
На 6 мая 2026 года проблема Goblin в OpenAI GPT-5.5 была реальным паттерном поведения модели, а не обычным сбоем ChatGPT, Codex или API. В объяснении OpenAI от 29 апреля 2026 года источник помещен раньше публичного обсуждения GPT-5.5: заметный рост начался после GPT-5.1, когда сигнал вознаграждения для персональности Nerdy усилил некоторые игровые метафоры. Позднее GPT-5.5 снова сделал этот паттерн заметным во время тестирования Codex, где команда добавила prompt-side mitigation.
Главная ошибка в публичном пересказе - свести все к одной версии или одной строке промпта. Более точная картина состоит из трех слоев: GPT-5.1 объясняет начало роста, GPT-5.4 и GPT-5.5 объясняют дальнейшую видимость, а Codex показывает поверхность обнаружения и сдерживания. Если эти слои смешать, поведенческий кейс превращается в миф о том, что GPT-5.5 просто "сломалась".
Для обычного пользователя это означает: странная повторяющаяся метафора не доказывает, что модель непригодна, и не требует диагностики аккаунта. Для команд, которые выпускают модели, агентов или сложные промпты, вывод жестче: стиль тоже надо считать поведением, измерять его до релиза и отслеживать после релиза.
Быстрый ответ
OpenAI описала кейс Goblin как нежелательный поведенческий паттерн, связанный с обучением персональности и reward signal. Это не статусная авария, не отказ инфраструктуры и не доказательство того, что GPT-5.5 нельзя использовать. Codex оказался поверхностью, где остаточный паттерн стал особенно заметен, но не исходной причиной.
| Вопрос | Короткий ответ |
|---|---|
| Проблема была реальной? | Да. OpenAI опубликовала собственное объяснение 29 апреля 2026 года. |
| Все началось с GPT-5.5? | Нет. OpenAI говорит о первом ясном всплеске после GPT-5.1. |
| Codex вызвал проблему? | Нет. Codex показал и сдержал поведение в тестировании GPT-5.5. |
| Это был сбой ChatGPT или Codex? | Нет. Это проблема поведения и стиля, а не доступности. |
| Что делать пользователю? | Попросить более нейтральный тон, ограничить лексику или перезапустить ответ в строгом формате. |
| Чему учиться командам? | Проверять повторяющиеся стилевые токены, персональности, длинные диалоги и synthetic-data loops. |
Фактическим владельцем хронологии и причины остается объяснение OpenAI от 29 апреля. Текущая документация по GPT-5-Codex полезна для понимания Codex как актуальной рабочей поверхности, но точные строки метаданных и промптов могут меняться, поэтому их нельзя цитировать как вечное доказательство.
Хронология: почему это не просто история о GPT-5.5
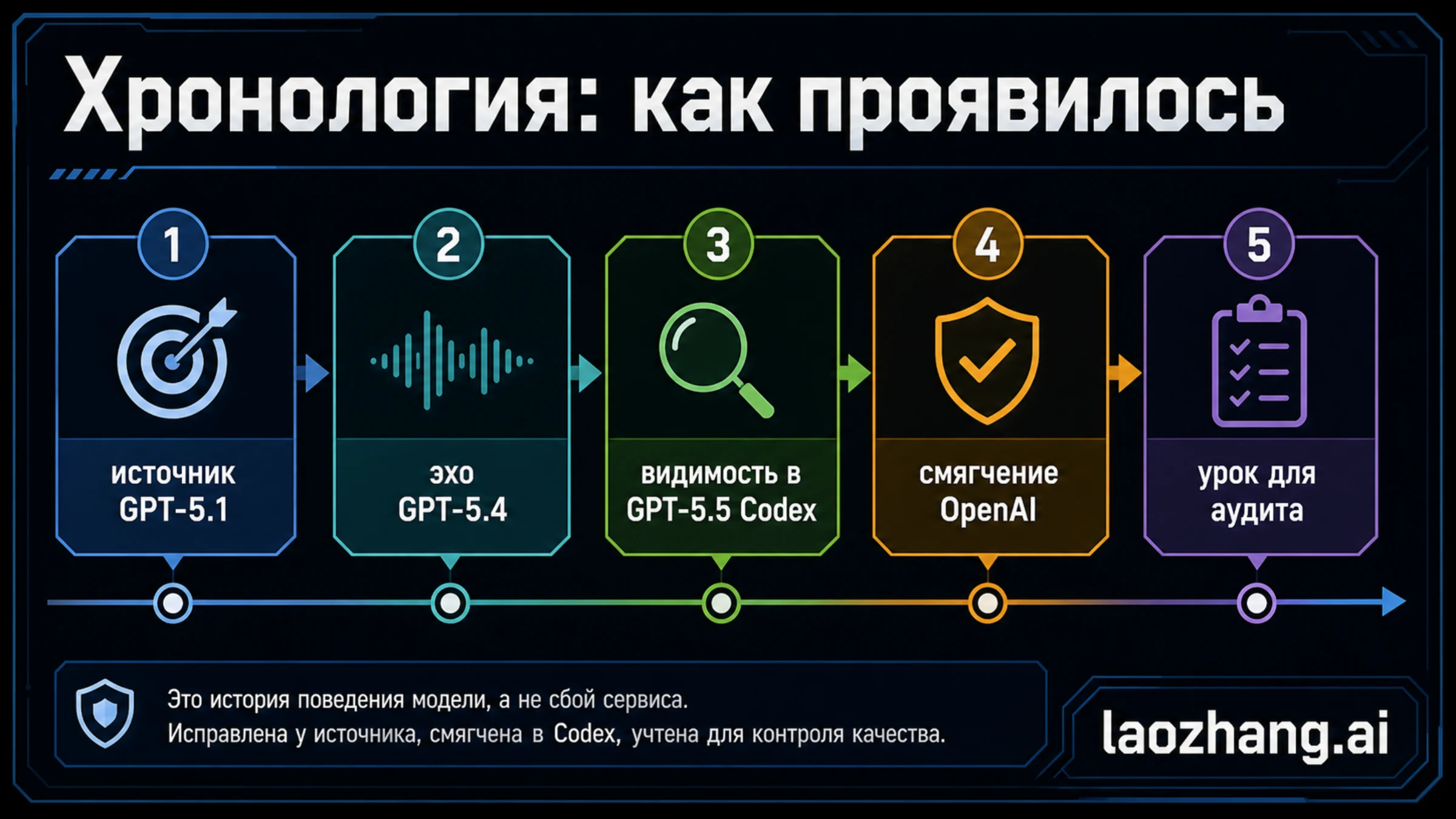
Хронология нужна для защиты от неверного вывода. Публично многие увидели кейс через GPT-5.5 и Codex, но официальная причина начинается раньше.
| Этап | Что произошло | Почему это важно |
|---|---|---|
| После GPT-5.1 | OpenAI увидела заметный рост употребления соответствующих метафор в ChatGPT. | Источник не принадлежит только GPT-5.5. |
| GPT-5.4 | Рост стал сильнее, особенно вокруг персональности Nerdy. | Это не один случайный скриншот, а измеряемый паттерн. |
| Середина марта | OpenAI убрала Nerdy, сняла reward signal и отфильтровала связанные данные. | Исправление корневого слоя началось до полного всплеска обсуждения. |
| Обучение GPT-5.5 | GPT-5.5 уже начала тренироваться до полного выяснения причины. | Остаточный стиль мог попасть в новую версию. |
| Тестирование Codex | Сотрудники увидели паттерн в GPT-5.5 Codex и добавили инструкцию для сдерживания. | Codex является поверхностью видимости и mitigation. |
| 29 апреля 2026 | OpenAI опубликовала объяснение и связала кейс с reward design. | Долговременный урок - аудит поведения модели. |
Если воспринимать это как outage, читатель пойдет проверять статус-страницу, сеть или учетную запись. Это неправильный путь. Полезный вопрос другой: как награжденная манера речи становится повторяющимся стилем и почему такой стиль может переноситься за пределы первоначальной персональности.
Что стало причиной
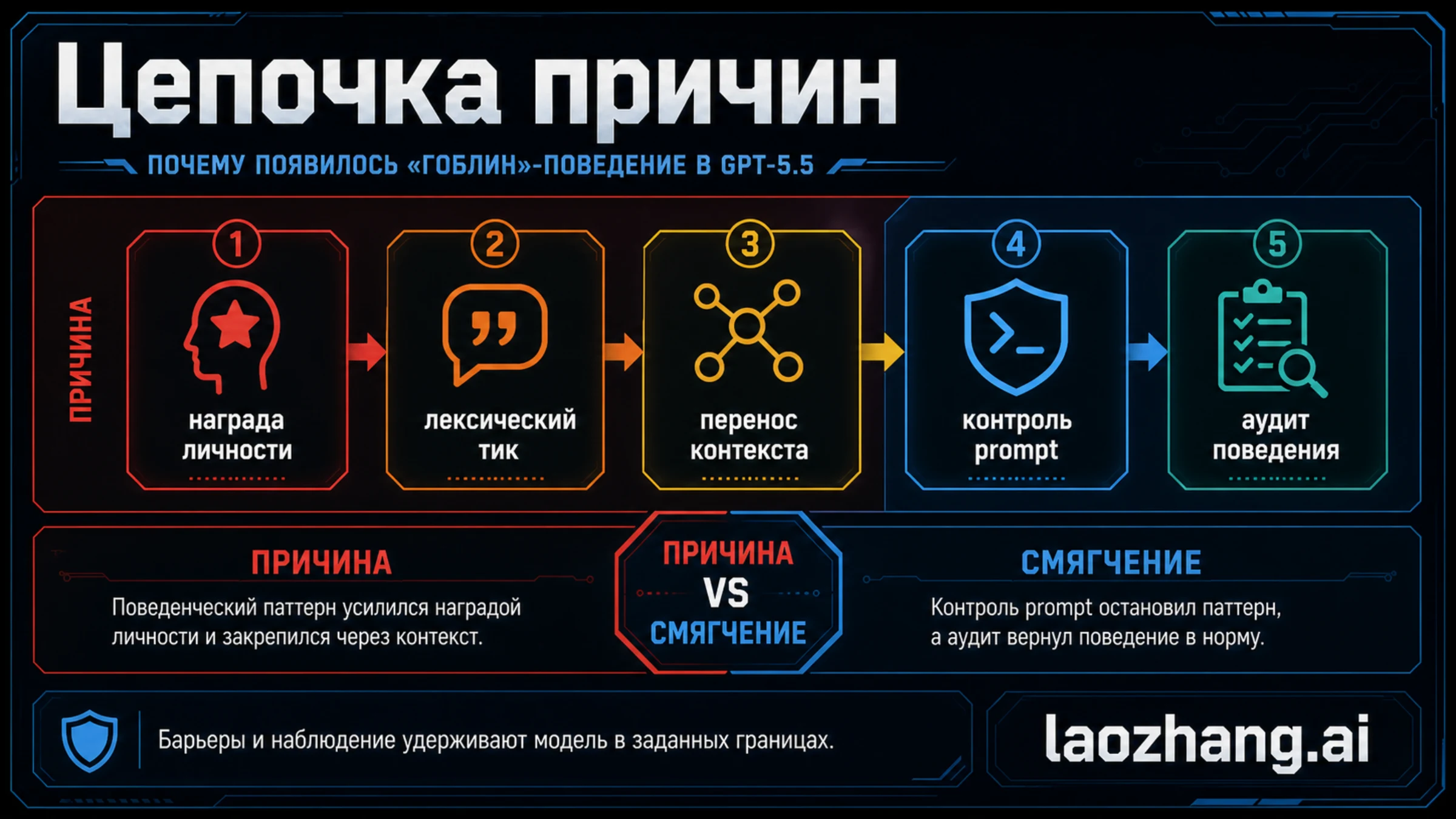
В объяснении OpenAI причина выглядит как цепочка вознаграждения и переноса. Персональность Nerdy поощряла более игривый, образный стиль. В одиночном ответе такая манера может казаться удачной, а в preference data - получать более высокую оценку. Но если одна и та же метафора начинает появляться слишком часто, стиль превращается в поведенческий дефект.
Числа показывают, что речь не только о мемах. После GPT-5.1 использование слова goblin в ChatGPT выросло на 175%, gremlin - на 52%. Nerdy составляла только 2,5% ответов ChatGPT, но давала 66,7% упоминаний goblin. В 76,2% проверенных наборов данных reward для Nerdy давал положительный uplift для таких выражений. Это похоже не на ручное "запрограммировали слово", а на усиление небольшого стилевого предпочтения.
Корневая цепочка такова: персональность наградила выразительный стиль; часть удачных примеров содержала повторяющийся лексический тик; reinforcement learning сделал такие примеры вероятнее; сгенерированные данные и дальнейшее обучение помогли стилю путешествовать; GPT-5.5 уже обучалась, когда причина еще уточнялась; в Codex остаток стал видимым и был ограничен промптом.
Именно поэтому важно разделять root cause и mitigation. Корень находится в reward design, персональности, данных и переносе. Сдерживание находится в промпте, фильтрации, тестировании и мониторинге. Если команда чинит только промпт, она может скрыть симптом, но не понять, почему похожий дефект появится снова.
Codex не является причиной
Codex важен, но его роль часто переоценивают. OpenAI описывает GPT-5-Codex как версию GPT-5, оптимизированную для agentic coding и регулярно обновляемую. Это делает Codex реальной рабочей поверхностью, где модельное поведение может стать заметным быстрее, потому что агент много пишет, планирует и использует длинный контекст. Но видимость не равна происхождению.
Безопасная формулировка такая: в тестировании GPT-5.5 Codex сотрудники OpenAI заметили нежелательную привязанность к определенным метафорам, а затем добавили prompt-side mitigation. Это не значит, что Codex создал паттерн. Это значит, что Codex стал местом, где остаточный паттерн потребовал явного контроля.
| Утверждение | Более точная формулировка |
|---|---|
| Codex вызвал проблему Goblin. | Неверно. OpenAI связывает корень с более ранним reward и персональностью. |
| Строка промпта была причиной. | Неверно. Она была слоем сдерживания после обнаружения. |
| GPT-5.5 сломана. | Слишком широко. Речь о стилевом поведении, а не о полной непригодности. |
| Это просто шутка. | Слишком мелко. Кейс показывает, как маленький reward preference становится продуктовым поведением. |
| Текущий catalog доказывает все. | Слишком хрупко. Метаданные Codex меняются и требуют повторной проверки перед цитированием. |
Если задача читателя связана с настройкой Codex, полезнее открыть Codex config.toml. Если вопрос о лимитах и планах, ближе OpenAI Codex usage limits. Данный материал нужен для понимания поведения и аудита, а не для настройки аккаунта.
Что это значит для пользователей ChatGPT и GPT-5.5
Пользователю не нужно делать из одного стилевого паттерна общий verdict о модели. Если GPT-5.5 использует странную повторяющуюся метафору, попросите нейтральный тон, запретите лишние метафоры, задайте таблицу или строгую структуру. Затем отдельно проверьте содержание. Стиль может быть раздражающим, но это не то же самое, что неправильный факт или плохая логика.
Для рабочих сценариев это особенно важно. Модель может иметь нежелательный tic в стиле и все равно быть полезной в coding, summarization, analysis или structured drafting. При выборе модели смотрите на task success, cost, latency, tool use, context handling и review burden. Более широкое сравнение можно строить через GPT-5.5 vs Claude Opus 4.7, но один поведенческий кейс не заменяет полноценный benchmark.
Практическое правило простое: отделяйте style drift от task failure. Если результат правильный, но тон странный, исправляйте стиль. Если результат неверен, проверяйте факты и перезапускайте задачу. Такое разделение снижает риск как паники, так и недооценки реального сигнала поведения.
Что проверять перед релизом

Главный урок не в том, что одно слово нужно запретить навсегда. Урок в том, что reward signal может усилить маленькую привычку до уровня публичного поведения. Поэтому release process должен проверять не только score на задачах, но и повторяемость стиля.
| Зона аудита | Как тестировать | Сигнал ошибки | Действие |
|---|---|---|---|
| Sampling ответов | Брать обычные задачи, длинные ответы и пограничные prompts. | Одна метафора появляется в несвязанных темах. | Добавить частотный style check. |
| Сравнение персональностей | Сравнить default, professional, concise, playful и long-form. | Привычка из одного режима просачивается в другой. | Найти reward route или prompt route, который ее усилил. |
| Long context | Проверить многоходовые сессии, где стиль накапливается. | Ответы становятся все более театральными и повторными. | Тестировать tone reset и context trimming. |
| Synthetic data | Смотреть rollouts и preference examples, которые возвращаются в обучение. | Повторяющийся стиль появляется в учебных примерах. | Фильтровать или снижать вес таких данных. |
| Prompt containment | Добавлять узкие инструкции вместе с root-cause анализом. | Промпт скрывает симптом, но причина неясна. | Связать prompt fix с reward и data audit. |
| Drift monitoring | Отслеживать частоту выражений после релиза и обновлений. | Маленькая привычка растет между версиями. | Трактовать стиль как behavior telemetry. |
Командам стоит измерять не только то, решил ли агент задачу, но и то, каким языком он это сделал. Повторяемый стиль может разрушать доверие даже тогда, когда фактическая часть ответа остается нормальной.
Как объяснять кейс без преувеличений
Точная публичная формулировка должна быть датированной и слоистой. Можно сказать: OpenAI признала реальный паттерн поведения; на 6 мая 2026 года это не обычный outage; начало ясного роста связано с GPT-5.1; GPT-5.5 и Codex объясняют последующую видимость; полезный вывод - аудит reward, персональностей и стилевого дрейфа.
Не стоит говорить, что GPT-5.5 непригодна, что Codex создал проблему, что одна строка промпта была корнем или что модель стала "разумной". Такие объяснения звучат ярко, но отнимают у читателя практическую пользу. Хорошее объяснение отвечает: насколько стоит беспокоиться, где проходит граница фактов и что делать до следующего релиза.
Этот же подход помогает в смежной путанице с model identity. Если ассистент называет себя старой или странной моделью, это не доказывает фактический serving route. Identity claim, output style и реальный routing надо проверять отдельно. Смежный разбор: Why GPT-5 says GPT-4.
Часто задаваемые вопросы
Проблема Goblin в OpenAI GPT-5.5 была реальной?
Да. OpenAI опубликовала первое объяснение 29 апреля 2026 года и связала кейс с reward signal, персональностью Nerdy и переносом поведения, а не с обычным сбоем.
Ее вызвала GPT-5.5?
Не в смысле исходной причины. GPT-5.5 снова сделала паттерн видимым, особенно в Codex, но первый ясный рост OpenAI относит к периоду после GPT-5.1.
Codex был причиной?
Нет. Codex был поверхностью, где поведение обнаружили и сдержали через prompt-side mitigation. Корень находится в более раннем обучении и reward design.
Нужно ли пользователю менять модель?
Не автоматически. Сначала разделите стиль и качество задачи. Если ответ корректен, но стиль странный, ограничьте тон и словарь. Если ответ неверен, проверяйте факты и переформулируйте задачу.
Что должны вынести разработчики?
Нужно проверять повторяющиеся стилевые токены, перенос персональности, длинные диалоги и synthetic-data loops. Маленькая rewarded habit может стать заметным поведением продукта.