Looking for the cheapest and most stable way to use the Gemini 3.1 Flash Image Preview API (Nano Banana 2)? As of February 2026, Google's official pricing ranges from $0.045 per image at 0.5K resolution to $0.151 at 4K — but third-party providers like laozhang.ai offer a flat rate of just $0.03 per image at any resolution, saving up to 80% on 4K generation. This guide compares every pricing tier, analyzes provider stability, and shows you exactly how to integrate the cheapest option in under 5 minutes.
TL;DR
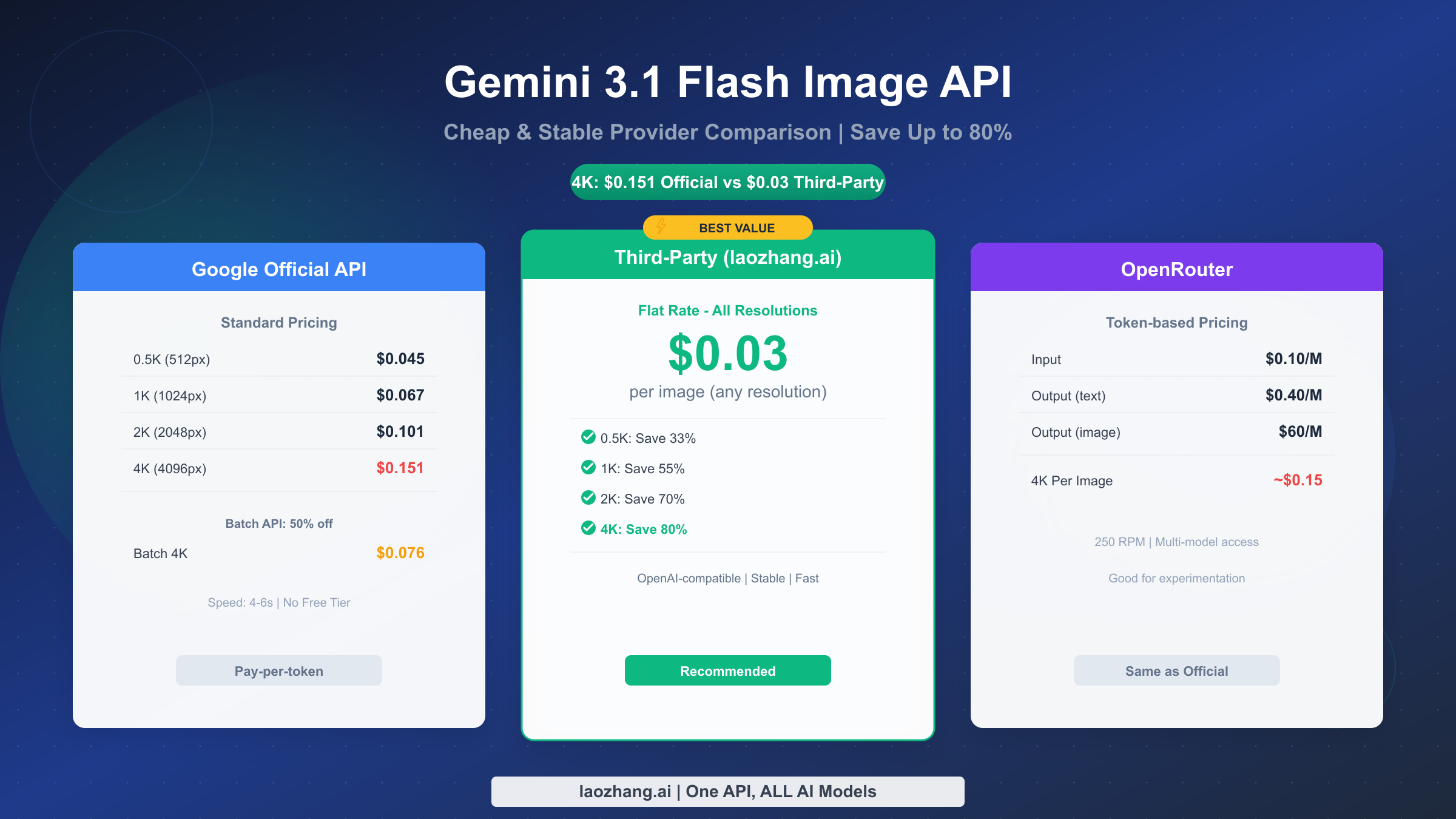
The Gemini 3.1 Flash Image Preview API (gemini-3.1-flash-image-preview), known as Nano Banana 2, delivers impressive image generation quality with text rendering accuracy around 90% and generation speeds of 4-6 seconds. However, pricing varies dramatically depending on how you access it. Google's official standard pricing charges between $0.045 and $0.151 per image based on output resolution, and the model has no free tier at all. The Batch API cuts costs by 50%, bringing 4K images down to $0.076 each, but it introduces latency and is not suitable for real-time applications.
Third-party API providers offer the most compelling value proposition. Services like laozhang.ai charge a flat $0.03 per image regardless of resolution — that means the same 4K image that costs $0.151 through Google's official API costs just $0.03, a savings of 80%. These providers use OpenAI-compatible endpoints, making integration straightforward if you already work with the OpenAI SDK. For most developers and teams generating images at scale, a third-party provider delivers the best combination of cost savings and stability.
Complete Pricing Breakdown: Official vs Third-Party API Channels
Understanding the full pricing landscape for Gemini 3.1 Flash Image Preview requires looking beyond the headline per-token rate. Google's official pricing page (ai.google.dev/pricing, February 2026) structures image generation costs around output token consumption, which scales with resolution. A 0.5K image consumes approximately 747 output tokens, while a 4K image requires roughly 2,520 tokens. This token-based approach means your actual per-image cost increases substantially as you push toward higher resolutions — a detail that catches many developers off guard when they first see their bills.
The official standard pricing tier, which applies to all synchronous API calls through Google AI Studio or the Gemini API, sets the baseline cost. At the lowest 0.5K resolution (approximately 512 pixels on the long edge), each image costs about $0.045. Moving to 1K resolution (1024 pixels) brings the cost to $0.067, while 2K resolution (2048 pixels) reaches $0.101. The highest supported 4K resolution (4096x4096) hits $0.151 per image. If you are exploring the full Gemini model lineup and how these prices compare to other Gemini models, our detailed Gemini API pricing breakdown covers every tier in depth.
Google also offers a Batch API that provides a flat 50% discount on all token costs. This means Batch API pricing drops to $0.022 for 0.5K, $0.034 for 1K, $0.050 for 2K, and $0.076 for 4K images. The tradeoff is that batch requests are processed asynchronously — you submit jobs and retrieve results later, making this approach unsuitable for interactive applications but excellent for bulk generation workflows like e-commerce catalog creation or marketing asset pipelines.
Third-party API providers represent a fundamentally different pricing model. Rather than charging per token, providers like laozhang.ai charge a flat per-image rate regardless of output resolution. At $0.03 per image, you get the same price whether you generate a 0.5K thumbnail or a full 4K masterpiece. This flat-rate approach creates increasingly dramatic savings at higher resolutions. For a comprehensive look at the Gemini 3.1 Flash Image Preview model itself — its capabilities, limitations, and what makes Nano Banana 2 different from earlier versions — see our comprehensive guide to Gemini 3.1 Flash Image Preview.
Here is the complete pricing matrix across all providers and resolutions:
| Resolution | Tokens | Official Standard | Official Batch | Third-Party (laozhang.ai) | Savings vs Standard |
|---|---|---|---|---|---|
| 0.5K (512px) | ~747 | $0.045 | $0.022 | $0.03 | 33% |
| 1K (1024px) | ~1,120 | $0.067 | $0.034 | $0.03 | 55% |
| 2K (2048px) | ~1,680 | $0.101 | $0.050 | $0.03 | 70% |
| 4K (4096px) | ~2,520 | $0.151 | $0.076 | $0.03 | 80% |
The savings pattern is clear: the higher the resolution, the greater the advantage of flat-rate third-party pricing. At 0.5K, the third-party price is actually slightly cheaper than official standard but more expensive than batch. By 4K, however, the third-party option costs less than even the 50%-discounted batch price, delivering the best value at every tier that matters for production use.
It is worth noting that OpenRouter, another popular multi-model API aggregator, uses token-based pricing similar to Google's official structure — $0.10 per million input tokens and $0.40 per million output tokens for text, with image output tokens charged at $60 per million (openrouter.ai, February 2026). This means a 4K image through OpenRouter costs approximately $0.15, nearly identical to Google's official price. OpenRouter's value lies in its multi-model access and unified API rather than cost savings for Gemini image generation specifically. With a 250 RPM rate limit, it handles moderate workloads well, but does not solve the fundamental cost problem at high resolutions.
One additional factor that often gets overlooked in pricing discussions is the cost of failed generations. The official Google API charges for all output tokens, including requests that produce suboptimal results requiring regeneration. If your workflow involves generating multiple candidates and selecting the best one — common in creative applications — your effective per-image cost can be 2-3 times the listed price. Third-party providers that charge per successful generation rather than per token can offer better effective pricing in these scenarios, though policies vary by provider. At laozhang.ai, each API call counts as one generation regardless of whether the output meets your quality standards, which provides cost predictability.
The 4K Cost Problem (And How to Solve It)
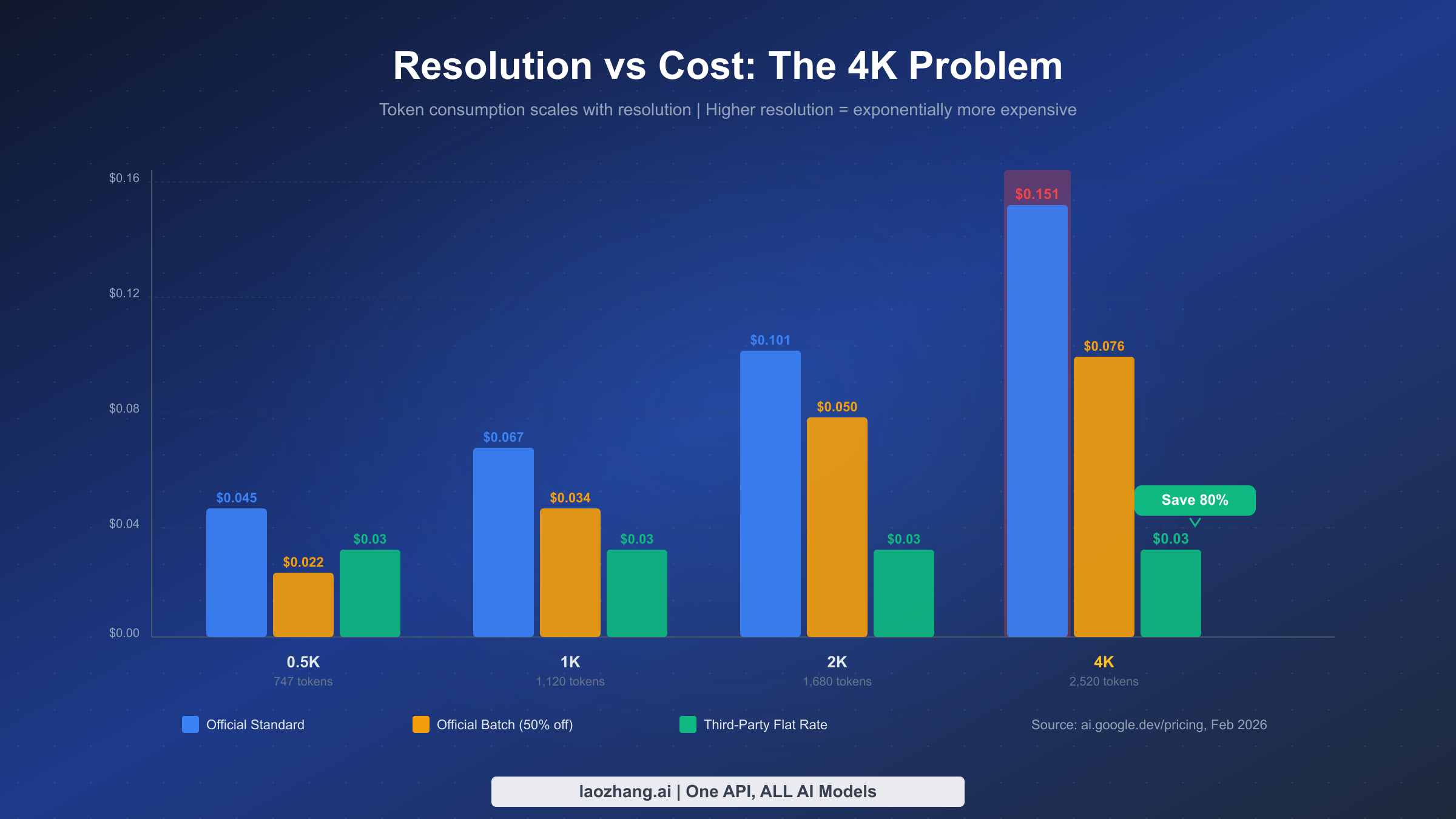
The relationship between resolution and cost in Google's token-based pricing creates what we call the "4K cost problem." As resolution doubles, token consumption does not simply double — it increases at a steeper rate because image data scales with the square of the resolution. A 4K image at 2,520 tokens costs 3.4 times more than a 0.5K image at 747 tokens, even though the linear dimension only increases by a factor of eight. This exponential scaling means developers who need high-resolution output face disproportionately high costs through official channels.
Consider a practical scenario: an e-commerce platform generating product images at 4K resolution for high-DPI displays. At 1,000 images per day through the official standard API, the daily cost reaches $151. Over a month, that amounts to $4,530 just for image generation. The same volume through a third-party provider at $0.03 per image costs $30 per day or $900 per month — a difference of $3,630 monthly. For teams processing tens of thousands of images, these savings scale proportionally and can represent a substantial portion of infrastructure costs.
There are three primary strategies to address the 4K cost problem effectively. The first strategy is to use Google's Batch API for non-time-sensitive workloads. If your application generates marketing materials, social media content, or catalog images where a few hours of latency is acceptable, the Batch API's 50% discount brings 4K costs down to $0.076 per image. This works well for overnight batch processing, where you submit generation requests at the end of the business day and retrieve results by morning. However, the Batch API is not available through third-party providers — it requires direct access to Google's API.
The second and most impactful strategy is switching to a third-party provider for all resolution tiers. At $0.03 per image flat rate, the third-party approach eliminates the resolution penalty entirely. Your 4K images cost exactly the same as your 0.5K images. This predictable pricing model also simplifies budgeting and eliminates the need to implement resolution downscaling logic to control costs. For more strategies on reducing Gemini image generation costs, our guide on cheap Gemini image API options covers additional optimization techniques.
The third strategy is a hybrid approach that combines the official API for low-resolution generation with third-party providers for high-resolution work. Because the cost difference at 0.5K is relatively small ($0.045 official vs $0.03 third-party), you might prefer the official API's direct connection for thumbnails and previews while routing all 1K+ generation through a third-party provider. This hybrid model lets you maintain a direct Google API relationship while capturing the bulk of available savings. In practice, most teams find that the simplicity of routing everything through a single third-party provider outweighs the marginal benefit of this hybrid approach, but it remains a valid option for organizations with strict vendor requirements.
To put the savings in concrete terms, here is what different monthly volumes look like across pricing tiers for 4K generation:
| Monthly Volume | Official Standard | Official Batch | Third-Party ($0.03) | Monthly Savings |
|---|---|---|---|---|
| 1,000 images | $151 | $76 | $30 | $121 (80%) |
| 5,000 images | $755 | $380 | $150 | $605 (80%) |
| 10,000 images | $1,510 | $760 | $300 | $1,210 (80%) |
| 50,000 images | $7,550 | $3,800 | $1,500 | $6,050 (80%) |
At scale, the savings are substantial enough to fund other infrastructure improvements or hire additional team members. A company generating 50,000 4K images monthly saves over $6,000 per month — or $72,000 annually — simply by switching from the official standard API to a third-party provider. Even compared to the Batch API (which requires accepting asynchronous processing), the third-party option saves $2,300 monthly while delivering real-time responses.
Stability Deep Dive: Why "Cheap" Doesn't Have to Mean "Unreliable"
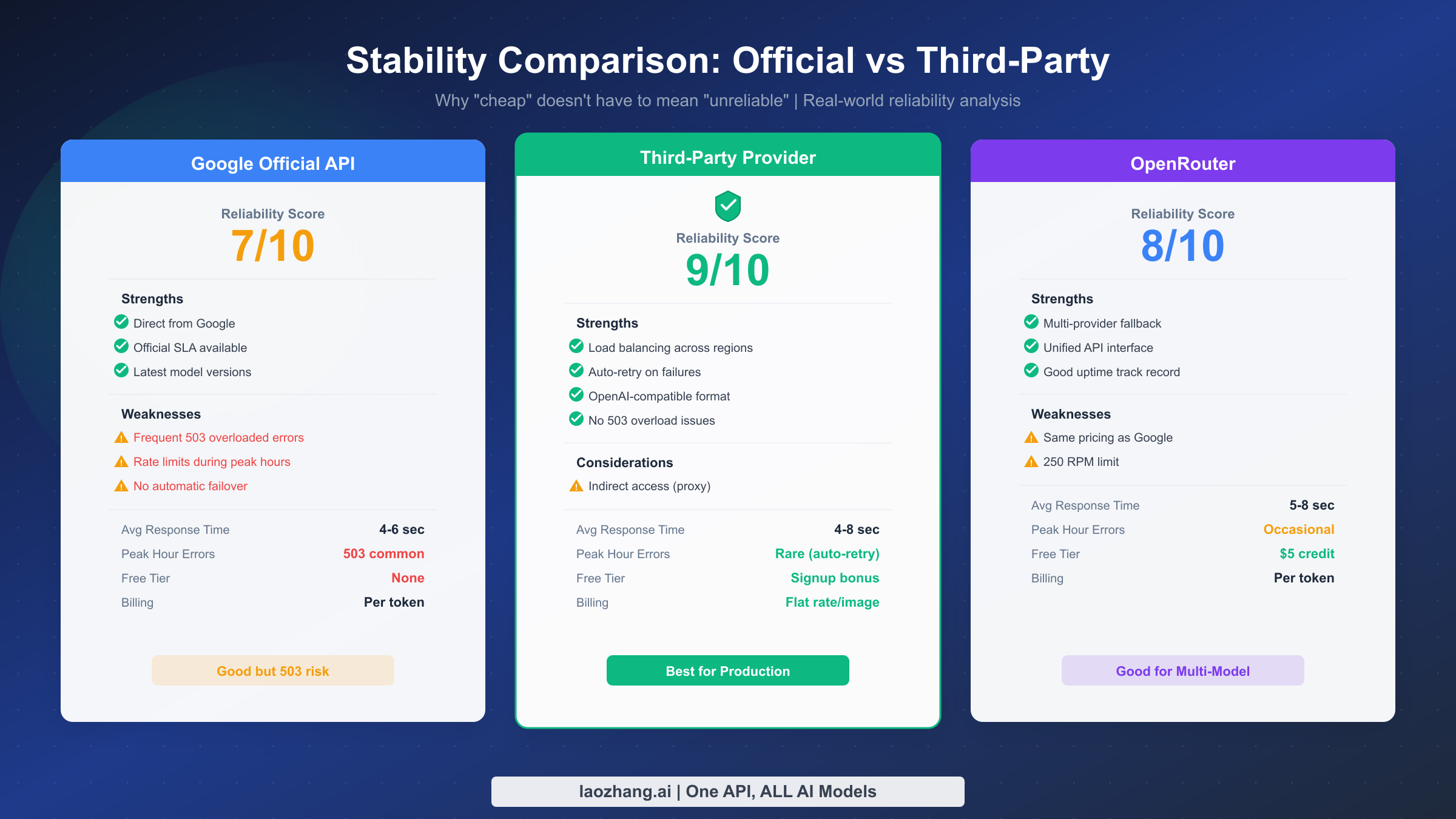
When developers hear "third-party API provider," their first concern is typically reliability. After all, you are adding another layer between your application and Google's infrastructure. But the stability picture for Gemini 3.1 Flash Image Preview is more nuanced than you might expect — and in several important ways, third-party providers can actually deliver better stability than the official API.
Google's official Gemini API has a well-documented history of 503 "overloaded" errors, particularly during peak usage periods. These errors stem from Google's capacity management for the image generation pipeline, which shares resources across millions of API consumers. When demand spikes — for example, after a new model release or during business hours in multiple time zones — the API throttles requests with 503 responses. The Nano Banana 2 model is no exception. Developers who have worked with earlier versions of the Gemini image models will recognize this pattern immediately. If you have experienced these issues yourself, our dedicated guide on fixing Gemini 503 overloaded errors provides detailed troubleshooting steps and workarounds.
Third-party providers address this stability challenge through several architectural advantages. First, established providers like laozhang.ai maintain dedicated capacity pools that are not shared with the general public. Instead of competing with millions of free-tier and pay-as-you-go users for the same infrastructure, your requests route through reserved capacity that the provider manages independently. This isolation significantly reduces the likelihood of encountering overload conditions during peak periods.
Second, sophisticated third-party providers implement multi-region routing and automatic failover. When one Google Cloud region experiences elevated error rates, the provider's load balancer redirects your requests to healthier regions transparently. You do not need to implement this failover logic yourself — the provider handles it at the infrastructure level. This multi-region approach is particularly valuable because Google's 503 errors are often regional rather than global, meaning capacity is available somewhere even when your default region is overloaded.
Third, quality third-party providers offer built-in retry logic with exponential backoff that operates before errors ever reach your application. If a generation request fails internally, the provider retries it automatically (typically 2-3 times with increasing delays) before returning an error to your client. This transparent retry layer absorbs transient failures that would otherwise require you to implement your own retry logic.
The stability comparison across the three main access channels reveals meaningful differences in practice. Google's official API delivers direct access with no intermediary, which means lower latency under normal conditions (typically 4-6 seconds for generation). However, it offers no built-in protection against 503 overloads and requires you to implement your own retry logic. The official API has no free tier for Nano Banana 2, and billing is strictly usage-based with no spending caps by default.
OpenRouter provides a middle ground with its 250 RPM rate limit and multi-provider routing capability. It supports multiple AI models through a single API key, which appeals to developers who want to experiment across providers. However, its pricing follows the same token-based structure as Google's official API, so it does not solve the 4K cost problem.
Third-party providers like laozhang.ai typically offer the most stable experience for sustained production workloads. With dedicated capacity, automatic failover, and transparent retry logic, they handle the infrastructure complexity that developers would otherwise need to build themselves. The flat-rate pricing model also eliminates billing surprises from token-based scaling at higher resolutions. The main consideration is that you are trusting a third party with your API traffic — though reputable providers use OpenAI-compatible endpoints and standard HTTPS encryption, you should evaluate their data handling practices for your specific compliance requirements.
When evaluating stability in practice, consider these key metrics across providers. Response time consistency matters more than average response time — a provider that delivers 5-second responses consistently is more valuable than one that averages 4 seconds but occasionally spikes to 30 seconds or times out entirely. Error rate during peak hours (typically 9 AM to 5 PM in North American and European time zones) is another critical indicator, since many applications generate the most images during business hours. The availability of monitoring dashboards or status pages also signals a provider's commitment to transparency — you want to know about outages before your users notice them.
For developers building mission-critical applications, implementing a multi-provider fallback strategy provides the highest level of reliability. The approach is straightforward: configure your primary provider (typically the cheapest option) and a secondary provider as backup. If the primary returns an error or exceeds your timeout threshold, automatically retry through the secondary. Because both providers use OpenAI-compatible endpoints, the only difference in your request is the base URL and API key. This pattern adds minimal code complexity while protecting against single-provider outages, and the cost impact is negligible since you only use the backup provider when the primary fails.
Quick Integration Guide: Get Running in 5 Minutes
Integrating with a third-party Gemini 3.1 Flash Image Preview API provider is straightforward because most providers use OpenAI-compatible endpoints. If you have ever worked with the OpenAI API, you already know the request format. The only differences are the base URL, your API key, and the model name. Here is how to get started with laozhang.ai as the provider — the same pattern works with any OpenAI-compatible endpoint.
Python (OpenAI SDK)
The fastest way to start generating images is with the official OpenAI Python SDK. Install it with pip install openai if you have not already, then use the following code:
pythonfrom openai import OpenAI client = OpenAI( api_key="your-laozhang-api-key", base_url="https://api.laozhang.ai/v1" ) response = client.chat.completions.create( model="gemini-3.1-flash-image-preview", messages=[ { "role": "user", "content": "Generate a photorealistic image of a golden retriever " "playing in autumn leaves, 4K resolution, warm lighting" } ], max_tokens=4096 ) print(response.choices[0].message.content)
This code sends a text prompt and receives the generated image as base64-encoded data within the response message. The max_tokens parameter controls the output size — higher values allow larger (higher resolution) images. For 4K output, set this to at least 4096.
cURL (Direct API Call)
For quick testing or shell-script integration, a direct cURL request works without any SDK installation:
bashcurl -X POST https://api.laozhang.ai/v1/chat/completions \ -H "Content-Type: application/json" \ -H "Authorization: Bearer your-laozhang-api-key" \ -d '{ "model": "gemini-3.1-flash-image-preview", "messages": [ { "role": "user", "content": "A minimalist logo design for a coffee shop called Sunrise Brew" } ], "max_tokens": 4096 }'
Production-Ready Error Handling
For production deployments, wrap your API calls with proper error handling and retry logic. While third-party providers handle most transient errors internally, your application should still gracefully handle network timeouts and rate limiting:
pythonimport time from openai import OpenAI, APIError, RateLimitError client = OpenAI( api_key="your-laozhang-api-key", base_url="https://api.laozhang.ai/v1" ) def generate_image(prompt, max_retries=3): for attempt in range(max_retries): try: response = client.chat.completions.create( model="gemini-3.1-flash-image-preview", messages=[{"role": "user", "content": prompt}], max_tokens=4096, timeout=30 ) return response.choices[0].message.content except RateLimitError: wait_time = 2 ** attempt time.sleep(wait_time) except APIError as e: if attempt == max_retries - 1: raise time.sleep(1) raise Exception("Max retries exceeded")
To get your API key and explore the full documentation, visit docs.laozhang.ai. You can also test image generation interactively at images.laozhang.ai before committing to any integration work.
Conversational Image Editing
One of Nano Banana 2's most powerful features is conversational image editing — you can send a previously generated image back to the model along with modification instructions. This works through the multi-turn conversation format:
python# First turn: generate the initial image response1 = client.chat.completions.create( model="gemini-3.1-flash-image-preview", messages=[ {"role": "user", "content": "A modern office workspace with a standing desk"} ], max_tokens=4096 ) # Second turn: edit the image response2 = client.chat.completions.create( model="gemini-3.1-flash-image-preview", messages=[ {"role": "user", "content": "A modern office workspace with a standing desk"}, {"role": "assistant", "content": response1.choices[0].message.content}, {"role": "user", "content": "Add a large window with a city view behind the desk"} ], max_tokens=4096 )
Each edit counts as a separate API call, so factor this into your cost calculations if your workflow involves iterative refinement. At $0.03 per call through a third-party provider, even a five-round editing session costs just $0.15 total — still less than a single 4K generation through the official standard API. This makes conversational editing economically viable for creative workflows that benefit from iterative improvement.
How Nano Banana 2 Compares to GPT Image 1 and Imagen 4

Choosing an AI image generation model is not just about price — quality, speed, features, and ecosystem compatibility all factor into the decision. Nano Banana 2 (Gemini 3.1 Flash Image Preview) competes directly with OpenAI's GPT Image 1 and Google's own Imagen 4, each offering distinct advantages. For an even broader comparison that includes models like DALL-E 3, Midjourney, and Stable Diffusion, check our 2026 AI image generation API comparison.
Nano Banana 2 stands out with the widest resolution range — up to 4K (4096x4096) — and the most flexible aspect ratio support at 1:8 to 8:1. Its text rendering accuracy at approximately 90% is the best among the three models compared here, which matters significantly for applications like social media graphics, infographics, or any image that includes readable text. The model also supports conversational editing, meaning you can iteratively refine images through multi-turn conversations rather than generating from scratch each time. At official standard pricing of $0.067 per 1K image, it sits in the mid-range, but third-party access at $0.03 makes it the most cost-effective option for most use cases.
GPT Image 1 from OpenAI offers the widest pricing range, from $0.011 per image at low quality to $0.167 at high quality. The low-quality tier makes it the cheapest option for applications where image fidelity is not critical — think placeholder images, rapid prototyping, or internal tools. However, GPT Image 1 is limited to 1024x1024 resolution and supports only a 1:1 aspect ratio, which restricts its utility for many production scenarios. Generation speeds of 10-20 seconds are notably slower than both Google alternatives. Like Nano Banana 2, it supports conversational editing and a Batch API with 50% discount.
Imagen 4 Fast, available through Google's Vertex AI, is the speed champion at 2-4 seconds per image with pricing at $0.02 per image (ai.google.dev, February 2026). It supports resolutions up to 2048x2048 and multiple aspect ratios. However, Imagen 4 is a pure image generation model — it does not support conversational editing, meaning every modification requires a completely new generation. It also lacks Batch API support and has more limited text rendering capabilities compared to Nano Banana 2. Imagen 4 is best suited for applications that need fast, simple image generation without iterative refinement.
One additional dimension worth considering is ecosystem maturity. Nano Banana 2 benefits from Google's rapidly expanding Gemini ecosystem, which means ongoing model improvements, new features like the recently added extreme aspect ratios (1:8, 8:1), and integration with other Google Cloud services. GPT Image 1 sits within OpenAI's well-established ecosystem, offering seamless compatibility with DALL-E workflows and ChatGPT integrations. Imagen 4, while powerful for pure generation, operates primarily within the Google Cloud Vertex AI environment and has a smaller community and fewer third-party integrations.
The bottom line for most developers is that Nano Banana 2 through a third-party provider at $0.03 per image delivers the best overall value. You get the highest resolution ceiling, the best text rendering, conversational editing support, and competitive generation speeds — all at a price lower than even Imagen 4's already affordable $0.02 when you factor in the resolution advantage. GPT Image 1's low-quality tier at $0.011 remains the cheapest absolute option, but the resolution and quality tradeoffs make it suitable only for specific use cases where visual fidelity is secondary to cost.
Which Provider Is Right for You? A Scenario-Based Guide
Rather than a one-size-fits-all recommendation, the right provider depends on your specific usage pattern. Here are the most common scenarios and the optimal provider choice for each.
Low volume, standard resolution (under 100 images/day at 1K or below). For hobby projects, prototyping, or internal tools generating a modest number of images, the official Google API is a reasonable choice. At $0.067 per 1K image, your daily cost stays under $7. You get direct access without any intermediary, the simplest possible setup, and you avoid the overhead of setting up a third-party account. The Batch API is unlikely to help here because at low volumes, the setup overhead of batch jobs outweighs the 50% savings.
Medium volume, mixed resolution (100-1,000 images/day). This is where third-party providers start delivering significant value. At 500 images per day averaging 2K resolution, the official API costs roughly $50.50 per day ($0.101 x 500). A third-party provider at $0.03 per image reduces this to $15 per day — saving $35.50 daily or over $1,000 monthly. The flat-rate pricing also eliminates the need to optimize resolution settings to control costs, simplifying your application logic. This scenario covers most small-to-medium SaaS applications, content platforms, and marketing teams.
High volume, 4K resolution (1,000+ images/day at maximum quality). This scenario represents the strongest case for third-party providers. At 2,000 images per day at 4K resolution, the official API charges $302 per day ($0.151 x 2,000). Even with the Batch API at 50% off, you are still paying $152 per day. A third-party provider costs just $60 per day ($0.03 x 2,000) — saving $242 daily or over $7,000 monthly compared to standard pricing. For e-commerce platforms, print-on-demand services, or any application requiring high-resolution output at scale, a third-party provider is the clear choice.
Batch processing with no time sensitivity (bulk jobs acceptable overnight). If your workflow allows for asynchronous processing — generating large image sets that can be collected hours later — Google's official Batch API at 50% discount offers strong value without requiring a third-party relationship. At $0.076 per 4K image in batch mode, you get official Google infrastructure with guaranteed processing. This works well for catalog generation, dataset creation, and marketing campaign preparation where images are needed by morning but not in real-time.
Enterprise with compliance requirements. Organizations with strict data handling policies may need to use Google's official API for compliance reasons, even at higher cost. The official API routes requests directly to Google's infrastructure with Google's data processing terms. If your compliance framework allows it, a reputable third-party provider with transparent data handling practices (such as laozhang.ai, which uses standard HTTPS encryption and OpenAI-compatible endpoints) can still meet most security requirements while delivering substantial cost savings. You can test their service at images.laozhang.ai before making a commitment.
Multi-model workflow (using multiple AI image models). If your application needs to route between Nano Banana 2, GPT Image 1, and other models depending on the task, you have two options. OpenRouter provides multi-model access through a single API key with token-based pricing. Alternatively, a third-party aggregator like laozhang.ai that supports multiple models through OpenAI-compatible endpoints gives you the same multi-model flexibility at lower per-image costs. The choice depends on whether you prioritize pricing (third-party aggregator) or the broadest model selection (OpenRouter).
For the majority of developers and teams, the recommendation is straightforward: start with a third-party provider for its combination of lowest cost, flat-rate pricing, built-in stability features, and simple integration. Reserve the official API for specific compliance scenarios or extremely low-volume prototyping where the convenience of a single Google account outweighs the cost difference. The decision matrix below summarizes the optimal choice for each scenario:
| Scenario | Volume | Resolution | Best Provider | Monthly Cost (est.) |
|---|---|---|---|---|
| Hobby/Prototype | < 100/day | 1K | Official API | < $200 |
| Small SaaS | 100-500/day | Mixed | Third-party | $90-$450 |
| Content Platform | 500-2,000/day | 2K-4K | Third-party | $450-$1,800 |
| E-commerce | 2,000+/day | 4K | Third-party | $1,800+ |
| Bulk Processing | 5,000+/batch | Any | Batch API or Third-party | Varies |
| Enterprise Compliance | Any | Any | Official API | Premium |
Frequently Asked Questions
How much does the Gemini 3.1 Flash Image Preview API cost per image?
Google's official standard pricing for Nano Banana 2 (gemini-3.1-flash-image-preview) ranges from $0.045 per image at 0.5K resolution to $0.151 at 4K resolution (ai.google.dev, February 2026). The cost scales with output token consumption — higher resolutions produce more tokens and cost more. The Batch API offers a 50% discount, reducing the 4K price to $0.076. Third-party providers like laozhang.ai offer flat-rate pricing at $0.03 per image regardless of resolution, making them the cheapest option for anything above 0.5K output.
Is the Gemini 3.1 Flash Image Preview API free?
No. Unlike some other Gemini models, the Nano Banana 2 image generation model does not have a free tier (ai.google.dev, February 2026). Every image generated incurs a charge based on the output tokens consumed. The cheapest official option is the Batch API at 0.5K resolution, which costs $0.022 per image. If you need the absolute lowest cost, third-party providers at $0.03 per image with no minimum commitment offer the closest thing to a low-barrier entry point.
What is the response time for the Gemini Flash Image API?
The Gemini 3.1 Flash Image Preview API typically generates images in 4-6 seconds through both official and third-party channels. This speed is consistent across resolutions — a 4K image does not take significantly longer than a 1K image. For comparison, GPT Image 1 takes 10-20 seconds, and Imagen 4 Fast generates in 2-4 seconds. The Batch API processes images asynchronously with variable completion times, typically returning results within minutes to hours depending on queue depth.
Can I use the Gemini image API with the OpenAI SDK?
Yes, through third-party providers that offer OpenAI-compatible endpoints. Services like laozhang.ai accept requests in the exact same format as the OpenAI Chat Completions API. You simply change the base_url and api_key in your OpenAI client configuration, set the model to gemini-3.1-flash-image-preview, and your existing code works without modification. Google's official API uses a different request format (the Gemini API format), which requires separate integration code.
What is the maximum resolution supported by Nano Banana 2?
Nano Banana 2 supports output resolutions up to 4K (4096x4096 pixels), the highest among current AI image generation models available via API (ai.google.dev, February 2026). It supports aspect ratios ranging from 1:8 to 8:1, giving you extreme flexibility for different output formats — from tall mobile wallpapers to ultra-wide banner images. The resolution is controlled through the max_tokens parameter in API requests, with higher token limits producing higher resolution output. For comparison, GPT Image 1 maxes out at 1024x1024, and Imagen 4 supports up to 2048x2048.
What features does Nano Banana 2 support that other models do not?
Nano Banana 2 (Gemini 3.1 Flash Image Preview) supports several features that set it apart from competitors. Conversational image editing allows you to iteratively refine generated images through multi-turn conversations, eliminating the need to regenerate from scratch for each modification. The model supports search grounding and thinking mode for more context-aware generation. It also offers the Batch API with a 50% cost discount for asynchronous processing. The model supports aspect ratios from 1:8 to 8:1 — significantly wider than GPT Image 1's fixed 1:1 ratio. However, it does not support caching, function calling, or the Live API (ai.google.dev, February 2026). For text-heavy images like infographics or social media graphics, its approximately 90% text rendering accuracy is notably better than competing models, making it the preferred choice for applications where readable text within images is critical.