
GPT-5 が GPT-4 と名乗ったからといって、それだけで ChatGPT が本当に GPT-4 に戻ったとは言えません。OpenAI は現在、これをかなり明確に説明しています。返信の中でモデルが自分をどう呼ぶかは生成テキストであり、誤っていることも、単に汎化された言い方であることもあります。もし UI に Used GPT-5 のようなメッセージ単位の注記が出ているなら、OpenAI はその注記の方を信頼すべきだと言っています。
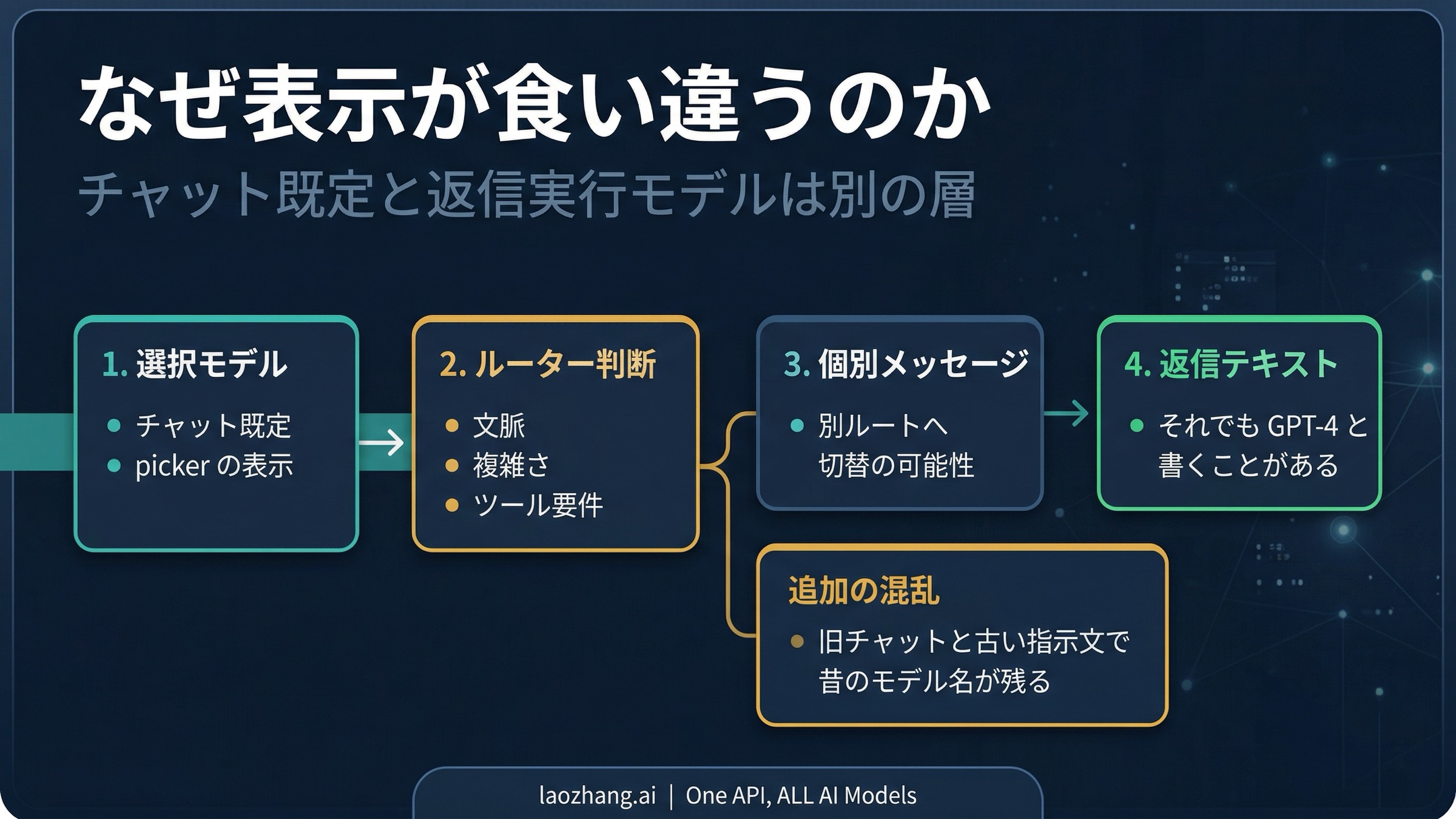
この種の混乱が今の ChatGPT で起きやすいのは、もはや「1つのチャット = 1つの固定モデル名」という単純な構造ではないからです。上部の picker はチャットの既定モデルを示しますが、個別のメッセージは別のモデルにルーティングされることがあります。さらに、古い会話はモデル退役後に新しい等価モデルへ移行されることがあり、Custom GPT や custom instructions に古い GPT-4 文言が残っていると、それが返信内に再び現れることもあります。これらの層が食い違ったとき、いちばん信用してはいけないのが、返信本文の中に出てくる自己紹介です。
この記事は 2026 年 4 月 1 日時点の OpenAI Help Center、ChatGPT Release Notes、GPT-5 System Card、OpenAI 開発者向けドキュメントを確認したうえでまとめています。
まず結論: どの信号を信じるべきか
最初に覚えるべきなのは次の優先順位です。
| 信号 | 実際に示しているもの | 信頼度 | 使いどころ |
|---|---|---|---|
| 返信内の「私は GPT-4 です」 | 生成された自己説明 | 低い | 手がかりにはなるが、決定的証拠にはしない |
Used GPT-5 のような注記 | そのメッセージを処理したモデル | 高い | ChatGPT ではまずこれを見る |
| 上部のモデル picker | そのチャットの既定モデル | 中くらい | 会話全体の既定値には useful だが、個別返信の確定には足りない |
| API の request / log | 実際に呼ばれたモデル | API では最も高い | 実装や検証ではこれを使う |

要点はシンプルです。ChatGPT では、OpenAI 自身がメッセージ単位の注記を authoritative とし、返信内の自己言及は fallible な生成テキストだと説明しています。API では、信頼すべきなのは request と log であって、モデルが自然言語で何と名乗ったかではありません。
なぜ今こうなりやすいのか: ChatGPT の GPT-5 はルーティングされる
OpenAI の公式説明そのものが、この混乱の大部分を説明しています。GPT-5 System Card では、GPT-5 はリアルタイムの router を持つ統合システムとして説明されています。router は文脈、複雑さ、ツール利用の必要性、明示的な意図などを見て、どのモデル経路を使うかを判断します。ChatGPT の release notes でも、GPT-5 は auto-switching を行う単一システムとして扱われ、その後 Instant、Thinking、legacy model access といった表面上の制御が追加されました。
つまり、今の ChatGPT における「モデル」という言葉は 1 層ではありません。チャットの既定モデル、ある 1 通のメッセージを実際に処理したモデル、古い会話が現在どの等価モデルへ移ったか、そして返信本文の中でモデルが自分をどう呼んだか。多くの場合これらは揃いますが、揃わないこともあります。そのとき、ユーザーには「同じ会話なのにモデル名が食い違う」ように見えます。
Used GPT-5 に関する OpenAI のヘルプ記事は、この構造をさらにはっきりさせています。OpenAI は、特定のメッセージだけが別モデルにルーティングされることがあり、あなたが選んだモデルはチャットの default として残る、と説明しています。つまり、picker に出ているラベルと、その瞬間の返信を処理した実際のモデルは、短時間なら普通に食い違い得ます。
だからこそ、次の3つが同時に起きても不思議ではありません。
- picker には元の既定モデルが残っている
- その返信には
Used GPT-5の注記が付いている - 本文ではモデルが「GPT-4」と名乗っている
これらは互いに完全に否定し合うものではありません。単に別レイヤーの情報であり、本文中の自己紹介が最も弱いだけです。
よくある原因は3つに分かれる
実際のケースの多くは、次の3つのどれかに入ります。直し方もそれぞれ違います。
1. その返信だけ別モデルにルーティングされた。 これは OpenAI が最も明示的に説明しているケースです。ヘルプ記事には、システムがメッセージ単位で別モデルへルーティングすることがあると書かれています。公開情報でいちばんわかりやすい例は sensitive topic ですが、System Card を見ると、複雑さやツール要件、文脈も関係します。UI に Used GPT-5 と表示されているなら、そのメッセージについては本文の自己紹介よりこちらを優先するべきです。
2. 古い会話や古いモデル表面を引きずっている。 OpenAI は 2026 年に複数の旧 ChatGPT モデルを退役させ、その会話を新しい等価モデルへ移しました。release notes には、以前 GPT-5.1 を使っていた会話は GPT-5.3 Instant や GPT-5.4 Thinking / Pro の対応経路へ自動で継続するとあります。GPT-4o などの退役告知にも、conversations や projects が GPT-5.3 Instant / GPT-5.4 の等価先へ進むことが書かれています。つまり、昔のモデル名に基づく感覚は、現在の backend とズレやすいということです。
3. 指示文の中に古い GPT-4 文言が残っている。 OpenAI は「だから GPT-5 が GPT-4 と言う」と直接書いたヘルプ記事を出してはいません。なので、これは推測ではなく inference として扱うべきです。ただし、根拠の強い inference です。OpenAI は personality と custom instructions が今はすべてのチャットに即時適用されると説明しています。また GPT-5 の prompting guide では、GPT-5 は指示への追従性が非常に高く、曖昧または矛盾した instructions に影響されやすいと説明しています。この2つを合わせると、builder prompt、system prompt、saved template、custom instructions のどこかに You are GPT-4 のような古い identity text が残っていると、backend が GPT-5 に変わっても本文に GPT-4 が出続ける、という状況は十分にあり得ます。
この3つ目が、問題をもっとも「しつこく」見せる原因でもあります。メッセージ単位の routing は一時的ですし、古い会話の移行も date と release notes を見れば説明できます。しかし、古い prompt 文言は消すまで何度でも再発します。
実際に何が答えたのかをどう確認するか
確認方法は surface ごとに分けるべきです。
ChatGPT では、まず OpenAI 自身が authoritative だとしているものを見ます。返信に Used GPT-5 のような注記があるなら、それをそのメッセージの source of truth として扱います。そのうえで picker を見れば、チャット全体の default がわかります。ただし、それだけで個別メッセージのモデルまで確定したと思わないことが大切です。
古いスレッドなら、「昔はこのモデルだった」という記憶だけでは判断しないでください。現在の release notes と retirement notice を確認した方が正確です。OpenAI は、古い会話が新しい等価モデルへ移ることをすでに文書化しています。
Custom GPT を使っているなら、実際に見るべきなのは builder の model 設定と instruction text です。モデルに向かって「自分は誰か」と尋ね続けても、あまり大きな価値はありません。instruction の実体を見る方がはるかに役に立ちます。
API ではさらに明確です。ChatGPT の message-level routing という考え方を API にそのまま持ち込まないでください。API では、authoritative なのは request と log です。もしアプリが GPT-5 を送っているのに回答文が「私は GPT-4」と言ったなら、それは backend の秘密の切り替えを示すより、prompt / output 側の問題を示すことの方が多いです。
間違った名前が繰り返し出るときの直し方
原因の層さえわかれば、直し方は短いです。
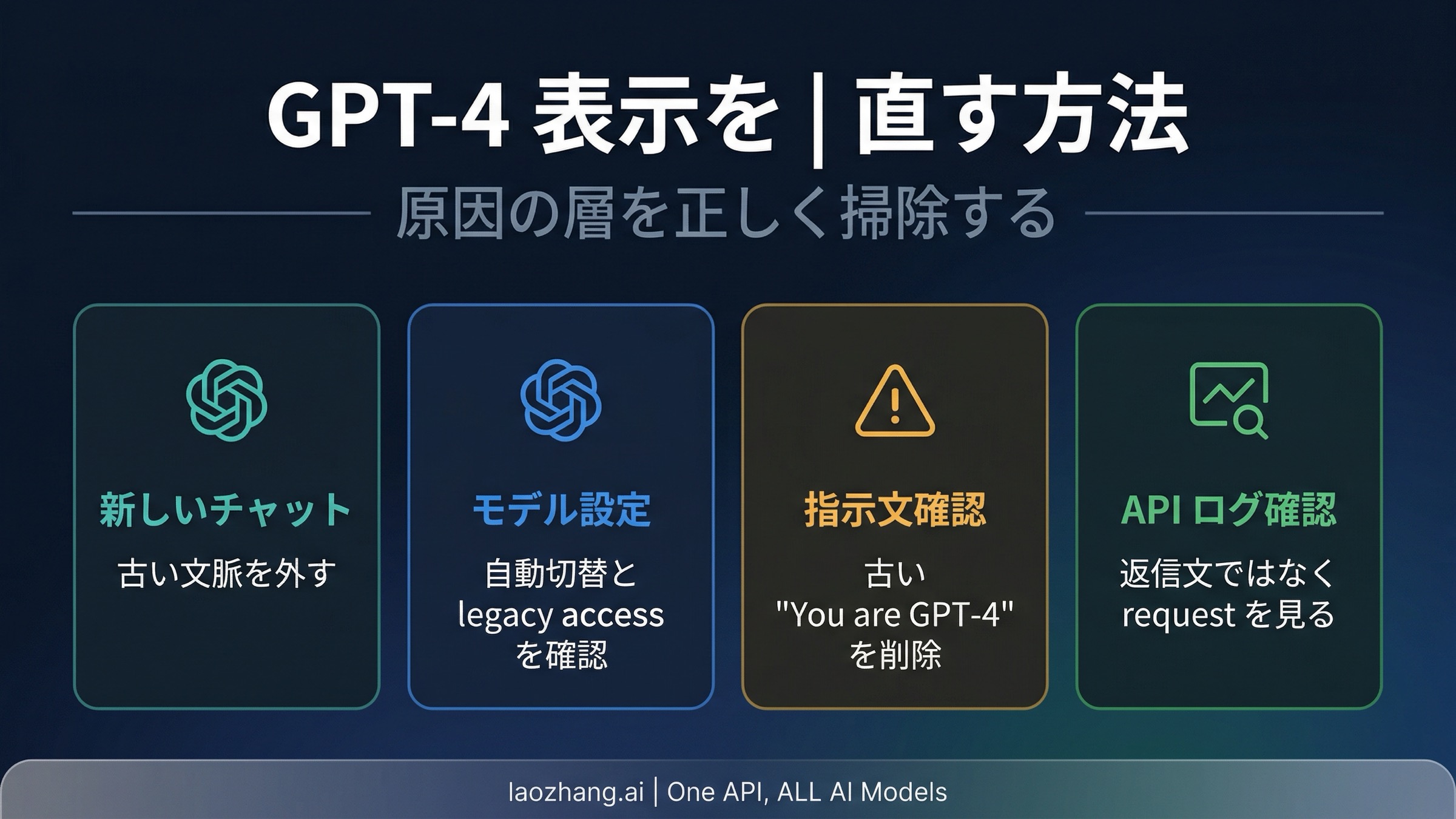
- まず新しいチャットを作る。 旧スレッドには古い文脈、古い切り替え、古い instructions が残りすぎています。
- モデル設定で switching や legacy access を確認する。 これらは便利ですが、default と actual message model の取り違えも起こしやすくします。
- Custom GPT の instructions、personal instructions、長く使っている prompt template を監査する。
You are GPT-4、As GPT-4のような古い identity 文言を探してください。しつこく再発するケースはここに原因があることが多いです。 - API では必ず log を見る。 回答文に自己紹介をさせる方法は、回帰テストや本番確認には向いていません。
今日の ChatGPT でいちばんやめた方がいい習慣は、「自分のモデル名を言ってみて」と聞くことを model verification に使うことです。昔よりずっと unreliable ですし、API debugging ではなおさらです。
では、本当に GPT-4 を使っていることになるのか
多くの場合、そうではありません。少なくとも、その1文だけではそう結論できません。
本文に GPT-4 と書かれていた、というだけでは弱い証拠です。OpenAI は自己言及が誤っていたり一般化されていたりする可能性を認めています。一方で、UI に Used GPT-5 と出ているなら、その方が強い証拠です。API の log に GPT-5 の request が記録されているなら、それも返信本文より強い証拠です。
本当に重要なのは、間違った名前がより強い signal と一致したときです。たとえば builder instructions に古い GPT-4 identity text が残っている、意図的に legacy surface を使っている、あるいは log 上の model path が期待と違う。そこまでそろって初めて、単なる wording mismatch ではなく configuration や product layer の問題として扱うべきです。
いちばん実用的なルール
GPT-5 が GPT-4 と言ったら、まず backend が間違っていると疑うより先に、その一文が間違っていると考えてください。
そのうえで、surface に合った最強の signal を見る。ChatGPT なら message annotation と settings、API なら request と log、Custom GPT なら builder と instruction text。そうすれば、曖昧な命名の混乱は短い診断手順に変わります。