La Batch API de Nano Banana Pro ofrece un descuento garantizado del 50% en toda la generacion de imagenes, reduciendo los costos de 4K de $0.24 a $0.12 por imagen (ai.google.dev, marzo 2026). Para desarrolladores que generan miles de imagenes mensualmente, este unico cambio puede ahorrar mas de $1,200 al mes en 10,000 imagenes 4K. Combinado con estrategias de optimizacion adicionales como la adecuacion de resolucion y APIs de terceros como laozhang.ai a $0.05 por imagen fijo, el ahorro total puede alcanzar el 85%. Esta guia recorre cada nivel de precios, proporciona codigo de automatizacion listo para produccion y te ayuda a elegir la estrategia correcta para tu volumen especifico y requisitos de latencia.
Resumen rapido
La Batch API de Nano Banana Pro (Gemini 3 Pro Image) ofrece un descuento fijo del 50% en toda la generacion de imagenes al procesar solicitudes de forma asincrona dentro de 24 horas. Las imagenes estandar en 4K cuestan $0.24 cada una, mientras que el procesamiento por lotes las reduce a $0.12. Proveedores de terceros como laozhang.ai ofrecen un precio aun mas bajo de $0.05 por imagen independientemente de la resolucion, ahorrando hasta un 79%. Para maximizar el ahorro, combina el procesamiento por lotes para trabajo masivo programado con laozhang.ai para solicitudes bajo demanda: este enfoque hibrido puede reducir tu costo efectivo por imagen a aproximadamente $0.035, una reduccion del 85% respecto al precio estandar.
Que es la Batch API de Nano Banana Pro y por que importa
Nano Banana Pro es el nombre comunitario del modelo Gemini 3 Pro Image de Google (ID del modelo: gemini-3-pro-image-preview), uno de los generadores de imagenes por IA mas capaces disponibles a traves de API en 2026. El modelo genera imagenes en resoluciones desde 1K (1024x1024) hasta 4K (4096x4096), con una precision excepcional de renderizado de texto entre 94-96% segun datos de benchmark de spectrumailab. Su calidad se posiciona consistentemente entre las mejores en evaluaciones independientes, convirtiendolo en una opcion preferida para flujos de trabajo profesionales de generacion de imagenes.
La Batch API es el modo de procesamiento asincrono de Google para los modelos Gemini. En lugar de enviar solicitudes individuales y esperar respuestas en tiempo real, envias un lote de solicitudes como un unico trabajo. Google procesa estas solicitudes en segundo plano, generalmente completandolas en unas pocas horas pero garantizando la entrega dentro de 24 horas. A cambio de aceptar este retraso, recibes un descuento fijo del 50% en todos los costos de tokens, tanto de entrada como de salida.
Esta distincion importa enormemente a escala. Una agencia de marketing que genera 5,000 imagenes de producto al mes en resolucion 4K gastaria $1,200 mensuales usando llamadas API estandar. Cambiar a la Batch API reduce inmediatamente eso a $600, un ahorro anual de $7,200 sin cambiar una sola linea de logica de generacion de imagenes. Las imagenes producidas son identicas en calidad; solo difiere el tiempo de entrega. Para cualquier flujo de trabajo donde las imagenes no necesitan aparecer en segundos (generacion de catalogos, programacion de redes sociales, construccion de bibliotecas de activos, creacion de variantes para pruebas A/B), la Batch API representa la optimizacion de costos mas impactante disponible.
Comprender el panorama completo de precios es esencial antes de elegir tu enfoque, porque el descuento del 50% de la Batch API es solo una pieza de un rompecabezas mucho mayor de optimizacion de costos. Los ahorros reales vienen de apilar multiples estrategias juntas, que es exactamente lo que cubre el resto de esta guia.
Desglose completo de precios: cada resolucion y costo oculto
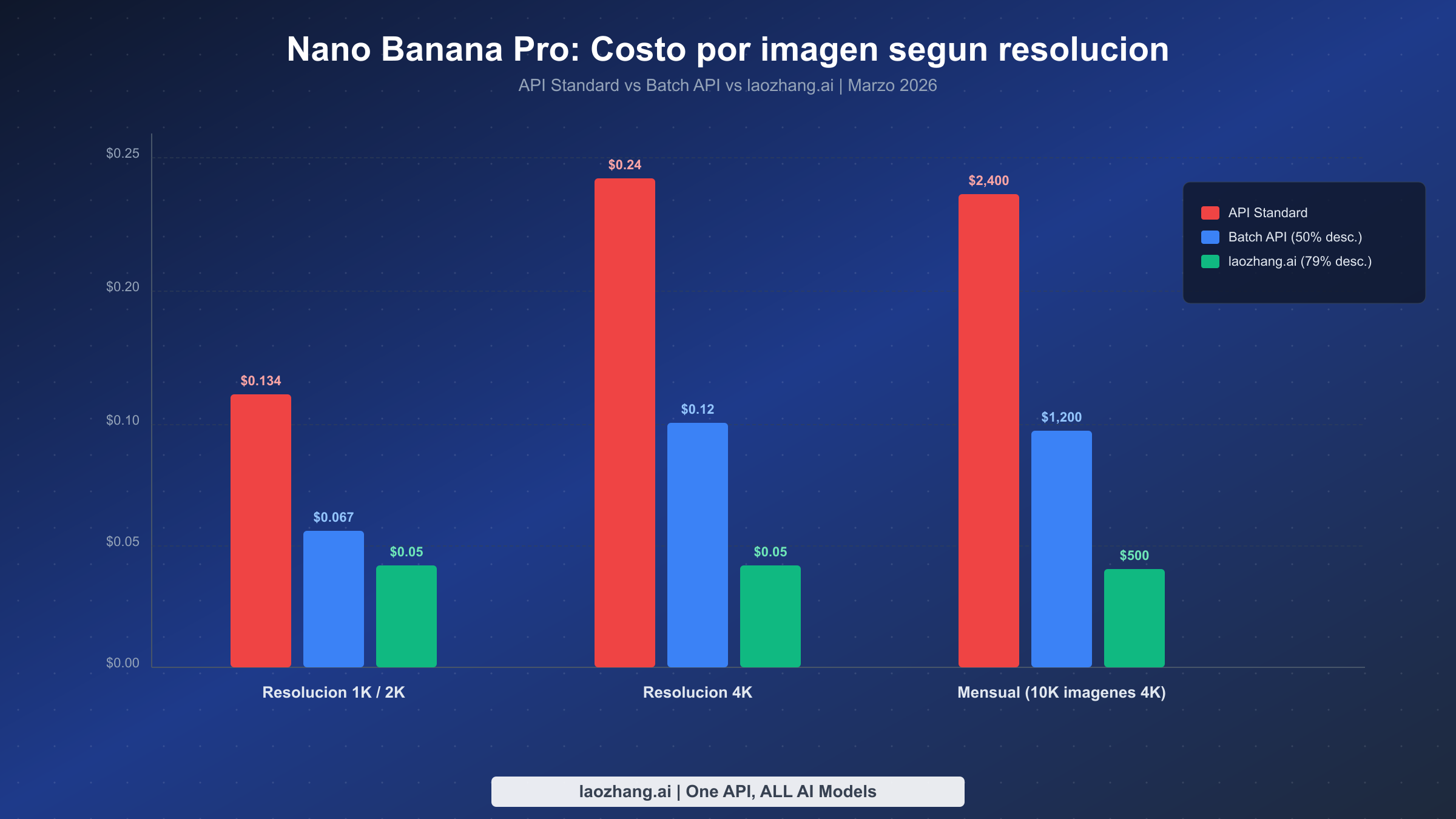
Google establece los precios de Nano Banana Pro usando un sistema basado en tokens, donde la generacion de imagenes consume tanto tokens de entrada (tu prompt) como tokens de salida (los datos de la imagen generada). El costo por imagen varia segun la resolucion porque las imagenes de mayor resolucion requieren mas tokens de salida. A marzo de 2026, los precios oficiales de ai.google.dev se desglosan de la siguiente manera:
| Resolucion | API Standard | Batch API (50% desc.) | Ahorro |
|---|---|---|---|
| 1K (1024x1024) | $0.134 | $0.067 | $0.067/imagen |
| 2K (2048x2048) | $0.134 | $0.067 | $0.067/imagen |
| 4K (4096x4096) | $0.24 | $0.12 | $0.12/imagen |
Estos precios por imagen se derivan de las tarifas subyacentes de tokens: $2.00 por millon de tokens de entrada y $120.00 por millon de tokens de salida de imagen para procesamiento estandar, con tarifas por lotes exactamente reducidas a la mitad a $1.00 y $60.00 respectivamente (pagina de precios de ai.google.dev, actualizada el 12 de marzo de 2026). Para un analisis mas profundo de la estructura completa de precios de Nano Banana Pro incluyendo niveles de suscripcion, consulta nuestro desglose detallado de precios de Nano Banana Pro.
Lo que muchos desarrolladores pasan por alto son los costos ocultos que inflan el verdadero gasto por imagen mas alla de las cifras principales. El costo de tokens de entrada a menudo se ignora porque parece trivialmente pequeno: a $2.00 por millon de tokens, un prompt de 100 tokens cuesta solo $0.0002. Sin embargo, prompts complejos con descripciones detalladas de escenas, especificaciones de estilo y prompts negativos pueden alcanzar facilmente 500-1,000 tokens, agregando $0.001-0.002 por imagen. Con 10,000 imagenes al mes, eso son $10-20 adicionales que nunca aparecen en calculadoras de precios simples.
Las solicitudes fallidas representan otro costo oculto que toma desprevenidos a los equipos. No todas las solicitudes de generacion de imagenes tienen exito: los filtros de seguridad pueden bloquear ciertos prompts, pueden ocurrir errores de timeout durante periodos de alta demanda, y prompts ambiguos pueden producir resultados inutilizables que requieren regeneracion. Basandose en informes de la comunidad en discusiones de Reddit y nuestras propias pruebas, una tasa de exito realista en el primer intento varia entre 70-90% dependiendo de la complejidad del prompt. Esto significa que por cada 100 imagenes utilizables que necesitas, puedes generar realmente 110-140 intentos, inflando tu costo efectivo por imagen entre un 10-40%.
La formula del costo real para cualquier mes dado debe tener en cuenta todos estos factores:
Costo Mensual Real = (imagenes_objetivo / tasa_exito) × costo_por_imagen + (intentos_totales × tokens_prompt_promedio × tarifa_tokens_entrada)
Para un ejemplo concreto: generar 5,000 imagenes 4K utilizables via Batch API con una tasa de exito del 85% y prompts promedio de 300 tokens cuesta aproximadamente $706 al mes, no los $600 que sugeriria una multiplicacion simple. Comprender este costo real te ayuda a hacer comparaciones precisas entre diferentes estrategias de optimizacion.
La guia de precios de Nano Banana 2 cubre la alternativa de nivel Flash (Gemini 3.1 Flash Image) que comienza en solo $0.045 por imagen, vale la pena considerarla si puedes aceptar una calidad ligeramente inferior para ahorros adicionales significativos.
Cuando usar Batch vs Standard vs terceros

Elegir entre API Standard, Batch API y proveedores de terceros no se trata simplemente de encontrar el precio mas bajo, sino de hacer coincidir tu enfoque de procesamiento con los requisitos reales de tu flujo de trabajo. La decision gira en torno a dos variables clave: tolerancia a la latencia y volumen mensual.
Las necesidades en tiempo real (menos de 30 segundos) eliminan la Batch API como opcion por completo. Si tu aplicacion genera imagenes bajo demanda en respuesta a acciones del usuario (una herramienta de diseno, un chatbot con capacidades de imagen o un sistema de personalizacion de contenido en tiempo real), necesitas procesamiento sincrono. Para estos casos de uso con volumen moderado (menos de 5,000 imagenes al mes), la API Standard a $0.134-0.24 por imagen es la opcion directa. Sin embargo, una vez que tu volumen en tiempo real supera las 5,000 imagenes mensuales, proveedores de terceros como laozhang.ai se vuelven atractivos porque ofrecen la misma latencia en tiempo real a $0.05 por imagen, independientemente de la resolucion. Eso es un ahorro del 63-79% comparado con la API Standard manteniendo el mismo patron de respuesta sincrona. La integracion de la API es casi identica: simplemente apuntas tus solicitudes a un endpoint diferente. Para equipos que ya ejecutan cargas de trabajo en produccion, la migracion generalmente toma menos de una hora.
Las cargas de trabajo tolerantes a lotes (aceptables de horas a un dia) son donde la Batch API de Google brilla. La generacion de imagenes de productos para e-commerce, calendarios de contenido para redes sociales, bibliotecas de activos de marketing y la creacion de datos de entrenamiento caen en esta categoria. Envias solicitudes en bloque, continuas con otro trabajo y recuperas los resultados cuando estan listos. El descuento del 50% la convierte en la opcion oficial mas rentable, con imagenes 4K a $0.12 cada una. La consideracion clave es el diseno del flujo de trabajo: necesitas construir tu pipeline alrededor del procesamiento asincrono, lo que significa implementar envio de trabajos, consulta de estado, recuperacion de resultados y manejo de errores.
Las cargas de trabajo de ultra alto volumen (10,000+ imagenes mensuales) se benefician mas de una estrategia hibrida que combina multiples enfoques. Enruta las solicitudes urgentes puntuales a traves de laozhang.ai a $0.05 por imagen para resultados instantaneos. Programa la generacion masiva a traves de la Batch API a $0.067-0.12 por imagen. Usa la API Standard solo para pruebas y prototipado. Este enfoque hibrido ofrece un costo combinado por imagen de aproximadamente $0.035-0.05 dependiendo de la proporcion de trabajo urgente vs programado, representando ahorros del 79-85% comparado con el uso exclusivo de la API Standard.
El modelo mental es simple: si puedes esperar, usa la Batch API. Si no puedes esperar pero necesitas volumen, usa laozhang.ai. Si estas probando o prototipando, usa la API Standard. Si estas a escala empresarial, combina las tres con enrutamiento inteligente.
Una consideracion frecuentemente pasada por alto es el costo operativo de ejecutar infraestructura de lotes. El procesamiento por lotes requiere construir y mantener gestion de trabajos asincronos: colas de envio, consulta de estado, almacenamiento de resultados, recuperacion de fallos y paneles de monitoreo. Para un equipo pequeno que genera 1,000 imagenes al mes, el tiempo de ingenieria dedicado a mantener esta infraestructura puede superar los ahorros en dolares comparado con simplemente usar la API sincrona de laozhang.ai a $0.05 por imagen. El punto de cruce donde la infraestructura de lotes se amortiza tipicamente ocurre alrededor de 5,000-10,000 imagenes al mes, donde el ahorro por imagen ($0.067 batch vs $0.05 laozhang.ai para 2K) multiplicado por volumen genera suficientes ahorros mensuales para justificar la sobrecarga de mantenimiento.
Otra consideracion practica es la previsibilidad de la facturacion. Los costos de API Standard y Batch fluctuan con las opciones de resolucion, la complejidad del prompt y las tasas de reintento. Los proveedores de terceros con precios fijos por imagen eliminan esta variabilidad por completo. Para equipos que necesitan pronosticar costos mensuales con precision (comun en entornos de agencia con presupuestos fijos de clientes), la ventaja de previsibilidad del precio fijo puede ser tan valiosa como la reduccion del costo por imagen en si.
Configuracion paso a paso de la generacion de imagenes por lotes
Implementar la generacion de imagenes con Batch API requiere cuatro componentes: preparacion de solicitudes, envio del trabajo por lotes, consulta de estado y recuperacion de resultados. La siguiente implementacion en Python cubre el flujo de trabajo completo con manejo de errores de nivel produccion.
Primero, asegurate de tener instalado y configurado el SDK de Python de Google Generative AI:
bashpip install google-genai
pythonimport google.genai as genai import json import time client = genai.Client(api_key="YOUR_API_KEY") # Define your batch of image generation requests prompts = [ "A professional product photo of a minimalist ceramic coffee mug on a marble surface, soft natural lighting, 4K quality", "An isometric illustration of a modern home office setup with plants, warm color palette, clean vector style", "A photorealistic landscape of a mountain lake at sunset with mirror-like reflections, cinematic lighting", ]
El proceso de envio por lotes empaqueta multiples solicitudes en una sola llamada API. Cada solicitud especifica el modelo, el prompt y los parametros de generacion:
pythondef submit_batch_job(prompts, resolution="2048x2048"): """Submit a batch of image generation requests.""" requests = [] for i, prompt in enumerate(prompts): requests.append({ "custom_id": f"img-{i:04d}", "model": "gemini-3-pro-image-preview", "contents": [{"parts": [{"text": prompt}]}], "generationConfig": { "responseModalities": ["IMAGE"], "imageGenerationConfig": { "numberOfImages": 1, "outputImageResolution": resolution } } }) # Submit the batch batch_job = client.batches.create( model="gemini-3-pro-image-preview", requests=requests ) print(f"Batch job submitted: {batch_job.name}") return batch_job
Despues del envio, necesitas consultar el estado hasta la finalizacion. Los trabajos por lotes tipicamente se completan dentro de 1-4 horas para volumenes razonables, aunque el SLA garantiza la finalizacion dentro de 24 horas:
pythondef wait_for_completion(batch_job, poll_interval=60): """Poll batch job status until completion.""" while True: status = client.batches.get(name=batch_job.name) state = status.state if state == "JOB_STATE_SUCCEEDED": print(f"Batch completed: {status.request_counts}") return status elif state == "JOB_STATE_FAILED": raise Exception(f"Batch failed: {status.error}") elif state == "JOB_STATE_CANCELLED": raise Exception("Batch was cancelled") print(f"Status: {state} - waiting {poll_interval}s...") time.sleep(poll_interval)
Finalmente, recupera y guarda las imagenes generadas:
pythondef retrieve_results(batch_job, output_dir="./generated_images"): """Download all generated images from completed batch.""" import os import base64 os.makedirs(output_dir, exist_ok=True) results = client.batches.list_results(name=batch_job.name) saved = 0 failed = 0 for result in results: custom_id = result.custom_id if result.response and result.response.candidates: for candidate in result.response.candidates: for part in candidate.content.parts: if hasattr(part, 'inline_data'): img_data = base64.b64decode(part.inline_data.data) filepath = os.path.join(output_dir, f"{custom_id}.png") with open(filepath, 'wb') as f: f.write(img_data) saved += 1 else: failed += 1 print(f"Failed: {custom_id} - {result.error if result.error else 'Unknown error'}") print(f"Results: {saved} saved, {failed} failed") return saved, failed
Para implementaciones en produccion, envuelve el flujo de trabajo completo con logica de reintentos y monitoreo. El siguiente manejador de errores demuestra como gestionar fallos parciales y reintentar automaticamente errores recuperables:
pythondef run_batch_with_retries(prompts, max_retries=3): """Complete batch workflow with error handling and retries.""" remaining = prompts.copy() all_results = [] attempt = 0 while remaining and attempt < max_retries: attempt += 1 print(f"Attempt {attempt}: submitting {len(remaining)} prompts") batch_job = submit_batch_job(remaining) status = wait_for_completion(batch_job) saved, failed_ids = retrieve_results(batch_job) all_results.extend(saved) if failed_ids: # Only retry prompts that failed due to transient errors remaining = [p for i, p in enumerate(remaining) if f"img-{i:04d}" in failed_ids] time.sleep(30 * attempt) # Exponential backoff else: remaining = [] if remaining: print(f"WARNING: {len(remaining)} prompts failed after {max_retries} attempts") return all_results
La logica de reintentos anterior maneja los escenarios de fallo por lotes mas comunes: sobrecarga temporal del servidor (que se resuelve con reintento), problemas intermitentes de red y agotamiento de cuota (que se libera tras una breve espera). Los bloqueos de filtro de seguridad no se reintentan porque indican violaciones de politica de contenido que no se resolvaran por repeticion; estos deben registrarse y sus prompts ajustarse manualmente.
Monitorear tu pipeline de lotes es igualmente importante para mantener la eficiencia de costos a lo largo del tiempo. Rastrea tres metricas clave: tasa de exito (objetivo superior al 85%), tiempo promedio de finalizacion (establece una linea base de tu carga de trabajo tipica) y costo por imagen utilizable (contabilizando reintentos). Un pico repentino en la tasa de fallos a menudo indica un problema de calidad de prompts o una degradacion del servicio, ambos requiriendo respuestas diferentes.
Si encuentras errores persistentes durante el procesamiento por lotes, nuestra guia de solucion de errores de Nano Banana cubre los modos de fallo mas comunes incluyendo el caso limite de 200-OK-pero-sin-imagen, falsos positivos del filtro de seguridad y manejo de limites de tasa. Los patrones clave a implementar mas alla de reintentos basicos son colas de mensajes muertos para solicitudes que fallan permanentemente, alertas cuando las tasas de fallo superan tu umbral aceptable (tipicamente 10-15%) y enrutamiento de respaldo automatico a laozhang.ai cuando las tasas de fallo de lotes se disparan.
Optimizacion de costos por volumen: 6 escenarios del mundo real
La estrategia optima de costos cambia dramaticamente segun tu volumen mensual de generacion de imagenes. Aqui hay seis escenarios concretos con recomendaciones especificas y proyecciones de costos mensuales, todos calculados usando resolucion 4K como linea base:
Escenario 1: Aficionado (menos de 100 imagenes/mes) — Tu mejor opcion es el nivel gratuito de Google AI Studio, que proporciona aproximadamente 50 solicitudes de generacion de imagenes por dia sin costo. Para imagenes adicionales ocasionales, la API Standard a $0.24 por imagen mantiene el gasto mensual por debajo de $25 sin sobrecarga de infraestructura. No te molestes con la Batch API a esta escala: la complejidad de configuracion no vale la pena por los ahorros en volumenes tan pequenos. Costo mensual: $0-24.
Escenario 2: Creador (500 imagenes/mes) — A este volumen, la Batch API comienza a tener sentido. Procesar 500 imagenes a traves de la Batch API a $0.12 cada una cuesta $60 al mes, comparado con $120 con la API Standard, un ahorro limpio de $60. Sin embargo, si necesitas generacion en tiempo real para trabajo de diseno iterativo, laozhang.ai a $0.05 por imagen reduce el total a solo $25 al mes. La eleccion depende de si puedes agrupar tu trabajo en sesiones de generacion programadas. Costo mensual: $25-60.
Escenario 3: Freelance (2,000 imagenes/mes) — Aqui es donde las estrategias hibridas se vuelven optimas. Genera tu contenido planificado (60-70% del volumen) a traves de la Batch API a $0.12 por imagen, y enruta las solicitudes urgentes de clientes (30-40% del volumen) a traves de laozhang.ai a $0.05 por imagen. El costo combinado resulta en aproximadamente $0.077 por imagen, o $154 al mes. Comparado con $480 en la API Standard, eso es una reduccion del 68%. Costo mensual: $100-154.
Escenario 4: Pequena empresa (5,000 imagenes/mes) — Con 5,000 imagenes, el precio fijo de $0.05 de laozhang.ai se vuelve extremadamente competitivo para todo el volumen: $250 al mes en total, con procesamiento en tiempo real y sin complejidad de flujo de trabajo por lotes. Compara eso con $600 para la Batch API o $1,200 para la API Standard. Incluso combinar la Batch API ($0.12) con laozhang.ai costaria mas que usar laozhang.ai exclusivamente en este nivel. La ventaja de simplicidad es significativa: un solo endpoint de API, facturacion predecible, sin gestion de trabajos asincronos. Costo mensual: $250.
Escenario 5: Agencia (20,000 imagenes/mes) — Las agencias se benefician del enfoque hibrido completo. Enruta el 70% del volumen (14,000 imagenes) a traves de la Batch API a $0.12 para trabajo programado de catalogos y campanas, y el 30% restante (6,000 imagenes) a traves de laozhang.ai para generacion en tiempo real orientada al cliente. Total: $1,680 + $300 = $1,980 al mes. Alternativamente, enrutar todo a traves de laozhang.ai cuesta $1,000, sustancialmente menos. La Batch API solo gana en base por imagen; la ventaja de volumen total va a los proveedores de terceros con tarifa plana. Costo mensual: $1,000-1,980.
Escenario 6: Empresa (100,000+ imagenes/mes) — A esta escala, cada centavo por imagen importa enormemente. Una reduccion de $0.01 ahorra $1,000 mensuales. La arquitectura optima usa enrutamiento escalonado: Batch API (resolucion 0.5K a $0.022/imagen) para miniaturas y previsualizaciones no criticas, laozhang.ai ($0.05/imagen) para generacion de grado produccion, y API Standard solo para funciones en tiempo real orientadas al usuario. Con una distribucion 50/40/10, el costo combinado alcanza aproximadamente $0.035 por imagen, o $3,500 al mes, comparado con $24,000 en la API Standard 4K. Eso son $20,500 en ahorros mensuales, o $246,000 anuales. Costo mensual: $3,500-5,000.
| Escenario | Volumen mensual | Mejor estrategia | Costo mensual | vs Standard |
|---|---|---|---|---|
| Aficionado | <100 | Nivel gratuito + Standard | $0-24 | Linea base |
| Creador | 500 | Batch o laozhang.ai | $25-60 | -50 a -79% |
| Freelance | 2,000 | Hibrido (Batch + laozhang) | $100-154 | -68% |
| PYME | 5,000 | laozhang.ai tarifa plana | $250 | -79% |
| Agencia | 20,000 | laozhang.ai o Hibrido | $1,000-1,980 | -58 a -79% |
| Empresa | 100K+ | Enrutamiento escalonado | $3,500-5,000 | -79 a -85% |
Estrategias avanzadas de optimizacion de costos

Mas alla de elegir entre la Batch API y la API Standard, varias estrategias avanzadas pueden reducir aun mas tu costo por imagen. Estas estrategias se apilan: aplicar todas ellas compone los ahorros de forma multiplicativa en lugar de aditiva.
La adecuacion de resolucion es la optimizacion mas simple que la mayoria de los equipos pasa por alto. No todas las imagenes necesitan resolucion 4K. Las publicaciones de redes sociales se muestran a 1080x1080 pixeles en la mayoria de las plataformas, las miniaturas de blogs se renderizan a 600x400, y las imagenes de email marketing raramente superan 800x600. Generar estas a resolucion 4K y luego reducirlas desperdicia el 44% de tu costo por imagen. Adecua tu resolucion de generacion al contexto de visualizacion real: usa 1K para redes sociales y miniaturas, 2K para imagenes hero web y listados de productos, y reserva 4K exclusivamente para materiales de impresion, pantallas de gran formato y portafolios. Un equipo que genera 5,000 imagenes mensuales con una distribucion tipica de 60% social/web (1K), 30% producto (2K) y 10% premium (4K) reduce su costo promedio por imagen de $0.24 a aproximadamente $0.15, una reduccion del 37% antes de cualquier otra optimizacion.
La ingenieria de prompts para eficiencia de costos reduce el desperdicio mejorando tu tasa de exito en el primer intento. La idea clave es que prompts mas cortos y precisos no solo cuestan menos tokens de entrada sino que tambien producen resultados mas predecibles. Reemplaza descripciones vagas como "una cocina moderna bonita" con parametros especificos: "una cocina minimalista con encimeras de marmol blanco, accesorios negro mate, una sola lampara colgante, toma a nivel de ojos, luz natural desde la izquierda, fotorrealista." Los prompts estructurados con instrucciones explicitas de estilo, iluminacion, angulo de camara y composicion consistentemente logran tasas de exito del 90%+ en el primer intento comparado con 60-70% para prompts vagos. A escala, esta mejora del 20-30% en la tasa de exito se traduce directamente en un 20-30% menos de llamadas API desperdiciadas.
El almacenamiento en cache y deduplicacion de solicitudes evita pagar dos veces por la misma imagen. Si tu aplicacion genera imagenes de productos con variantes de colores o fondos, almacena en cache la generacion base y modifica programaticamente en lugar de regenerar desde cero. Implementa una clave de cache basada en hash sobre el texto del prompt: antes de enviar cualquier nueva solicitud, verifica si un prompt identico o casi identico ha sido procesado en las ultimas 24-48 horas.
La implementacion es directa: normaliza el texto del prompt (minusculas, recortar espacios en blanco, ordenar parametros de estilo), genera un hash MD5 o SHA-256, y verifica contra un simple almacen clave-valor (Redis, SQLite, o incluso un archivo JSON para operaciones mas pequenas). Cuando ocurre un acierto de cache, sirve la imagen almacenada inmediatamente: cero costo de API, cero latencia. Para aplicaciones con cualquier grado de repeticion de prompts (variantes de pruebas A/B, actualizaciones de plantillas estacionales, versiones multilingues del mismo visual), el almacenamiento en cache por si solo puede reducir las llamadas totales a la API entre un 15-40%.
Considera tambien implementar coincidencia difusa para prompts casi duplicados. Dos prompts que difieren solo en una frase menor ("un coche deportivo rojo en una autopista" vs "un coche deportivo rojo conduciendo por una autopista") probablemente produciran resultados visualmente similares. Un umbral de similitud del 95% en embeddings de prompts puede capturar estos casi duplicados y servir resultados en cache, reduciendo aun mas las llamadas API innecesarias. El esfuerzo de ingenieria incremental para el almacenamiento en cache difuso es minimo comparado con los ahorros de costos que genera a escala, particularmente para aplicaciones de e-commerce donde las descripciones de productos siguen patrones formulaicos.
La arquitectura de enrutamiento hibrido es la estrategia mas poderosa, combinando todos los niveles de precios disponibles en un unico sistema inteligente. La implementacion es directa: una funcion de enrutamiento que evalua cada solicitud contra reglas de prioridad, volumen y costo:
pythondef route_request(prompt, priority="normal", resolution="2K"): """Route image generation to the most cost-effective provider.""" if priority == "urgent": # Real-time via laozhang.ai: $0.05/image, any resolution return generate_via_laozhang(prompt, resolution) elif priority == "normal": # Queue for batch processing: 50% off return queue_for_batch(prompt, resolution) else: # Low priority: use lowest resolution batch return queue_for_batch(prompt, "1K")
Al enrutar las solicitudes urgentes (tipicamente 20-30% del volumen) a traves de laozhang.ai y programar el resto via Batch API, el costo combinado por imagen baja a aproximadamente $0.035-0.05, una reduccion del 79-85% respecto al precio estandar 4K. Para equipos listos para explorar el panorama completo de modelos de generacion de imagenes y precios, nuestra comparativa de generadores de imagenes IA lideres cubre como Nano Banana Pro se compara con FLUX, GPT Image y otras alternativas.
Alternativas de API de terceros comparadas
Mientras que la Batch API de Google ofrece la ruta oficial mas rentable, los proveedores de API de terceros pueden ofrecer ahorros aun mayores al agregar demanda y optimizar costos de infraestructura. Aqui esta como se comparan las principales alternativas para acceso a Nano Banana Pro:
| Proveedor | Precio/Imagen | Resolucion | Latencia | Ventaja clave |
|---|---|---|---|---|
| Oficial Standard | $0.134-0.24 | 1K-4K | 8-12s | Soporte directo de Google, SLA |
| Oficial Batch | $0.067-0.12 | 1K-4K | Hasta 24h | 50% desc., cuotas mas altas |
| laozhang.ai | $0.05 | Todas las resoluciones | 8-15s | Tarifa plana, sin recargo por resolucion |
| Kie.ai | ~$0.02 | 1K-4K | 10-20s | Sistema de creditos con bonificaciones |
| PiAPI | $0.105-0.18 | 1K-4K | 8-15s | Acceso multi-modelo |
Entre estas opciones, laozhang.ai destaca para casos de uso en produccion por su combinacion de precios fijos y procesamiento en tiempo real. El costo de $0.05 por imagen se aplica uniformemente independientemente de si solicitas resolucion 1K o 4K, eliminando la necesidad de optimizar la resolucion por razones de costo. Esta simplicidad de precios reduce la sobrecarga cognitiva y hace que la prevision de costos sea trivial: multiplica tu volumen esperado por $0.05 y tendras tu factura mensual exacta.
La interfaz API de la plataforma sigue el formato estandar compatible con OpenAI, lo que significa que la migracion desde la API oficial de Google requiere cambios minimos de codigo. La diferencia principal de integracion es la URL del endpoint y el encabezado de autenticacion: los formatos de solicitud y respuesta se mantienen compatibles. Para equipos que ya usan laozhang.ai para modelos de texto (Claude, GPT-4o, DeepSeek), agregar generacion de imagenes es una extension natural sin cuentas adicionales ni complejidad de facturacion.
¿Cuando tiene mas sentido un proveedor de terceros que la Batch API de Google? El punto de quiebre ocurre cuando tu mezcla de urgencia se inclina hacia el tiempo real. Si mas del 40% de tus solicitudes de generacion de imagenes necesitan resultados en minutos en lugar de horas, el descuento del 50% de la Batch API no puede compensar el enrutamiento de la porcion urgente a traves de la API Standard a precio completo. En ese escenario, ejecutar todo a traves de laozhang.ai a $0.05 por imagen ofrece un costo total menor que una division Batch/Standard, siendo ademas mas simple de implementar y mantener.
El proceso de integracion con laozhang.ai sigue un patron familiar para desarrolladores que han trabajado con APIs compatibles con OpenAI. Despues de registrarte y obtener una clave API, el unico cambio de codigo requerido es actualizar la URL base y el encabezado de autenticacion. El formato de payload de solicitud para generacion de imagenes refleja la estructura estandar de la API de Gemini, asi que las plantillas de prompts existentes y las configuraciones de generacion se transfieren directamente sin modificacion. Los nuevos usuarios reciben un saldo de credito gratuito para probar el servicio antes de comprometerse con el uso de pago, y la plataforma soporta tanto prepago basado en creditos como modelos de facturacion mensual. La documentacion y guias de integracion estan disponibles en docs.laozhang.ai.
Para equipos evaluando multiples proveedores de terceros, los diferenciadores clave mas alla de los precios son la fiabilidad del uptime, la latencia geografica (particularmente importante para usuarios de Asia-Pacifico) y la amplitud de modelos soportados. Un proveedor que ofrece Nano Banana Pro junto con modelos de texto como Claude y GPT-4o consolida tu infraestructura de IA en una unica relacion de facturacion, reduciendo la sobrecarga de gestion de proveedores. Este beneficio de consolidacion se vuelve cada vez mas valioso a medida que las organizaciones escalan su uso de IA a traves de multiples tipos de modelos y casos de uso.
Preguntas frecuentes
¿La Batch API produce imagenes de menor calidad que la API Standard?
No. La Batch API usa el modelo identico Gemini 3 Pro Image con los mismos parametros y pesos. La unica diferencia es el tiempo de procesamiento: las solicitudes por lotes se ponen en cola y se procesan durante periodos de menor demanda, que es como Google financia el descuento del 50%. La calidad de imagen, resolucion, precision del renderizado de texto y adherencia al estilo son todos identicos entre los modos de procesamiento por lotes y estandar.
¿Cuanto tardan realmente en completarse los trabajos de la Batch API?
Google garantiza la finalizacion dentro de 24 horas, pero los tiempos de finalizacion reales son tipicamente mucho mas rapidos. Basandose en informes de la comunidad y nuestras pruebas, los lotes pequenos (menos de 100 imagenes) generalmente se completan dentro de 1-2 horas. Los lotes medianos (100-1,000 imagenes) tipicamente terminan en 2-6 horas. Los lotes muy grandes (1,000+ imagenes) pueden tomar 6-12 horas. Los tiempos de procesamiento pueden variar segun la carga actual de servidores de Google, pero raramente hemos visto trabajos acercarse al limite de 24 horas.
¿Puedo usar la Batch API para todas las resoluciones incluyendo 4K?
Si. La Batch API soporta todas las mismas resoluciones que la API Standard: 1K (1024x1024), 2K (2048x2048) y 4K (4096x4096). El descuento del 50% se aplica igualmente en todas las resoluciones, haciendo que el procesamiento por lotes de 4K ($0.12/imagen) sea mas barato que incluso el procesamiento estandar de 1K ($0.134/imagen).
¿Que sucede si algunas imagenes en un trabajo por lotes fallan?
Los trabajos por lotes procesan cada solicitud independientemente. Si solicitudes individuales fallan (debido a bloqueos del filtro de seguridad, prompts invalidos u otros errores), las solicitudes restantes continuan procesandose normalmente. La respuesta del trabajo por lotes incluye informacion de estado por solicitud, permitiendote identificar y reintentar solo las solicitudes fallidas. No se te cobra por solicitudes fallidas que no producen salida.
¿Es seguro usar laozhang.ai para aplicaciones de produccion?
laozhang.ai opera como un servicio proxy de API que enruta solicitudes a la infraestructura oficial del modelo de Google. Las imagenes son generadas por el mismo modelo Gemini 3 Pro Image; laozhang.ai no ejecuta su propia inferencia. Para uso en produccion, las consideraciones clave son el SLA de uptime (consulta el estado actual en docs.laozhang.ai), las politicas de manejo de datos y si tus requisitos de cumplimiento permiten el enrutamiento de API a traves de terceros. Muchos equipos de desarrollo y pequenas y medianas empresas usan servicios proxy como este sin problemas, aunque las empresas con requisitos estrictos de gobernanza de datos deben evaluar contra sus politicas especificas.
Proximos pasos
El camino desde el gasto actual hasta los costos optimizados sigue una progresion clara. Comienza con la estrategia que coincida con tu situacion actual, luego agrega optimizaciones adicionales a medida que tu volumen crece.
Si generas menos de 500 imagenes mensuales, comienza con la Batch API: es el cambio mas simple con el retorno garantizado mas alto (50% de ahorro). Configura el flujo de trabajo en Python de la seccion de implementacion anterior, ejecuta tu primer trabajo por lotes y verifica que el modelo de procesamiento asincrono se ajusta a tu flujo de trabajo. La configuracion completa tipicamente toma menos de una hora, y veras ahorros en tu primer lote. Comienza con un lote de prueba pequeno de 10-20 imagenes para validar el flujo de trabajo antes de comprometer todo tu volumen.
Para volumenes superiores a 1,000 imagenes mensuales, evalua laozhang.ai junto con la Batch API. Ejecuta un piloto de dos semanas donde enrutas el 50% del trafico a traves de cada servicio y comparas costos totales, distribuciones de latencia y calidad de imagen. La mayoria de los equipos encuentran que el precio fijo de $0.05 ofrece mejores economias para cargas de trabajo de urgencia mixta. El proceso de migracion es directo: laozhang.ai usa un formato de API compatible con OpenAI, asi que esencialmente estas cambiando una URL de endpoint y una clave API en tu codigo existente. Rastrea tu costo combinado por imagen durante el piloto para establecer tu linea base para optimizacion futura.
A escala (5,000+ imagenes mensuales), implementa la arquitectura completa de enrutamiento hibrido. Mapea tus solicitudes de generacion de imagenes en niveles de prioridad, asigna cada nivel al proveedor mas rentable y monitorea el costo combinado por imagen semanalmente. Construye un panel simple que rastree imagenes generadas por proveedor, tasas de exito, latencia promedio y costo por imagen utilizable. Esta visibilidad es esencial para la optimizacion continua: puedes encontrar que desplazar un 10% mas de volumen de Batch a laozhang.ai durante periodos de alta demanda mejora tanto la fiabilidad como el costo.
La diferencia entre un pipeline no optimizado a $0.24 por imagen y un enfoque hibrido completamente optimizado a $0.035 por imagen puede significar la diferencia entre un presupuesto de generacion de imagenes de $24,000 y $3,500 al mes, ahorros que se componen en seis cifras anualmente. Las estrategias en esta guia representan el estado actual de la optimizacion de costos para Nano Banana Pro en marzo de 2026. A medida que Google continua evolucionando su estructura de precios y nuevos proveedores de terceros entran al mercado, los numeros especificos cambiaran, pero los principios fundamentales (lotes para volumen masivo, terceros para volumen, hibrido para ahorro maximo) seguiran siendo aplicables independientemente de los niveles de precios exactos.