Ошибки Gemini Image API делятся на три категории: ограничения скорости 429 (вызванные нулевым лимитом тарификации, превышением IPM, ошибкой Ghost Bug или динамической общей квотой), скрытые сбои генерации (неверный endpoint, неправильная настройка responseModalities или отсутствие тарификации) и проблемы с параметрами (imageConfig игнорируется, регистрозависимость image_size, отсутствие TEXT в responseModalities). Начните с проверки панели квот в GCP Console, затем убедитесь, что тарификация включена — бесплатный уровень IPM равен 0 с 7 декабря 2025 года. Используйте правильный endpoint /v1beta/ с responseModalities: ["TEXT", "IMAGE"].
Краткое содержание
Три категории ошибок — три пути диагностики. Ошибки 429 имеют четыре различные первопричины, каждая из которых требует своего решения — не стоит просто «ждать и повторять попытку», не определив тип. Скрытые сбои (HTTP 200 без изображения в ответе) почти всегда вызваны неправильной настройкой responseModalities. Сбои параметров (настройки приняты, но проигнорированы) обычно связаны с регистром в image_size или удалением imageConfig промежуточным слоем. Проверяйте тарификацию в первую очередь, затем endpoint, затем параметры — именно в таком порядке.
Понимание ошибок Gemini Image API: карта диагностики
Когда генерация изображений Gemini перестаёт работать, разработчики, как правило, сталкиваются с одним из трёх различных режимов сбоя, каждый из которых требует совершенно иного подхода к диагностике. Первый режим — жёсткая ошибка: ваш вызов API возвращает HTTP 429 или HTTP 400, запрос отклоняется до начала любой генерации. Второй — скрытый сбой, когда вызов успешно завершается с кодом HTTP 200, но ответ не содержит данных изображения. Третий — ошибка конфигурации, когда изображения генерируются успешно, но результат не соответствует заданным настройкам: неверное разрешение, неверное соотношение сторон или совершенно другие параметры, чем указанные.
Понимание того, в каком режиме сбоя вы находитесь, является критически важным первым шагом. Неправильная идентификация уводит разработчиков по неверному пути диагностики, теряя часы. Таблица ниже сопоставляет каждый тип ошибки с HTTP-статусом, кодом gRPC-статуса и разделом этого руководства, в котором он рассматривается.
| Тип ошибки | HTTP-статус | gRPC-статус | Типичный симптом | Раздел руководства |
|---|---|---|---|---|
| Лимит тарификации = 0 | 429 | RESOURCE_EXHAUSTED | Бесплатный уровень, нет изображений | Раздел 2 |
| Превышение лимита IPM | 429 | RESOURCE_EXHAUSTED | Генерирует, затем сбой | Раздел 2 |
| Ошибка Ghost 429 | 429 | RESOURCE_EXHAUSTED | После обновления тарификации | Раздел 2 |
| Динамическая общая квота | 429 | RESOURCE_EXHAUSTED | Трафик модели предварительного просмотра | Раздел 2 |
| Неверный responseModalities | 200 | — | Пустой массив parts[] | Раздел 3 |
| Неверный endpoint | 404/400 | NOT_FOUND | Неподдерживаемая операция | Раздел 3 |
| Неверное имя модели | 400 | INVALID_ARGUMENT | Модель не найдена | Раздел 3 |
| Тарификация не включена | 400 | FAILED_PRECONDITION | Явное сообщение об ошибке | Раздел 3 |
| Ошибка регистра image_size | 200 | — | Неверное разрешение вывода | Раздел 4 |
| imageConfig удалён | 200 | — | Конфигурация молча проигнорирована | Раздел 4 |
| Отсутствие модальности TEXT | 200 | — | Пустой ответ | Раздел 4 |
Для общих ошибок Gemini API, не связанных с изображениями, наше общее руководство по устранению ошибок Gemini API охватывает весь спектр ошибок, не связанных с изображениями. Эта статья посвящена исключительно трём категориям ошибок, уникальным для генерации изображений — ошибкам, которые не рассматриваются в общих руководствах по Gemini API. Image API имеет собственное измерение квот (IPM — изображений в минуту), собственные обязательные параметры и собственные endpoint-ы моделей, неприменимые к генерации текста.
Важнейший принцип диагностики: никогда не считайте ошибку 429 просто «ограничением скорости», которое нужно переждать. Четыре совершенно разные первопричины дают идентичные ответы 429, и ожидание — правильный ответ лишь для одной из них. Аналогично, никогда не считайте успешный HTTP 200 подтверждением того, что ваше изображение было сгенерировано — код 200 может скрывать ошибку конфигурации, приводящую к пустому ответу.
Ошибка 429: четыре первопричины, четыре разных решения
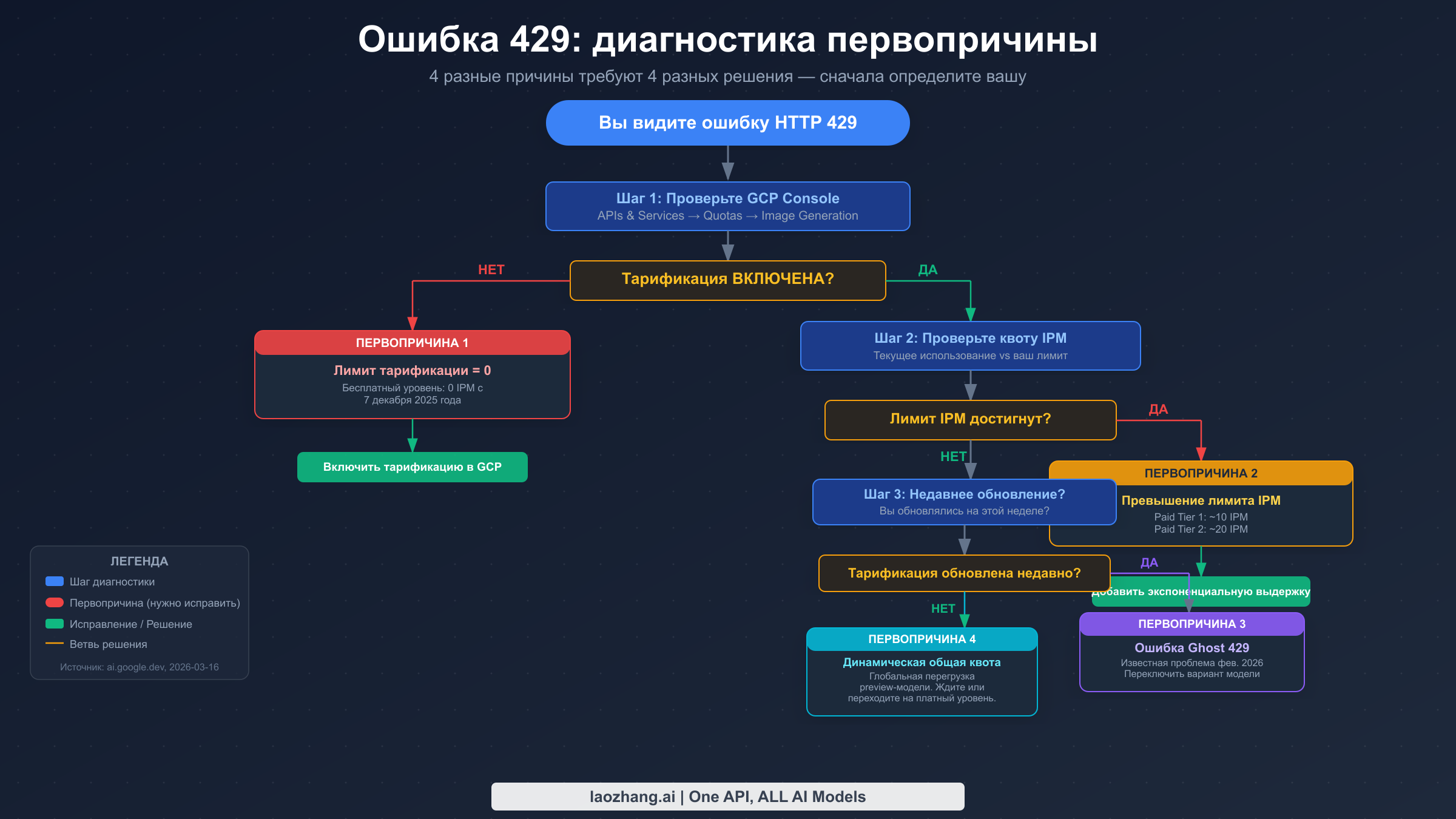
Ошибка 429 RESOURCE_EXHAUSTED — наиболее распространённая ошибка Gemini Image API, но она вводит в заблуждение, так как выглядит идентично вне зависимости от того, какая из четырёх совершенно разных проблем её вызвала. С ней сталкивается каждый разработчик Gemini Image, и почти все материалы в интернете трактуют её как единую проблему — «вы превысили лимит скорости». Такой подход приводит к потере времени, поскольку четыре первопричины имеют четыре совершенно разных решения, и применение неправильного решения не поможет.
Первопричина 1: лимит тарификации = 0 (бесплатный уровень)
Наиболее распространённой причиной ошибки 429 для новых разработчиков является самая простая: с 7 декабря 2025 года бесплатный уровень имеет квоту на изображение (IPM) равную нулю (проверено по документации Firebase AI Logic, 2026-03-16). Это означает, что аккаунты бесплатного уровня не могут генерировать какие-либо изображения через API — не низкий лимит, а именно ноль. При этом ошибка 429 говорит не о том, что вы «превысили лимит», а о том, что ваш лимит уже равен нулю.
Чтобы убедиться, что это ваш случай, перейдите в GCP Console → APIs & Services → Generative Language API → Quotas and Limits. Отфильтруйте по «image» и посмотрите на квоту IPM (Images Per Minute). Если она показывает 0, у вас Первопричина 1. Решение — включить тарификацию в вашем проекте Google Cloud и перейти как минимум на Paid Tier 1. Обратите внимание, что включение тарификации не всегда немедленно восстанавливает квоту — может быть задержка распространения 15-30 минут.
Первопричина 2: превышение лимита IPM (платный уровень)
После включения тарификации у вас есть поминутная квота на генерацию изображений. По данным нашего подробного руководства по ограничению скорости 429 для Gemini Image, Paid Tier 1 поддерживает приблизительно 10 IPM (изображений в минуту), а Paid Tier 2 — приблизительно 20 IPM. Это отличается от RPM (запросов в минуту) — у моделей изображений есть собственная отдельная квота IPM, применяемая исключительно к вызовам генерации изображений.
Диагностический признак Первопричины 2 — паттерн: ваше приложение работает нормально изначально, затем начинает получать ошибки 429 после генерации нескольких изображений подряд. Панель квот в GCP Console покажет, что ваше текущее использование приближается к лимиту IPM или достигло его. Решение — экспоненциальная выдержка: начните с задержки 2 секунды после первой ошибки 429, удваивая при каждой повторной попытке (2с, 4с, 8с, 16с). Задания пакетной обработки должны заранее рассчитывать задержку, необходимую для соблюдения лимитов IPM, а не ждать достижения лимита и реагировать с запозданием.
Первопричина 3: ошибка Ghost 429 (февраль 2026 года)
Эта ошибка затрагивает аккаунты, недавно обновившие уровень тарификации. Симптом: ошибки 429 сохраняются даже после успешного обновления тарификации — GCP Console показывает ненулевую квоту IPM, тарификация включена, но генерация изображений по-прежнему возвращает 429. Google подтвердил это как известную проблему на форуме AI Developers в феврале 2026 года. Ошибка затрагивает уровень применения квот для аккаунта, где новое распределение квот некорректно распространяется.
Временное решение — переключиться на другой вариант модели. Если вы используете gemini-3.1-flash-image-preview, попробуйте переключиться на gemini-2.5-flash-image или наоборот. Во многих случаях это позволяет обойти затронутый путь применения квот. Кроме того, ожидание 24-48 часов часто решает проблему по мере завершения распространения квот. Если ошибка сохраняется, обращение в службу поддержки Google Cloud с явным указанием на проблему Ghost 429 февраля 2026 года ускоряет решение.
Для ошибок 503 перегрузки, которые могут выглядеть похоже, смотрите наше руководство по устранению ошибок 503 перегрузки.
Первопричина 4: динамическая общая квота (модели предварительного просмотра)
Модели предварительного просмотра — gemini-3.1-flash-image-preview и gemini-3-pro-image-preview — не используют поквотное распределение на проект, как производственные модели. Вместо этого они используют то, что Google называет Dynamic Shared Quota (динамическая общая квота): доступная мощность распределяется между всеми пользователями модели предварительного просмотра глобально, и ошибки 429 возникают при высокой глобальной загруженности системы, независимо от вашего индивидуального уровня использования. Google подтвердил такое поведение в теме поддержки от 29 января 2026 года на support.google.com.
Это единственная первопричина, при которой ожидание действительно является правильным ответом. Ошибка 429 возникает не из-за ваших действий — это временное ограничение глобальной мощности модели предварительного просмотра. Экспоненциальная выдержка с более длинными задержками (начиная с 5 секунд вместо 2) работает здесь. Для производственных приложений с требованиями к надёжности правильным архитектурным решением является использование производственной модели, такой как gemini-2.5-flash-image, или Vertex AI с выделенной пропускной способностью, что даёт вам выделенные мощности вместо общих.
Вот полная реализация экспоненциальной выдержки, которая определяет, с каким типом ошибки 429 вы столкнулись:
pythonimport time import google.generativeai as genai def generate_image_with_backoff(prompt: str, max_retries: int = 5) -> dict: """Generate image with exponential backoff for 429 errors.""" client = genai.GenerativeModel("gemini-3.1-flash-image-preview") for attempt in range(max_retries): try: response = client.generate_content( contents=prompt, generation_config={ "responseModalities": ["TEXT", "IMAGE"], } ) return response except Exception as e: error_str = str(e) if "429" not in error_str and "RESOURCE_EXHAUSTED" not in error_str: raise # Not a rate limit error if attempt == max_retries - 1: raise # Exhausted retries # Exponential backoff: 2s, 4s, 8s, 16s, 32s delay = 2 ** (attempt + 1) print(f"429 on attempt {attempt + 1}, waiting {delay}s...") time.sleep(delay) raise Exception("Max retries exceeded")
Генерация изображений ничего не возвращает: устранение скрытых сбоев
Скрытые сбои — наиболее неприятный тип ошибок Gemini Image, потому что они не дают никакой полезной обратной связи. Ваш вызов API возвращает HTTP 200 (успех), ответ является корректным JSON, но когда вы ищете данные изображения, массив parts пустой или содержит только текст. Исключение не выбрасывается, сообщение об ошибке не объясняет, что пошло не так. Эта категория сбоев имеет четыре различные причины, каждая из которых требует отдельного расследования.
Наиболее распространённая причина: неправильная настройка responseModalities
Наиболее частый скрытый сбой происходит из-за единственного пропущенного слова в конфигурации. Gemini Image API требует, чтобы responseModalities включал как "TEXT", так и "IMAGE" — указание только ["IMAGE"] приводит к успешному HTTP 200 с пустым массивом parts. Исключение не выбрасывается. API принимает запрос, обрабатывает его и возвращает ничего полезного, не объясняя почему.
Это требование задокументировано в официальной документации по генерации изображений Gemini (ai.google.dev/gemini-api/docs/image-generation, проверено 2026-03-16), но многие разработчики сталкиваются с этим, потому что примеры из неофициальных источников показывают только ["IMAGE"], или они предполагают, что указания модальности "IMAGE" достаточно, поскольку именно это им нужно. Правильная конфигурация:
pythongeneration_config = { "responseModalities": ["TEXT", "IMAGE"], # Both required "imageConfig": { "image_size": "1K" # Note: uppercase K } }
Почему требуется TEXT? Модели изображений Gemini являются мультимодальными по своей конструкции — они генерируют текстовый ответ вместе с изображением (обычно описание или подпись). API построен вокруг этой модели двойного вывода, и попытка подавить текстовый вывод, опустив TEXT из responseModalities, приводит к сбою всего ответа, а не к возврату только изображения. В настоящее время нет способа получить вывод только изображения без включения TEXT в список модальностей.
Неверный endpoint API
Некоторые разработчики интегрируют генерацию изображений Gemini через совместимые с OpenAI клиенты или используют endpoint /v1/ вместо /v1beta/. Gemini Image Generation API требует пути endpoint /v1beta/. Запросы к совместимому с OpenAI endpoint (/v1/images/generations) или стабильному пути /v1/ возвращают либо ошибки 404, либо явные сообщения «неподдерживаемая операция».
Правильная структура endpoint:
POST https://generativelanguage.googleapis.com/v1beta/models/{model-name}:generateContent
Если вы используете совместимую с OpenAI библиотеку с Gemini, убедитесь, что базовый URL настроен правильно. Многие разработчики, использующие Python-библиотеку openai с Gemini, изменяют base_url, чтобы указать на серверы Gemini, но если они указывают на путь /v1/, модели изображений окажутся недоступными.
Неверное имя модели
Три текущие модели изображений Gemini имеют конкретные имена, которые необходимо использовать точно так, как задокументировано. На момент написания (проверено по ai.google.dev, 2026-03-16) текущие имена моделей таковы:
gemini-3.1-flash-image-preview— быстрая генерация, модель предварительного просмотраgemini-3-pro-image-preview— высокое качество, модель предварительного просмотраgemini-2.5-flash-image— эффективная, стабильная модель
К распространённым ошибкам относится использование gemini-2.5-flash-preview-image (неверный порядок суффикса), gemini-flash-image (отсутствует версия) или устаревших имён моделей. Ошибки в именах моделей обычно возвращают 400 INVALID_ARGUMENT или 404 NOT_FOUND — они обычно не производят скрытый ответ 200. Но они вызывают сбой генерации с другой сигнатурой ошибки, отличной от ограничений скорости.
Тарификация не включена: ошибка 400, которую можно принять за ошибку конфигурации
Когда тарификация не включена и вы превысили нулевую квоту бесплатного уровня, можно ожидать чёткой ошибки. Gemini Image API фактически возвращает HTTP 400 со статусом gRPC FAILED_PRECONDITION и сообщением, включающим слово «billing». Это отличается от ошибки 429, которую вы получили бы, если бы тарификация была включена, но квота исчерпана. Статус FAILED_PRECONDITION означает, что предусловие для операции не выполнено — в данном случае предусловием является то, что тарификация должна быть включена для использования Image Generation API вообще.
Если вы видите FAILED_PRECONDITION в ответе об ошибке, решение всегда одно — включить тарификацию в GCP Console, а не изменять параметры API. Эта ошибка не будет устранена изменением responseModalities или imageConfig.
Параметры, которые молча не работают: imageConfig и responseModalities

Сбои параметров — особая категория неудобств с Gemini Image API, поскольку API принимает ваш запрос без жалоб, генерирует изображение и возвращает его — но изображение не соответствует вашим спецификациям. Вы запросили разрешение 2K и получили 512px. Вы задали соотношение сторон и получили 1:1. Вы настроили imageConfig и это не дало эффекта. API не отклонил ваши параметры; он просто проигнорировал их.
Ловушка регистрозависимости image_size
Параметр image_size внутри imageConfig чувствителен к регистру неочевидным образом. Допустимые значения используют заглавную «K» — "512", "1K", "2K", "4K". Использование строчной "1k" не вызывает ошибки; значение молча откатывается до разрешения по умолчанию (512px). Это означает, что вы можете написать, казалось бы, правильный код, протестировать его и никогда не осознать, что ваша настройка разрешения игнорируется.
Эта конкретная проблема проверена по официальной документации Gemini API (ai.google.dev, 2026-03-16). Ловушка особенно коварна для разработчиков, пришедших из языков или API со строчными соглашениями, где строковые значения нечувствительны к регистру. В ответе нет предупреждения о том, что ваше "1k" было недопустимым — изображение просто получается меньше ожидаемого.
Полный список допустимых значений image_size: "512", "1K", "2K", "4K". Параметр соотношения сторон (aspect_ratio) принимает "1:1", "3:4", "4:3", "9:16", "16:9" — они нечувствительны к регистру и используют обозначение через двоеточие.
Почему responseModalities должен включать TEXT
Как упоминалось в разделе о скрытых сбоях, responseModalities должен включать как "TEXT", так и "IMAGE". Но есть дополнительный нюанс относительно порядка параметров. Массив responseModalities должен перечислять "TEXT" первым, а "IMAGE" вторым — хотя API в настоящее время принимает любой порядок, задокументированный порядок — ["TEXT", "IMAGE"], и отклонение от него может вызвать проблемы в будущих версиях API. Это мелочь, но производственный код должен следовать задокументированному соглашению.
python"responseModalities": ["TEXT", "IMAGE"] # Accepted but not recommended "responseModalities": ["IMAGE", "TEXT"] # WRONG - silently returns empty response "responseModalities": ["IMAGE"] # WRONG - no images even requested "responseModalities": ["TEXT"]
Удаление imageConfig промежуточным слоем
Это наиболее тонкий режим сбоя параметров. При использовании промежуточных слоёв, таких как LiteLLM, для проксирования вызовов Gemini API параметр imageConfig часто удаляется из запроса до его достижения Gemini API. Проблема LiteLLM GitHub #18656 документирует это поведение — LiteLLM нормализует параметры к своему внутреннему формату, и imageConfig не переживает эту нормализацию.
Симптом: ваши изображения генерируются, но настройки разрешения и соотношения сторон не дают эффекта. Решение — обходить промежуточный слой для генерации изображений Gemini и использовать нативный HTTP API напрямую. Если вам необходимо использовать LiteLLM или аналогичные инструменты для вашей инфраструктуры, вам нужно будет маршрутизировать запросы генерации изображений напрямую, направляя генерацию текста через промежуточный слой.
Вот как вызвать API напрямую, обходя любой промежуточный слой:
pythonimport requests import base64 def generate_image_direct(prompt: str, api_key: str, size: str = "1K") -> bytes: """Direct HTTP call to Gemini Image API — bypasses middleware.""" url = "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent" headers = {"Content-Type": "application/json"} params = {"key": api_key} payload = { "contents": [{"parts": [{"text": prompt}]}], "generationConfig": { "responseModalities": ["TEXT", "IMAGE"], "imageConfig": { "image_size": size, # Must be "512", "1K", "2K", or "4K" "aspect_ratio": "16:9" # Optional } } } response = requests.post(url, json=payload, headers=headers, params=params) response.raise_for_status() data = response.json() for part in data["candidates"][0]["content"]["parts"]: if "inlineData" in part: return base64.b64decode(part["inlineData"]["data"]) raise ValueError("No image data in response — check responseModalities config")
Обратите внимание, что generationConfig оборачивает imageConfig в прямых HTTP-запросах. Некоторые версии SDK используют плоский словарь generation_config, но нативный REST API использует вложенную структуру, показанную выше. Это ещё один источник путаницы с параметрами — интерфейс SDK не всегда совпадает с базовой структурой HTTP-запроса.
Проверка квоты: руководство по диагностике в GCP Console
Понимание вашей ситуации с квотой необходимо для диагностики ошибок 429, но многие разработчики не знают, где найти точную информацию о квотах или что означают цифры. GCP Console содержит авторитетные данные, но навигация до них неочевидна.
Поиск квоты на генерацию изображений
Точный путь навигации в GCP Console (проверено 2026-03-16):
- Перейдите на console.cloud.google.com
- Выберите ваш проект из выпадающего списка в верхней части
- Перейдите в APIs & Services → Generative Language API
- Нажмите Quotas and System Limits в левой боковой панели
- В строке фильтра введите «image» для фильтрации по квотам, специфичным для изображений
Просмотр квот показывает несколько измерений. Для генерации изображений критически важным является IPM (Images Per Minute) — это измерение, по которому ограничивается генерация изображений Gemini. Не путайте его с RPM (Requests Per Minute), которое регулирует вызовы генерации текста и не является ограничивающим фактором для вызовов Image API.
Понимание измерений квот
Модели изображений Gemini имеют три измерения квот:
| Измерение | Что ограничивает | Типичный охват |
|---|---|---|
| RPM (запросов в минуту) | Вызовы API в минуту | Общее с текстовыми моделями |
| RPD (запросов в день) | Вызовы API в день | Модели предварительного просмотра: 1500/день |
| IPM (изображений в минуту) | Изображений в минуту | Только для изображений; наиболее критично |
По состоянию на 7 декабря 2025 года IPM бесплатного уровня равен 0 — это означает, что бесплатные аккаунты не могут генерировать какие-либо изображения через API. Это было изменением по сравнению с предыдущим бесплатным уровнем, который допускал ограниченную генерацию изображений. Если вы обновились до этой даты и у вас унаследованная квота, GCP Console покажет вашу текущую норму. Если вы создали аккаунт или впервые включили API после 7 декабря 2025 года, ваш IPM будет равен 0 до включения тарификации.
Для аккаунтов Paid Tier 1 (тарификация включена, ниже пороговых значений Tier 2), проверенные данные из нашего анализа SERP (wentuo.ai, документация Firebase, 2026-03-16) показывают приблизительно 10 IPM. Paid Tier 2 (более высокий объём использования) обеспечивает приблизительно 20 IPM. Vertex AI с выделенной пропускной способностью даёт выделенную квоту, согласованную с Google, устраняя ограничения общего пула.
Интерпретация панели квот
Панель квот показывает текущее использование в процентах от лимита. Значение «100%» означает, что вы достигли лимита для данного временного окна. Важно: сброс квот происходит по скользящим окнам, а не по фиксированным часовым минутам. Ваша квота IPM рассчитывается по скользящему 60-секундному окну, поэтому если вы сгенерировали 10 изображений в 12:00:00 и находитесь на Paid Tier 1 (лимит 10 IPM), вы не сможете генерировать больше до 12:01:00.
Если квота показывает 0%, но вы всё равно получаете ошибки 429, это сильный диагностический сигнал либо ошибки Ghost 429 (Первопричина 3 из Раздела 2), либо проблемы распространения квот после недавнего изменения тарификации. В таком случае подождите 15-30 минут для распространения изменений квот, и если проблема сохраняется более нескольких часов, обратитесь к рекомендациям по Ghost 429 в Разделе 2.
Выбор правильного уровня для генерации изображений Gemini
Используемый уровень имеет существенное значение как для стоимости, так и для надёжности, особенно для производственных приложений. Понимание компромиссов помогает принять правильное инфраструктурное решение, а не обнаруживать ограничения под производственной нагрузкой.
| Уровень | IPM | RPM | RPD | Лучшее применение |
|---|---|---|---|---|
| Бесплатный | 0 | 10 | 1500 | Только обучение (нет изображений) |
| Paid Tier 1 | ~10 | 10 | 1500 | Лёгкое производственное использование |
| Paid Tier 2 | ~20 | 20+ | 3000+ | Умеренное производство |
| Vertex AI | По согласованию | По согласованию | По согласованию | Высоконагруженное производство |
Модели предварительного просмотра vs. производственные модели
Модели gemini-3.1-flash-image-preview и gemini-3-pro-image-preview являются моделями предварительного просмотра — они работают на Dynamic Shared Quota и не предоставляют тех же гарантий надёжности, что и производственные модели. Для возможностей генерации изображений Gemini только gemini-2.5-flash-image является стабильной (не предварительной) моделью на момент написания.
Для производственных сценариев использования это важно по двум причинам. Во-первых, ошибки 429 у моделей предварительного просмотра могут возникать даже тогда, когда вы находитесь в пределах личной квоты — они отражают глобальную загруженность, а не ваше использование. Во-вторых, модели предварительного просмотра могут быть изменены или объявлены устаревшими без полного предварительного уведомления, предоставляемого производственным моделям. Если вы создаёте что-то, что должно надёжно работать месяцами, стабильная модель является лучшей основой, даже если она имеет несколько иные возможности. Полный обзор возможностей моделей предварительного просмотра см. в нашем руководстве по возможностям модели Gemini 3.1 Flash Image Preview.
Когда стоит рассмотреть альтернативных провайдеров API
Если вам нужна более высокая пропускная способность, чем предоставляют уровни AI Studio, но вы ещё не готовы к полной интеграции Vertex AI, сторонние агрегаторы API, такие как laozhang.ai, предлагают модели изображений Gemini с иными структурами ограничения скорости. Это может быть полезно для разработки, тестирования или дополнения основного доступа к API в периоды пиковой нагрузки. Подход через агрегатор добавляет сетевой переход и не должен быть вашей основной производственной инфраструктурой для критических приложений, но может служить полезным резервом, когда основная квота исчерпана.
Для промышленной генерации изображений Vertex AI с выделенной пропускной способностью является правильным долгосрочным решением — вы договариваетесь о выделенных мощностях, а не конкурируете с другими пользователями в общих пулах квот.
Готовый к производству код обработки ошибок
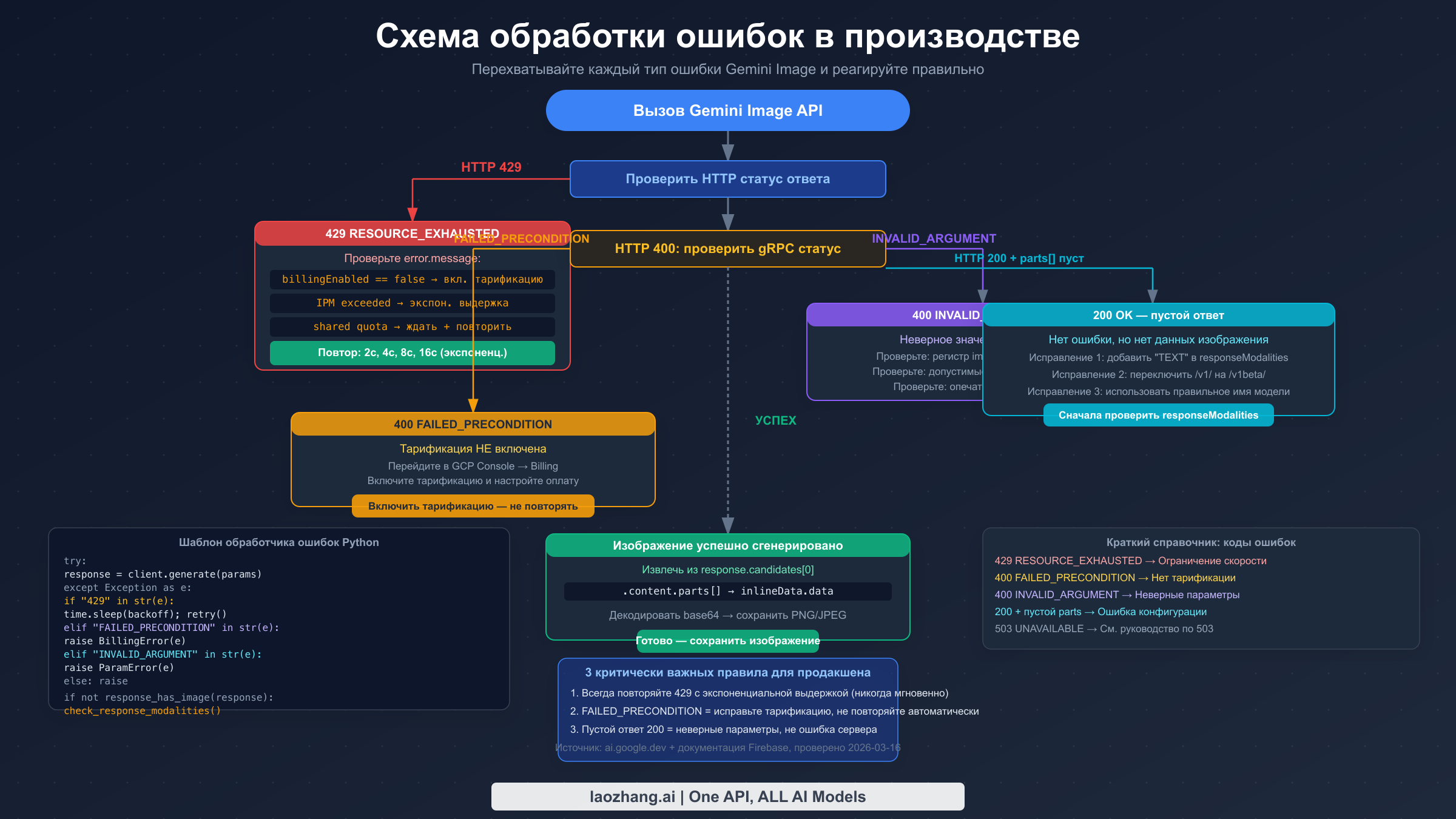
Промышленная генерация изображений Gemini требует систематической обработки всех трёх категорий ошибок. Код ниже предоставляет полную реализацию на Python с правильной классификацией ошибок, экспоненциальной выдержкой, валидацией параметров и обнаружением пустых ответов.
pythonimport time import base64 import requests from typing import Optional from dataclasses import dataclass # Valid parameter constants (from official docs, verified 2026-03-16) VALID_IMAGE_SIZES = {"512", "1K", "2K", "4K"} VALID_ASPECT_RATIOS = {"1:1", "3:4", "4:3", "9:16", "16:9"} GEMINI_IMAGE_ENDPOINT = ( "https://generativelanguage.googleapis.com/v1beta/models/" "{model}:generateContent" ) @dataclass class ImageGenerationError(Exception): """Base class for Gemini image generation errors.""" message: str error_type: str # "rate_limit", "billing", "parameter", "empty_response" retryable: bool def validate_image_config(image_size: str, aspect_ratio: Optional[str] = None): """Validate imageConfig parameters before API call.""" if image_size not in VALID_IMAGE_SIZES: raise ImageGenerationError( message=f"Invalid image_size '{image_size}'. Valid values: {VALID_IMAGE_SIZES}. " f"Note: case-sensitive — use '1K' not '1k'.", error_type="parameter", retryable=False ) if aspect_ratio and aspect_ratio not in VALID_ASPECT_RATIOS: raise ImageGenerationError( message=f"Invalid aspect_ratio '{aspect_ratio}'. Valid: {VALID_ASPECT_RATIOS}", error_type="parameter", retryable=False ) def classify_error(response_or_exception) -> ImageGenerationError: """Classify API error into actionable categories.""" if isinstance(response_or_exception, requests.Response): status = response_or_exception.status_code try: body = response_or_exception.json() error_msg = str(body.get("error", {}).get("message", "")) grpc_status = body.get("error", {}).get("status", "") except Exception: error_msg = response_or_exception.text grpc_status = "" else: error_msg = str(response_or_exception) status = 500 grpc_status = "" if status == 429 or "RESOURCE_EXHAUSTED" in grpc_status: return ImageGenerationError( message=f"Rate limit exceeded: {error_msg}", error_type="rate_limit", retryable=True ) elif "FAILED_PRECONDITION" in grpc_status or "billing" in error_msg.lower(): return ImageGenerationError( message="Billing not enabled. Enable billing in GCP Console.", error_type="billing", retryable=False # Retrying won't help — fix billing first ) elif "INVALID_ARGUMENT" in grpc_status or status == 400: return ImageGenerationError( message=f"Invalid parameter: {error_msg}", error_type="parameter", retryable=False ) else: return ImageGenerationError( message=f"Unexpected error ({status}): {error_msg}", error_type="unknown", retryable=False ) def generate_image( prompt: str, api_key: str, model: str = "gemini-3.1-flash-image-preview", image_size: str = "1K", aspect_ratio: Optional[str] = None, max_retries: int = 5, initial_backoff: float = 2.0 ) -> bytes: """ Generate image with full error handling. Returns raw image bytes (PNG format). Raises ImageGenerationError with retryable flag for caller to handle. """ # Validate parameters before making API call validate_image_config(image_size, aspect_ratio) url = GEMINI_IMAGE_ENDPOINT.format(model=model) headers = {"Content-Type": "application/json"} params = {"key": api_key} image_config = {"image_size": image_size} if aspect_ratio: image_config["aspect_ratio"] = aspect_ratio payload = { "contents": [{"parts": [{"text": prompt}]}], "generationConfig": { "responseModalities": ["TEXT", "IMAGE"], # Both required "imageConfig": image_config } } last_error = None for attempt in range(max_retries): try: response = requests.post( url, json=payload, headers=headers, params=params, timeout=60 ) if not response.ok: error = classify_error(response) if not error.retryable: raise error last_error = error backoff = initial_backoff * (2 ** attempt) print(f"Attempt {attempt + 1}: {error.error_type}, retrying in {backoff}s") time.sleep(backoff) continue # HTTP 200 — check for actual image data data = response.json() candidates = data.get("candidates", []) if not candidates: raise ImageGenerationError( message="No candidates in response. Check model name and quota.", error_type="empty_response", retryable=False ) parts = candidates[0].get("content", {}).get("parts", []) for part in parts: if "inlineData" in part: return base64.b64decode(part["inlineData"]["data"]) # 200 OK but no image data — common config error raise ImageGenerationError( message=( "HTTP 200 but no image in response. " "Verify responseModalities includes both 'TEXT' and 'IMAGE'. " "Check you're using /v1beta/ endpoint." ), error_type="empty_response", retryable=False ) except ImageGenerationError: raise # Don't retry non-retryable errors except requests.RequestException as e: last_error = classify_error(e) if attempt < max_retries - 1: backoff = initial_backoff * (2 ** attempt) time.sleep(backoff) raise last_error or ImageGenerationError( message="Max retries exceeded", error_type="rate_limit", retryable=True ) # Usage example if __name__ == "__main__": try: image_bytes = generate_image( prompt="A serene mountain lake at sunset", api_key="YOUR_API_KEY", model="gemini-3.1-flash-image-preview", image_size="1K", aspect_ratio="16:9" ) with open("output.png", "wb") as f: f.write(image_bytes) print("Image saved to output.png") except ImageGenerationError as e: print(f"Error type: {e.error_type}") print(f"Message: {e.message}") print(f"Retryable: {e.retryable}") if e.error_type == "billing": print("Action: Enable billing at console.cloud.google.com/billing") elif e.error_type == "parameter": print("Action: Fix parameters — check image_size casing and aspect_ratio format") elif e.error_type == "empty_response": print("Action: Add 'TEXT' to responseModalities and verify /v1beta/ endpoint")
Версия JavaScript/Node.js
javascriptconst fetch = require('node-fetch'); const VALID_IMAGE_SIZES = new Set(['512', '1K', '2K', '4K']); async function generateImage(prompt, apiKey, options = {}) { const { model = 'gemini-3.1-flash-image-preview', imageSize = '1K', aspectRatio = null, maxRetries = 5, } = options; if (!VALID_IMAGE_SIZES.has(imageSize)) { throw new Error(`Invalid imageSize '${imageSize}'. Use: ${[...VALID_IMAGE_SIZES].join(', ')}`); } const url = `https://generativelanguage.googleapis.com/v1beta/models/${model}:generateContent?key=${apiKey}`; const imageConfig = { image_size: imageSize }; if (aspectRatio) imageConfig.aspect_ratio = aspectRatio; const payload = { contents: [{ parts: [{ text: prompt }] }], generationConfig: { responseModalities: ['TEXT', 'IMAGE'], imageConfig, }, }; for (let attempt = 0; attempt < maxRetries; attempt++) { const response = await fetch(url, { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify(payload), }); if (response.status === 429) { if (attempt === maxRetries - 1) throw new Error('Max retries exceeded (429)'); const delay = Math.pow(2, attempt + 1) * 1000; await new Promise(r => setTimeout(r, delay)); continue; } if (!response.ok) { const body = await response.json(); const status = body?.error?.status || ''; if (status === 'FAILED_PRECONDITION') { throw new Error('Billing not enabled. Enable billing in GCP Console.'); } throw new Error(`API error ${response.status}: ${JSON.stringify(body?.error)}`); } const data = await response.json(); const parts = data?.candidates?.[0]?.content?.parts || []; const imagePart = parts.find(p => p.inlineData); if (!imagePart) { throw new Error( 'HTTP 200 but no image data. Check responseModalities includes TEXT and IMAGE.' ); } return Buffer.from(imagePart.inlineData.data, 'base64'); } }
Для высококонкурентных производственных сценариев, где вам нужно обрабатывать несколько моделей и стратегии резервирования, агрегаторы API, такие как endpoint изображений laozhang.ai, могут служить резервом при исчерпании основной квоты. Агрегатор обрабатывает ограничение скорости внутренне, что упрощает ваш код обработки ошибок при введении ограничений основного API.
Часто задаваемые вопросы
Почему мой вызов Gemini Image API возвращает HTTP 200, но без изображения?
Наиболее распространённая причина — responseModalities установлен в ["IMAGE"] вместо ["TEXT", "IMAGE"]. Gemini Image API требует обеих модальностей — TEXT и IMAGE — опускание TEXT вызывает возврат пустого ответа API без ошибки. Проверьте ваш generationConfig и убедитесь, что он включает оба значения. Если это верно, убедитесь, что вы используете endpoint /v1beta/, а не /v1/ или совместимый с OpenAI endpoint.
Как исправить ошибки 429 Gemini Image API после перехода на платный план?
Сначала проверьте, как давно вы обновились. Если это было в течение последних 24-48 часов, вас может затрагивать ошибка Ghost 429 (известная проблема с февраля 2026 года, при которой новые активации тарификации не сразу распространяют квоту). Попробуйте временно переключиться на другой вариант модели. Если ошибка 429 сохраняется более 48 часов при ненулевой квоте в GCP Console, обратитесь в службу поддержки, сославшись на проблему распространения квот. Также убедитесь в GCP Console, что ваша квота IPM (Images Per Minute) действительно ненулевая — включение тарификации не означает автоматически ненулевую квоту изображений.
Почему мои настройки imageConfig игнорируются?
Две распространённые причины: регистрозависимость или удаление промежуточным слоем. Для регистрозависимости проверьте, что значение image_size использует заглавную K — "1K", а не "1k". Для удаления промежуточным слоем: если вы маршрутизируете через LiteLLM или аналогичный прокси, imageConfig может быть удалён до достижения Gemini API. Решение — делать прямые HTTP-вызовы к Gemini API для генерации изображений вместо использования прокси.
В чём разница между квотами IPM и RPM для моделей изображений Gemini?
RPM (Requests Per Minute) ограничивает количество вызовов API в минуту и применяется ко всем моделям Gemini. IPM (Images Per Minute) специфично для изображений и ограничивает количество отдельных изображений, которые могут быть сгенерированы в минуту. Один вызов API может генерировать несколько изображений, если numberOfImages установлен больше 1, и каждое изображение учитывается в квоте IPM отдельно. Квота IPM обычно является ограничивающим фактором для генерации изображений — вы достигнете IPM раньше RPM при большинстве паттернов использования.
Безопасно ли использовать предварительные версии моделей Gemini Image в производстве?
Предварительные версии моделей (gemini-3.1-flash-image-preview, gemini-3-pro-image-preview) используют Dynamic Shared Quota, то есть они могут возвращать ошибки 429 из-за глобальной перегруженности, даже когда вы находитесь в пределах личных лимитов квот. Для разработки и лёгкого производственного использования они подходят, но для приложений с требованиями SLA используйте стабильную модель gemini-2.5-flash-image или Vertex AI с выделенной пропускной способностью. Предварительные версии моделей также могут быть изменены или объявлены устаревшими с меньшим предупреждением, чем производственные модели.
Заключение и следующие шаги
Ошибки Gemini Image API действительно сбивают с толку, потому что разные проблемы дают одинаково выглядящие симптомы. Ошибка 429 может означать, что у вашего бесплатного уровня нулевая квота, или ваша платная квота исчерпана, или вы столкнулись с известной ошибкой, или испытываете глобальную перегруженность — и каждый сценарий требует совершенно разного ответа. Пустой HTTP 200 может означать неправильную конфигурацию параметров, неверный endpoint или вмешательство промежуточного слоя.
Последовательность диагностики, работающая для всех типов ошибок: сначала проверьте тарификацию (GCP Console → APIs & Services → Generative Language API → Quotas), затем проверьте параметры (responseModalities: ["TEXT", "IMAGE"], image_size: "1K" заглавная), затем подтвердите endpoint (/v1beta/, а не /v1/). Большинство проблем решаются на одном из этих трёх контрольных пунктов.
Для производственных приложений встраивайте классификацию ошибок в ваш код с самого начала — разграничение повторяемых ошибок 429 от неповторяемых ошибок тарификации и параметров сэкономит операционные усилия в будущем. Полный пример кода в Разделе 7 обеспечивает эту классификацию «из коробки».
Если вы систематически достигаете лимитов квот и вам нужна более высокая пропускная способность без сложности провизионирования Vertex AI, рассмотрите пересмотр стратегии пакетной генерации для соблюдения лимитов IPM, или изучите, соответствуют ли пороговые значения квот Tier 2 вашим требованиям. Структура квот разработана для масштабирования с использованием — то, что начинается как ограничение, становится управляемым, как только вы понимаете, какое измерение является ограничивающим фактором для вашей нагрузки.