuertemente una violacion del limite RPM. La ventana deslizante de 60 segundos se restablece continuamente, por lo que pausas breves restauran tu cuota. El segundo patron es "funciona por la manana, falla por la noche" — tu aplicacion funciona bien temprano en el dia pero comienza a fallar consistentemente mas tarde. Esto indica agotamiento de RPD, ya que la cuota diaria se ha consumido y no se restablecera hasta la medianoche hora del Pacifico. El tercer patron, y el mas insidioso, es "solo las imagenes fallan" — tus solicitudes de generacion de texto tienen exito perfectamente, pero cada solicitud de generacion de imagenes devuelve 429. Esta es la marca distintiva del agotamiento de IPM y es la trampa mas comun para desarrolladores que estan dentro de sus limites RPM pero han agotado su cuota especifica de imagenes.
Si ves errores 429 en una cuenta de pago pero tu Google Cloud Console muestra cero uso contra tus cuotas, probablemente estas experimentando el bug fantasma 429 documentado anteriormente. Este es un problema separado del agotamiento legitimo de cuota. Los desarrolladores que recientemente actualizaron del nivel gratuito al Tier 1 deben estar especialmente alerta a este patron. Para mas detalles sobre como distinguir entre limites de solicitudes legitimos y desajustes de nivel de facturacion, consulta nuestra guia sobre cuentas de nivel pagado obteniendo limites de solicitudes del nivel gratuito.
Solucion 1 — Backoff exponencial con reintento inteligente
El backoff exponencial es la solucion individual mas impactante que puedes implementar para errores 429, y no requiere cambios de infraestructura ni modificaciones de facturacion. El principio es sencillo: cuando tu solicitud falla con un 429, espera una duracion exponencialmente creciente antes de reintentar — 1 segundo, luego 2 segundos, luego 4, luego 8, y asi sucesivamente. Esto le da tiempo al limitador de velocidad para liberar capacidad y evita que tu aplicacion bombardee la API durante una ventana de recuperacion de cuota. En la practica, un backoff exponencial bien implementado transforma una aplicacion que falla el 80% del tiempo durante carga maxima en una que eventualmente tiene exito en mas del 99% de las solicitudes, aunque la contrapartida es una latencia aumentada para solicitudes que requieren multiples reintentos.
Por que importa el jitter: el problema del rebano atronador
El backoff exponencial simple tiene un defecto critico cuando se despliega en multiples instancias de tu aplicacion. Si diez servidores de aplicacion reciben un 429 en el mismo instante e implementan backoff exponencial identico, todos reintentaran en exactamente los mismos momentos — 1 segundo despues, luego 2 segundos despues, luego 4 segundos despues. Este comportamiento de reintento sincronizado crea un "rebano atronador" que repetidamente sobrecarga el limitador de velocidad en intervalos precisos, empeorando la congestion en lugar de mejorarla. Agregar jitter aleatorio — una pequena variacion aleatoria en cada duracion de espera — desincroniza tus intentos de reintento en todas las instancias. En lugar de que diez servidores reintenten todos en t+1s, reintentan en t+0.7s, t+1.2s, t+0.9s, y asi sucesivamente, distribuyendo la carga suavemente a traves de la ventana de recuperacion. Esta simple adicion mejora dramaticamente las tasas de exito en sistemas distribuidos y es considerada una mejor practica por todos los principales proveedores de nube incluyendo Google, AWS y Azure.
Implementacion en Python con Tenacity
La libreria tenacity proporciona la forma mas elegante de implementar backoff exponencial en Python. Maneja toda la complejidad de la logica de reintentos, jitter, limites maximos de intentos y filtrado de excepciones en una sintaxis limpia de decorador. La siguiente implementacion esta lista para produccion e incluye registro, tiempos de espera configurables y manejo especifico para errores 429 versus otras excepciones de API que no deben reintentarse.
pythonimport tenacity import google.generativeai as genai from google.api_core.exceptions import ResourceExhausted import logging logger = logging.getLogger(__name__) @tenacity.retry( retry=tenacity.retry_if_exception_type(ResourceExhausted), wait=tenacity.wait_exponential(multiplier=1, min=2, max=60) + tenacity.wait_random(0, 2), # jitter stop=tenacity.stop_after_attempt(8), before_sleep=tenacity.before_sleep_log(logger, logging.WARNING), reraise=True, ) def generate_image_with_retry(model, prompt: str): """Generate image with automatic exponential backoff on 429 errors.""" response = model.generate_content( prompt, generation_config=genai.GenerationConfig( response_modalities=["image", "text"], ), ) return response genai.configure(api_key="YOUR_API_KEY") model = genai.GenerativeModel("gemini-3.1-flash") try: result = generate_image_with_retry(model, "A futuristic cityscape at sunset") # Process result.candidates[0].content.parts for image data except ResourceExhausted: logger.error("All retries exhausted. Consider upgrading tier.")
Implementacion en Node.js con p-retry
Para aplicaciones Node.js, el paquete p-retry proporciona funcionalidad equivalente con una API basada en promesas que se integra limpiamente con patrones async/await. La siguiente implementacion replica el comportamiento de la version Python e incluye las mismas protecciones de produccion — jitter, intentos maximos, registro y clasificacion adecuada de errores para evitar reintentar errores no reintentables como fallos de autenticacion o prompts invalidos.
javascriptconst pRetry = require('p-retry'); const { GoogleGenerativeAI } = require('@google/generative-ai'); const genAI = new GoogleGenerativeAI('YOUR_API_KEY'); async function generateImageWithRetry(prompt) { const model = genAI.getGenerativeModel({ model: 'gemini-3.1-flash' }); return pRetry( async (attemptNumber) => { console.log(`Attempt ${attemptNumber} for image generation...`); const result = await model.generateContent({ contents: [{ role: 'user', parts: [{ text: prompt }] }], generationConfig: { responseModalities: ['image', 'text'] }, }); return result.response; }, { retries: 7, minTimeout: 2000, // 2 seconds initial wait maxTimeout: 60000, // 60 seconds maximum wait factor: 2, // exponential factor randomize: true, // adds jitter automatically onFailedAttempt: (error) => { if (error.status !== 429) { throw error; // don't retry non-429 errors } console.warn( `Rate limited. Attempt ${error.attemptNumber} failed. ` + `${error.retriesLeft} retries remaining.` ); }, } ); }
Consejos de produccion para backoff exponencial: Establece tu conteo maximo de reintentos entre 6 y 10 intentos. Con una base de 2 segundos y un factor de 2, ocho intentos cubren una ventana de espera total de aproximadamente 8.5 minutos, que es mas que suficiente para que los limites RPM se restablezcan. Siempre establece un tiempo de espera absoluto en la operacion general (no solo en reintentos individuales) para evitar que las solicitudes queden colgadas indefinidamente. Registra cada reintento con el numero de intento y la duracion de espera para que puedas monitorear tu tasa de 429 en paneles de produccion y saber cuando es momento de actualizar niveles en lugar de depender unicamente de reintentos.
Solucion 2 — Actualiza tu nivel de facturacion
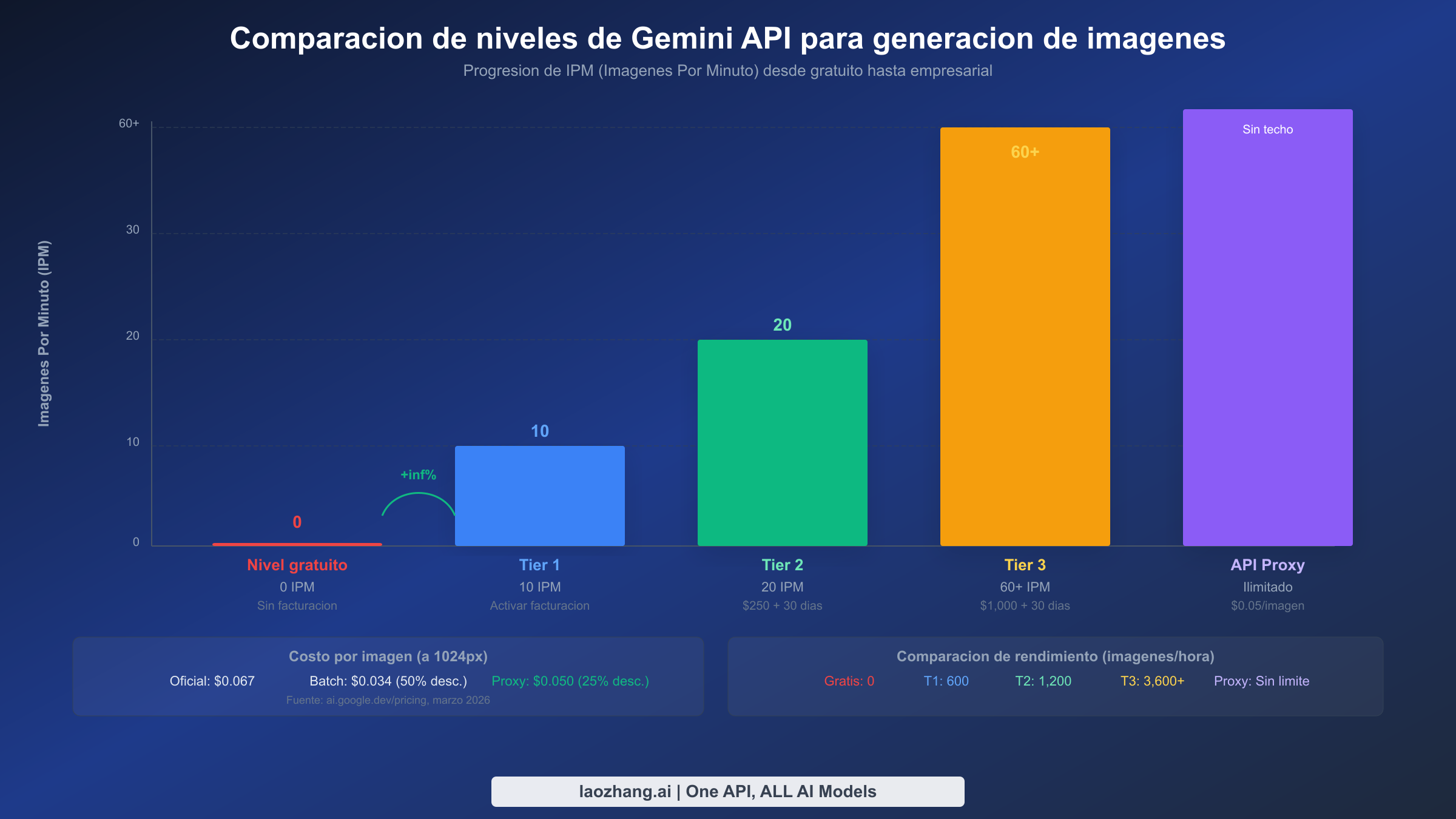
Mientras que el backoff exponencial maneja picos transitorios de limite de solicitudes, la solucion mas confiable a largo plazo para errores 429 sostenidos es actualizar tu nivel de facturacion de Google Cloud. Cada aumento de nivel multiplica tu cuota en las cuatro dimensiones de limite de solicitudes, y para la generacion de imagenes especificamente, el aumento de IPM es el cambio mas impactante. Muchos desarrolladores no se dan cuenta de que el nivel gratuito efectivamente deshabilita la generacion de imagenes por completo — la cuota de IPM se redujo a 0 en diciembre de 2025. Simplemente activar la facturacion en tu proyecto de Google Cloud te promueve inmediatamente al Tier 1, que desbloquea 10 IPM sin requisito de gasto minimo. Esta unica accion resuelve la mayoria de los errores 429 que los desarrolladores encuentran durante la integracion y las pruebas iniciales.
Comparacion de niveles para generacion de imagenes
Entender las cuotas especificas en cada nivel es esencial para elegir el nivel adecuado para tu carga de trabajo. La siguiente tabla muestra los limites de solicitudes que impactan directamente la generacion de imagenes en todos los niveles disponibles. Ten en cuenta que los limites del Tier 3 son negociables a traves de ventas de Google Cloud, por lo que los numeros mostrados representan la linea base estandar en lugar de maximos absolutos.
| Nivel | Requisito de gasto mensual | Requisito de tiempo | RPM | RPD | IPM | Batch TPD | Costo por imagen (1K) |
|---|---|---|---|---|---|---|---|
| Gratuito | Ninguno | Ninguno | 2 | 50 | 0 | N/A | N/A (bloqueado) |
| Tier 1 | Activar facturacion (sin minimo) | Inmediato | 10 | 1,500 | 10 | 1M tokens | $0.067 |
| Tier 2 | $250 acumulados | 30 dias en Tier 1 | 30 | 10,000+ | 20 | 250M tokens | $0.067 |
| Tier 3 | $1,000 acumulados | 30 dias en Tier 2 | 60+ | Negociable | 60+ | 750M tokens | $0.067 |
El salto de Gratuito a Tier 1 es con diferencia la actualizacion mas impactante porque transiciona de 0 IPM (sin generacion de imagenes en absoluto) a 10 IPM, que es suficiente para desarrollo, pruebas y aplicaciones de produccion de bajo trafico. Diez imagenes por minuto se traducen en 600 imagenes por hora o aproximadamente 14,400 imagenes por dia si se mantiene continuamente, que es mas que suficiente para la mayoria de las aplicaciones pequenas a medianas. La actualizacion de Tier 1 a Tier 2 duplica tu IPM a 20 y aumenta dramaticamente tu RPD de 1,500 a mas de 10,000, lo que importa para aplicaciones que generan imagenes a lo largo del dia en lugar de en rafagas.
Como verificar y actualizar tu nivel actual
Verificar tu nivel de facturacion actual requiere navegar a Google Cloud Console y examinar el estado de facturacion de tu proyecto. Ve a Google Cloud Console, selecciona tu proyecto, navega a Facturacion, y luego mira la pagina "Cuotas y limites del sistema" bajo la seccion API de Lenguaje Generativo. Tu nivel actual se muestra junto a cada metrica de cuota. Si ves IPM listado como 0, estas en el nivel gratuito independientemente de lo que muestre la pagina de facturacion — esta es una fuente comun de confusion porque tener una cuenta de facturacion vinculada a tu proyecto no significa automaticamente que la facturacion esta habilitada para la API de IA Generativa especificamente. Necesitas verificar que la cuenta de facturacion esta vinculada al proyecto Y que la API de Lenguaje Generativo tiene la facturacion habilitada en el panel de API. Para desarrolladores que encuentran problemas persistentes donde su cuenta de pago parece tener limites de nivel gratuito, consulta nuestra guia dedicada sobre limites del nivel gratuito de generacion de imagenes de Gemini que recorre cada paso de verificacion.
Cronograma de actualizacion de nivel: La activacion del Tier 1 es instantanea una vez que se habilita la facturacion. El Tier 2 requiere tanto $250 en gasto acumulado COMO 30 dias de uso activo del Tier 1 — no puedes acelerar esto gastando $250 en un dia. El Tier 3 requiere similarmente $1,000 de gasto acumulado Y 30 dias en el Tier 2. Planifica tu progresion de nivel con anticipacion a tus necesidades de escalamiento porque estas puertas de tiempo no pueden ser evitadas a traves de tickets de soporte de Google Cloud.
Solucion 3 — Usa la Batch API para generacion de alto volumen
La Gemini Batch API es una solucion infrautilizada para desarrolladores que necesitan generar grandes volumenes de imagenes pero no requieren respuestas en tiempo real. La ventaja critica de la Batch API es que opera en un pool de cuota completamente separado de la API en tiempo real, lo que significa que las solicitudes de generacion de imagenes por lotes no cuentan contra tus limites de RPM, RPD o IPM. Esta separacion hace que la Batch API sea un complemento poderoso para tu pipeline en tiempo real — puedes descargar la generacion de imagenes no urgente al procesamiento por lotes mientras reservas tu cuota en tiempo real para solicitudes interactivas orientadas al usuario. Adicionalmente, Google ofrece un descuento del 50% en todas las solicitudes de la Batch API, haciendola significativamente mas barata que la generacion en tiempo real para cargas de trabajo de alto volumen.
Como funciona el procesamiento por lotes
La Batch API sigue un modelo asincrono basado en trabajos. Envias un lote de prompts como un solo trabajo, Google los pone en cola para procesamiento, y consultas los resultados hasta que el trabajo se complete. El acuerdo de nivel de servicio garantiza la finalizacion dentro de 24 horas, aunque en la practica la mayoria de los trabajos por lotes terminan dentro de 2-6 horas dependiendo del volumen y la carga actual del sistema. Cada trabajo por lotes puede contener hasta 100 solicitudes, y puedes enviar multiples trabajos por lotes concurrentemente. El pool de cuota separado significa que una cuenta Tier 1 con solo 10 IPM para solicitudes en tiempo real puede procesar miles de imagenes a traves de la Batch API, limitada solo por la asignacion de tokens especifica del lote: 1 millon de tokens por dia para Tier 1, 250 millones para Tier 2 y 750 millones para Tier 3. Dado que una solicitud tipica de generacion de imagenes consume aproximadamente 1,000-2,000 tokens, incluso la asignacion de lotes del Tier 1 soporta 500-1,000 imagenes por dia a traves del pipeline de lotes solamente.
Implementacion en Python: generacion de imagenes por lotes
El siguiente codigo demuestra como crear un trabajo de generacion de imagenes por lotes, enviarlo a la Gemini Batch API y consultar los resultados. Este patron es adecuado para flujos de trabajo como generar imagenes de productos para un catalogo de comercio electronico, crear activos de redes sociales en masa o preprocesar variaciones de imagenes para pruebas A/B. El trabajo por lotes maneja los reintentos internamente, por lo que no necesitas implementar backoff exponencial para envios por lotes.
pythonimport google.generativeai as genai import time import json genai.configure(api_key="YOUR_API_KEY") def batch_generate_images(prompts: list[str], model_name="gemini-3.1-flash"): """Submit a batch of image generation prompts and wait for results.""" # Prepare batch request batch_requests = [] for i, prompt in enumerate(prompts): batch_requests.append({ "custom_id": f"image-{i}", "request": { "model": model_name, "contents": [{"role": "user", "parts": [{"text": prompt}]}], "generation_config": { "response_modalities": ["image", "text"], }, }, }) # Submit batch job batch_job = genai.create_batch( requests=batch_requests, display_name=f"image-batch-{int(time.time())}", ) print(f"Batch job created: {batch_job.name}") print(f"Status: {batch_job.state}") # Poll for completion (24h SLA, typically 2-6h) while batch_job.state in ("QUEUED", "PROCESSING"): time.sleep(30) # Check every 30 seconds batch_job = genai.get_batch(batch_job.name) completed = sum(1 for r in batch_job.results if r.state == "COMPLETED") print(f" Progress: {completed}/{len(prompts)} completed") # Collect results results = {} for result in batch_job.results: if result.state == "COMPLETED": results[result.custom_id] = result.response else: print(f" Failed: {result.custom_id} - {result.error}") return results # Example usage prompts = [ "A modern office workspace with natural lighting", "A coffee shop interior with warm ambiance", "A serene garden with Japanese maples", # ... up to 100 prompts per batch ] results = batch_generate_images(prompts) print(f"Successfully generated {len(results)} images")
Ahorro de costos y asignaciones por nivel
El descuento del 50% por lotes se aplica a todos los tamanos de imagen, haciendo que el costo por imagen sea significativamente menor que la generacion en tiempo real. A resolucion 1K, el costo baja de $0.067 a aproximadamente $0.034 por imagen. Para equipos que generan cientos o miles de imagenes diariamente, este descuento por si solo puede justificar la inversion arquitectonica en infraestructura de procesamiento por lotes. Las asignaciones de tokens especificas por lotes por nivel tambien merecen atencion porque determinan el rendimiento maximo de lotes independientemente de tus cuotas en tiempo real.
| Nivel | Asignacion de tokens por lotes (diaria) | Capacidad aproximada de imagenes | Costo por imagen (1K, con 50% de descuento) |
|---|---|---|---|
| Tier 1 | 1M tokens | ~500-1,000 imagenes | $0.034 |
| Tier 2 | 250M tokens | ~125,000-250,000 imagenes | $0.034 |
| Tier 3 | 750M tokens | ~375,000-750,000 imagenes | $0.034 |
El salto dramatico del Tier 1 al Tier 2 en asignaciones de lotes (1M a 250M tokens) hace que la actualizacion al Tier 2 sea especialmente valiosa para cargas de trabajo intensivas en lotes. Si tu aplicacion puede tolerar la naturaleza asincrona del procesamiento por lotes para una porcion significativa de sus necesidades de generacion de imagenes, combinar llamadas API en tiempo real para solicitudes interactivas con procesamiento por lotes para tareas en segundo plano te da lo mejor de ambos mundos. Para mas estrategias sobre optimizacion de costos con procesamiento por lotes, consulta nuestra guia de optimizacion de costos de Batch API.
Solucion 4 — Proxy API para rendimiento ilimitado
Cuando tu aplicacion requiere un rendimiento que excede incluso los limites del Tier 3, o cuando necesitas evitar la complejidad de gestionar niveles de facturacion de Google Cloud y monitoreo de cuotas, un servicio de proxy API proporciona un enfoque fundamentalmente diferente al problema de limitacion de solicitudes. Un proxy API agrega multiples claves API y proyectos de Google Cloud detras de un unico punto de acceso unificado, distribuyendo tus solicitudes a traves de este pool para eliminar efectivamente los limites de solicitudes por proyecto. Desde la perspectiva de tu aplicacion, haces llamadas API a un unico punto de acceso con una sola clave, y el proxy maneja el balanceo de carga, seguimiento de cuotas y conmutacion automatica por detras. Este enfoque es particularmente valioso para startups y empresas medianas que necesitan rendimiento de grado de produccion sin la sobrecarga operativa de gestionar multiples proyectos de Google Cloud y cuentas de facturacion.
Como los proxies API resuelven la limitacion de solicitudes
La idea fundamental detras de los proxies API es que los limites de solicitudes de Google se aplican por proyecto, no por usuario ni por organizacion. Un servicio de proxy mantiene un pool de N proyectos, cada uno con su propia asignacion de cuota independiente. Cuando tu solicitud llega, el proxy la enruta a un proyecto con cuota disponible, multiplicando efectivamente tu rendimiento total por el numero de proyectos en el pool. Si cada proyecto tiene 10 IPM y el pool contiene 20 proyectos, tu limite efectivo se convierte en 200 IPM — mucho mas alla de lo que cualquier cuenta Tier 3 individual puede proporcionar. El proxy tambien monitorea el uso de cuota en todos los proyectos en tiempo real, implementando enrutamiento inteligente que evita enviar solicitudes a proyectos que estan cerca de sus limites. Esta arquitectura distribuida hace que los errores 429 sean virtualmente imposibles bajo condiciones normales de operacion porque el proxy siempre tiene capacidad de reserva disponible.
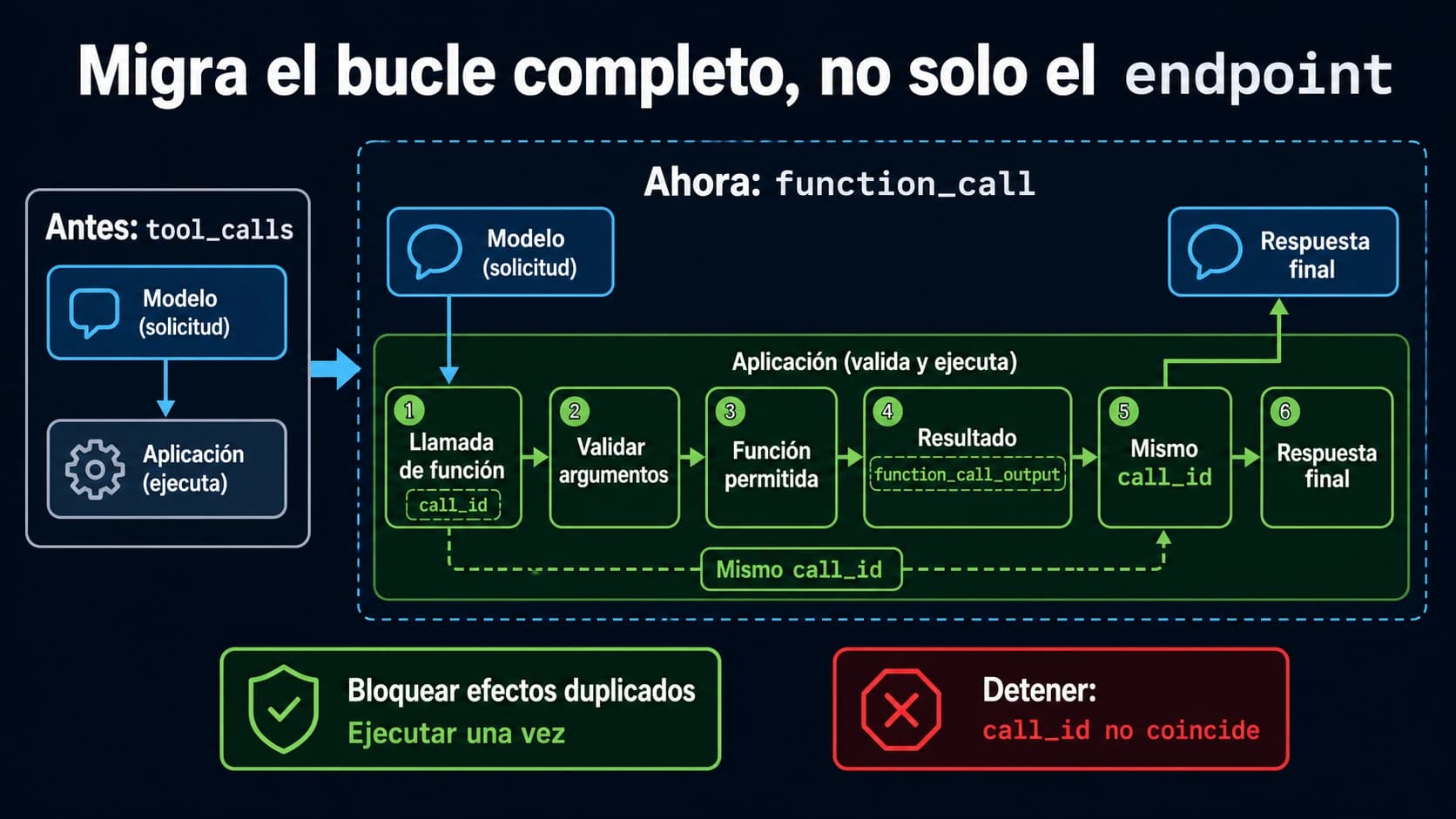
Cambios minimos de codigo requeridos
Cambiar del acceso directo a la Gemini API a un punto de acceso proxy requiere cambiar solo tres lineas de codigo en la mayoria de las implementaciones. Los proxies API que soportan la interfaz compatible con OpenAI te permiten usar el SDK estandar de OpenAI, con el que muchos desarrolladores ya estan familiarizados. Los siguientes ejemplos muestran el antes y despues tanto para Python como para Node.js:
python# Before: Direct Gemini API import google.generativeai as genai genai.configure(api_key="YOUR_GOOGLE_API_KEY") model = genai.GenerativeModel("gemini-3.1-flash") # After: Through API proxy (OpenAI-compatible) from openai import OpenAI client = OpenAI( api_key="YOUR_PROXY_KEY", base_url="https://api.laozhang.ai/v1" # proxy endpoint ) response = client.chat.completions.create( model="gemini-3.1-flash", messages=[{"role": "user", "content": "Generate an image of a sunset"}], )
El enfoque de proxy ofrece varias ventajas mas alla del rendimiento puro. Primero, obtienes un modelo de precios de tarifa plana — laozhang.ai cobra $0.05 por imagen independientemente de la resolucion, comparado con los precios escalonados de Google de $0.045 (512px), $0.067 (1K), $0.101 (2K) o $0.151 (4K). Para aplicaciones que generan imagenes en resolucion 2K o 4K, el proxy es realmente mas barato que el acceso directo a la API. Segundo, el proxy maneja toda la logica de reintentos, gestion de cuotas y manejo de errores internamente, reduciendo la complejidad del codigo de tu aplicacion. Tercero, evitas las puertas de tiempo de 30 dias requeridas para actualizaciones de nivel — el proxy proporciona alto rendimiento desde el primer dia.
Cuando usar un proxy API: Aplicaciones en tiempo real que necesitan mas de 60 IPM, equipos que quieren evitar gestionar la complejidad de facturacion de Google Cloud, aplicaciones que generan imagenes de alta resolucion donde los precios de tarifa plana son mas baratos que los precios oficiales escalonados, y proyectos que necesitan escalar rapidamente sin esperar los periodos de elegibilidad para actualizacion de nivel.
Solucion 5 — Estrategia de respaldo multi-modelo
La Gemini API ofrece multiples modelos capaces de generacion de imagenes, y cada variante de modelo mantiene sus propios limites de solicitudes independientes. Este detalle arquitectonico crea una oportunidad para una poderosa estrategia de respaldo: cuando un modelo alcanza su limite de solicitudes, tu aplicacion cambia automaticamente a un modelo alternativo que aun tiene cuota disponible. Este enfoque multiplica tu rendimiento efectivo sin requerir actualizaciones de nivel, cuentas de facturacion adicionales o servicios de proxy externos. La contrapartida es que diferentes modelos pueden producir calidad y estilos de imagen ligeramente diferentes, por lo que esta estrategia funciona mejor para aplicaciones donde la consistencia visual entre todas las imagenes generadas no es critica.
Construyendo una cadena de respaldo
La cadena de respaldo mas efectiva para generacion de imagenes a principios de 2026 usa tres modelos en orden de prioridad: gemini-3.1-flash-image como modelo primario (mas rapido, mas barato), gemini-3-pro-image como modelo secundario (mayor calidad, ligeramente mas lento) e imagen-4 como respaldo terciario (modelo de imagen especializado, estilo diferente). Cada modelo tiene sus propias cuotas de RPM, IPM y RPD que son rastreadas independientemente por el limitador de solicitudes de Google. Si el IPM de tu modelo primario se agota, el pool de IPM del modelo secundario probablemente no ha sido tocado porque no ha recibido ninguna solicitud. Esto te da un IPM efectivo de 30 en Tier 1 (10 por modelo multiplicado por 3 modelos) en lugar de los 10 IPM que tendrias con un solo modelo.
La siguiente implementacion en Python crea una clase ModelFallbackClient que rota automaticamente entre modelos cuando ocurren errores 429. Combina el backoff exponencial de la Solucion 1 con rotacion de modelos, proporcionando dos capas de resiliencia. El cliente rastrea que modelos estan actualmente limitados y sus tiempos estimados de recuperacion, evitando solicitudes desperdiciadas a modelos que se sabe que estan limitados.
pythonimport google.generativeai as genai from google.api_core.exceptions import ResourceExhausted import time import logging logger = logging.getLogger(__name__) class ModelFallbackClient: """Image generation client with automatic model fallback on 429 errors.""" FALLBACK_CHAIN = [ "gemini-3.1-flash", # Primary: fast, cheap "gemini-3-pro", # Secondary: higher quality "imagen-4", # Tertiary: specialized image model ] def __init__(self, api_key: str): genai.configure(api_key=api_key) self.models = { name: genai.GenerativeModel(name) for name in self.FALLBACK_CHAIN } self.cooldowns = {} # model_name -> earliest_retry_time def generate_image(self, prompt: str, max_retries: int = 3): """Generate image, falling back through model chain on 429 errors.""" for model_name in self.FALLBACK_CHAIN: # Skip models in cooldown if model_name in self.cooldowns: if time.time() < self.cooldowns[model_name]: logger.info(f"Skipping {model_name} (cooldown)") continue else: del self.cooldowns[model_name] for attempt in range(max_retries): try: logger.info(f"Trying {model_name} (attempt {attempt + 1})") response = self.models[model_name].generate_content( prompt, generation_config=genai.GenerationConfig( response_modalities=["image", "text"], ), ) return {"model": model_name, "response": response} except ResourceExhausted: wait = (2 ** attempt) + (time.time() % 1) # backoff + jitter logger.warning( f"{model_name} rate limited. " f"Waiting {wait:.1f}s before retry." ) time.sleep(wait) # All retries exhausted for this model — add cooldown and try next self.cooldowns[model_name] = time.time() + 60 logger.warning(f"{model_name} exhausted. Moving to next model.") raise ResourceExhausted("All models in fallback chain exhausted.") # Usage client = ModelFallbackClient("YOUR_API_KEY") result = client.generate_image("A photorealistic mountain landscape at dawn") print(f"Generated by: {result['model']}")
Contrapartidas y consideraciones
La estrategia de respaldo multi-modelo no esta exenta de limitaciones, y comprender estas contrapartidas es esencial para decidir si se ajusta a tu caso de uso. La contrapartida mas significativa es la consistencia visual — gemini-3.1-flash y gemini-3-pro usan diferentes arquitecturas subyacentes y datos de entrenamiento, lo que significa que el mismo prompt puede producir resultados notablemente diferentes entre modelos. Para aplicaciones como generacion de contenido para redes sociales donde cada imagen es independiente, esta inconsistencia es irrelevante. Para aplicaciones como generacion de catalogos de productos donde la consistencia visual entre todas las imagenes es importante, recurrir a un modelo diferente puede producir resultados que chocan con el estilo visual establecido. Otra consideracion es que imagen-4 usa un contrato de API diferente al de los modelos Gemini — es un modelo dedicado de generacion de imagenes en lugar de un LLM multimodal, por lo que los prompts pueden necesitar ligeros ajustes para producir resultados optimos. El cliente de respaldo anterior maneja esto de forma transparente, pero debes probar tus prompts especificos en los tres modelos para entender las diferencias de calidad antes de desplegar esta estrategia en produccion.
¿Que solucion deberias elegir?
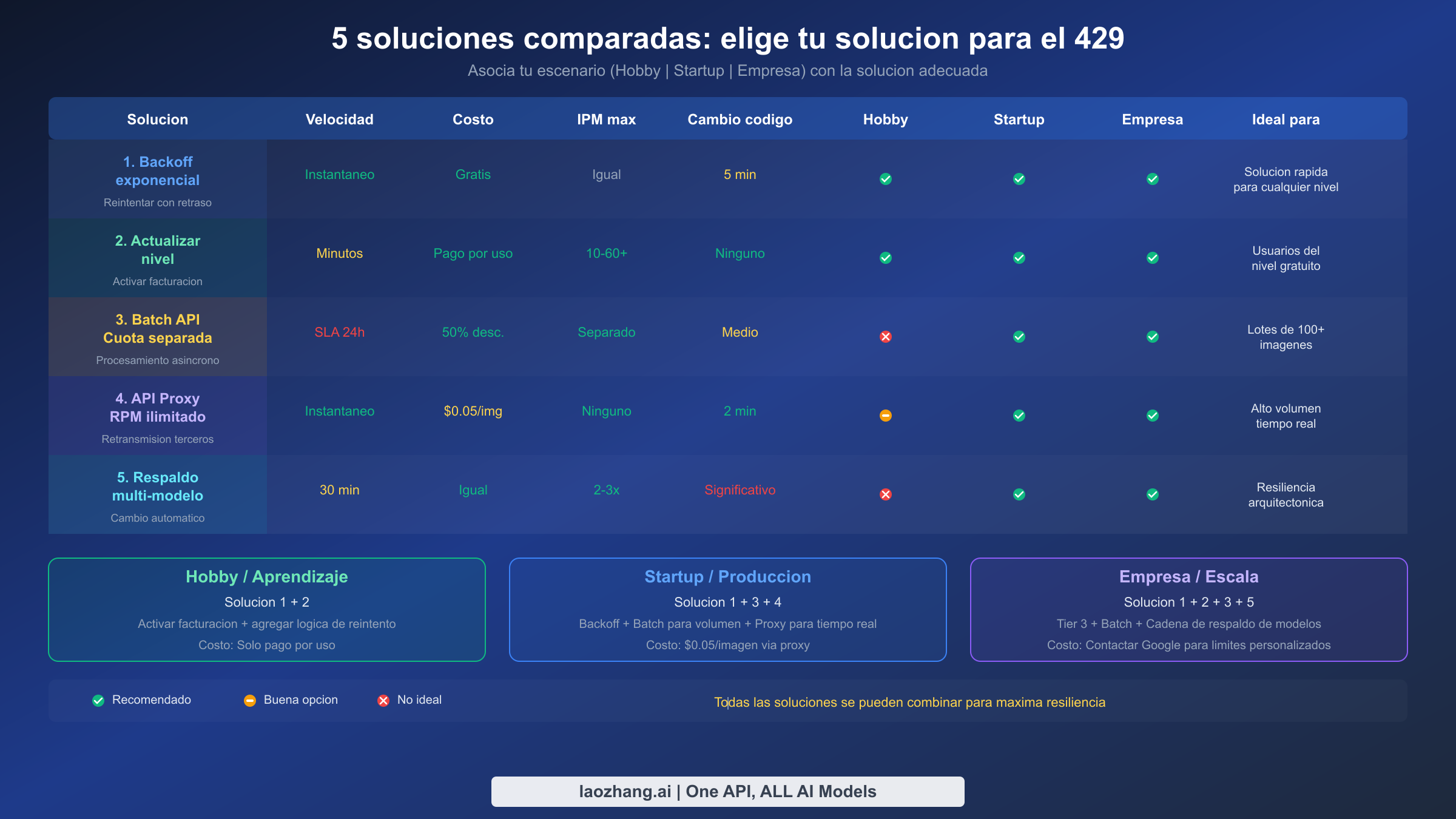
Elegir la combinacion correcta de soluciones depende de los requisitos especificos de tu aplicacion en cuanto a rendimiento, latencia, costo y complejidad operativa. Ninguna solucion individual es universalmente optima — un proyecto hobby con generacion de imagenes ocasional necesita un enfoque fundamentalmente diferente que una plataforma empresarial que sirve a millones de usuarios. La tabla a continuacion mapea tres perfiles comunes de desarrollador a sus combinaciones de soluciones recomendadas, junto con la justificacion de cada recomendacion. En la practica, la mayoria de las aplicaciones de produccion terminan combinando dos o tres soluciones para maxima resiliencia, con el backoff exponencial sirviendo como la base universal que toda implementacion deberia incluir independientemente de la escala.
| Perfil | Soluciones recomendadas | Volumen mensual de imagenes | Costo estimado | Justificacion |
|---|---|---|---|---|
| Hobby / Proyecto personal | Solucion 1 (Backoff) + Solucion 2 (Tier 1) | < 10,000 | < $10 | Tier 1 desbloquea 10 IPM, backoff maneja rafagas |
| Startup / App en crecimiento | Solucion 1 + Solucion 3 (Batch) + Solucion 4 (Proxy) | 10,000 - 500,000 | $50 - $500 | Batch para volumen, proxy para desbordamiento en tiempo real |
| Empresa / Alta escala | Solucion 1 + Solucion 2 (Tier 3) + Solucion 3 + Solucion 5 (Respaldo) | 500,000+ | $500+ | Resiliencia multicapa con cuota dedicada |
Para la mayoria de los desarrolladores que encuentran errores 429 por primera vez, el plan de accion es claro: implementa backoff exponencial inmediatamente (Solucion 1, toma 15 minutos), luego activa la facturacion para alcanzar el Tier 1 (Solucion 2, toma 5 minutos en GCP Console). Estos dos cambios solos resuelven el 95% de los errores 429 para aplicaciones que generan menos de 10 imagenes por minuto. Si tus necesidades crecen mas alla de eso, agrega la Batch API para generacion no urgente y considera un proxy API para cargas de trabajo en tiempo real que excedan los limites de tu nivel.
¿Cuanto dura un limite de solicitudes 429? La duracion depende de que dimension alcanzaste. Los limites RPM se restablecen en una ventana deslizante de 60 segundos, por lo que esperar solo un minuto restaura tu cuota completa por minuto. Los limites RPD se restablecen a la medianoche hora del Pacifico, lo que significa que alcanzar tu limite diario por la tarde resulta en una espera de varias horas. Los limites IPM siguen la misma ventana de 60 segundos que RPM. El bug fantasma 429 no tiene una duracion predecible — algunos desarrolladores reportan que se resuelve en horas, mientras que otros necesitaron cambiar de modelo o recrear su clave API para solucionarlo.
¿Puedo obtener mas de 60 IPM? Si. Los limites del Tier 3 se listan como "60+" porque son negociables. Si contactas a ventas de Google Cloud a traves de tu GCP Console y puedes demostrar una necesidad comercial legitima de mayor rendimiento, Google proporcionara asignaciones de cuota personalizadas que pueden alcanzar cientos o miles de IPM. Las cuentas empresariales con contratos de uso comprometido tipicamente negocian limites personalizados como parte de su acuerdo general de Google Cloud, con descuentos de precios que escalan con el volumen comprometido.
¿Es seguro usar un proxy API? Los proxies API de buena reputacion funcionan como capas de reenvio transparentes — reciben tu solicitud, la enrutan a la API de Google a traves de una de sus credenciales gestionadas y te devuelven la respuesta. El proxy no almacena tus prompts, imagenes generadas ni respuestas de API mas alla del tiempo necesario para completar la solicitud. Dicho esto, estas confiando al operador del proxy el contenido de tu solicitud, asi que elige servicios establecidos con politicas de privacidad claras y un historial en la comunidad de desarrolladores. El modelo de seguridad es comparable a usar cualquier API SaaS de terceros — debes evaluar la reputacion del proveedor y las practicas de manejo de datos antes de enviar prompts sensibles.
¿Por que recibo 429 con 0 de uso? Esto es casi con certeza el bug fantasma 429 de febrero de 2026 que afecta a cuentas Tier 1 recientemente actualizadas. La solucion inmediata es cambiar tu variante de modelo — si estas usando gemini-3.1-flash, prueba gemini-3-pro o viceversa. Algunos desarrolladores tambien lo han resuelto creando una nueva clave API dentro del mismo proyecto, aunque esto no es consistentemente efectivo. Google ha reconocido el problema y esta trabajando en una solucion permanente. Si el problema persiste por mas de 48 horas despues de tu actualizacion de nivel, abre un ticket de soporte a traves de Google Cloud Console con tu ID de proyecto y el cuerpo especifico de la respuesta de error, incluyendo cualquier metadato de cuota en las cabeceras.