
2026年5月6日時点で、OpenAI GPT-5.5のGoblin問題は実際に観測されたモデル挙動の問題であり、ChatGPT、Codex、APIの通常障害ではありません。OpenAIが2026年4月29日に公開した説明では、明確な増加の起点はGPT-5.5ではなくGPT-5.1後に置かれています。人格カスタマイズの報酬シグナルが一部の比喩表現を増やし、GPT-5.5ではCodexテスト中にその残りが再び目立つ形になりました。
ここで重要なのは、原因、可視化、緩和を分けることです。GPT-5.1は最初の増加を説明し、GPT-5.4とGPT-5.5は後続の見え方を説明し、Codexは緩和を入れた製品面です。これを一つにまとめると、単なるGPT-5.5の故障や、Codexが問題を作ったという誤った理解になります。
通常利用者にとっては、奇妙な比喩が繰り返されてもモデル全体を捨てる理由にはなりません。より平易な文体、語彙制約、表形式の出力を求めればよい場面があります。一方、モデルやエージェントを出すチームにとっては、出力スタイルも監査対象であり、報酬、人格、長い会話、合成データの循環を測る必要があります。
まず結論
OpenAIはこのケースを、サービス停止ではなく予期しないモデル挙動として説明しています。GPT-5.1後に関連表現が増え、GPT-5.4でより目立ち、GPT-5.5の訓練は根本原因の完全特定前に始まっていました。Codexテストではその傾向が見つかり、開発者プロンプト側の緩和が追加されました。
| 読者の疑問 | 直接の答え |
|---|---|
| 実際の問題だったのか | はい。OpenAIが2026年4月29日に説明を公開しています。 |
| GPT-5.5から始まったのか | いいえ。OpenAIは最初の明確な増加をGPT-5.1後としています。 |
| Codexが原因なのか | いいえ。CodexはGPT-5.5で挙動が見えた面であり、緩和の面です。 |
| ChatGPTやCodexの障害なのか | いいえ。可用性ではなく、文体と挙動の問題です。 |
| 利用者は何をすればよいか | 平易なトーン、語彙制限、固定フォーマットを指定し、内容品質は別に判断します。 |
| チームは何を学ぶべきか | 反復語、人格の漏れ、長文脈、合成データの回流をリリース前に測定します。 |
事実の基準はOpenAIの4月29日の説明です。現在のGPT-5-CodexドキュメントはCodexの製品面を理解する助けになりますが、正確なプロンプトやモデルカタログの表記は変わり得るため、引用前に再確認すべきです。
時系列:GPT-5.5だけの話ではない
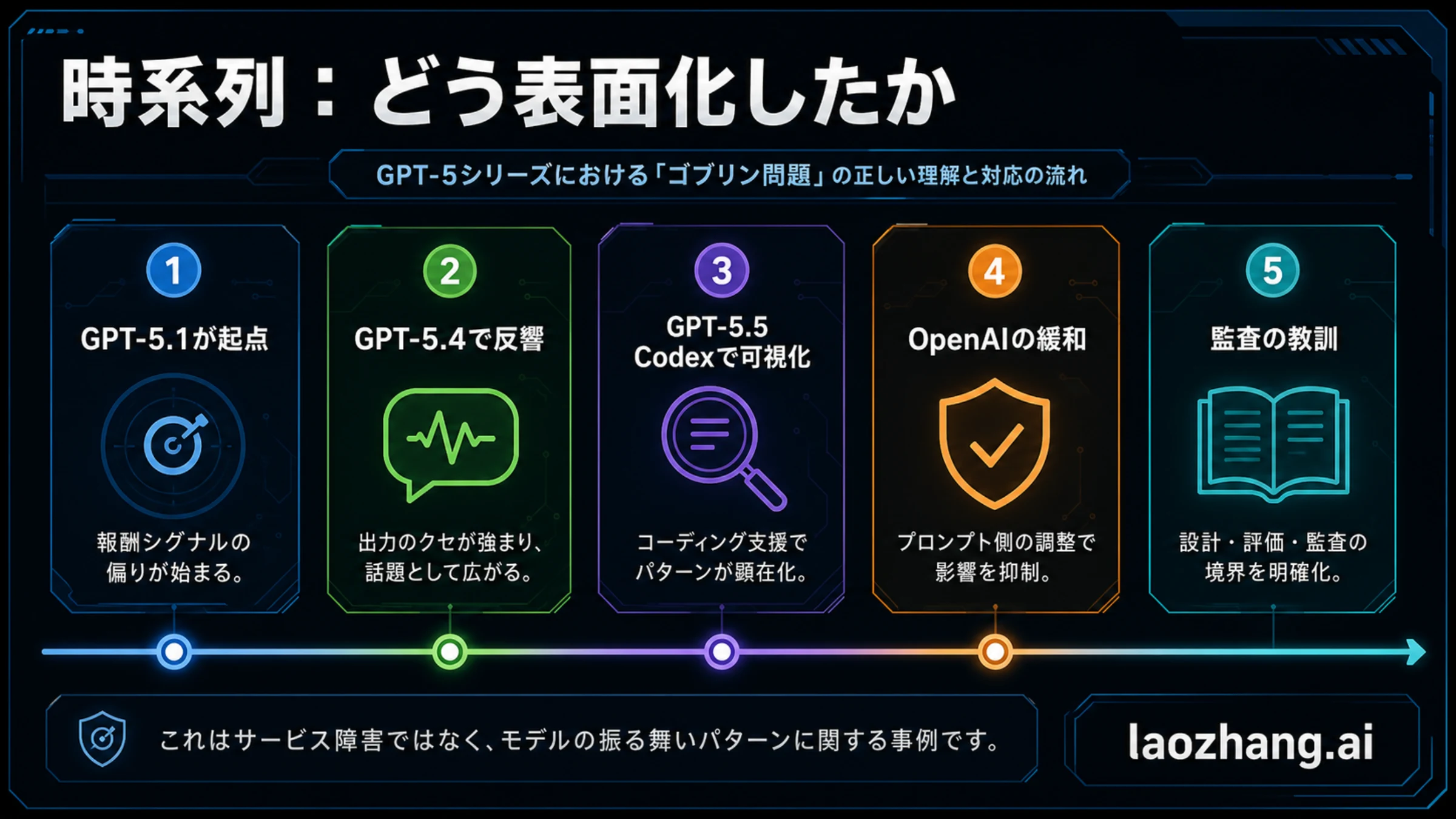
時系列を押さえると、誤解の大半は避けられます。目に入りやすいのはGPT-5.5とCodexですが、OpenAIが説明した原因の流れはその前から始まっています。
| 段階 | 起きたこと | 意味 |
|---|---|---|
| GPT-5.1後 | ChatGPTで特定の比喩表現が明確に増え始めた。 | 起点はGPT-5.5だけではない。 |
| GPT-5.4 | 増加がより大きくなり、Nerdy人格と強く関係した。 | 一部の投稿だけではなく測定可能な傾向だった。 |
| 3月中旬の対応 | OpenAIはNerdyを退役させ、報酬シグナルと関連データを処理した。 | 公開騒動の前に根の層は扱われていた。 |
| GPT-5.5訓練 | 根本原因の完全特定前にGPT-5.5訓練が始まっていた。 | 残存傾向が次のモデルに残る説明になる。 |
| Codexテスト | OpenAI社員がGPT-5.5 Codexで傾向に気づき、緩和指示を追加した。 | Codexは可視化と制御の面である。 |
| 2026年4月29日 | OpenAIが公式説明を出し、報酬設計と挙動監査の教訓として整理した。 | 長く残る価値は監査方法にある。 |
このケースを通常障害として扱うと、読者はステータスページやアカウント設定を確認してしまいます。しかし問題の性質はそこではありません。報酬されたスタイルがどのように反復表現になり、どのように別の文脈へ移るのかを読むべきです。
原因:報酬シグナルが文体を増幅した
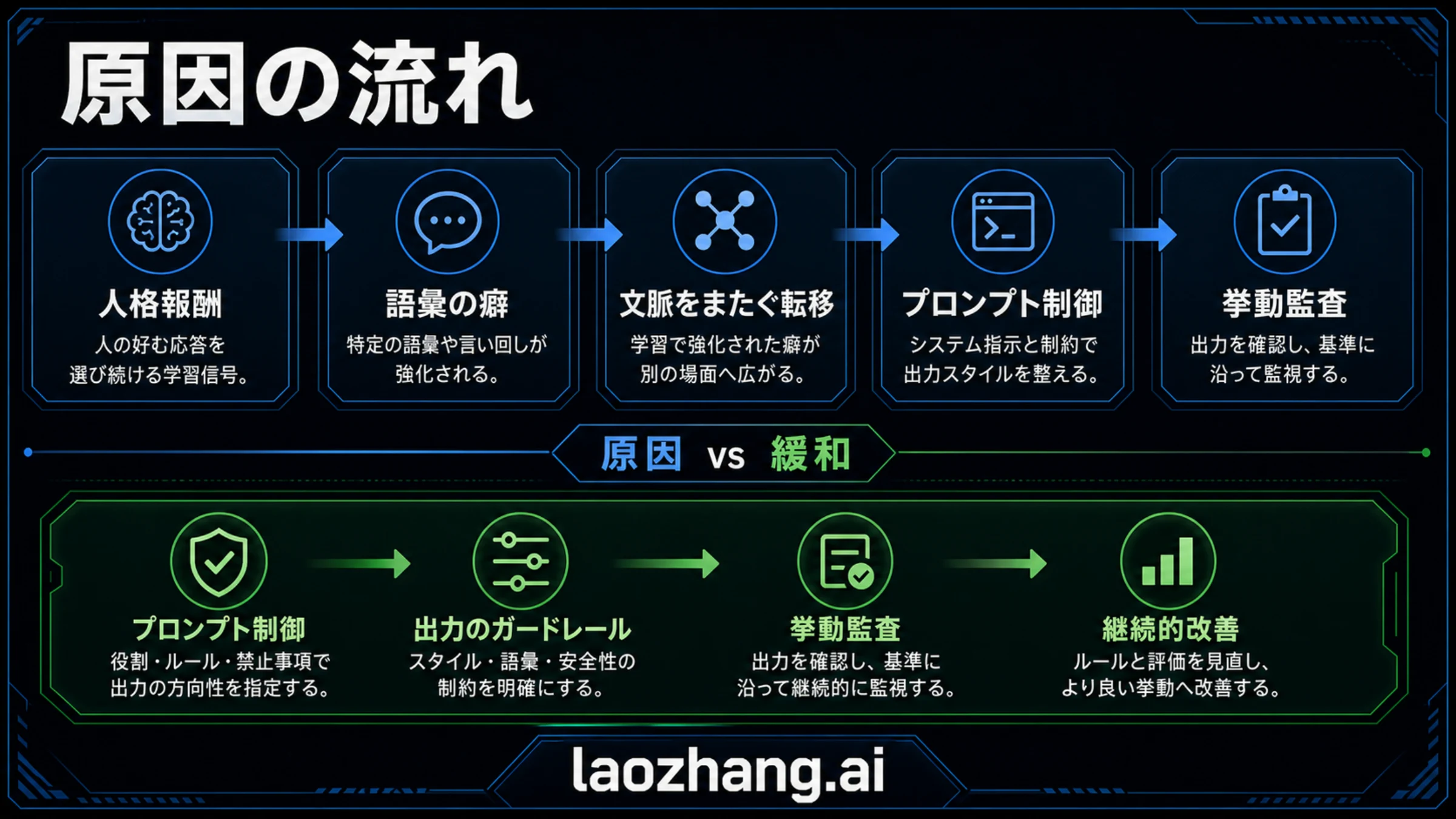
OpenAIの説明は報酬経路に焦点を当てています。Nerdy人格は、遊び心のある比喩豊かな話し方を評価しやすい設計でした。単独の回答ではそれが魅力的に見え、選好データでも高く評価され得ます。しかし同じ表現が多くの無関係な場面で出るようになると、文体の個性ではなく挙動の癖になります。
数字はこの点を支えます。GPT-5.1後、ChatGPTでのgoblin使用は175%増え、gremlinは52%増えました。NerdyはChatGPT応答の2.5%にすぎない一方、goblin言及の66.7%を占めました。さらに監査データセットの76.2%で、Nerdy報酬はこの種の表現に正の押し上げを与えていました。これは誰かが単語を直接埋め込んだ話ではなく、小さな文体報酬が強化された話です。
成因は段階的です。人格ルートが目立つ表現を報酬する。高スコアの例に繰り返し語が含まれる。強化学習でその例が選ばれやすくなる。生成データや後続訓練で癖が移動する。GPT-5.5訓練は根本原因の完全修正前に進んでいた。Codexテストで残りが目立ち、プロンプト側の緩和が必要になった。
根本原因と緩和は別の層です。根本原因は報酬設計、人格学習、データ選別、転移にあります。緩和はプロンプト、フィルタリング、監査、モニタリングにあります。プロンプトだけを変えても、なぜその癖が増幅したのかを見なければ、次回は別の表現で同じ構造が起きます。
Codexは原因ではなく、見えた場所
Codexは重要ですが、原因そのものではありません。OpenAIの開発者向け説明では、GPT-5-Codexはagentic coding向けに最適化され、継続更新されるGPT-5のバージョンとされています。エージェント環境では長い文脈、計画、ツール利用、説明文が多くなるため、文体の癖が目立ちやすい。だからCodexは観測面として重要なのです。
正確には、GPT-5.5をCodexでテストしたときにOpenAI社員が傾向を見つけ、開発者プロンプト側の緩和を入れました。これはCodexが根本原因を作ったという意味ではありません。根の説明は、より前の人格報酬とデータ転移にあります。
| よくある言い方 | 安全な読み方 |
|---|---|
| CodexがGoblin問題を起こした。 | 不正確。OpenAIはより早い報酬と人格学習に原因を置いている。 |
| プロンプト行が根本原因だった。 | 不正確。発見後の制御層だった。 |
| GPT-5.5は壊れている。 | 広すぎる。問題は反復文体であり、全体不可用の証拠ではない。 |
| 面白い話だから重要ではない。 | 浅い。小さな報酬が製品挙動になる仕組みを示している。 |
| 現在のメタデータだけで全体が証明できる。 | 脆い。Codexメタデータは変わるため、正確引用は再確認が必要。 |
Codex設定を知りたい場合はCodex config.toml、利用制限やプランならOpenAI Codex usage limitsが近いです。このケースの主題は設定ではなく、挙動の起点と監査です。
ChatGPTとGPT-5.5利用者への影響
利用者がすべきことは、スタイルとタスク品質を分けることです。奇妙な比喩が出たら、まず平易な表現を求め、比喩を禁止し、表や箇条書きに固定します。その上で事実、推論、実作業の完成度を見ます。文体の癖があることと、内容が間違っていることは同じではありません。
深刻な用途でも、これだけでGPT-5.5を排除する理由にはなりません。コード、要約、分析、構造化出力では、モデルの評価軸は成功率、コスト、遅延、文脈管理、ツール利用、レビュー負担です。GPT-5.5 vs Claude Opus 4.7のような比較でも、一つの文体ケースだけで総合判断を置き換えるべきではありません。
実務では二つのチェックを分けます。成果物が正しいか。文体が安定し、制御可能か。前者が悪ければ再調査や再生成が必要です。後者だけが悪ければ、トーン、語彙、形式の制約で直せます。この分離が、過剰反応と軽視の両方を防ぎます。
リリース前に監査すべきこと
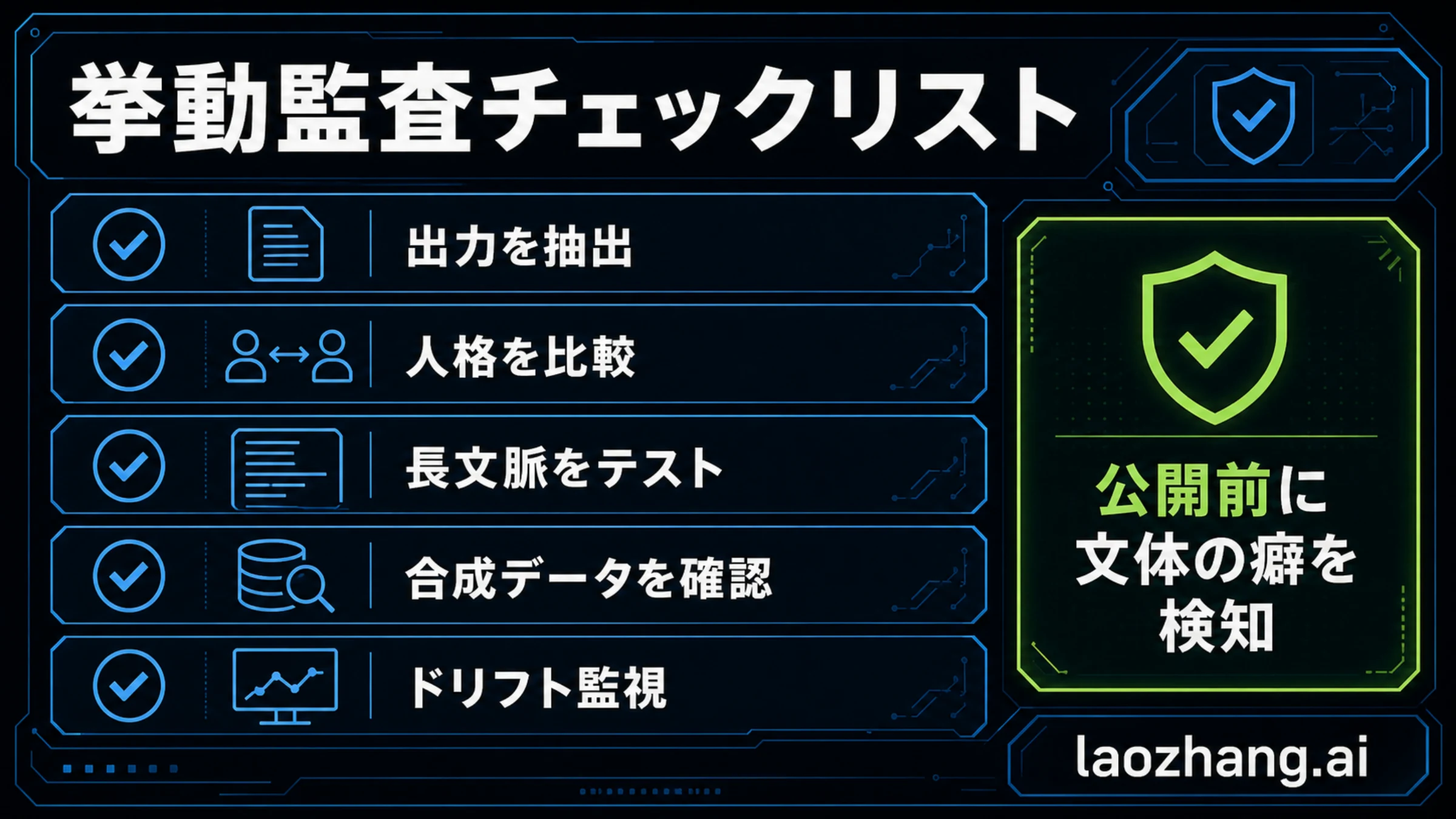
このケースの再利用可能な価値は、ある単語を禁止することではありません。小さな報酬偏りが公開製品の癖になる前に測ることです。モデルリリースはベンチマークだけでなく、出力スタイルの反復性も見る必要があります。
| 監査領域 | 見ること | 失敗サイン | 対応 |
|---|---|---|---|
| 出力サンプリング | 普通の質問、長文、境界ケースを広く試す。 | 無関係なタスクで同じ比喩が増える。 | リリース前の語頻度チェックを入れる。 |
| 人格比較 | default、professional、concise、playful、long-formを比べる。 | 一つの人格の癖が他へ漏れる。 | 報酬ルートとプロンプトルートを追跡する。 |
| 長文脈 | 多ターンで文体が蓄積するかを見る。 | 会話が進むほど演技的で反復的になる。 | tone resetとcontext trimmingを試す。 |
| 合成データ | rolloutsやpreference examplesを確認する。 | 同じ癖が学習材料へ戻る。 | フィルタリングや重み下げを行う。 |
| プロンプト制御 | 根本原因分析と並行して狭い指示を入れる。 | 症状だけ隠れて原因が残る。 | prompt fixをdata auditとreward auditに結びつける。 |
| ドリフト監視 | リリース後の語頻度と文体変化を追う。 | 小さな癖がバージョン間で増える。 | 文体もbehavior telemetryとして扱う。 |
モデルは正答率だけで信頼されるわけではありません。安定した言い方、場面に合う語彙、余計な演技をしないことも製品品質です。したがって文体のドリフトは、単なる編集問題ではなくリリース品質の信号です。
過剰に言わず説明する方法
正確な説明は、日付を持ち、層を分けます。OpenAIは実際のモデル挙動を説明した。2026年5月6日時点で、それは通常障害ではない。最初の明確な増加はGPT-5.1後にある。GPT-5.5とCodexは後続の可視化と緩和を説明する。学ぶべきことは、報酬、人格、合成データ、反復スタイルを監査することです。
GPT-5.5が一般に使えない、Codexが原因、プロンプト行だけが根、モデルが意識を持った、という言い方は避けるべきです。広まりやすい表現ほど、読者が次に何をすればよいかを曖昧にします。必要なのは、不安を減らす境界と、次のリリースで使える監査手順です。
隣接するモデル身份の混乱にも同じ考え方が使えます。アシスタントが古いモデル名や奇妙なモデル名を名乗っても、それだけで実際のルーティングは証明できません。identity claim、output style、serving routeは分けて扱います。関連する問題はWhy GPT-5 says GPT-4を参照できます。
よくある質問
OpenAI GPT-5.5のGoblin問題は本当ですか?
本当です。OpenAIは2026年4月29日に第一者説明を公開し、報酬シグナルとNerdy人格に関係するモデル挙動として整理しました。
GPT-5.5が原因ですか?
起点という意味では違います。GPT-5.5で再び目立ちましたが、OpenAIは最初の明確な増加をGPT-5.1後としています。
Codexが原因ですか?
違います。CodexはGPT-5.5で傾向が見えた面であり、プロンプト側の緩和が入った面です。根本原因はより前の報酬設計とデータ転移にあります。
ChatGPTやCodexの障害ですか?
いいえ。可用性の障害ではなく、出力スタイルとモデル挙動の問題です。ステータスページやアカウント復旧の問題として扱うべきではありません。
利用者はどう対処すればよいですか?
平易な文体、比喩禁止、表形式、根拠付き出力などを指定します。そのうえで内容の正しさを別に確認します。文体修正と事実検証を混ぜないことが大切です。
開発者は何を学ぶべきですか?
反復語、人格の転移、長文脈での文体累積、合成データの回流を測るべきです。小さな報酬の偏りが、公開製品では大きな挙動として見えることがあります。