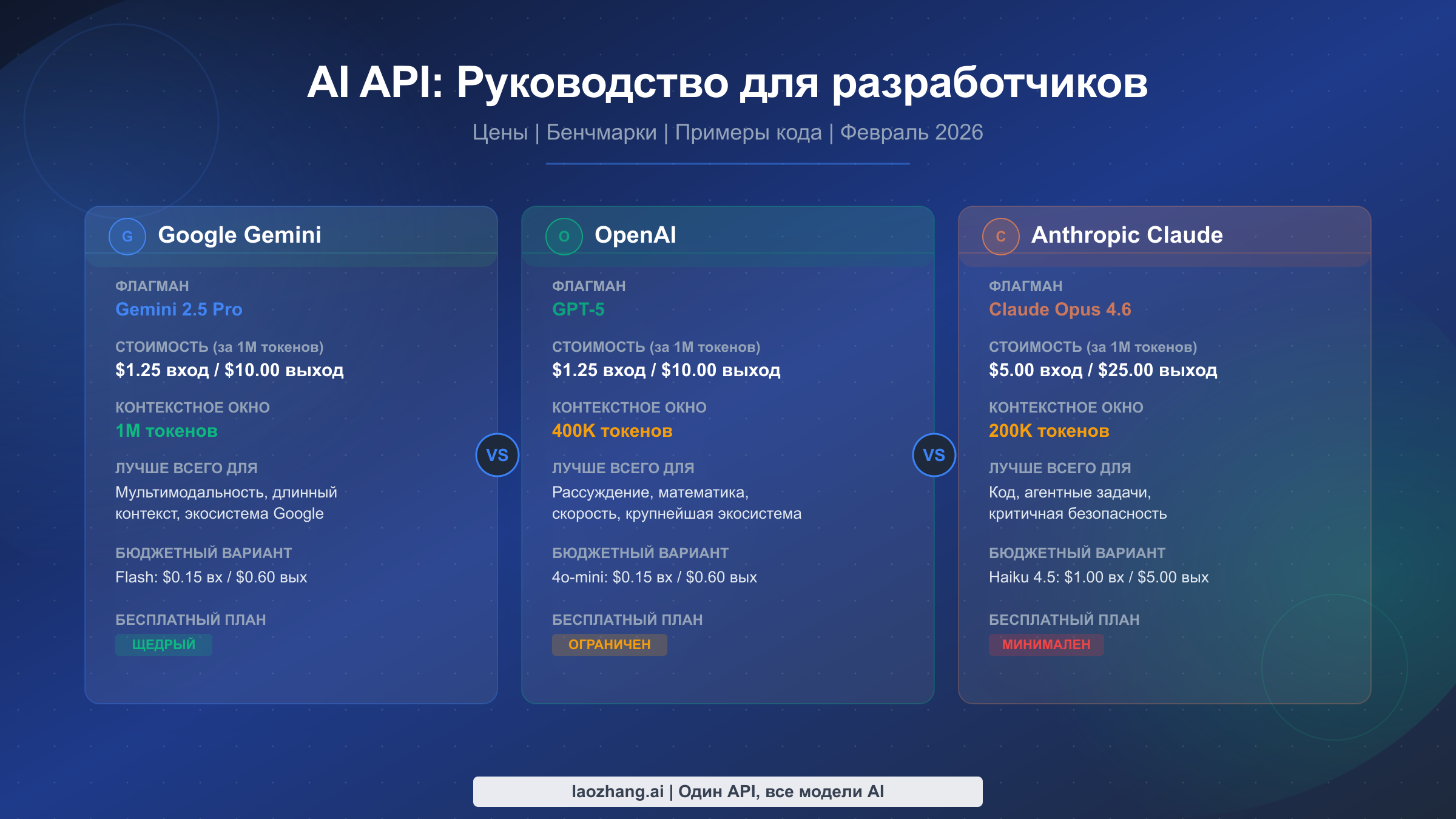
Выбор между API Gemini, OpenAI и Claude в 2026 году сводится к трём факторам: что вы разрабатываете, какой у вас бюджет и какие компромиссы вы готовы принять. По состоянию на февраль 2026 года GPT-5 и Gemini 2.5 Pro имеют одинаковую цену флагманского уровня --- $1,25 за миллион входных токенов, тогда как Claude Opus 4.6 стоит дороже --- $5,00, но лидирует в бенчмарках для разработчиков, таких как SWE-bench. В этом руководстве подробно разбирается каждый ценовой уровень, приводятся реальные сценарии стоимости и даётся система принятия решений на основе верифицированных данных из официальных источников.
Краткое содержание
Рынок AI API пришёл к сближению цен при расхождении возможностей. GPT-5 обеспечивает наиболее сильное общее мышление и математическую производительность, набрав идеальные 100% на AIME 2025 и обрабатывая токены со скоростью 187 токенов в секунду. Claude Opus 4.6 доминирует в бенчмарках кодирования с результатом 80,9% на SWE-bench Verified и превосходит конкурентов в агентных многоступенчатых задачах. Gemini 2.5 Pro предлагает самое большое контекстное окно --- 1 миллион токенов --- и совпадает по цене с GPT-5: $1,25/$10,00 за миллион токенов, что делает его очевидным выбором для обработки длинных документов. Для экономных разработчиков и GPT-4o mini, и Gemini 2.5 Flash стоят всего $0,15/$0,60 за миллион токенов, обеспечивая впечатляющие возможности за малую долю стоимости флагманских моделей.
Сравнение производительности --- бенчмарки, которые действительно важны
Бенчмарки производительности могут вводить в заблуждение, если смотреть не на те показатели. Модель, блестяще решающая академическую математику, может спотыкаться на реальных задачах программирования, а лидер в тестах с множественным выбором может выдавать медленный и дорогой результат в продакшене. Наиболее важные для разработчиков бенчмарки в 2026 году --- это SWE-bench Verified для оценки способности к программированию, AIME для математического мышления, MMLU для общих знаний и чистая пропускная способность для приложений, чувствительных к задержкам. Понимание этих цифр в контексте, а не простое принятие позиций в рейтинге за чистую монету --- вот что отличает информированный выбор API от решений, основанных на маркетинге.
Бенчмарк кодирования, привлекающий наибольшее внимание инженерных команд, --- SWE-bench Verified, который проверяет способность модели решать реальные задачи с GitHub из популярных open-source репозиториев. По состоянию на февраль 2026 года Claude Opus 4.5 занимает первое место с результатом 80,9%, за ним следуют Gemini 3 Pro с 76,8% и GPT-5.2 с 74,9% (humai.blog, февраль 2026). Этот разрыв примерно в 6 процентных пунктов между Claude и GPT-5 значителен для команд, создающих инструменты разработки с поддержкой ИИ, системы code review или автономных агентов программирования. Доминирование Claude в SWE-bench отражает целенаправленный фокус Anthropic на агентных возможностях программирования, и это проявляется на практике: Claude Code, CLI-инструмент Anthropic, стабильно справляется с многофайловыми рефакторингами и сложными сессиями отладки, с которыми другие модели испытывают трудности. Для команд, где качество кода является основным приоритетом, это преимущество в бенчмарке напрямую выражается в меньшем количестве циклов ревью, минимальной ручной корректировке и более высоком доверии разработчиков к коду, сгенерированному ИИ. Подробнее о различиях моделей Anthropic можно узнать в нашем сравнении Claude Opus и Sonnet.
В области математического мышления GPT-5.2 достиг идеальных 100% на AIME 2025 --- результата, которого не удалось достичь ни одной другой модели (множество источников, февраль 2026). Это не просто академический курьёз: высокая математическая производительность коррелирует с лучшими результатами в задачах структурированного мышления, анализа данных, финансового моделирования и любых приложений, где важна логическая дедукция. Gemini 2.5 Pro также показывает хорошие результаты в математических бенчмарках, хотя точные баллы AIME реже публикуются. Математическая производительность Claude уверенная, но не является его главной сильной стороной: Claude Opus набирает примерно 95,4% на GSM8K по сравнению с 96,8% у GPT-5. Для таких приложений, как автоматизированный финансовый анализ, научные вычисления или образовательное репетиторство, математическое преимущество GPT-5 оправдывает сопоставимую цену.
Производительность в общих знаниях, измеряемая MMLU (Massive Multitask Language Understanding), достигла уровня, на котором все три флагманские модели показывают результаты в пределах нескольких процентных пунктов друг от друга. GPT-5 набирает приблизительно 94,2%, Claude Opus 4.5 --- 93,8%, а Gemini 2.5 Pro --- около 92% (humai.blog, февраль 2026). Эти различия настолько малы, что MMLU сам по себе не должен определять ваш выбор API. MMLU показывает, что все три провайдера достигли уровня общей компетенции, при котором дифференцирующим фактором является уже не «какая модель знает больше», а «какая модель наиболее эффективно применяет свои знания для вашей конкретной задачи». Конвергенция в общих бенчмарках делает расхождение в специализированных бенчмарках, таких как SWE-bench и AIME, более значимым, поскольку они выявляют подлинные архитектурные различия и различия в обучении между моделями, а не просто преимущества масштаба.
Скорость имеет огромное значение в продакшен-среде, где пользователи ждут ответов. GPT-5.2 лидирует со скоростью примерно 187 токенов в секунду, что примерно в 3--4 раза быстрее Claude Opus, выдающего около 50 токенов в секунду (humai.blog, февраль 2026). Модели Gemini Flash обеспечивают исключительно малую задержку --- около 650 миллисекунд среднего времени отклика для коротких запросов. Когда вы разрабатываете чат-бот, помощник для программирования в реальном времени или любое пользовательское приложение, где воспринимаемая скорость отклика влияет на удовлетворённость, эти различия в скорости накапливаются при миллионах запросов. Скоростное преимущество OpenAI является одним из его сильнейших аргументов для развёртываний, чувствительных к задержкам, тогда как более медленная генерация Claude часто приемлема для фоновых задач, таких как генерация кода, анализ документов и пакетное создание контента. На практике многие команды обнаруживают, что 3--4-кратная разница в скорости имеет меньшее значение, чем можно ожидать, поскольку узким местом в большинстве приложений является сетевая задержка и парсинг ответа, а не чистая скорость генерации токенов. Однако для потоковых приложений, где пользователи наблюдают появление текста символ за символом, разница между 50 и 187 токенами в секунду создаёт заметно различный пользовательский опыт.
Общая картина бенчмарков ясно демонстрирует специализацию, а не универсальное превосходство. Ни одна модель не побеждает во всех измерениях. Следующая таблица обобщает ключевые конкурентные преимущества:
| Категория | Лидер | Результат / метрика | Второе место |
|---|---|---|---|
| Кодирование (SWE-bench) | Claude Opus 4.5 | 80,9% | Gemini 3 Pro (76,8%) |
| Математика (AIME 2025) | GPT-5.2 | 100% | Claude Opus (~95%) |
| Общие знания (MMLU) | GPT-5 | 94,2% | Claude Opus (93,8%) |
| Скорость (ток/с) | GPT-5.2 | 187 ток/с | Claude (~50 ток/с) |
| Контекстное окно | Gemini 2.5 Pro | 1 млн токенов | GPT-5 (400 тыс.) |
Именно эта специализация объясняет, почему стратегия мультимодельной маршрутизации, описанная в разделе оптимизации затрат, так эффективна: вы получаете лучшую модель для каждой категории задач, не платя флагманские цены за всё подряд.
Полный разбор цен API (февраль 2026)
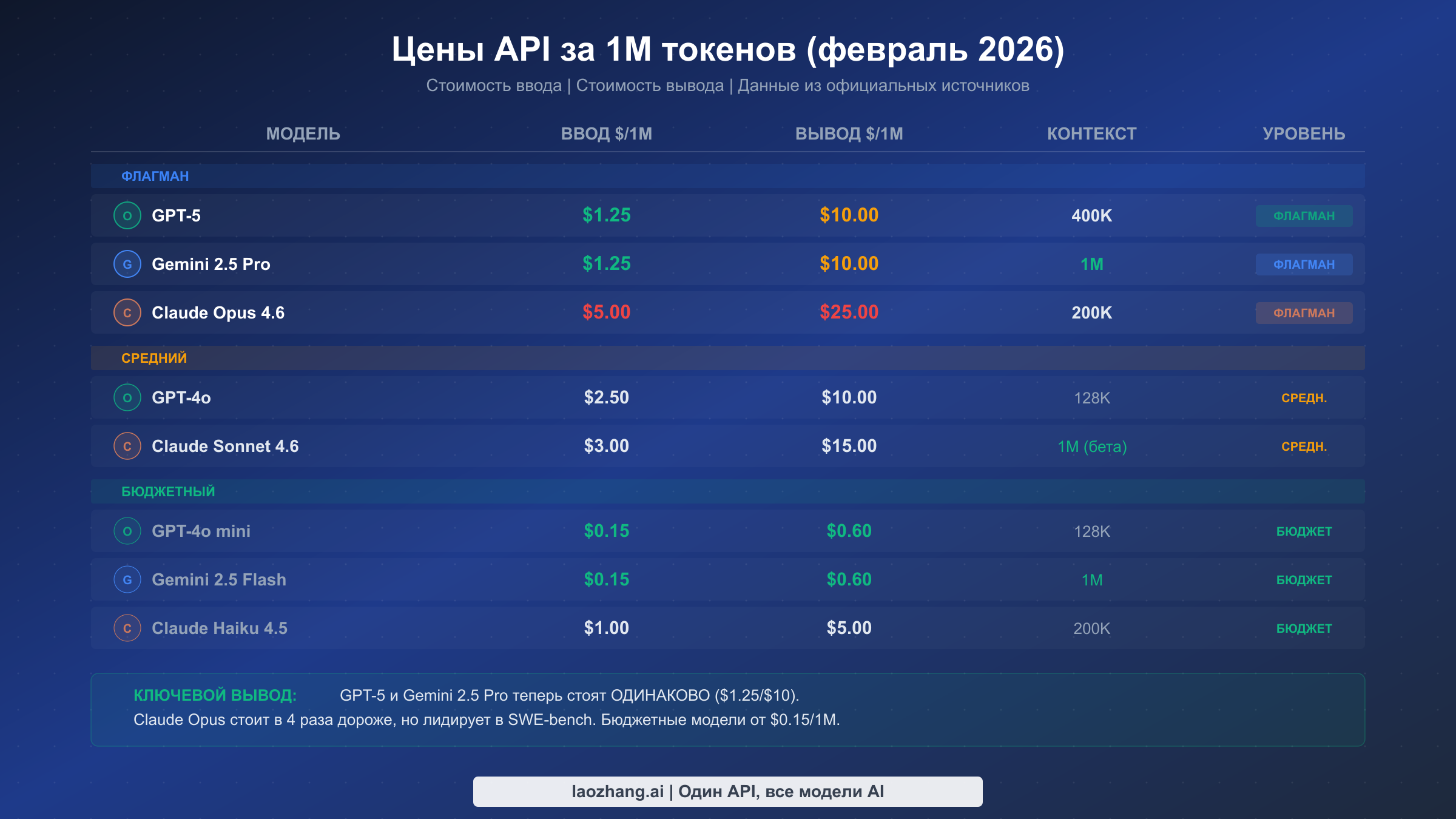
Ценообразование --- это та область, где рынок AI API 2026 года рассказывает свою самую интересную историю. Два года назад между провайдерами существовали огромные разрывы. Сегодня флагманский уровень в значительной степени сблизился, а бюджетные тарифы стали удивительно доступными, создавая двухскоростной рынок, который проницательные разработчики могут использовать в своих интересах. Все приведённые ниже цены указаны за миллион токенов и верифицированы по официальным страницам тарифов и результатам поиска Google на 26 февраля 2026 года.
Флагманский уровень
Флагманский уровень --- это место, где вы получаете лучшее мышление, наиболее способное программирование и высочайшую точность в сложных задачах. GPT-5 и Gemini 2.5 Pro теперь стоят одинаково: $1,25 за вход и $10,00 за выход на миллион токенов, что представляет собой значительное снижение цены по сравнению с предыдущими поколениями. Claude Opus 4.6 с ценой $5,00 за вход и $25,00 за выход стоит в 4 раза дороже по входным токенам и в 2,5 раза дороже по выходным по сравнению с прямыми конкурентами. Эта премия обеспечивает лучшую производительность кодирования на рынке, как обсуждалось в разделе бенчмарков, но это означает, что нужно стратегически подходить к его использованию. Разумный подход --- резервировать Claude Opus для сложного программирования и агентных задач, где его преимущество в SWE-bench оправдывает стоимость, а для задач общего мышления использовать GPT-5 или Gemini Pro, где все три модели показывают сопоставимые результаты. Стоит отметить, что Gemini 2.5 Pro использует многоуровневое ценообразование: запросы до 200 тыс. токенов получают тариф $1,25/$10,00, а более длинные запросы свыше 200 тыс. токенов обходятся в $2,50/$15,00. Для глубокого изучения ценовой структуры Claude и вариантов подписки смотрите наше подробное руководство по ценам и подпискам Claude.
Средний уровень
Средний уровень предлагает отличный баланс возможностей и стоимости для продакшен-нагрузок, которым нужна производительность выше бюджетной без флагманских расходов. Claude Sonnet 4.6 стоит $3,00/$15,00 за миллион токенов и обеспечивает качество программирования, близкое к Opus, поэтому многие команды разработчиков используют Sonnet в качестве модели по умолчанию и переключаются на Opus только для самых сложных задач. GPT-4o по цене $2,50/$10,00 остаётся надёжным универсальным вариантом с хорошо зарекомендовавшей себя экосистемой инструментов и интеграций. GPT-4.1 и модель рассуждения o3 стоят по $2,00/$8,00, предлагая специализированные возможности в расширенном контексте (1 млн для GPT-4.1) и структурированном мышлении (o3) соответственно. Этот уровень --- оптимальная точка старта для большинства продакшен-приложений, поскольку соотношение качества к стоимости здесь значительно лучше, чем у флагманских моделей, для большинства сценариев использования.
Бюджетный уровень и бесплатный доступ
Бюджетный уровень стал самой захватывающей частью рынка API 2026 года. GPT-4o mini и Gemini 2.5 Flash стоят по $0,15 за вход и $0,60 за выход на миллион токенов, что делает их примерно в 8 раз дешевле флагманов по входным и в 17 раз дешевле по выходным токенам. При таких ценах вы можете обрабатывать огромные объёмы текста за копейки. Claude Haiku 4.5 по цене $1,00/$5,00 значительно дороже других бюджетных вариантов, но всё равно намного дешевле моделей среднего уровня. Для объёмных задач, таких как классификация контента, анализ тональности, извлечение данных и простые вопросы-ответы, бюджетные модели показывают удивительно хорошие результаты. Ключевое различие на этом уровне --- контекстное окно: Gemini 2.5 Flash предлагает полноценное контекстное окно в 1 миллион токенов, тогда как GPT-4o mini ограничен 128 тыс. токенов. Если вам нужно обрабатывать длинные документы недорого, Gemini Flash --- безусловный победитель.
Бесплатные тарифы также важны для прототипирования и для независимых разработчиков, создающих сторонние проекты. Google предлагает наиболее щедрый бесплатный тариф для Gemini: 1500 запросов в день на Gemini 2.5 Flash через Google AI Studio, чего достаточно для создания и тестирования реального приложения без каких-либо затрат. Подробнее о максимальном использовании этого предложения читайте в нашем руководстве о щедром бесплатном тарифе Gemini. OpenAI предоставляет ограниченные бесплатные кредиты для новых аккаунтов, но не имеет постоянного бесплатного тарифа для API. Anthropic предлагает минимальный бесплатный доступ через API, хотя веб-интерфейс Claude.ai имеет бесплатный уровень для личного использования. Для разработчиков на этапе экспериментов начать с бесплатного тарифа Gemini для валидации идеи, прежде чем выделять бюджет на любого провайдера, --- практичный и безрисковый подход. DeepSeek также заслуживает упоминания в разговоре о бюджете: DeepSeek R1 по цене $0,55/$2,19 и DeepSeek V3.2 по цене $0,27/$1,10 за миллион токенов предлагают конкурентоспособные возможности рассуждения по ценам ниже, чем даже бюджетные модели крупных провайдеров, хотя доступность и ограничения скорости могут быть менее предсказуемыми, чем у «большой тройки». Общий посыл бюджетного уровня ясен: вам больше не нужно тратить флагманские деньги, чтобы получить действительно полезные возможности ИИ, а 66-кратная разница в цене между выходными токенами Claude Opus и Gemini Flash означает, что маршрутизация моделей --- это не просто приятная оптимизация, а экономическая необходимость.
Реальная стоимость 10 000 вызовов API
Абстрактная цена за токен приобретает смысл только тогда, когда вы переводите её в реальные ежемесячные счета для вашего конкретного сценария использования. Нижеследующие сценарии используют одинаковые допущения: каждый вызов API в среднем содержит 2000 входных и 500 выходных токенов, что типично для диалогового приложения с умеренным контекстом. Расчёты основаны на официальных ценах, верифицированных 26 февраля 2026 года, и охватывают три распространённых профиля разработчиков: независимый разработчик, стартап-команда и корпоративное развёртывание.
Независимый разработчик (10 000 вызовов в день) создаёт сторонний проект или продукт на ранней стадии, обрабатывая примерно 300 000 вызовов в месяц. С GPT-4o mini или Gemini 2.5 Flash на бюджетном уровне это стоит примерно $0,30 в день за входные токены ($0,15 x 20 млн / 1 млн) плюс $0,30 за выходные ($0,60 x 0,5 млн / 1 млн), что в сумме составляет около $0,60 в день или $18 в месяц. Та же нагрузка на GPT-5 стоит примерно $2,50 за вход плюс $5,00 за выход, или $7,50 в день и $225 в месяц. На Claude Opus 4.6 стоимость возрастает до $10,00 за вход плюс $12,50 за выход, или $22,50 в день и $675 в месяц. Разница между $18/месяц на бюджетной модели и $675/месяц на Claude Opus колоссальна для независимого разработчика. Именно поэтому маршрутизация моделей, которую мы рассмотрим в разделе оптимизации затрат, --- не опция, а необходимость для всех, кто разрабатывает с ограниченным бюджетом.
Стартап-команда (100 000 вызовов в день) управляет продакшен-приложением с реальными пользователями. При 3 миллионах вызовов в месяц бюджетные модели стоят примерно $180 в месяц, GPT-5 --- $2250 в месяц, а Claude Opus --- $6750 в месяц. Большинство стартапов в этом диапазоне используют смешанную стратегию: направляют 70--80% трафика через бюджетные модели для простых задач (классификация, базовые вопросы-ответы, извлечение данных), 15--20% через модели среднего уровня для стандартного мышления и лишь 5--10% через флагманские модели для сложных задач, требующих наивысшего качества. Стартап, использующий стратегию маршрутизации 70/20/10 с Gemini Flash, GPT-4o и Claude Sonnet, заплатит примерно $180 (Flash) + $450 (4o) + $338 (Sonnet) = около $968 в месяц по сравнению с $6750, если бы всё шло через Claude Opus. Это снижение затрат на 86% при минимальном влиянии на качество задач, направляемых на более дешёвые модели.
Корпоративное развёртывание (1 000 000+ вызовов в день) работает в масштабе, где каждая доля цента на вызов имеет значение. При 30 миллионах вызовов в месяц счёт на бюджетных моделях составляет примерно $1800/месяц, на GPT-5 --- $22 500/месяц, а на Claude Opus --- $67 500/месяц. Корпоративные команды почти повсеместно внедряют сложную маршрутизацию моделей, кэширование промптов и пакетную обработку. Хорошо оптимизированное корпоративное развёртывание обычно позволяет снизить затраты на 70--90% по сравнению с наивным использованием одной модели. Разница между $67 500 и $6750 ежемесячных затрат --- это разница между AI-инициативой, которая получает одобрение, и той, которую зарубят при рассмотрении бюджета.
Следующая таблица обобщает ежемесячные расходы по всем трём сценариям и уровням моделей, предоставляя быструю справку для планирования бюджета. Все расчёты предполагают одинаковые средние 2000 входных / 500 выходных токенов на вызов:
| Сценарий | Вызовов в день | Бюджетная модель | GPT-5 | Claude Opus 4.6 | Смешанная маршрутизация |
|---|---|---|---|---|---|
| Независимый разработчик | 10 000 | $18/мес | $225/мес | $675/мес | ~$45/мес |
| Стартап-команда | 100 000 | $180/мес | $2 250/мес | $6 750/мес | ~$968/мес |
| Корпоративное | 1 000 000 | $1 800/мес | $22 500/мес | $67 500/мес | ~$6 750/мес |
Столбец «Смешанная маршрутизация» предполагает распределение 70/20/10, описанное в сценарии стартапа выше, где 70% трафика идёт на бюджетные модели, 20% на средний уровень и 10% на флагманские. Эти цифры демонстрируют, почему оптимизация затрат --- не роскошь, а необходимость: без маршрутизации даже приложения среднего масштаба быстро накапливают счета, которые трудно оправдать перед заинтересованными сторонами. Разрыв между наивным и оптимизированным развёртыванием часто является разницей между жизнеспособным AI-продуктом и тем, который не может поддерживать собственные инфраструктурные расходы.
Как сократить расходы на AI API на 50% и более

Оптимизация затрат --- это не скупость, а разумное распоряжение бюджетом, чтобы вы могли позволить себе использовать ИИ в том масштабе, который требует ваше приложение. Пять стратегий ниже ранжированы по потенциальной экономии, и их комбинация может снизить общие расходы на API на 70--90% без значительной деградации качества. Это те же техники, которые используют компании, обрабатывающие миллионы вызовов API ежедневно, и они доступны командам любого размера.
Кэширование промптов обеспечивает наибольшую индивидуальную экономию --- до 90% на кэшированных токенах. Все три провайдера теперь поддерживают эту функцию нативно, хотя детали реализации различаются. OpenAI автоматически кэширует повторяющиеся префиксы промптов, что означает экономию без изменений кода, если ваши системные промпты одинаковы для всех вызовов. Anthropic использует явные блоки cache_control, дающие точный контроль над тем, что кэшируется, но требующие продуманной реализации. Google взимает $0,025 за миллион токенов в час за кэширование контекста, что экономически оправдано для приложений, повторно обрабатывающих одни и те же длинные документы. Если ваше приложение отправляет одинаковый системный промпт или префикс контекста при каждом вызове --- а большинство приложений именно так и делают, --- кэширование промптов должно стать первой оптимизацией, которую вы внедрите. Настройка занимает менее часа, а выгода проявляется мгновенно. Для команд, обрабатывающих системный промпт в 4000 токенов при 100 000 ежедневных вызовах, кэширование экономит примерно $500/месяц только на ценах GPT-5. Подробнее об управлении использованием API читайте в нашем руководстве по лимитам скорости Gemini API.
Интеллектуальная маршрутизация моделей --- вторая по значимости стратегия, обеспечивающая 60--80% экономии за счёт направления каждого запроса к наиболее дешёвой модели, способной его обработать. Концепция проста: лёгкий классификатор (который сам может быть бюджетной моделью) анализирует каждый входящий запрос и направляет простые задачи --- классификацию, извлечение данных, базовые вопросы-ответы --- на GPT-4o mini или Gemini Flash по $0,15 за миллион входных токенов; задачи стандартного мышления --- на GPT-4o или Gemini Pro среднего уровня; а сложное программирование, многоступенчатое мышление и нюансированный анализ резервирует для Claude Sonnet или Opus. На практике 60--80% запросов в большинстве приложений достаточно просты для бюджетных моделей, что означает оплату по бюджетным ценам за большую часть трафика. Сам классификатор добавляет минимальные затраты --- возможно, $0,01--0,02 за запрос на бюджетной модели, а решение о маршрутизации обычно добавляет менее 100 мс задержки.
Пакетная обработка снижает затраты на 50% для любых запросов, не требующих немедленного ответа. Все три провайдера предлагают пакетные API: Batch API от OpenAI, Message Batches от Anthropic и пакетное предсказание от Google --- все предоставляют фиксированную скидку 50% в обмен на 24-часовое окно обработки. Это идеально для разметки данных, модерации контента, анализа документов и любых фоновых задач. Если 30% вашей нагрузки допускают отложенные ответы, пакетная обработка сама по себе экономит 15% общего счёта.
Оптимизация промптов уменьшает потребление токенов на 30--50% за счёт устранения ненужного контекста, упрощения инструкций и использования структурированных форматов вывода. Типичные выигрыши включают замену многословных системных промптов лаконичными, сокращение few-shot примеров до минимума, необходимого для качества, использование формата вывода JSON для уменьшения многословности ответов и разбиение сложных промптов на целенаправленные подзадачи, каждая из которых использует меньше токенов. Хорошо оптимизированный промпт, достигающий того же качества при 800 токенах вместо наивных 2000, экономит 60% на этом вызове.
Комбинация всех четырёх стратегий даёт впечатляющие результаты. Рассмотрим реальный сценарий: компания, обрабатывающая 100 000 вызовов API в день с использованием GPT-5 для всего, со средними 2000 входных и 500 выходных токенов на вызов. Без оптимизации это стоит примерно $750 в день или $22 500 в месяц. После внедрения кэширования промптов для системного промпта (90% экономии на кэшированной части), маршрутизации 70% запросов на бюджетные модели, пакетной обработки 20% несрочных задач и оптимизации промптов на 30% --- та же нагрузка стоит примерно $95 в день или $2850 в месяц, что составляет снижение на 87%. Усилия по оптимизации занимают несколько недель инженерного времени, но окупаются в течение первого месяца.
Опыт разработчика --- от SDK до продакшена
Опыт разработчика при интеграции AI API выходит далеко за рамки ценообразования и бенчмарков. Он включает качество SDK, ясность документации, обработку ошибок, прозрачность лимитов скорости и более широкую экосистему инструментов и поддержки сообщества. Когда вы оцениваете эти API для продакшен-приложения, трение интеграции и обслуживания часто имеет не меньшее значение, чем сырые возможности модели, потому что модель, которую сложно правильно использовать, обойдётся вам во времени разработчиков столько же, сколько сэкономит на стоимости токенов.
Экосистема разработчиков OpenAI --- наиболее зрелая и обширная из трёх провайдеров. Python SDK (openai) и Node.js SDK хорошо поддерживаются, тщательно документированы и широко приняты. Дизайн API следует единообразному паттерну, который легко изучить и трудно использовать неправильно, с такими функциями, как вызов функций, структурированные выходы и стриминг, реализованными чисто и аккуратно. Документация OpenAI исчерпывающая и включает playground для экспериментов, репозиторий cookbook с практическими примерами и активный форум разработчиков. Огромный объём сторонних руководств, ответов на Stack Overflow и open-source интеграций означает, что практически любая проблема интеграции, с которой вы столкнётесь, уже была решена кем-то до вас. Лимиты скорости чётко документированы, а сообщения об ошибках описательны, что упрощает отладку. Основная критика со стороны разработчиков --- темп изменений API с устареванием моделей и изменениями параметров, требующими периодической миграции, хотя OpenAI значительно улучшил коммуникацию сроков устаревания в 2025--2026 годах.
API Claude от Anthropic значительно развился и теперь сопоставим с опытом разработчика OpenAI в большинстве областей. Python SDK чист и хорошо документирован, с особенно сильной поддержкой стриминга, использования инструментов и формата Messages API. Документация Anthropic превосходна --- пожалуй, наиболее технически точная из трёх провайдеров, с чёткими объяснениями таких концепций, как управление контекстным окном, управление кэшем и лучшие практики системных промптов. Где Anthropic действительно выделяется --- это инструментарий разработчика вокруг API: Claude Code, CLI-помощник для программирования, предоставляет эталонную реализацию агентного ИИ, которую многие команды адаптируют для своих задач. Функция расширенного мышления API, раскрывающая цепочку рассуждений модели, уникальна и ценна для отладки сложных выходов. Сообщество разработчиков меньше, чем у OpenAI, но высоко вовлечено, особенно среди команд, создающих агентные приложения и инструменты программирования. Наиболее частая жалоба разработчиков на Anthropic --- лимиты скорости в пиковые периоды, хотя ситуация улучшилась на протяжении 2025--2026 годов.
API Gemini от Google предлагает самый щедрый бесплатный тариф и глубочайшую интеграцию с облачной экосистемой Google. Python SDK поддерживает как Google AI Studio (для экспериментов и прототипирования), так и Vertex AI (для продакшена), и переход между ними достаточно плавный. Выдающаяся функция Gemini для разработчиков --- контекстное окно в 1 миллион токенов, которое устраняет необходимость в сложных стратегиях разбиения и извлечения, требуемых другими провайдерами для обработки длинных документов. API нативно поддерживает мультимодальный ввод, принимая текст, изображения, аудио и видео в одном запросе, что упрощает разработку мультимодальных приложений. Документация Google исчерпывающая, но может быть сложнее для навигации, чем у Anthropic или OpenAI, из-за более широкого контекста облачной платформы. Сообщество разработчиков быстро растёт, а playground AI Studio обеспечивает отличную среду для экспериментов. Основная точка трения для разработчиков --- периодическая путаница между ценами, возможностями и лимитами AI Studio и Vertex AI, которые не всегда чётко разграничены в документации.
Все три провайдера поддерживают потоковые ответы, вызов функций (использование инструментов), структурированный вывод в JSON и инструкции системного уровня. Паттерны кода достаточно похожи, чтобы переключение между провайдерами или реализация мультипровайдерной маршрутизации были несложными --- обычно достаточно изменений в инициализации клиента и незначительных корректировок промптов. Вот минимальный пример, показывающий, насколько похожи три API на практике:
pythonfrom openai import OpenAI client = OpenAI(api_key="sk-...") response = client.chat.completions.create( model="gpt-5", messages=[{"role": "user", "content": "Explain quantum computing"}] ) # Anthropic from anthropic import Anthropic client = Anthropic(api_key="sk-ant-...") response = client.messages.create( model="claude-opus-4-6-20260214", max_tokens=1024, messages=[{"role": "user", "content": "Explain quantum computing"}] ) # Google Gemini import google.generativeai as genai genai.configure(api_key="AIza...") model = genai.GenerativeModel("gemini-2.5-pro") response = model.generate_content("Explain quantum computing")
Конвергенция в дизайне API означает, что ваш выбор должен определяться прежде всего возможностями модели и ценообразованием, а не различиями SDK. Любая компетентная команда разработчиков может интегрировать любой из этих API за день-два работы.
Важный аспект, часто упускаемый при сравнении API, --- обработка ошибок и надёжность в продакшене. API OpenAI возвращает подробные коды ошибок с чёткими шагами исправления, а заголовки лимитов скорости упрощают реализацию адаптивного троттлинга. Ответы об ошибках Anthropic аналогично хорошо структурированы, с явными сигналами перегрузки, помогающими реализовать мягкую деградацию. Обработка ошибок API Gemini от Google адекватна, но иногда менее описательна, особенно когда ошибки исходят от базовой инфраструктуры Vertex AI. Все три провайдера периодически испытывают сбои и снижение производительности, поэтому продакшен-приложения должны реализовывать логику повторных попыток с экспоненциальным откатом как базовый минимум. Помимо надёжности отдельного провайдера, это ещё один сильный аргумент в пользу мультипровайдерных архитектур: если один провайдер испытывает сбой, ваше приложение может автоматически перенаправлять трафик на альтернативную модель, поддерживая доступность сервиса даже во время инфраструктурных инцидентов. Операционная устойчивость мультимодельной архитектуры --- это преимущество, которое не отображается в бенчмарках или таблицах цен, но имеет огромное значение, когда от вашего приложения зависят платящие пользователи.
Какой API выбрать? Система принятия решений
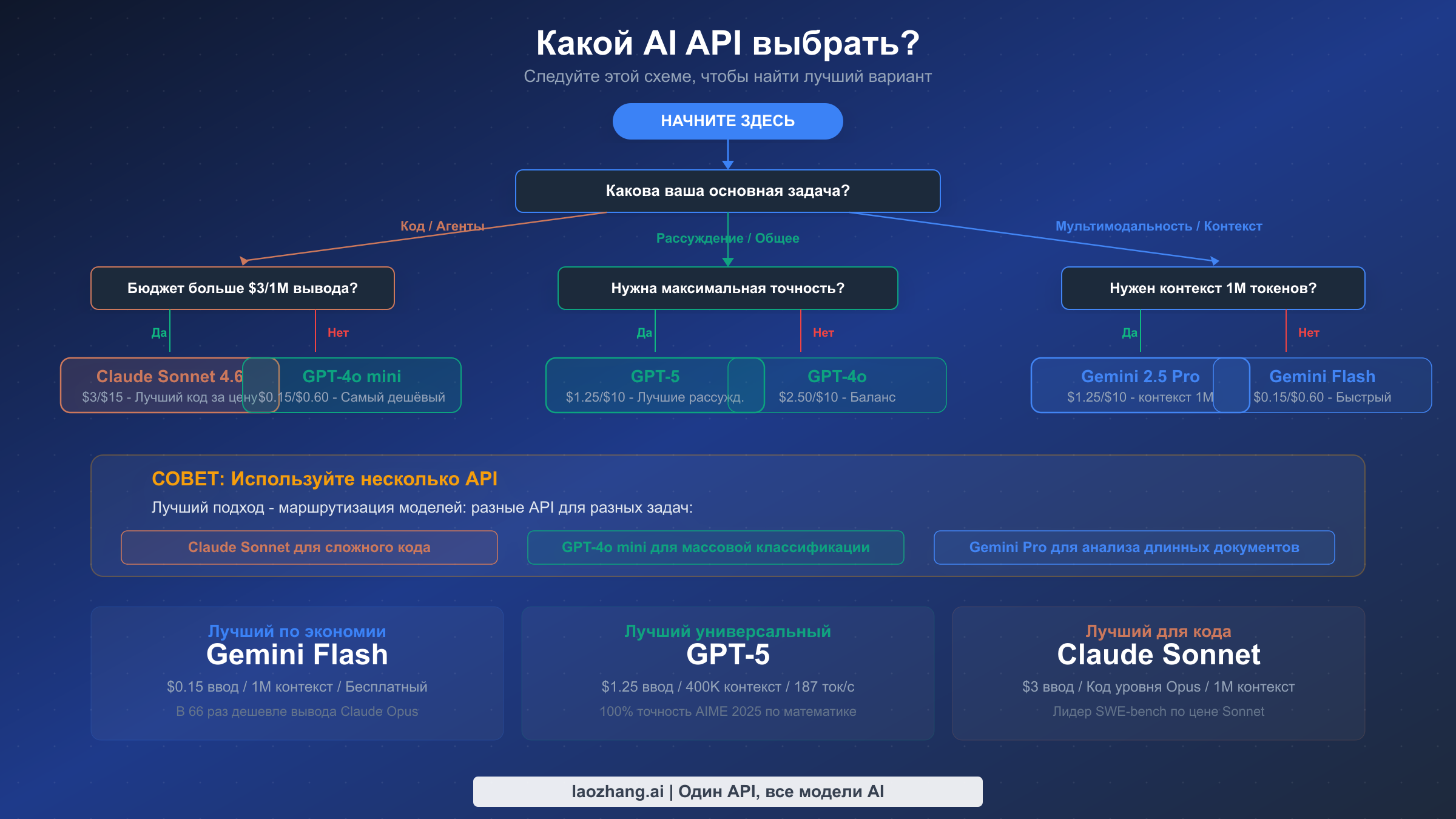
Вместо того чтобы объявлять один API «лучшим», наиболее полезный подход --- система принятия решений, которая сопоставляет ваши конкретные потребности с правильным провайдером. Приведённая ниже система проходит через сценарий использования, бюджетные ограничения и аспекты масштабирования, приходя к чёткой рекомендации. Это та же методология, которую используют инженерные команды компаний, обрабатывающих миллионы вызовов API ежедневно, адаптированная для разработчиков любого масштаба.
Начните с вашего основного сценария использования. Если ваша основная потребность --- помощь в программировании, генерация кода или агентные многоступенчатые задачи, Claude --- ваш сильнейший вариант. Claude Sonnet 4.6 по цене $3,00/$15,00 обеспечивает отличную производительность кодирования по разумной цене, а для самых сложных задач можно переключиться на Opus 4.6. Разрыв в SWE-bench между Claude и конкурентами достаточно велик, чтобы оправдать премию для нагрузок, ориентированных на программирование. Если ваша основная потребность --- общее мышление, ответы на вопросы, математический анализ или задачи широкого спектра, GPT-5 по цене $1,25/$10,00 предлагает лучшее соотношение цены и качества: первоклассное мышление, самую высокую скорость вывода 187 токенов в секунду и наиболее зрелую экосистему. Если ваше приложение обрабатывает длинные документы, работает с мультимодальным вводом или находится в экосистеме Google Cloud, Gemini 2.5 Pro --- естественный выбор. Его контекстное окно в 1 миллион токенов по цене $1,25/$10,00 не имеет аналогов у конкурентов, а мультимодальные возможности для обработки текста, изображений и видео в одном вызове значительно упрощают разработку.
Далее учтите ваши бюджетные ограничения. Если стоимость --- ваш главный приоритет и нужно удержать ежемесячные расходы в пределах $100, Gemini 2.5 Flash и GPT-4o mini --- ваши рабочие лошадки по $0,15/$0,60. Gemini Flash выигрывает, если нужен длинный контекст; GPT-4o mini --- если вы цените экосистему и документацию OpenAI. Если бюджет позволяет $500--2000 в месяц, открывается средний уровень: Claude Sonnet для программирования, GPT-4o для общих задач, и вы можете позволить направить небольшой процент трафика на флагманские модели для критически важных по качеству запросов. Если бюджет не является основным ограничением, используйте маршрутизацию моделей для получения лучшего качества по каждому типу задач без перерасхода.
Наконец, подумайте о траектории масштабирования. Если вы ожидаете рост от 10 тыс. до 100 тыс. и далее до 1 млн+ ежедневных вызовов, инвестируйте заранее в инфраструктуру маршрутизации моделей, кэширование промптов и пакетную обработку. Инженерные усилия по оптимизации при 10 тыс. вызовов окупаются при 100 тыс. и становятся критически важными при 1 млн.
Наиболее эффективный подход для большинства продакшен-команд в 2026 году --- не выбирать один API, а использовать все три стратегически. Направляйте сложное программирование на Claude Sonnet, высокообъёмную классификацию на GPT-4o mini или Gemini Flash, обработку длинных документов на Gemini Pro и общее мышление на GPT-5. Эта мультимодельная стратегия обеспечивает лучшее качество за каждый потраченный доллар, снижает риск зависимости от одного провайдера и позволяет вашему приложению пользоваться улучшениями от любого провайдера. Эпоха «выбери один API и используй его для всего» закончилась. Разработчики и компании, извлекающие максимальную ценность из ИИ в 2026 году, --- те, кто относится к выбору модели как к решению времени выполнения, а не одноразовому выбору.
Также стоит учитывать траекторию развития каждого провайдера. OpenAI обладает самыми глубокими корпоративными связями и самым агрессивным ритмом выпуска моделей, что означает, что их экосистема, как правило, первой получает новые функции (структурированные выходы, возможности компьютерного зрения, API реального времени). Anthropic сосредоточился на безопасности и надёжности, что важно для регулируемых отраслей --- здравоохранения, финансов и юриспруденции. Google обладает преимуществом инфраструктурной интеграции: если вы уже используете Google Cloud, BigQuery или Firebase, Gemini органично встраивается в вашу существующую инфраструктуру. Эти факторы экосистемы зачастую весят больше при долгосрочных платформенных решениях, чем любой отдельный бенчмарк или ценовой показатель, поскольку затраты на переключение накапливаются со временем по мере того, как ваша кодовая база становится всё более интегрированной с инструментарием конкретного провайдера.
Часто задаваемые вопросы
Можно ли использовать API GPT-5 бесплатно? GPT-5 не является бесплатным через API. OpenAI предоставляет ограниченные бесплатные кредиты для новых аккаунтов, но постоянное использование API требует платного аккаунта. GPT-5 стоит $1,25 за миллион входных токенов и $10,00 за миллион выходных токенов (openai.com, февраль 2026). Для бесплатного доступа к AI API наиболее щедрый бесплатный тариф предлагает Google Gemini API --- до 1500 бесплатных запросов в день на Gemini 2.5 Flash через Google AI Studio, что делает его жизнеспособным вариантом для прототипирования и приложений с малым объёмом без каких-либо платежей.
Какой AI API самый дешёвый для высоконагруженных приложений? По чистой стоимости за токен GPT-4o mini и Gemini 2.5 Flash идут вровень --- $0,15 за вход и $0,60 за выход на миллион токенов по состоянию на февраль 2026 года. Однако Gemini 2.5 Flash предлагает контекстное окно в 1 миллион токенов по сравнению с 128 тыс. у GPT-4o mini, что делает Flash более экономичным для приложений, обрабатывающих длинные документы. С учётом стратегий оптимизации --- кэширования промптов (до 90% экономии), пакетной обработки (50% скидка) и маршрутизации моделей --- общие эффективные затраты могут снизиться на 70--90% независимо от выбранного провайдера.
Как Gemini, GPT и Claude сравниваются для задач программирования? Claude уверенно лидирует в бенчмарках кодирования: Claude Opus 4.5 набрал 80,9% на SWE-bench Verified по сравнению с 76,8% у Gemini 3 Pro и 74,9% у GPT-5.2 (humai.blog, февраль 2026). Для бюджетных задач программирования Claude Sonnet 4.6 по цене $3,00/$15,00 обеспечивает качество кодирования, близкое к Opus, за малую долю стоимости. GPT-5 превосходит конкурентов в математическом мышлении в коде (100% AIME 2025), но уступает в сложных многофайловых задачах программной инженерии. Gemini хорошо работает с кодом, но его основное преимущество --- обработка крупных кодовых баз благодаря контекстному окну в 1 млн токенов, а не качество генерации кода как таковое.
Можно ли использовать несколько AI API в одном приложении? Да, и это рекомендуемый подход для продакшен-приложений в 2026 году. Использование нескольких API через стратегию маршрутизации позволяет назначать каждой задаче наиболее экономичную модель. Простые задачи идут на бюджетные модели ($0,15/млн вход), сложное программирование --- на Claude, а общее мышление --- на GPT-5. Большинство компаний, обрабатывающих свыше 100 тыс. ежедневных вызовов API, используют ту или иную форму маршрутизации моделей для одновременной оптимизации затрат и качества.
Какое контекстное окно мне нужно? Требования к контекстному окну зависят от вашего сценария использования. Для диалоговых чат-ботов и коротких задач 128 тыс. токенов (GPT-4o, GPT-4o mini) более чем достаточно. Для анализа документов и обработки длинных текстов Gemini 2.5 Pro и Flash предлагают 1 миллион токенов, устраняя необходимость в разбиении документов на части. Claude Sonnet 4.6 предлагает 1 млн токенов в бета-версии, тогда как Claude Opus 4.6 ограничен 200 тыс. GPT-5 предоставляет 400 тыс. токенов. Если вашему приложению необходимо обрабатывать документы длиннее 200 тыс. токенов, Gemini или Claude Sonnet --- ваши единственные варианты среди флагманских и среднеуровневых моделей.