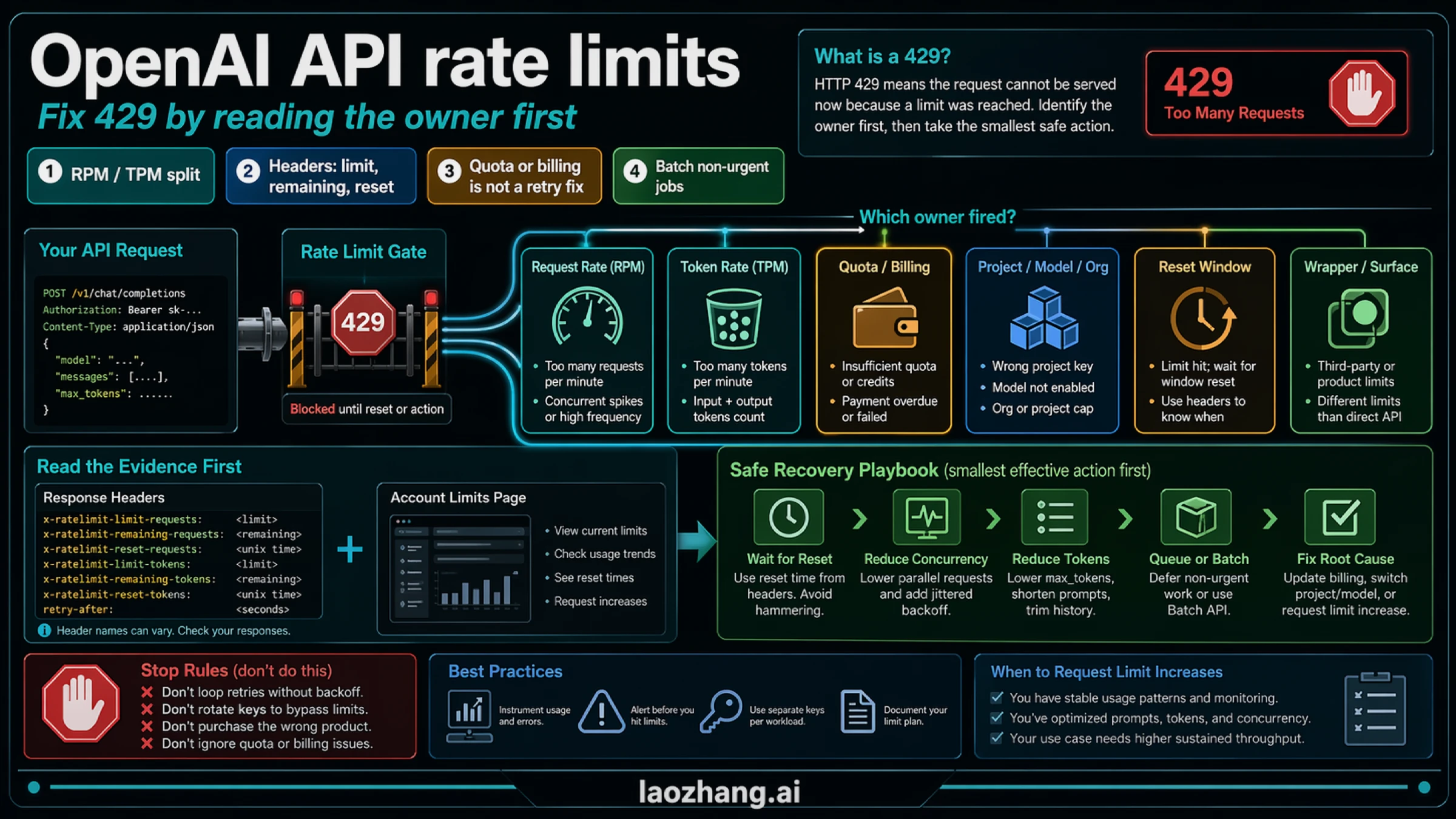
An OpenAI API 429 is not a prompt to rotate keys, retry harder, or upgrade the wrong product surface. It means the current API route hit a request, token, quota, billing, project, model, wrapper, or reset-window owner, and the fix depends on which owner fired. Start by reading the x-ratelimit-* headers and the account Limits page; then choose the smallest safe action: wait for reset, reduce concurrency, cap token output, queue or batch non-urgent work, repair billing or project scope, or request higher limits with evidence. Stop treating it as a retry problem when quota, billing state, or a non-API ChatGPT/Codex limit is the real owner. Exact live limits are account facts, so treat official OpenAI docs and the Limits page as the contract boundary instead of copying stale universal numbers.
TL;DR
| Question | Short answer |
|---|---|
What does OpenAI API 429 usually mean? | Your current API route exceeded a request, token, quota, billing, scope, or reset-window limit. |
| What is the first check? | Read the response headers and compare them with the account Limits page. |
| What are the most common technical owners? | Request rate, token rate, burst traffic, oversized completions, and wrong project or model scope. |
| What are the most common non-code owners? | Insufficient quota, billing problems, expired trial state, or using the wrong product surface. |
| What should you do before requesting higher limits? | Lower concurrency, add exponential backoff with jitter, reduce expected output, and move non-urgent work to queues or Batch API. |
| What should you not do blindly? | Rotate keys, spam retries, assume credits equal throughput, or treat ChatGPT/Codex plan limits as Platform API rate limits. |
Start with the owner, not the retry loop
Most developers do not lose time because they do not know what rate limits are. They lose time because 429 looks like one problem while OpenAI actually exposes several different limit owners. The official Rate limits guide makes the contract clear if you read it carefully: your account has live limits in the Limits page, usage tiers can expand those limits, response headers can tell you what was consumed and when the window resets, and mitigation starts with backoff instead of brute-force resend.
That means the useful first question is not "What is the OpenAI API rate limit?" It is "Which limit fired on this request?" A request-rate problem and a token-rate problem can both surface as 429, but they lead to different fixes. A quota or billing problem can also look like a rate problem from the outside, but it will not be solved by backoff. A wrong project, wrong organization, or wrong model route can make the request look rate-limited even when the deeper issue is scope.
If you want one operator rule to keep in your head, use this:
- Read the owner.
- Read the reset signal.
- Apply the smallest safe fix.
- Escalate only after you can prove the traffic is stable and the route is correct.
That order beats the most common bad instincts:
- retrying faster,
- rotating keys,
- buying credits without checking throughput,
- or upgrading a ChatGPT or Codex plan that does not own Platform API limits in the first place.
For the adjacent scope question, use our organization and project setup guide. If your confusion is really about consumer plans or Codex product limits, the correct sibling pages are OpenAI Codex usage limits and Codex API key vs subscription, not this Platform API runbook.
What OpenAI rate limits actually measure
OpenAI's first-party docs describe rate limits as multi-dimensional, not as one universal number. The practical dimensions are:
- Requests per minute. Too many calls in a short window.
- Tokens per minute. Too much prompt plus output volume, even when request count looks modest.
- Usage tier. Your account tier influences how much headroom is available.
- Live account limits. The current source of truth is the Limits page in your account settings, not a copied table from an old tutorial.
- Reset signals. Headers can tell you how long to wait before the window reopens.
That is why stale "OpenAI allows X requests per minute" tables are unsafe as primary guidance. They flatten a live account boundary into a universal statement. The docs support a safer model: use public docs for definitions, headers, tiers, and mitigation patterns, but use the Limits page for the actual live ceiling on your account.
The distinction between request and token pressure matters more than many guides admit. RPM problems usually come from too many parallel calls, tight loops, or aggressive retries. TPM problems often come from long prompts, oversized history windows, large outputs, or a queue of requests that each ask for more tokens than the workload really needs. If you do not separate those two, you may shrink concurrency when the real problem is completion size, or cap output when the real problem is a burst of simultaneous requests.
One more subtlety from the Help Center matters during incidents: short bursts can fail inside quantized windows even if your average per-minute math looks acceptable. In other words, "I am under the per-minute budget on paper" does not prove your instantaneous traffic shape is safe.
Read the response before you change anything
OpenAI's Cookbook and rate-limit docs both push toward the same operational habit: read the response first, because failed retries still count against your budget. Blind repetition turns one limit event into a cooldown spiral.
The headers to look for are the ones OpenAI documents in the rate-limit guide:
x-ratelimit-limit-requestsx-ratelimit-remaining-requestsx-ratelimit-reset-requestsx-ratelimit-limit-tokensx-ratelimit-remaining-tokensx-ratelimit-reset-tokens
If those headers are present, they tell you more than the error message alone:
| Signal | What it usually tells you | First action |
|---|---|---|
remaining-requests near zero | Request frequency is too high | Lower concurrency, smooth bursts, and back off |
remaining-tokens near zero | Prompt plus output budget is too large | Cut prompt size, lower expected output, or batch work |
| Reset header is short | The route is probably fine, but you need to wait | Sleep until reset plus jitter |
| Limits page shows low headroom | The account or route ceiling is the constraint | Optimize first, then request increase if needed |
| Headers look normal but the request still fails | Scope, billing, wrapper, or wrong endpoint may be involved | Check project, org, model, and product surface |

In practice, the most useful move is to log the response in a form you can compare across attempts: status code, error body, request path, model, project or organization context, and any x-ratelimit-* values you received. That gives you incident evidence instead of memory.
If you need a minimal pattern, the logic looks like this:
tsconst resetRequests = res.headers.get("x-ratelimit-reset-requests"); const resetTokens = res.headers.get("x-ratelimit-reset-tokens"); const remainingRequests = res.headers.get("x-ratelimit-remaining-requests"); const remainingTokens = res.headers.get("x-ratelimit-remaining-tokens"); const owner = remainingRequests === "0" ? "requests" : remainingTokens === "0" ? "tokens" : "unknown"; // Use the later reset if both request and token windows matter.
You do not need perfect code on the first pass. You need enough evidence to avoid choosing the wrong branch.
Diagnose the owner
Once you have the response and the Limits page in front of you, the next job is classification.
1. Request-rate owner
This is the classic burst problem. The request count, parallelism, or retry loop is too aggressive for the current route. Symptoms usually include low or zero remaining-requests, a short reset window, and a workload pattern with many simultaneous calls. The fix is usually traffic shaping, not billing.
2. Token-rate owner
This owner is often missed because the application is not making that many requests. But each request is expensive. Long chat history, oversized system prompts, high max_tokens, or unbounded completion size can consume TPM faster than expected. OpenAI's docs explicitly note that large response caps can affect accounting, so keeping the expected output close to reality is not just a cost optimization. It is a throughput control.
3. Quota or billing owner
This is where retries become actively unhelpful. If the account is out of usable quota, has a billing issue, or the payment route is not healthy, you are not dealing with a simple per-minute event. The right move is to verify the account state, credits, billing method, or trial status. If your question is really about account credits or trial boundaries, the relevant sibling page is OpenAI API free trial.
4. Project, organization, or model scope owner
The request can be syntactically fine and still be on the wrong route. A project may not have the same limit profile as another project. A model may have different availability or rate behavior. The wrong organization or wrong project can make the request look broken when the real problem is scope. This is one reason copied settings across environments are unreliable.
5. Wrong product surface owner
This confusion appears constantly in real incidents: developers mix OpenAI Platform API limits with ChatGPT, Codex, or wrapper-level limits. Those are different contracts. A ChatGPT upgrade does not automatically fix a Platform API 429. A Codex usage window is not the same thing as API throughput. A gateway or wrapper may impose its own limits even when the underlying model is OpenAI-compatible.
That distinction is not theoretical. It changes who owns the next step.
Fix traffic safely
Once you know the owner, use the smallest safe mitigation first. OpenAI's docs and Cookbook consistently point toward backoff with jitter, not immediate repeated resend.
The recovery ladder usually looks like this:
- Wait for the reset window if the route is otherwise correct.
- Lower concurrency if bursts are the main cause.
- Add exponential backoff with jitter so retries do not pile up on the same window edge.
- Cap expected output and trim unnecessary prompt material when tokens are the pressure point.
- Queue or batch non-urgent work instead of keeping everything on the synchronous path.
- Request higher limits only after the route, billing, and traffic shape are already correct.
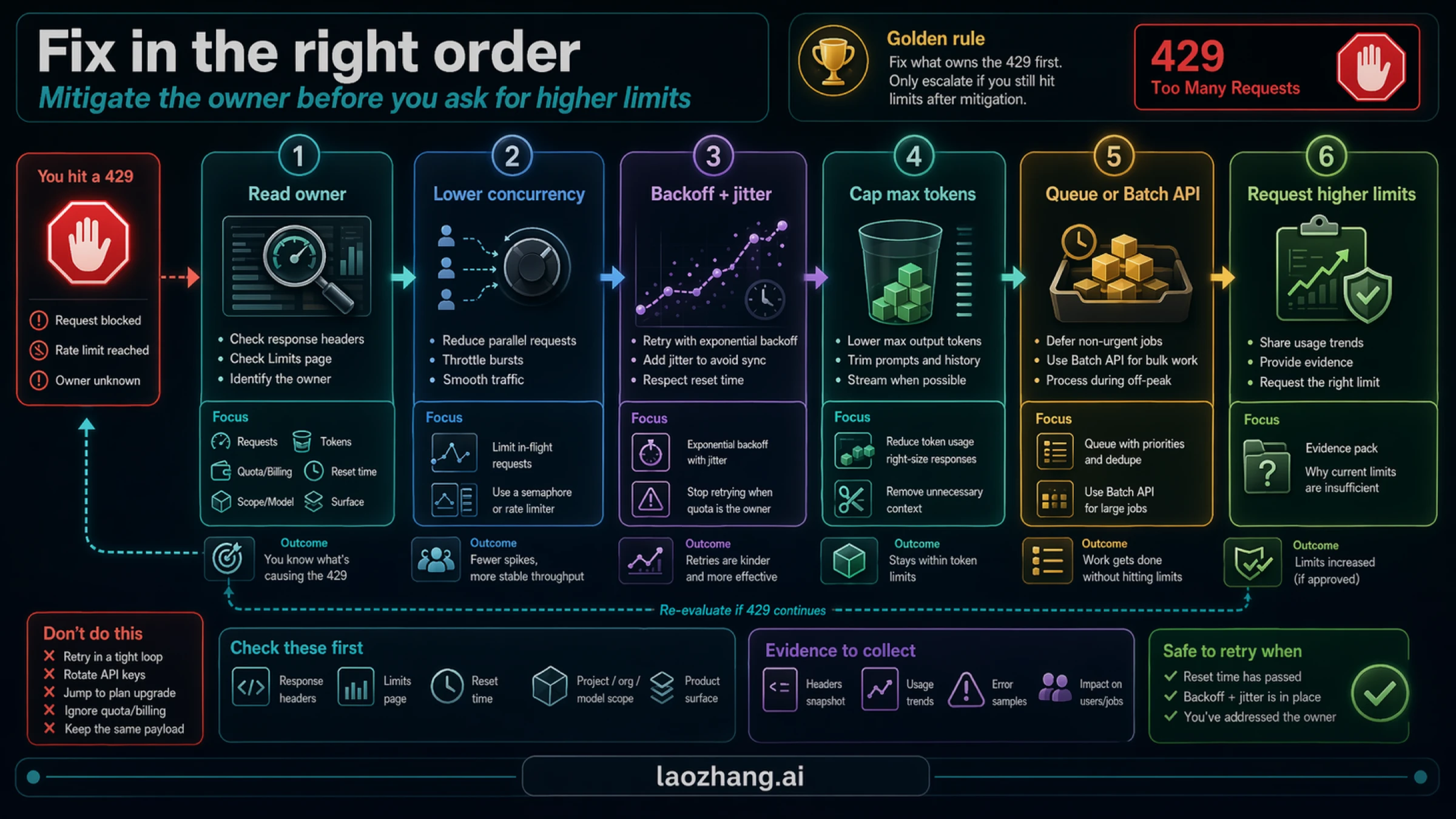
For code, the main mistake is to treat backoff as a decoration. It should be a real control path with jitter and stop conditions. A useful operator pattern is:
tsconst base = 500; // ms const max = 15000; for (let attempt = 0; attempt < 6; attempt += 1) { const wait = Math.min(max, base * 2 ** attempt); const jitter = Math.random() * 0.25 * wait; await sleep(wait + jitter); }
That snippet is not enough by itself, but it illustrates the principle. The retry path should get quieter, not louder, after every failure.
For TPM pressure, token trimming is often the cheapest fix. Lower max_tokens or the equivalent response-size cap if you are consistently asking for more output than you need. Shorten prompt history. Remove unused context blocks. If the workload is background processing, move it to a queue or the Batch API, which OpenAI explicitly positions as a better route for non-immediate work.
Increase throughput only after you have stable evidence
Many teams ask for higher limits too early. That is expensive in time and sometimes in money, and it hides whether the application would have stabilized with better traffic discipline.
Escalation makes sense when all of these are true:
- the route is correct,
- billing is healthy,
- the owner is known,
- retries are already bounded,
- prompt and output budgets are reasonable,
- and the workload still needs more sustained capacity.
That is where usage tier and limit increase requests matter. The public docs say usage tiers generally expand available limits as spend grows, and the Help Center points developers back to the Limits page for increase requests. That is the right contract boundary: public docs explain the system, but your actual increase path depends on the live account surface.
Before you request more throughput, collect evidence that makes the request legible:
- the model and endpoint,
- observed request and token pressure,
- reset behavior,
- concurrency profile,
- what optimization you already tried,
- and why Batch API or queueing is not enough.
That evidence helps in two ways. It supports any formal increase request, and it keeps your own team from asking for capacity when the underlying problem is still architecture.
Stop rules
Some moves are so common and so counterproductive that they deserve a separate checklist.
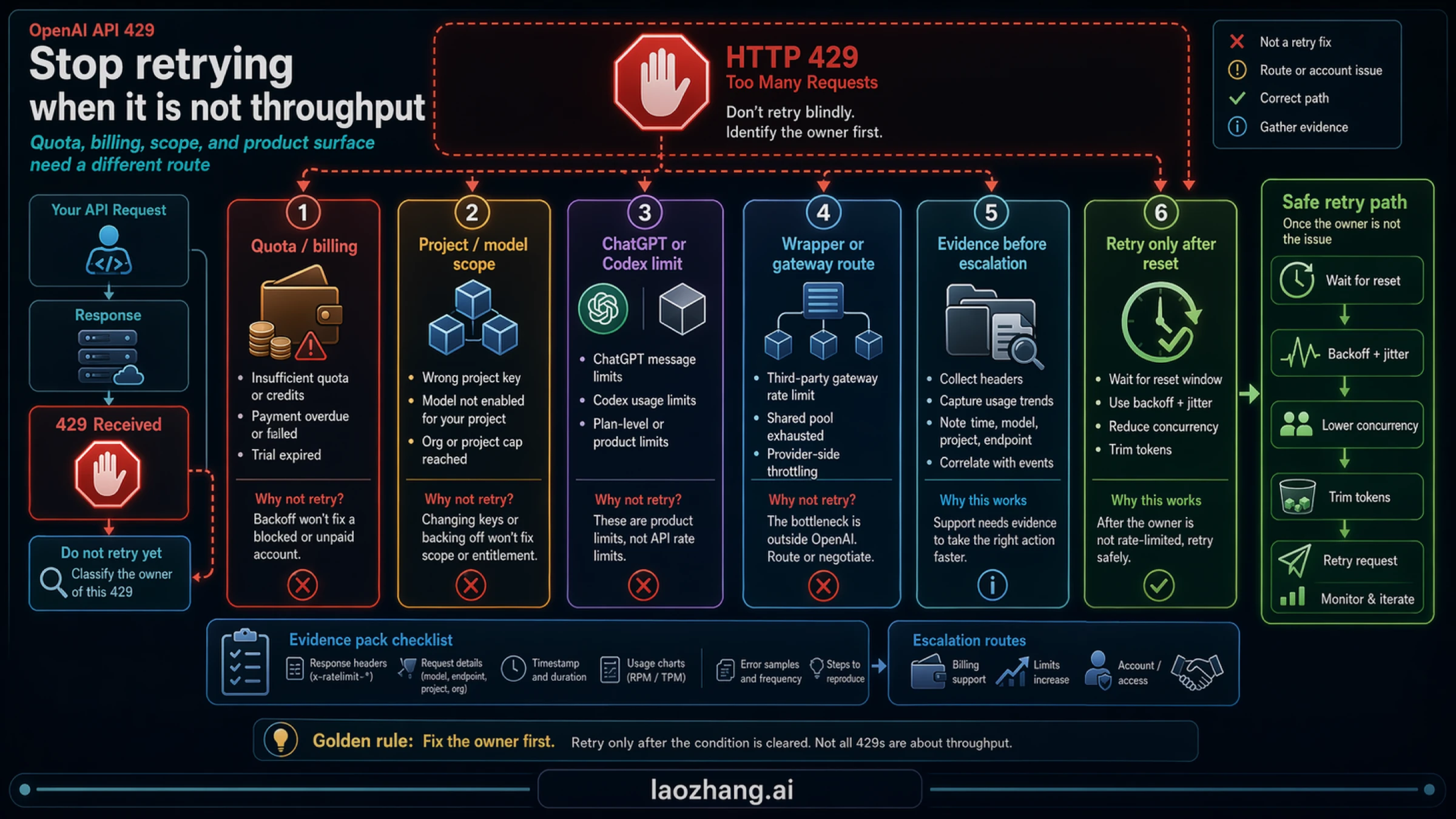
Do not default to these:
- Rotating keys. If the same account, project, or route owns the limit, key rotation is not a real fix.
- Buying credits without checking throughput. Credits can solve account-availability problems, but they do not automatically increase RPM or TPM.
- Upgrading ChatGPT or Codex plans to fix API limits. Those are separate surfaces from Platform API limits.
- Copying exact numbers from old tutorials. Exact live limits belong to the Limits page.
- Retrying blindly. Failed retries consume budget and extend the incident.
Use this mental split instead:
| If the problem is | Do this next |
|---|---|
| Request burst | Lower parallelism and add jitter |
| Token pressure | Trim prompt and output size |
| Short reset window | Wait and retry safely |
| Billing or quota | Repair account state |
| Wrong project or model | Correct scope and route |
| Non-API product limit | Leave the API article and switch surfaces |
That last row matters more than it looks. If your real question is "Why did Codex or ChatGPT stop accepting work?" then this is the wrong runbook. Switch to the route-owned surface instead of forcing everything through API terminology.
FAQ
What does OpenAI API 429 mean?
It means the current API route exceeded a request, token, quota, billing, scope, or reset-window boundary. Treat it as a classification problem first, not as a generic retry problem.
Where do exact current OpenAI API limits live?
In the account Limits page. Use the public docs for definitions, tier logic, and header names, but use the live account surface for the current ceiling on your route.
Do credits guarantee more throughput?
No. Credits help only when the real owner is quota or billing. They do not automatically fix request-rate or token-rate ceilings.
Can ChatGPT Plus, Pro, or Codex subscriptions fix Platform API rate limits?
No. Consumer plans and Codex product windows are separate contracts from Platform API throughput. Use the route that actually owns the problem.
When does Batch API help?
When the workload is non-immediate. If the job does not need synchronous responses, batching can reduce pressure on the live request path and is a better fit than keeping every task in a real-time loop.
When should I request higher limits?
After the route is correct, billing is healthy, backoff is in place, token budget is reasonable, and the workload still needs more sustained capacity.
The practical takeaway
The fastest honest fix for OpenAI API rate limits is not "retry later" or "upgrade something." It is "identify the owner, read the reset signal, and choose the smallest safe action."
That single shift resolves most 429 incidents faster than any copied limit table. If the owner is requests, smooth bursts. If the owner is tokens, shrink the payload. If the owner is billing or quota, repair the account state. If the owner is scope, move to the right project, organization, model, or endpoint. And if the workload is not urgent, stop forcing it through the synchronous path when Batch API or queueing would do the job better.