
Claude Opus 4 и Sonnet 4 отличаются прежде всего производительностью, ценой и сценариями использования. Opus 4.5 (февраль 2026) стоит $5/$25 за миллион токенов — значительное снижение на 67% с первоначальных $15/$75 — тогда как Sonnet 4.5 сохраняет цену $3/$15. Для большинства разработчиков Sonnet 4.5 предлагает лучший баланс скорости (54,84 токена/сек против 38,93 у Opus), стоимости и возможностей, в то время как Opus 4.5 превосходит в сложных задачах, требующих продолжительного рассуждения на протяжении часов.
Краткое содержание
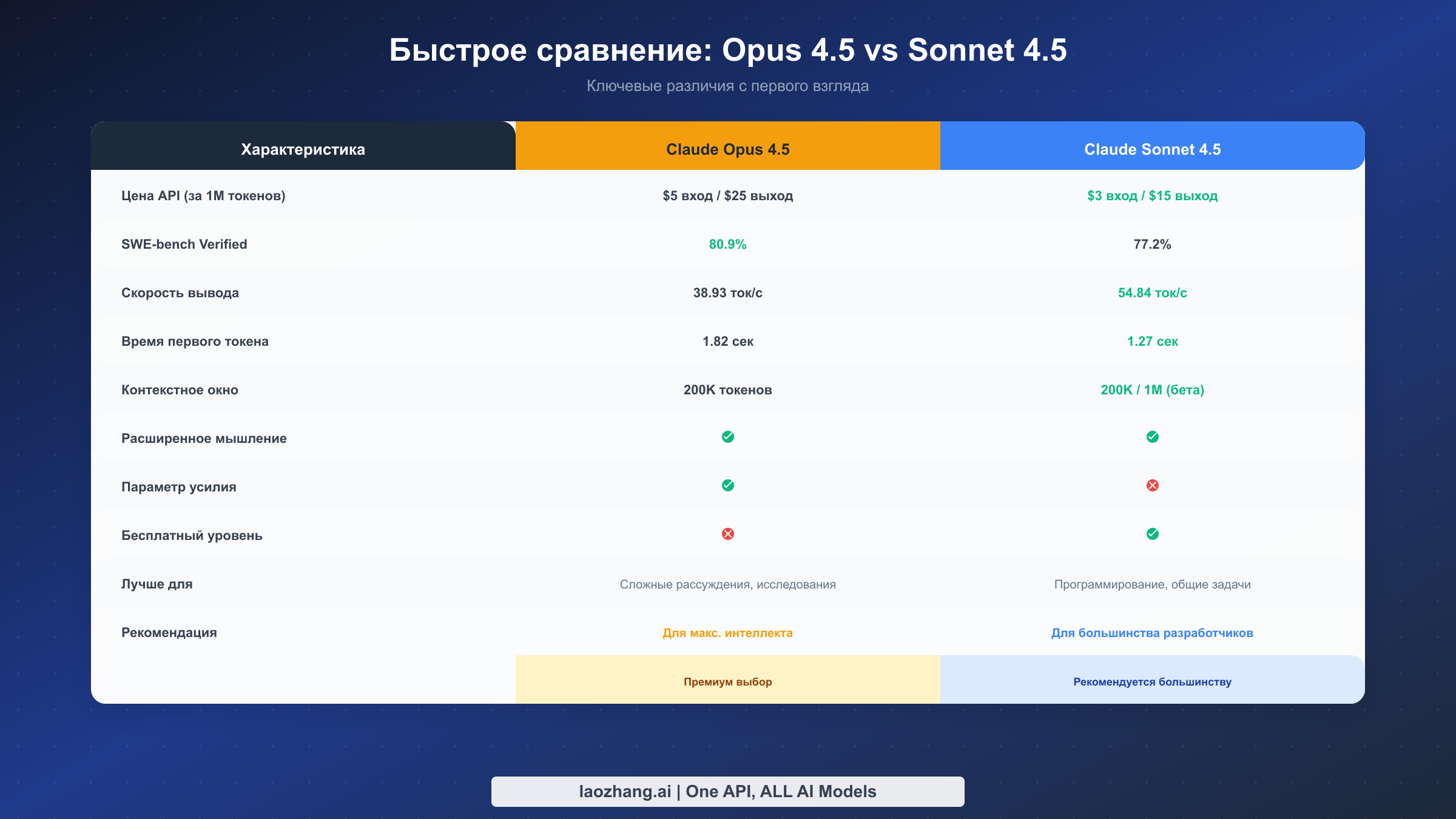
Выбор между Claude Opus 4.5 и Sonnet 4.5 сводится к трём факторам: насколько сложны ваши задачи, сколько вы готовы потратить и насколько быстрые ответы вам нужны. Таблица выше отражает ключевые различия, но понимание того, что эти цифры означают на практике, требует более глубокого контекста.
Opus 4.5 представляет собой флагманскую модель Anthropic, разработанную для длительной автономной работы и сложных многошаговых рассуждений. Когда Anthropic говорит о «многочасовых агентных задачах», они имеют в виду именно Opus — это модель, которая обеспечивает самые сложные функции Claude Code и обрабатывает исследовательские задачи, требующие устойчивого внимания на протяжении тысяч строк кода или документов. Показатель 80,9% на SWE-bench Verified отражает её способность решать реальные проблемы GitHub с минимальным вмешательством человека.
Sonnet 4.5, напротив, оптимизирован для 90% случаев использования, когда вам нужна способная помощь ИИ без премиальной цены. Его показатель 77,2% на SWE-bench отстаёт от Opus всего на 3,7 процентных пункта, но экономия 40% на затратах и улучшение скорости на 41% делают его практичным выбором для большинства рабочих процессов разработки. Бесплатный доступ через claude.ai делает его доступным для экспериментов и личных проектов.
| Характеристика | Opus 4.5 | Sonnet 4.5 | Победитель |
|---|---|---|---|
| Цена входных токенов | $5/М токенов | $3/М токенов | Sonnet |
| Цена выходных токенов | $25/М токенов | $15/М токенов | Sonnet |
| SWE-bench Verified | 80,9% | 77,2% | Opus |
| Скорость вывода | 38,93 ток/с | 54,84 ток/с | Sonnet |
| Время первого токена | 1,82 с | 1,27 с | Sonnet |
| Контекстное окно | 200K | 200K (1M бета) | Sonnet |
| Расширенное мышление | Да | Да | Ничья |
| Бесплатный уровень | Нет | Да | Sonnet |
| Лучше для | Сложные рассуждения | Общие задачи | Зависит |
Практическая рекомендация проста: начните с Sonnet 4.5. Если вы обнаружите, что достигаете его пределов — задачи, требующие расширенного рассуждения, рефакторинг множества файлов или автономная агентная работа — тогда переходите на Opus. Большинство разработчиков никогда не нуждаются в этом переключении.
Разбор цен на модели
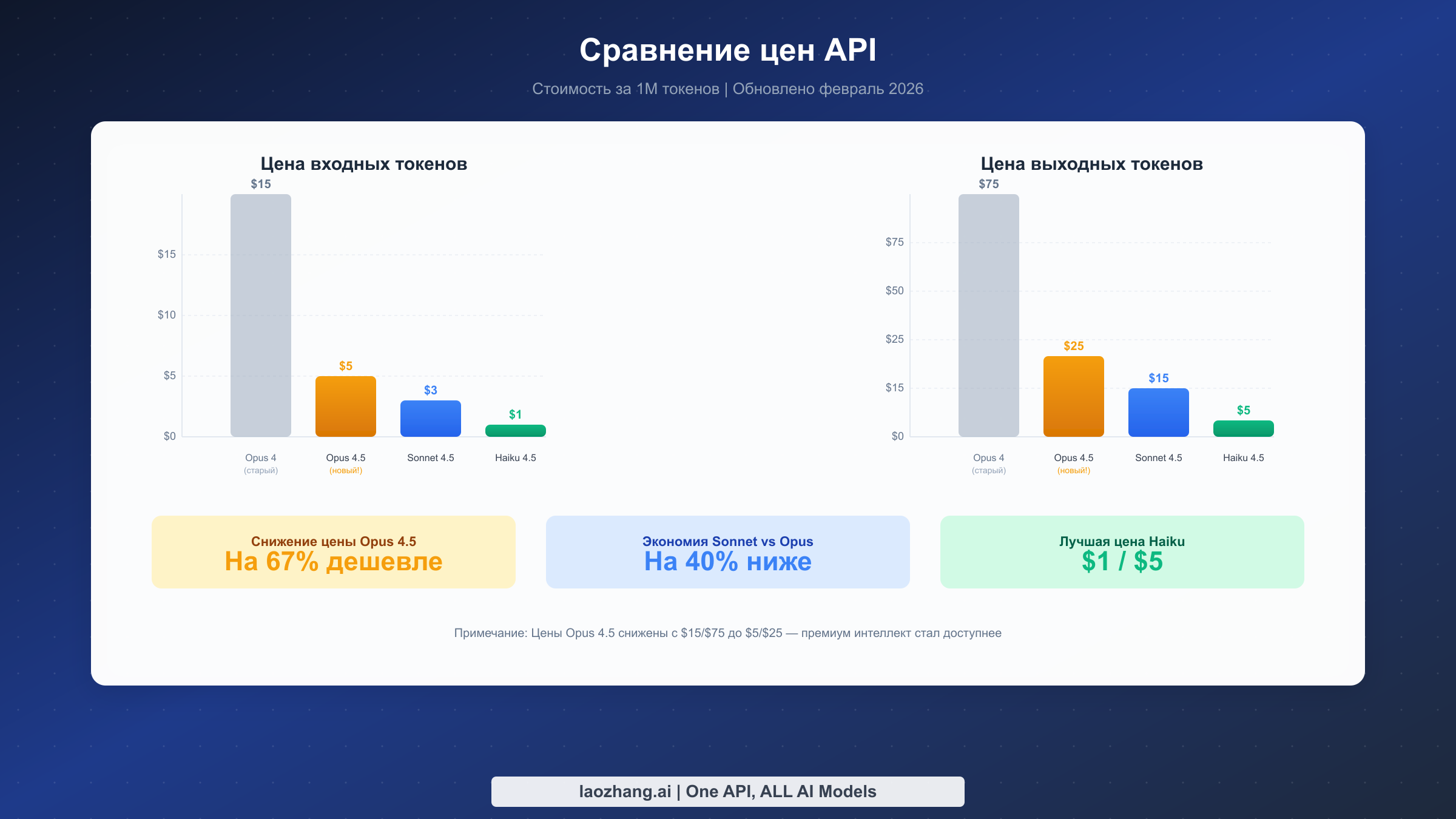
Ценовой ландшафт февраля 2026 года для моделей Claude представляет значительный сдвиг от первоначальной стратегии ценообразования Anthropic. Наиболее примечательно то, что Opus 4.5 получил драматическое снижение цены на 67%, сделав премиальные возможности ИИ доступными гораздо более широкой аудитории. Этот раздел подробно разбирает, сколько вы будете платить в различных сценариях использования.
Главное изменение — новая цена Opus 4.5: $5 за миллион входных токенов и $25 за миллион выходных токенов. Сравните это с первоначальной ценой Opus 4 в $15/$75, и вы увидите существенную экономию для пользователей с большими объёмами. Для типичной сессии программирования, обрабатывающей 100 000 токенов контекста и генерирующей 50 000 токенов вывода, стоимость упала с $5,25 до $1,75 — снижение на 67%, которое фундаментально меняет экономику использования самой мощной модели Anthropic.
Sonnet 4.5 сохраняет позицию лидера по соотношению цена-качество с $3 за миллион входных токенов и $15 за миллион выходных токенов. Хотя эти цены не изменились с момента запуска, сама модель получила улучшения возможностей, делающие её всё более конкурентоспособной с Opus для повседневных задач. Разница в стоимости 40% между Sonnet и Opus значительна в масштабе: разработчик, обрабатывающий 10 миллионов токенов ежемесячно, экономит $200, выбирая Sonnet вместо Opus.
Уровни подписки и их ценность
Anthropic предлагает три уровня подписки для claude.ai с различными уровнями доступа:
Бесплатный уровень предоставляет доступ к Sonnet 4.5 с ограничениями использования, подходящими для случайного изучения и личных проектов. При интенсивном использовании вы столкнётесь с ограничениями скорости, но для обучения и экспериментов он действительно полезен. Opus 4.5 недоступен на бесплатном уровне — это один из ключевых дифференцирующих факторов, подталкивающих опытных пользователей к платным планам.
Claude Pro за $20 в месяц разблокирует более высокие ограничения скорости и приоритетный доступ в пиковое время. Вы получаете доступ как к Sonnet 4.5, так и к Opus 4.5 через веб-интерфейс, хотя доступ к API требует отдельной оплаты. Для разработчиков, которые в основном работают через claude.ai, а не API, это представляет отличную ценность — особенно если вам иногда нужен Opus для сложных задач.
Claude Max за $100+ в месяц ориентирован на корпоративных пользователей, которым нужна гарантированная доступность и максимальные ограничения скорости. На этом уровне вы по существу платите за доступ с SLA-гарантиями и поддержку, а не за различия в базовых возможностях.
Примеры расчёта стоимости
Понимание реальных затрат требует контекста о том, как токены преобразуются в фактическую работу:
Типичная сессия проверки кода может обработать 50 000 входных токенов (проверяемый код плюс контекст) и сгенерировать 10 000 выходных токенов (комментарии и предложения по ревью). С Sonnet 4.5 это стоит $0,30. С Opus 4.5 та же сессия стоит $0,50. За 100 таких сессий в месяц разница составляет $20 — не пустяк, но и не запретительно.
Для автономных агентов программирования, работающих длительное время, расчёт меняется. 4-часовая сессия Opus, обрабатывающая 2 миллиона токенов контекста и генерирующая 500 000 токенов вывода, будет стоить примерно $22,50. Та же задача с Sonnet обойдётся в $13,50, но может потребовать больше человеческого вмешательства или дать результаты более низкого качества для действительно сложных задач рассуждения.
Объяснение бенчмарков производительности
Бенчмарки производительности для больших языковых моделей могут казаться «алфавитным супом» — SWE-bench, AIME, GPQA, MMLU — но каждый измеряет что-то конкретное и значимое. Понимание того, что эти цифры на самом деле представляют, помогает вам принимать обоснованные решения, а не просто гнаться за самым высоким баллом.
SWE-bench Verified стал золотым стандартом для оценки способности программирования в реальных условиях. Бенчмарк представляет моделям реальные проблемы GitHub из популярных проектов с открытым исходным кодом и измеряет, могут ли они создать патчи, которые пройдут тестовый набор проекта. Показатель Opus 4.5 в 80,9% означает, что он успешно решает около 4 из 5 проблем, которые пытается решить — замечательное достижение, учитывая, что это реальные баги, которые достаточно озадачили разработчиков-людей, чтобы они создали issue. Показатель Sonnet 4.5 в 77,2% ставит его в тот же уровень, лишь немного позади.
Практическая разница между 80,9% и 77,2% тонкая. Для простых исправлений багов и реализации функций обе модели работают сопоставимо. Opus выигрывает при рефакторинге множества файлов, понимании сложных архитектур проектов и поддержании согласованности в течение длительных сессий программирования. Если вы просите модель вносить изменения, охватывающие 10+ файлов с сложными зависимостями, эти 3,7 процентных пункта разрыва становятся более заметными.
Бенчмарки математики и рассуждений
Задачи AIME (American Invitational Mathematics Examination) тестируют сложное математическое рассуждение. Сильная производительность Opus 4.5 здесь отражает его способность связывать логические шаги в сложных задачах — ту же способность, которая делает его эффективным для задач расширенного рассуждения в нематематических областях.
GPQA Diamond фокусируется на вопросах естественных наук уровня аспирантуры, требующих экспертных знаний. Высокие баллы указывают на то, что модель может рассуждать о специализированном техническом контенте, а не просто воспроизводить факты. Это важно для разработчиков, работающих в научных вычислениях, биоинформатике или других областях, требующих глубокого технического понимания.
MMLU (Massive Multitask Language Understanding) охватывает 57 предметов от элементарной математики до профессионального права. Хотя полезен как общий индикатор способностей, он менее предсказуем для производительности программирования, чем SWE-bench. Модель может превосходить в MMLU, но всё ещё испытывать трудности с практическими задачами разработки программного обеспечения.
Важные метрики скорости
Два показателя скорости заслуживают внимания: Время до первого токена (TTFT) и пропускная способность (токены в секунду).
TTFT измеряет задержку до появления первого ответа. 1,27 секунды у Sonnet 4.5 против 1,82 секунды у Opus 4.5 могут показаться незначительными, но в интерактивных средах разработки эти полсекунды накапливаются. Когда вы быстро итерируете промпты или используете помощь ИИ в вашей IDE, более быстрый TTFT создаёт более отзывчивый опыт.
Пропускная способность влияет на то, как быстро вы получаете полные ответы. 54,84 токена в секунду у Sonnet против 38,93 у Opus означает, что Sonnet завершает ответ в 1000 токенов примерно за 18 секунд, тогда как Opus занимает 26 секунд. Для генерации длинного контента или подробных объяснений кода это преимущество в скорости 41% делает Sonnet заметно более быстрым.
Возможности контекстного окна
Обе модели поддерживают контекстные окна в 200 000 токенов — достаточно для обработки целых кодовых баз, длинных документов или расширенных историй разговоров. Sonnet 4.5 дополнительно предлагает бета-версию контекстного окна в 1 миллион токенов, полезную для обработки чрезвычайно больших документов или поддержания более длинных историй разговоров.
На практике большинство взаимодействий остаются значительно ниже 100 000 токенов. Большие контекстные окна важнее всего для специализированных случаев: анализа целых репозиториев, обработки документов размером с книгу или поддержания контекста в многодневных сессиях автономных агентов.
Лимит выходных токенов в 16 384 токена (с расширенным выводом 64 000+ для Opus с расширенным мышлением) определяет максимальную длину одного ответа. Для большинства задач программирования этого более чем достаточно. Режим расширенного мышления, доступный на обеих моделях, позволяет более длинные цепочки рассуждений, когда сложные задачи их требуют.
Claude 4 против 4.5 — Какую версию выбрать
Нумерация версий моделей Claude создаёт реальную путаницу. Opus 4, Opus 4.5, Sonnet 4, Sonnet 4.5 — какую использовать и когда? Этот раздел проясняет различие и даёт конкретные рекомендации для правильного выбора.
Фундаментальное различие простое: версии 4.5 представляют текущее состояние искусства, тогда как версии 4.0 — это старые снимки с другими компромиссами цена-производительность. Anthropic постепенно улучшал модели 4.5 с момента их первоначального выпуска, включая отзывы и расширенные возможности. Версии 4.0 существуют в основном для обратной совместимости и оптимизации затрат в конкретных сценариях.
Когда версии 4.0 имеют смысл
Claude Sonnet 4 (не 4.5) всё ещё может быть доступен по сниженным ценам для определённых случаев использования. Если ваше приложение было протестировано и проверено с конкретной версией модели, переход на 4.5 вносит риск изменений в поведении — пусть и незначительных. Производственные системы со строгими требованиями к регрессионному тестированию иногда предпочитают стабильность версии инкрементальным улучшениям возможностей.
Однако для новых проектов редко есть причина начинать с 4.0. Улучшения возможностей в версиях 4.5 не приходят с значительным увеличением стоимости для Sonnet, а цена Opus 4.5 на самом деле ниже, чем была у Opus 4 при запуске. Если у вас нет конкретных требований обратной совместимости, выбирайте по умолчанию 4.5.
Важные различия в возможностях
Sonnet 4.5 представил несколько улучшений по сравнению с Sonnet 4:
Поддержка расширенного мышления позволяет модели рассуждать через сложные проблемы шаг за шагом, показывая свою работу и обнаруживая ошибки до фиксации окончательных ответов. Эта возможность, ранее эксклюзивная для Opus, значительно улучшает производительность в многошаговых задачах рассуждения.
Улучшенное следование инструкциям означает, что Sonnet 4.5 более надёжно придерживается указанных форматов вывода, стилей программирования и поведенческих ограничений. Разработчики, которые боролись с более ранними моделями, игнорирующими конкретные инструкции, часто находят 4.5 более послушным.
Лучшая генерация кода отражает улучшенное обучение на задачах программирования. Разрыв между Sonnet и Opus сократился с 4.5, делая Sonnet всё более жизнеспособным для сложной работы по разработке.
Opus 4.5 также улучшился по сравнению с Opus 4, но самым значительным изменением было снижение цены. Основная способность модели — устойчивое автономное рассуждение в течение длительных периодов — уже была сильной. Обновление 4.5 скорее уточнило, чем революционизировало его возможности.
Рекомендации по миграции
Для существующих пользователей Sonnet 4: мигрируйте на 4.5, если у вас нет проверенного поведения, которое вы не можете рисковать изменить. Улучшения возможностей значительны, а цена остаётся постоянной.
Для существующих пользователей Opus 4: мигрируйте на 4.5 немедленно. Оставаясь на 4.0, вы платите больше за меньшие возможности.
Для новых проектов: начните с Sonnet 4.5. Переходите на Opus 4.5 только если вы столкнётесь с конкретными задачами, где производительности Sonnet недостаточно. Большинство разработчиков обнаруживают, что Sonnet 4.5 эффективно справляется с их потребностями, что делает экономию затрат оправданной.
| Аспект | Версии 4.0 | Версии 4.5 |
|---|---|---|
| Текущий статус | Устаревшие | Активная разработка |
| Расширенное мышление | Только Opus | Обе модели |
| Следование инструкциям | Хорошо | Улучшено |
| Цены | Похожи (Opus ниже) | Текущие тарифы |
| Рекомендация | Только существующие системы | Все новые проекты |
Руководство по интеграции API
Интеграция моделей Claude в ваше приложение требует понимания процесса аутентификации, структуры запросов и шаблонов обработки ошибок. Этот раздел предоставляет рабочие примеры кода на Python и Node.js, которые вы можете адаптировать к вашим конкретным потребностям.
Интеграция с Python
Пакет anthropic для Python предоставляет наиболее чистый путь интеграции. Установите его через pip и настройте ваш API-ключ:
pythonimport anthropic import os client = anthropic.Anthropic( api_key=os.environ.get("ANTHROPIC_API_KEY") ) # Базовый запрос завершения def get_completion(prompt: str, model: str = "claude-sonnet-4-5-20250929") -> str: """ Получить завершение от Claude. Аргументы: prompt: Сообщение пользователя model: ID модели (claude-opus-4-5-20251101 или claude-sonnet-4-5-20250929) Возвращает: Текст ответа модели """ message = client.messages.create( model=model, max_tokens=4096, messages=[ {"role": "user", "content": prompt} ] ) return message.content[0].text # Потоковая передача для ответов в реальном времени def get_streaming_completion(prompt: str, model: str = "claude-sonnet-4-5-20250929"): """Потоковое завершение для отображения в реальном времени.""" with client.messages.stream( model=model, max_tokens=4096, messages=[{"role": "user", "content": prompt}] ) as stream: for text in stream.text_stream: print(text, end="", flush=True)
ID моделей следуют шаблону claude-{модель}-{версия}-{дата}. Используйте claude-opus-4-5-20251101 для Opus 4.5 и claude-sonnet-4-5-20250929 для Sonnet 4.5.
Интеграция с Node.js
Для проектов JavaScript/TypeScript пакет @anthropic-ai/sdk предоставляет эквивалентную функциональность:
javascriptimport Anthropic from "@anthropic-ai/sdk"; const client = new Anthropic({ apiKey: process.env.ANTHROPIC_API_KEY, }); async function getCompletion(prompt, model = "claude-sonnet-4-5-20250929") { const message = await client.messages.create({ model: model, max_tokens: 4096, messages: [{ role: "user", content: prompt }], }); return message.content[0].text; } // Пример потоковой передачи async function streamCompletion(prompt, model = "claude-sonnet-4-5-20250929") { const stream = await client.messages.stream({ model: model, max_tokens: 4096, messages: [{ role: "user", content: prompt }], }); for await (const event of stream) { if (event.type === "content_block_delta" && event.delta.type === "text_delta") { process.stdout.write(event.delta.text); } } }
Лучшие практики обработки ошибок
API Claude может возвращать несколько типов ошибок, требующих разных стратегий обработки. Правильная обработка ошибок предотвращает каскадные сбои и предоставляет содержательную обратную связь пользователям.
Ограничение скорости (HTTP 429) происходит, когда вы превышаете лимиты запросов вашего уровня API. Реализуйте экспоненциальный откат с добавлением случайности для их корректной обработки. Для информации об управлении лимитами скорости для AI API понимание общих шаблонов помогает работать с разными провайдерами.
pythonimport time import random def retry_with_backoff(func, max_retries=5): """Повторить функцию с экспоненциальным откатом.""" for attempt in range(max_retries): try: return func() except anthropic.RateLimitError: if attempt == max_retries - 1: raise wait_time = (2 ** attempt) + random.uniform(0, 1) time.sleep(wait_time)
Ошибки длины контекста возникают, когда ваш ввод превышает контекстное окно модели. Отслеживайте использование токенов и реализуйте стратегии обрезки для больших входных данных. Библиотека tiktoken предоставляет точный подсчёт токенов для планирования.
Ошибки аутентификации указывают на проблемы с API-ключом — проверьте, что ваш ключ правильно установлен в переменных окружения и не истёк. Никогда не жёстко кодируйте API-ключи в исходном коде.
Когда выбирать Opus против Sonnet
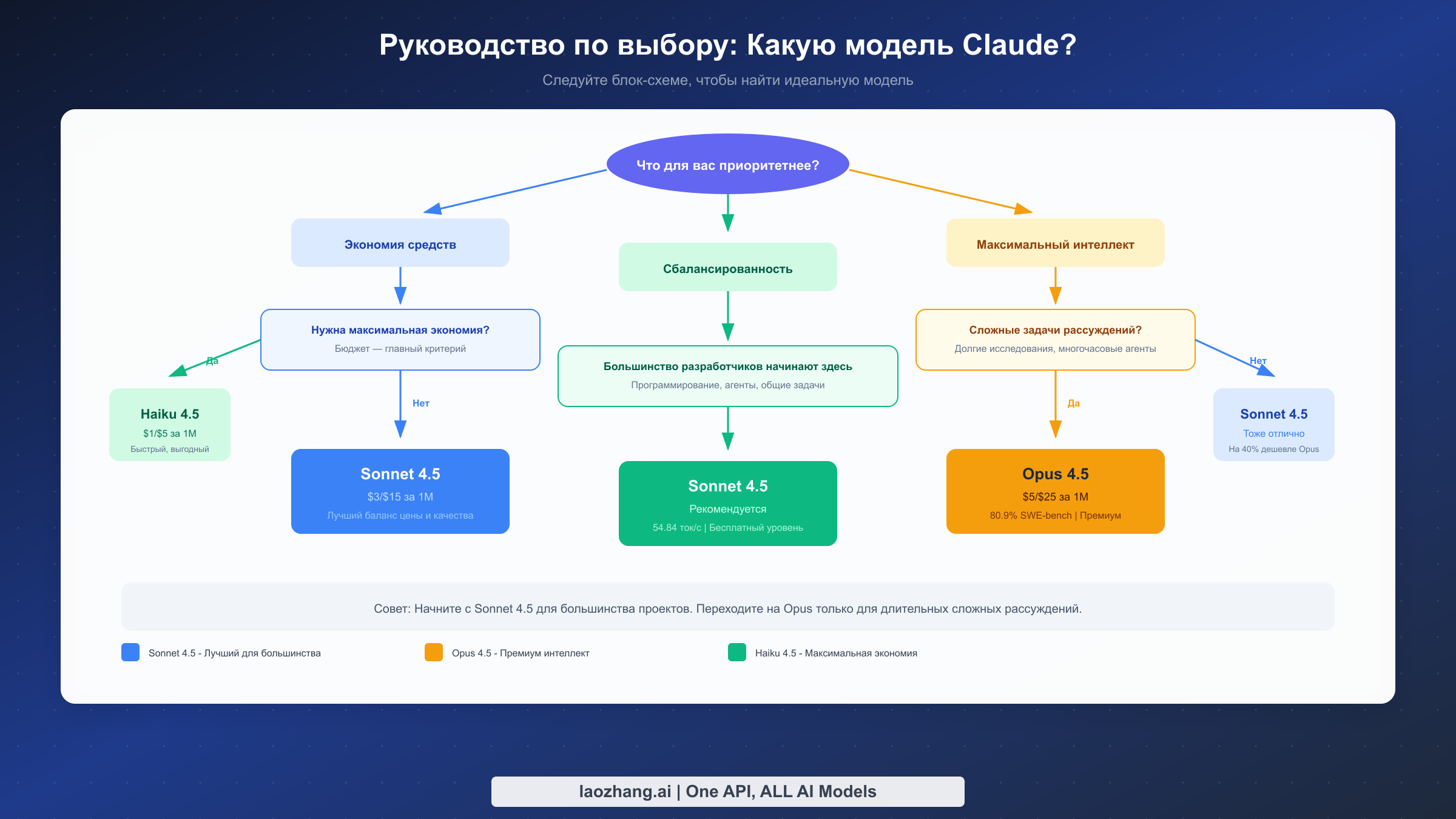
Решение между Opus и Sonnet — это не вопрос о том, какая модель «лучше» — это о соответствии возможностей требованиям. Эта структура помогает вам принять решение на основе вашей конкретной ситуации, а не абстрактных бенчмарков.
Выбирайте Opus 4.5, когда:
Ваши задачи требуют устойчивого рассуждения в течение длительных периодов. Многочасовые сессии автономных агентов, комплексный рефакторинг кодовой базы или исследовательские задачи, которым нужно поддерживать контекст и согласованность через множество файлов — это территория Opus. Архитектура модели специально оптимизирована для этих расширенных операций.
Потолок качества важнее экономической эффективности. Если вы создаёте продукт, где контент, генерируемый ИИ, напрямую достигает конечных пользователей, и различия в качестве сразу видны, немного более высокие баллы бенчмарков Opus могут оправдать премию. Подготовка юридических документов, обобщение медицинской информации и финансовый анализ часто попадают в эту категорию.
Вы раздвигаете границы того, что может делать современный ИИ. Экспериментальные приложения, новые проблемные области и задачи, которые часто терпят неудачу с другими моделями — Opus даёт вам лучший шанс на успех, даже если это стоит больше за попытку.
Ваш объём достаточно мал, чтобы разница в стоимости была незначительной. Если вы обрабатываете менее миллиона токенов в месяц, долларовая разница между Opus и Sonnet минимальна. В этом масштабе выбор Opus по умолчанию гарантирует, что вы никогда не будете ограничены возможностями модели.
Выбирайте Sonnet 4.5, когда:
Вы создаёте приложения, которые нужно масштабировать. Экономия 40% между Sonnet и Opus быстро накапливается в масштабе. Приложение с миллионом токенов в день экономит $6 000 ежегодно, используя Sonnet вместо Opus.
Скорость важна для пользовательского опыта. Более быстрый TTFT и более высокая пропускная способность Sonnet создают более отзывчивые приложения. Интерактивные помощники по программированию, чат-боты и инструменты анализа в реальном времени выигрывают от более быстрого отклика.
Ваши задачи хорошо определены с чёткими критериями успеха. Стандартная генерация кода, документация, помощь в отладке и обработка структурированных данных — Sonnet справляется с ними компетентно. Небольшой разрыв в качестве по сравнению с Opus редко влияет на результаты типичных задач разработки.
Вы работаете с ограниченным бюджетом или только начинаете. Бесплатный доступ к Sonnet делает его доступным для обучения и экспериментов. Нет причин тратить деньги на Opus, пока вы ещё выясняете, как эффективно интегрировать ИИ в свой рабочий процесс.
Гибридный подход
Многие успешные реализации стратегически используют обе модели. Направляйте простые запросы в Sonnet для экономической эффективности, эскалируйте сложные задачи в Opus при необходимости. Клиент anthropic делает переключение моделей простым — просто измените параметр model.
pythondef smart_route(task_complexity: str, prompt: str) -> str: """Маршрутизация к соответствующей модели на основе сложности задачи.""" model = ( "claude-opus-4-5-20251101" if task_complexity == "high" else "claude-sonnet-4-5-20250929" ) return get_completion(prompt, model)
Этот шаблон оптимизирует как стоимость, так и качество, используя премиальные ресурсы только там, где они обеспечивают значимые преимущества.
Стратегии оптимизации затрат
Управление затратами на API ИИ требует понимания не только ценообразования, но и различных механизмов снижения расходов без ущерба для качества. Anthropic предоставляет несколько встроенных функций снижения затрат, которые многие разработчики недоиспользуют.
Преимущества кэширования промптов
Кэширование промптов снижает затраты, когда вы повторно отправляете один и тот же контекст (системные промпты, примеры few-shot или большие документы) в нескольких запросах. Вместо повторной обработки тех же токенов, кэшированные префиксы хранятся и используются повторно. Для приложений с согласованными системными промптами или справочной документацией кэширование может снизить затраты на входные токены до 90% для кэшированной части.
Для эффективного использования кэширования структурируйте свои промпты так, чтобы повторно используемый контент появлялся первым. Поместите системный промпт и любой согласованный контекст в начало, а затем переменный пользовательский ввод. Частота попаданий в кэш напрямую коррелирует с тем, насколько последовательно вы структурируете свои запросы.
Скидки на пакетную обработку
Anthropic предлагает пакетную обработку для рабочих нагрузок не в реальном времени со снижением затрат на 50%. Если ваше приложение может допустить задержки обработки в часы, а не секунды — массовый анализ контента, ночная генерация отчётов или асинхронная обработка данных — пакетная обработка обеспечивает значительную экономию.
Компромисс — это задержка: пакетные задания завершаются в течение 24 часов, а не немедленно. Для рабочих процессов разработки, требующих мгновенной обратной связи, пакетная обработка не подходит. Для фоновой обработки это по существу ИИ за полцены.
Техники оптимизации токенов
Снижение использования токенов напрямую снижает затраты. Несколько стратегий помогают без ущерба для качества:
Сжимайте многословные промпты. Удаляйте избыточные инструкции, исключайте лишние примеры и используйте краткий язык. Сокращение длины промпта на 40% даёт снижение затрат на ввод на 40%.
Транслируйте ответы и реализуйте раннюю остановку. Если вы ищете конкретный ответ, который появляется в начале ответа, остановите генерацию, как только получите то, что вам нужно, вместо того чтобы ждать полного вывода.
Используйте соответствующие лимиты max_tokens. Установка более низких лимитов, когда вы ожидаете короткие ответы, предотвращает оплату токенов, которые вы отбросите. Приложение вопросов-ответов, ожидающее ответы в один абзац, не должно запрашивать 4096 токенов.
При обработке миллионов токенов ежедневно даже небольшая экономия на токен значительно накапливается — стоит оценить для производственных рабочих нагрузок, где официальные затраты на API становятся существенными.
Сравнение затрат между провайдерами ИИ
Понимание ценообразования Claude в контексте помогает планированию бюджета. Если вы оцениваете альтернативы, такие как сравнение бесплатного уровня Gemini API, математика цена за токен отличается, но принципы оптимизации остаются схожими.
| Стратегия | Потенциальная экономия | Лучше всего для |
|---|---|---|
| Кэширование промптов | До 90% на кэшированной части | Согласованные системные промпты |
| Пакетная обработка | 50% | Рабочие нагрузки не в реальном времени |
| Оптимизация токенов | 20-40% | Все приложения |
| Маршрутизация моделей | 40% (Sonnet vs Opus) | Задачи переменной сложности |
| Сторонние шлюзы | Варьируется | Производство большого объёма |
Наиболее эффективная оптимизация затрат сочетает несколько стратегий. Хорошо структурированное приложение, использующее кэширование промптов, умную маршрутизацию моделей и оптимизированное использование токенов, может снизить затраты на 60-70% по сравнению с наивными реализациями — разница между доступной функцией на ИИ и той, которая превышает ваш бюджет.
Заключение и рекомендации
Выбор между Claude Opus 4.5 и Sonnet 4.5 сейчас яснее, чем когда-либо. Снижение цены Opus 4.5 на 67% делает премиальные возможности ИИ доступными для большего числа разработчиков, тогда как Sonnet 4.5 остаётся практичным выбором для большинства повседневных работ по разработке.
Если вы начинаете с нуля, начните с Sonnet 4.5. Его сочетание скорости, экономической эффективности и возможностей эффективно справляется с подавляющим большинством задач разработки. Бесплатный доступ через claude.ai означает, что вы можете экспериментировать без обязательств. Только когда вы столкнётесь с конкретными ограничениями — задачами, которые действительно требуют расширенного автономного рассуждения или наивысшего потолка качества — вам следует рассмотреть переход на Opus.
Для производственных приложений гибридный подход часто работает лучше всего. Направляйте рутинные запросы в Sonnet для экономической эффективности, эскалируйте сложные задачи в Opus, когда дополнительные возможности оправдывают премию. Реализуйте кэширование промптов, рассмотрите пакетную обработку для фоновых рабочих нагрузок и оптимизируйте использование токенов для минимизации затрат на обеих моделях.
Бенчмарки рассказывают одну историю, но практическое использование рассказывает другую. Показатель Sonnet 4.5 в 77,2% на SWE-bench против 80,9% у Opus 4.5 представляет значимый разрыв в контролируемых тестах. В повседневной разработке эти 3,7 процентных пункта разницы редко определяют успех или неудачу. Улучшение скорости на 41% и экономия затрат на 40% с Sonnet обеспечивают ощутимые немедленные преимущества, которые большинство разработчиков замечают больше, чем разницу в возможностях.
По мере того как Anthropic продолжает развивать обе линейки моделей, ожидайте, что разрыв продолжит сокращаться. Сегодняшний Sonnet соответствует или превосходит прошлогодний Opus во многих отношениях. Марш прогресса выгоден пользователям, которые сохраняют гибкость своих реализаций и избегают чрезмерной оптимизации для какой-либо одной версии модели.
Что бы вы ни выбрали, фундаментальные основы эффективной интеграции ИИ остаются постоянными: пишите чёткие промпты, корректно обрабатывайте ошибки, оптимизируйте использование токенов и соответствуйте возможностям модели требованиям задачи. Лучшая модель — та, которая решает вашу конкретную проблему в рамках вашего бюджета — и с ценовым ландшафтом февраля 2026 года и Opus, и Sonnet предлагают убедительные ценностные предложения.