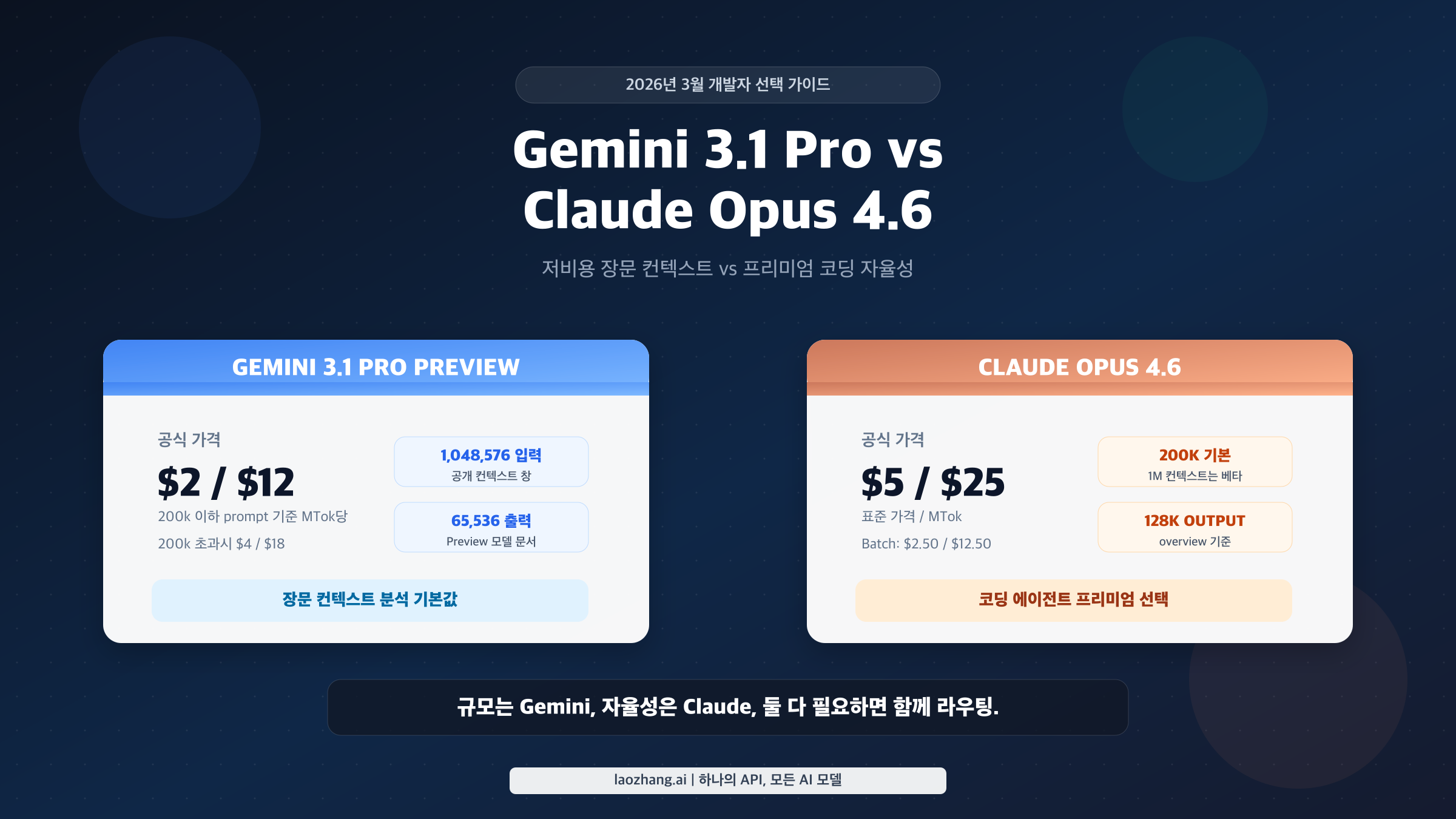
대부분의 개발자가 "Gemini 3.1 Pro vs Claude Opus 4.6"를 찾을 때 진짜 원하는 것은 모델 철학이 아닙니다. 무엇부터 붙여 봐야 하느냐는 빠른 답입니다. 2026년 3월 기준 실무 규칙은 단순합니다. 장문 컨텍스트와 비용 통제가 핵심이면 Gemini부터, 코드 에이전트의 첫 성공률이 핵심이면 Claude부터, 시스템이 이미 넓은 입력 처리 단계와 좁은 실행 단계로 갈라져 있다면 둘 다 두고 작업별로 나눠 쓰면 됩니다.
이 답이 성립하는 이유도 비교적 명확합니다. Google은 가격, 토큰 한도, 장문 입력 운용 쪽 근거가 더 또렷하고, Anthropic은 고난도 코딩과 자율 실행 쪽 공개 근거가 더 강합니다. 문제는 benchmark를 보는 것 자체가 아니라, 서로 다른 SKU와 Preview/beta 상태를 한 표에 섞어 단일 순위처럼 읽는 데 있습니다.
답만 먼저 말하면
문서 묶음, 저장소 인제스트, 비용 민감한 분석이 주업무라면 Gemini 3.1 Pro Preview부터 검증하세요. 코드 리뷰, 디버깅, 도구 오케스트레이션처럼 첫 시도의 질이 바로 인건비로 이어지는 업무라면 Claude Opus 4.6부터 보는 편이 맞습니다. 앞단은 대량 문맥 처리, 뒷단은 고품질 실행으로 나뉘는 제품이라면 한 모델 승자를 억지로 고르지 말고 둘 다 유지하세요. 2026년 3월 기준 가장 빠르고 현실적인 답은 이 정도면 충분합니다.
| 제품에서 주로 필요한 것 | 먼저 볼 모델 | 이유 |
|---|---|---|
| 긴 문서, 저장소 인제스트, 비용 민감한 분석 | Gemini 3.1 Pro Preview | 공식 가격이 더 낮고 백만 입력 컨텍스트 문서가 더 명확함 |
| 코드 리뷰, 디버깅, 도구 사용, 다단계 실행 | Claude Opus 4.6 | 고난도 코딩과 자율 실행에 대한 공개 근거가 더 강함 |
| 대량 입력 처리 + 품질 민감한 최종 실행 | 둘 다 유지 | Gemini는 넓은 입력 단계, Claude는 비싼 최종 실행 단계에 더 잘 맞음 |
실제로 무엇을 비교하고 있나?

가장 먼저 바로잡아야 할 것은 비교 대상 그 자체입니다. 많은 사람이 "Gemini 3.1"이라고 말할 때 Gemini 3.1 Pro Preview, Gemini 3.1 Pro Preview Customtools, 혹은 포럼과 래퍼에서 언급되는 다른 Gemini 3.1 계열을 한꺼번에 의미합니다. Claude Opus 4.6과 직접 API 비교를 하려면 가장 깔끔한 대상은 Gemini 3.1 Pro Preview 입니다. Google이 이 모델에 대해 가격, token 제한, software engineering 포지셔닝을 공개적으로 문서화하고 있기 때문입니다. Anthropic 쪽의 비교 상대는 Claude Opus 4.6 이지 Sonnet 4.6이 아닙니다. Sonnet은 더 저렴한 선택일 수 있지만, 그건 다른 제품 의사결정입니다. Claude 가격 계층 전체를 따로 보고 싶다면 Claude Opus 4.6 pricing guide를 읽는 편이 낫습니다.
출시 시점도 중요합니다. 두 모델 모두 충분히 최신이기 때문에, 오래된 전제를 들고 오면 설계 판단이 바로 틀어질 수 있습니다. Google은 2026년 2월 19일 Gemini 3.1 Pro를 발표했고 공식 모델 페이지는 아직도 Preview 로 표시합니다. Anthropic은 2026년 2월 5일 Claude Opus 4.6을 발표했고, 최신 Opus급 모델이자 복잡한 추론과 코딩에 가장 강한 옵션으로 포지셔닝합니다. 따라서 이 비교는 본질적으로 freshness-sensitive합니다. Gemini 2.5나 Claude 4.1 시대 가격과 한도를 기준으로 쓴 글은 단순히 조금 오래된 게 아니라, 전혀 다른 아키텍처 결론으로 이끌 수 있습니다.
하드 스펙만 봐도 의사결정의 윤곽이 나옵니다. Google 공식 문서는 Gemini 3.1 Pro Preview에 1,048,576 입력 token 과 65,536 출력 token 을 명시합니다. Anthropic의 model overview는 Opus 4.6에 200k context 와 128k max output 을 제시하고, 별도의 launch post에서는 1M-token context window in beta 를 언급합니다. 이것은 사소한 사양이 아닙니다. 초대형 프롬프트가 핵심인 워크로드라면 Gemini의 공개 문서가 더 명확하고 더 저렴합니다. 반대로 매우 긴 생성 결과가 중요하다면 Claude의 128k 출력 한도는 실제 장점이 됩니다.
| 항목 | Gemini 3.1 Pro Preview | Claude Opus 4.6 |
|---|---|---|
| 출시일 | 2026-02-19 | 2026-02-05 |
| 상태 | Preview | 현재 플래그십 |
| 입력 가격 | <=200k 에서 $2/MTok, >200k 에서 $4/MTok | $5/MTok |
| 출력 가격 | <=200k 에서 $12/MTok, >200k 에서 $18/MTok | $25/MTok |
| 입력 컨텍스트 | 1,048,576 tokens | overview에서는 200k, launch post에서는 1M beta |
| 최대 출력 | 65,536 tokens | 128k tokens |
| 공개 성능 신호 | 장문 컨텍스트와 비용 통제 쪽이 더 설득력 있음 | 고난도 코딩과 자율 실행 쪽 공개 근거가 더 강함 |
| 공식 포지셔닝 | better thinking, token efficiency, grounded behavior, software engineering, precise tool usage | complex coding, agentic work, computer use, tool use, search, finance |
이 섹션에서 한 가지만 기억한다면 이것입니다. Gemini 3.1 Pro Preview는 "싼 Claude"가 아니고, Claude Opus 4.6은 "더 비싼 Gemini"도 아닙니다. 두 모델은 서로 다른 failure profile을 상대로 판매되고 있습니다. Gemini는 긴 컨텍스트와 정확한 도구 사용을 감당하면서도 가격 경쟁력을 유지하는 workhorse에 가깝고, Opus는 어려운 코딩과 고자율 작업에서 실패 루프를 줄여 프리미엄을 회수하는 모델에 가깝습니다.
공개 benchmark는 이렇게 읽어야 한다
검색 사용자가 benchmark 스냅샷을 기대하는 것은 자연스럽습니다. 다만 이 비교는 한 장의 점수표로 끝나지 않습니다. Anthropic은 Opus 4.6을 Terminal-Bench 2.0, Humanity's Last Exam, BrowseComp, GDPval-AA 같은 공개 benchmark와 함께 고난도 코딩 및 자율 실행 모델로 밀고 있습니다. Google은 Gemini 3.1 Pro Preview를 benchmark 순위표보다 가격, 백만 입력, token efficiency, grounded behavior, 도구 정밀성 쪽으로 설명합니다. 따라서 올바른 해석은 "Claude가 공개 성능 서사에서 더 강하다"는 점은 인정하되, 장문 입력과 비용 구조에서는 Gemini 문서가 더 직접적이라는 사실을 함께 보는 것입니다. Sonnet, Opus, Preview, beta context를 한 표에 섞어 단일 승자를 만드는 글은 이 핵심을 놓칩니다.
가격과 컨텍스트: Gemini가 기본값이 되는 이유
결론: Gemini는 긴 입력을 많이 다루고 비용 통제가 중요한 팀에게 가장 먼저 검토할 기본 선택지입니다.
근거: Google이 더 낮은 공식 가격과 백만 입력 컨텍스트를 문서로 명확하게 공개하고 있습니다.
선택 기준: 긴 문서, 저장소, 검색 기반 분석을 대량으로 처리하는 쪽이라면 Gemini부터 검증하는 편이 맞습니다.
직접적인 API 가격만 놓고 보면 Gemini 3.1 Pro Preview가 가장 분명한 우위를 가집니다. Google의 공식 pricing page에 따르면, Gemini 3.1 Pro Preview는 prompt가 200k token 이하일 때 입력 $2.00 / 출력 $12.00 per million tokens 이고, 200k 를 넘으면 입력 $4.00 / 출력 $18.00 입니다. Anthropic의 pricing documentation은 Claude Opus 4.6을 입력 $5.00 / 출력 $25.00 으로 둡니다. 즉 일반적인 <=200k 구간에서는 Gemini가 입력 기준 60%, 출력 기준 52% 저렴합니다. 긴 프롬프트 tier에 들어가도 입력은 20%, 출력은 28% 싸게 유지됩니다.
가장 중요한 가격 디테일은 Gemini의 우위가 임계값 의존적 이라는 점입니다. 저가 tier만 인용하면 Gemini는 거의 터무니없이 싸 보입니다. 하지만 실제 운영에서는 200k 를 얼마나 자주 넘느냐가 그림을 바꿉니다. 일반적인 interactive coding tool, support copilot, 구조화된 document Q&A, 중간 규모 planning agent라면 많은 요청이 이 경계 아래에 머물고, Gemini의 가격 차이는 크게 느껴집니다. 반대로 거대한 저장소, 긴 법률 문서 묶음, massive research packet을 자주 한 번에 넣는다면 Gemini의 가격은 올라갑니다. 그래도 Opus보다 싸지만, 격차는 "압도적 승리"가 아니라 품질과 함께 해석해야 하는 좁은 마진이 됩니다.
batch와 caching을 고려하면 비교는 더 흥미로워집니다. Google은 Gemini 3.1 Pro Preview에 대해 <=200k 에서 $1/$6, >200k 에서 $2/$9 의 batch pricing 을 공개합니다. Anthropic은 Opus 4.6 batch를 $2.50/$12.50 으로 둡니다. repository indexing, 대규모 추출, 야간 분석 같은 비동기 workload에서는 두 모델 모두 표준 가격보다 훨씬 매력적이 되지만, 여전히 Gemini가 더 저렴합니다. caching은 Google이 명시적 비용과 저장 모델을 쓰고, Anthropic은 write multiplier와 매우 낮은 read multiplier를 씁니다. 한 줄 비교는 어렵지만 결론은 단순합니다. 같은 정적 컨텍스트를 반복 전송하지 않게 설계하면 두 벤더 모두 훨씬 경제적으로 변합니다.
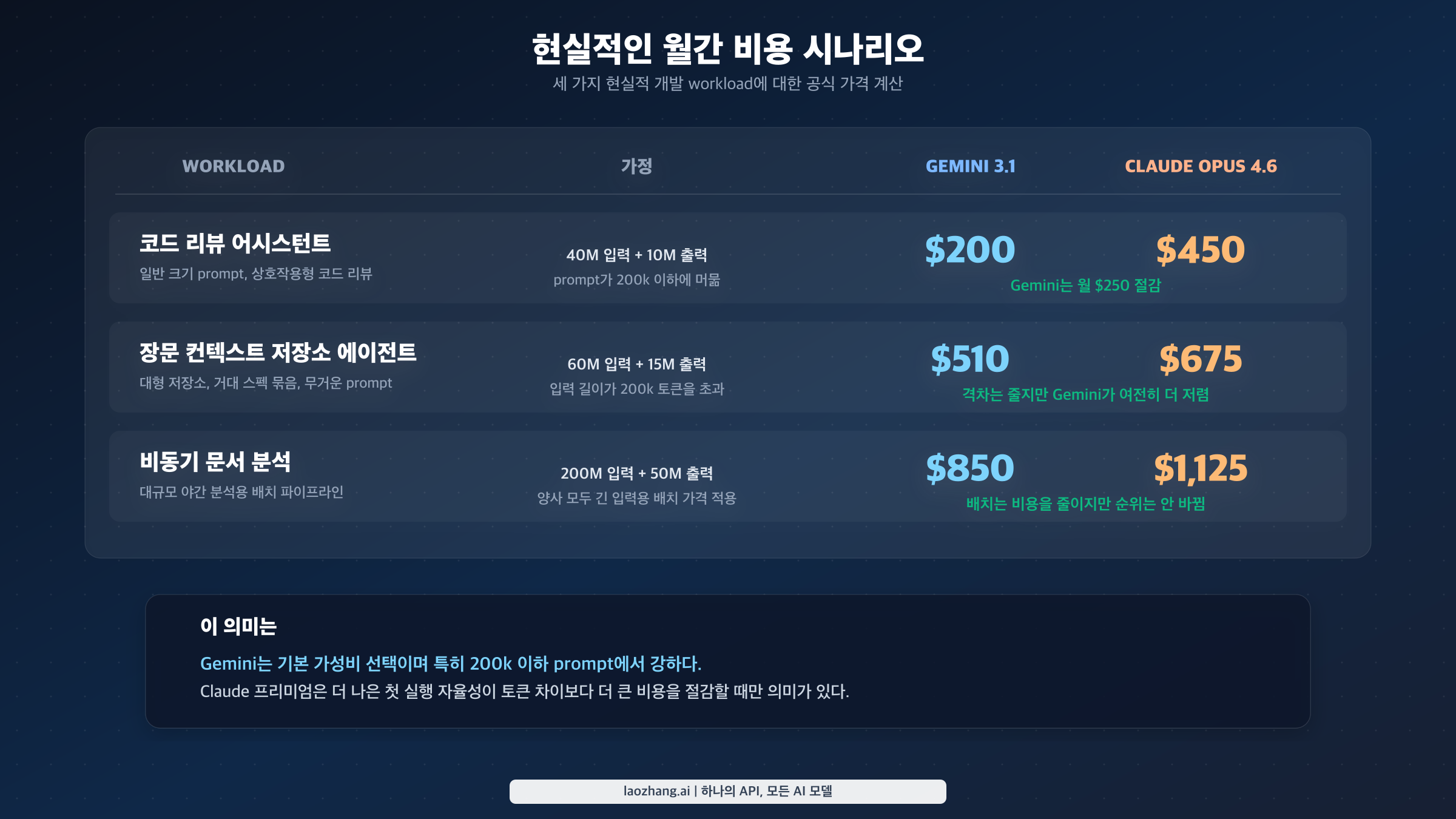
이 차이를 월 단위 시나리오로 보면 더 명확합니다.
| 워크로드 | 가정 | Gemini 3.1 Pro Preview | Claude Opus 4.6 |
|---|---|---|---|
| Code review assistant | 40M input, 10M output, prompt <=200k | $200 | $450 |
| Long-context repo agent | 60M input, 15M output, prompt >200k | $510 | $675 |
| Async document analysis (batch) | 200M input, 50M output, 긴 prompt batch 사용 | $850 | $1,125 |
이 숫자는 의도적으로 단순화했습니다. search grounding 비용, cached context 저장 비용, 그리고 모델 품질 평가는 포함하지 않았습니다. 보여 주려는 것은 가격의 모양입니다. 일반 프롬프트에서는 Gemini가 두 배 이상 효율적입니다. 장문 컨텍스트에서는 더 비싼 tier로 넘어가면서 격차가 줄어듭니다. batch 모드에서는 둘 다 부담이 줄지만 순위 자체는 바뀌지 않습니다.
컨텍스트는 이 가격을 어떻게 해석할지를 바꿉니다. Gemini 3.1 Pro Preview는 1,048,576 token 입력 한도 를 공개된 기본값으로 제공합니다. Anthropic의 overview는 Opus 4.6을 200k context 모델처럼 보여 주고, 많은 팀은 우선 그 값을 기본 운영 전제로 삼을 것입니다. launch post에 1M-token context window 가 beta라고 쓰여 있더라도 말입니다. 애플리케이션 로드맵이 백만 token 입력을 정상적인 프로덕션 동작으로 가정한다면 Gemini 쪽 문서가 훨씬 더 명확합니다. 반대로 긴 생성 출력이 중요하다면 Claude의 128k output 이 강한 반대 방향 논거가 됩니다.
또 하나 더 중요한 세부 사항이 있습니다. Google은 Grounding with Google Search 를 무료 할당량 이후 별도 과금합니다. Anthropic의 가격 페이지는 token, caching, fast mode, batch, regional inference에 더 집중합니다. 따라서 grounded search가 핵심 가치인 워크플로우에서는 Gemini가 특히 매력적이지만, token 가격만 전체 비용이라고 보면 안 됩니다. 이 부분까지 포함해 Gemini를 설계 관점에서 보고 싶다면 Gemini 3.1 Pro Preview access guide를 함께 보는 편이 낫습니다.
코딩과 에이전트 실행: Claude Opus 4.6이 비싸도 먼저 볼 가치가 있는 이유
결론: Claude는 코드와 도구 실행에서 첫 시도의 품질이 바로 비용으로 이어지는 팀에게 더 적합한 출발점입니다.
근거: Anthropic이 고난도 코딩, 디버깅, 장기 에이전트 실행에 대해 더 강한 공개 근거를 제시합니다.
선택 기준: 실패한 첫 응답을 사람이 많이 수리해야 하는 구조라면 Claude의 프리미엄을 먼저 검증해야 합니다.
가격이 전부였다면 이 글은 이미 끝났을 것입니다. 그럼에도 Opus 4.6을 진지하게 봐야 하는 이유는 Claude의 공식 근거가 실제로 가장 비싼 실패 지점, 즉 코딩, tool use, 다단계 agent behavior에 매우 강하기 때문입니다. Anthropic의 launch post는 이 부분에서 거의 모호함이 없습니다. Opus 4.6이 coding skill을 개선했고, 더 신중하게 계획하며, agentic task를 더 오래 유지하고, 더 큰 codebase에서 더 안정적이며, code review와 debugging에서 자기 실수를 더 잘 찾는다고 말합니다. 이것은 단순한 마케팅 수사가 아니라, 코딩 에이전트가 실제 팀 동료가 될지, 아니면 뒷정리를 늘리는 비싼 도구가 될지를 가르는 행동 특성입니다.
중요한 점은 잘못된 모델의 비용이 token 청구서가 아니라 사람의 수리 루프 일 수 있다는 것입니다. 긴 컨텍스트 모델이 저렴하더라도 잘못된 도구 호출을 반복하고, 코드베이스 전반의 부작용을 놓치고, 여러 번의 재시도 끝에야 수렴한다면 결국 시스템 전체 비용은 더 비쌀 수 있습니다. 그런 상황에서는 Opus의 프리미엄이 충분히 합리적입니다. 한 번에 쓸 만한 결과가 나오는 편이 세 번의 보통 수준 시도보다 더 쌀 수 있습니다. 특히 그 실패가 token이 아니라 개발자 시간, CI 분, 리뷰 집중력을 소모한다면 더욱 그렇습니다.
공식 증거의 비대칭성도 여기서 다시 중요합니다. Google은 Gemini 3.1 Pro Preview를 software engineering behavior, groundedness, token efficiency, precise tool usage가 필요한 agentic workflow에 맞춰 최적화했다고 말합니다. 이는 의미 있고 유망한 정보입니다. 하지만 이 글에서 사용한 공식 소스 범위 안에서는, Google이 Anthropic만큼 강하게 "Gemini가 최고의 coding autonomy 모델"이라고 공개 benchmark 기반으로 주장하지는 않습니다. 따라서 코딩 중심 제품에서 비싼 평가 시간을 어디에 먼저 쓸지를 정해야 한다면, Opus 쪽이 더 강한 first-party proof를 갖고 있다고 보는 편이 맞습니다. Gemini는 비용 민감한 장문 컨텍스트 평가에, Opus는 프리미엄 coding evaluation에 더 적합합니다.
다르게 말하면 Opus 4.6의 가치는 모델이 한 번의 요청에서 더 많은 책임을 져야 할 때 가장 커집니다. patch를 작성하고, 도구를 조율하고, 여러 파일에 걸쳐 디버깅하고, 사람이 계속 곁에서 감시하지 않아도 될 만큼 신뢰할 수 있는 연구 요약을 만들어야 할 때입니다. 반대로 모델 역할이 긴 입력을 ingest하고, 분류하고, 선별하고, 1차 분석을 한 뒤 다음 단계의 모델이나 사람이 이어받는 것이라면 Gemini의 경제성이 더 자연스럽습니다.
이 점을 무시하고 코딩을 benchmark 표의 한 줄로 압축해 버리는 글은 독자를 잘못 이끕니다. 실제 소프트웨어 엔지니어링은 코드 생성만이 아닙니다. 범위 설정, 도구 선택, 저장소 탐색, 오류 복구, code review, 그리고 여러 단계 실행 중 일관성을 유지하는 능력까지 포함됩니다. Anthropic은 Opus 4.6에서 바로 그 문제를 정면으로 다루고 있습니다. Google의 Gemini 메시지는 더 긴 컨텍스트, groundedness, 정밀한 도구 사용이 필요한 엔지니어링 워크플로우 쪽에 가깝습니다. 서로 겹치지만 동일하지는 않으며, 프리미엄이 타당해지는지는 제품이 어느 쪽에 더 가까운가에 달려 있습니다.
긴 컨텍스트, 근거 기반 분석, 큰 입력에서 Gemini가 앞서는 이유
결론: Gemini는 큰 입력을 읽고 묶고 정리하는 작업에서 구조적으로 더 자연스러운 기본 모델입니다.
근거: 백만 token 입력, 더 낮은 가격, 명시적인 grounding 비용 구조가 함께 문서화되어 있습니다.
선택 기준: 시스템이 코드를 직접 쓰기보다 자료를 많이 읽고 정리하고 검증하는 편이면 Gemini부터 시작하세요.
Gemini의 가장 분명한 구조적 강점은 "충분히 괜찮고 저렴하다"가 아닙니다. 공개된 백만 token 입력 용량, 더 낮은 가격, 그리고 명시적인 grounding 경제성이 함께 묶여 있어, 큰 입력 시스템의 기본 모델로 설득하기 쉽다는 점입니다. 내부 리서치 도구, repository explainer, 계약 분석 파이프라인, transcript intelligence, 혹은 대량의 소스 자료를 한 번에 넣어야 하는 워크플로우라면 Gemini 3.1 Pro Preview는 1차 원리만 봐도 꽤 매력적입니다. Opus 급 가격을 지불하지 않고 큰 컨텍스트 창을 얻을 수 있고, 200k 를 넘는 tier에서도 여전히 Claude Opus보다 저렴합니다.
Google의 공식 포지셔닝도 이 용도와 잘 맞습니다. model page는 improved token efficiency, more grounded and factually consistent behavior, 그리고 실제 작업에서 precise tool usage가 필요한 agentic workflow를 강조합니다. 이것은 "최고의 자율 코딩 모델"이라기보다 "실제 제품 업무를 위한 강한 장문 컨텍스트 reasoning engine"에 가깝게 읽힙니다. pricing page가 search grounding 비용을 명시하는 것도, 방대한 컨텍스트와 최신 정보 검색을 결합해야 하는 애플리케이션에는 유용합니다. 예산 측면에서는 번거롭지만, 프로덕션 시스템을 솔직하게 설계하는 데는 오히려 도움이 됩니다.
입력이 커질수록 Gemini의 장점은 더 커집니다. 많은 장문 컨텍스트 워크로드는 겉으로는 reasoning 문제처럼 보이지만, 실제 병목은 ingestion과 recall입니다. 충분한 양의 소스 자료를 하나의 일관된 프레임 안에 담아낼 수 있느냐가 핵심입니다. 그래서 공개된 1,048,576 입력 한도와 기본 200k context 표기 사이의 차이는 운영상 매우 중요합니다. Opus의 1M beta context가 특정 환경에서 잘 동작하더라도, 오늘 시점에 "백만 token 이야기를 운영으로 옮기기 쉬운" 모델은 Gemini입니다.
그렇다고 마지막 단계까지 Gemini가 자동으로 이긴다는 뜻은 아닙니다. 실제로는 Gemini로 ingestion, filtering, large-context synthesis를 하고, 가장 어려운 코딩이나 자율 실행 단계는 Claude로 넘기는 구조가 최선인 경우가 많습니다. 이것은 과한 설계가 아니라, 긴 컨텍스트 분석과 도구 중심 실행이라는 서로 다른 병목에 서로 다른 강점을 배치하는 자연스러운 분해입니다.
피해야 할 미묘한 실수는 Gemini가 싸다는 이유로 스택의 모든 단계에 억지로 넣는 것입니다. Google 문서에서 나와야 할 결론은 "Gemini가 Claude를 대체한다"가 아니라, "context size, groundedness, 직접 비용이 premium first-pass autonomy보다 더 중요할 때 Gemini를 기본 후보로 삼아야 한다"는 것입니다. 많은 엔지니어링 조직에서 이것만으로도 이미 상당한 비중의 프로덕션 트래픽을 설명합니다.
프로덕션 현실: Preview, beta, 그리고 이 라벨이 실제로 뜻하는 것
결론: 상태 라벨은 마케팅 문구가 아니라 배포 전략을 바꾸는 운영 신호입니다.
근거: Gemini 3.1 Pro는 여전히 Preview이고, Opus 4.6의 1M 컨텍스트는 여전히 beta 경로로 설명됩니다.
선택 기준: Gemini는 통제된 rollout과 fallback이 있는 환경에, Claude의 1M 은 검증 전까지 beta capacity로 보는 편이 안전합니다.
나쁜 모델 결정을 가장 빨리 만드는 방법은 상태 라벨을 마케팅 장식처럼 취급하는 것입니다. 그것은 deployment signal입니다. Google이 Gemini 3.1 Pro를 아직 Preview 로 표시한다는 사실은, 사용 방식에 바로 영향을 줍니다. Preview는 "쓸 수 없다"가 아닙니다. 더 빠른 반복, 행동 변화 가능성, 그리고 안정적인 production baseline보다 더 강한 회귀 테스트 필요성을 받아들여야 한다는 뜻입니다. 내부 도구, evaluation loop, fallback 경로가 있는 장문 컨텍스트 분석 시스템, 혹은 rollout을 엄격히 통제하는 제품에는 충분히 수용 가능합니다. 하지만 모델이 mission-critical 외부 워크플로우의 단일 truth source라면 이야기가 달라집니다.
Anthropic의 상황은 다르지만 무위험은 아닙니다. Opus 4.6 자체는 current flagship Claude 모델로 분명히 포지셔닝되어 있고, model overview도 일반적인 프로덕션 계획에 쓸 만합니다. 그러나 백만 token 이야기는 launch post에서 여전히 beta 라고 되어 있습니다. 따라서 "Claude Opus 4.6은 어디서나 완전히 정상화된 1M context를 가진다"라고 아키텍처 문서에 적는 것은, 자기 환경에서 beta path를 확인한 뒤에나 해야 합니다. 가장 안전한 표현은 이 글에서 사용한 것처럼, overview 표의 기본값은 200k, 1M 은 launch announcement 기준 beta capability라는 설명입니다.
그러면 현실적인 운영 자세는 이렇게 정리됩니다.
| 배포 관점 | Gemini 3.1 Pro Preview | Claude Opus 4.6 |
|---|---|---|
| 공식 상태 신호 | Preview | 현재 플래그십 |
| 가장 안전한 기본 가정 | 백만 token 입력은 문서화된 제품 능력의 일부 | 200k context가 문서화된 기본값이며 1M 은 beta capacity로 취급 |
| 지금 더 자연스러운 용도 | 장문 컨텍스트 내부 도구, 평가 루프, grounded analysis | 프리미엄 코딩 에이전트, 고자율 작업, 긴 출력 합성 |
흥미로운 점은, 업무가 맞다면 어느 라벨도 자동 탈락 사유가 되어서는 안 된다는 것입니다. Preview 모델도 문서화된 강점이 일과 잘 맞고 fallback을 설계했다면 올바른 선택이 될 수 있습니다. beta 컨텍스트 확장도 숨은 보장이 아니라 optional capacity로 다루면 충분히 유용할 수 있습니다. 하면 안 되는 것은 "둘 다 1M이니 상태는 중요하지 않다"라고 단순화하는 것입니다. 상태는 벤더가 아직 actively shaping 중인 행동에 여러분의 아키텍처가 얼마나 기대고 있는지를 알려 줍니다.
이런 운영상의 미묘한 차이가 스택 전체에서 얼마나 중요한지 잘 판단되지 않는다면, 그것 자체가 단일 모델 commitment를 피해야 한다는 신호일 수 있습니다. 두 모델 모두 reachable하게 두고, 각 모델의 문서가 가장 강한 단계에서 쓰는 편이 낫습니다. 비대칭적인 증거에서 억지로 permanent winner를 뽑아내는 것보다 안전합니다.
그래서 무엇을 선택해야 하는가?

여기까지 오면 추천은 꽤 명확합니다. Gemini 3.1 Pro Preview를 먼저 고를 상황은 거대한 프롬프트를 합리적인 가격으로 처리해야 할 때, grounded research나 document-analysis flow를 구축할 때, 혹은 매 요청마다 Opus 요금을 내지 않고 장문 컨텍스트 제품 가설을 실험하고 싶을 때입니다. 높은 볼륨의 대부분이 ingestion, filtering, retrieval-heavy analysis, first-pass engineering assistance라면 Gemini는 자연스러운 시작점입니다.
Claude Opus 4.6을 먼저 고를 상황은 제품의 hardest part가 agentic coding, tool orchestration, code review, 대형 저장소 디버깅, 혹은 첫 번째 시도가 틀리면 비용이 크게 드는 premium reasoning일 때입니다. 이 영역에서는 Anthropic의 공식 케이스가 더 강합니다. 모델의 실수가 manual repair, retry loop, 개발자 신뢰 하락으로 이어진다면, Claude의 프리미엄은 가격표보다 훨씬 더 쉽게 정당화됩니다.
둘 다 라우팅해야 하는 상황은 시스템이 사실상 두 단계로 이루어져 있을 때입니다. 하나는 고볼륨 장문 컨텍스트 단계, 다른 하나는 더 좁지만 품질 민감도가 높은 실행 단계입니다. 2026년 많은 기술 팀에게는 이것이 가장 좋은 답일 가능성이 높습니다. 넓은 funnel을 Gemini로 처리하고, 더 좁지만 가치가 높은 실행 단계에서 Claude를 사용하는 방식입니다. 운영 단순성 때문에 한 모델에 모든 일을 맡기고 싶을 수 있지만, 그 단순함이 종종 성능과 비용 양쪽을 희생시킵니다.
여기서 product mention도 실제로 유용한 형태가 됩니다. Google과 Anthropic 둘 다 유지하되, 처음부터 키 관리, 청구, routing glue를 별도로 운영하고 싶지 않다면 laozhang.ai 같은 unified gateway가 실무 부담을 줄여 줍니다. 핵심 가치는 "더 싼 마법"이 아니라 dual-model architecture를 테스트하고 유지하기 쉽게 만든다는 점입니다.
더 큰 패턴은, 2026년의 좋은 답이 특정 벤더에 대한 영구 충성이 아니라 workload strategy라는 점입니다. 이 글을 읽고 진짜 질문이 두 모델 비교보다 더 크다는 생각이 들었다면, 다음 단계는 더 좁은 benchmark 글이 아니라 이 주요 프로바이더 API 비교입니다.
시간을 낭비하지 않는 평가 방법
이 비교가 온라인에서 자주 왜곡되는 이유 중 하나는, 팀들이 추상적 논쟁으로 결론을 내리려 하고 disciplined evaluation plan으로 풀지 않기 때문입니다. Gemini 3.1 Pro Preview와 Claude Opus 4.6의 올바른 평가는 "둘 다에게 멋진 프롬프트 하나를 던져 보고 더 좋아 보이는 답을 고른다"가 아닙니다. 실제 프로덕션에서 돈이 나갈 workload bucket별로 나눠서 평가해야 합니다. 이렇게 나누지 않으면 잘못된 것을 benchmark하고, 데모 작업에 맞춰 아키텍처를 과적합하게 됩니다.
가장 깔끔한 방법은 세 개의 workload track 을 만드는 것입니다. 첫째는 large-context synthesis track 입니다. 긴 문서, 긴 저장소, research packet, 명세서 묶음 등으로 각 모델이 큰 입력을 얼마나 잘 ingest하고 reasoning하는지 봅니다. 둘째는 coding and agent track 입니다. multi-file 변경, tool-using task, debugging, code review, 반복적인 저장소 작업을 통해 행동하면서도 일관성을 유지하는지 봅니다. 셋째는 grounded analysis track 입니다. 외부 정보를 사용하거나 최신 자료를 교차 확인해야 하는 작업을 넣어, 정적 프롬프트 밖의 세계와 연결되는 순간을 평가합니다. 이 세 가지는 이 글이 말해 온 tradeoff를 정확히 재현합니다.
그리고 측정해야 할 것은 추상적 answer quality가 아니라 first-pass usefulness 입니다. 각 작업마다 최소 네 가지 숫자를 보세요. 첫 응답이 바로 사용 가능했는가, 몇 번의 retry나 correction이 필요했는가, 총 token 비용은 얼마였는가, 사람이 복구하는 데 얼마나 시간이 들었는가. 앞의 두 수치는 Claude의 프리미엄이 실제 execution quality로 돌아오는지 알려 주고, 세 번째는 Gemini의 저가가 200k 를 넘은 뒤에도 의미가 있는지 보여 줍니다. 네 번째는 공개 비교에서 가장 자주 빠지는 지표입니다. API 비용이 더 싼 모델이 전체 시스템 비용도 더 싸다는 뜻은 아닙니다.
Gemini 평가 안에는 프롬프트 길이 분리 를 강제로 넣는 편이 좋습니다. 하나는 분명히 200k 미만인 bucket, 다른 하나는 분명히 그 이상인 bucket을 만드세요. 그렇지 않으면 저가 tier만 보고 "Gemini가 엄청나게 싸다"는 결론으로 쉽게 흘러갑니다. Claude 쪽에서는 공개된 128k output limit이 한 번의 응답으로 끝낼 수 있는 작업 양을 얼마나 바꾸는지 세심하게 봐야 합니다. 긴 보고서, 대형 코드 변환, 방대한 structured output이 자주 필요한 제품이라면 이 출력 여유가 benchmark 몇 줄보다 더 중요합니다.
평가 하네스 자체도 reversible하게 설계해야 합니다. 같은 instructions, 같은 scoring rubric, 가능한 한 같은 주변 인프라를 쓰세요. 장차 두 제공자를 route할 가능성이 있다면 prompt format과 success criteria도 portable하게 유지해야 합니다. 이 지점에서 자가 router든 laozhang.ai 같은 gateway든 adapter layer가 실제 가치를 냅니다. 목표는 편의성 자체가 아니라, 모델 지형이 아직 빠르게 변하는 동안 optionality를 지키는 것입니다.
제대로 평가하면 결과는 인터넷 헤드라인보다 대개 덜 극적입니다. Gemini가 스택의 한 부분에서 분명히 낫고, Claude가 다른 부분에서 분명히 낫고, 진짜 이득은 두 경로를 모두 유지하는 데서 나옵니다. 단일 승자를 억지로 만들기보다, 가격과 한도와 모델 행동이 계속 변해도 따라갈 수 있는 시스템 설계를 얻게 됩니다.
아키텍처를 실제로 바꾸는 통합상의 차이
이 두 모델 사이에서 가장 중요한 엔지니어링 차이는 headline capability가 아니라, routing layer, 예산 모델, 프로덕션 모니터링을 바꾸는 세부 사항입니다.
첫째, Gemini의 가격 임계값은 routing 전에 token counting이 필요하다는 뜻입니다. 요청이 200k prompt token을 자주 넘는다면 Gemini의 낮은 headline price를 상수처럼 취급할 수 없습니다. 이것은 Gemini가 나쁜 거래라는 뜻이 아니라, model router가 prompt size를 의사결정 입력으로 받아야 한다는 뜻입니다. 이를 무시한 시스템은 비용 추정도 escalation rule도 흔들립니다.
둘째, Claude의 output limit은 한 번에 맡길 수 있는 일의 크기를 바꿉니다. Opus 4.6의 128k max output은 patch generation, 장문 합성, 대형 structured report 생성에 직접 영향을 줍니다. Gemini의 65,536 도 작지는 않지만 차이는 분명합니다.
셋째, grounding과 caching 경제성은 모델별 기능이지 일반적인 "최적화"가 아닙니다. Google은 search grounding 비용을 명시적으로 드러내고, Anthropic은 prompt caching multiplier와 regional inference premium을 더 명시적으로 보여 줍니다. 진지한 프로덕션 경제성을 원한다면 이것들을 별도 항목으로 모델링해야 합니다.
넷째, 하나의 모델에 표준화하기 전에 evaluation harness를 먼저 표준화해야 합니다. prompt, test case, success criteria를 portable하게 유지하면 모델 선택은 계속 되돌릴 수 있습니다. 두 제공자를 모두 route할 가능성이 있다면 docs.laozhang.ai 같은 진입점을 포함한 통합 레이어가 이 가역성을 지키는 데 도움을 줍니다.
핵심 교훈은 단순합니다. 모델 선택을 일회성 브랜드 결정처럼 설계하지 마십시오. 컨텍스트 크기, 자율성 품질, 가격 곡선은 계속 움직일 것입니다. 그 전제로 시스템을 설계해야 합니다.
자주 묻는 질문
Gemini 3.1 Pro Preview가 Claude Opus 4.6보다 더 저렴한가요?
네. 공식 가격 기준으로 Gemini가 두 tier 모두 더 저렴합니다. 200k token 이하에서는 Gemini가 $2/$12, Opus가 $5/$25 입니다. 200k 를 넘으면 Gemini는 $4/$18 으로 올라가지만 여전히 더 쌉니다.
Claude Opus 4.6이 코딩에 더 좋은가요?
공식 근거만 놓고 보면 그렇습니다. Anthropic은 coding, debugging, code review, computer use, long-running agentic work를 직접 강조합니다. Google도 Gemini를 software engineering용으로 포지셔닝하지만, 이 글에서 사용한 공식 소스에서는 같은 강도의 benchmark 중심 주장을 내놓지는 않습니다.
Claude Opus 4.6은 정말 1M context인가요?
Anthropic의 launch post는 1M token context window를 beta라고 말합니다. 반면 model overview는 200k context를 메인 표에 표시합니다. 가장 안전한 프로덕션 해석은 200k 가 문서화된 기본값이고, 1M 은 의존하기 전에 직접 검증해야 할 beta capability라는 것입니다.
Gemini가 아직 Preview라면 피해야 하나요?
그렇지는 않습니다. Preview는 rollout 방식을 바꿔야 한다는 의미이지 자동 탈락 사유는 아닙니다. 내부 도구, 평가 루프, 장문 컨텍스트 분석, fallback이 가능한 워크로드에서는 여전히 강한 선택지입니다.
대부분의 팀은 하나만 골라야 하나요, 아니면 둘 다 라우팅해야 하나요?
많은 팀에게는 routing이 더 합리적입니다. Gemini는 고볼륨 장문 컨텍스트 작업의 첫 후보이고, Claude는 프리미엄 코딩과 고자율 실행의 첫 후보입니다. 시스템이 두 종류의 작업을 모두 가진다면, 단일 모델 고정보다 두 경로를 유지하는 편이 더 이성적입니다.