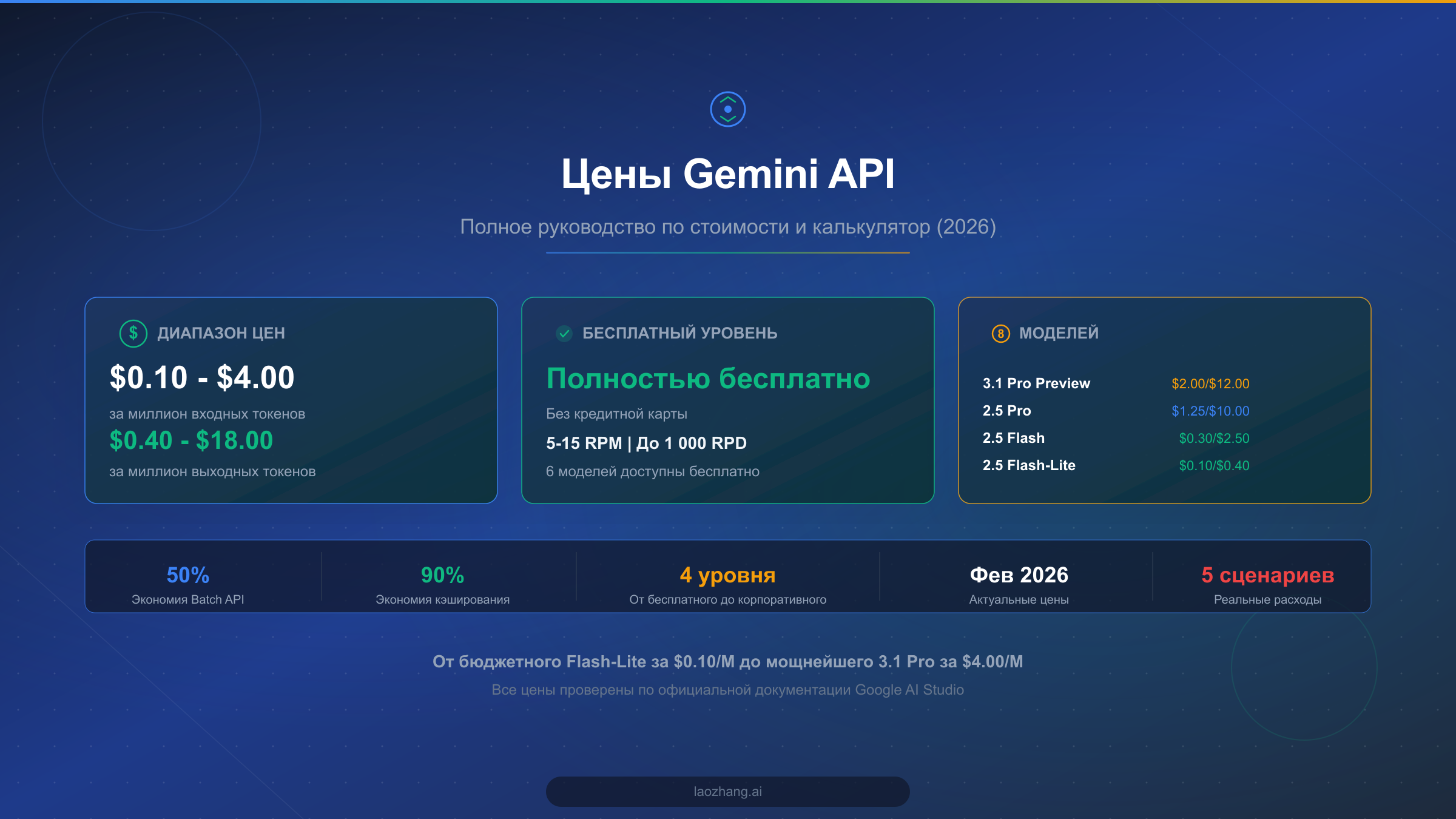
Стоимость Gemini API охватывает удивительно широкий диапазон: от $0.10 за миллион входных токенов для бюджетной модели Flash-Lite до $4.00 за миллион входных токенов для самой мощной 3.1 Pro Preview, согласно официальной странице цен Google AI Studio, проверенной 26 февраля 2026 года. Стоимость выходных токенов варьируется от $0.40 до $18.00 за миллион. Google также предлагает полноценный бесплатный уровень без необходимости привязки кредитной карты, поддерживающий от 5 до 15 запросов в минуту и до 1000 запросов в день для шести различных моделей. Независимо от того, создаете ли вы проект на выходных или масштабируете корпоративный AI-конвейер, понимание этих ценовых уровней необходимо для предсказуемого контроля расходов при работе с наиболее продвинутыми языковыми моделями Google.
Краткое содержание
Стоимость Gemini API составляет от $0.10 до $4.00 за миллион входных токенов в зависимости от выбранной модели. Бесплатный уровень предоставляет доступ к шести моделям, включая Gemini 2.5 Flash и 3 Flash Preview, с лимитами 5-15 RPM и до 1000 запросов в день. При платном использовании Gemini 2.5 Flash-Lite предлагает лучшее соотношение цена/качество за $0.10/$0.40 на миллион токенов, тогда как Gemini 2.5 Pro обеспечивает оптимальный баланс возможностей и стоимости за $1.25/$10.00. Вы можете сократить расходы до 90% за счет кэширования контекста, пакетной обработки и грамотного выбора моделей.
Полная таблица цен Gemini API (февраль 2026)
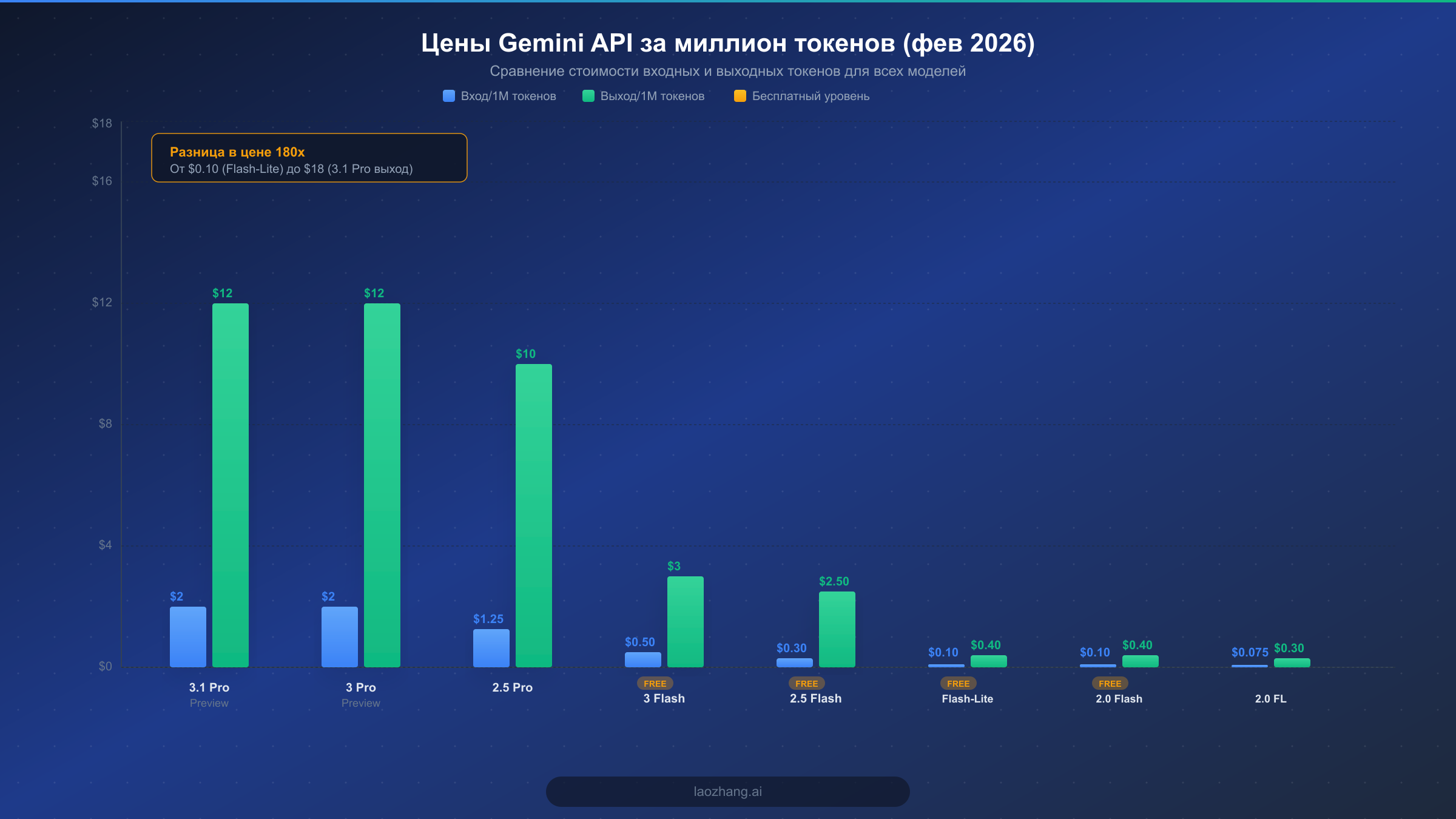
В настоящее время Google предлагает восемь различных моделей через Gemini API, каждая из которых нацелена на определенные сценарии использования и бюджетные рамки. Структура ценообразования основана на простой модели оплаты за токены: вы отдельно платите за входные токены (ваши промпты и контекст) и за выходные токены (ответы модели). Понимание полной ценовой картины критически важно, поскольку разница между самым дешевым и самым дорогим вариантами составляет 180-кратный множитель стоимости, а значит, неправильный выбор модели может кратно увеличить ваш ежемесячный счет.
Флагманскими моделями линейки Gemini являются 3.1 Pro Preview и 3 Pro Preview, обе по цене $2.00 за миллион входных токенов и $12.00 за миллион выходных токенов при окне контекста до 200 000 токенов (ai.google.dev, февраль 2026). При превышении порога в 200K токенов эти цены удваиваются до $4.00 и $18.00 соответственно, что делает критически важным мониторинг длины контекста при работе с большими документами или продолжительными диалогами. Эти модели Pro обеспечивают наивысший уровень рассуждений и лучше всего подходят для сложного анализа, многоэтапного решения задач и работы, где точность важнее экономической эффективности.
Gemini 2.5 Pro занимает привлекательную среднюю позицию по цене $1.25 за миллион входных токенов и $10.00 за миллион выходных токенов при стандартном контексте, с повышением до $2.50 и $15.00 для контекстов, превышающих 200K токенов (ai.google.dev, февраль 2026). Для большинства рабочих нагрузок в продакшене эта модель представляет оптимальный баланс между возможностями и стоимостью, обеспечивая производительность, близкую к флагманской, примерно за 60% от цены Pro Preview. Разработчики, создающие приложения, которым нужны мощные способности к рассуждению без премиальной цены, часто обнаруживают, что 2.5 Pro эффективно справляется с их задачами, оставляя запас в бюджете для масштабирования.
Семейство моделей Flash является находкой для разработчиков, ориентированных на экономию. Gemini 3 Flash Preview стоит $0.50 за миллион входных токенов для текста и $1.00 для аудио, а выходные токены обходятся в $3.00 за миллион. Gemini 2.5 Flash ещё дешевле: $0.30 за миллион текстовых входных токенов и $2.50 за выходные. Для минимальной стоимости за токен Gemini 2.5 Flash-Lite берет всего $0.10 за миллион входных токенов и $0.40 за миллион выходных, что делает его одной из самых доступных языковых моделей коммерческого класса на рынке. Gemini 2.0 Flash совпадает с Flash-Lite по цене $0.10/$0.40 для текста, а ещё более ранняя 2.0 Flash-Lite достигает ценового дна на уровне $0.075 за миллион входных токенов и $0.30 за выходные (invertedstone.com, февраль 2026).
| Модель | Вход/1M (<=200K) | Выход/1M (<=200K) | Вход/1M (>200K) | Выход/1M (>200K) |
|---|---|---|---|---|
| Gemini 3.1 Pro Preview | $2.00 | $12.00 | $4.00 | $18.00 |
| Gemini 3 Pro Preview | $2.00 | $12.00 | $4.00 | $18.00 |
| Gemini 2.5 Pro | $1.25 | $10.00 | $2.50 | $15.00 |
| Gemini 3 Flash Preview | $0.50 (текст) | $3.00 | - | - |
| Gemini 2.5 Flash | $0.30 (текст) | $2.50 | - | - |
| Gemini 2.5 Flash-Lite | $0.10 (текст) | $0.40 | - | - |
| Gemini 2.0 Flash | $0.10 (текст) | $0.40 | - | - |
| Gemini 2.0 Flash-Lite | $0.075 | $0.30 | - | - |
Обработка аудиовхода обходится дороже для всех моделей Flash. Gemini 2.5 Flash взимает $1.00 за миллион аудиотокенов по сравнению с $0.30 за текст, тогда как Flash-Lite берет $0.30 за аудио против $0.10 за текст. Если ваше приложение обрабатывает значительный объем аудиоконтента, учитывайте этот трехкратный множитель при расчете стоимости. Для приложений, которые могут работать с новейшими возможностями Gemini, ознакомьтесь с нашим руководством по бесплатному доступу к API Gemini 3.1 Pro, чтобы узнать о текущей доступности моделей.
Бесплатный ли Gemini API? Полное руководство по бесплатному уровню
Одним из наиболее привлекательных аспектов Gemini API является его полноценный бесплатный уровень, который не требует ни кредитной карты, ни настройки биллинга. В отличие от многих конкурентов, предлагающих ограниченные пробные кредиты или ограниченные по времени пробные периоды, Google обеспечивает постоянный бесплатный доступ к шести моделям, включая Gemini 3 Flash Preview, Gemini 2.5 Flash, Gemini 2.5 Flash-Lite, Gemini 2.0 Flash, Gemini Embedding и модели с открытым исходным кодом Gemma 3 и 3n (ai.google.dev, февраль 2026). Это делает Gemini одной из наиболее доступных AI API-платформ для разработчиков, которые хотят прототипировать, экспериментировать или создавать приложения с низким трафиком без каких-либо финансовых обязательств.
Бесплатный уровень имеет существенные лимиты скорости, определяющие реальный объем работы без оплаты. Лимиты запросов в минуту (RPM) варьируются от 5 до 15 в зависимости от конкретной модели, причем большинство моделей Flash допускают около 10 RPM. Лимиты дневных запросов (RPD) варьируются значительнее: от примерно 100 до 1000 запросов в день в зависимости от модели и текущего распределения. Лимиты токенов в минуту (TPM) составляют около 250 000, что обеспечивает достаточную пропускную способность для умеренного интерактивного использования, но может стать узким местом при пакетной обработке или в высоконагруженных приложениях. Для более детального разбора этих лимитов и их влияния на различные сценарии использования ознакомьтесь с нашим подробным руководством по бесплатному уровню Gemini API.
Важно понимать, что изменилось в декабре 2025 года, когда Google существенно сократил квоты бесплатного уровня примерно на 50-80% (подтверждено отчетами Reddit и HowToGeek). До этих сокращений пользователи бесплатного уровня пользовались значительно более щедрыми лимитами, и их урезание застало многих разработчиков врасплох. Текущие лимиты по-прежнему обеспечивают реальную пользу для личных проектов и прототипирования, однако разработчики, полагавшиеся на бесплатный уровень для продакшен-нагрузок, были вынуждены перейти на платные планы или кардинально снизить объем использования. Если вы планируете опираться на бесплатный уровень, предусмотрите запас и внимательно отслеживайте потребление, поскольку квоты могут меняться без значительного предварительного уведомления.
Существует одно критическое ограничение, которое многие разработчики упускают из виду: контент, отправленный через бесплатный уровень, может использоваться Google для улучшения их моделей. Это означает, что конфиденциальные данные, проприетарный код или секретную бизнес-информацию категорически нельзя обрабатывать через бесплатный доступ. Платный уровень, напротив, предусматривает соглашения об обработке данных, запрещающие Google использовать ваши данные для обучения моделей. Одно это различие часто становится решающим фактором для компаний, оценивающих пригодность бесплатного уровня для своих задач. Для полной картины лимитов скорости на всех уровнях ознакомьтесь с нашим руководством по лимитам скорости Gemini API.
Когда стоит перейти с бесплатного на платный уровень?
Решение о переходе с бесплатного на платный план обычно определяется тремя факторами: потребностью в пропускной способности, требованиями к конфиденциальности данных и ожиданиями по надежности. Если вы постоянно упираетесь в лимиты RPM или RPD при обычной работе, или если ваше приложение обслуживает реальных пользователей, ожидающих стабильного времени отклика, переход на Tier 1 (для которого достаточно просто настроить платежный аккаунт) немедленно повышает RPM до 150-300 в зависимости от модели. Оплата основана исключительно на фактическом использовании без минимальных обязательств, поэтому вы платите только за реально потребленные ресурсы. Tier 2 требует накопленных расходов не менее $250 за 30 дней и открывает 1000+ RPM, а Tier 3 при расходах от $1000 обеспечивает ещё более высокие лимиты, подходящие для развертываний корпоративного масштаба (aifreeapi.com, январь 2026).
Реальная стоимость Gemini API: 5 практических сценариев

Таблицы с ценами за токены полезны для сравнения, но большинство разработчиков хотят знать одно: сколько это реально будет стоить каждый месяц? Ответ сильно зависит от конкретного сценария использования, выбранной модели, эффективности структурирования промптов и того, используете ли вы функции оптимизации вроде кэширования и пакетной обработки. Сырые цены за токен могут вводить в заблуждение, так как не учитывают различные соотношения входных и выходных токенов, которые генерируют разные приложения, и не отражают влияние выбора модели на общее количество токенов, необходимых для достижения приемлемых результатов. Ниже представлены пять детальных реальных сценариев, основанных на типичных применениях Gemini API, с оценками токенов, рассчитанными на основе типичных паттернов использования и стоимости по официальным ценам, проверенным в феврале 2026 года. Эти оценки предполагают стандартное использование без оптимизации, поэтому ваши реальные расходы могут быть значительно ниже, если вы реализуете стратегии, описанные далее в этом руководстве.
Сценарий 1: Чат-бот поддержки клиентов ($5-$30/месяц)
Чат-бот службы поддержки, обрабатывающий от 500 до 2000 ежедневных запросов, представляет один из самых распространенных сценариев использования Gemini API. При использовании Gemini 2.5 Flash по цене $0.30 за миллион входных токенов и $2.50 за миллион выходных, со средним потреблением около 1000 входных токенов на диалог (системный промпт, запрос пользователя и история общения) и генерацией примерно 500 выходных токенов на ответ, вы будете обрабатывать от 15 до 60 миллионов токенов в месяц. При нижнем уровне нагрузки в 500 ежедневных запросов ваш ежемесячный счет составит примерно $5-$8, тогда как 2000 ежедневных запросов увеличат расходы до $20-$30. Привлекательный момент заключается в том, что если ваш трафик не выходит за лимиты бесплатного уровня (примерно 1000 RPD), такой чат-бот потенциально может работать совершенно бесплатно, что делает его одним из самых доступных способов развернуть AI-поддержку клиентов.
Сценарий 2: Ассистент для программирования ($15-$60/месяц)
Ассистент для разработчиков обычно требует более мощную модель, такую как Gemini 2.5 Pro, для обработки сложной генерации кода, отладки и архитектурных предложений. При 100-500 ежедневных запросах со средним объемом 2000 входных токенов (контекст кода, содержимое файлов и инструкции) и 1000 выходных токенов (сгенерированный код и пояснения) месячное потребление составит от 6 до 15 миллионов токенов. По ценам 2.5 Pro в $1.25 за миллион входных токенов и $10.00 за миллион выходных это выливается примерно в $15 при минимальной нагрузке и до $60 при интенсивном использовании. Кэширование контекста может кардинально сократить эти расходы, если ваши пользователи часто работают в одной и той же кодовой базе, поскольку закэшированный системный контекст и структура репозитория тарифицируются по сниженным ставкам, потенциально сокращая затраты на 50-75%.
Сценарий 3: Конвейер анализа документов ($30-$120/месяц)
Рабочие нагрузки по анализу документов, такие как проверка контрактов, извлечение данных из PDF и суммаризация отчетов, отличаются высоким объемом входных токенов, поскольку каждый документ может содержать десятки тысяч токенов. При обработке от 20 до 100 документов ежедневно с помощью Gemini 2.5 Pro, где каждый документ в среднем содержит 50 000 входных токенов и генерирует 2000 выходных токенов извлеченной информации, ежемесячное потребление составит от 30 до 150 миллионов токенов. Здесь критически важен ценовой уровень, зависящий от длины контекста: если ваши документы превышают порог в 200K токенов в одном запросе, стоимость входных токенов удваивается с $1.25 до $2.50 за миллион. При стандартной длине контекста ежемесячные расходы составят от $30 до $120, однако длинные документы могут существенно увеличить эту сумму. Пакетная обработка через Batch API со скидкой 50% может значительно снизить затраты для не критичных по времени рабочих процессов обработки документов.
7 способов сократить расходы на Gemini API до 90%
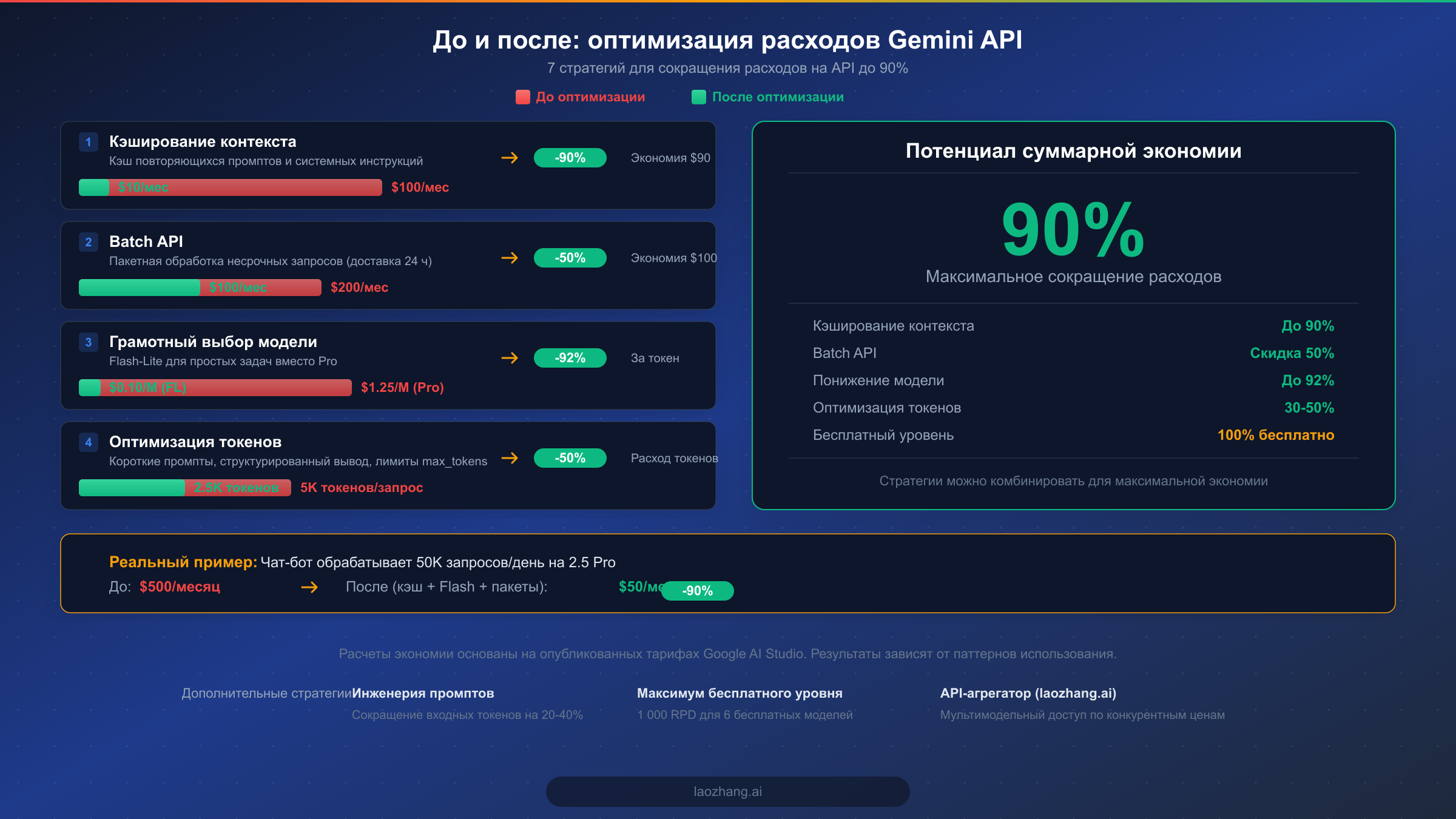
Оптимизация расходов -- это область, где достигается реальная экономия, и Gemini API предлагает несколько мощных механизмов, которые большинство разработчиков недоиспользуют. Комбинируя правильные стратегии, вполне реалистично сократить расходы на API на 70-90% по сравнению с наивной реализацией. Ключ в понимании того, какие оптимизации применимы к вашим конкретным паттернам использования, и в их эффективной комбинации.
Кэширование контекста: самая значительная экономия (до 90%)
Кэширование контекста -- самая эффективная оптимизация, доступная в Gemini API, и удивительно мало разработчиков ею пользуются. Когда ваше приложение многократно отправляет один и тот же системный промпт, примеры few-shot или справочные документы с каждым запросом, вы каждый раз оплачиваете полную стоимость входных токенов за идентичный контент. Кэширование контекста позволяет сохранить этот повторяющийся контекст и ссылаться на него в нескольких запросах по кардинально сниженным ставкам: закэшированные токены обходятся до 90% дешевле обычных входных (ai.google.dev, февраль 2026). Компромисс заключается в плате за хранение кэша -- $4.50 за миллион токенов в час, поэтому эта оптимизация оправдана только при достаточно частом повторном использовании закэшированного контента, когда экономия на входных токенах перевешивает стоимость хранения. Для чат-бота с системным промптом в 2000 токенов и 1000 ежедневных запросов кэширование этого промпта экономит примерно $0.60 в день на входных токенах, тогда как хранение может обойтись в $0.22 в день, обеспечивая очевидную чистую экономию.
Batch API: скидка 50% для несрочных задач
Batch API предоставляет фиксированную скидку 50% как на входные, так и на выходные токены в обмен на 24-часовое окно доставки результатов (ai.google.dev, февраль 2026). Это идеальный вариант для задач, не требующих немедленных ответов: ночная генерация контента, массовая классификация данных, конвейеры суммаризации документов и периодическая аналитическая обработка. Реализация проста: вместо отдельных синхронных запросов вы отправляете пакет промптов и забираете результаты по завершении обработки. Для конвейера генерации контента, производящего 50 статей ежедневно при обычной стоимости $30 в месяц, переход на пакетную обработку немедленно сокращает эту сумму до $15 в месяц без снижения качества.
Грамотный выбор модели: подбирайте модель под задачу
Одна из самых распространенных и дорогостоящих ошибок -- использование мощной модели Pro для задач, с которыми модель Flash справляется ничуть не хуже. Gemini 2.5 Flash-Lite по цене $0.10 за миллион входных токенов в 12.5 раз дешевле Gemini 2.5 Pro по $1.25, однако для многих рутинных задач -- классификации текста, простого извлечения данных, прямолинейных ответов на вопросы -- Flash-Lite дает сопоставимые результаты. Практичный подход состоит в создании маршрутизирующего слоя, который оценивает входящие запросы и направляет их на соответствующий уровень модели. Сложные задачи на рассуждение -- на Pro, стандартные задачи -- на Flash, простая классификация -- на Flash-Lite. Такой многоуровневый подход обычно сокращает общие расходы на 60-80%, сохраняя качество там, где оно действительно важно.
Оптимизация промптов: сокращение токенов на 20-40%
Инженерия промптов -- недооцененный рычаг экономии, поскольку она снижает затраты у самого источника, минимизируя количество отправляемых и получаемых токенов. Наиболее эффективная техника -- замена многословных инструкций на естественном языке структурированными форматами. Вместо того чтобы писать «Пожалуйста, проанализируйте следующий текст и предоставьте подробное резюме, включая основные темы, ключевые выводы и все упомянутые рекомендации», можно использовать структурированный промпт вроде «Резюме: темы, выводы, рекомендации» с четкой спецификацией формата вывода. Такое сжатие регулярно сокращает входные токены на 20-40% без ущерба для качества результата. Аналогично, установка явных лимитов max_tokens предотвращает генерацию моделью неоправданно длинных ответов. Если вам нужно резюме на 100 слов, установка max_tokens на 150 не позволит модели выдать эссе на 500 слов, экономя примерно 70% расходов на выходные токены для этого запроса.
Максимальное использование бесплатного уровня и стратегическая маршрутизация моделей
Даже после перехода на платный уровень квоты бесплатного уровня продолжают действовать как отдельное выделение, которое не засчитывается в оплачиваемое использование. Грамотная архитектура может направлять трафик разработки, внутреннего тестирования и низкоприоритетных фоновых задач через бесплатный доступ, резервируя платный уровень для продакшен-запросов от реальных пользователей. С учетом 1000 бесплатных ежедневных запросов для шести моделей эта стратегия может компенсировать значительную часть общих расходов, особенно для небольших команд. Для организаций, работающих с несколькими AI-провайдерами, агрегаторные платформы вроде laozhang.ai предоставляют мультимодельный доступ с конкурентоспособными ценами и упрощенным биллингом, что позволяет дополнительно снизить затраты благодаря скидкам за объем и интеллектуальной маршрутизации моделей, автоматически выбирающей наиболее экономичную модель для каждого типа запросов.
Gemini vs OpenAI vs Claude: какой API дешевле?
Выбор между Gemini, OpenAI и Claude от Anthropic часто сводится к пересечению цены, возможностей и специфических требований конкретного сценария использования. По состоянию на февраль 2026 года ценовой ландшафт демонстрирует четкую дифференциацию между тремя основными провайдерами, каждый из которых предлагает уникальное ценностное предложение для различных типов рабочих нагрузок и бюджетов.
Сравнивая цены на флагманские модели, Gemini 2.5 Pro от Google по цене $1.25 за миллион входных токенов и $10.00 за миллион выходных значительно дешевле GPT-4o от OpenAI по $5.00/$15.00 и кардинально доступнее Claude Opus от Anthropic по $15.00/$75.00 за миллион токенов (intuitionlabs.ai, февраль 2026). Это означает, что для эквивалентных рабочих нагрузок Gemini 2.5 Pro обходится примерно на 75% дешевле GPT-4o по входным токенам и на 33% дешевле по выходным. В сравнении с Claude Opus экономия ещё более впечатляющая -- свыше 90% как на входных, так и на выходных токенах. Для чувствительных к стоимости приложений, которые не требуют специфических возможностей OpenAI или Claude, Gemini представляет убедительный экономический аргумент.
В бюджетном сегменте модели Gemini Flash-Lite по $0.10 за миллион входных токенов выгодно конкурируют с GPT-4o Mini от OpenAI и Claude Haiku от Anthropic. Модели xAI Grok предлагают ещё более низкую стоимость за токен: $0.20 за миллион входных и $0.50 за миллион выходных, однако с меньшей экосистемой, меньшим количеством интеграций и менее обширной документацией по сравнению с устоявшимися провайдерами. Для продакшен-нагрузок, обрабатывающих миллионы токенов ежедневно, эти различия в цене за токен превращаются в существенную ежемесячную экономию, зачастую составляющую тысячи долларов в месяц при масштабной работе. Если выразить это в конкретных цифрах, приложение, обрабатывающее 100 миллионов токенов в месяц, обойдется примерно в $125 с Gemini 2.5 Pro, $500 с GPT-4o и $1500 с Claude Opus только за входные токены, наглядно демонстрируя, насколько существенно выбор провайдера влияет на итоговые расходы. Когда к расчету добавляются выходные токены, разрыв ещё увеличивается, поскольку ценообразование выходных токенов Gemini пропорционально более конкурентоспособно на каждом уровне моделей.
| Провайдер | Флагманская модель | Вход/1M | Выход/1M | Лучше всего для |
|---|---|---|---|---|
| Google Gemini | 2.5 Pro | $1.25 | $10.00 | Лучшее соотношение цена/качество |
| OpenAI | GPT-4o | $5.00 | $15.00 | Экосистема и плагины |
| Anthropic | Claude Opus | $15.00 | $75.00 | Сложные рассуждения |
| xAI | Grok | $0.20 | $0.50 | Бюджетные приложения |
Тем не менее цена -- не единственный фактор при выборе API-провайдера. GPT-4o от OpenAI сохраняет преимущества в некоторых задачах программирования и обладает самой широкой экосистемой сторонних интеграций, плагинов и инструментов тонкой настройки. Сообщество разработчиков у OpenAI самое большое, что означает больше учебных материалов, библиотек и поддержки от сообщества. Claude Opus превосходно справляется с нюансированным анализом, генерацией длинного контента и задачами, требующими точного следования инструкциям, что делает его предпочтительным выбором для приложений, где точность и безопасность имеют первостепенное значение. Для детального анализа ценовой структуры Claude ознакомьтесь с нашим руководством по ценам Claude API.
Уникальные преимущества Gemini включают нативные мультимодальные возможности с обработкой аудио и видеовхода на уровне API, самый щедрый бесплатный уровень среди крупных провайдеров без необходимости привязки кредитной карты и бесшовную интеграцию с сервисами Google Cloud, включая Vertex AI для корпоративных развертываний. Размеры окна контекста для моделей Gemini Pro также обычно больше, чем у конкурентов при сопоставимых ценах, что делает Gemini особенно подходящим для анализа документов и обработки длинных текстов. При выборе между провайдерами рекомендуется провести бенчмарк с реальными продакшен-промптами на двух-трех сервисах, чтобы оценить реальные различия в качестве наряду с ценовыми различиями.
Для разработчиков и команд, работающих с несколькими провайдерами, практическая задача управления отдельными API-ключами, платежными аккаунтами и клиентскими библиотеками для каждого сервиса создает дополнительные операционные издержки. Платформы вроде laozhang.ai решают эту проблему, предоставляя единый доступ ко всем основным моделям через одну точку входа, упрощая мультипровайдерное управление и зачастую предлагая конкурентоспособные цены благодаря объединению объемов. Такой подход также позволяет легко проводить A/B-тестирование между провайдерами и обеспечивает бесшовное переключение при сбоях одного из провайдеров.
Скрытые расходы и контроль бюджета Gemini API
Помимо прямолинейного ценообразования за токены, существует ряд дополнительных затрат, которые могут застать разработчиков врасплох, если не предусмотреть их в бюджете. Понимание этих скрытых расходов до того, как они появятся в счете, критически важно для поддержания предсказуемых расходов на API.
Плата за хранение кэша контекста -- наиболее часто упускаемая из виду статья расходов. Хотя кэширование снижает стоимость входных токенов на каждый запрос, сам закэшированный контент облагается платой за хранение в размере $4.50 за миллион токенов в час (ai.google.dev, февраль 2026). Для скромного кэша в 10 миллионов токенов (примерно средняя по размеру кодовая база или коллекция документов) это составляет $45 в час или $1080 в день при непрерывной работе. Вывод очевиден: кэши контекста следует создавать стратегически, тщательно мониторить и оперативно удалять, когда они больше не нужны. Настройка автоматического управления жизненным циклом кэшей предотвращает незаметное накопление расходов на хранение.
Заземление через Google Search и Google Maps -- мощные функции, которые связывают ответы Gemini API с актуальными веб-данными и информацией о местоположении, но они имеют собственное ценообразование. Google Search grounding предоставляет 1500 бесплатных запросов в день, а каждые дополнительные 1000 промптов стоят $35. Google Maps grounding аналогично дает 1500 бесплатных ежедневных запросов с тарифом $25 за каждые 1000 промптов сверх лимита. Для приложений, активно использующих заземленные ответы, таких как исследовательские ассистенты или геолокационные сервисы, эти расходы могут быстро нарастать и должны учитываться в расчетах стоимости каждого запроса наравне с тарификацией токенов.
Обработка аудио и видео тарифицируется по повышенным ставкам по сравнению с текстом, и эти расходы могут доминировать в вашем счете, если приложение обрабатывает значительный объем мультимедийного контента. Как упоминалось ранее, входные аудиотокены стоят в 3-10 раз дороже текстовых в зависимости от модели, причем Gemini 2.5 Flash берет $1.00 за миллион аудиотокенов против $0.30 за текст. Обработка видео через модели вроде Veo 3.1 тарифицируется отдельно: от $0.15 до $0.60 за секунду сгенерированного видео, а генерация изображений через Imagen 4 стоит от $0.02 до $0.06 за изображение в зависимости от разрешения и настроек качества (ai.google.dev, февраль 2026). Для набирающей популярность функции нативной генерации изображений Gemini 2.5 Flash каждое сгенерированное изображение обходится примерно в $0.039. Если ваше приложение обрабатывает смешанный медиаконтент, самое важное, что вы можете сделать, -- это настроить раздельное отслеживание расходов для каждой модальности, поскольку усредненная метрика стоимости скроет реальные затраты на самый дорогой тип обработки и значительно затруднит принятие обоснованных решений по оптимизации.
Контроль бюджета и уведомления о расходах
Google предоставляет несколько инструментов для контроля расходов на Gemini API, и настроить их перед масштабированием на продакшен настоятельно рекомендуется. Самый важный первый шаг -- настройка уведомлений о расходах в Google Cloud Console, которые отправляют email-оповещения при достижении заданных пороговых значений, например 50%, 80% и 100% от вашего месячного бюджета. Эти оповещения дают раннее предупреждение, позволяя расследовать неожиданные всплески расходов до того, как они станут значительной проблемой.
Помимо оповещений, вы можете настроить жесткие лимиты расходов, автоматически отключающие доступ к API при исчерпании бюджета, что обеспечивает критическую защиту от неконтролируемого роста затрат из-за ошибок в коде, всплесков трафика или неправильно настроенной логики повторных попыток. Это особенно важно во время разработки, когда экспериментальный код может случайно сгенерировать тысячи вызовов API через бесконечные циклы или слишком агрессивные механизмы ретраев. Для продакшен-приложений реализация отслеживания стоимости на уровне запросов в коде вашего приложения дает гранулярную видимость паттернов расходов в реальном времени. Логируя количество токенов и расчетную стоимость каждого вызова API, вы можете определить, какие функции или пользователи потребляют наибольшую часть бюджета, и принимать обоснованные решения о направлении усилий по оптимизации. Многие команды обнаруживают, что добавление простого промежуточного слоя, вычисляющего и логирующего стоимость каждого запроса, окупается в течение первого месяца, выявляя неэффективности, которые иначе остались бы незамеченными.
Как выбрать подходящую модель Gemini для вашего бюджета
Выбор правильной модели -- это фундаментальное решение по стоимости, которое вы принимаете при работе с Gemini API, и неправильный выбор может означать переплату в 10-40 раз за аналогичные результаты. Представленная ниже система принятия решений поможет сопоставить ваши конкретные требования с наиболее экономичным уровнем модели.
Для простых высокообъемных задач -- классификации текста, извлечения сущностей, анализа тональности и базовых ответов на вопросы -- Gemini 2.5 Flash-Lite или 2.0 Flash по цене $0.10 за миллион входных токенов обеспечивают отличные результаты при минимальных затратах. Эти модели надежно справляются со структурированными задачами, а их скорость делает их идеальными для приложений реального времени, где важна задержка. Когда ваши задачи требуют умеренных рассуждений, генерации кода или тонкого понимания языка, Gemini 2.5 Flash по цене $0.30 за миллион токенов предлагает значительный рост возможностей всего за трехкратную стоимость Flash-Lite, что представляет исключительную ценность для большинства продакшен-нагрузок.
Для сложного анализа, продвинутого программирования, многоэтапных рассуждений и задач, где критична точность, рекомендуемым выбором является Gemini 2.5 Pro по цене $1.25 за миллион токенов. Она дороже моделей Flash, но обеспечивает ощутимо лучшие результаты на сложных задачах, что делает соотношение стоимости и качества на задачу выгодным, когда важна высокая точность. Модели Pro Preview (3.1 и 3 Pro) по $2.00 за миллион токенов следует резервировать для передовых требований, где вам нужны абсолютно последние возможности и вы готовы работать с моделями на стадии предварительного просмотра. Для более глубокого сравнения возможностей моделей разных поколений ознакомьтесь с нашим обзором моделей Gemini 3.
Практический путь развития для большинства разработчиков следует предсказуемой прогрессии. Начните с бесплатного уровня на этапе прототипирования и валидации, где вы можете экспериментировать с различными моделями и стратегиями промптов без каких-либо финансовых обязательств. Когда ваше приложение будет готово для реальных пользователей, перейдите на Tier 1, включив биллинг, и разверните его с моделями Flash, обеспечивающими лучшее сочетание низкой стоимости и готовности к продакшену. По мере роста пользовательской базы и сбора реальных данных об использовании выборочно подключайте модели Pro для конкретных высокоценных задач, сохраняя модели Flash для рутинных операций. Наконец, масштабирование до Tier 2 после накопления $250 расходов открывает более высокие лимиты скорости, необходимые для развертываний корпоративного масштаба. Такая поэтапная прогрессия позволяет вам валидировать экономику вашего сценария использования на каждом шаге, прежде чем переходить к более дорогим моделям, гарантируя, что каждый доллар расходов на API приносит измеримую ценность вашим пользователям.
Наиболее распространенная ошибка разработчиков -- выбор модели на этапе прототипирования и полное отсутствие пересмотра этого решения по мере развития приложения и прояснения паттернов использования. Планируйте ежеквартальный пересмотр выбора модели на основе фактических данных об использовании, поскольку быстро развивающаяся линейка моделей Gemini означает, что более новые и дешевые модели могут справляться с вашей нагрузкой так же хорошо, как и более дорогой вариант, выбранный изначально.
FAQ: ответы на ваши вопросы о ценах Gemini API
Сколько стоит Gemini API за миллион токенов?
Стоимость Gemini API составляет от $0.075 до $4.00 за миллион входных токенов и от $0.30 до $18.00 за миллион выходных, в зависимости от модели и длины контекста. Самый доступный вариант -- Gemini 2.0 Flash-Lite по $0.075/$0.30, тогда как самая мощная Gemini 3.1 Pro Preview стоит $2.00/$12.00 для стандартного контекста и $4.00/$18.00 для контекстов свыше 200K токенов (ai.google.dev, февраль 2026).
Бесплатен ли Gemini API?
Да, Google предлагает полноценный бесплатный уровень без привязки кредитной карты и настройки биллинга. Шесть моделей доступны бесплатно, включая Gemini 2.5 Flash и 3 Flash Preview, с лимитами от 5 до 15 запросов в минуту и до 1000 запросов в день. Однако данные, отправленные через бесплатный уровень, могут использоваться для улучшения моделей, поэтому избегайте отправки конфиденциальной информации.
Что дешевле: Gemini API или ChatGPT API?
Gemini API значительно дешевле для сопоставимых моделей. Gemini 2.5 Pro стоит $1.25 за миллион входных токенов против $5.00 у GPT-4o, что делает Gemini примерно на 75% дешевле по стоимости входных токенов. В бюджетном сегменте Gemini Flash-Lite по $0.10 за миллион токенов конкурирует с GPT-4o Mini, предлагая аналогичную ценность в нижнем ценовом диапазоне.
Какие лимиты скорости у Gemini API?
Лимиты скорости зависят от вашего тарифного уровня и конкретной используемой модели. Бесплатный уровень предоставляет 5-15 RPM и 100-1000 RPD, чего достаточно для разработки и тестирования, но что будет ограничивать продакшен-приложения при умеренной нагрузке. Tier 1, который активируется просто настройкой любого платежного аккаунта без минимальных расходов, предлагает 150-300 RPM в зависимости от модели. Tier 2 требует накопленных расходов не менее $250 за 30 дней и открывает 1000+ RPM -- уровень, на котором необходимо работать большинству продакшен-приложений с реальным пользовательским трафиком. Tier 3 при расходах от $1000 обеспечивает наивысшие лимиты, подходящие для корпоративных развертываний и высоконагруженных приложений, обслуживающих тысячи одновременных пользователей.
Как можно сократить расходы на Gemini API?
Три наиболее эффективные стратегии: кэширование контекста (экономия до 90% на повторяющихся входных токенах), Batch API (фиксированная скидка 50% для несрочных запросов) и грамотный выбор модели (использование Flash-Lite по $0.10/M вместо Pro по $1.25/M дает экономию 92% за токен). Комбинирование этих стратегий позволяет сократить общие расходы на API на 70-90%.
Меняются ли цены Gemini API для длинного контекста?
Да, модели Pro взимают двойную плату за длину контекста, превышающую 200 000 токенов. Стоимость входных токенов Gemini 2.5 Pro увеличивается с $1.25 до $2.50 за миллион, а выходных -- с $10.00 до $15.00. Модели Flash в настоящее время не имеют ценовых уровней, зависящих от длины контекста.
Начало работы с Gemini API
Начать работу с Gemini API просто и занимает всего несколько минут. Перейдите в Google AI Studio по адресу ai.google.dev для создания API-ключа, который дает немедленный бесплатный доступ к шести моделям без какой-либо настройки биллинга. Самый быстрый способ поэкспериментировать -- через веб-интерфейс AI Studio, который позволяет тестировать промпты на разных моделях и сравнивать результаты до написания кода.
Для программного доступа Google предоставляет официальные клиентские библиотеки для Python, JavaScript, Go и других языков, доступные через соответствующие менеджеры пакетов. Базовая реализация на Python требует установки пакета google-generativeai через pip и буквально три строки функционального кода: настройка API-ключа, создание экземпляра модели и вызов generate_content с вашим промптом. Объект ответа содержит сгенерированный текст вместе с метаданными об использовании токенов, что бесценно для отслеживания расходов с самого начала. Начните с Gemini 2.5 Flash для большинства сценариев, так как эта модель предлагает лучший баланс скорости, возможностей и стоимости всего за $0.30 за миллион входных токенов. По мере роста использования и прояснения требований вы сможете переключиться на модели Pro для конкретных задач, реализовать стратегии кэширования для часто повторяющихся контекстов и масштабироваться через систему платных уровней по мере увеличения объема запросов.
После завершения первоначальной настройки рекомендуемые следующие шаги -- провести бенчмарк вашего конкретного сценария на двух-трех моделях, чтобы найти оптимальное соотношение стоимости и качества для ваших конкретных промптов и требований. Различные модели демонстрируют разные сильные стороны в зависимости от типа задачи, поэтому эмпирическое тестирование на ваших реальных данных значительно надежнее, чем опора на общие бенчмарки. Внедрите базовое отслеживание расходов с первого дня для четкой видимости паттернов расходов по всем вызовам API и настройте уведомления о биллинге перед активацией платного уровня, чтобы предотвратить неожиданные и потенциально значительные счета.
Построение экономически эффективного AI-приложения -- это не разовая оптимизация, а непрерывный процесс мониторинга, измерения и корректировки. По мере того как Google продолжает выпускать новые модели и корректировать цены, осведомленность о последних изменениях гарантирует, что вы всегда используете наиболее экономичные варианты. Экосистема Gemini развивается быстро: новые релизы моделей, обновления цен и добавление функций происходят регулярно. Сочетая знания о ценообразовании из этого руководства с методичным подходом к выбору моделей, мониторингу расходов и непрерывной оптимизации, вы сможете создавать мощные AI-приложения, обеспечивающие исключительную ценность при уверенном контроле расходов.