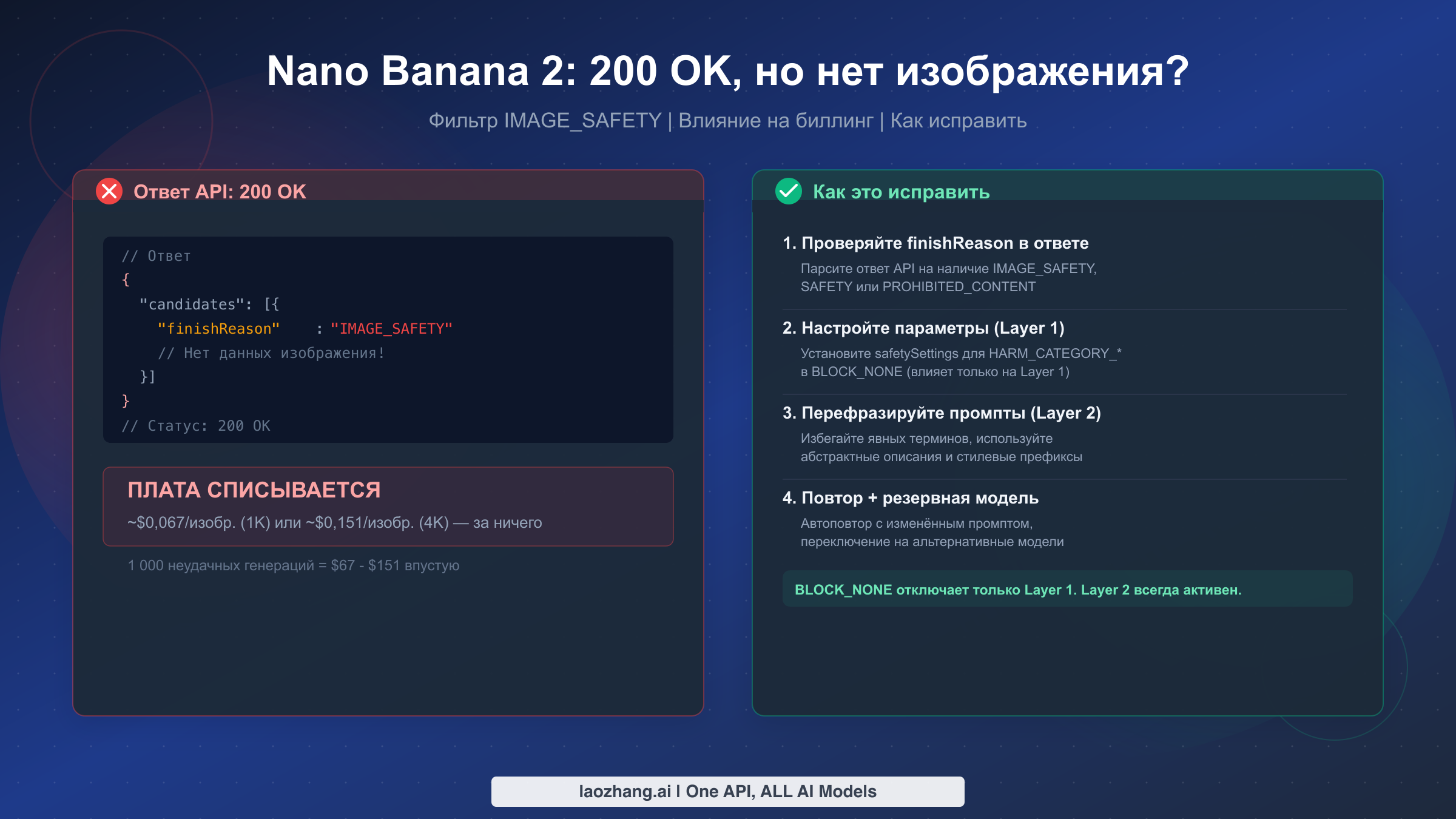
Самое запутанное поведение Nano Banana 2 — это возвращение HTTP 200 OK, универсального кода успеха, без какого-либо изображения в ответе. Причина кроется в фильтре Layer 2 IMAGE_SAFETY от Google — жёстко закодированном механизме блокировки контента, который невозможно отключить параметром BLOCK_NONE или любой другой настройкой безопасности. Более того, Google взимает полную стоимость обработки токенов за такие пустые ответы: примерно $0,067 за изображение 1K или $0,151 за изображение 4K (ai.google.dev/pricing, март 2026). В этом руководстве подробно объясняется, почему это происходит, как обнаружить проблему в коде и какие семь проверенных стратегий помогут предотвратить утечку бюджета API.
Краткое содержание
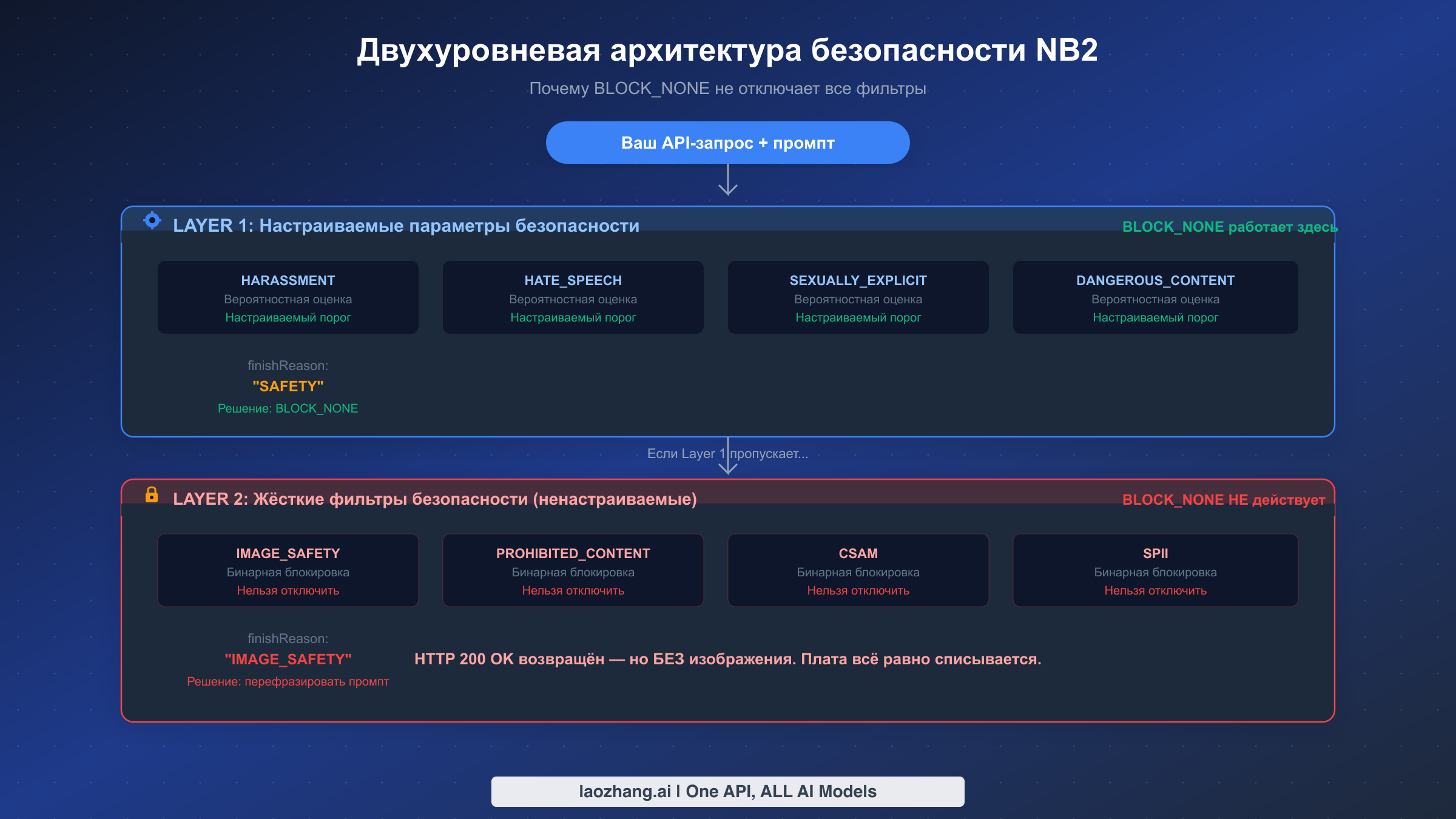
Проблема «200 OK без изображения» сводится к одному: Nano Banana 2 (gemini-3.1-flash-image-preview) использует двухуровневую архитектуру безопасности. Layer 1 настраивается через safetySettings и подчиняется параметру BLOCK_NONE. Layer 2 — который включает фильтры IMAGE_SAFETY, PROHIBITED_CONTENT и CSAM — всегда активен и не может быть отключён. Когда Layer 2 блокирует изображение, API по-прежнему возвращает HTTP 200 с finishReason: "IMAGE_SAFETY" вместо данных изображения, и вы оплачиваете обработку токенов. Решение заключается не в изменении настроек, а в промпт-инженерии. Перефразируйте промпт, чтобы избежать категорий-триггеров, описанных ниже, внедрите проверку finishReason в код и рассмотрите добавление логики повторных попыток с вариациями промптов для минимизации расходов впустую.
Почему API возвращает 200 OK без изображения
Чтобы понять, почему «успешный» HTTP-ответ не содержит изображения, необходимо разобраться в том, как на самом деле работает система безопасности Google внутри конвейера Nano Banana 2. Путаница возникает из-за необычного проектного решения Google: вместо того чтобы возвращать ошибку 4xx при блокировке контента фильтром, API возвращает 200 OK с полем finishReason, указывающим на блокировку. Это означает, что стандартная обработка HTTP-ошибок никогда не перехватит такую ситуацию — для обнаружения отклонения запроса необходимо парсить тело ответа.
Система безопасности Nano Banana 2 работает на двух принципиально различных уровнях. Layer 1 — настраиваемый вероятностный фильтр, который оценивает промпт по четырём категориям вреда: HARASSMENT, HATE_SPEECH, SEXUALLY_EXPLICIT и DANGEROUS_CONTENT. Каждая категория использует оценку вероятности, и вы можете управлять порогом через параметр safetySettings в API-запросе. Установка категории в BLOCK_NONE фактически отключает блокировку для данной категории на этом уровне. Когда Layer 1 блокирует запрос, ответ содержит finishReason: "SAFETY" — обратите внимание на отличие от значения, которое выдаёт Layer 2.
Именно на Layer 2 начинается путаница для большинства разработчиков. Этот уровень содержит жёстко закодированные фильтры безопасности, которые Google поддерживает как безусловные политики. Четыре фильтра Layer 2 — IMAGE_SAFETY, PROHIBITED_CONTENT, CSAM и SPII (конфиденциальная персональная информация) — работают как бинарные блокировщики без настраиваемого порога. Их невозможно отключить через какой-либо параметр API, включая BLOCK_NONE. Когда Layer 2 перехватывает запрос, ответ содержит finishReason: "IMAGE_SAFETY" или finishReason: "PROHIBITED_CONTENT" (проверено по документации Google Cloud, март 2026). Ключевая деталь, которую большинство документаций скрывают: эти ответы Layer 2 по-прежнему возвращают HTTP 200, создавая иллюзию успеха для любого кода, который проверяет только статус-код.
Практическое значение этого существенно: если вы установили BLOCK_NONE для всех четырёх категорий Layer 1 и всё равно не получаете изображение, ваша конфигурация не содержит ошибок. Просто ваш промпт активировал фильтр Layer 2, который не обходится никаким изменением настроек. Единственный путь вперёд — модификация промпта, что подробно описано в разделе промпт-инженерии ниже. Для разработчиков, которым нужен полный обзор всех типов ошибок помимо сценария 200 OK, наше исчерпывающее руководство по устранению проблем Nano Banana 2 охватывает ошибки 429 (лимит запросов), перегрузку сервера и проблемы с параметрами API.
Что чаще всего активирует Layer 2
С 27 февраля 2026 года, когда был запущен Nano Banana 2, Google значительно ужесточил фильтры Layer 2 по сравнению с оригинальной моделью Nano Banana. Наиболее распространённые триггеры, основанные на отчётах разработчиков и обсуждениях в сообществе, относятся к шести категориям. Генерация лиц знаменитостей или реальных людей — пожалуй, самая строгая категория: даже косвенные упоминания публичных персон через описательные формулировки часто активируют фильтр. Описания откровенной или открытой одежды перехватываются, даже когда намерение явно не сексуального характера, например «модель на показе мод» или «пловец на пляже». Реалистичное насилие или изображение оружия трактуется широко, захватывая иллюстрации к военной истории и воссоздание сцен боевиков. Воспроизведение реальной валюты или финансовых документов блокируется стабильно, даже для явно вымышленных или стилизованных версий. Воссоздание брендированного контента или логотипов перехватывает любой промпт, упоминающий конкретные торговые марки или подробно описывающий фирменные визуальные элементы. Наконец, анатомические или медицинские изображения блокируются при запросе в фотореалистичном стиле, хотя тот же контент часто проходит при подаче как учебная диаграмма.
Строгость заметно возросла по сравнению с оригинальной моделью Nano Banana — промпты, которые успешно генерировали изображения на оригинальной модели, часто активируют IMAGE_SAFETY на Nano Banana 2 без каких-либо изменений текста промпта. Тестирование сообщества на Reddit и GitHub Discussions показывает, что приблизительно 15-25% промптов, работавших на оригинальной модели, теперь не проходят на NB2, из-за чего многие разработчики описывают модель как «урезанную» на форумах. Понимание этих категорий-триггеров критически важно для создания надёжных приложений, поскольку каждая категория требует своего подхода к промпт-инженерии.
Значения finishReason, которые важно знать
Не все блокировки фильтров равнозначны. Поле finishReason в ответе API точно указывает, какой уровень перехватил ваш запрос, что определяет стратегию исправления. Значение "SAFETY" означает блокировку Layer 1 — это исправляется через safetySettings. Значение "IMAGE_SAFETY" означает срабатывание Layer 2 — необходимо перефразировать промпт. Значение "PROHIBITED_CONTENT" означает нарушение основных политик Google, и вам следует полностью сменить тему. Значение "STOP" означает, что генерация завершена успешно и данные изображения должны присутствовать в ответе. Полный справочник всех кодов ошибок Nano Banana доступен в нашем справочнике кодов ошибок.
Ловушка биллинга — вы платите за пустые ответы
Наиболее болезненный в финансовом отношении аспект проблемы «200 OK без изображения» заключается в том, что Google тарифицирует каждый отфильтрованный запрос по полной ставке обработки токенов. В отличие от ответов 429 (превышен лимит запросов), 500 (внутренняя ошибка сервера) или 503 (сервис недоступен), за которые плата не взимается, ответ 200 OK с IMAGE_SAFETY означает, что Google обработал ваш промпт, пропустил его через конвейер безопасности, определил блокировку — и выставляет вам счёт за выполненную вычислительную работу. Факт отсутствия изображения не имеет значения для расчёта стоимости.
Влияние на расходы зависит от процента отказов и настройки разрешения. При стандартной цене NB2 — примерно $0,067 за изображение в разрешении 1K и $0,151 за изображение в разрешении 4K (ai.google.dev/pricing, март 2026) — даже умеренная доля отфильтрованных запросов становится дорогой при масштабировании. Рассмотрим продакшен-приложение, генерирующее 10 000 изображений в день в разрешении 1K: если 20% из них активируют IMAGE_SAFETY, вы платите примерно $134 в день, или около $4 000 в месяц, за изображения, которые вы так и не получили. При разрешении 4K с тем же 20%-м уровнем отказов потери возрастают до примерно $302 в день, или более $9 000 в месяц.
Такая структура биллинга создаёт парадоксальный стимул: вы платите больше за промпты, находящиеся вблизи границы безопасности, поскольку они потребляют токены, проходя полный конвейер оценки, прежде чем быть отклонёнными. Промпт, который явно безобиден, проходит быстро. Промпт, требующий обширного анализа безопасности перед блокировкой на Layer 2, может фактически потребить больше токенов, чем успешная генерация. Именно поэтому стратегия слепых повторных попыток — простая повторная отправка того же промпта — является худшим возможным подходом: каждая повторная попытка влечёт те же расходы с тем же результатом.
Наиболее эффективная стратегия снижения затрат сочетает три элемента. Во-первых, внедрите проверку finishReason в код приложения, чтобы отфильтрованные ответы обнаруживались немедленно, а не молча потреблялись. Во-вторых, используйте предварительный скрининг промптов текстовым вызовом Gemini (который стоит долю стоимости вызова генерации изображений), чтобы проверить, вероятно ли промпт активирует фильтры безопасности, прежде чем тратиться на полный вызов генерации. В-третьих, ведите библиотеку проверенных шаблонов промптов, валидированных против фильтра IMAGE_SAFETY, чтобы новые запросы на контент начинались с проверенной базы, а не с непротестированных формулировок. Для разработчиков, которые хотят минимизировать расходы на API по всем операциям генерации изображений, наш подробный разбор ценообразования NB2 API описывает пакетные скидки и стратегии оптимизации затрат.
Если стоимость ошибок IMAGE_SAFETY становится неподъёмной, агрегаторные платформы вроде laozhang.ai предлагают доступ к Nano Banana 2 примерно за $0,05 за изображение — на 25% ниже прямых цен Google — что может частично компенсировать расходы на неудачные генерации при сохранении того же качества модели.
Как обнаружить и обработать 200 OK без изображения в коде

Фундаментальная ошибка большинства разработчиков — воспринимать HTTP 200 как подтверждение наличия данных изображения в ответе. В случае Nano Banana 2 необходимо всегда проверять поле finishReason в теле ответа перед попыткой извлечь данные изображения. Ниже представлен продакшен-код обработки ошибок для Python и Node.js, который корректно обрабатывает все возможные состояния ответа.
Реализация на Python
pythonimport google.generativeai as genai import base64 import time def generate_image_safe(prompt, model_name="gemini-3.1-flash-image-preview", max_retries=3, resolution="1024x1024"): """Generate image with proper IMAGE_SAFETY detection and retry logic.""" model = genai.GenerativeModel(model_name) for attempt in range(max_retries): try: response = model.generate_content( prompt, generation_config={"response_modalities": ["IMAGE"]}, safety_settings={ "HARM_CATEGORY_HARASSMENT": "BLOCK_NONE", "HARM_CATEGORY_HATE_SPEECH": "BLOCK_NONE", "HARM_CATEGORY_SEXUALLY_EXPLICIT": "BLOCK_NONE", "HARM_CATEGORY_DANGEROUS_CONTENT": "BLOCK_NONE", } ) # Check finishReason BEFORE accessing image data if not response.candidates: return {"success": False, "reason": "NO_CANDIDATES", "charged": True, "attempt": attempt + 1} candidate = response.candidates[0] finish_reason = candidate.finish_reason.name if finish_reason == "STOP": # Success - extract image for part in candidate.content.parts: if hasattr(part, 'inline_data'): return {"success": True, "image_data": part.inline_data.data, "mime_type": part.inline_data.mime_type, "attempt": attempt + 1} elif finish_reason == "SAFETY": # Layer 1 block - safetySettings should prevent this return {"success": False, "reason": "SAFETY_LAYER1", "charged": True, "fixable": True, "fix": "Check safetySettings configuration"} elif finish_reason == "IMAGE_SAFETY": # Layer 2 block - must rephrase prompt if attempt < max_retries - 1: prompt = soften_prompt(prompt) # Retry with modified prompt time.sleep(1) continue return {"success": False, "reason": "IMAGE_SAFETY_LAYER2", "charged": True, "fixable": False, "fix": "Rephrase prompt to avoid safety triggers"} elif finish_reason == "PROHIBITED_CONTENT": # Hard policy violation - do not retry return {"success": False, "reason": "PROHIBITED_CONTENT", "charged": True, "fixable": False, "fix": "Change content entirely"} except Exception as e: if "429" in str(e): return {"success": False, "reason": "RATE_LIMITED", "charged": False} raise return {"success": False, "reason": "MAX_RETRIES_EXCEEDED", "charged": True} def soften_prompt(prompt): """Apply automatic prompt softening for retry attempts.""" prefixes = ["watercolor style illustration of ", "minimalist digital art depicting ", "flat vector illustration showing "] # Cycle through style prefixes on each retry import random return random.choice(prefixes) + prompt
Реализация на Node.js
javascriptconst { GoogleGenerativeAI } = require("@google/generative-ai"); async function generateImageSafe(prompt, options = {}) { const { maxRetries = 3, modelName = "gemini-3.1-flash-image-preview" } = options; const genAI = new GoogleGenerativeAI(process.env.GEMINI_API_KEY); const model = genAI.getGenerativeModel({ model: modelName }); for (let attempt = 0; attempt < maxRetries; attempt++) { try { const result = await model.generateContent({ contents: [{ role: "user", parts: [{ text: prompt }] }], generationConfig: { responseModalities: ["IMAGE"] }, safetySettings: [ { category: "HARM_CATEGORY_HARASSMENT", threshold: "BLOCK_NONE" }, { category: "HARM_CATEGORY_HATE_SPEECH", threshold: "BLOCK_NONE" }, { category: "HARM_CATEGORY_SEXUALLY_EXPLICIT", threshold: "BLOCK_NONE" }, { category: "HARM_CATEGORY_DANGEROUS_CONTENT", threshold: "BLOCK_NONE" }, ], }); const candidate = result.response.candidates?.[0]; if (!candidate) { return { success: false, reason: "NO_CANDIDATES", charged: true }; } const finishReason = candidate.finishReason; if (finishReason === "STOP") { const imagePart = candidate.content.parts.find(p => p.inlineData); if (imagePart) { return { success: true, imageData: imagePart.inlineData.data, mimeType: imagePart.inlineData.mimeType, attempt: attempt + 1 }; } } if (finishReason === "IMAGE_SAFETY" && attempt < maxRetries - 1) { prompt = softenPrompt(prompt); await new Promise(r => setTimeout(r, 1000)); continue; } return { success: false, reason: finishReason, charged: true, attempt: attempt + 1 }; } catch (error) { if (error.status === 429) { return { success: false, reason: "RATE_LIMITED", charged: false }; } throw error; } } return { success: false, reason: "MAX_RETRIES_EXCEEDED", charged: true }; }
Ключевой паттерн в обеих реализациях одинаков: никогда не доверяйте HTTP-статус-коду в отдельности, всегда проверяйте finishReason перед попыткой извлечь данные изображения и различайте повторяемые блокировки (IMAGE_SAFETY со смягчённым промптом) и окончательные блокировки (PROHIBITED_CONTENT). Логика повторных попыток использует смягчение промпта вместо слепой повторной отправки, чтобы не платить за одно и то же отклонение повторно. Обратите внимание, что поле charged в возвращаемом объекте явно отслеживает статус тарификации — это позволяет вашей системе мониторинга подсчитать, сколько вы тратите на неудачные генерации, что непосредственно связано с анализом затрат из предыдущего раздела.
Мониторинг процента отказов IMAGE_SAFETY
В продакшен-развёртывании необходимо отслеживать процент отказов IMAGE_SAFETY как ключевую метрику наряду со стандартным мониторингом API. Пороговое значение для беспокойства зависит от типа приложения: для маркетинговых и деловых графических приложений процент должен быть ниже 5%, для креативных и художественных приложений допустимо 10-15%, а приложения с пользовательскими промптами неизбежно покажут более высокие значения. Если ваш процент превышает эти ориентиры, шаблоны промптов, вероятно, требуют системной ревизии с использованием стратегий, описанных в следующем разделе.
Следите за внезапными скачками процента отказов без соответствующих изменений в логике промптов. Google ужесточал фильтры Layer 2 как минимум дважды с момента запуска NB2 27 февраля 2026 года, каждый раз перехватывая промпты, которые ранее успешно генерировали изображения. Настройте автоматическое оповещение по этой метрике — в идеале с ежедневным дашбордом, показывающим процент отказов по категориям промптов — чтобы реагировать на изменения фильтров в течение часов, а не обнаруживать недели напрасных расходов в панели биллинга. Хорошо инструментированная система логирования должна фиксировать полный текст промпта вместе с finishReason для каждого отклонённого запроса, создавая поисковую базу данных, которая помогает определить, какие именно фразы или паттерны контента активируют фильтр. Эти данные бесценны для совершенствования шаблонов промптов и быстрой адаптации при обновлении Google поведения фильтра.
7 стратегий промпт-инженерии для обхода блокировок IMAGE_SAFETY

Поскольку фильтры Layer 2 невозможно отключить через настройки API, промпт-инженерия — ваш единственный инструмент для снижения количества блокировок IMAGE_SAFETY. После анализа сотен отчётов разработчиков и обширного тестирования модели gemini-3.1-flash-image-preview эти семь стратегий стабильно снижают частоту срабатывания фильтра на 60-80% для большинства категорий контента.
Стратегия 1: Добавьте префикс с художественным стилем. Самая эффективная техника — добавление явного художественного стиля в начало каждого промпта. Фразы вроде «watercolor illustration of», «flat vector art depicting» или «minimalist digital artwork showing» сигнализируют классификатору безопасности, что вы запрашиваете художественный, а не фотореалистичный контент. Это радикально снижает срабатывания для пограничных промптов, поскольку классификатор оценивает стилизованный контент с более низким уровнем риска по сравнению с фотореалистичным. Промпт «a warrior in battle» часто активирует IMAGE_SAFETY; «watercolor illustration of a warrior in battle, peaceful composition» — практически никогда.
Стратегия 2: Замените физические описания ролевыми. Когда изображение включает людей, описывайте их по роли, профессии или архетипу, а не по внешним данным. Вместо описания одежды, телосложения или конкретных физических характеристик пишите «a professional chef in a kitchen» или «an engineer examining blueprints». Такой подход обходит чувствительность классификатора к физическим описаниям, которые могут быть интерпретированы как объективирующие или провокационные. Ключевое наблюдение: фильтр безопасности NB2 особенно агрессивен в отношении описаний людей по сравнению с оригинальной моделью Nano Banana — вероятно, как намеренное изменение политики с момента запуска в феврале 2026 года.
Стратегия 3: Используйте «illustration» или «diagram» для образовательного контента. Медицинские, анатомические и научные изображения часто активируют IMAGE_SAFETY при запросе в формате фотографии, но проходят при запросе как диаграмма или учебная иллюстрация. Если ваше приложение генерирует образовательный контент, всегда формулируйте запрос как «medical textbook diagram», «scientific illustration» или «educational schematic». Это соответствует тому, как классификатор обучен различать образовательный и потенциально вредный визуальный контент. Для разработчиков, работающих с контентом на границе фильтров безопасности, эта техника перефразирования незаменима.
Стратегия 4: Избегайте всех реальных имён и брендированного контента. Nano Banana 2 применяет особо строгую фильтрацию к запросам, связанным с реальными людьми, знаменитостями, публичными персонами и узнаваемыми торговыми марками или логотипами. Никогда не включайте имя реального человека в промпт генерации изображений — вместо этого опишите архетип или роль. Аналогично избегайте упоминания конкретных торговых марок, названий продуктов или защищённых визуальных элементов. Если вам нужно нечто, похожее на эстетику конкретного бренда, описывайте визуальный стиль абстрактно: «a minimalist tech company logo with geometric shapes» вместо ссылки на конкретную компанию. Это существенное изменение по сравнению с более ранними моделями, которое застаёт многих разработчиков врасплох при переходе на NB2.
Стратегия 5: Добавляйте негативные квалификаторы безопасности. Явное добавление фраз вроде «no violence», «peaceful scene», «fully clothed» или «family-friendly» в промпты действует как дополнительный сигнал для классификатора безопасности. Хотя это может казаться избыточным — вы ведь не запрашиваете жестокий контент — классификатор использует эти явные сигналы для корректировки своих оценок уверенности. Думайте об этом как о предоставлении классификатору положительных свидетельств намерения вместо опоры на отсутствие негативных сигналов.
Стратегия 6: Разбивайте сложные сцены на составные элементы. Один сложный промпт, описывающий множество элементов — «a crowded nightclub with people dancing and drinks flowing, neon lights, realistic photo» — объединяет несколько пограничных элементов, которые по отдельности могут пройти, но вместе активируют фильтр. Классификатор безопасности, по-видимому, использует кумулятивную оценку риска, при которой каждый потенциально чувствительный элемент добавляется к общей оценке, превышающей порог, даже когда ни один отдельный элемент не вызвал бы блокировку сам по себе. Вместо этого генерируйте фоновую сцену и персонажей отдельно, или упрощайте композицию для снижения числа потенциально проблемных элементов в запросе. Например, вместо описания ночного клуба можно сгенерировать «a modern interior with neon lighting and geometric decor, digital art» — убрав людей и конкретную деятельность. Такой подход жертвует эффективностью промпта ради надёжности, и на практике более простые композиции часто дают лучшие визуальные результаты, поскольку модель может сосредоточить качество на меньшем числе элементов.
Стратегия 7: Предварительный скрининг текстовой генерацией. Прежде чем вкладываться в полный вызов генерации изображения (который стоит $0,067-$0,151), отправьте тот же промпт текстовой модели Gemini с просьбой оценить, активирует ли промпт фильтры безопасности. Текстовый вызов стоит доли цента — обычно менее $0,001 — и может спасти вас от оплаты гарантированного отклонения. Это особенно ценно для пользовательских промптов, где невозможно предсказать контент заранее. Реализация проста: отправьте промпт вида «Would this image generation prompt trigger Google's safety filters? Respond YES or NO with a brief reason: [ваш промпт]» в Gemini Flash (текстовый режим). Модель предварительного скрининга не идеально предсказывает поведение Layer 2, поскольку использует другой путь оценки безопасности, но она перехватывает примерно 70% промптов, которые были бы заблокированы, согласно тестированию сообщества разработчиков. Для приложений, обрабатывающих тысячи пользовательских промптов в день, один этот шаг предварительного скрининга может сэкономить сотни долларов в месяц, отфильтровывая наиболее очевидно проблемные запросы до их попадания в дорогостоящий конвейер генерации изображений.
Когда NB2 слишком строг — сравнение альтернативных моделей
Если ваш сценарий использования стабильно наталкивается на блокировки IMAGE_SAFETY несмотря на применение описанных выше стратегий промптов, Nano Banana 2 может оказаться не лучшей моделью для вашего приложения. Различные модели генерации изображений имеют различную философию фильтров безопасности, и некоторые значительно более лояльны для определённых категорий контента.
DALL-E 3, доступный через API OpenAI, использует другой подход к безопасности, который в целом менее ограничителен для художественного и креативного контента, но более строг к фотореалистичным человеческим лицам. Его цена выше — примерно $0,040-$0,080 за изображение в зависимости от разрешения, — но более низкий процент отказов для креативного контента может сделать его дешевле по стоимости за успешное изображение для определённых сценариев. Midjourney v6 — наиболее лояльная из крупных коммерческих моделей для художественного и креативного контента, хотя доступ к API ограничен их платформой с другой моделью ценообразования через уровни подписки. Flux 2 (от Black Forest Labs) предлагает дружественный к разработчикам подход с более гранулярными настройками безопасности и более низкой частотой фильтрации для безвредного контента — он особенно силён в модной индустрии, дизайне персонажей и креативных портретах, где фильтры NB2 наиболее агрессивны. GPT Image (модель gpt-image-1 от OpenAI) предлагает ещё одну альтернативу с умеренной фильтрацией безопасности и сильным пониманием промптов. Для полного сравнения этих моделей по качеству, скорости, ценам и строгости фильтров безопасности обратитесь к нашему детальному сравнению моделей.
Практическая система принятия решений зависит от ваших конкретных потребностей в контенте и экономики отказов. Если ваше приложение генерирует деловую графику, маркетинговые материалы или абстрактное искусство, фильтры NB2 редко вмешиваются, и его преимущество в скорости (обычно 2-4 секунды на генерацию) делает его лучшим выбором для сценариев с большим объёмом. Если ваше приложение связано с дизайном персонажей, модой или креативными портретами, процент IMAGE_SAFETY может быть достаточно высоким — иногда превышая 30-40% запросов — чтобы менее ограничительная модель оказалась более рентабельной даже при более высокой цене за изображение, просто потому что вы не платите за отклонения. Критическая метрика — эффективная стоимость за успешное изображение (общие расходы, делённые на успешные генерации), а не сравнение прайс-листов. Модель, которая стоит вдвое дороже за изображение, но имеет нулевой процент отклонений, дешевле NB2, если более половины ваших запросов к NB2 фильтруются.
Рассмотрите возможность внедрения стратегии многоуровневой маршрутизации для продакшен-приложений. Начинайте с NB2 для каждого запроса, поскольку он предлагает лучшее соотношение цены и производительности при прохождении фильтра. Если первая попытка возвращает IMAGE_SAFETY, автоматически перенаправляйте запрос на резервную модель вместо повторной попытки с тем же промптом на NB2. Такой подход использует преимущество NB2 в стоимости для большинства запросов, избегая при этом растущих расходов от повторных отклонений. Логика маршрутизации добавляет минимальную задержку (несколько сотен миллисекунд на решение о резерве), но может снизить эффективную стоимость за изображение на 20-40% для приложений со смешанными типами контента.
Для разработчиков, стремящихся минимизировать риски миграции, такие платформы, как laozhang.ai, предоставляют унифицированный API с поддержкой нескольких моделей генерации изображений через единый эндпоинт. Это позволяет реализовать автоматический фолбэк: сначала пробовать NB2 для его преимущества в скорости и стоимости, а при блокировке IMAGE_SAFETY автоматически перенаправлять на альтернативную модель. Такой подход использует скорость NB2 для большинства запросов, избегая расходов на повторные отклонения.
Часто задаваемые вопросы
Почему Nano Banana 2 возвращает 200 OK при заблокированном изображении?
Google спроектировал Gemini API таким образом, чтобы возвращать HTTP 200 для любого запроса, который был успешно получен и обработан сервером, независимо от того, был ли выходной контент отфильтрован системой безопасности. С точки зрения проектирования API Google, сервер успешно обработал ваш запрос — фильтр безопасности является решением на уровне приложения, а не ошибкой транспортного уровня. Поле finishReason в теле ответа указывает фактический результат попытки генерации контента. Такой дизайн отличается от подхода большинства REST API к фильтрации контента — такие сервисы, как DALL-E от OpenAI, возвращают коды ошибок 4xx при блокировках безопасности — и является основным источником путаницы для разработчиков, впервые интегрирующих NB2. Практический вывод: нельзя полагаться только на проверку HTTP-статус-кода; необходимо всегда парсить тело ответа и проверять поле finishReason.
Отключает ли BLOCK_NONE все фильтры безопасности?
Нет. BLOCK_NONE влияет только на вероятностные фильтры Layer 1 (HARASSMENT, HATE_SPEECH, SEXUALLY_EXPLICIT, DANGEROUS_CONTENT). Жёстко закодированные фильтры Layer 2 (IMAGE_SAFETY, PROHIBITED_CONTENT, CSAM, SPII) остаются активными вне зависимости от конфигурации safetySettings. Это безусловная политика Google, которая применяется ко всем моделям генерации изображений Gemini (проверено по ai.google.dev/safety-settings, март 2026).
Взимается ли плата за ответы 200 OK без изображения?
Да. Любой ответ 200 OK, включая те, что содержат finishReason: "IMAGE_SAFETY", тарифицируется по стандартной ставке обработки токенов. Только серверные ошибки (429, 500, 503) не тарифицируются. Это означает, что каждая блокировка IMAGE_SAFETY обходится вам примерно в $0,067 за разрешение 1K или $0,151 за разрешение 4K (ai.google.dev/pricing, март 2026).
В чём разница между значениями finishReason SAFETY и IMAGE_SAFETY?
SAFETY указывает на блокировку Layer 1 (настраиваемый, исправляется через safetySettings). IMAGE_SAFETY указывает на блокировку Layer 2 (ненастраиваемый, исправляется перефразированием промпта). Оба приводят к ответам 200 OK без данных изображения, но стратегия исправления принципиально различается. Всегда проверяйте конкретное полученное значение, прежде чем определять подход к устранению проблемы.
Является ли Nano Banana 2 более строгим, чем оригинальный Nano Banana?
Да. Nano Banana 2 (gemini-3.1-flash-image-preview, запущен 27 февраля 2026) применяет более строгую фильтрацию Layer 2 по сравнению с оригинальной моделью Nano Banana, особенно для лиц знаменитостей, провокационного контента и брендированных изображений. Промпты, которые успешно генерировали изображения на оригинальной модели, могут активировать IMAGE_SAFETY на NB2 без каких-либо изменений текста промпта.
Итоги и дальнейшие шаги
Проблема «200 OK без изображения» в Nano Banana 2 — это не баг, а намеренное проектное решение Google, при котором фильтрация контента происходит на уровне приложения, тогда как HTTP-транспорт сообщает об успехе. Главные выводы из этого руководства: во-первых, всегда проверяйте finishReason в каждом ответе API вместо того, чтобы доверять HTTP-статус-коду; во-вторых, поймите, что фильтры Layer 2 (IMAGE_SAFETY) невозможно отключить, и они требуют исправлений на уровне промпта; в-третьих, отслеживайте процент отказов и рассчитывайте влияние на биллинг, поскольку отфильтрованные ответы 200 OK тарифицируются по полной ставке.
Ваши первоочередные действия: внедрите парсинг finishReason в код приложения с использованием предоставленных выше шаблонов для Python или Node.js, применяйте стратегию префикса художественного стиля к наиболее частым шаблонам промптов (одно это снижает отказы на 40-60%) и настройте мониторинг процента отказов IMAGE_SAFETY для раннего обнаружения как проблем с промптами, так и ужесточения фильтров со стороны Google. Для приложений с высоким процентом фильтрации рассчитайте эффективную стоимость за успешное изображение и оцените, снизит ли стратегия мультимодельного фолбэка общие расходы.
По мере развития Google конвейера генерации изображений Gemini поведение фильтра Layer 2 будет эволюционировать. Лучшая защита — устойчивая архитектура приложения, которая мгновенно обнаруживает отфильтрованные ответы, логирует контекст для анализа и перенаправляет на альтернативы при необходимости. Разработчики, которые рассматривают IMAGE_SAFETY как задачу проектирования системы, а не досадное ограничение, создают приложения, работающие надёжно вне зависимости от того, как Google корректирует пороги безопасности.