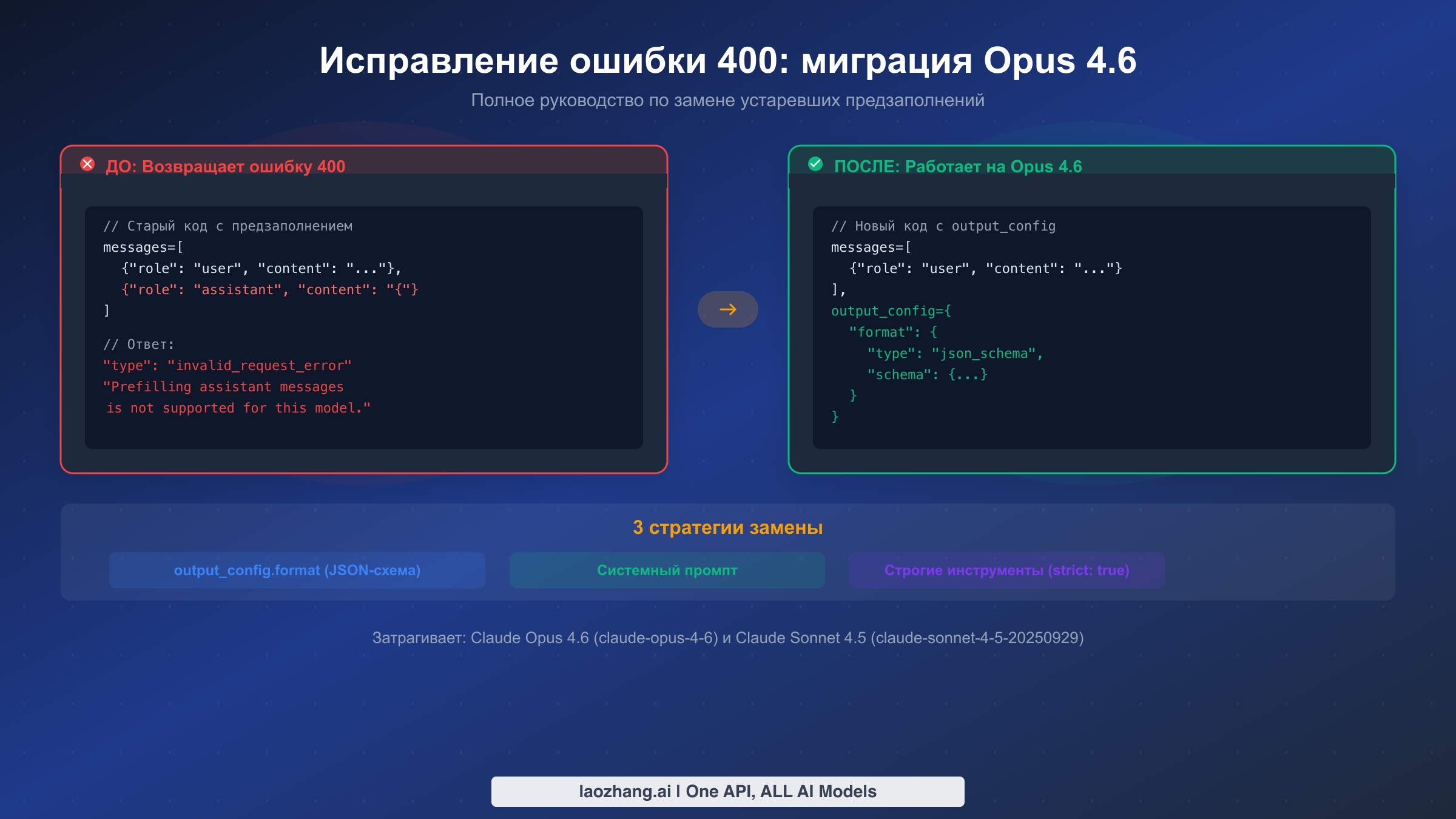
Ошибки 429 при генерации изображений Gemini возникают, когда ваше приложение превышает одно из четырёх измерений лимитов Google: Requests Per Minute (RPM), Requests Per Day (RPD), Tokens Per Minute (TPM) или часто упускаемое из виду Images Per Minute (IPM). Самое быстрое решение — реализация экспоненциального бэкоффа с джиттером, который превращает 80% неудач в 99%+ успешных запросов при пиковой нагрузке. Однако если вы на бесплатном уровне, сначала необходимо подключить биллинг, потому что IPM бесплатного уровня снизился до 0 в декабре 2025 года, что фактически отключает генерацию изображений без платного аккаунта. Tier 1 даёт вам 10 IPM мгновенно без минимальных затрат.
Почему генерация изображений Gemini возвращает ошибку 429
Каждый провайдер API реализует ограничение запросов для защиты инфраструктуры от злоупотреблений и обеспечения справедливого распределения ресурсов между всеми пользователями. Когда ваши запросы к Gemini API превышают выделенную квоту для вашего тарифного плана, серверы Google отвечают HTTP-статусом 429 и сообщением об ошибке RESOURCE_EXHAUSTED. Это не ошибка в вашем коде и не проблема с моделью Gemini — это API-шлюз, применяющий границы квот, которые Google установил для вашего проекта. Понимание механики этой ошибки — первый шаг к построению устойчивого конвейера генерации изображений, способного обрабатывать нагрузки продакшен-уровня без перебоев.
Ответ 429 от Gemini API несёт специфическую структуру, которую многие разработчики упускают из виду. Тело ответа содержит JSON-объект с полем error, включающим код статуса RESOURCE_EXHAUSTED, человекочитаемое сообщение о том, какая квота была превышена, и, что критически важно, метаданные в заголовках — x-ratelimit-limit, x-ratelimit-remaining и x-ratelimit-reset, которые точно указывают, какое измерение вызвало ограничение и когда оно сбросится. Многие разработчики просто перехватывают 429 и повторяют запрос вслепую, но разбор этих заголовков даёт вам информацию для реализации точечных решений, а не грубого перебора повторов. Если x-ratelimit-remaining для IPM показывает 0, тогда как RPM ещё имеет запас — вы знаете, что узкое место именно в пропускной способности генерации изображений, а не в общем объёме запросов.
Четыре измерения лимитов запросов
Google применяет ограничения по четырём независимым измерениям, и превышение любого из них вызывает ошибку 429. Большинство разработчиков знакомы с RPM и RPD, но появление IPM вместе со встроенными возможностями генерации изображений Gemini в конце 2025 года застало многие команды врасплох. Каждое измерение работает независимо — вы можете быть в пределах RPM-лимита, но всё равно получить ограничение, потому что ваша IPM-квота исчерпана. Эта таблица описывает каждое измерение и его влияние на нагрузку генерации изображений:
| Измерение | Полное название | Что измеряет | Влияние на генерацию изображений |
|---|---|---|---|
| RPM | Requests Per Minute | Общее количество API-вызовов за 60-секундное окно | Влияет на все вызовы Gemini, включая текстовые |
| RPD | Requests Per Day | Общее количество API-вызовов за 24-часовое окно (сброс в полночь PT) | Ограничивает суточный объём всех операций |
| TPM | Tokens Per Minute | Общее количество входных + выходных токенов в минуту | Преимущественно влияет на текст; изображения считаются фиксированными блоками токенов |
| IPM | Images Per Minute | Количество сгенерированных изображений в минуту | Скрытый убийца — напрямую ограничивает генерацию изображений |
IPM: скрытый убийца, которого пропускают большинство разработчиков
Images Per Minute — это измерение лимита, которое вызывает наибольшую путаницу среди разработчиков, интегрирующих функции генерации изображений Gemini. В отличие от RPM, который регулирует все API-запросы, включая текстовые генерации, IPM считает конкретно количество изображений, которые ваше приложение генерирует в 60-секундном скользящем окне. Один API-вызов, генерирующий четыре изображения, потребляет 4 IPM, а не 1 RPM. Это означает, что вы можете быть в пределах RPM-квоты и всё же достичь потолка IPM, если ваши запросы часто создают несколько изображений. Проблема усугубляется тем, что бесплатный уровень снизился до 0 IPM в декабре 2025 года, а это значит, что любая попытка генерации изображений на неоплаченном аккаунте возвращает немедленный 429 без обработки запроса. Многие разработчики, отлаживая свою первую ошибку 429, тратят часы на проверку логики кода, тогда как реальная проблема в том, что их тарифный план просто не допускает генерацию изображений.
Баг «фантомных 429» от февраля 2026
В начале февраля 2026 года множество разработчиков на платных аккаунтах Tier 1 начали получать ошибки 429 RESOURCE_EXHAUSTED несмотря на то, что их панели мониторинга показывали нулевое или близкое к нулю потребление квот. Этот баг «фантомных 429», по-видимому, является серверной проблемой системы отслеживания квот Google, при которой ограничитель некорректно подсчитывает использование для определённых конфигураций проектов. Баг в основном затрагивает аккаунты, которые недавно были обновлены с бесплатного до Tier 1, и чаще всего проявляется в первые 24-48 часов после подключения биллинга. Google подтвердил проблему на форумах разработчиков и рекомендовал переключиться на другой вариант модели (например, с gemini-3.1-flash на gemini-3-pro) в качестве временного обходного пути, пока инженерная команда ведёт расследование. Если вы сталкиваетесь с ошибками 429 при действительно нулевом использовании в панели квот Google Cloud Console, этот баг является наиболее вероятной причиной, а не какая-либо ошибка конфигурации с вашей стороны. Для более широкого понимания кодов ошибок Gemini API и их решений смотрите наше полное руководство по устранению ошибок Gemini API. Если вы хотите детально разобраться в системе ограничения запросов, наше полное руководство по лимитам Gemini API охватывает каждый уровень и измерение.
Быстрая диагностика — какой лимит вы превысили?

Прежде чем переходить к решениям, необходимо определить, какое конкретно измерение лимита блокирует ваши запросы. Применение неправильного решения тратит время — экспоненциальный бэкофф решает проблемы RPM, но ничего не даёт при узком месте IPM, где нужно повышение уровня. Процесс диагностики требует анализа как ответа об ошибке от API, так и ваших паттернов использования во времени. Google не всегда включает явную информацию об измерении в тело ошибки 429, поэтому часто необходимо сопоставить время ошибки с известными паттернами запросов, чтобы сузить причину. Хорошая новость в том, что каждое измерение лимита создаёт характерный паттерн сбоя, который можно определить систематическим подходом.
Чтение метаданных ответа об ошибке
Самый прямой способ определить, какой лимит вы достигли — разобрать заголовки ответа и тело ошибки из ответа 429. Google включает метаданные лимитов в заголовки ответа, хотя конкретные заголовки могут различаться в зависимости от того, какая квота была исчерпана. Следующий фрагмент на Python демонстрирует, как извлечь и записать эту диагностическую информацию из неудавшегося запроса. Этот код перехватывает исключение 429, извлекает все связанные с лимитами заголовки и выводит структурированный диагностический отчёт, который сразу показывает, какое измерение является узким местом.
pythonimport google.generativeai as genai from google.api_core.exceptions import ResourceExhausted def diagnose_rate_limit(api_key: str, prompt: str): genai.configure(api_key=api_key) model = genai.GenerativeModel("gemini-3.1-flash") try: response = model.generate_content(prompt) return response except ResourceExhausted as e: print(f"429 RESOURCE_EXHAUSTED: {e.message}") # Parse error details for quota dimension if hasattr(e, 'errors') and e.errors: for error in e.errors: metadata = error.get('metadata', {}) print(f" Quota dimension: {metadata.get('quota_dimension', 'unknown')}") print(f" Quota limit: {metadata.get('quota_limit', 'unknown')}") print(f" Quota usage: {metadata.get('quota_usage', 'unknown')}") # Check for ghost 429 pattern if "usage: 0" in str(e) or "quota_usage: 0" in str(e.errors): print(" WARNING: Ghost 429 detected (usage=0).") print(" This matches the known Feb 2026 bug.") print(" Try switching model: gemini-3-pro or imagen-4") raise
Три паттерна сбоев
Помимо разбора метаданных ошибки, вы можете определить измерение лимита, наблюдая за временным паттерном сбоев. Каждое измерение создаёт характерную сигнатуру, потому что RPM, RPD и IPM работают в разных временных окнах. Понимание этих паттернов необходимо, когда метаданные ошибки неполны или когда вы отлаживаете проблемы в продакшен-среде, где для работы доступны только логи. Вот три паттерна, на которые стоит обратить внимание:
Первый паттерн — «всплески, затем успех»: ваше приложение отправляет быстрый всплеск запросов, получает несколько ошибок 429, а затем успешно работает после ожидания 30-60 секунд. Этот паттерн убедительно указывает на нарушение лимита RPM. 60-секундное скользящее окно сбрасывается непрерывно, поэтому краткие паузы восстанавливают квоту. Второй паттерн — «работает утром, падает вечером»: приложение нормально работает в начале дня, но начинает стабильно отказывать позже. Это указывает на исчерпание RPD, так как суточная квота израсходована и не сбросится до полуночи по тихоокеанскому времени. Третий и самый коварный паттерн — «только изображения не работают»: текстовые запросы генерации проходят идеально, но каждый запрос на генерацию изображения возвращает 429. Это характерный признак исчерпания IPM и самая распространённая ловушка для разработчиков, которые укладываются в лимиты RPM, но исчерпали свою квоту на изображения.
Если вы видите ошибки 429 на платном аккаунте, но Google Cloud Console показывает нулевое использование квот, вероятно, вы столкнулись с багом фантомных 429, описанным выше. Это отдельная проблема от легитимного исчерпания квот. Разработчики, недавно обновившиеся с бесплатного уровня до Tier 1, должны быть особенно внимательны к этому паттерну. Для получения дополнительных сведений о различении между легитимными лимитами и несоответствиями тарифного плана смотрите наше руководство по платным аккаунтам, получающим лимиты бесплатного уровня.
Решение 1 — Экспоненциальный бэкофф с умным повтором
Экспоненциальный бэкофф — это единственная наиболее эффективная мера, которую вы можете реализовать против ошибок 429, и она не требует никаких инфраструктурных изменений или модификаций биллинга. Принцип прост: когда запрос завершается ошибкой 429, ожидайте экспоненциально возрастающий период перед повтором — 1 секунда, затем 2 секунды, затем 4, затем 8 и так далее. Это даёт ограничителю время освободить мощность и предотвращает постоянную бомбардировку API во время окна восстановления квоты. На практике хорошо реализованный экспоненциальный бэкофф преобразует приложение, которое отказывает в 80% случаев при пиковой нагрузке, в приложение, которое в итоге успешно обрабатывает 99%+ запросов, хотя компромиссом является увеличенная задержка для запросов, требующих нескольких повторов.
Почему джиттер важен: проблема «громового стада»
Простой экспоненциальный бэкофф имеет критический недостаток при развёртывании на нескольких экземплярах приложения. Если десять серверов приложений одновременно получают 429 и реализуют идентичный экспоненциальный бэкофф, все они будут повторять запросы в точно одинаковое время — через 1 секунду, затем через 2 секунды, затем через 4 секунды. Такое синхронизированное поведение повторов создаёт «громовое стадо», которое повторно перегружает ограничитель через точные интервалы, усугубляя перегрузку, а не устраняя её. Добавление случайного джиттера — небольшого случайного отклонения к каждой длительности ожидания — десинхронизирует ваши попытки повтора на всех экземплярах. Вместо того чтобы десять серверов повторяли запрос в t+1с, они повторяют в t+0.7с, t+1.2с, t+0.9с и так далее, равномерно распределяя нагрузку в окне восстановления. Это простое дополнение кардинально улучшает показатели успеха в распределённых системах и считается лучшей практикой всеми крупными облачными провайдерами, включая Google, AWS и Azure.
Реализация на Python с Tenacity
Библиотека tenacity предоставляет наиболее элегантный способ реализации экспоненциального бэкоффа в Python. Она обрабатывает всю сложность логики повторов, джиттера, максимального количества попыток и фильтрации исключений в чистом синтаксисе декораторов. Следующая реализация готова к продакшену и включает логирование, настраиваемые таймауты и специфическую обработку ошибок 429 в отличие от других API-исключений, которые не должны повторяться.
pythonimport tenacity import google.generativeai as genai from google.api_core.exceptions import ResourceExhausted import logging logger = logging.getLogger(__name__) @tenacity.retry( retry=tenacity.retry_if_exception_type(ResourceExhausted), wait=tenacity.wait_exponential(multiplier=1, min=2, max=60) + tenacity.wait_random(0, 2), # jitter stop=tenacity.stop_after_attempt(8), before_sleep=tenacity.before_sleep_log(logger, logging.WARNING), reraise=True, ) def generate_image_with_retry(model, prompt: str): """Generate image with automatic exponential backoff on 429 errors.""" response = model.generate_content( prompt, generation_config=genai.GenerationConfig( response_modalities=["image", "text"], ), ) return response genai.configure(api_key="YOUR_API_KEY") model = genai.GenerativeModel("gemini-3.1-flash") try: result = generate_image_with_retry(model, "A futuristic cityscape at sunset") # Process result.candidates[0].content.parts for image data except ResourceExhausted: logger.error("All retries exhausted. Consider upgrading tier.")
Реализация на Node.js с p-retry
Для приложений на Node.js пакет p-retry предоставляет эквивалентную функциональность с API на основе промисов, который чисто интегрируется с паттернами async/await. Следующая реализация повторяет поведение Python-версии и включает те же продакшен-гарантии — джиттер, максимальное количество попыток, логирование и правильную классификацию ошибок, чтобы избежать повторов ошибок, которые не подлежат повтору, таких как ошибки аутентификации или невалидные промпты.
javascriptconst pRetry = require('p-retry'); const { GoogleGenerativeAI } = require('@google/generative-ai'); const genAI = new GoogleGenerativeAI('YOUR_API_KEY'); async function generateImageWithRetry(prompt) { const model = genAI.getGenerativeModel({ model: 'gemini-3.1-flash' }); return pRetry( async (attemptNumber) => { console.log(`Attempt ${attemptNumber} for image generation...`); const result = await model.generateContent({ contents: [{ role: 'user', parts: [{ text: prompt }] }], generationConfig: { responseModalities: ['image', 'text'] }, }); return result.response; }, { retries: 7, minTimeout: 2000, // 2 seconds initial wait maxTimeout: 60000, // 60 seconds maximum wait factor: 2, // exponential factor randomize: true, // adds jitter automatically onFailedAttempt: (error) => { if (error.status !== 429) { throw error; // don't retry non-429 errors } console.warn( `Rate limited. Attempt ${error.attemptNumber} failed. ` + `${error.retriesLeft} retries remaining.` ); }, } ); }
Советы для продакшена по экспоненциальному бэкоффу: установите максимальное количество повторов от 6 до 10. При базе 2 секунды и множителе 2 восемь попыток покрывают общее окно ожидания примерно в 8,5 минут, что более чем достаточно для сброса лимитов RPM. Всегда устанавливайте абсолютный таймаут на всю операцию (а не только на отдельные повторы), чтобы запросы не зависали бесконечно. Логируйте каждый повтор с номером попытки и длительностью ожидания, чтобы отслеживать процент ошибок 429 на продакшен-дашбордах и знать, когда пора повышать уровень, а не полагаться только на повторы.
Решение 2 — Повышение тарифного уровня
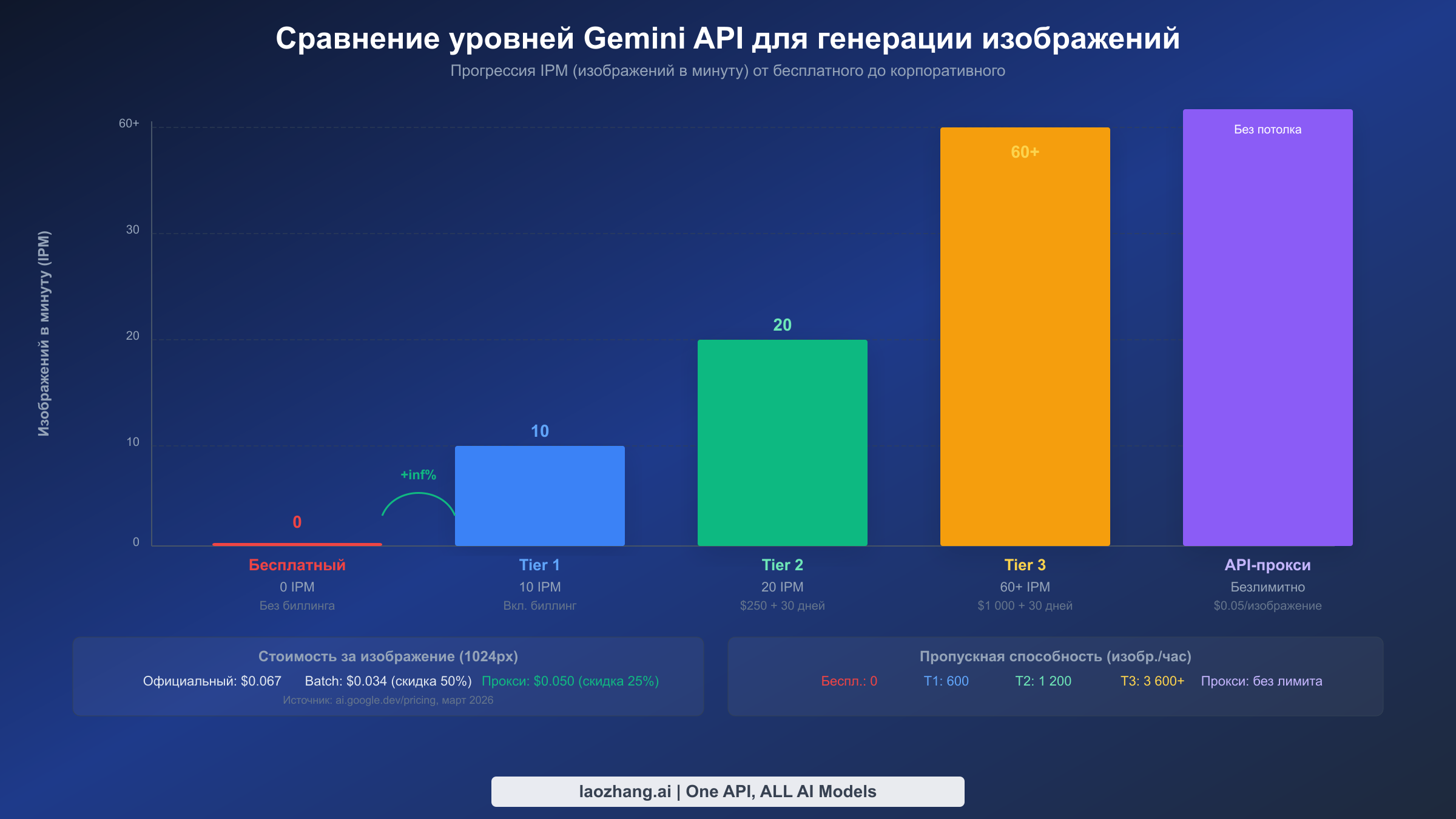
Хотя экспоненциальный бэкофф справляется с временными всплесками ошибок лимитов, наиболее надёжное долгосрочное решение для постоянных ошибок 429 — повышение тарифного уровня биллинга Google Cloud. Каждое повышение уровня умножает вашу квоту по всем четырём измерениям лимитов, и для генерации изображений именно увеличение IPM оказывает наибольшее влияние. Многие разработчики не осознают, что бесплатный уровень фактически полностью отключает генерацию изображений — квота IPM была снижена до 0 в декабре 2025 года. Простое подключение биллинга к проекту Google Cloud мгновенно переводит вас на Tier 1, который даёт 10 IPM без минимальных затрат. Это единственное действие устраняет подавляющее большинство ошибок 429, с которыми разработчики сталкиваются при начальной интеграции и тестировании.
Сравнение уровней для генерации изображений
Понимание конкретных квот на каждом уровне необходимо для выбора подходящего для вашей нагрузки. Следующая таблица показывает лимиты, непосредственно влияющие на генерацию изображений на всех доступных уровнях. Обратите внимание, что лимиты Tier 3 являются договорными через отдел продаж Google Cloud, поэтому указанные числа представляют стандартную базу, а не жёсткие максимумы.
| Уровень | Минимальные затраты в месяц | Временное требование | RPM | RPD | IPM | Batch TPD | Стоимость изображения (1K) |
|---|---|---|---|---|---|---|---|
| Бесплатный | Нет | Нет | 2 | 50 | 0 | Н/Д | Н/Д (заблокировано) |
| Tier 1 | Подключение биллинга (без минимума) | Мгновенно | 10 | 1 500 | 10 | 1M токенов | $0,067 |
| Tier 2 | $250 накопительно | 30 дней на Tier 1 | 30 | 10 000+ | 20 | 250M токенов | $0,067 |
| Tier 3 | $1 000 накопительно | 30 дней на Tier 2 | 60+ | Договорной | 60+ | 750M токенов | $0,067 |
Переход с бесплатного на Tier 1 — это безусловно самое значительное повышение, потому что оно переводит с 0 IPM (генерация изображений полностью недоступна) на 10 IPM, что достаточно для разработки, тестирования и продакшен-приложений с невысоким трафиком. Десять изображений в минуту соответствуют 600 изображениям в час или примерно 14 400 изображениям в день при непрерывной работе, что более чем достаточно для большинства малых и средних приложений. Переход с Tier 1 на Tier 2 удваивает IPM до 20 и кардинально увеличивает RPD с 1 500 до более 10 000, что важно для приложений, генерирующих изображения в течение всего дня, а не всплесками.
Как проверить и повысить текущий уровень
Проверка текущего тарифного уровня требует перехода в Google Cloud Console и изучения статуса биллинга вашего проекта. Перейдите в Google Cloud Console, выберите проект, откройте раздел «Биллинг», а затем страницу «Quotas & System Limits» в секции Generative Language API. Текущий уровень отображается рядом с каждой метрикой квоты. Если IPM указан как 0, вы на бесплатном уровне независимо от того, что показывает страница биллинга — это распространённый источник путаницы, потому что наличие биллингового аккаунта, привязанного к проекту, автоматически не означает, что биллинг включён для API генеративного ИИ. Необходимо убедиться, что биллинговый аккаунт привязан к проекту И что для Generative Language API биллинг включён в панели API. Для разработчиков, сталкивающихся с постоянными проблемами, когда их платный аккаунт, похоже, имеет лимиты бесплатного уровня, смотрите наше специализированное руководство по лимитам бесплатного уровня генерации изображений Gemini, которое проведёт через каждый шаг проверки.
Сроки повышения уровня: активация Tier 1 мгновенна при подключении биллинга. Tier 2 требует как $250 накопительных расходов, ТАК И 30 дней активного использования Tier 1 — вы не можете ускорить это, потратив $250 за один день. Tier 3 аналогично требует $1 000 накопительных расходов И 30 дней на Tier 2. Планируйте повышение уровня заранее, до момента масштабирования, потому что эти временные ограничения не могут быть обойдены через обращение в поддержку Google Cloud.
Решение 3 — Batch API для массовой генерации
Gemini Batch API — это недооценённое решение для разработчиков, которым нужно генерировать большие объёмы изображений, но не требуется отклик в реальном времени. Ключевое преимущество Batch API в том, что он работает на полностью отдельном пуле квот от API реального времени — это значит, что запросы пакетной генерации изображений не считаются в ваших лимитах RPM, RPD или IPM. Это разделение делает Batch API мощным дополнением к вашему конвейеру реального времени — вы можете перенести несрочную генерацию изображений на пакетную обработку, сохраняя квоту реального времени для интерактивных пользовательских запросов. Кроме того, Google предоставляет 50% скидку на все запросы через Batch API, что делает его значительно дешевле генерации в реальном времени для больших объёмов.
Как работает пакетная обработка
Batch API следует асинхронной модели на основе задач. Вы отправляете пакет промптов как единую задачу, Google ставит их в очередь обработки, и вы опрашиваете статус до завершения. Соглашение об уровне обслуживания гарантирует выполнение в течение 24 часов, хотя на практике большинство пакетных задач завершаются за 2-6 часов в зависимости от объёма и текущей загрузки системы. Каждая пакетная задача может содержать до 100 запросов, и вы можете одновременно отправлять несколько задач. Отдельный пул квот означает, что аккаунт Tier 1 с только 10 IPM для запросов реального времени может обрабатывать тысячи изображений через Batch API, ограниченный только выделением токенов для пакетной обработки: 1 миллион токенов в день для Tier 1, 250 миллионов для Tier 2 и 750 миллионов для Tier 3. Поскольку типичный запрос на генерацию изображения потребляет примерно 1 000-2 000 токенов, даже выделение Tier 1 поддерживает 500-1 000 изображений в день через пакетный конвейер.
Реализация на Python: пакетная генерация изображений
Следующий код демонстрирует, как создать задачу пакетной генерации изображений, отправить её в Gemini Batch API и опросить результаты. Этот паттерн подходит для рабочих процессов вроде генерации изображений товаров для интернет-магазина, массового создания активов для социальных сетей или предварительной обработки вариантов изображений для A/B-тестирования. Пакетная задача обрабатывает повторы внутренне, поэтому вам не нужно реализовывать экспоненциальный бэкофф для пакетных отправок.
pythonimport google.generativeai as genai import time import json genai.configure(api_key="YOUR_API_KEY") def batch_generate_images(prompts: list[str], model_name="gemini-3.1-flash"): """Submit a batch of image generation prompts and wait for results.""" # Prepare batch request batch_requests = [] for i, prompt in enumerate(prompts): batch_requests.append({ "custom_id": f"image-{i}", "request": { "model": model_name, "contents": [{"role": "user", "parts": [{"text": prompt}]}], "generation_config": { "response_modalities": ["image", "text"], }, }, }) # Submit batch job batch_job = genai.create_batch( requests=batch_requests, display_name=f"image-batch-{int(time.time())}", ) print(f"Batch job created: {batch_job.name}") print(f"Status: {batch_job.state}") # Poll for completion (24h SLA, typically 2-6h) while batch_job.state in ("QUEUED", "PROCESSING"): time.sleep(30) # Check every 30 seconds batch_job = genai.get_batch(batch_job.name) completed = sum(1 for r in batch_job.results if r.state == "COMPLETED") print(f" Progress: {completed}/{len(prompts)} completed") # Collect results results = {} for result in batch_job.results: if result.state == "COMPLETED": results[result.custom_id] = result.response else: print(f" Failed: {result.custom_id} - {result.error}") return results # Example usage prompts = [ "A modern office workspace with natural lighting", "A coffee shop interior with warm ambiance", "A serene garden with Japanese maples", # ... up to 100 prompts per batch ] results = batch_generate_images(prompts) print(f"Successfully generated {len(results)} images")
Экономия и выделения по уровням
50% скидка на пакетную обработку применяется ко всем размерам изображений, что делает стоимость за изображение значительно ниже, чем при генерации в реальном времени. При разрешении 1K стоимость снижается с $0,067 до примерно $0,034 за изображение. Для команд, генерирующих сотни или тысячи изображений ежедневно, одна только эта скидка может оправдать архитектурные инвестиции в инфраструктуру пакетной обработки. Выделения токенов для пакетной обработки по уровням также заслуживают внимания, поскольку они определяют максимальную пропускную способность пакетной обработки независимо от квот реального времени.
| Уровень | Пакетное выделение токенов (в день) | Приблизительная ёмкость изображений | Стоимость за изображение (1K, со скидкой 50%) |
|---|---|---|---|
| Tier 1 | 1M токенов | ~500-1 000 изображений | $0,034 |
| Tier 2 | 250M токенов | ~125 000-250 000 изображений | $0,034 |
| Tier 3 | 750M токенов | ~375 000-750 000 изображений | $0,034 |
Кардинальный скачок от Tier 1 к Tier 2 в пакетных выделениях (с 1M до 250M токенов) делает повышение до Tier 2 особенно ценным для нагрузок с интенсивной пакетной обработкой. Если ваше приложение может допустить асинхронный характер пакетной обработки для значительной части потребностей в генерации изображений, сочетание вызовов API реального времени для интерактивных запросов с пакетной обработкой для фоновых задач даёт лучшее из обоих миров. Дополнительные стратегии оптимизации затрат с помощью пакетной обработки описаны в нашем руководстве по оптимизации затрат Batch API.
Решение 4 — API-прокси для неограниченной пропускной способности
Когда вашему приложению требуется пропускная способность, превышающая даже лимиты Tier 3, или когда вы хотите избежать сложности управления тарифными уровнями Google Cloud и мониторинга квот, сервис API-прокси обеспечивает принципиально иной подход к проблеме ограничения запросов. API-прокси агрегирует несколько API-ключей и проектов Google Cloud за единой унифицированной конечной точкой, распределяя ваши запросы по этому пулу для фактического устранения лимитов отдельных проектов. С точки зрения вашего приложения, вы делаете API-вызовы к одной конечной точке с одним ключом, а прокси управляет балансировкой нагрузки, отслеживанием квот и автоматическим переключением за кулисами. Этот подход особенно ценен для стартапов и компаний среднего размера, которым нужна пропускная способность продакшен-уровня без операционных затрат на управление несколькими проектами Google Cloud и биллинговыми аккаунтами.
Как API-прокси решают проблему ограничения запросов
Фундаментальная идея API-прокси заключается в том, что лимиты Google применяются на уровне проекта, а не пользователя или организации. Прокси-сервис поддерживает пул из N проектов, каждый со своим независимым выделением квот. Когда поступает ваш запрос, прокси направляет его к проекту с доступной квотой, фактически умножая общую пропускную способность на количество проектов в пуле. Если каждый проект имеет 10 IPM, а пул содержит 20 проектов, ваш эффективный лимит становится 200 IPM — это далеко за пределами возможностей любого отдельного аккаунта Tier 3. Прокси также отслеживает использование квот по всем проектам в реальном времени, реализуя интеллектуальную маршрутизацию, которая избегает отправки запросов к проектам, близким к своим лимитам. Такая распределённая архитектура делает ошибки 429 практически невозможными при нормальных условиях работы, поскольку у прокси всегда есть свободная ёмкость.
Минимальные изменения в коде
Переход с прямого доступа к Gemini API на конечную точку прокси требует изменения всего трёх строк кода в большинстве реализаций. API-прокси, поддерживающие интерфейс, совместимый с OpenAI, позволяют использовать стандартный OpenAI SDK, с которым многие разработчики уже знакомы. Следующие примеры показывают «до» и «после» для Python и Node.js:
python# Before: Direct Gemini API import google.generativeai as genai genai.configure(api_key="YOUR_GOOGLE_API_KEY") model = genai.GenerativeModel("gemini-3.1-flash") # After: Through API proxy (OpenAI-compatible) from openai import OpenAI client = OpenAI( api_key="YOUR_PROXY_KEY", base_url="https://api.laozhang.ai/v1" # proxy endpoint ) response = client.chat.completions.create( model="gemini-3.1-flash", messages=[{"role": "user", "content": "Generate an image of a sunset"}], )
Подход через прокси предлагает несколько преимуществ помимо чистой пропускной способности. Во-первых, вы получаете модель ценообразования с фиксированной ставкой — laozhang.ai берёт $0,05 за изображение независимо от разрешения, тогда как у Google тарификация зависит от уровня: $0,045 (512px), $0,067 (1K), $0,101 (2K) или $0,151 (4K). Для приложений, генерирующих изображения в разрешении 2K или 4K, прокси фактически дешевле прямого доступа к API. Во-вторых, прокси обрабатывает всю логику повторов, управление квотами и обработку ошибок внутренне, уменьшая сложность кода вашего приложения. В-третьих, вы избегаете 30-дневных ограничений, необходимых для повышения уровня — прокси обеспечивает высокую пропускную способность с первого дня.
Когда использовать API-прокси: приложения реального времени, требующие более 60 IPM, команды, желающие избежать сложностей управления биллингом Google Cloud, приложения, генерирующие изображения высокого разрешения, где фиксированная ставка дешевле официальной тарификации, и проекты, которым нужно быстро масштабироваться без ожидания периодов повышения уровня.
Решение 5 — Стратегия мультимодельного фоллбэка
Gemini API предлагает несколько моделей, способных генерировать изображения, и каждый вариант модели поддерживает собственные независимые лимиты. Эта архитектурная деталь создаёт возможность для мощной стратегии фоллбэка: когда одна модель достигает лимита, ваше приложение автоматически переключается на альтернативную модель, у которой ещё есть доступная квота. Этот подход умножает эффективную пропускную способность без повышения уровня, дополнительных биллинговых аккаунтов или внешних прокси-сервисов. Компромисс в том, что разные модели могут генерировать изображения немного разного качества и стиля, поэтому эта стратегия лучше всего работает для приложений, где единообразие всех сгенерированных изображений не критично.
Построение цепочки фоллбэка
Наиболее эффективная цепочка фоллбэка для генерации изображений в начале 2026 года использует три модели в порядке приоритета: gemini-3.1-flash-image как основная модель (самая быстрая, самая дешёвая), gemini-3-pro-image как вторичная (более высокое качество, чуть медленнее) и imagen-4 как третичный вариант (специализированная модель для изображений, другой стиль). У каждой модели собственные квоты RPM, IPM и RPD, которые отслеживаются Google независимо. Если IPM вашей основной модели исчерпан, пул IPM вторичной модели, вероятно, нетронут, потому что к ней не поступали запросы. Это даёт эффективный IPM 30 на Tier 1 (10 на модель умножить на 3 модели) вместо 10 IPM при использовании одной модели.
Следующая реализация на Python создаёт класс ModelFallbackClient, который автоматически переключается между моделями при возникновении ошибок 429. Он сочетает экспоненциальный бэкофф из Решения 1 с ротацией моделей, обеспечивая два уровня устойчивости. Клиент отслеживает, какие модели в данный момент ограничены и их расчётное время восстановления, избегая бесполезных запросов к моделям, которые заведомо ограничены.
pythonimport google.generativeai as genai from google.api_core.exceptions import ResourceExhausted import time import logging logger = logging.getLogger(__name__) class ModelFallbackClient: """Image generation client with automatic model fallback on 429 errors.""" FALLBACK_CHAIN = [ "gemini-3.1-flash", # Primary: fast, cheap "gemini-3-pro", # Secondary: higher quality "imagen-4", # Tertiary: specialized image model ] def __init__(self, api_key: str): genai.configure(api_key=api_key) self.models = { name: genai.GenerativeModel(name) for name in self.FALLBACK_CHAIN } self.cooldowns = {} # model_name -> earliest_retry_time def generate_image(self, prompt: str, max_retries: int = 3): """Generate image, falling back through model chain on 429 errors.""" for model_name in self.FALLBACK_CHAIN: # Skip models in cooldown if model_name in self.cooldowns: if time.time() < self.cooldowns[model_name]: logger.info(f"Skipping {model_name} (cooldown)") continue else: del self.cooldowns[model_name] for attempt in range(max_retries): try: logger.info(f"Trying {model_name} (attempt {attempt + 1})") response = self.models[model_name].generate_content( prompt, generation_config=genai.GenerationConfig( response_modalities=["image", "text"], ), ) return {"model": model_name, "response": response} except ResourceExhausted: wait = (2 ** attempt) + (time.time() % 1) # backoff + jitter logger.warning( f"{model_name} rate limited. " f"Waiting {wait:.1f}s before retry." ) time.sleep(wait) # All retries exhausted for this model — add cooldown and try next self.cooldowns[model_name] = time.time() + 60 logger.warning(f"{model_name} exhausted. Moving to next model.") raise ResourceExhausted("All models in fallback chain exhausted.") # Usage client = ModelFallbackClient("YOUR_API_KEY") result = client.generate_image("A photorealistic mountain landscape at dawn") print(f"Generated by: {result['model']}")
Компромиссы и особенности
Стратегия мультимодельного фоллбэка не лишена ограничений, и понимание этих компромиссов необходимо для принятия решения о её применимости в вашем случае. Наиболее значительный компромисс — визуальная согласованность: gemini-3.1-flash и gemini-3-pro используют разные базовые архитектуры и обучающие данные, а это значит, что один и тот же промпт может давать заметно отличающиеся результаты на разных моделях. Для приложений типа генерации контента для социальных сетей, где каждое изображение существует самостоятельно, эта несогласованность несущественна. Для приложений типа генерации каталога товаров, где визуальная согласованность всех изображений важна, фоллбэк на другую модель может дать результаты, выбивающиеся из установленного визуального стиля. Ещё одно соображение — imagen-4 использует иной API-контракт, чем модели Gemini: это выделенная модель генерации изображений, а не мультимодальная LLM, поэтому промпты могут потребовать небольших корректировок для оптимальных результатов. Клиент фоллбэка выше обрабатывает это прозрачно, но вам следует протестировать конкретные промпты на всех трёх моделях, чтобы понять различия в качестве, прежде чем развёртывать эту стратегию в продакшене.
Какое решение выбрать?

Выбор правильной комбинации решений зависит от конкретных требований вашего приложения к пропускной способности, задержке, стоимости и операционной сложности. Ни одно решение не является универсально оптимальным — хобби-проекту с нечастой генерацией изображений нужен принципиально иной подход, чем корпоративной платформе, обслуживающей миллионы пользователей. Таблица ниже сопоставляет три типичных профиля разработчиков с рекомендуемыми комбинациями решений и обоснованием каждой рекомендации. На практике большинство продакшен-приложений используют комбинацию двух-трёх решений для максимальной устойчивости, при этом экспоненциальный бэкофф служит универсальной основой, которую должна включать каждая реализация независимо от масштаба.
| Профиль | Рекомендуемые решения | Месячный объём изображений | Ожидаемая стоимость | Обоснование |
|---|---|---|---|---|
| Хобби / Пет-проект | Решение 1 (бэкофф) + Решение 2 (Tier 1) | < 10 000 | < $10 | Tier 1 открывает 10 IPM, бэкофф обрабатывает всплески |
| Стартап / Растущее приложение | Решение 1 + Решение 3 (Batch) + Решение 4 (прокси) | 10 000 - 500 000 | $50 - $500 | Batch для массовой генерации, прокси для пиковых нагрузок реального времени |
| Предприятие / Большой масштаб | Решение 1 + Решение 2 (Tier 3) + Решение 3 + Решение 5 (фоллбэк) | 500 000+ | $500+ | Многоуровневая устойчивость с выделенными квотами |
Для большинства разработчиков, впервые столкнувшихся с ошибками 429, план действий ясен: реализуйте экспоненциальный бэкофф немедленно (Решение 1, занимает 15 минут), затем подключите биллинг для достижения Tier 1 (Решение 2, занимает 5 минут в GCP Console). Эти два изменения устраняют 95% ошибок 429 для приложений, генерирующих менее 10 изображений в минуту. Если ваши потребности вырастут, добавьте Batch API для несрочной генерации и рассмотрите API-прокси для нагрузок реального времени, превышающих лимиты уровня.
Как долго длится ограничение 429? Длительность зависит от того, какое измерение вы превысили. Лимиты RPM сбрасываются в скользящем 60-секундном окне, поэтому ожидание всего одной минуты восстанавливает полную поминутную квоту. Лимиты RPD сбрасываются в полночь по тихоокеанскому времени, что означает: превышение суточного лимита днём приводит к ожиданию в несколько часов. Лимиты IPM следуют тому же 60-секундному окну, что и RPM. У бага фантомных 429 нет предсказуемой длительности — некоторые разработчики сообщают о его разрешении в течение нескольких часов, тогда как другим потребовалось переключить модель или пересоздать API-ключ.
Можно ли получить более 60 IPM? Да. Лимиты Tier 3 указаны как «60+», потому что они являются договорными. Если вы свяжетесь с отделом продаж Google Cloud через GCP Console и сможете продемонстрировать обоснованную бизнес-потребность в более высокой пропускной способности, Google предоставит пользовательские квоты, которые могут достигать сотен или тысяч IPM. Корпоративные аккаунты с контрактами на фиксированное потребление обычно договариваются о пользовательских лимитах в рамках общего соглашения с Google Cloud, со скидками, масштабируемыми по объёму.
Безопасно ли использование API-прокси? Авторитетные API-прокси функционируют как прозрачные передающие слои — они получают ваш запрос, направляют его к API Google через одни из своих управляемых учётных данных и возвращают ответ вам. Прокси не хранит ваши промпты, сгенерированные изображения или ответы API дольше, чем необходимо для завершения запроса. Тем не менее, вы доверяете оператору прокси содержание своих запросов, поэтому выбирайте проверенные сервисы с понятной политикой конфиденциальности и репутацией в сообществе разработчиков. Модель безопасности сравнима с использованием любого стороннего SaaS API — вам следует оценить репутацию провайдера и практики обработки данных перед отправкой чувствительных промптов.
Почему я получаю 429 при нулевом использовании? Это почти наверняка баг фантомных 429 от февраля 2026 года, затрагивающий недавно обновлённые аккаунты Tier 1. Немедленный обходной путь — переключить вариант модели: если вы используете gemini-3.1-flash, попробуйте gemini-3-pro и наоборот. Некоторые разработчики также решили проблему, создав новый API-ключ в том же проекте, хотя это не всегда эффективно. Google подтвердил проблему и работает над постоянным решением. Если проблема сохраняется более 48 часов после повышения уровня, откройте запрос в поддержку через Google Cloud Console с ID проекта и конкретным телом ответа об ошибке, включая метаданные квот в заголовках.