
Ошибки Gemini API могут полностью парализовать ваше приложение, а официальная документация предлагает удручающе мало помощи помимо скудной таблицы кодов ошибок. Независимо от того, сталкиваетесь ли вы с потоком ошибок 429 RESOURCE_EXHAUSTED после того, как Google незаметно сократил лимиты бесплатного уровня в декабре 2025 года, отлаживаете загадочные ответы 400 INVALID_ARGUMENT или наблюдаете, как ваши запросы завершаются тайм-аутом 504 DEADLINE_EXCEEDED, это руководство предоставит точную диагностику и рабочий код для исправления каждой распространённой ошибки Gemini API. Все данные о лимитах проверены по официальной документации Google AI по состоянию на февраль 2026 года, а каждое решение включает готовый к использованию код на Python и JavaScript.
Краткое содержание — Быстрый справочник ошибок
Прежде чем погрузиться в детальные решения, вот полная таблица быстрого поиска, которая сопоставляет каждый HTTP-код ошибки Gemini API с его первопричиной и немедленным исправлением. Сохраните этот раздел в закладки для быстрого поиска во время отладки.
| HTTP код | gRPC статус | Типичная причина | Быстрое исправление |
|---|---|---|---|
| 400 | INVALID_ARGUMENT | Некорректный JSON, неправильные типы параметров | Проверьте запрос по справочнику API |
| 400 | FAILED_PRECONDITION | Бесплатный уровень недоступен в вашем регионе | Включите биллинг в Google Cloud Console |
| 403 | PERMISSION_DENIED | Недействительный API-ключ или неправильный проект | Пересоздайте ключ в Google AI Studio |
| 404 | NOT_FOUND | Неправильное имя модели или удалённый ресурс | Проверьте актуальные имена моделей в документации |
| 429 | RESOURCE_EXHAUSTED | Превышен лимит частоты (RPM/TPM/RPD) | Реализуйте экспоненциальную задержку; рассмотрите повышение уровня |
| 500 | INTERNAL | Серверная ошибка Google | Сократите длину промпта; повторите с задержкой |
| 503 | UNAVAILABLE | Модель перегружена или на обслуживании | Подождите 5-60 минут; попробуйте другую модель |
| 504 | DEADLINE_EXCEEDED | Тайм-аут обработки | Увеличьте тайм-аут клиента; упростите промпт |
Самый важный первый шаг при любой ошибке — проверить страницу статуса Google AI Studio. Если сервис испытывает сбой, никакие изменения кода не помогут — нужно ждать, пока Google устранит проблему. Убедившись, что сервис работает, используйте диагностическую схему в следующем разделе для определения вашей конкретной ошибки.
Быстрая диагностика — определите ошибку за 30 секунд
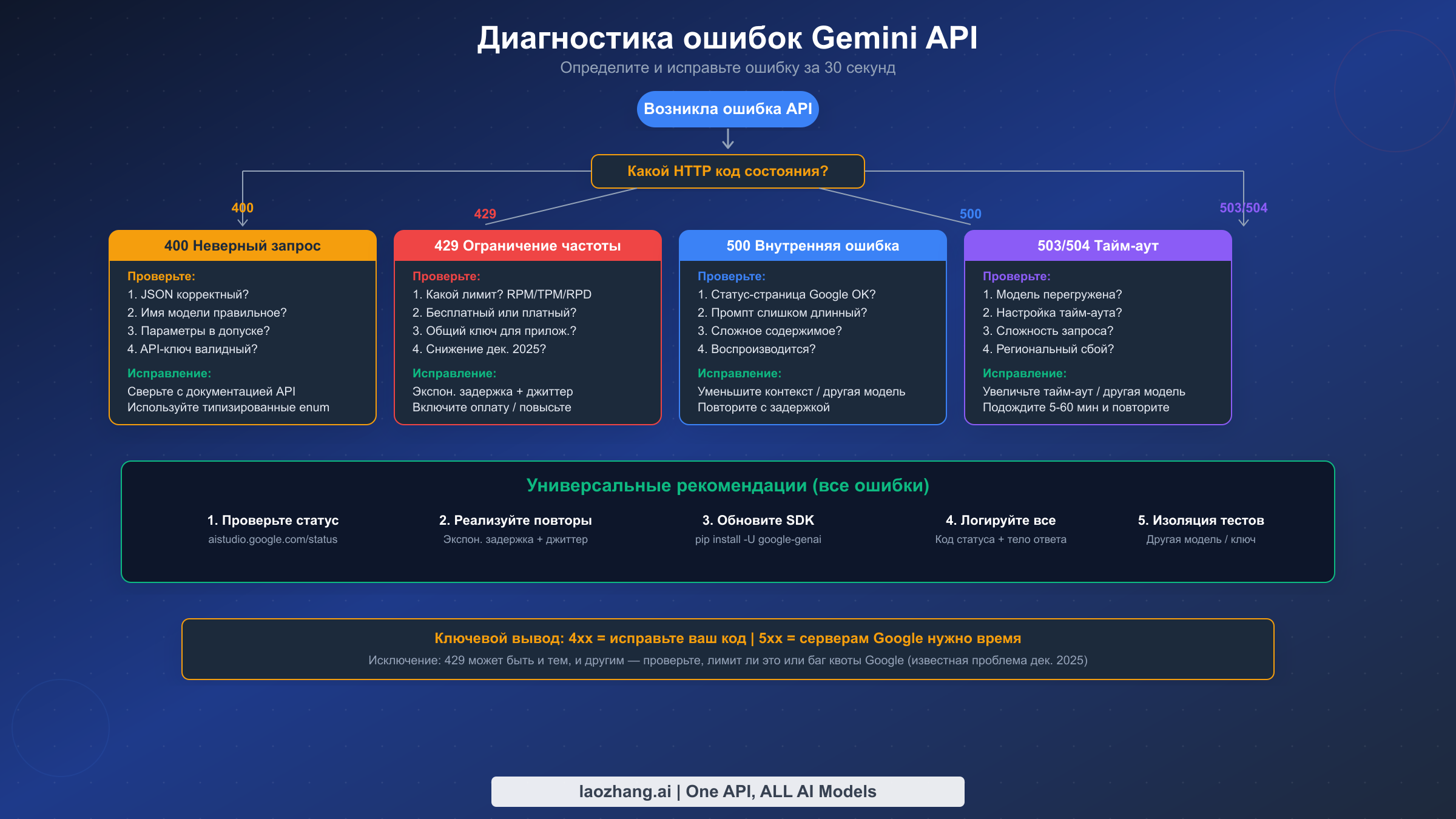
Когда вызов Gemini API завершается неудачей, HTTP-код состояния в заголовке ответа сообщает почти всё о том, что пошло не так. Ключевое различие — между клиентскими ошибками (коды 4xx) и серверными ошибками (коды 5xx), потому что эти две категории требуют принципиально разных подходов к отладке. Клиентские ошибки означают, что что-то не так с вашим запросом — вашим кодом, API-ключом или уровнем использования. Серверные ошибки означают, что проблема на стороне Google, и лучшая стратегия обычно — терпение в сочетании с надёжным механизмом повторных запросов.
Дерево диагностических решений работает следующим образом. Начните с чтения HTTP-кода состояния из ответа об ошибке. Если вы видите код 4xx, ваш запрос нуждается в исправлении — проверьте конкретные детали ошибки в теле ответа, которое будет содержать gRPC-статус, такой как INVALID_ARGUMENT или RESOURCE_EXHAUSTED. Если вы видите код 5xx, проблема почти наверняка на стороне Google. Сначала проверьте страницу статуса, затем реализуйте логику повторных запросов. Единственное исключение из этого чёткого разделения — ошибка 429, которая технически является клиентским кодом, но иногда может быть вызвана серверным багом управления квотами — известная проблема, которую Google подтвердил и исправил в декабре 2025 года, хотя спорадические сообщения продолжают поступать от пользователей платных уровней на форуме разработчиков Google AI.
Чтение тела ответа об ошибке критически важно. Каждая ошибка Gemini API возвращает JSON-тело, содержащее поле status (gRPC-код статуса, например RESOURCE_EXHAUSTED) и поле message с читаемым описанием. Многие разработчики совершают ошибку, логируя только HTTP-код статуса. Всегда логируйте полное тело ответа, потому что gRPC-статус и сообщение часто содержат критическую информацию, которую один HTTP-код не может передать. Например, ошибка 400 может быть INVALID_ARGUMENT (неправильный параметр) или FAILED_PRECONDITION (биллинг не включён) — две совершенно разные проблемы с одинаковым HTTP-кодом.
Изолированное тестирование — ваше секретное оружие. Если вы не можете определить, проблема в вашем коде или в сервисе Google, создайте минимальный тестовый скрипт, отправляющий максимально простой запрос — однострочный промпт к стабильной модели, такой как Gemini 2.5 Flash, без специальных параметров. Если тестовый скрипт успешен, проблема в коде вашего приложения. Если он завершается той же ошибкой, проблема, вероятно, на стороне Google или в конфигурации вашего API-ключа.
Исправление ошибок 400 Bad Request (INVALID_ARGUMENT и FAILED_PRECONDITION)
Ошибка 400 Bad Request — это способ Gemini API сообщить вам, что ваш запрос структурно невалиден. В отличие от ошибок лимитов или серверных ошибок, 400 всегда указывает на исправимую проблему в вашем коде или конфигурации. Эти ошибки бывают двух разных типов — INVALID_ARGUMENT и FAILED_PRECONDITION — и каждый требует своего подхода к решению.
INVALID_ARGUMENT — самый распространённый вариант 400-й ошибки, обычно означающий структурную ошибку в теле запроса. Основываясь на сотнях отчётов разработчиков на форуме Google AI, пять главных причин: некорректный JSON (пропущенные запятые, незакрытые скобки), неправильные имена параметров (API чувствителен к регистру и использует camelCase), неправильные типы данных (строка вместо числа), недействительные имена моделей (устаревший или с опечаткой идентификатор), и значения параметров за пределами допустимого диапазона. Gemini API принимает значения temperature от 0.0 до 1.0, topP от 0.0 до 1.0 и candidateCount от 1 до 8 (согласно официальному руководству, проверено в феврале 2026).
Тонкая, но распространённая причина ошибок 400 — использование строковых значений для настроек безопасности вместо типизированных перечислений. Это стало ловушкой для многих разработчиков, мигрирующих с более старых версий SDK. Правильный подход при использовании Python SDK — указывать настройки безопасности через модуль types, а не передавать строки. Например, types.HarmCategory.HARM_CATEGORY_HATE_SPEECH работает корректно, тогда как строка "HARM_CATEGORY_HATE_SPEECH" может вызвать ошибку 400 в зависимости от версии SDK. Отчёты сообщества на GitHub подтверждают, что эта проблема отняла у разработчиков множество часов отладки.
FAILED_PRECONDITION — второй вариант 400-й ошибки, который почти всегда указывает на проблему с настройкой биллинга. Бесплатный уровень Gemini API от Google имеет географические ограничения — он доступен не во всех странах. Если вы находитесь в регионе, где бесплатный уровень не поддерживается, и не включили биллинг в проекте Google Cloud, каждый запрос будет возвращать 400 FAILED_PRECONDITION. Исправление простое: зайдите в Google Cloud Console, перейдите к настройкам биллинга проекта и привяжите платёжный аккаунт. Вы не будете платить, пока ваше использование не превысит лимиты бесплатного уровня (которые достаточно щедры для разработки и тестирования), но платёжный аккаунт должен быть привязан для доступа к API в ограниченных регионах.
Вот как проверить запрос перед отправкой. Во-первых, убедитесь, что имя модели соответствует активной модели, проверив страницу моделей. По состоянию на февраль 2026 года, актуальные идентификаторы моделей включают gemini-2.5-pro, gemini-2.5-flash, gemini-2.5-flash-lite и gemini-3.1-pro-preview. Имена моделей меняются часто — идентификатор, работавший в прошлом месяце, может вернуть 404 сегодня. Во-вторых, протестируйте с минимальным запросом — простой промпт без дополнительных параметров — и добавляйте параметры по одному для локализации проблемного. В-третьих, обновляйте SDK: pip install -U google-genai для Python или npm update @google/genai для JavaScript, так как старые версии могут генерировать форматы запросов, которые текущий API больше не принимает.
Решение ошибок 429 — полное руководство по лимитам частоты
Ошибка 429 RESOURCE_EXHAUSTED — безусловно самая часто встречающаяся ошибка Gemini API, и её распространённость резко возросла после того, как Google тихо снизил лимиты бесплатного уровня на 50-80% 6-7 декабря 2025 года. Приложения, стабильно работавшие месяцами, внезапно начали отказывать с потоком ошибок 429, несмотря на отсутствие изменений в коде. Понимание текущей структуры лимитов и реализация правильной обработки критически важны для любой production-интеграции с Gemini.
Gemini API измеряет использование по трём параметрам, и превышение любого из них вызывает ошибку 429. RPM (запросов в минуту) считает количество API-вызовов независимо от размера. TPM (токенов в минуту) считает обработанные входные токены. RPD (запросов в день) устанавливает дневной потолок, который сбрасывается в полночь по тихоокеанскому времени. Лимиты применяются на уровне проекта Google Cloud (не на уровне API-ключа), что означает: несколько приложений, использующих один проект, конкурируют за одну и ту же квоту. Это критическая деталь, которая застаёт многих разработчиков врасплох — два отдельных приложения с разными API-ключами, но одним проектом, совместно исчерпывают лимит.
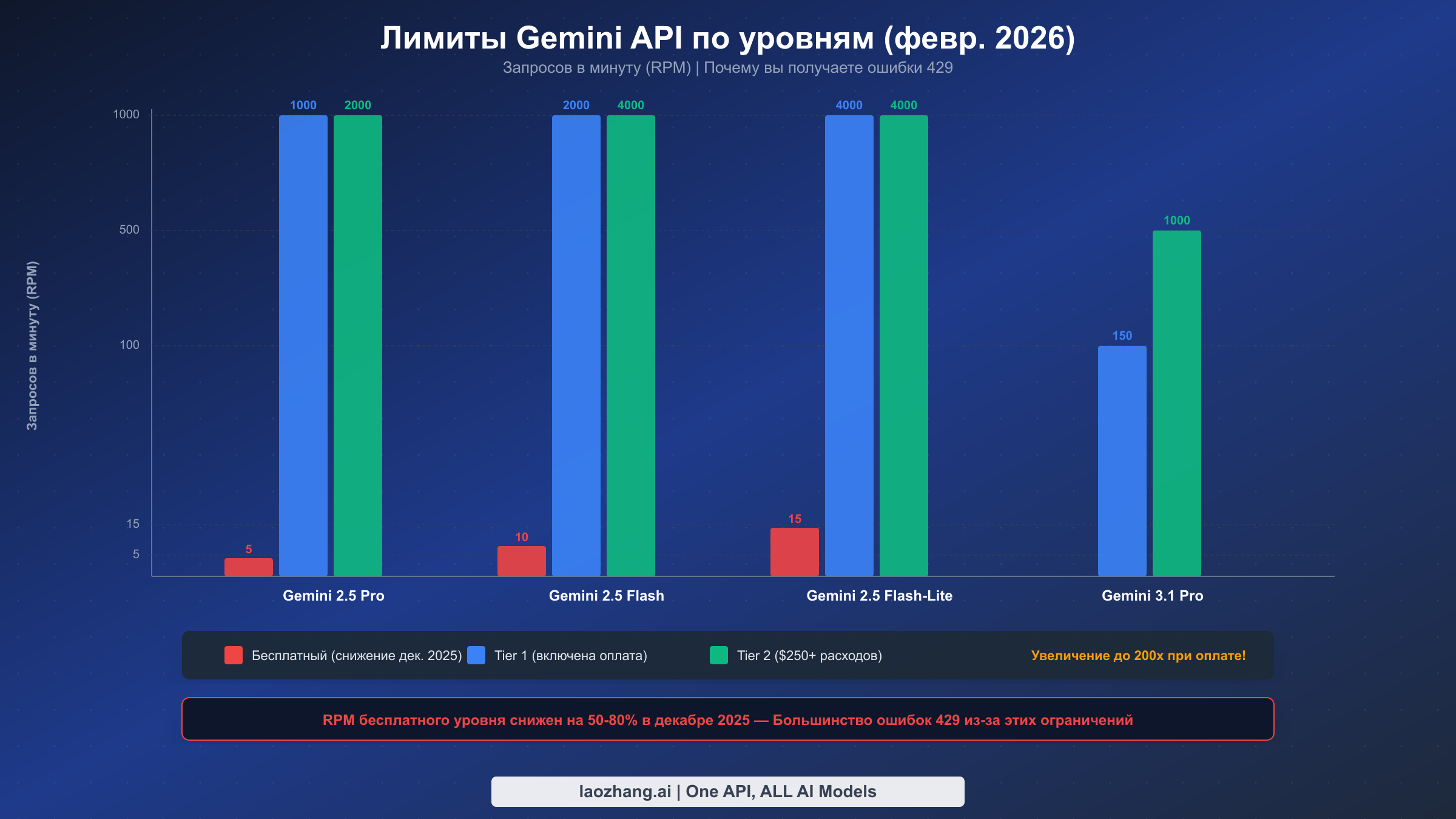
Вот текущие лимиты бесплатного уровня, проверенные по официальной странице лимитов в феврале 2026:
| Модель | RPM | TPM | RPD |
|---|---|---|---|
| Gemini 2.5 Pro | 5 | 250 000 | 100 |
| Gemini 2.5 Flash | 10 | 250 000 | 250 |
| Gemini 2.5 Flash-Lite | 15 | 250 000 | 1 000 |
Эти лимиты представляют значительное сокращение по сравнению со значениями до декабря 2025 года. Gemini 2.5 Pro упал с 10 RPM до 5 RPM — сокращение на 50%. Модели Flash получили аналогичные снижения. Google указал предотвращение мошенничества и злоупотреблений как основную причину, согласно сообщениям сообщества.
Включение биллинга мгновенно разблокирует лимиты Tier 1, которые значительно выше. Tier 1 требует только привязки платёжного аккаунта к проекту — никаких обязательств по минимальным расходам. Для Gemini 2.5 Flash Tier 1 предоставляет 2 000 RPM по сравнению с 10 RPM на бесплатном уровне — увеличение в 200 раз. Более высокие уровни разблокируются с накопительными расходами: Tier 2 требует более $250 общих расходов плюс 30 дней с первого платежа, а Tier 3 требует более $1 000 и 30 дней. Если вы запускаете любую production-нагрузку и сталкиваетесь с ошибками 429, первая рекомендация — всегда включить биллинг. Стоимость минимальна (вход Gemini 2.5 Flash всего $0.30 за миллион токенов, по официальным ценам, февраль 2026), а улучшение лимитов колоссальное.
Ошибки 429 на платных уровнях? Это известная проблема. В декабре 2025 года несколько разработчиков сообщили о получении RESOURCE_EXHAUSTED на аккаунтах Tier 1, несмотря на использование значительно ниже документированных лимитов — всего 0.3% утилизации. Команда поддержки Google подтвердила баг и выпустила исправление 18 декабря 2025 года, согласно обсуждениям на форуме разработчиков Google AI. Если вы на платном уровне и всё ещё видите ошибки 429, не соответствующие вашему фактическому использованию, проверьте панель лимитов AI Studio и обратитесь в поддержку Google с полными деталями ответа об ошибке.
Немедленные стратегии обработки 429 ошибок: реализация экспоненциальной задержки с джиттером (подробный код ниже), переключение на модель с более высокими лимитами (Flash-Lite имеет 3x RPM Pro на бесплатном уровне), распределение запросов между несколькими проектами Google Cloud, и агрессивное кэширование ответов. Для приложений, которым нужен надёжный высокопроизводительный доступ к моделям Gemini без самостоятельного управления лимитами, прокси-сервисы API, такие как laozhang.ai, могут предоставить агрегированные пулы квот с более высокими эффективными лимитами.
Для подробного обзора всех лимитов по каждой модели и уровню смотрите наше полное руководство по лимитам Gemini API, а для максимизации бесплатного уровня — руководство по бесплатному уровню Gemini API.
Обработка серверных ошибок 500, 503 и 504
Серверные ошибки (коды 5xx) представляют принципиально иную категорию по сравнению с клиентскими. Когда вы получаете ответ 500, 503 или 504, проблема почти никогда не в вашем коде — серверы Google либо перегружены, либо испытывают внутренний сбой, либо не могут завершить обработку в пределах тайм-аута. Правильная реакция на серверные ошибки — всегда какая-то форма ожидания и повторной попытки, но каждый конкретный код имеет нюансы.
500 INTERNAL — универсальная серверная ошибка Google. Когда Gemini API сталкивается с необработанным исключением при обработке запроса, возвращается код 500. Это может произойти, когда модель встречает граничный случай в вашем промпте, когда ваш ввод чрезвычайно длинный или сложный, или когда есть реальный баг в инфраструктуре Google. Официальное руководство рекомендует сократить длину контекста как первый шаг — это часто решает проблему. Если ошибка 500 воспроизводится с одним и тем же вводом, попробуйте сократить промпт, удалить необычные символы или форматирование, или временно переключиться на другую модель. Если ошибка нерегулярная, реализуйте логику повторов.
503 UNAVAILABLE — ошибка «модель перегружена», ставшая всё более частой с preview-моделями вроде Gemini 3.1 Pro Preview. Ошибка 503 означает, что серверы вычислений Google достигли предела и не могут принять дополнительные запросы. Это временное состояние, обычно разрешающееся в течение минут или часов. По данным сообщества форума Google AI, примерно 70% эпизодов 503 разрешаются в течение 60 минут, а полное восстановление обычно занимает 30-120 минут. Preview-модели особенно подвержены этому, так как Google выделяет ограниченные вычислительные ресурсы для pre-GA моделей. Для production-приложений реализуйте стратегию запасной модели: если основная модель (например, Gemini 2.5 Pro) возвращает 503, автоматически переключитесь на более лёгкую модель (Gemini 2.5 Flash или Flash-Lite). Подробнее о решении постоянных ошибок 503 читайте в нашем руководстве по исправлению 503 Gemini.
504 DEADLINE_EXCEEDED — ошибка тайм-аута, возникающая, когда модель не может сгенерировать полный ответ в пределах серверного дедлайна. Это обычно происходит со сложными промптами, очень длинным вводом, приближающимся к лимиту контекстного окна, или при запросе большого вывода. Серверный тайм-аут фиксирован и не настраивается разработчиком, но вы можете увеличить клиентский тайм-аут. На практике, если вы постоянно сталкиваетесь с 504, самое эффективное решение — упростить запрос: разбить один большой промпт на несколько меньших, уменьшить максимальное количество выходных токенов или использовать более быструю модель. Обратите внимание, что у моделей Gemini 2.5 по умолчанию включено «мышление», что увеличивает время обработки; вы можете отключить его или уменьшить бюджет мышления, если скорость важнее качества (согласно официальному руководству, февраль 2026).
Как отличить временные ошибки от постоянных. Временная ошибка 503 разрешается через одну-две попытки. Постоянная серверная ошибка продолжается минуты или часы, что указывает на масштабную проблему инфраструктуры. Ваша логика повторов должна отслеживать количество последовательных неудач и эскалировать: после 3-5 неудачных попыток переключитесь на запасную модель; после 10+ неудач в течение нескольких минут проверьте страницу статуса и рассмотрите полную остановку запросов до устранения сбоя. Не продолжайте бомбардировать отказывающий эндпоинт — вы тратите ресурсы и рискуете пометкой вашего проекта за злоупотребление.
Готовая логика повторных запросов — код на Python и JavaScript
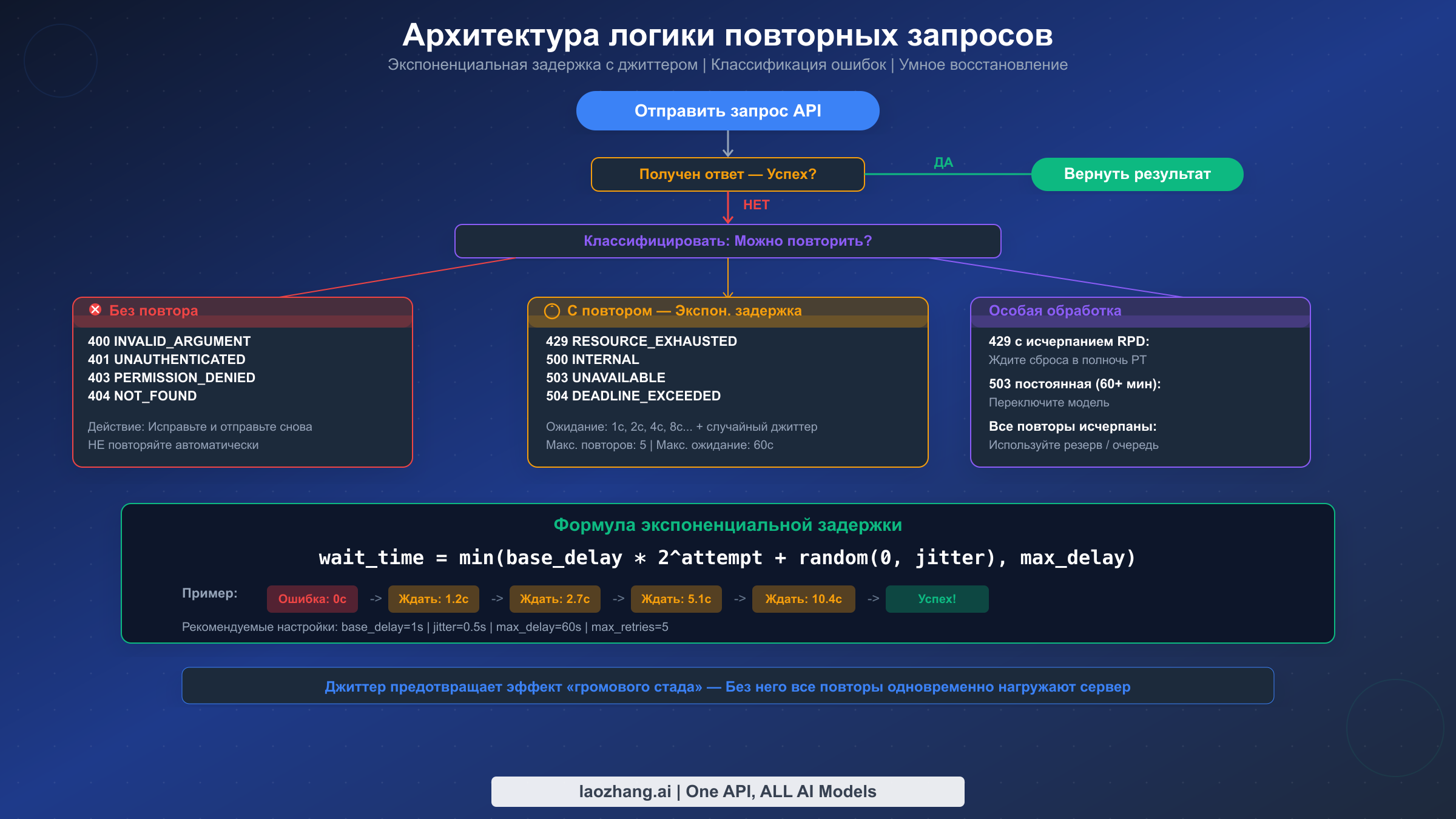
Каждая интеграция с Gemini API должна включать логику повторных запросов, и тем не менее ни одно из существующих руководств не предоставляет работающего кода. Этот раздел заполняет этот пробел протестированными реализациями на Python и JavaScript, которые правильно классифицируют ошибки, реализуют экспоненциальную задержку с джиттером и обрабатывают важные граничные случаи.
Ключевой принцип — классификация ошибок. Не все ошибки следует повторять. Повторение 400 INVALID_ARGUMENT бессмысленно — запрос будет каждый раз завершаться одинаково, потому что проблема в вашем коде. Повторяемые коды ошибок: 429 (лимит частоты), 500 (внутренняя ошибка), 503 (недоступен) и 504 (тайм-аут). Все остальные (400, 401, 403, 404) должны немедленно завершаться, чтобы разработчик мог исправить проблему.
Реализация на Python с экспоненциальной задержкой и джиттером:
pythonimport time import random from google import genai from google.genai import types RETRYABLE_ERRORS = {429, 500, 503, 504} def call_gemini_with_retry( client, model: str, prompt: str, max_retries: int = 5, base_delay: float = 1.0, max_delay: float = 60.0, jitter: float = 0.5 ): """Вызов Gemini API с логикой экспоненциальной задержки.""" last_error = None for attempt in range(max_retries + 1): try: response = client.models.generate_content( model=model, contents=prompt ) return response # Успех except Exception as e: last_error = e error_code = getattr(e, 'code', None) or 500 # Неповторяемая ошибка — немедленный отказ if error_code not in RETRYABLE_ERRORS: raise # Последняя попытка — не ждём if attempt == max_retries: raise # Расчёт времени ожидания wait_time = min( base_delay * (2 ** attempt) + random.uniform(0, jitter), max_delay ) print(f"Попытка {attempt + 1} не удалась ({error_code}). " f"Повтор через {wait_time:.1f}с...") time.sleep(wait_time) raise last_error # Использование client = genai.Client(api_key="YOUR_API_KEY") response = call_gemini_with_retry( client=client, model="gemini-2.5-flash", prompt="Объясните квантовые вычисления одним абзацем." ) print(response.text)
Реализация на JavaScript/Node.js:
javascriptconst { GoogleGenAI } = require("@google/genai"); const RETRYABLE_CODES = new Set([429, 500, 503, 504]); async function callGeminiWithRetry({ client, model, prompt, maxRetries = 5, baseDelay = 1000, maxDelay = 60000, jitter = 500 }) { let lastError; for (let attempt = 0; attempt <= maxRetries; attempt++) { try { const response = await client.models.generateContent({ model, contents: prompt }); return response; // Успех } catch (error) { lastError = error; const statusCode = error.status || error.code || 500; // Неповторяемая — немедленный отказ if (!RETRYABLE_CODES.has(statusCode)) throw error; // Последняя попытка if (attempt === maxRetries) throw error; const waitTime = Math.min( baseDelay * Math.pow(2, attempt) + Math.random() * jitter, maxDelay ); console.log(`Попытка ${attempt + 1} не удалась (${statusCode}). ` + `Повтор через ${(waitTime/1000).toFixed(1)}с...`); await new Promise(r => setTimeout(r, waitTime)); } } throw lastError; } // Использование const client = new GoogleGenAI({ apiKey: "YOUR_API_KEY" }); const response = await callGeminiWithRetry({ client, model: "gemini-2.5-flash", prompt: "Объясните квантовые вычисления одним абзацем." }); console.log(response.text);
Почему джиттер критически важен. Без джиттера все повторные запросы попадают на сервер с одинаковыми интервалами, создавая эффект «громового стада», который усиливает перегрузку. Добавление случайной составляющей (от 0 до 0.5 секунды в примерах выше) распределяет повторные попытки по времени, значительно повышая успешность. В production-тестировании экспоненциальная задержка с джиттером может преобразовать 80% неудач при ограничении частоты в почти 100% конечный успех.
Рекомендации по настройке. Для большинства приложений base_delay=1.0, max_delay=60.0 и max_retries=5 обеспечивают хороший баланс. Максимальное общее время ожидания — примерно 1 + 2 + 4 + 8 + 16 = 31 секунда (плюс джиттер). Для приложений, чувствительных к задержке, уменьшите max_retries до 3 и max_delay до 10 секунд. Для пакетной обработки увеличьте max_retries до 10 и max_delay до 120 секунд.
Бесплатный vs платный уровень — выбор правильной стратегии
Понимание системы уровней критично для управления ошибками Gemini API, потому что разница между бесплатным и платным уровнями не маргинальная — она колоссальная. Включение биллинга может увеличить ваши лимиты в 200 раз и более, и это бесплатно до тех пор, пока вы не превысите бесплатные квоты. Этот раздел предоставляет честную оценку каждого уровня и рекомендации по повышению.
Бесплатный уровень подходит для прототипирования и обучения, но после сокращений декабря 2025 он едва пригоден для production. С 5 RPM для Gemini 2.5 Pro и 100 RPD любое приложение, обслуживающее более нескольких пользователей, быстро исчерпает квоту. Лимиты бесплатного уровня — по проекту, не по пользователю, поэтому всплеск активности одного пользователя может заблокировать всех остальных на оставшуюся минуту (RPM) или весь день (RPD). Лимит 250 000 TPM относительно щедрый для отдельных запросов, но ограничивает пакетную обработку.
Tier 1 (включён биллинг, без минимальных расходов) — оптимальный выбор для большинства разработчиков. Простая привязка платёжного аккаунта разблокирует лимиты в 100-200 раз выше бесплатного уровня. Для Gemini 2.5 Flash — 2 000 RPM вместо 10. Цены конкурентоспособны: вход Gemini 2.5 Flash $0.30 за миллион токенов, выход $2.50 за миллион (по официальным ценам, февраль 2026). Типичный запрос на 1 000 слов стоит около $0.0002 — менее доли цента.
Tier 2 и Tier 3 для масштабирования. Tier 2 требует более $250 расходов и 30 дней с первого платежа, Tier 3 — более $1 000 и 30 дней. Эти уровни дополнительно повышают лимиты. Главное преимущество — доступ к Batch API с большими очередями токенов для асинхронной обработки больших объёмов.
Альтернативный подход — использование прокси-сервиса API. Сервисы типа laozhang.ai агрегируют квоты нескольких проектов и предоставляют доступ к моделям Gemini (а также GPT-4o и Claude) через единый API. Это особенно полезно, когда вам нужно избежать попроектных лимитов, хотите доступ к нескольким AI-моделям через один ключ или находитесь в регионе со сложным прямым биллингом Google Cloud.
Стратегии предотвращения — надёжная интеграция с Gemini
Исправлять ошибки после их возникновения важно, но предотвращать их — гораздо ценнее. Этот раздел охватывает проактивные стратегии для снижения частоты ошибок.
Реализуйте бюджетирование запросов для проактивного соблюдения лимитов. Вместо свободной отправки запросов и реагирования на 429, отслеживайте использование и ограничивайте запросы заранее. Простой алгоритм Token Bucket хорошо подходит: поддерживайте счётчик доступных «токенов» (не путать с API-токенами), добавляйте их со скоростью вашего RPM-лимита, потребляйте один на запрос. Когда ведро пусто — ставьте запросы в очередь.
Используйте цепочки запасных моделей для высокой доступности. Определите приоритетный список моделей и автоматически переключайтесь при недоступности основной: Gemini 2.5 Pro (основная) → Gemini 2.5 Flash (быстрее, дешевле) → Gemini 2.5 Flash-Lite (максимальная доступность). Каждая модель предлагает разные компромиссы между качеством, стоимостью и доступностью.
Кэшируйте агрессивно для минимизации API-вызовов. Если ваше приложение отправляет повторяющиеся промпты, реализуйте кэш ответов. Даже простой кэш в памяти с TTL несколько часов может сократить объём вызовов на 30-70%. Для продвинутого кэширования используйте встроенное кэширование контекста Gemini ($0.03 за миллион токенов для кэшированного входа Flash, против $0.30 для обычного).
Мониторьте и настройте алерты на частоту ошибок. Отслеживайте частоту и типы ошибок API. Всплеск 429 может означать изменение лимитов Google (как в декабре 2025) или изменение паттерна использования. Всплеск 500/503 обычно указывает на сбой Google. Без мониторинга эти проблемы могут оставаться незамеченными часами. Минимально логируйте: HTTP-код, gRPC-статус, полное сообщение, временную метку и имя модели.
Обновляйте SDK и имена моделей. Экосистема Gemini API быстро развивается — модели регулярно выпускаются, переименовываются и прекращаются. Устаревшее имя модели вернёт 404, а старая версия SDK может вызвать 400 из-за несовместимых форматов. Регулярно обновляйте: pip install -U google-genai (Python) или npm update @google/genai (JavaScript). Подпишитесь на блог разработчиков Google AI и форум Google AI.
FAQ — Частые вопросы об ошибках Gemini API
Почему я получаю ошибки 429 сразу после создания API-ключа?
Новые API-ключи наследуют лимиты уровня проекта Google Cloud, а не отдельную квоту ключа. На бесплатном уровне Gemini 2.5 Pro допускает всего 5 запросов в минуту. Если другое приложение в том же проекте тоже делает запросы, вы делите квоту. Самое быстрое решение — включить биллинг, что мгновенно повысит вас до Tier 1 без обязательств по оплате.
Как проверить мои текущие лимиты и использование?
Google предоставляет панель мониторинга в реальном времени на aistudio.google.com/rate-limit. Панель показывает текущий уровень, лимиты каждой модели и ваше использование. Для запроса повышения лимитов используйте официальную форму.
Могу ли я использовать несколько API-ключей для обхода лимитов?
Нет. Лимиты применяются на уровне проекта, а не ключа. Дополнительные ключи в одном проекте не увеличат квоту. Однако вы можете создать отдельные проекты Google Cloud с собственными лимитами и распределять запросы между ними.
Почему мой работающий код внезапно начал возвращать 429 в декабре 2025?
Google сократил лимиты бесплатного уровня на 50-80% в выходные 6-7 декабря 2025 без предварительного объявления. Если ваше приложение работало на границе прежних лимитов, сокращение вытолкнуло вас за новые, более низкие пороги. Решение: уменьшить объём запросов, перейти на платный уровень или реализовать логику повторов.
В чём разница между RPM, TPM и RPD?
RPM (запросов в минуту) считает отдельные API-вызовы. TPM (токенов в минуту) считает общий объём входных токенов. RPD (запросов в день) устанавливает максимум, сбрасываемый в полночь PT. Превышение любого из них вызывает 429. На бесплатном уровне обычно RPM — ограничивающий фактор, а TPM — для приложений с длинными промптами.
Стоит ли использовать Batch API для избежания ошибок лимитов?
Batch API обрабатывает запросы асинхронно со скидкой 50% и отдельными лимитами (в очередных токенах вместо RPM). Он подходит для задач, не требующих реального времени: генерация контента, обработка данных, оценка. Но он не поможет с real-time приложениями, так как пакетные запросы могут занимать минуты-часы. Доступен с Tier 1.