Большинство разработчиков, которые ищут «Gemini 3.1 Pro vs Claude Opus 4.6», на самом деле не хотят читать теорию сравнения моделей. Им нужен быстрый ответ: что тестировать первым? На март 2026 года практическое правило простое. Если основная нагрузка — длинный контекст и контроль затрат, начинайте с Gemini. Если главное — надёжность кодового агента, начинайте с Claude. Если система естественно делится на широкий этап сбора контекста и узкий этап исполнения, держите обе модели и маршрутизируйте задачи.
Этот ответ работает потому, что официальные доказательства несимметричны, но полезны. Google даёт более чистую картину по цене, лимитам токенов и сценариям с длинным контекстом. Anthropic даёт более сильный публичный кейс для дорогих задач с кодом и высокой автономностью. Ошибка не в том, что люди смотрят на benchmark-ы. Ошибка в том, что сводные таблицы часто смешивают разные SKU, режимы Preview и beta-возможности так, будто это одна честная шкала.
Если нужен только короткий ответ
Если большая часть вашего production-трафика — это анализ документов, загрузка репозиториев, исследовательские задачи с опорой на поиск или другие длинные prompt, где критична прямая стоимость API, начинайте с Gemini 3.1 Pro Preview. Если самые трудные задачи — это code review, генерация patch, многошаговый tool use и debugging, где плохая первая попытка означает дорогую ручную переделку, начинайте с Claude Opus 4.6. Если ваша система уже делится на широкий этап сбора контекста и узкий этап качественного исполнения, не пытайтесь выбрать одного вечного победителя. Держите обе модели и маршрутизируйте по типу задачи. На март 2026 года это самый быстрый и честный вывод, и он лучше соответствует официальным ценам, лимитам контекста и product positioning, чем большинство коротких benchmark-вердиктов.
| Если продукту в основном нужно... | С чего начинать | Почему |
|---|---|---|
| Длинные документы, ingestion репозиториев, чувствительный к цене анализ | Gemini 3.1 Pro Preview | Ниже официальный прайс и более ясная история про миллионный входной контекст |
| Code review, debugging, многошаговый tool use, генерация patch | Claude Opus 4.6 | Более сильная first-party аргументация в пользу coding-heavy autonomy |
| Широкая стадия ingestion + узкая стадия исполнения | Использовать обе | Gemini берёт дешёвую context-heavy работу, Claude — дорогой финальный execution |
Как читать benchmark-ы без самообмана
Публичные performance-данные важны, потому что именно их ждут пользователи из поиска. Проблема не в том, что benchmark-ы бесполезны. Проблема в том, что по этой паре моделей нет одной чистой и симметричной публичной scorecard. Anthropic гораздо яснее публикует benchmark-case для Opus 4.6 как premium-модели для coding и autonomy, подчёркивая Terminal-Bench 2.0, Humanity's Last Exam, BrowseComp и GDPval-AA. У Google публичный кейс Gemini 3.1 Pro Preview сильнее в другом: цена, миллионный input, token efficiency, grounded behavior и позиционирование для инженерных задач. Практический вывод такой: публичные benchmark-ы делают Claude более очевидным кандидатом для оценки coding-agent сценариев, а цены и лимиты токенов делают Gemini более очевидным кандидатом для long-context систем с контролем затрат. Не стоит доверять таблицам, которые смешивают Sonnet, Opus, preview-варианты и beta context как будто это идеально сопоставимые вещи.
Быстрый обзор: что именно вы сравниваете?

Первое, что нужно исправить, — сам объект сравнения. Когда люди говорят «Gemini 3.1», они часто имеют в виду несколько разных продуктов одновременно: Gemini 3.1 Pro Preview, Gemini 3.1 Pro Preview Customtools или другие варианты семейства Gemini 3.1, которые упоминаются в форумах и сторонних обёртках. Для прямого API-сравнения с Claude Opus 4.6 самым чистым и корректным сопоставлением является Gemini 3.1 Pro Preview, потому что именно для него Google публично документирует цены, лимиты токенов и позиционирование вокруг software engineering. Со стороны Anthropic релевантной парой является именно Claude Opus 4.6, а не Sonnet 4.6. Sonnet часто выгоднее по цене, но это уже другое продуктовое решение. Если после этой статьи вам нужно глубже разобраться в ценовых уровнях Claude, отдельный гайд по ценам Claude Opus 4.6 будет полезнее.
Время релиза тоже важно, потому что обе модели достаточно свежие, и старые предположения здесь опасны. Google анонсировал Gemini 3.1 Pro 19 февраля 2026 года, и официальная страница модели по-прежнему помечает его как Preview. Anthropic выпустил Claude Opus 4.6 5 февраля 2026 года, позиционируя его как новейшую Opus-class модель и наиболее сильную опцию для сложного reasoning и coding. Значит, сравнение по своей природе сильно зависит от актуальности данных: статья, написанная на предположениях эпохи Gemini 2.5 или Claude 4.1, не просто немного устарела — она подталкивает к совсем другому архитектурному решению.
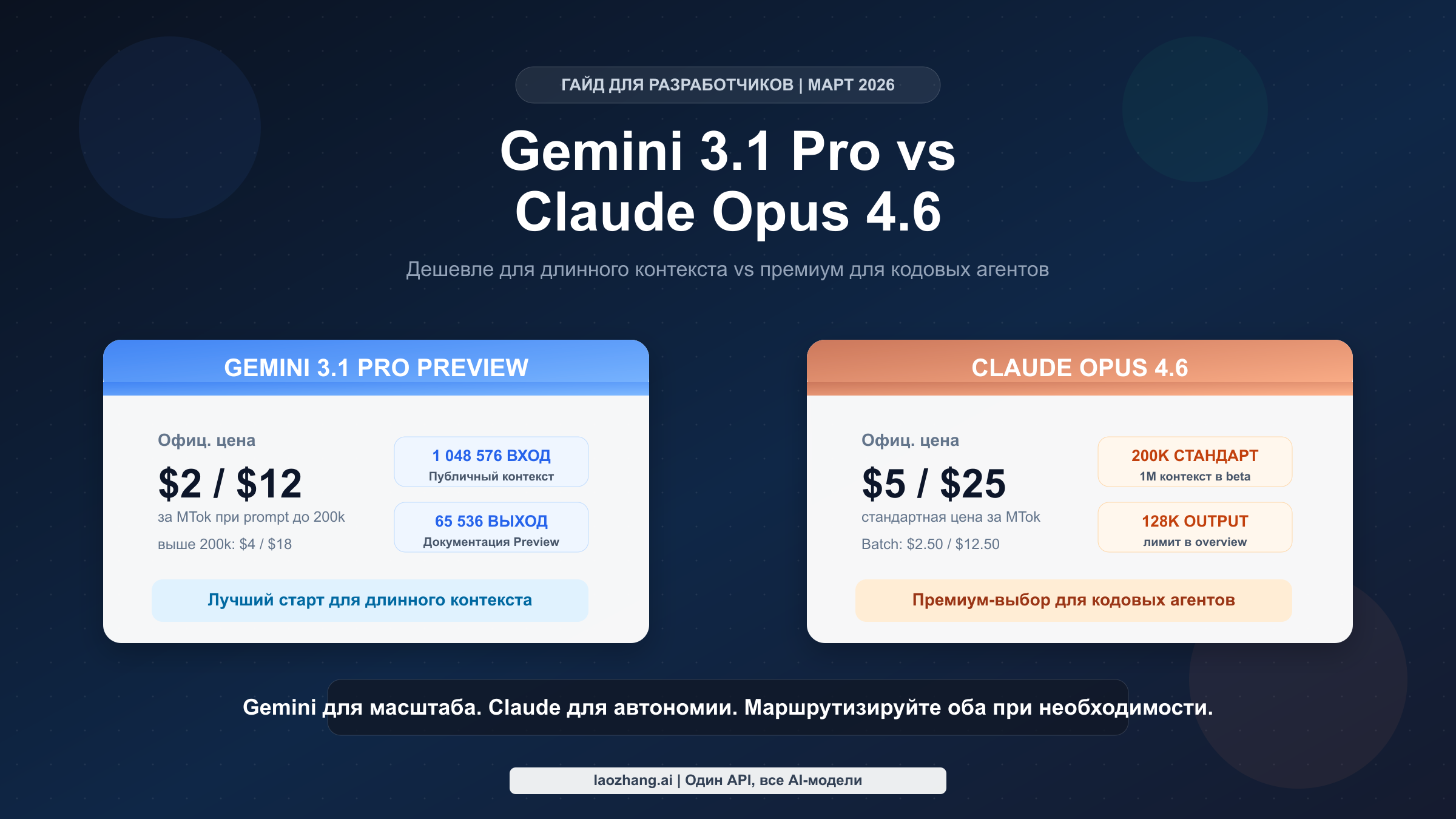
Даже один набор сухих характеристик уже показывает форму выбора. Официальная документация Google публикует для Gemini 3.1 Pro Preview 1,048,576 входных токенов и 65,536 выходных токенов. Таблица model overview от Anthropic показывает для Opus 4.6 200k context и 128k max output, а в launch post отдельно говорится, что Opus 4.6 поддерживает 1M-token context window in beta. Это не косметические детали. Если ваш workload состоит в основном из очень больших prompt, документация Gemini яснее и дешевле. Если же для вас критично очень длинное сгенерированное output, опубликованный лимит 128k у Claude становится реальным преимуществом.
| Параметр | Gemini 3.1 Pro Preview | Claude Opus 4.6 |
|---|---|---|
| Дата релиза | 19 фев 2026 | 5 фев 2026 |
| Статус | Preview | Текущая флагманская модель |
| Цена входа | $2/MTok при <=200k, $4/MTok выше 200k | $5/MTok |
| Цена выхода | $12/MTok при <=200k, $18/MTok выше 200k | $25/MTok |
| Входной контекст | 1,048,576 токенов | 200k в overview; 1M beta в launch post |
| Макс. output | 65,536 токенов | 128k токенов |
| Публичный сигнал по performance | сильнее для long-context и контроля затрат | сильнее для тяжёлого coding и autonomy |
| Официальное позиционирование | better thinking, token efficiency, grounded behavior, software engineering, precise tool usage | complex coding, agentic work, computer use, tool use, search, finance |
Если нужно запомнить только одну мысль из этого раздела, то вот она: Gemini 3.1 Pro Preview — это не «дешёвый Claude», а Claude Opus 4.6 — не просто «более дорогой Gemini». Эти модели продаются под разные failure profiles. Gemini оптимизирован и оценён как длинноконтекстный, инструментально-точный workhorse, который сохраняет привлекательную цену даже после порога 200k. Opus же продаётся как модель, которая должна окупать себя за счёт уменьшения failure loops в самых тяжёлых coding- и autonomy-heavy задачах.
Цена и контекст: почему Gemini выглядит базовым выбором по ценности
Вывод: Gemini должен быть стартовым кандидатом, когда решение в первую очередь определяется ценой API и размером prompt.
Основание: Google публикует цену $2/$12 до 200k prompt tokens и $4/$18 выше этого порога, а также документированный лимит входа в 1,048,576 токенов.
Что выбирать: Для анализа документов, ingestion репозиториев, batch-extraction и других высокообъёмных задач с большим контекстом сначала проверяйте Gemini.
Если смотреть только на прямые API-цены, Gemini 3.1 Pro Preview получает самое сильное преимущество с самого начала. Согласно официальной странице цен Gemini, Gemini 3.1 Pro Preview стоит $2.00 за вход / $12.00 за выход на миллион токенов, если prompt остаётся в пределах 200k, и $4.00 / $18.00, когда prompt превышает 200k. В документации Anthropic по ценам Claude Opus 4.6 стоит $5.00 за вход / $25.00 за выход на миллион токенов. Это означает, что в обычном <=200k сценарии Gemini дешевле на 60% по input и на 52% по output. Даже после перехода на long-prompt tier Gemini всё равно дешевле на 20% по входу и на 28% по выходу.
Самый важный нюанс заключается в том, что преимущество Gemini зависит от порога, а не является постоянной величиной. Многие быстрые сравнения цитируют только дешёвый tier, и тогда Gemini кажется почти абсурдно дешёвым относительно Opus. Но в реальной эксплуатации всё зависит от того, как часто вы пересекаете границу 200k prompt-токенов. Если вы строите обычные interactive coding tools, support copilots, структурированный document Q&A или planning agents среднего размера, значительная часть запросов останется ниже этого порога, и преимущество Gemini по цене будет очень заметным. Если же вы регулярно отправляете в контекст огромные репозитории, длинные юридические наборы или большие research packets, цена Gemini повышается. Он всё ещё остаётся дешевле Opus, но разрыв уже не выглядит как безоговорочный разгром и становится более тонким аргументом, который нужно интерпретировать через качество.
Batch и caching делают картину ещё интереснее. Google публикует batch pricing для Gemini 3.1 Pro Preview: $1/$6 для prompt до 200k и $2/$9 выше этого порога. Anthropic оценивает batch-запросы Opus 4.6 в $2.50/$12.50. Для асинхронных workload-ов вроде индексации репозиториев, массового извлечения данных или ночного анализа обе модели становятся заметно привлекательнее, чем по стандартному прайсу, но Gemini всё равно сохраняет более низкую стоимость. Что касается caching, Google использует явную схему с ценой за caching и storage, а Anthropic — систему write-мультипликаторов и очень дешёвого read-мультипликатора. Это мешает простому one-line сравнению, но стратегический вывод прост: обе компании вознаграждают повторное использование контекста, и обе становятся заметно дешевле, если вы перестаёте пересылать одну и ту же статическую prompt-нагрузку снова и снова.
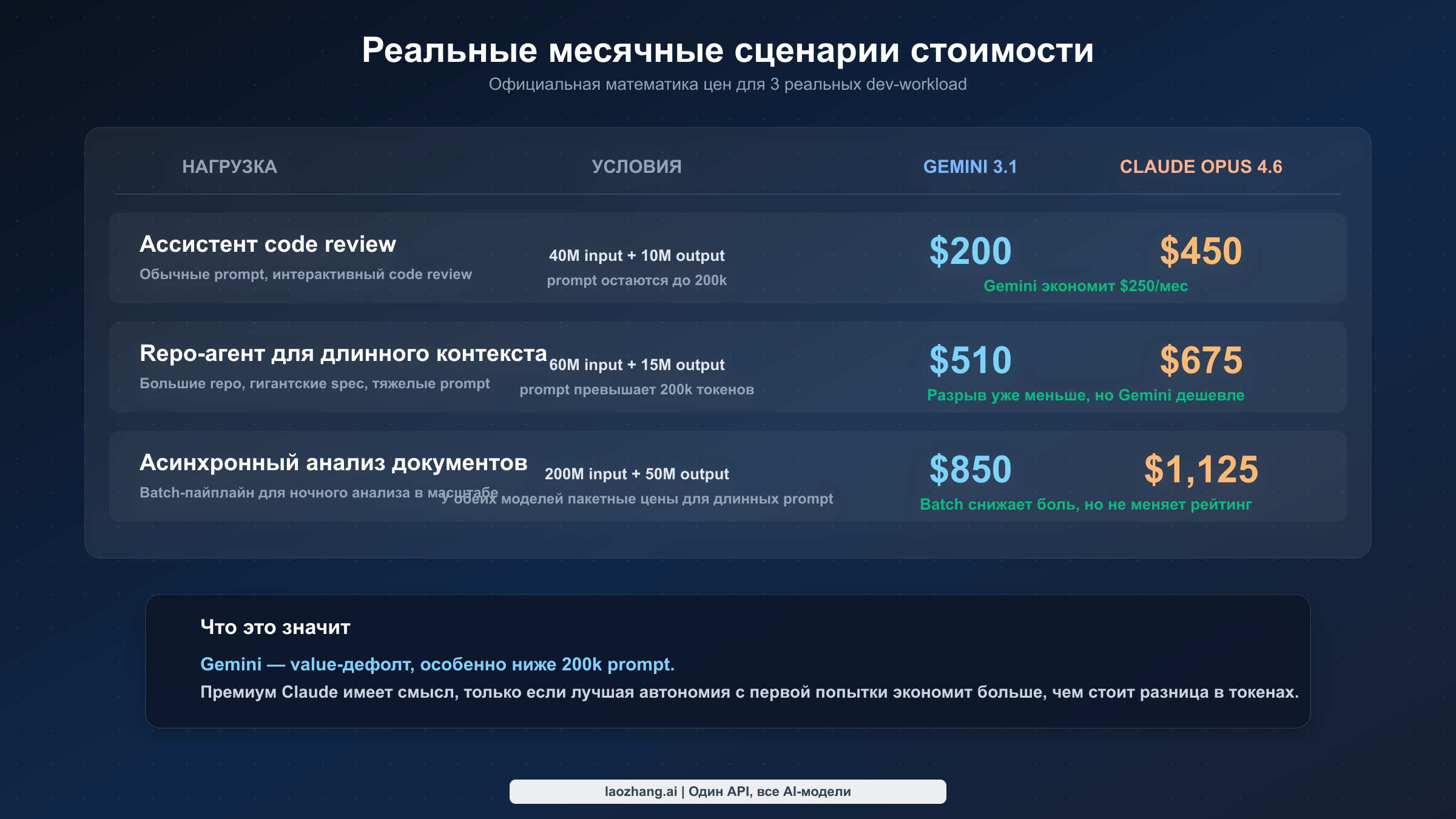
Разницу проще увидеть на конкретных сценариях месячных затрат:
| Workload | Предпосылки | Gemini 3.1 Pro Preview | Claude Opus 4.6 |
|---|---|---|---|
| Ассистент code review | 40M input, 10M output, prompt <=200k | $200 | $450 |
| Long-context repo agent | 60M input, 15M output, prompt >200k | $510 | $675 |
| Асинхронный анализ документов (batch) | 200M input, 50M output, long-prompt batch | $850 | $1,125 |
Эти числа намеренно упрощены. Они не включают search-grounding fees, storage for cached context и не пытаются оценить качество моделей. Их задача — показать форму цены. В обычном prompt-кейсе Gemini более чем вдвое выгоднее. В long-context кейсе разрыв сужается, потому что Gemini переходит в более дорогой tier. В batch-сценарии Gemini всё равно дешевле напрямую, но уже не настолько, чтобы качество перестало иметь значение.
Контекст — вторая половина этого раздела, и именно он меняет трактовку цены. Gemini 3.1 Pro Preview даёт опубликованный лимит 1,048,576 входных токенов «из коробки». Anthropic в model overview по-прежнему показывает Opus 4.6 как 200k context-модель, и именно на это будут опираться многие команды по умолчанию, даже несмотря на заявление в launch post о 1M-token context window в beta. Если ваша roadmap подразумевает миллионный контекст как нормальную производственную способность, документация Gemini просто яснее. Если же приложение нуждается не в экстремально длинном входе, а в очень длинном генерируемом output, опубликованный лимит 128k output у Claude становится аргументом в другую сторону.
Есть и ещё одна деталь ценообразования, которая оказывается важнее, чем выглядит на первый взгляд: Google отдельно тарифицирует Grounding with Google Search после бесплатной ежемесячной квоты, тогда как страница Anthropic больше концентрируется на токенах, caching, fast mode, batch и региональном inference. Это делает Gemini особенно привлекательным для workflows, где grounded search является частью продукта, но одновременно означает, что вам нужно моделировать и search-query costs, а не считать «цену токена» полной стоимостью системы. Для команд, которые пока просто хотят понять, стоит ли вообще углубляться в Gemini, следующий разумный шаг — гайд по доступу к Gemini 3.1 Pro Preview.
Кодовые и агентные сценарии: почему Claude Opus 4.6 всё ещё оправдывает премиум
Вывод: Claude логичнее тестировать первым там, где самая дорогая ошибка происходит в коде, инструментах и многошаговом исполнении.
Основание: У Anthropic заметно сильнее публичный benchmark- и product-case именно для coding-heavy autonomy.
Что выбирать: Если главный риск для команды — не цена токена, а дорогая ручная переделка после неудачной первой попытки, начинайте с Claude.
Если бы история ограничивалась ценой, Gemini был бы очевидным победителем, и статья на этом закончилась бы. Причина, по которой Opus 4.6 всё ещё заслуживает серьёзной оценки, заключается в том, что официальные доказательства Claude особенно сильны там, где многие дорогие AI-системы на практике ломаются: coding, tool use и многошаговое агентное поведение. Launch post Anthropic говорит об этом очень прямо. Opus 4.6 лучше кодит, осторожнее планирует, дольше удерживает agentic tasks, надёжнее работает в больших codebase и лучше справляется с code review и debugging, замечая собственные ошибки. Это не размытые маркетинговые фразы. Они напрямую описывают то поведение, которое определяет, является ли coding-агент реальным помощником или дорогим источником cleanup work.
Это важно, потому что стоимость неверно выбранной модели часто заключается не в токеновом счёте, а в цикле человеческого ремонта. Модель с длинным контекстом может быть дешёвой в запуске, но всё равно обходиться дороже как система, если она регулярно делает неправильные tool calls, пропускает побочные эффекты по кодовой базе или требует нескольких попыток, прежде чем сойдётся к рабочему решению. В таких ситуациях premium Opus оказывается вполне рациональным, даже если per-token цена выглядит болезненно. Один сильный первый проход часто дешевле трёх посредственных, особенно когда провалы съедают время разработчика, минуты CI и ревью-внимание, а не только токены.
Разрыв в публичных доказательствах важен и здесь. В случае Gemini 3.1 Pro Preview Google говорит, что модель оптимизирована под software engineering behavior, token efficiency, groundedness и agentic workflows, требующие точного tool usage. Это значимо. Но, по крайней мере в официальных источниках, использованных в этой статье, Google не публикует столь же жёсткий публичный case в духе «Gemini — лучшая coding-autonomy модель», как это делает Anthropic для Opus. Если вы решаете, куда тратить дорогие часы оценки для coding-heavy продукта, этот разный proof burden должен влиять на план тестирования. Opus имеет более сильное first-party обоснование для premium coding evaluation. Gemini — более сильное first-party обоснование для cost-sensitive long-context evaluation.
Иначе говоря, Opus 4.6 максимально силён там, где модель должна нести больше ответственности в одном запросе. Если модель пишет patch, координирует инструменты, дебажит по нескольким файлам или синтезирует высокоценное исследование так, чтобы пользователь доверял результату без постоянного надзора, premium оправдать легче. Если же модель занимается длинным ingestion, triage, filtering или first-pass analysis, прежде чем задачу подхватит другая модель или человек, экономика Gemini обычно выглядит разумнее.
Именно тут многие статьи про «победителя» подводят читателя, сжимая coding до одной benchmark-строки. Настоящая software engineering работа — это не просто code generation. Это scope-setting, выбор инструментов, навигация по репозиторию, восстановление после ошибок, code review и способность сохранять coherence в многошаговом execution. Anthropic говорит об Opus 4.6 именно в этой плоскости. Google же описывает Gemini скорее как long-context, grounded, tool-precise engineering workflow engine. Эти задачи пересекаются, но не совпадают, и premium Opus имеет смысл только тогда, когда ваш продукт ближе к стороне Anthropic в этом пересечении.
Длинный контекст, проверка с опорой на источники и большие входы: где Gemini действительно сильнее
Вывод: Gemini логичнее брать как базовую модель для длинного контекста, больших входов и задач, где важно удержать стоимость под контролем.
Основание: Google публично документирует миллионный вход, более низкий прайс и отдельную экономику grounding.
Что выбирать: Если система чаще читает, сводит и перепроверяет большие массивы данных, чем автономно пишет и чинит код, начинайте с Gemini.
Главное архитектурное преимущество Gemini — не в том, что он «достаточно хорош». Оно в том, что модель сочетает публично задокументированную миллионную входную ёмкость, более низкие цены и явную экономику grounding, что делает её очень простой для рационального выбора в системах с большим input. Если вы строите внутренний research tool, explainer для репозиториев, pipeline анализа контрактов, transcript intelligence layer или любой другой workflow, где настоящая сложность заключается в том, чтобы удержать много исходного материала в одной coherent reasoning pass, Gemini 3.1 Pro Preview чрезвычайно привлекателен уже на уровне first principles. Вы получаете большой контекст без оплаты Opus-level цен, а даже более дорогой tier выше 200k prompt всё равно дешевле Claude Opus и по входу, и по выходу.
Собственное позиционирование Google усиливает эту трактовку. На model page подчёркиваются improved token efficiency, более grounded и factually consistent behavior, а также agentic workflows, которым требуется precise tool usage в реальных доменах. Это звучит не как «лучший автономный кодер», а как «сильный long-context reasoning engine для реальной продуктовой работы». Страница цен также явно прописывает search-grounding economics, что особенно важно, если ваше приложение должно совмещать гигантский контекст и свежую внешнюю информацию. В отличие от вендоров, которые оставляют grounding cost размытой зоной, Google заставляет думать о ней сразу. Для бюджета это неудобно, но для честного проектирования production-системы это плюс.
Gemini становится тем привлекательнее, чем больше ваши input payloads. Многие long-context workload-ы только внешне выглядят как reasoning-задачи. На глубинном уровне они упираются в ingestion и recall: можете ли вы поместить достаточно исходного материала в одну и ту же coherent context frame. Именно здесь различие между опубликованным лимитом 1,048,576 входных токенов и default-таблицей на 200k приобретает эксплуатационный смысл. Даже если 1M beta-context у Opus в итоге хорошо заработает в вашей среде, Gemini всё равно остаётся моделью, у которой миллионный контекст проще всего operationalize на основе публичной документации уже сейчас.
Это, однако, не означает автоматическую победу Gemini на финальном шаге. Во многих системах лучшая архитектура выглядит так: Gemini занимается ingestion, filtering и large-context synthesis, а Claude подключается для самых сложных coding- или autonomy-sensitive actions. Это не overengineering, а зачастую наиболее рациональный split. Long-context analysis и tool-heavy execution — разные bottleneck-ы. Модель может быть сильнее в одном и при этом не выигрывать другое.
Тонкая ошибка, которой стоит избегать, — использовать низкую цену Gemini как повод насильно встраивать его во все слои стека. Правильный вывод из документации Google — не «Gemini заменяет Claude», а «Gemini заслуживает быть default candidate там, где размер контекста, groundedness и прямая стоимость важнее premium first-pass autonomy». Для многих инженерных организаций это уже описывает существенную долю production-трафика.
Производственная реальность: Preview, beta и что на самом деле означают эти метки
Вывод: Status labels — это часть архитектурного решения, а не сноска внизу страницы.
Основание: Gemini 3.1 Pro официально остаётся Preview, а история с 1M context у Opus 4.6 всё ещё прямо описана как beta в launch material Anthropic.
Что выбирать: Gemini лучше подходит для контролируемых rollout-ов и систем с fallback-путями. 1M context у Opus нужно трактовать как beta-capacity, пока вы не проверили её в своей среде.
Самый быстрый способ принять плохое модельное решение — считать status labels маркетинговой мелочью. Это не так. Это deployment signals. Официальные материалы Google всё ещё помечают Gemini 3.1 Pro как Preview, и уже одно это должно менять способ его использования. Preview не означает «непригоден». Это означает, что вы должны ожидать более быстрых итераций, возможного поведения drift и большей потребности в regression testing, чем у устоявшейся production baseline. Это совершенно приемлемо для внутренних инструментов, evaluation loops, long-context analysis systems с fallback paths и тех продуктов, где rollout находится под вашим контролем. Это гораздо менее комфортно, если модель — единственный source of truth в mission-critical внешнем workflow.
У Anthropic история иная, но не лишённая риска. Сам Opus 4.6 явно позиционируется как текущая флагманская Claude-модель, а model overview у Anthropic достаточно стабилен для нормального production planning. Но миллионный контекст всё ещё явно называется beta в launch post. Это значит, что командам не стоит писать в архитектурной документации «Claude Opus 4.6 имеет полностью нормализованное 1M context window везде», пока они не проверили beta path в своей среде. Самая безопасная и точная формулировка — та, что используется в этой статье: Opus имеет опубликованный 200k context в overview-таблице и 1M beta-context capability согласно launch announcement Anthropic.
Отсюда следует довольно прямой production posture:
| Проблема деплоя | Gemini 3.1 Pro Preview | Claude Opus 4.6 |
|---|---|---|
| Официальный статус | Preview | Текущая флагманская модель |
| Самое безопасное предположение | миллионный input — часть документированной product capability | 200k context — документированный default, 1M нужно трактовать как beta-capacity |
| Лучший fit прямо сейчас | long-context internal tools, evaluation loops, grounded analysis | premium coding agents, high-autonomy tasks, long-output synthesis |
Интересно то, что ни одна из меток сама по себе не должна вас отпугнуть, если workload совпадает. Preview-модель всё ещё может быть правильным выбором, если её документированные сильные стороны точно совпадают с задачей, а вы выстроили вокруг неё разумный fallback. Beta-расширение контекста тоже может быть очень полезным, если вы относитесь к нему как к optional capacity, а не как к скрытой гарантии. Чего точно не стоит делать, так это сглаживать всё это до формулы «обе модели поддерживают 1M context, значит статус неважен». Статус важен, потому что показывает, насколько значительная часть вашей архитектуры опирается на поведение, которое вендор ещё активно формирует.
Если вам трудно понять, насколько важны эти operational нюансы для вашего стека, это обычно знак, что выбор не следует оформлять как commitment к одной модели. Сохраняйте доступ к обеим. Проектируйте этапы так, чтобы каждая модель использовалась там, где её документированная сила наиболее очевидна. Это безопаснее, чем пытаться выдавить permanent winner из несимметричного набора доказательств.
Какую модель всё-таки выбрать?

На этом этапе рекомендацию можно сформулировать очень прямо. Выбирайте Gemini 3.1 Pro Preview первым, если ваша основная проблема — это обработка больших prompt-пакетов по разумной цене, построение grounded research или document-analysis flows, либо оценка идей long-context продуктов без оплаты Opus-level цен на каждом вызове. Gemini также выглядит естественным первым кандидатом, если большая часть вашего high-volume трафика — это ingestion, filtering, retrieval-heavy analysis или first-pass engineering assistance, а не deeply autonomous execution.
Выбирайте Claude Opus 4.6 первым, если hardest part вашего продукта — agentic coding, tool orchestration, code review, debugging по большим репозиториям или premium reasoning, где плохой первый проход слишком дорог. Здесь first-party case Anthropic просто сильнее. Если ошибка модели запускает ручной repair, retry loops или быстро подрывает доверие разработчиков, premium Claude становится значительно более оправданным, чем кажется по прайс-таблице.
Маршрутизируйте обе, если в вашей системе уже фактически существуют две стадии: high-volume long-context stage и более узкая, quality-critical execution stage. Для многих технических команд в 2026 году именно это и будет лучшим ответом. Используйте Gemini для поглощения контекста, grounded analysis и дешёвой обработки широкого воронкообразного входа. Используйте Claude на более узком, но более ценном этапе, где execution quality действительно решает исход. Самая частая ошибка — заставлять одну модель делать обе работы только потому, что так «проще в эксплуатации».
Именно тут product mention может быть по-настоящему полезным, а не рекламным. Если вы хотите держать и Google, и Anthropic под рукой, не управляя с первого дня раздельными ключами, биллингом и routing glue, unified gateway вроде laozhang.ai может снизить операционные затраты. Его ценность не в «магической экономии», а в том, что dual-model architecture становится проще тестировать и поддерживать.
Главный вывод шире самой этой пары моделей: лучший ответ в 2026 году редко выглядит как постоянный выбор одного вендора. Это стратегия распределения workload-ов. Если после чтения вы понимаете, что ваше реальное решение шире двухмодельного сравнения, следующий разумный шаг — не искать ещё одну узкую benchmark-статью, а посмотреть широкое сравнение API основных провайдеров.
Как оценивать обе модели так, чтобы не потратить неделю впустую
Одна из причин, почему такие сравнения так часто искажаются в сети, состоит в том, что команды пытаются решить вопрос абстрактным спором вместо дисциплинированного evaluation plan. Правильная оценка Gemini 3.1 Pro Preview и Claude Opus 4.6 — это не «дать обеим моделям один эффектный prompt и выбрать более красивый ответ». Нужно проверять их на тех workload buckets, за которые вы в реальности будете платить в production. Если вы не разделите задачи на такие buckets, вы протестируете не тот вопрос и подгоните архитектурное решение под демо-задачи.
Самый чистый способ — создать три workload tracks. Первый — large-context synthesis track: длинные документы, большие репозитории, research packets или наборы спецификаций, которые показывают, насколько хорошо каждая модель ingest-ит и осмысляет большой input. Второй — coding and agent track: multi-file changes, tool-using tasks, debugging, code review и любые сценарии итеративной работы по репозиторию, которые проверяют, может ли модель сохранять coherence во время действия. Третий — grounded analysis track: задачи, где модели нужно использовать внешнюю информацию или перепроверять свежий материал, а не работать только внутри статичного prompt. Эти три трека напрямую соответствуют tradeoff-ам, которые описывает статья, и позволяют реально увидеть границы ценности Gemini и premium case Claude.
После того как buckets выбраны правильно, измерять нужно first-pass usefulness, а не абстрактное «качество ответа». Хорошая рубрика обычно включает четыре числа на задачу: был ли первый ответ пригоден к использованию, сколько потребовалось retries или corrections, какова была полная token cost и сколько времени ушло на человеческий ремонт. Первые два показателя говорят, действительно ли premium Claude окупается качеством execution. Третий показывает, сохраняет ли дешёвая цена Gemini смысл после порога 200k prompt-токенов. Четвёртый — это как раз та метрика, которой почти всегда не хватает в публичных сравнениях: модель с более дешёвым API bill не обязательно является более дешёвой системой, если ваша команда тратит по двадцать минут на исправление каждого плохого результата.
Полезно также принудительно добавить prompt-length split внутри оценки Gemini. Оставьте один bucket явно ниже 200k prompt-токенов, а второй — явно выше. Иначе вы рискуете прийти к выводу, что Gemini «радикально дешевле», основываясь только на low tier. Для Claude имеет смысл внимательно смотреть, как опубликованный лимит 128k output влияет на объём работы, который можно получить за один проход. Если вашему продукту регулярно нужны длинные отчёты, длинные code transformations или крупные structured outputs, этот output headroom может оказаться важнее, чем ещё одна строка в benchmark-таблице.
Оценка должна быть обратимой по дизайну. Используйте одинаковые инструкции, одинаковую scoring rubric и по возможности одинаковую окружающую инфраструктуру. Если вы уже знаете, что в будущем, возможно, будете маршрутизировать между двумя провайдерами, стройте test harness так, чтобы формат prompt-ов и success criteria оставались переносимыми. Именно тут unified gateway или adapter layer становится действительно полезным. Независимо от того, делаете ли вы собственный router или пользуетесь сервисом вроде laozhang.ai, цель не в удобстве ради удобства. Цель — сохранить optionality в момент, когда модельный ландшафт всё ещё движется очень быстро.
Практический результат хорошей оценки обычно менее драматичен, чем того хочется интернету. Многие команды обнаружат, что Gemini явно лучше на одной части стека, Claude — на другой, а настоящая победа приходит от сохранения обеих траекторий. Это лучше, чем насильно искать одного победителя, потому что в итоге вы получаете системный дизайн, который можно улучшать по мере того, как цены, лимиты и поведение моделей продолжают меняться.
Интеграционные детали, которые реально меняют архитектуру
Самые полезные инженерные различия между этими моделями — это не headline capabilities, а те детали, которые меняют routing layer, budgeting и production monitoring.
Во-первых, ценовой порог Gemini означает, что размер prompt надо знать ещё до маршрутизации. Если ваши запросы часто пересекают 200k prompt-токенов, нельзя считать низкую headline-цену Gemini постоянной. Это не делает Gemini плохой сделкой. Это означает, что model router должен учитывать размер prompt как часть решения. Системы, игнорирующие это, получают шумную оценку стоимости и неудачные escalation rules.
Во-вторых, output limit у Claude реально влияет на то, сколько работы можно получить за один проход. Опубликованный лимит 128k output у Opus 4.6 — это не просто декоративный параметр из спецификации. Он влияет на patch generation, long-form synthesis и генерацию крупных structured reports. Лимит Gemini в 65,536 output всё ещё велик, но он заметно меньше.
В-третьих, grounding и caching economics — это model-specific features, а не абстрактная “оптимизация”. Google явно показывает search-grounding charges, что особенно важно для приложений, ценность которых зависит от свежести информации. Anthropic явно показывает prompt caching multipliers и regional inference premiums. Если вас интересует серьёзная production economics, эти строчки нужно моделировать отдельно, а не прятать в общую графу “прочие расходы”.
В-четвёртых, evaluation harness нужно нормализовать до того, как вы стандартизируете одну модель. Самый надёжный архитектурный шаг — сделать prompt-ы, test cases и success criteria максимально переносимыми. Тогда выбор модели остаётся обратимым. Если вы заранее знаете, что можете routing-овать между обоими провайдерами, единый integration layer или gateway — включая такие варианты, как docs.laozhang.ai — заметно упрощает сохранение этой переносимости.
Главный архитектурный урок прост: не проектируйте систему так, будто выбор модели — это разовое branding-решение. Проектируйте её так, словно размер контекста, качество автономности и ценовые кривые будут и дальше двигаться. Потому что именно так и будет.
Часто задаваемые вопросы
Gemini 3.1 Pro Preview дешевле, чем Claude Opus 4.6?
Да. По официальному прайсу Gemini дешевле в обоих tiers. При prompt до 200k токенов Gemini стоит $2/$12 за MTok против $5/$25 у Opus. Выше 200k Gemini поднимается до $4/$18, но всё равно остаётся дешевле, хотя разрыв сокращается.
Claude Opus 4.6 лучше подходит для кодинга?
С точки зрения официальных доказательств — да, его case сильнее именно для coding и agentic execution. В материалах Anthropic прямо подчёркиваются coding, debugging, code review, computer use и long-running agentic tasks. Google тоже позиционирует Gemini для software engineering, но в официальных источниках, использованных здесь, не даёт столь же агрессивного публичного benchmark-case.
У Claude Opus 4.6 действительно есть 1M context?
В launch post Anthropic говорится, что Opus 4.6 имеет 1M token context window in beta. В model overview при этом по-прежнему указано 200k context. Самая безопасная production-интерпретация: 200k — документированный default, а 1M — beta-возможность, которую нужно валидировать отдельно.
Стоит ли избегать Gemini только потому, что он всё ещё Preview?
Не обязательно. Preview должен менять способ rollout, а не автоматически исключать Gemini. Это всё ещё сильный выбор для внутренних инструментов, evaluation loops, long-context analysis и других workload-ов, где его документированные преимущества хорошо совпадают с задачей и где допустима быстрая итерация.
Большинству команд лучше выбрать одну модель или маршрутизировать обе?
Многие команды выиграют больше от routing. Gemini — лучший первый кандидат для high-volume long-context задач. Claude — лучший первый кандидат для premium coding и high-autonomy execution. Если в вашей системе присутствуют обе категории задач, постоянный single-model answer обычно менее рационален, чем сохранение обеих опций.