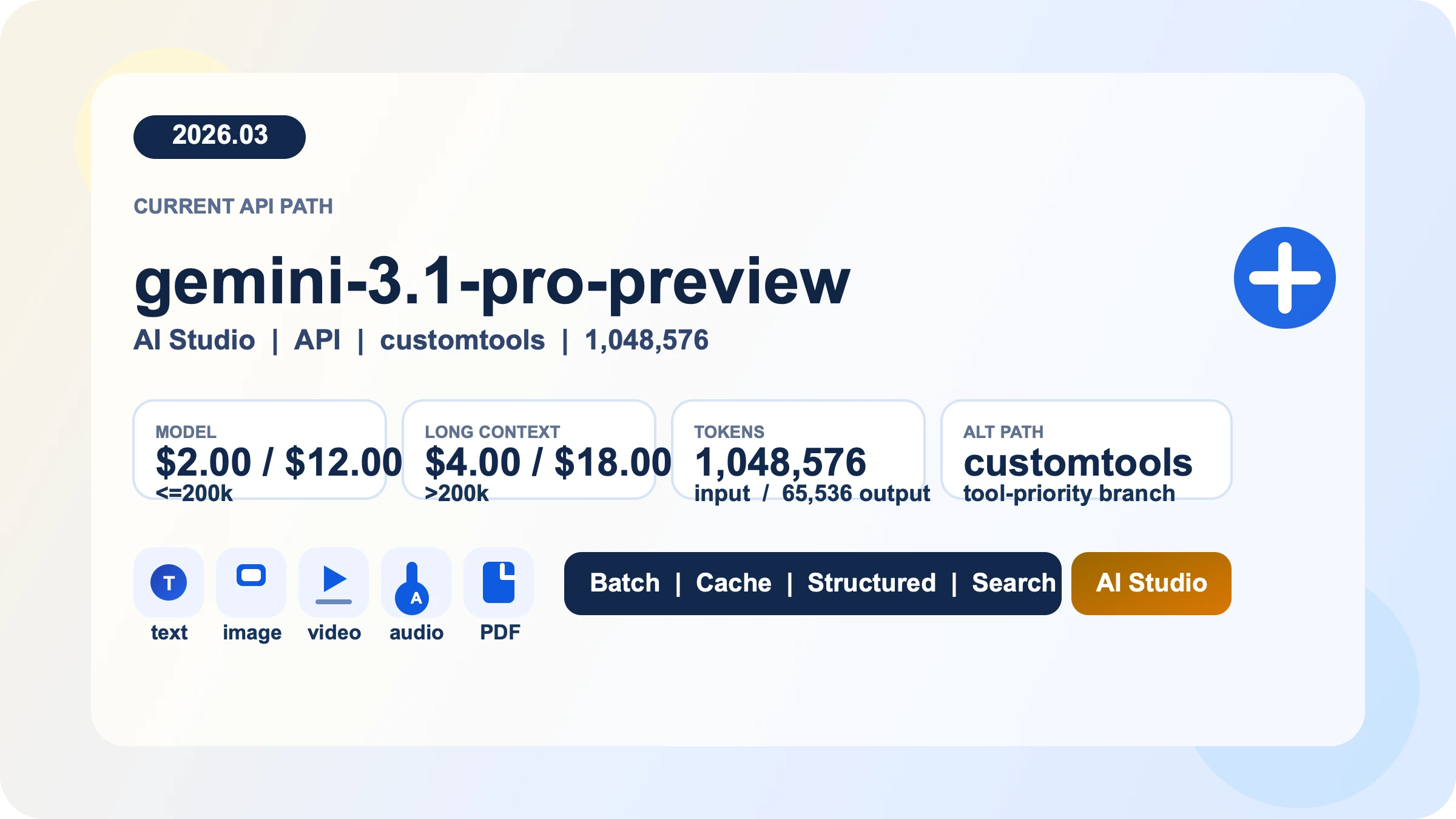
Gemini 3.1 Pro API — это текущий платный preview-путь Google для длинного контекста, мультимодального ввода и developer workflow с инструментами. По состоянию на 28 марта 2026 года стандартный тариф — $2 за input и $12 за output на 1M токенов при prompt до 200k, затем $4 / $18 выше порога; Batch стоит вдвое дешевле. После повторной проверки официальной документации, основной актуальный model ID — gemini-3.1-pro-preview, старый gemini-3-pro-preview уже отключен и теперь указывает на новую модель, а отдельный endpoint gemini-3.1-pro-preview-customtools предназначен для агентных сценариев, где в работе смешиваются bash и зарегистрированные инструменты. Если вам нужен не пересказ анонса, а рабочий путь без устаревших model ID, копипастных таблиц квот и неожиданных расходов, начинать нужно именно отсюда.
“Примечание по источникам: этот материал основан на странице модели Gemini 3.1 Pro, странице тарифов, странице rate limits, гайде по API key, документации OpenAI compatibility, Gemini 3 developer guide и release notes Google. Всё перепроверено 28 марта 2026 года.
TL;DR
- По умолчанию используйте
gemini-3.1-pro-preview. - К
gemini-3.1-pro-preview-customtoolsстоит переходить только тогда, когда приоритет custom tools действительно влияет на надёжность агента. - Программный доступ к Gemini 3.1 Pro платный, но AI Studio остаётся самым быстрым способом бесплатно проверить промпты и поведение модели до интеграции billing.
- До 200k токенов в prompt цена составляет $2.00 / $12.00 за 1M токенов; выше порога — $4.00 / $18.00. Batch стоит вдвое дешевле, а caching — реальный рычаг стоимости.
- Ваши реальные RPM, TPM и RPD теперь нужно смотреть в AI Studio. Google прямо указывает на него как на источник активных лимитов.
- Если вы всё ещё используете
gemini-3-pro-preview, это уже не стилистический выбор, а миграционный долг.
Самый быстрый путь к первому рабочему запросу Gemini 3.1 Pro
Google по-прежнему привязывает создание Gemini API key к Google AI Studio. Практический порядок такой: открыть AI Studio, импортировать или создать проект, сгенерировать в нём ключ, а затем прописать локально GEMINI_API_KEY или GOOGLE_API_KEY. В гайде Google по API keys явно сказано, что официальные библиотеки автоматически подхватывают оба варианта, а если заданы оба, приоритет получает GOOGLE_API_KEY. Если вы только проверяете поведение промптов, на AI Studio можно и остановиться. Если вам нужен программный доступ именно к Gemini 3.1 Pro, подключайте billing заранее и не относитесь к этой модели как к бесплатному API-каналу.
Для большинства команд самый чистый старт — официальный GenAI SDK. Ни Python, ни JavaScript, ни REST здесь не требуют сложной обвязки.
pythonfrom google import genai from google.genai import types client = genai.Client() response = client.models.generate_content( model="gemini-3.1-pro-preview", contents="Review this API design and list the main tradeoffs.", config=types.GenerateContentConfig( thinking_config=types.ThinkingConfig(thinking_level="medium") ), ) print(response.text)
javascriptimport { GoogleGenAI } from "@google/genai"; const ai = new GoogleGenAI({}); const response = await ai.models.generateContent({ model: "gemini-3.1-pro-preview", contents: "Review this API design and list the main tradeoffs.", config: { thinkingConfig: { thinkingLevel: "medium", }, }, }); console.log(response.text);
bashcurl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-pro-preview:generateContent" \ -H "x-goog-api-key: $GEMINI_API_KEY" \ -H "Content-Type: application/json" \ -X POST \ -d '{ "contents": [{ "parts": [{"text": "Review this API design and list the main tradeoffs."}] }], "generationConfig": { "thinkingConfig": { "thinkingLevel": "medium" } } }'
Важно не только то, что запрос запускается, но и то, что он запускается с явным model ID и явной настройкой reasoning. В Gemini 3 developer guide для Gemini 3.1 Pro задокументировано, что high является динамическим значением по умолчанию. Если вы оставляете reasoning полностью на автопилоте, вы тем самым оставляете на автопилоте и задержку, и часть стоимости output tokens.
Сначала выберите правильный model ID, а потом уже оптимизируйте
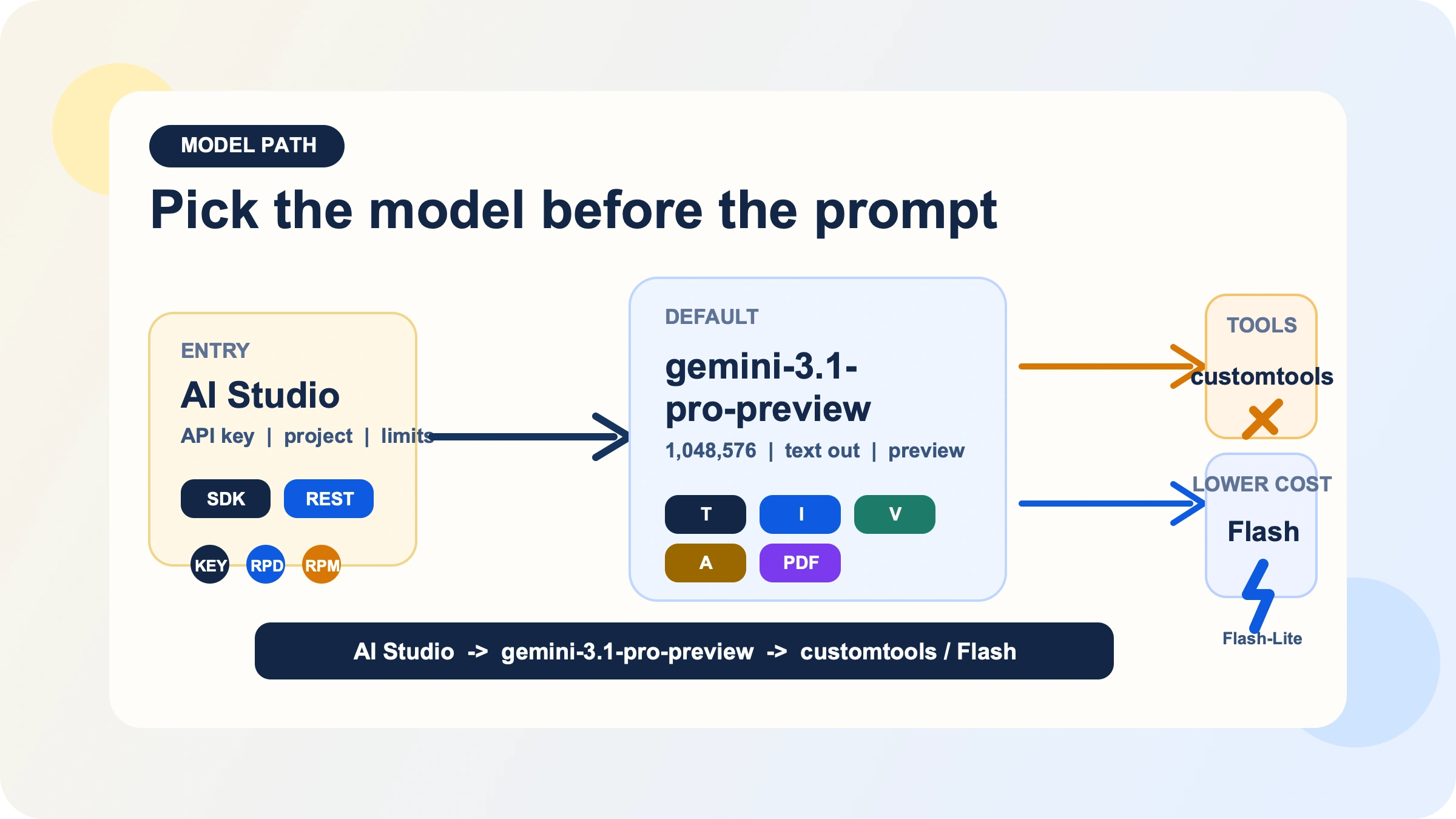
Главное решение на этом этапе — не prompt engineering, а выбор модельного пути.
Базовый путь — gemini-3.1-pro-preview. На официальной странице модели Google описывает его как preview-модель, улучшающую серию Gemini 3 Pro за счёт более сильного thinking, лучшей token efficiency и более надёжного поведения в software engineering и agentic workflow. Она принимает text, image, video, audio и PDF на вход, выдаёт text на выход и поддерживает набор действительно полезных production-возможностей: Batch API, caching, code execution, function calling, search grounding, Maps grounding, structured outputs и URL context. Это делает модель хорошим выбором для анализа больших документов, мультимодального reasoning и workflow, где важны tools или структурированные ответы.
Но на той же странице чётко прописаны и ограничения. Gemini 3.1 Pro Preview не поддерживает image generation, audio generation и Live API. Если ваша реальная задача — генерация изображений, голос в реальном времени или максимально дешёвый high-volume text pipeline, значит, вы с самого начала свернули не туда. В таких сценариях логичнее смотреть на Flash, Flash-Lite, image- или live-модели. Если же вам нужна именно бесплатная программная точка входа, сначала прочитайте наш гайд по бесплатному tier Gemini API, а не пытайтесь заставить Pro выполнять чужую роль.
Вторая ветка — gemini-3.1-pro-preview-customtools. Это не другой флагман с иными тарифами или длиной контекста, а отдельный endpoint для команд, которые строят агентов с bash и одновременно с зарегистрированными инструментами. Официальная модельная страница говорит, что он лучше приоритизирует ваши custom tools вроде view_file или search_code, но также предупреждает: в задачах, где такие tools не дают преимущества, качество может колебаться. Вывод простой. Если ваша проблема — именно приоритет инструментов, выбирайте customtools осознанно. Если же вы делаете обычный reasoning, чат или анализ документов, оставайтесь на стандартном пути. Для более глубокого разбора у нас уже есть отдельный гайд по Gemini 3.1 Pro customtools.
И ещё один факт следует считать окончательно решённым. В release notes Google прямо сказано: gemini-3-pro-preview был отключён 9 марта 2026 года и теперь указывает на gemini-3.1-pro-preview. Даже если alias временно спасает старые вызовы, новый код должен использовать актуальную строку модели явно.
Как понимать тарифы и лимиты без самообмана

Тарифы Gemini 3.1 Pro выглядят простыми только до тех пор, пока вы не забываете про порог размера prompt. На актуальной странице Google pricing стандартные цены для prompt до 200k токенов такие:
| Диапазон | Input | Output | Batch |
|---|---|---|---|
<=200k | $2.00 / 1M | $12.00 / 1M | $1.00 / $6.00 |
>200k | $4.00 / 1M | $18.00 / 1M | $2.00 / $9.00 |
Этот порог важен именно потому, что сильная сторона Gemini 3.1 Pro — 1,048,576 токенов входного контекста. Многие материалы останавливаются на фразе «контекст 1M», но не продолжают мысль: если вы реально часто работаете в длинном контексте, ваша экономика запросов меняется. На практике важнее большинства benchmark-таблиц оказываются четыре рычага:
- По возможности держите рутинные prompts ниже 200k.
- Используйте Batch для асинхронной фоновой работы.
- Включайте caching, если постоянно отправляете один и тот же большой инструкционный или справочный блок.
- Относитесь к thinking level как к полноценному ценовому рычагу.
Страница pricing у Google даёт конкретные цифры по двум часто игнорируемым строкам: context caching и grounding. Caching стоит $0.20 / $0.40 за 1M токенов (<=200k / >200k) плюс $4.50 за 1M токенов в час за storage, поэтому он выгоден только при повторном использовании больших блоков. Search и Maps grounding делят бесплатный пул 5 000 prompts в месяц (для Batch лимит ниже), затем тариф $14 за 1 000 запросов; если вам не нужны свежие web‑факты, grounding быстро становится лишним множителем расходов.
С лимитами нужен другой взгляд. На странице rate limits Google теперь прямо пишет, что реальные API limits зависят от usage tier и состояния аккаунта и должны проверяться в AI Studio. Это значит, что любой блог, включая этот, не должен притворяться окончательной таблицей RPM для вашего проекта. При этом официальная документация всё же даёт важные правила:
- rate limiting измеряется по RPM, TPM и RPD
- квоты применяются на уровне проекта, а не API key
- RPD сбрасывается в полночь по Pacific
- для preview-моделей лимиты строже
- ваши активные лимиты находятся в AI Studio
На той же странице описана и текущая логика tiers: Tier 1 начинается после подключения billing, Tier 2 требует уже платного использования и времени после первого успешного платежа, Tier 3 — заметно большего spend и более длинной истории. Если вы всерьёз планируете capacity, используйте официальный rate-limits page, чтобы понять правила, а затем смотрите именно AI Studio, где находятся реальные цифры для вашего проекта.
Есть и одна практическая деталь конца марта, которую легко пропустить. В release notes Google отмечает, что 12 марта 2026 года в AI Studio появились project-level spend caps. Если вы подключаете Gemini 3.1 Pro для команды и хотите поставить финансовый предохранитель до первых тяжёлых long-context jobs, это стоит настроить.
Thinking, длинный контекст и кеш — вот где обычно растёт счёт
Gemini 3.1 Pro — не та модель, которую стоит оставлять на полном автопилоте только потому, что API выглядит аккуратно. В Gemini 3 developer guide указано, что для Gemini 3.1 Pro доступны три thinking level: low, medium и high, причём high является динамическим значением по умолчанию. Там же сказано, что thinking_level нельзя комбинировать с устаревшим thinking_budget в одном запросе, иначе вы получите 400. Это не мелочь, а важный миграционный сигнал: старые Gemini-потоки нужно обновлять полностью, а не наполовину.
Мой практический совет — использовать medium как первый серьёзный default для повседневной работы, а затем опускаться или подниматься в зависимости от задачи. Это инженерная рекомендация, выведенная из поведения модели и тарифов, а не буквальная цитата Google. Для извлечения, классификации, коротких преобразований и других задач, где глубокое reasoning не является узким местом, часто разумнее начинать с low. Когда же вы выбираете Gemini 3.1 Pro именно ради сложного анализа, проверки большого codebase или многошагового reasoning, high может быть оправдан — но потому, что этого требует workload, а не потому, что SDK оставил его неявно.
С длинным контекстом нужно относиться к себе так же жёстко. Окно на 1M токенов реально существует, и это одна из лучших причин использовать Gemini 3.1 Pro. Но главный вопрос не в том, «поместится ли это», а в том, «как часто мне действительно нужно платить long-context rate и какие части этого контекста стоит сначала закешировать или сократить». Если вы каждый раз пересылаете огромный неизменный system prompt, один и тот же пакет документов или статичный repo context, то самый ленивый путь быстро становится самым дорогим.
Если вам нужен более детальный разбор того, как routing reasoning устроен в Gemini, посмотрите наш отдельный гайд по thinking level в Gemini 3.1 Pro. Но на уровне этой обзорной статьи достаточно трёх правил: reasoning нужно задавать явно, порог 200k нужно держать в голове, а длинный контекст нельзя превращать в привычку только потому, что модель это позволяет.
Как мигрировать, если вы использовали Gemini 3 Pro Preview или OpenAI SDK
Если раньше вы использовали Gemini 3 Pro Preview, миграционная суть очень проста. В release notes от 9 марта 2026 года Google пишет, что модель отключена, а gemini-3-pro-preview теперь указывает на gemini-3.1-pro-preview. Разумный operational ход — явно заменить model string в коде, пересмотреть ожидания от thinking-поведения и решить, должен ли workload остаться на стандартном пути или уйти в -customtools.
Если ваша команда уже глубоко сидит на OpenAI SDK, то слой OpenAI compatibility у Google — самый дешёвый мост по объёму изменений. Официальная документация показывает, что Gemini можно вызывать из Python- и JavaScript-библиотек OpenAI, поменяв API key, base URL и model name. Для команд, которые хотят сначала протестировать Gemini в уже существующем OpenAI-клиентском стеке, это очень удобный путь.
pythonfrom openai import OpenAI client = OpenAI( api_key="GEMINI_API_KEY", base_url="https://generativelanguage.googleapis.com/v1beta/openai/" ) response = client.chat.completions.create( model="gemini-3.1-pro-preview", reasoning_effort="medium", messages=[ {"role": "user", "content": "Summarize the migration risks in this API design."} ] ) print(response.choices[0].message.content)
У compatibility-документации есть ещё одна полезная деталь: она сопоставляет reasoning_effort из OpenAI-модели с reasoning controls Gemini. Значения minimal и low соответствуют Gemini low, medium — Gemini medium, high — Gemini high. Правило остаётся тем же, что и в native path: не надо накладывать друг на друга две overlapping reasoning-настройки. Если вы уже используете reasoning_effort через OpenAI-compatible endpoint, не добавляйте поверх него отдельный Gemini thinking control, если только официальный документ прямо не говорит, что для вашего пути это допустимо.
Именно в этот момент стоит перепроверить все старые tutorials и внутренние snippets. У preview-моделей опасность часто не в одном устаревшем model name, а в целой связке устаревших параметров и ценовых допущений. Самый безопасный путь — унифицировать текущий model string, пересчитать стоимость, а затем прогнать несколько репрезентативных prompts в AI Studio до того, как маршрут уйдёт в production.
Когда Gemini 3.1 Pro — правильный API, а когда нет
Gemini 3.1 Pro оправдан тогда, когда вашему workload реально нужны одновременно три свойства: сильный reasoning, длинный контекст и tool-aware мультимодальная поверхность. Такое сочетание хорошо подходит для ревью больших документов, анализа крупных codebase, структурированного извлечения из сложных mixed inputs и agent workflow, где важны code execution, function calling, grounding или URL context. Он также уместен для команд, которые готовы жить с платной preview-моделью и принимать более строгие лимиты по сравнению с дешёвыми high-volume вариантами.
Переходите на gemini-3.1-pro-preview-customtools, когда у вас агент одновременно работает с bash и зарегистрированными инструментами, и именно приоритет инструментов является проблемой надёжности. Выбирайте более дешёвый путь через Flash или Flash-Lite, когда важнее latency и budget sensitivity, чем флагманское reasoning. Идите в другую модельную семью, если вам нужен image output или live audio. А если главная задача звучит как «мне нужен бесплатный API для прототипа», тогда Pro изначально не должен быть вашей стартовой точкой — в таком случае сначала полезнее прочитать наш гайд по бесплатному tier Gemini API и гайд по rate limits Gemini API.
Если вы одновременно сравниваете Gemini, OpenAI и Claude и хотите держать их за единым routing layer, то сервис вроде laozhang.ai может быть практичен, потому что он сокращает фрагментацию авторизации и биллинга. Но проверять надо не только наличие model name в каталоге, а реальную прозрачность feature surface — особенно если вам важны preview-specific behavior или customtools path.
Финальный вывод несложен. Gemini 3.1 Pro API стоит использовать тогда, когда вам действительно нужна именно его форма, а не просто самый свежий бренд. Если ваша реальная работа — «быстрый, дешёвый, high-volume text», не платите за Pro только потому, что вокруг него больше шума. Если же ваша задача — «один большой мультимодальный контекст, структурированный вывод, grounding и надёжное многошаговое выполнение», Gemini 3.1 Pro остаётся сильным текущим выбором.
FAQ
Gemini 3.1 Pro API бесплатный?
Нет. На актуальной странице pricing Google у Gemini 3.1 Pro Preview нет free API tier. В AI Studio модель можно протестировать, но программные вызовы платные.
gemini-3-pro-preview всё ещё работает?
Он был отключён 9 марта 2026 года. В release notes Google сказано, что старый model ID теперь указывает на gemini-3.1-pro-preview, но новый код должен использовать актуальную строку явно.
Нужно ли использовать gemini-3.1-pro-preview-customtools в каждом проекте?
Нет. Это оправдано только там, где custom-tool priority реально влияет на поведение агента. Google также предупреждает о возможных quality fluctuations в задачах, которым такие tools не помогают.
Где смотреть мои реальные RPM, TPM и RPD?
В AI Studio. Страница Google rate limits теперь прямо отправляет пользователей туда, потому что capacity зависит от tier и состояния аккаунта.
Можно ли вызывать Gemini 3.1 Pro через OpenAI SDK?
Да. Документация Google по OpenAI compatibility показывает, что для этого достаточно изменить API key, base URL и model name.
Поддерживает ли Gemini 3.1 Pro image generation или Live API?
Нет. На актуальной модельной странице image generation, audio generation и Live API отмечены как unsupported.