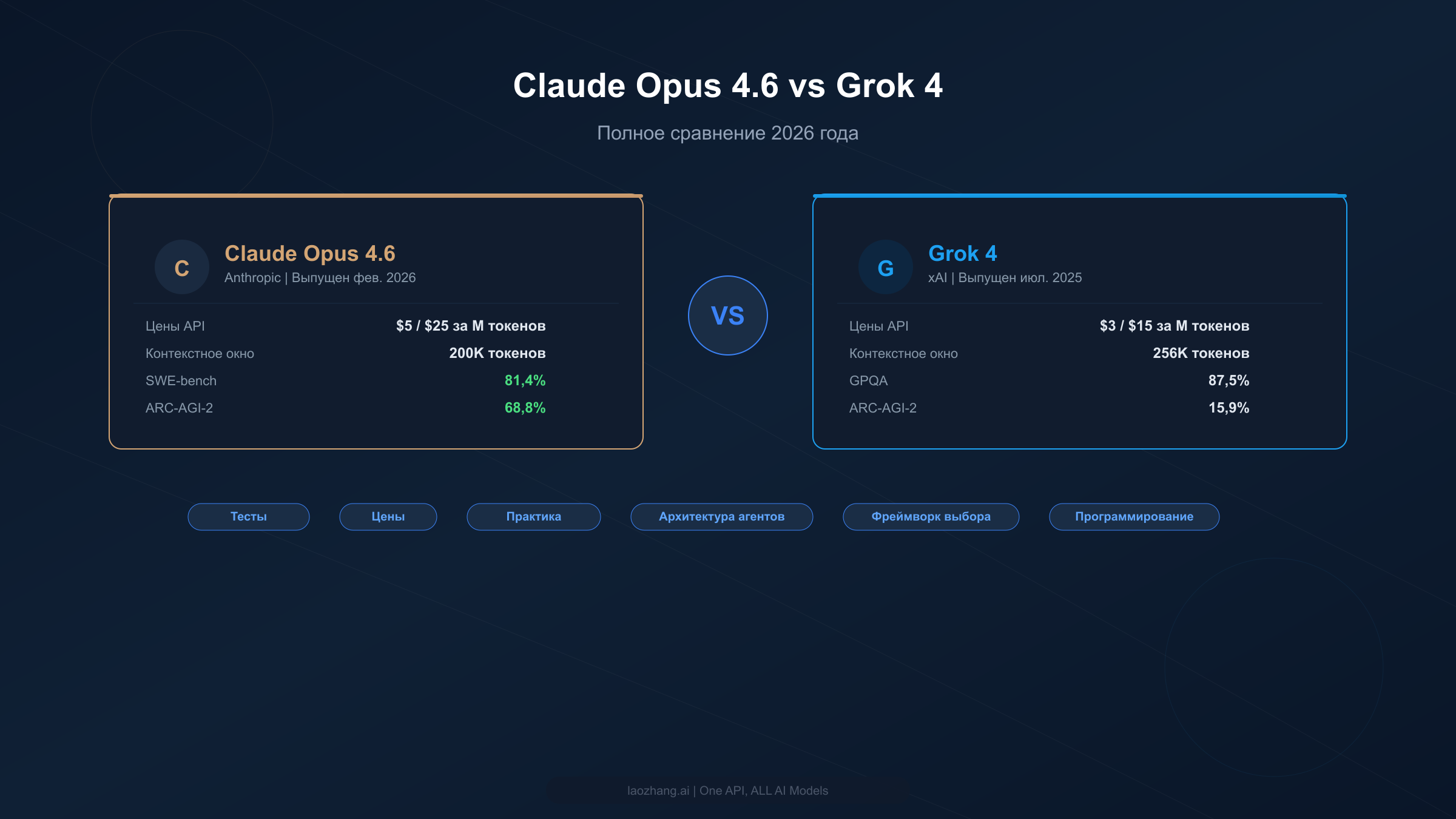
Claude Opus 4.6 превосходит Grok 4 по большинству бенчмарков — включая SWE-bench (81,4% против сопоставимого результата), ARC-AGI-2 (68,8% против 15,9%) и задачи рассуждения — но стоит на 67% дороже: $5/$25 за миллион токенов по сравнению с $3/$15 у Grok 4. Для разработчиков с ограниченным бюджетом варианты Grok 4 Fast предлагают доступ к API всего за $0,20/$0,50 за миллион токенов с контекстным окном в 2 млн токенов, что делает их одними из самых экономичных вариантов среди передовых моделей в 2026 году.
Краткое содержание — Сравнительная таблица
Выбор между Claude Opus 4.6 и Grok 4 в конечном счёте сводится к тому, что для вас важнее: максимальная производительность в программировании и рассуждении или экономичность с сильными математическими возможностями. Обе модели представляют передний край ИИ в 2026 году, но они обслуживают совершенно разные аудитории и сценарии использования. Таблица ниже даёт краткий обзор их сравнения по наиболее важным параметрам — от цен API до результатов бенчмарков и зрелости экосистемы. Используйте её как отправную точку, а затем углубляйтесь в разделы, соответствующие вашим конкретным потребностям.
| Характеристика | Claude Opus 4.6 | Grok 4 | Победитель |
|---|---|---|---|
| Цена API (вход) | $5,00/М токенов | $3,00/М токенов | Grok 4 |
| Цена API (выход) | $25,00/М токенов | $15,00/М токенов | Grok 4 |
| Контекстное окно | 200K токенов | 256K токенов | Grok 4 |
| SWE-bench | 81,4% | ~72% (оценка) | Claude |
| ARC-AGI-2 | 68,8% | 15,9% | Claude |
| GPQA | 84,0% | 87,5% | Grok 4 |
| Индекс математики | ~88% | 92,7% | Grok 4 |
| Скорость | ~80 ток/с | 40,6 ток/с | Claude |
| CLI для кода | Claude Code (встроенный) | Нет | Claude |
| Мульти-агент | Agent Teams (API) | 4.20 Beta (потребительский) | Claude |
| Подписка | $20/мес (Pro) | $30/мес (SuperGrok) | Claude |
| Бюджетный API | Haiku 4.5 ($1/$5) | Fast ($0,20/$0,50) | Grok 4 |
Картина ясна: Claude доминирует в тестах программирования и рассуждения, тогда как Grok предлагает лучшие цены и более сильную математическую производительность. Но реальная картина сложнее, чем может показать любая таблица — особенно если учесть кардинально разные подходы каждой компании к архитектуре агентов и инструментам для разработчиков, которые мы подробно рассмотрим ниже. Одно важное замечание о строке «Бюджетный API»: Grok 4 Fast — это не просто более дешёвая версия Grok 4, а фундаментально другая модель с огромным контекстным окном в 2 млн токенов, что делает её пригодной для совершенно иных задач, чем флагманский Grok 4. Аналогично, Claude Haiku 4.5 идёт на другие компромиссы между качеством и скоростью по сравнению с Opus. Сравнение бюджетных уровней полезно для планирования затрат, но их не следует рассматривать как прямую замену флагманским моделям в критически важных по производительности приложениях.
Ландшафт моделей в 2026 году
Прежде чем напрямую сравнивать Claude Opus 4.6 и Grok 4, важно понять, какое место каждая модель занимает в своём семействе. Это особенно важно для стороны Grok, где линейка моделей стала действительно запутанной — даже для опытных разработчиков. xAI выпустила множество вариантов для разных уровней доступа, и понимание того, какой именно «Grok 4» вы сравниваете с Claude, существенно влияет на справедливость любого сравнения.
Claude Opus 4.6 находится на вершине иерархии моделей Anthropic по состоянию на март 2026 года. Выпущенная 5 февраля 2026 года, она представляет самую мощную модель рассуждения Anthropic, расположенную выше Claude Sonnet 4.6 (сбалансированный вариант за $3/$15 за миллион токенов) и Claude Haiku 4.5 (оптимизированный по скорости вариант за $1/$5 за миллион токенов). Именование понятное: Opus для максимальных возможностей, Sonnet для лучшего баланса производительности и стоимости, Haiku для скорости и эффективности. Когда обсуждают «Claude» в контексте передовых возможностей ИИ, почти всегда подразумевают уровень Opus. Для более детального сравнения Opus и Sonnet внутри семейства Claude смотрите наше сравнение Claude Opus и Sonnet.
Семейство моделей Grok (важный контекст)
Ландшафт Grok — это то место, где возникает больше всего путаницы, и ни одна другая статья-сравнение в текущем ТОП-10 результатов поиска не объясняет это должным образом. Вот полная разбивка семейства Grok 4 по состоянию на март 2026 года (проверено по docs.x.ai):
Grok 4 (grok-4-0709) — это флагманская модель, выпущенная 9 июля 2025 года. Она поддерживает постоянно включённое рассуждение (режим без рассуждения отсутствует), контекстное окно 256K и цену $3,00 за входные / $15,00 за выходные миллионы токенов. Именно эта модель конкурирует напрямую с Claude Opus 4.6. Важное отличие: рассуждение Grok 4 всегда активно, то есть вы всегда платите за глубокий процесс мышления. Claude Opus 4.6, напротив, предлагает расширенное мышление как опциональную функцию, давая разработчикам более тонкий контроль над стоимостью.
Варианты Grok 4 Fast включают режимы с рассуждением и без (grok-4-fast-reasoning и grok-4-fast-non-reasoning), а также их аналоги версии 4.1. Они имеют огромное контекстное окно в 2 млн токенов и стоят всего $0,20/$0,50 за миллион токенов — в 15-25 раз дешевле Claude Opus 4.6. Они жертвуют частью возможностей ради значительной экономии, но для многих приложений производительность более чем достаточна. Контекстное окно в 2 млн токенов особенно ценно для обработки целых кодовых баз или длинных документов, которые потребовали бы разбиения на части при использовании других моделей.
Grok 4.20 Beta — это потребительская мультиагентная система, запущенная 17 февраля 2026 года. Доступная через SuperGrok ($30/мес) и SuperGrok Heavy ($300/мес), она включает четырёх специализированных агентов — Captain, Research, Logic и Creative — которые совместно работают над сложными задачами. Это ответ xAI на Agent Teams от Claude, но с принципиально иной философией, которую мы рассмотрим в разделе об архитектуре. Примечательно, что Grok 4.20 Beta пока не имеет доступа через API, оставаясь исключительно потребительским продуктом.
Почему это важно для вашего сравнения
Когда вы видите сравнения бенчмарков в интернете, большинство автоматически генерируемых инструментов противопоставляют «Claude Opus 4.6» и «Grok 4», не уточняя, какой именно вариант Grok, и сравнивают ли они возможности API, потребительские функции или «сырую» производительность модели. Справедливое сравнение должно сопоставлять Claude Opus 4.6 со стандартным API Grok 4 для анализа бенчмарков и цен, одновременно признавая варианты Fast как привлекательные бюджетные альтернативы, а 4.20 Beta — как интересного потребительского конкурента Claude Pro.
Разбор цен — каждый доллар на счету
Для понимания реальной стоимости этих моделей необходимо заглянуть дальше цены за токен и рассмотреть, сколько вы фактически потратите в реальных сценариях использования. Заголовочные цифры — $5/$25 для Claude против $3/$15 для Grok — рассказывают лишь часть истории. Способ обработки токенов рассуждения, кэширования и многоуровневого доступа каждой моделью создаёт существенные различия в стоимости, которые полностью зависят от вашего конкретного сценария использования. Для полного обзора ценообразования Claude по всем уровням смотрите наше подробное руководство по ценам Claude Opus 4.6.
Цены API: полная картина
Базовое сравнение цен API показывает 40%-ное ценовое преимущество Grok 4 как по входным, так и по выходным токенам. Но несколько факторов усложняют эту простую математику. Claude Opus 4.6 стоит $5,00 за миллион входных токенов и $25,00 за миллион выходных токенов (проверено по platform.claude.com, март 2026 г.). Grok 4 стоит $3,00 за входные и $15,00 за выходные миллионы токенов, с кэшированными входными токенами по $0,75 за миллион (docs.x.ai, март 2026 г.). Скидка Grok 4 на кэширование промптов до $0,75 за миллион токенов более агрессивна, чем уровень кэширования Claude, что может значительно снизить стоимость для приложений, повторно использующих системные промпты или справочные документы в нескольких вызовах API.
Сравнение бюджетных уровней — вот где разрыв становится драматичным. Самый доступный вариант Anthropic — Claude Haiku 4.5 по $1,00/$5,00 за миллион токенов — хорошее соотношение цена-качество, но всё ещё в 5 раз дороже Grok 4 Fast за $0,20/$0,50. Для высоконагруженных приложений, где нужны возможности, близкие к передовым, без соответствующих цен, варианты Grok 4 Fast представляют одно из лучших предложений на рынке. Они также предлагают контекстное окно в 2 млн токенов по сравнению с более скромным контекстом Haiku.
Цены потребительских подписок
Для пользователей, предпочитающих подписку вместо интеграции через API, Claude Pro стоит $20/мес и предоставляет доступ к Opus 4.6 с щедрыми лимитами использования. SuperGrok, сопоставимое предложение xAI, стоит $30/мес и включает доступ к Grok 4 плюс мультиагентную систему 4.20 Beta. SuperGrok Heavy за $300/мес нацелен на продвинутых пользователей и предприятия, которым нужны более высокие лимиты частоты запросов и приоритетный доступ. С точки зрения чистой ценности подписки Claude Pro предлагает доступ к передовому уровню по более низкой месячной цене, хотя SuperGrok включает мультиагентные возможности, которые Claude не предоставляет в своём уровне подписки.
Анализ стоимости задач: сколько вы реально заплатите
Цена за токен обретает смысл только при сопоставлении с реальными задачами. Вот сколько стоят пять типичных задач разработчика с каждой моделью, основываясь на типичных паттернах потребления токенов. Стандартный код-ревью pull-запроса на 500 строк (примерно 4000 входных и 2000 выходных токенов) обходится примерно в $0,07 с Claude Opus 4.6 против $0,04 с Grok 4 — разница около 3 центов, которая едва заметна на уровне отдельной задачи. Анализ 50-страничного технического документа (примерно 25 000 входных токенов, 5000 выходных) стоит около $0,25 с Claude и $0,15 с Grok. Разговор с чат-ботом из 10 реплик обходится примерно в $0,05 с Claude против $0,03 с Grok. Сессии отладки с расширенным контекстом обычно стоят $0,50-$1,00 с Claude и $0,30-$0,60 с Grok. Полный анализ кодовой базы с использованием максимального контекстного окна стоит примерно $1,00 с Claude (200K токенов) против $0,77 с Grok (256K токенов).
Разница в стоимости становится ощутимой в масштабе. Команда разработчиков, совершающая 1000 вызовов API в день, сэкономит примерно $30-$50 ежедневно, выбрав Grok 4 вместо Claude Opus 4.6 — примерно $900-$1500 в месяц. Однако если Grok 4 Fast достаточно для части этих вызовов, экономия нарастает стремительно. Использование Grok 4 Fast для 80% задач и резервирование Grok 4 для сложных рассуждений может снизить ежемесячный счёт до $200 и менее, по сравнению с $1500+ при использовании исключительно Claude Opus.
Стоит отметить, что Anthropic также предлагает многоуровневое ценообразование внутри семейства Claude. Практичная стратегия оптимизации затрат для пользователей Claude — направлять простые задачи в Claude Haiku 4.5 ($1/$5 за миллион токенов), задачи средней сложности в Sonnet 4.6 ($3/$15), а Opus 4.6 резервировать для задач, которым действительно нужно рассуждение уровня передовых моделей. Такой подход может снизить затраты на семейство Claude на 60-70% по сравнению с использованием Opus для всего подряд. Тот же принцип применим на стороне Grok: используйте варианты Fast по умолчанию и эскалируйте до стандартного Grok 4 только при необходимости.
Глубокий разбор бенчмарков — что на самом деле значат цифры
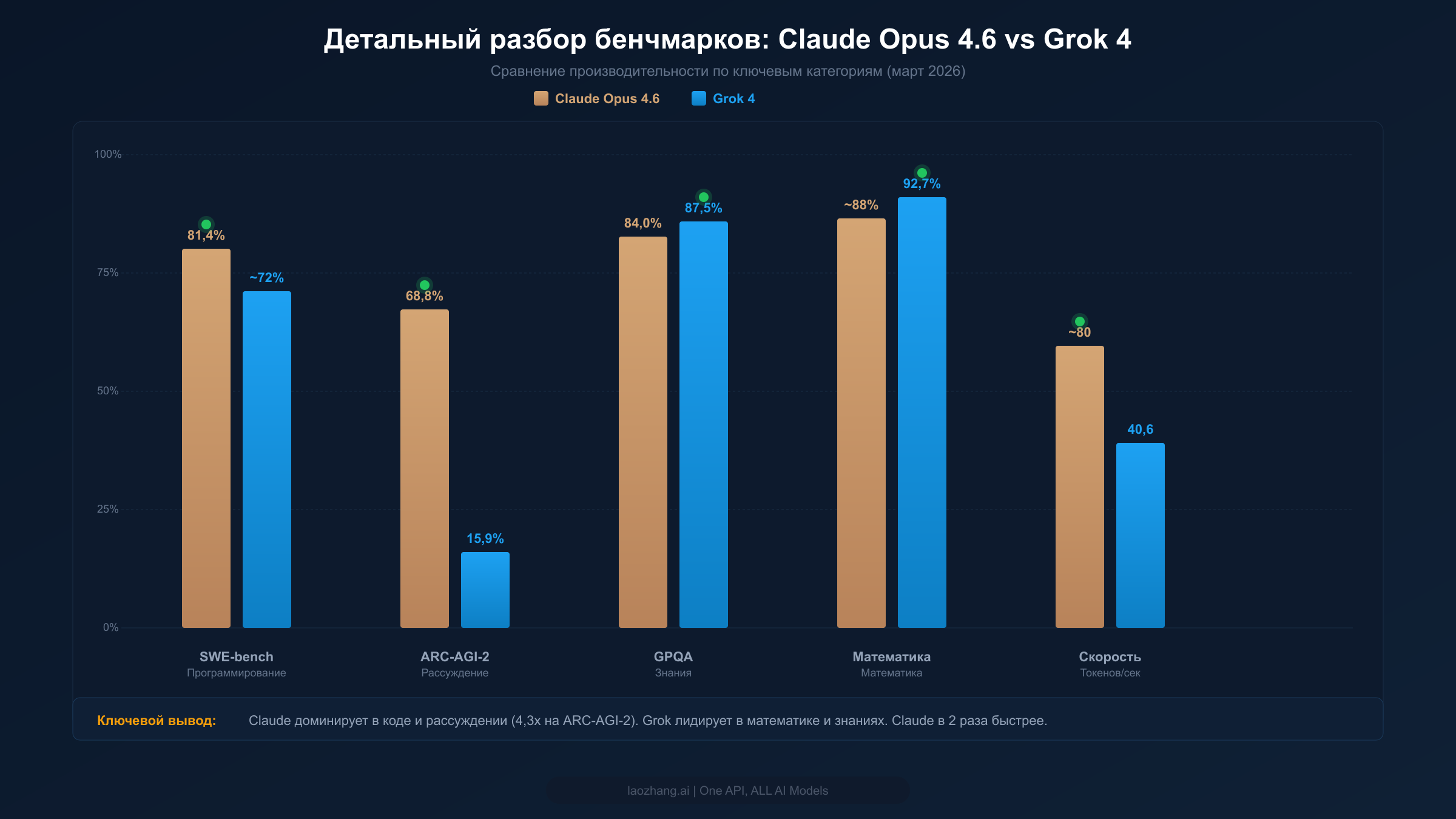
Результаты бенчмарков встречаются повсюду в сравнениях ИИ-моделей, но «сырые» цифры без контекста хуже, чем бесполезные — они вводят в заблуждение. Разница в 5 процентных пунктов на GPQA имеет совершенно другие практические последствия, чем такой же разрыв на SWE-bench. В этом разделе мы разбираем, что именно измеряет каждый крупный бенчмарк, что результаты говорят о реальных возможностях и где каждая модель по-настоящему преуспевает, а где различия незначительны.
Бенчмарки программирования: где лидирует Claude
SWE-bench Verified — это золотой стандарт оценки способности модели решать реальные задачи программирования — исправление настоящих багов из популярных open-source Python-репозиториев. Claude Opus 4.6 набирает 81,4% в этом бенчмарке (официальное объявление Anthropic, февраль 2026 г.), что представляет значительное лидерство над ориентировочными ~72% Grok 4. Это не тривиальный разрыв: он означает, что Claude успешно решает примерно одну из десяти дополнительных реальных задач программирования, с которыми Grok не справляется. Для команд разработчиков, оценивающих эти модели для помощи в коде, эта разница напрямую транслируется в меньшее количество ручных вмешательств и более быстрые циклы итерации.
Terminal-Bench измеряет способности агентного программирования — насколько хорошо модель может автономно работать в терминальной среде, выполняя команды, интерпретируя результаты и итеративно улучшая решения. Claude Opus 4.6 набирает здесь 43,2% — бенчмарк, по которому Grok 4 не публиковал официальных результатов. Эта метрика становится всё важнее по мере того, как разработчики внедряют агентные рабочие процессы, где ИИ действует как полуавтономный напарник-программист, а не просто инструмент автодополнения кода. Отсутствие результатов Grok 4 на Terminal-Bench само по себе показательно — xAI не позиционирует Grok как агентную модель для программирования, тогда как Anthropic построила целый продукт (Claude Code) вокруг этой возможности. Для команд, рассматривающих модель для автономных задач разработки, эта разница в стратегическом фокусе важна не менее самих результатов бенчмарков.
Бенчмарки рассуждения: драматический разрыв
ARC-AGI-2 создан для тестирования способности к нестандартному рассуждению — того типа гибкого интеллекта, который требует подлинного понимания, а не сопоставления паттернов. Разрыв здесь чрезвычайный: Claude Opus 4.6 набирает 68,8% против 15,9% у Grok 4. Это 4,3-кратное различие — самый большой разрыв в производительности между этими двумя моделями по любому крупному бенчмарку. Что это значит на практике? Задачи ARC-AGI-2 требуют от модели выявления абстрактных паттернов и применения их в новых контекстах — именно тот тип рассуждения, который важен для сложных решений по архитектуре ПО, творческого решения проблем и задач, где путь решения не предопределён. Если ваша работа регулярно связана с нестандартными задачами рассуждения, этот разрыв в бенчмарке является высокопредиктивным для реальных различий в производительности.
Знания и математика: где преуспевает Grok
GPQA (Graduate-level Professional Quality Assurance) тестирует знания экспертного уровня в нескольких научных областях. Grok 4 лидирует здесь с 87,5% против 84,0% у Claude — заметное, но не драматичное преимущество. Это говорит о том, что Grok имеет небольшое превосходство в задачах, требующих глубоких предметных знаний в науке, медицине и технических областях. Индекс математики рассказывает похожую историю: 92,7% у Grok 4 против примерно 88% у Claude указывает на более сильное математическое рассуждение. Для приложений с акцентом на математические вычисления, статистический анализ или научное рассуждение преимущество Grok реально и стабильно прослеживается в нескольких бенчмарках, ориентированных на математику.
Скорость и задержка: производственный фактор
Для производственных приложений «сырые» результаты бенчмарков менее важны, чем сочетание качества и скорости. Claude Opus 4.6 генерирует примерно 80 токенов в секунду — примерно вдвое больше, чем 40,6 токенов/сек у Grok 4 (pricepertoken.com, март 2026 г.). Разница во времени до первого токена (TTFT) ещё более разительна: Claude начинает отвечать примерно через 1,5 секунды, тогда как у Grok 4 этот показатель составляет 10,79 секунды. Почти 10-секундная разница в TTFT критична для интерактивных приложений — чат-ботов, помощников по коду и инструментов анализа в реальном времени, где пользователи ожидают мгновенной отзывчивости. Постоянно включённое рассуждение Grok 4 способствует увеличению задержки, поскольку каждый запрос проходит через конвейер глубокого рассуждения вне зависимости от того, требует ли этого задача.
Программирование и разработка: где преуспевает Claude

Для разработчиков, оценивающих эти модели как помощников по коду, сравнение выходит далеко за пределы результатов бенчмарков и затрагивает экосистему инструментов, интеграций и опыта разработки, которую каждая платформа предоставляет. Именно здесь разрыв между Claude и Grok становится наиболее выраженным — не потому, что Grok 4 плохо справляется с кодом, а потому, что Anthropic серьёзно инвестировала в построение комплексного рабочего процесса разработчика вокруг Claude.
Claude Code — это нативный инструмент командной строки от Anthropic, который даёт Claude прямой доступ к вашему терминалу, файловой системе и среде разработки. Это не просто обёртка над API — это агентная система программирования, способная читать вашу кодовую базу, писать и редактировать файлы, запускать тесты, управлять операциями git и итеративно улучшать решения автономно. Аналогичного инструмента в экосистеме Grok не существует. Один этот продукт создаёт категорию опыта разработчика, которую Grok просто не может обеспечить одним лишь доступом к API. Для команд, уже использующих Claude Code, стоимость перехода на Grok включает потерю всего этого агентного рабочего процесса программирования.
Agent Teams, представленные с выпуском Claude 4.6, позволяют разработчикам оркестрировать несколько экземпляров Claude, работающих параллельно над различными аспектами задачи — один агент пишет код, другой управляет тестированием, третий проводит ревью качества. Эта мультиагентная возможность работает через API с детальным контролем разрешений и поддерживает изолированные git worktree для каждого агента, предотвращая конфликты между параллельными потоками работы. Для подробного разбора этих возможностей смотрите наше руководство по Claude Agent Teams.
Возможности программирования Grok 4, хотя и не так широко протестированные, имеют свои преимущества. Постоянно включённое рассуждение означает, что каждый запрос на код получает глубокий анализ по умолчанию, что может быть полезно для сложных алгоритмических задач и математического кода, где преимущество Grok в 92,7% по Индексу математики транслируется в лучшие решения. Контекстное окно в 2 млн токенов, доступное через варианты Grok 4 Fast, по-настоящему полезно для масштабного анализа кода — обработки целых репозиториев или длинных цепочек зависимостей, которые превысили бы лимит Claude в 200K. Кроме того, цена Grok 4 Fast в $0,20/$0,50 делает экономически целесообразным запуск масштабных автоматизированных конвейеров анализа кода, которые были бы непомерно дорогими с Claude Opus 4.6.
Практическая рекомендация для большинства команд разработчиков — рассмотреть мультимодельный подход. Используйте Claude Opus 4.6 (и конкретно Claude Code) для интерактивных сессий программирования, сложной отладки и задач, требующих агентного поведения. Резервируйте Grok 4 или Grok 4 Fast для пакетной обработки, математических вычислений и высоконагруженных задач анализа, где экономичность важнее пиковой производительности в программировании. Такой комбинированный подход позволяет использовать лучшие возможности каждой модели, эффективно управляя затратами.
Архитектура агентов — две разные философии
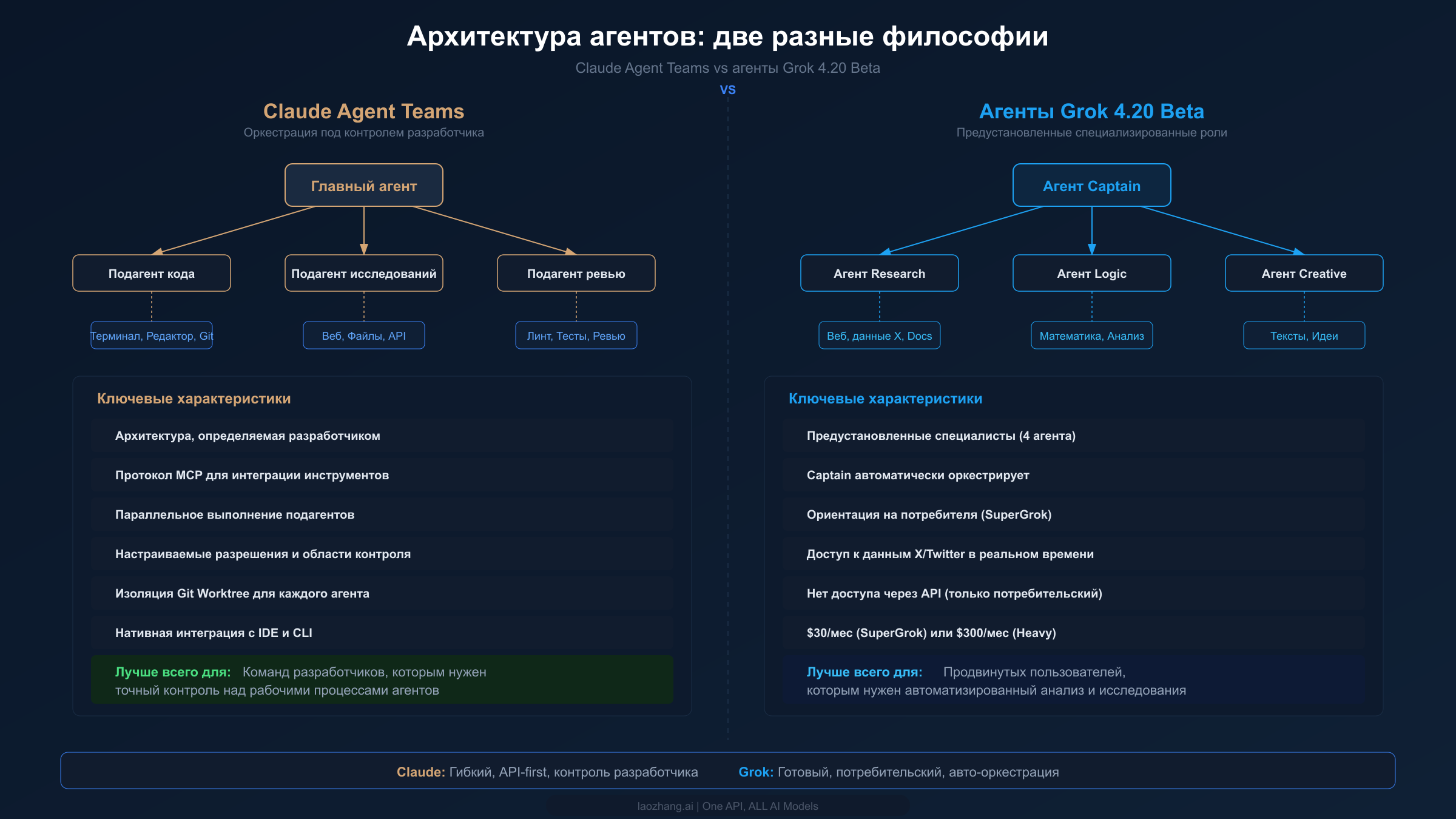
Наиболее перспективное сравнение Claude и Grok касается не результатов бенчмарков или цен, а того, как каждая компания представляет мультиагентные ИИ-системы. И Anthropic, и xAI выпустили мультиагентные возможности в начале 2026 года, но их подходы отражают принципиально разные философии относительно того, кто должен контролировать оркестрацию, как агенты взаимодействуют и какие задачи должны решать мультиагентные системы. Понимание этих архитектурных различий критически важно для каждого, кто планирует строить на этих платформах в долгосрочной перспективе.
Claude Agent Teams: оркестрация под контролем разработчика
Claude Agent Teams, запущенные как часть релиза Claude 4.6, следуют философии «сначала разработчик». Главный агент (или «лидер») может создавать подагентов с конкретными инструкциями, инструментами и областями разрешений. Разработчики определяют архитектуру — какие агенты существуют, к каким инструментам каждый имеет доступ и как они координируются. Система работает полностью через API, что означает полный программный контроль над каждым аспектом оркестрации. Подагенты могут работать параллельно, каждый в изолированном git worktree для предотвращения конфликтов, а главный агент синтезирует их результаты. Model Context Protocol (MCP) позволяет агентам интегрироваться с внешними инструментами — базами данных, API, файловыми системами и IDE — через стандартизированный интерфейс. Эта компонуемость означает, что разработчики могут построить именно тот мультиагентный рабочий процесс, который требует их сценарий использования — от простых конвейеров «код-ревью» с двумя агентами до сложных систем из пяти агентов, обрабатывающих разные аспекты крупного проекта.
Компромисс — в сложности. Построение эффективного рабочего процесса Agent Teams требует понимания паттернов оркестрации, определения чётких областей ответственности агентов, управления бюджетами токенов между параллельными агентами и обработки ошибок, когда подагенты дают противоречивые результаты. Это мощный инструмент, но он требует инвестиций от разработчика для эффективного использования. Отдача приходит в точности: хорошо спроектированные рабочие процессы Agent Teams могут значительно превзойти одномодельные взаимодействия на сложных задачах, потому что каждый агент может быть оптимизирован для своей конкретной роли с соответствующим контекстом и инструментами.
Агенты Grok 4.20 Beta: предустановленные специализированные роли
Подход Grok с 4.20 Beta ориентирован на потребителя. Вместо того чтобы требовать от разработчиков проектирования агентных архитектур, xAI предоставляет четырёх предустановленных специалистов-агентов — Captain, Research, Logic и Creative — которые автоматически координируются при решении сложных задач. Агент Captain служит оркестратором, распределяя подзадачи наиболее подходящему специалисту. Пользователям не нужно понимать мультиагентную архитектуру — они просто отправляют сложный запрос, и система самостоятельно обрабатывает декомпозицию и координацию. Этот подход согласуется с потребительской платформой SuperGrok от xAI, где цель — сделать продвинутые возможности ИИ доступными без технической экспертизы. Агент Research имеет прямой доступ к данным X/Twitter, обеспечивая возможности работы с информацией в реальном времени, которых нативно нет у агентов Claude. Агент Logic обрабатывает математические и аналитические задачи, используя сильные математические показатели Grok 4. Агент Creative фокусируется на генерации контента и идеях.
Компромисс — в гибкости. Вы не можете настраивать, какие агенты участвуют, определять новые специализированные роли или контролировать логику оркестрации. Система хорошо работает для универсальных сложных задач, но ей недостаёт точности, которая нужна разработчикам для специализированных рабочих процессов. И что критично — пока нет доступа через API: агенты Grok 4.20 Beta доступны только через потребительский интерфейс SuperGrok, что ограничивает их полезность для производственных приложений.
Какая архитектура побеждает?
Для разработчиков и инженерных команд Claude Agent Teams — очевидный победитель в 2026 году: система доступна через API, предлагает полную настройку и интегрируется с существующими инструментами разработки через MCP. Для продвинутых пользователей и исследователей, которым нужны мультиагентные возможности без написания кода, Grok 4.20 Beta предоставляет доступную, хотя и менее гибкую альтернативу. Настоящий вопрос — выпустит ли xAI доступ через API для своей мультиагентной системы, что сделает это сравнение значительно более конкурентным. До тех пор любая команда, которой нужны программные мультиагентные рабочие процессы, имеет только один вариант — Claude.
Анализ траекторий обеих компаний показывает важные сигналы для долгосрочного планирования. Anthropic систематически расширяла экосистему разработчика Claude — от первоначального API к Claude Code, затем к Agent Teams и интеграциям MCP — каждый слой строится на предыдущем. Это говорит о продолжающихся инвестициях в инструменты для разработчиков, которые делают Claude всё более привязанным к инженерным рабочим процессам. Траектория xAI более ориентирована на потребителя: SuperGrok и агентная система 4.20 Beta отдают приоритет доступности, а не программируемости. Ни одна траектория не является изначально лучшей, но они обслуживают разные аудитории. Если вы строите продукты, зависящие от возможностей ИИ-агентов, подход Claude «сначала разработчик» предлагает больше стабильности и компонуемости. Если вы создаёте потребительские ИИ-продукты, предустановленная агентная система Grok обеспечивает более быстрый выход на результат без пользовательской инженерии.
Какую модель выбрать?
Правильный выбор между Claude Opus 4.6 и Grok 4 зависит не столько от того, какая модель «лучше» в абсолютном выражении, сколько от того, какая модель лучше подходит для вашего конкретного сценария использования, бюджета и технических требований. На основе нашего всестороннего анализа бенчмарков, цен, возможностей программирования и архитектуры — вот шесть рекомендаций на основе сценариев, которые помогут вам принять уверенное решение.
Сценарий 1: Команда разработчиков ПО (5-20 разработчиков). Выбирайте Claude Opus 4.6. Сочетание превосходного результата SWE-bench (81,4%), Claude Code для агентного программирования, Agent Teams для параллельных рабочих процессов и качественных интеграций с IDE создаёт экосистему, созданную специально для профессиональной разработки ПО. Более высокая стоимость API ($5/$25 против $3/$15) компенсируется приростом производительности — исправление одного дополнительного бага в день, с которым Grok не справился бы, легко покрывает разницу в стоимости. Совет по экономии: используйте Claude Sonnet 4.6 ($3/$15) для рутинных задач и резервируйте Opus для сложного рассуждения.
Сценарий 2: Стартап с ограниченным бюджетом или индивидуальный разработчик. Выбирайте Grok 4 Fast ($0,20/$0,50). Будучи в 25 раз дешевле Claude Opus 4.6, Grok 4 Fast предоставляет возможности, близкие к передовым, за малую долю стоимости. Контекстное окно в 2 млн токенов — бонус для обработки больших кодовых баз. Для 10-20% задач, требующих максимальных возможностей, рассмотрите точечное использование Claude Opus 4.6 или стандартного Grok 4 вместо оплаты премиум-уровня для каждого запроса.
Сценарий 3: Наука о данных и математический анализ. Выбирайте Grok 4. Его 92,7% по Индексу математики и 87,5% по GPQA указывают на более сильную производительность в задачах математического рассуждения и научных знаний. Постоянно включённый режим рассуждения, хотя и добавляет задержку, обеспечивает глубокую аналитическую строгость при каждом запросе. Для команд, активно занимающихся статистическим анализом, обучением моделей или научными вычислениями, математическое преимущество Grok транслируется в ощутимые улучшения качества.
Сценарий 4: Предприятие с потребностями в мультиагентных рабочих процессах. Выбирайте Claude Opus 4.6 с Agent Teams. По состоянию на март 2026 года Claude — единственный вариант с мультиагентной оркестрацией, доступной через API. Если в дорожную карту вашего предприятия входит построение автономных рабочих процессов, автоматизированных конвейеров код-ревью или сложных многоэтапных систем анализа, Agent Teams Claude предоставляет программируемую основу, которая вам нужна. Мультиагентная система Grok 4.20 Beta остаётся доступной только для потребителей.
Сценарий 5: Приложения реального времени и чат-боты. Выбирайте Claude Opus 4.6. Двукратное преимущество в скорости (~80 ток/с против 40,6 ток/с) и значительно более быстрый TTFT (~1,5с против 10,79с) делают Claude единственным жизнеспособным вариантом для приложений, где задержка ответа имеет значение. 10-секундное ожидание первого токена неприемлемо в большинстве интерактивных сценариев.
Сценарий 6: Высоконагруженная обработка при ограниченном бюджете. Выбирайте смешанный подход с Grok 4 Fast в качестве основной модели. Направляйте 80% запросов через Grok 4 Fast ($0,20/$0,50), эскалируйте сложные задачи до стандартного Grok 4 ($3/$15) и используйте Claude Opus 4.6 только для задач, требующих максимальных возможностей программирования или рассуждения. Такой многоуровневый подход может снизить затраты на 85-95% по сравнению с использованием исключительно Claude Opus, сохраняя высокое качество для задач, которые действительно важны.
Общая нить всех шести сценариев — лучшая стратегия редко заключается в «использовании одной модели для всего». Ландшафт передового ИИ в 2026 году вознаграждает интеллектуальную маршрутизацию — сопоставление возможностей и стоимости модели с конкретными требованиями задач. Даже в рамках одного продукта вы можете использовать Claude для пользовательской помощи в программировании, а Grok 4 Fast — для фоновой обработки документов и извлечения данных. Дни исключительной привязки к одному провайдеру ИИ прошли; конкурентное преимущество получают команды, использующие правильную модель для каждой задачи. Реализация этой мультимодельной стратегии требует дополнительных инженерных усилий для логики маршрутизации моделей и управления несколькими API, но экономия затрат и улучшение качества оправдывают эти инвестиции для любой команды, совершающей более нескольких сотен вызовов API в день.
Начало работы и оптимизация затрат
Обе модели — Claude и Grok — предлагают простой доступ к API, но оптимизация реализации для максимальной экономичности и производительности требует понимания специфических возможностей каждой платформы. Вот практическое руководство по началу работы с каждой моделью и максимальной отдаче от вашего бюджета на API.
Начало работы с Claude Opus 4.6 требует ключа API Anthropic от console.anthropic.com. API следует стандартному паттерну REST с доступными SDK для Python и TypeScript. Процесс настройки прост: создайте аккаунт, сгенерируйте ключ API и сделайте первый запрос за считанные минуты. Включайте расширенное мышление только для задач, требующих глубокого рассуждения — активация по умолчанию увеличивает затраты без пропорционального прироста качества для более простых задач. Используйте кэширование промптов, включая блок cache_control в системных промптах для снижения стоимости входных токенов при повторяющихся вызовах. Для рабочих процессов программирования установите Claude Code (npm install -g @anthropic-ai/claude-code), чтобы получить полный агентный опыт разработки без написания пользовательских API-интеграций. Claude Code поддерживает прямой доступ к терминалу, редактирование файлов, операции git и мультиагентную оркестрацию прямо из командной строки, что делает его самым быстрым путём от «у меня есть ключ API» до «у меня есть рабочий процесс разработки на базе ИИ».
Начало работы с Grok 4 требует ключа API xAI от console.x.ai. API совместим с OpenAI, что делает миграцию простой для команд, уже использующих формат SDK OpenAI. Активно используйте кэшированные входные токены Grok 4 ($0,75/М против стандартных $3,00/М) — любой системный промпт или справочный документ, повторно используемый в вызовах, должен кэшироваться. Для чувствительных к бюджету приложений начните с Grok 4 Fast и эскалируйте до стандартного Grok 4 только когда сложность задачи этого требует. Контекстное окно в 2 млн токенов у вариантов Fast означает, что вам редко понадобится полный Grok 4 для задач обработки документов.
Стратегии оптимизации затрат, работающие с обеими моделями, включают реализацию интеллектуальной маршрутизации, анализирующей сложность задачи перед выбором уровня модели, группировку однотипных запросов для максимального использования кэша и установку лимитов бюджета токенов на запрос для предотвращения неконтролируемых затрат на задачи с чрезмерным объёмом вывода. Хорошо спроектированная система маршрутизации может использовать лёгкий классификатор (или даже эвристику на основе правил) для определения того, нужны ли каждому входящему запросу возможности передового уровня или достаточно бюджетной модели. Эта единственная оптимизация может снизить общие расходы на API на 50-70% для большинства приложений.
Для более широкого взгляда на то, как эти модели сравниваются с другими передовыми вариантами, включая GPT-4o и Gemini, смотрите наше всестороннее сравнение API ИИ-моделей. Ландшафт ИИ-моделей в 2026 году вознаграждает гибкость — команды, показывающие лучшие результаты, сопоставляют модели с задачами, а не привязываются исключительно к одному провайдеру. И Claude Opus 4.6, и Grok 4 — отличные модели, и оптимальная стратегия для большинства организаций — использовать обе там, где каждая из них сильна.
Часто задаваемые вопросы
Claude Opus 4.6 лучше, чем Grok 4?
Claude Opus 4.6 превосходит Grok 4 в тестах программирования (81,4% против ~72% SWE-bench), задачах рассуждения (68,8% против 15,9% ARC-AGI-2) и скорости ответа (~80 против 40,6 токенов/секунду). Однако Grok 4 лидирует в математическом рассуждении (92,7% Индекс математики) и задачах на знания (87,5% GPQA), при этом стоит на 40% дешевле. Ни одна модель не является универсально «лучшей» — правильный выбор зависит от того, является ли ваш основной сценарий программированием/рассуждением (Claude) или математикой/знаниями при меньшей стоимости (Grok).
Насколько дешевле Grok 4 по сравнению с Claude Opus 4.6?
Цена API Grok 4 составляет $3/$15 за миллион токенов по сравнению с $5/$25 у Claude, что делает его на 40% дешевле по входным и выходным токенам. Бюджетные варианты Grok 4 Fast по $0,20/$0,50 за миллион токенов в 25 раз дешевле Claude Opus 4.6, что делает их одними из самых доступных моделей, близких к передовому уровню. Grok также предлагает кэшированные входные токены по $0,75 за миллион.
Можно ли использовать и Claude, и Grok через один API?
Да.
Что такое Grok 4.20 Beta и как он сравнивается с Claude Agent Teams?
Grok 4.20 Beta — это потребительская мультиагентная система xAI с четырьмя специализированными агентами (Captain, Research, Logic, Creative), доступная через SuperGrok ($30/мес). Claude Agent Teams — это ориентированный на разработчиков мультиагентный фреймворк Anthropic, доступный через API. Ключевое различие: система Claude предлагает полный программный контроль и настройку, тогда как система Grok — предустановленная и доступна только для потребителей, без доступа через API.
Какая модель быстрее для производственных приложений?
Claude Opus 4.6 значительно быстрее: примерно 80 токенов/сек против 40,6 у Grok 4, со временем до первого токена ~1,5 секунды против 10,79 секунды у Grok 4. Для интерактивных приложений и чат-ботов преимущество Claude в скорости является решающим. Более высокая задержка Grok 4 обусловлена постоянно включённым режимом рассуждения, который обрабатывает каждый запрос через глубокое рассуждение вне зависимости от сложности.