
Agent Teams в Claude Code позволяют оркестрировать несколько ИИ-сессий для написания кода, которые напрямую обмениваются сообщениями, распределяют задачи и самостоятельно координируются, превращая часы последовательной работы в минуты параллельного выполнения. Эта экспериментальная функция, выпущенная вместе с Claude Opus 4.6 5 февраля 2026 года, требует установки одной переменной окружения и поддерживает команды из 2-16 агентов, работающих над общей кодовой базой. Агентные команды потребляют примерно в 7 раз больше токенов по сравнению с одиночной сессией в режиме планирования (code.claude.com/docs/en/costs, февраль 2026), однако для подходящих задач -- параллельного код-ревью, реализации многомодульных фич и сложной отладки -- выигрыш в продуктивности значительно превосходит затраты.
Краткое содержание
Claude Code Agent Teams позволяют одной сессии выступать в роли тимлида, который запускает независимых участников команды, каждый из которых обладает собственным контекстным окном и доступом к инструментам. Участники обмениваются сообщениями напрямую через систему почтовых ящиков и координируются через общий список задач -- в отличие от субагентов, которые отчитываются только перед родительской сессией. Для включения агентных команд необходимо установить CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1 в файле settings.json или в переменных окружения оболочки. Оптимальная область применения агентных команд -- сложная работа с множеством файлов, где участникам действительно нужна коммуникация: фулстек-фичи, охватывающие фронтенд, бэкенд и тесты; параллельное код-ревью, в ходе которого ревьюеры сопоставляют находки; а также сценарии отладки, где несколько «следователей» проверяют конкурирующие гипотезы. Агентные команды потребляют примерно в 3-7 раз больше токенов, чем одиночная сессия в зависимости от конфигурации, поэтому их не стоит использовать для простых последовательных задач, где одиночная сессия или легковесный субагент справится за малую долю стоимости.
Что такое Agent Teams и зачем они нужны
Claude Code прошёл через три отчётливых парадигмы работы со сложными задачами. Исходная модель одиночной сессии обрабатывает всё последовательно -- одно контекстное окно, одна задача за раз. Субагенты, появившиеся вместе с инструментом Task, добавили паттерн «звезда» (hub-and-spoke), при котором родительская сессия запускает легковесных воркеров, выполняющих конкретную задачу, возвращающих результат и завершающихся. Agent Teams, выпущенные с Opus 4.6 в феврале 2026 года, делают следующий шаг, обеспечивая полноценную одноранговую (peer-to-peer) коммуникацию между постоянными независимыми экземплярами Claude. Подробное введение в эту функцию и контекст её выпуска вы найдёте в нашем полном руководстве по Agent Teams в Claude 4.6.
Ключевая проблема, которую решают агентные команды -- межагентная коммуникация. При использовании субагентов, если воркер A обнаруживает что-то, о чём необходимо знать воркеру B, он не может сообщить B напрямую -- ему нужно отчитаться перед родительской сессией, которая затем передаст информацию, запустив ещё одного субагента или обновив собственный контекст. Это узкое место становится серьёзным ограничением при взаимозависимых задачах. Фронтенд-разработчику, создающему UI-компоненты, необходимо знать, какие API-эндпоинты создаёт бэкенд-разработчик, а тестировщику, пишущему интеграционные тесты, нужно знать, что делают оба. Агентные команды устраняют это узкое место, позволяя всем агентам общаться напрямую через общий почтовый ящик.
Архитектура состоит из четырёх взаимосвязанных компонентов. Тимлид (Team Lead) -- это ваша основная сессия Claude Code: она анализирует задачи, создаёт команды с помощью инструмента TeamCreate, запускает участников и оркестрирует общий рабочий процесс. Участники (Teammates) -- это независимые процессы Claude Code, каждый со своим контекстным окном и полным доступом к инструментам, запускаемые через инструмент Task с параметром team_name. Общий список задач (Shared Task List) по адресу ~/.claude/tasks/{team-name}/ служит каркасом координации, с задачами, имеющими статусы, владельцев и зависимости. Наконец, система почтовых ящиков (Mailbox System) обеспечивает прямой обмен сообщениями через инструмент SendMessage -- любой участник может написать любому другому участнику или отправить рассылку всей команде.
Инженерная команда Anthropic валидировала эту архитектуру, создав полноценный компилятор языка C с использованием 16 агентных команд (anthropic.com/engineering, февраль 2026). Проект потребовал примерно 2 000 сессий, 2 миллиарда входных токенов и 140 миллионов выходных токенов, произвёл 100 000 строк кода на Rust, который успешно скомпилировал ядро Linux 6.9, и обошёлся примерно в $20 000 за использование API. Этот proof-of-concept продемонстрировал, что мультиагентная координация работает в масштабе для реальной программной инженерии, а не только для игрушечных примеров.
Как настроить Agent Teams (полное руководство по конфигурации)
Агентные команды на данный момент являются экспериментальной функцией, что означает необходимость их явного включения одним из трёх способов. Наиболее надёжный подход -- добавить флаг в файл settings.json, что применится ко всем сессиям на вашей машине. Откройте настройки Claude Code, выполнив claude config или отредактировав файл ~/.claude/settings.json напрямую, и добавьте флаг экспериментальной функции в секцию переменных окружения. Это гарантирует, что агентные команды будут всегда доступны без необходимости запоминать переменные окружения при каждом запуске сессии.
json{ "env": { "CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS": "1" } }
Второй способ -- установка переменной окружения оболочки перед запуском Claude Code. Этот подход полезен, если вы хотите, чтобы агентные команды были доступны только в определённых терминальных сессиях, или если вы предпочитаете не менять глобальные конфигурационные файлы. Просто экспортируйте переменную в профиле оболочки или задайте её при запуске Claude Code.
bashexport CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1 claude
Третий способ -- включение агентных команд для конкретной сессии путём передачи флага как аргумента запуска, что идеально подходит для экспериментов без внесения постоянных изменений в конфигурацию. Независимо от выбранного метода, после включения агентные команды становятся доступны немедленно -- Claude Code будет использовать инструменты команды (TeamCreate, TaskCreate, SendMessage) всякий раз, когда определит, что задача выигрывает от мультиагентной координации.
Агентные команды поддерживают два режима отображения, определяющих, как будут отображаться сессии участников. Режим по умолчанию -- встроенный (in-process): все участники работают в одном окне терминала, отображая обновления статуса и уведомления о простое в общем потоке. Этот режим работает в любом терминале, но может стать перегруженным при 3 и более агентах. Режим разделённых панелей (split-pane) запускает каждого участника в отдельной панели терминала через tmux или iTerm2, предоставляя каждому агенту собственное рабочее пространство. Режим разделённых панелей настоятельно рекомендуется для команд из 3 и более агентов, так как позволяет визуально отслеживать действия каждого агента в реальном времени.
Для использования разделённых панелей с tmux убедитесь, что tmux установлен, и запустите сессию Claude Code внутри сессии tmux. Claude Code автоматически обнаружит tmux и создаст новые панели для каждого участника. В iTerm2 на macOS встроенная поддержка разделённых панелей определяется автоматически -- дополнительная настройка не требуется. Если ваш терминал не поддерживает ни tmux, ни разделённые панели iTerm2, агентные команды всё равно прекрасно работают во встроенном режиме, но визуальная обратная связь ограничивается статусными сообщениями в основной сессии.
Конфигурация разрешений играет значительную роль для агентных команд. По умолчанию участники наследуют ту же модель разрешений, что и тимлид, а это значит, что они могут запрашивать подтверждения в процессе выполнения. Для эффективной работы команды рассмотрите использование --dangerously-skip-permissions во время контролируемых сессий разработки или настройте белый список разрешённых инструментов. Вы также можете использовать параметр mode при запуске участников для установки режима "bypassPermissions" или "plan". Режим планирования особенно полезен -- он заставляет участников предлагать изменения перед их реализацией, добавляя проверочный шлюз, предотвращающий дорогостоящие ошибки в общих кодовых базах.
Оптимизация файла CLAUDE.md вашего проекта для рабочих процессов агентных команд -- это важный, но часто упускаемый из виду шаг. Когда участник запускается, он читает CLAUDE.md проекта, чтобы понять соглашения по коду, архитектуру и ограничения. Хорошо структурированный CLAUDE.md должен содержать чёткие описания границ модулей проекта (чтобы участники знали, какие файлы относятся к какой области), руководства по стилю кода (чтобы изменения от разных агентов были согласованными) и указания на файлы или директории, которые не следует модифицировать (для предотвращения конфликтов слияния между параллельно работающими агентами). Добавление секции, посвящённой координации в агентной команде -- например, «Работая в качестве участника команды, всегда проверяйте TaskList перед началом новой работы» -- может значительно улучшить поведение команды.
Agent Teams против субагентов: практическая схема принятия решений
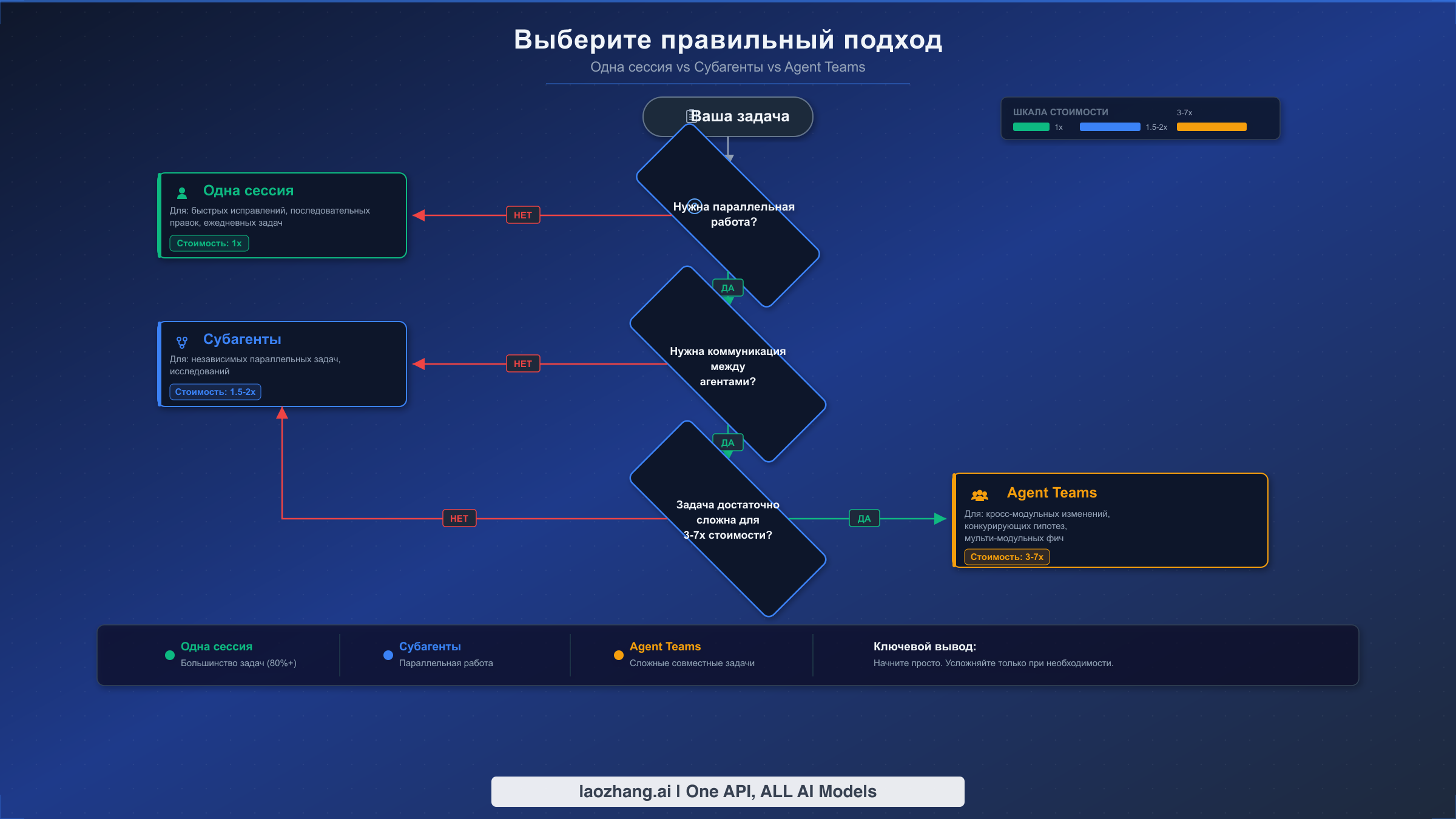
Выбор между одиночными сессиями, субагентами и агентными командами -- это самое важное решение, которое вы принимаете перед началом задачи, потому что оно напрямую определяет как стоимость, так и эффективность. Неправильный выбор либо тратит токены на ненужную координацию, либо упускает продуктивность, вынуждая выполнять последовательно работу, которая могла бы выполняться параллельно. Данная схема принятия решений сводит выбор к трём вопросам, которые последовательно сужают варианты, и её понимание предотвращает самую распространённую и дорогостоящую ошибку новых пользователей: использование агентных команд для всего подряд.
Первое измерение, которое нужно оценить -- действительно ли ваша задача выигрывает от параллельного выполнения. Если вы исправляете баг в одном файле, обновляете документацию или вносите изменения, которые естественно идут последовательно, одиночная сессия -- оптимальный выбор каждый раз. Одиночные сессии имеют минимальную стоимость в токенах (1x базовая), нулевые накладные расходы на координацию и прекрасно справляются с подавляющим большинством повседневных задач кодирования. Желание использовать агентные команды, потому что они «звучат мощно», понятно, но параллелизм приносит пользу только тогда, когда действительно есть работа, которая может выполняться одновременно, не создавая конфликтов.
Второй вопрос -- это ключевая развилка между субагентами и агентными командами: нужно ли параллельным воркерам общаться друг с другом? Субагенты работают по паттерну «звезда», где каждый воркер возвращает результаты родительской сессии и затем завершается, но «соседние» субагенты не могут общаться друг с другом напрямую. Это делает субагентов идеальными для «стыдно параллельных» задач -- запуск тестов в пяти разных модулях, поиск паттерна в нескольких директориях или генерация документации для независимых компонентов. Субагенты обходятся примерно в 1,5-2 раза дороже одиночной сессии, что значительно дешевле полноценных агентных команд.
Агентные команды оправдывают свою стоимость в 3-7 раз больше токенов только тогда, когда участникам действительно необходима одноранговая коммуникация. Каноническим примером является разработка фулстек-фичи: фронтенд-разработчику нужно знать, какие API-эндпоинты создаёт бэкенд-разработчик, а тестировщику -- контракты обеих сторон. Без прямой коммуникации родительская сессия становится дорогостоящим узким местом, ретранслирующим информацию между воркерами, а сам процесс ретрансляции потребляет токены и создаёт задержки. Аналогично, код-ревью выигрывает от агентных команд, когда ревьюеры должны опираться на находки друг друга: один ревьюер обнаруживает проблему производительности, сообщает о ней, а другой проверяет, не создаёт ли предложенное исправление уязвимость безопасности.
Следующая таблица отражает ключевые параметры по всем трём подходам:
| Параметр | Одиночная сессия | Субагенты | Agent Teams |
|---|---|---|---|
| Множитель стоимости в токенах | 1x | 1,5-2x | 3-7x |
| Коммуникация агентов | Н/Д | Только «звезда» (hub-and-spoke) | Полная одноранговая (peer-to-peer) |
| Сохранение контекста | Непрерывное | Завершается после задачи | Постоянное между ходами |
| Координация задач | Последовательная | Управляемая родителем | Самоорганизация через список задач |
| Лучше всего подходит для | Изменений в одном файле, последовательной работы | Независимых параллельных задач | Взаимозависимой параллельной работы |
| Сложность настройки | Нет | Минимальная | Флаг окружения + режим отображения |
| Оптимальный размер команды | 1 | 2-5 воркеров | 2-7 участников |
Практическая эвристика: если вы можете полностью описать задачу каждого параллельного воркера без ссылок на то, что делают другие воркеры, используйте субагенты. Если воркерам нужно задавать вопросы друг другу, обмениваться промежуточными результатами или координировать изменения для предотвращения конфликтов -- используйте агентные команды.
Реальная стоимость Agent Teams (с расчётами в долларах)
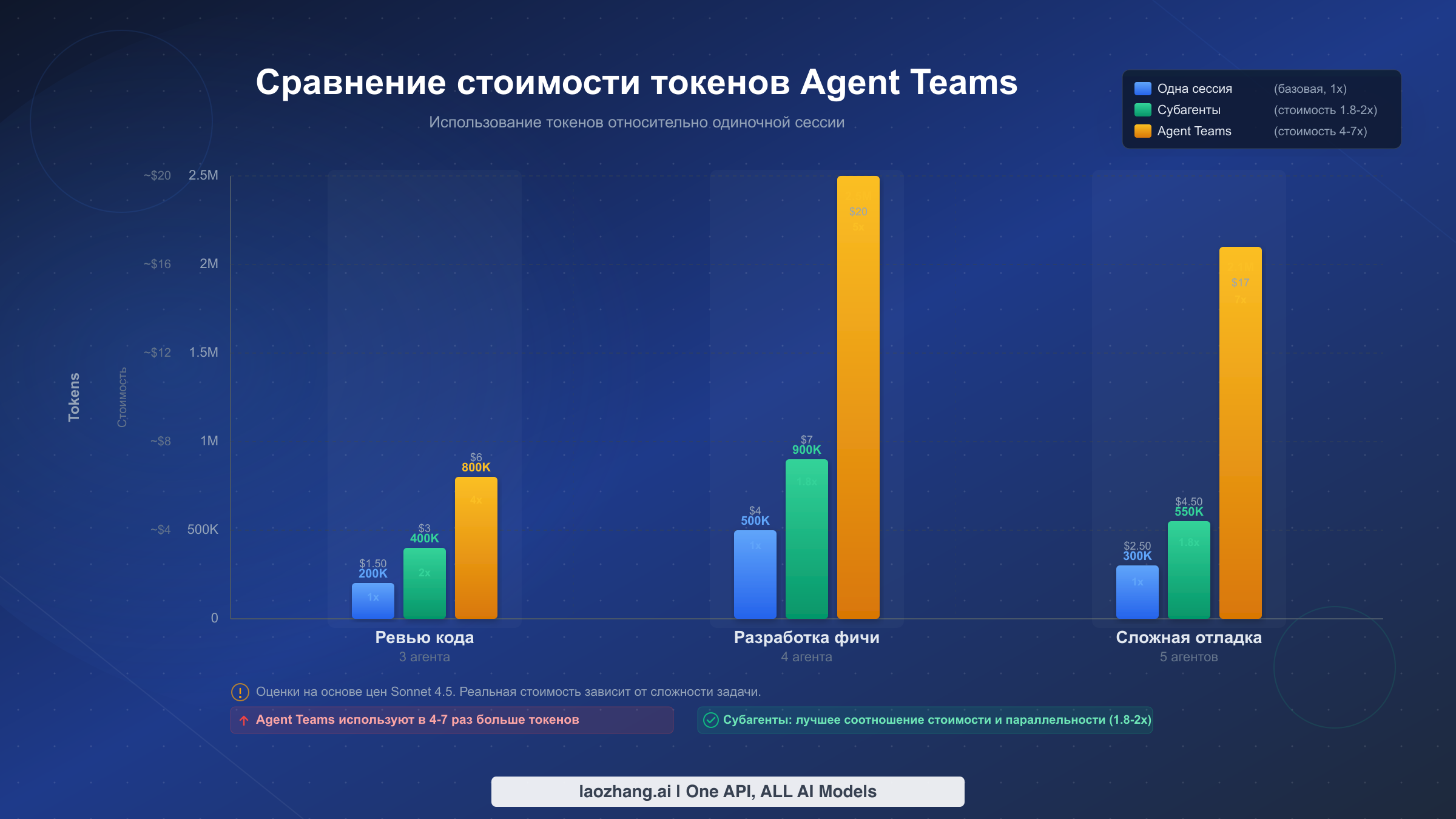
Стоимость -- это главный барьер на пути к внедрению агентных команд, и заглавная цифра -- примерно 7x токенов в режиме планирования (code.claude.com/docs/en/costs, февраль 2026) -- звучит тревожно без контекста. Этот множитель представляет верхнюю границу для режима планирования с несколькими участниками, но реальные затраты сильно варьируются в зависимости от размера команды, выбора модели и сложности задачи. По данным Anthropic, средний пользователь Claude Code тратит примерно $6 на разработчика в день, а 90-й процентиль составляет $12 в день (code.claude.com/docs/en/costs, февраль 2026). Подробный разбор ценообразования Claude по уровням подписки и доступу к API вы найдёте в руководстве по ценам и подписке Claude Opus 4.6.
Чтобы сделать затраты осязаемыми, ниже приведены расчёты для трёх типичных сценариев на основе подтверждённых цен API (claude.com/pricing, февраль 2026). Расчёты предполагают использование Opus 4.6 для тимлида и Sonnet 4.5 для участников команды -- это рекомендуемая конфигурация по соотношению цена-производительность.
Сценарий 1: Параллельное код-ревью (3 ревьюера, ~30 минут). Код-ревью одиночной сессией для PR среднего размера обычно потребляет около 200 000 токенов (150 000 входных, 50 000 выходных) и стоит примерно $2,00 на Opus 4.6. С использованием 3 участников агентной команды -- по одному на безопасность, производительность и качество кода -- тимлид потребляет ~100 000 токенов на координацию, а каждый ревьюер на Sonnet 4.5 потребляет ~180 000 токенов. Итого: примерно 640 000 токенов при смешанной стоимости ~$4,50. Множитель 2,25x обеспечивает три специализированных взгляда, которые один ревьюер мог бы пропустить, и ревьюеры могут сообщать о находках друг другу в реальном времени. Для большинства команд дополнительные $2,50 -- ничтожная сумма по сравнению со стоимостью выпуска уязвимости в продакшен.
Сценарий 2: Разработка фулстек-фичи (фронтенд + бэкенд + тесты, ~2 часа). Реализация фичи одиночной сессией обычно потребляет 400 000-600 000 токенов в зависимости от сложности и стоит $8-15 на Opus 4.6. Агентная команда из 3 специалистов -- фронтенд, бэкенд-API и интеграционные тесты -- потребляет примерно 300 000 токенов на Opus-тимлида и по 350 000 на каждого из Sonnet-участников, итого примерно 1,35 миллиона токенов при смешанной стоимости ~$20. Множитель стоимости 2,5-3x сжимает 4-6 часов последовательной работы примерно до 90 минут параллельного выполнения. Для разработчика с почасовой ставкой $100 дополнительные $12 на API экономят $300-500 во времени.
Сценарий 3: Сложная отладка с конкурирующими гипотезами (3-5 «следователей», ~1 час). Сложные баги часто требуют одновременной проверки нескольких теорий. Одиночная сессия, методично проверяющая 3 гипотезы, потребляет ~500 000 токенов за 1-2 часа и стоит примерно $10. Агентная команда из 3 «следователей», каждый из которых проверяет одну гипотезу, потребляет ~200 000 токенов на тимлида плюс по 250 000 на каждого «следователя», итого примерно 950 000 токенов при стоимости ~$13. Скромный множитель 1,3x обманчив -- настоящая экономия в реальном времени. Три параллельных «следователя» находят корневую причину за 20 минут вместо 90, и они могут обмениваться находками в реальном времени, быстрее отсекая тупиковые направления.
Самая действенная оптимизация стоимости -- стратегический выбор модели. Тимлид должен работать на Opus 4.6, потому что ему нужны сильнейшие возможности рассуждения для декомпозиции задач, координации и принятия решений. Участники по умолчанию должны использовать Sonnet 4.5, который обеспечивает отличные возможности кодирования при стоимости входных токенов на 60% ниже ($3 против $5/MTok) и выходных на 40% ниже ($15 против $25/MTok). Для простых, чётко определённых подзадач в рамках команды -- запуск линтеров, форматирование кода, поиск паттернов -- участники могут запускать собственных субагентов на Haiku 4.5 по $1/$5 за MTok, создавая трёхуровневую иерархию стоимости. Подробное сравнение, когда использовать Opus, а когда Sonnet, вы найдёте в сравнении моделей Opus и Sonnet.
Помимо выбора модели, четыре дополнительных тактики оптимизации значительно снижают расходы на агентные команды. Во-первых, задавайте явные границы области в промптах запуска -- участник, которому поручено «проверить модуль аутентификации на уязвимости безопасности», потребляет значительно меньше токенов, чем тот, кому сказали «проверить всю кодовую базу». Во-вторых, используйте параметр max_turns при запуске участников для ограничения количества API-обращений, предотвращая неконтролируемое потребление токенов «убежавшими» агентами. В-третьих, держите команды небольшими: 2-3 сфокусированных участника стабильно превосходят 5+ агентов с перекрывающимися обязанностями. В-четвёртых, используйте режим планирования для сложных реализаций -- тимлид проверяет предложенные изменения перед их выполнением участниками, предотвращая дорогостоящие циклы переработки.
Шаблоны промптов для эффективных агентных команд
Разница между продуктивной сессией агентной команды и бесполезной тратой токенов почти полностью определяется тем, как вы описываете задачу для Claude Code. Расплывчатая инструкция вроде «отрефакторить модуль пользователей» порождает команду, которая спотыкается об нечёткие обязанности и дублирование работы. Эффективный промпт запуска определяет цель, назначает чёткие роли, устанавливает границы области ответственности и задаёт критерии качества. Следующие шаблоны разработаны для копирования и адаптации под ваши конкретные проекты.
Шаблон 1: Параллельное код-ревью (3 специализированных ревьюера)
Review pull request #47 using a team of 3 specialized reviewers.
Create a team called "pr-47-review".
Reviewer 1 (Security): Review all changes in src/auth/ and src/api/
for authentication bypasses, injection vulnerabilities, and unsafe
data handling. Use Sonnet model.
Reviewer 2 (Performance): Review all changes for N+1 queries,
unnecessary re-renders, missing indexes, and memory leaks. Focus on
files touching database queries and React components. Use Sonnet model.
Reviewer 3 (Code Quality): Review for consistent error handling,
proper TypeScript types, test coverage gaps, and adherence to our
coding standards in CLAUDE.md. Use Sonnet model.
After all reviewers complete, synthesize findings into a single
prioritized report. Flag any conflicts between reviewers'
recommendations.
Этот шаблон работает, потому что каждому ревьюеру назначена непересекающаяся область, указана модель для контроля затрат, и включён этап синтеза в конце. Тимлид координирует, а три участника на Sonnet выполняют детальную проверку, удерживая общую стоимость примерно на уровне $4-5.
Шаблон 2: Реализация фулстек-фичи
Implement the user notification preferences feature from issue #234.
Create a team called "notification-prefs".
Teammate 1 (Backend): Create the API endpoints in src/api/notifications/
- GET /api/notifications/preferences (read current prefs)
- PUT /api/notifications/preferences (update prefs)
- Add database migration for notification_preferences table
- Write unit tests for the new endpoints
Use Sonnet model.
Teammate 2 (Frontend): Build the settings UI in src/components/settings/
- Create NotificationPreferences component
- Connect to the API endpoints (coordinate with Backend teammate
for exact request/response shapes)
- Add form validation and loading states
- Write component tests
Use Sonnet model.
Teammate 3 (Integration): After Backend and Frontend complete:
- Write end-to-end tests covering the full flow
- Verify the database migration runs cleanly
- Test error scenarios (network failures, invalid data)
Use Sonnet model. This task is blocked by Teammates 1 and 2.
Use delegate mode. I want to review the overall plan before
implementation begins.
Этот шаблон явно задаёт зависимости задач (участник 3 заблокирован участниками 1 и 2), запрашивает режим делегирования, чтобы тимлид координировал, а не реализовывал, и предписывает участникам координироваться по API-контрактам. Фронтенд-участник знает, что нужно спросить бэкенд-участника о формате запросов и ответов, а не гадать.
Шаблон 3: Отладка с конкурирующими гипотезами
The checkout flow is failing intermittently with a 500 error in
production. Error logs show "connection refused" but only for ~10%
of requests. Create a team called "checkout-debug" with 3 investigators.
Investigator 1: Hypothesis — Database connection pool exhaustion.
Check src/db/pool.ts configuration, look for connection leaks in
the checkout transaction code, analyze connection pool sizing vs
concurrent request volume.
Investigator 2: Hypothesis — Redis session store timeout.
Check src/cache/redis.ts for timeout configuration, look for
blocking operations in the session middleware, verify Redis health
check implementation.
Investigator 3: Hypothesis — Downstream payment API flakiness.
Check src/services/payment.ts for retry logic, look at error
handling for the payment provider webhook, check if circuit breaker
is configured correctly.
Each investigator: Share findings via messages as you go. If you
find strong evidence for your hypothesis, broadcast to the team
immediately. If you can rule out your hypothesis, say so and help
another investigator.
Ключевое нововведение в этом шаблоне -- явная инструкция «следователям» делиться находками и помогать друг другу. Это превращает команду в настоящее совместное расследование, а не трёх изолированных работников. «Следователь», исключивший свою гипотезу, может немедленно помочь сузить область поиска.
Шаблон 4: Исследование и изучение кодовой базы
I need to understand how our authentication system works before
refactoring it. Create a research team called "auth-research".
Researcher 1: Map the authentication flow from login to session
creation. Document every file involved, every middleware touched,
and every database query executed. Output a flow diagram in markdown.
Researcher 2: Identify all places in the codebase that check
authentication or authorization. List every guard, middleware,
decorator, and manual check. Flag any inconsistencies in how
auth is verified.
Researcher 3: Analyze the test coverage for authentication.
Which flows are well-tested? Which have no tests? What edge
cases are missing?
All researchers: Use read-only operations only. Do not modify
any files. Share interesting findings with each other as you discover them.
Этот шаблон использует агентные команды для исследования, а не реализации, с критическим ограничением: только чтение. Исследовательские команды -- один из самых безопасных способов начать использовать агентные команды, поскольку отсутствует риск файловых конфликтов или непреднамеренных изменений.
Пять элементов делают промпт запуска эффективным: понятное имя команды для отслеживания, конкретные назначения ролей с непересекающимися областями, явный выбор модели для контроля затрат, определённые ожидания по коммуникации (когда делиться находками, как координироваться) и критерии качества или ограничения (только чтение, режим планирования, зависимости «заблокирован»). Когда вы включаете все пять элементов, агентные команды стабильно выдают сфокусированные и экономичные результаты.
Продвинутые паттерны и лучшие практики
Освоив базовые рабочие процессы агентных команд, вы можете перейти к продвинутым паттернам, которые открывают значительно более сложную координацию. Эти паттерны решают наиболее распространённые сценарии сбоев, о которых сообщают опытные пользователи, и представляют собой выводы, полученные на практике.
Режим делегирования активируется нажатием Shift+Tab в сессии тимлида и принципиально меняет его поведение. В режиме делегирования тимлид ограничивается инструментами координации -- он не может редактировать файлы, выполнять команды или реализовывать что-либо напрямую. Это заставляет тимлида разбивать задачи на чёткие, хорошо определённые рабочие элементы и назначать их участникам, а не нетерпеливо хватать работу самому. Проблема «тимлид реализует вместо делегирования» -- один из самых распространённых антипаттернов агентных команд: без режима делегирования способный тимлид на Opus часто начинает реализовывать первую задачу самостоятельно, пока его участники простаивают, что полностью нивелирует смысл команды. Режим делегирования делает это невозможным, и результат -- стабильно лучшая декомпозиция задач и утилизация ресурсов.
Утверждение планов добавляет критический шлюз качества для работы с высокими ставками. Когда участники запускаются с mode: "plan", они работают в режиме только чтения -- могут исследовать кодовую базу, анализировать требования и проектировать подход к реализации, но не могут вносить никаких изменений, пока тимлид явно не утвердит их план. Участник вызывает ExitPlanMode, когда план готов, что отправляет запрос на утверждение тимлиду. Тимлид анализирует предложенный подход и либо утверждает его (участник выходит из режима планирования и начинает реализацию), либо отклоняет с обратной связью (участник пересматривает план). Этот паттерн незаменим для кодовых баз, где некорректные изменения дорого исправлять -- миграции баз данных, изменения публичных API и код, связанный с безопасностью, выигрывают от этапа проверки перед реализацией.
Хуки для контроля качества позволяют автоматизировать обеспечение качества на уровне команды через shell-команды, которые выполняются в ответ на события агента. Два события хуков особенно полезны для агентных команд. Хук TeammateIdle срабатывает, когда участник завершает ход и переходит в режим ожидания, что идеально подходит для запуска линтеров, проверки типов или тестовых наборов на недавних изменениях участника. Если хук обнаруживает ошибки, обратная связь поступает непосредственно участнику, чтобы он мог исправить проблему до того, как тимлид посчитает задачу выполненной. Хук TaskCompleted срабатывает при пометке задачи как завершённой, позволяя автоматически запускать интеграционные тесты или превью развёртывания по достижении контрольных точек. Хуки превращают агентные команды из рабочего процесса «доверяй и надейся» в «доверяй и проверяй».
Проектирование зависимостей задач определяет, насколько эффективно участники самоорганизуются. При создании задач используйте параметры addBlockedBy и addBlocks для выражения ограничений порядка выполнения. Хорошо спроектированный граф зависимостей гарантирует, что фундаментальная работа (миграции базы данных, общие типы, API-контракты) завершается до начала зависимой работы (UI-компоненты, интеграционные тесты). Участники автоматически соблюдают эти зависимости -- они не возьмут заблокированную задачу, пока все блокирующие условия не будут выполнены. Ошибка, которой следует избегать -- создание плоского, неструктурированного списка задач, где все задачи не имеют зависимостей. Без явного упорядочивания участники наперегонки захватывают задачи и часто строят на неустойчивом фундаменте, что ведёт к переделкам и потере токенов.
Типичные ошибки, приводящие к перерасходу токенов, заслуживают явного упоминания, потому что их удивительно легко совершить. Использование агентных команд для последовательных задач -- самая дорогостоящая ошибка: нет выигрыша от параллелизма, если каждый шаг зависит от предыдущего, а накладные расходы на координацию добавляют 3-7x стоимости при нулевом ускорении. Запуск слишком большого числа участников -- вторая по частоте проблема: более 4-5 активных агентов часто мешают друг другу, генерируют избыточный контекст и тратят токены на межагентные сообщения, перевешивающие пользу от параллелизма. Начало с чрезмерно широкими областями означает, что участники тратят первые 10-20 ходов на исследование кодовой базы вместо выполнения задачи, и эти «исследовательские» токены быстро накапливаются при 5 агентах. Решение -- давать каждому участнику сфокусированную, чётко ограниченную задачу с явной областью файлов или модулей.
Устранение неполадок агентных команд
Агентные команды привносят координационную сложность, которой нет в одиночных сессиях и субагентах, поэтому понимание типичных сценариев сбоев и их решений помогает быстро восстанавливаться, вместо того чтобы тратить токены на дезориентированных агентов.
Участники не появляются -- обычно это вызвано тем, что флаг функции не установлен в правильной области. Если вы установили CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1 как переменную оболочки, она действует только для текущей терминальной сессии -- другие терминалы или новые сессии её не получат. Самое надёжное решение -- добавить флаг в ~/.claude/settings.json, чтобы он действовал глобально. Также убедитесь, что версия Claude Code актуальна, выполнив claude --version, так как агентные команды требуют версию, выпущенную после 5 февраля 2026 года. Если вы используете режим разделённых панелей, проверьте, действительно ли запущен tmux, выполнив tmux ls -- агентные команды молча переключаются во встроенный режим, если tmux не обнаружен.
Файловые конфликты между участниками возникают, когда два агента пытаются одновременно модифицировать один и тот же файл. Симптом -- обычно перезапись изменений одного участника операцией записи другого, или появление конфликтов слияния в git status. Стратегия предотвращения -- назначение чёткого владения файлами или директориями в промпте запуска: «Участник 1 владеет src/api/, участник 2 владеет src/components/» -- чтобы они никогда не трогали одни и те же файлы. Если конфликт всё же произошёл, тимлид должен приостановить обоих участников, разрешить конфликт вручную или поручить одному участнику перечитать файл и согласовать изменения, после чего возобновить работу с более строгими границами. Настройка pre-commit хука, который обнаруживает конфликтующие изменения, позволяет выявлять это на ранней стадии.
Тимлид реализует вместо делегирования -- это поведенческая проблема, когда Opus-тимлид начинает писать код сам, вместо того чтобы назначать работу участникам. Это сводит на нет смысл команды и часто приводит к простаивающим участникам, которые потребляют токены, не делая ничего полезного. Решение -- активировать режим делегирования с помощью Shift+Tab, который ограничивает тимлида инструментами координации. Если вы заметили этот паттерн в середине сессии, можно также явно проинструктировать тимлида: «Не реализуй ничего самостоятельно. Разбей задачу на подзадачи и назначь их участникам команды».
Осиротевшие сессии tmux накапливаются, когда сессии агентных команд завершаются аварийно -- из-за разрыва сети, падения терминала или принудительного закрытия тимлида. Эти осиротевшие процессы продолжают работать в фоне, потребляя системные ресурсы, но больше не связаны ни с какой координационной инфраструктурой. Выполните tmux ls, чтобы просмотреть все сессии, и tmux kill-session -t {name}, чтобы очистить ненужные. Полезная практика -- включать дату или название задачи в имя команды, чтобы легко определять, какие сессии устарели.
Задержка обновления статуса задач возникает, когда участник завершает работу, но список задач не сразу отражает обновление. Это может привести к тому, что тимлид считает задачу ещё выполняемой, или другой участник избегает брать последующую работу. Корневая причина обычно в том, что участник завершил реализацию, но не вызвал TaskUpdate для пометки задачи как выполненной. Решение -- явные инструкции в промпте запуска: «После завершения задачи всегда вызывай TaskUpdate, чтобы пометить её как выполненную, затем вызови TaskList, чтобы проверить следующую доступную задачу». Встраивание этого в стандартный шаблон промпта предотвращает повторение проблемы.
Начните работать с Agent Teams уже сегодня
Начало работы с агентными командами не требует понимания каждого продвинутого паттерна -- вы можете продуктивно работать с минимальной настройкой и осваивать тонкости по мере столкновения с конкретными задачами. Следующий чек-лист проведёт вас от нуля до первой продуктивной сессии агентной команды менее чем за 5 минут.
Начните с быстрой настройки: добавьте "CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS": "1" в секцию env файла ~/.claude/settings.json. Установите tmux, если хотите отображение в разделённых панелях (рекомендуется для 3+ агентов, но не обязательно). Затем откройте Claude Code и опишите задачу, допускающую параллелизм -- начните с чего-то малорискового, вроде код-ревью или исследования кодовой базы, а не критичной реализации фичи. Наблюдайте, как тимлид декомпозирует задачу, запускает участников и координирует их работу.
Рекомендуемая траектория обучения системно формирует уверенность. Сначала попробуйте исследовательскую команду из 2 агентов, которая изучает вашу кодовую базу в режиме «только чтение» -- это знакомит с динамикой команды при нулевом риске. Затем попробуйте команду из 3 агентов для код-ревью, где каждый ревьюер фокусируется на отдельном измерении качества (безопасность, производительность, сопровождаемость). После этого попытайтесь реализовать небольшую фичу с 2-3 участниками, работающими над отдельными модулями. Наконец, экспериментируйте с продвинутыми паттернами -- режимом делегирования, утверждением планов и хуками -- когда освоите механику координации.
Для команд, выполняющих большие объёмы агентных рабочих нагрузок через API, управление затратами становится практической задачей. Стратегия смешивания моделей, описанная ранее (Opus-тимлид + Sonnet-участники + Haiku-субагенты), -- наиболее эффективная оптимизация. Направьте экспериментальный бюджет на понимание того, какие задачи действительно выигрывают от агентных команд, а какие лучше решаются одиночными сессиями или субагентами -- это понимание окупается многократно.
Часто задаваемые вопросы
Могут ли агентные команды работать с одним файлом одновременно? Технически могут, но делать так не следует. Два агента, пишущих в один файл, создают гонку условий, при которой изменения одного агента перезаписывают изменения другого. Назначайте чёткое владение файлами или директориями каждому участнику в промпте запуска.
Что произойдёт, если тимлид аварийно завершится в середине сессии? Участники продолжат работать независимо, но потеряют координационный центр. Они завершат текущую задачу, но не смогут получать новые назначения. Вы можете перезапустить Claude Code и подхватить осиротевших участников через список задач или очистить сессии tmux и начать заново.
Сколько участников следует использовать? Два-три сфокусированных участника стабильно превосходят более крупные команды. При более чем 4-5 активных агентах накладные расходы на координацию и риск файловых конфликтов растут быстрее, чем прирост продуктивности. Проект компилятора C использовал 16 агентов, но в рамках примерно 2 000 сессий -- а не 16 агентов одновременно (anthropic.com/engineering, февраль 2026).
Работают ли агентные команды с MCP-серверами? Да. Участники наследуют конфигурацию MCP-серверов из настроек проекта, поэтому любые MCP-инструменты, доступные тимлиду, также доступны участникам. Это означает, что агенты могут использовать пользовательские инструменты, подключения к базам данных и интеграции с внешними сервисами во время командных сессий.
Можно ли возобновить прерванную сессию агентной команды? На данный момент агентные команды не поддерживают нативное возобновление сессий. Если сессия прервана, список задач в ~/.claude/tasks/{team-name}/ сохраняется и показывает, какие задачи были выполнены, находились в работе или ожидали выполнения. Вы можете начать новую сессию, сослаться на существующий список задач и возобновить работу с последней завершённой контрольной точки.