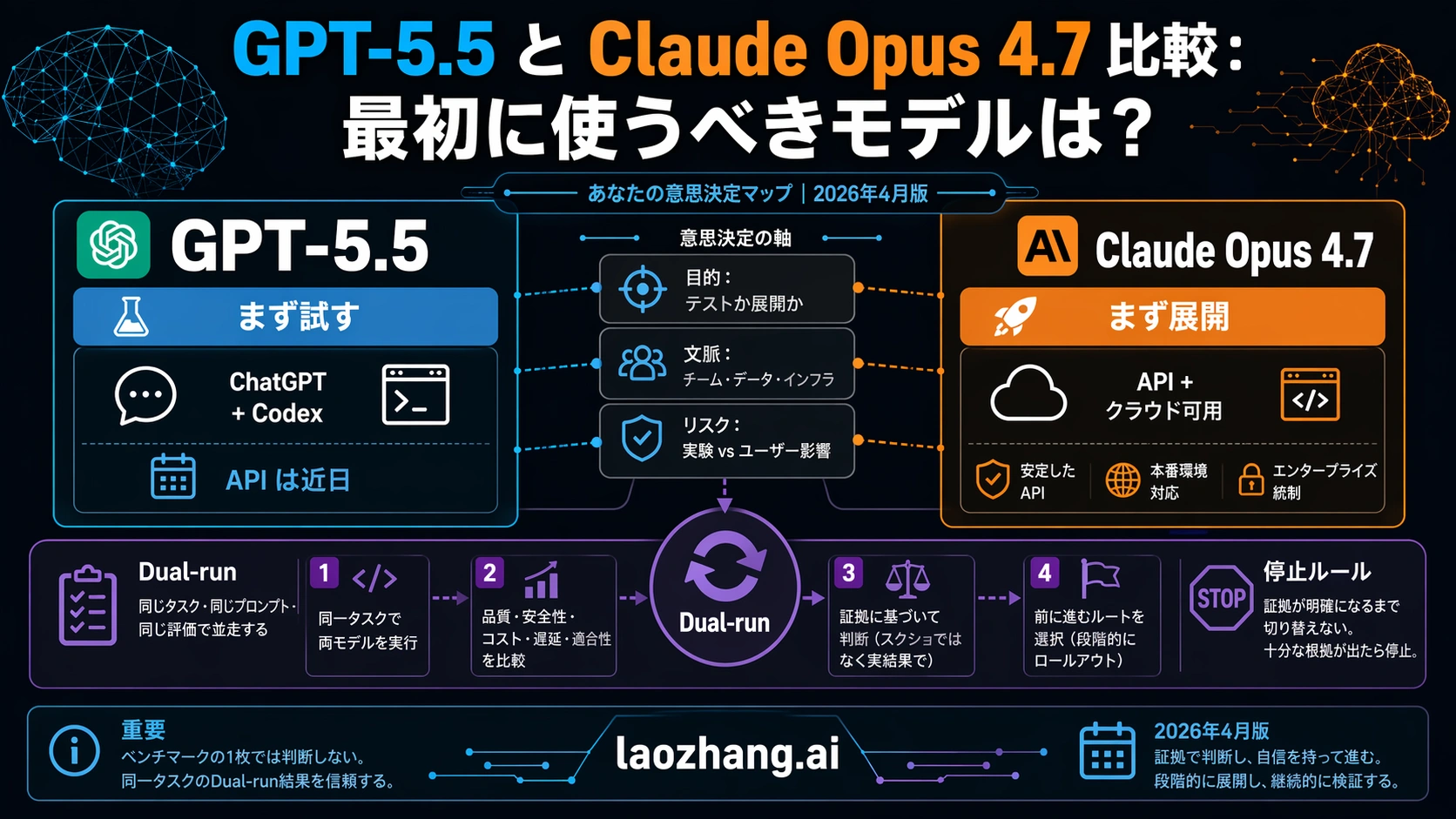
GPT-5.5 と Claude Opus 4.7 は、まだ対称な API 選択肢ではありません。2026年4月24日時点では、GPT-5.5 は ChatGPT と Codex など OpenAI の有料ユーザー向け surface に入っていますが、API access は coming soon です。一方で Claude Opus 4.7 は、Anthropic API、Amazon Bedrock、Google Vertex AI、Microsoft Foundry からすでに本番評価に入れられます。
そのため最初に見るべきなのは「どちらが強いか」ではなく、「あなたの作業はどの route で動くのか」です。ChatGPT、Codex、OpenAI 内のコード作業や人間のレビューを中心にするなら、GPT-5.5 を先に試す価値があります。サーバー側 API、cloud endpoint、企業向け rollout、ログ、権限、回収可能な fallback が必要なら、Claude Opus 4.7 を先に評価する方が現実的です。既存の有料 workflow を置き換えるなら、同じタスクで両方を走らせる前に default を替えてはいけません。
| ルート | 最初の動き | 合う理由 | 停止条件 |
|---|---|---|---|
| ChatGPT または Codex のテスト | GPT-5.5 を先に試す | OpenAI が professional work と agentic coding 向けに出している最新 route で、OpenAI 内 surface はすでに使える。 | OpenAI API が自分の account で公式に使えるまで production migration を組まない。 |
| Production API または cloud deployment | Claude Opus 4.7 を先に評価する | Claude API と主要 cloud platform で live になっている。 | launch-week の benchmark 表だけで premium default を替えない。 |
| 出力が多い、または予算が厳しい | 実際の prompt で両方を試算する | GPT-5.5 の API 価格は coming soon で input $5、output $30。Opus 4.7 は live で input $5、output $25。 | cache、batch、地域、tokenizer、retry を見ないまま予算承認しない。 |
| 既存 default の置き換え | dual-run してから判断 | 置き換え価値は失敗率、レビュー時間、回復コストで決まる。 | 同じ repo、同じ prompt、同じ tool budget、同じテストで勝つまで替えない。 |
速い答え
細部を見る前に、まず route で選びます。
| 状況 | 先に使うモデル | 理由 | 再確認すること |
|---|---|---|---|
| ChatGPT、Codex、OpenAI-native coding flow が中心 | GPT-5.5 | OpenAI は GPT-5.5 を professional work と agentic work の新しい frontier route として提示しており、これらの surface はすでに使える。 | API status、model ID、account limit、production 制約。 |
| 今日 production API や cloud endpoint が必要 | Claude Opus 4.7 | Anthropic は Opus 4.7 を Claude API と主要 cloud platform に出している。 | latency、region、rate limit、token use、deployment policy。 |
| 出力が多い、または予算承認が重要 | Opus 4.7 を live API baseline にする | Anthropic は input $5、output $25 を live price として示す。GPT-5.5 は coming-soon API 価格なので、開始日に再確認が必要。 | cached input、batch discount、regional multiplier、tokenizer effect。 |
| GPT-5.5 API pilot を準備したい | 公式 callable route を待つ | coming-soon price は計画には使えるが、本番 endpoint ではない。 | 開始日に OpenAI docs と pricing page を再確認。 |
| 動いている default を置き換えたい | 両方を dual-run | launch-week comparison は自社の failure mode、review load、rollback cost を測らない。 | 同じ task set、同じ tools、同じ acceptance tests、同じ cost accounting。 |

したがって結論は「GPT-5.5 が勝ち」でも「Claude が勝ち」でもありません。GPT-5.5 は OpenAI の live surface に残る作業で先に試すモデルです。Claude Opus 4.7 は API route や cloud route を今日必要とする作業で先に deploy evaluation に入れるモデルです。費用、顧客向け出力、SLA、社内自動化が関係するなら、両方を同じタスクで評価してから切り替えます。
可用性と価格が最初の分岐
価格比較は可用性から始めます。一方が必要な API route で live、もう一方が coming soon なら、最初の判断は benchmark ではありません。使える route がないモデルを本番計画の中心に置くと、model ID、rate limit、tool support、billing behavior のどれかで必ず止まります。
| 契約項目 | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| 現在の user surface | OpenAI の launch 情報では、paid users 向けに ChatGPT と Codex で rollout。 | Anthropic の Opus ページでは Claude products で利用可能。 |
| 2026年4月24日の API status | API access coming soon。価格表は live endpoint の証明ではない。 | Anthropic API と major cloud platforms で live。 |
| API model ID | API route が live になった日に OpenAI docs を確認し、勝手な ID を使わない。 | Anthropic model overview に claude-opus-4-7。 |
| Standard API price | coming soon: input $5、cached input $0.50、output $30 per million tokens。 | input $5、output $25 per million tokens、cache と batch options あり。 |
| Context と output | GPT-5.5 API が自分の account で live になってから確認。 | Messages API で 1M context と 128k max output。 |
| 高精度 route | GPT-5.5 Pro は future high-accuracy route で、高価格。今日の標準比較ではない。 | Opus 4.7 は現行 premium Opus route。 |
この表だけで default action が変わります。production integration を今日作る developer は、Opus 4.7 を live evaluation path に入れられます。GPT-5.5 API を使いたい team は、evaluation harness を保存し、公式 callable route が開いた日に走らせるべきです。非公式 model ID、SNS の screenshot、価格だけを根拠に deployment を組むのは危険です。
output price も重要です。GPT-5.5 が現在の listed price で API に出るなら、output 側は Opus 4.7 より高くなります。ただし、それだけで Opus が常に安いとは言えません。cached input、batch pricing、prompt length、tokenizer behavior、retry、human edit が invoice を変えます。だから output-heavy な workflow は、API が live になった日に実 prompt で両方を測る必要があります。
ベンチマークの読み方
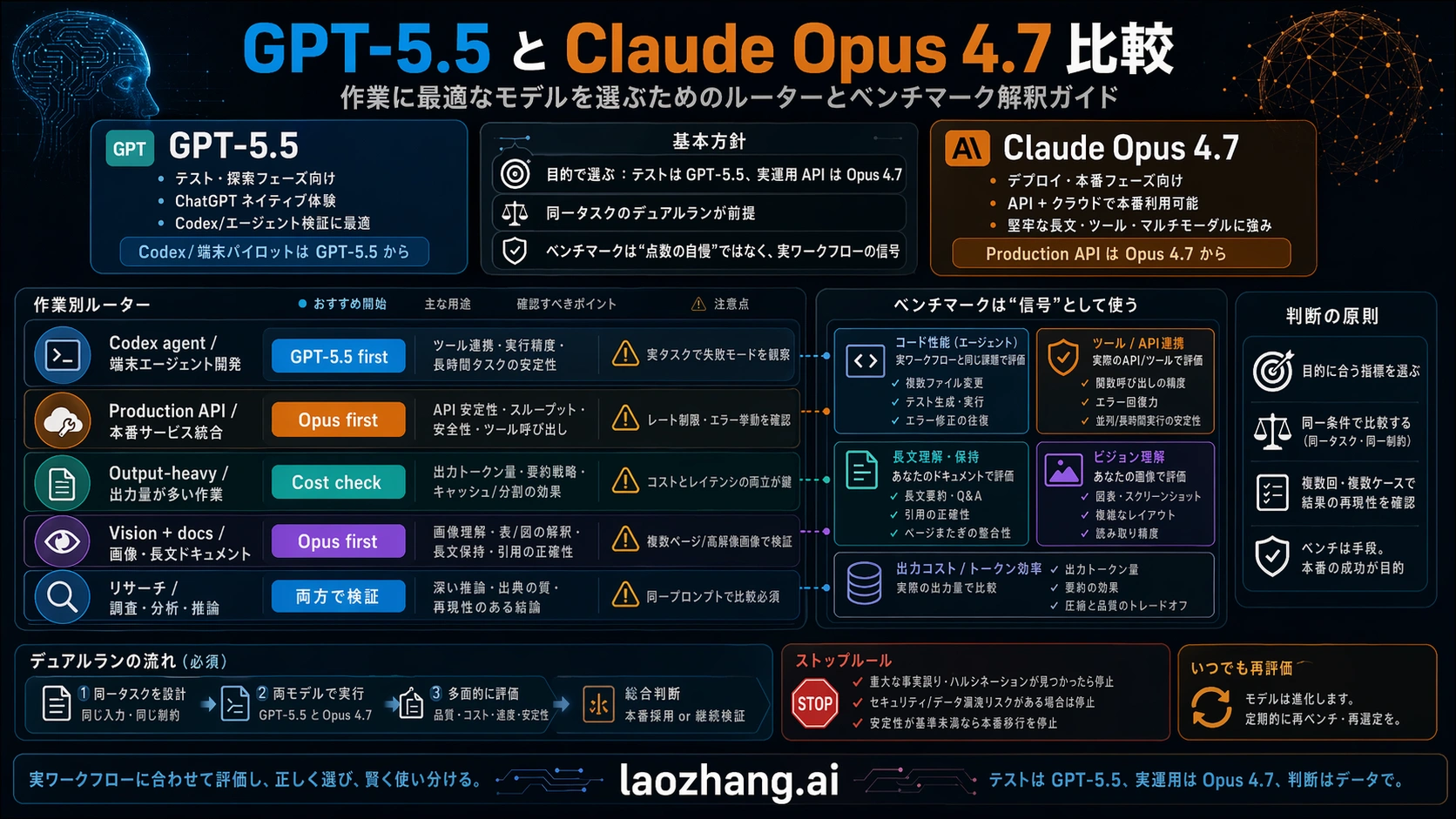
benchmark table は、workload に対応づけた時だけ役に立ちます。provider が release 時に出した数値は evidence ですが、neutral universal crown ではありません。実務の比較では、価格、OSWorld、Terminal-Bench、短い評価、設計思想が混ざりやすいものです。ここで必要なのは「全部勝ったか」ではなく、「自分の作業に近い行はどれか」です。
| Benchmark | GPT-5.5 公開結果 | Claude Opus 4.7 対照 | 実務上の読み方 |
|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | 69.4% | Codex や terminal-style OpenAI workflow で GPT-5.5 を先に試す強い理由。 |
| GDPval-agentic | 84.9% | 80.3% | professional task quality の参考になるが、domain-specific review loop が必要。 |
| OSWorld-Verified | 78.7% | 78.0% | ほぼ接近しており、deploy route と harness quality がより重要。 |
| BrowseComp | 84.4% | source table を確認 | browsing/research signal として扱い、API 決定に直結させない。 |
| FrontierMath Tier 4 | 35.4% | source table を確認 | hard reasoning の pilot 材料であり、workload tests の代替ではない。 |
| CyberGym | 81.8% | source table を確認 | セキュリティ系タスクが似ている時だけ価値が高い。 |
これらの数字は、agentic coding や professional task で GPT-5.5 を真剣に試すには十分です。ただし blanket replacement を承認するには足りません。OpenAI は benchmark の文脈を持ち、Anthropic は Opus API の contract を持ち、最終判断はあなたの workload が持っています。
最大の誤りは、live API model と not-yet-live API model を同じ deployability として比較することです。ChatGPT や Codex で何を試すかなら、GPT-5.5 の rows は非常に重要です。今日 API route の後ろに置くなら、availability が first filter であり、Opus 4.7 の方がきれいな deployability contract を持っています。
Coding と agent での選び方
実際の route が OpenAI-native なら、GPT-5.5 を先に使います。ChatGPT での analysis、Codex での repo work、terminal tasks、code review、OpenAI account 内の collaboration では、operator experience と model quality が同じくらい重要です。この場合の問いは「GPT-5.5 が既存の tool 内で review load を減らし、難しい作業を終えられるか」です。surface が live なので、これはすぐ検証できます。
実際の route が API-first、Claude-native、cloud-provider-first なら、Claude Opus 4.7 を先に使います。Anthropic は coding、agents、long context、high-resolution images、higher-effort control を前面に出していますが、もっと重要なのは deployable route です。server workflow、scheduled jobs、logs、permissions、region、rollout、rollback が必要なら、coming-soon への期待より live contract が大事です。
公平なテストは単純です。すでに review time を消費している十個のタスクを選びます。GPT-5.5 を live OpenAI surface で実行します。Opus 4.7 を実際に deploy する API または cloud route で実行します。first-pass correctness、tool recovery、format stability、token use、latency、human review minutes を記録します。model を昇格させるのは、benchmark story ではなく total work が減った時だけです。
repo edits、terminal tasks、OpenAI-native coding が主なら、GPT-5.5 が first seat です。production agent、explicit API budget、cloud routing、long context、controlled rollout が主なら、Opus 4.7 が first seat です。
Context、output、migration risk
短い chat では context と output limit は見えにくいですが、長いコードベース、文書レビュー、監査、report generation、agent loop では決定的です。Claude Opus 4.7 の live contract は明確で、Anthropic docs は Messages API に 1M context と 128k max output を示しています。pricing docs でも Opus 4.7 は standard pricing で full 1M context を含むとされています。
GPT-5.5 の API context、production limit、rate limit、tool availability、billing behavior は、API access があなたの account で live になった時に確認すべきです。それまでは「planned API route」または「coming-soon API pricing」と書くのが正確です。model ID、context window、rate limit、tool support、billing は、production migration を止める本物の条件です。
Opus 4.7 にも migration hazards があります。Anthropic の current notes では、temperature、top_p、top_k など non-default sampling parameters は 400 を返します。old extended-thinking budget fields は removed です。new tokenizer は content によって fixed text に対して最大約 35% more tokens を使う場合があります。これは Opus を避ける理由ではなく、実 harness で試す理由です。
long-form coding agents、document review、production workflow では、「どちらの context が大きいか」だけでは不十分です。必要な context を保持し、必要な output を出し、cost limit に入り、失敗した時に system が recovery できる route を選ぶ必要があります。
すでに GPT-5.4 または Opus 4.7 を使っている場合
すでに GPT-5.4 を API で使っているなら、GPT-5.5 が出たからといってすぐに外さないでください。GPT-5.5 は OpenAI-native pilot として正しい新候補ですが、GPT-5.5 API route が自分の account で live になるまでは、GPT-5.4 が deployable OpenAI API baseline です。OpenAI、Anthropic、Google のどれを route とするかという広い比較なら、隣の Claude Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro がより適切です。
すでに Claude Opus 4.7 を使っているなら、GPT-5.5 release は pilot の合図であって、automatic replacement の合図ではありません。API contract、cloud deployment、long context が Opus を選んだ理由なら、production route は維持します。その上で GPT-5.5 を OpenAI live surfaces で比較し、API access が official になった時に production route を再評価します。
Anthropic 側の same-family migration が主な関心なら、OpenAI-vs-Anthropic comparison より Claude Opus 4.7 vs Claude Opus 4.6 の方が狭く正確です。prompt behavior、token drift、same-family cost の話はそのページが担当します。
実用的な切替計画
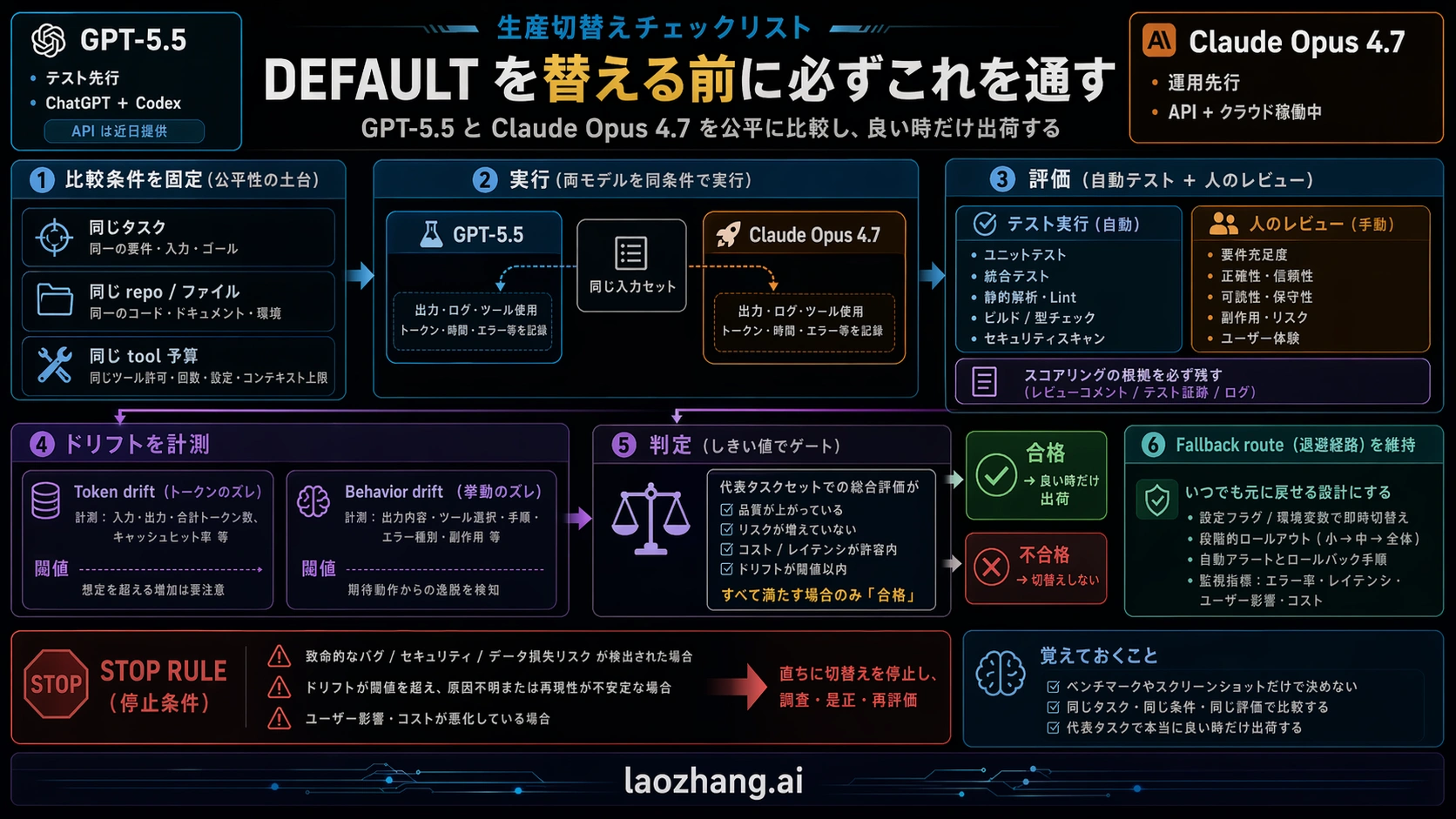
model switch は release plan を持つべきです。最低限の有効な plan は六つです。
| チェック | 実施内容 | 合格条件 |
|---|---|---|
| Route check | 必要な ChatGPT、Codex、API、cloud で model が live か確認する。 | production plan が coming-soon endpoint に依存しない。 |
| Task set | demo ではなく representative tasks を選ぶ。 | easy、hard、long-context、output-format、failure-prone tasks を含む。 |
| Harness parity | 可能な範囲で same prompts、same tools、same files、same budgets で実行する。 | 差が test setup ではなく model behavior から生じる。 |
| Quality score | correctness、recovery、formatting、human review minutes を追跡する。 | winner が total work を減らす。 |
| Cost score | input、cached input、output、retries、task-level cost を測る。 | selected route が real workload で支払える。 |
| Rollback route | rollout 中は old model または fallback route を残す。 | failed migration を pipeline rebuild なしで戻せる。 |
小さな team なら、これは一日以内の disciplined testing で終えられます。enterprise workflow なら、private pilot、shadow run、limited production route、default switch に分けるべきです。基準は同じです。model が新しいから切り替えるのではなく、実作業の failure、time、cost を減らした時だけ切り替えます。
FAQ
GPT-5.5 は Claude Opus 4.7 より優れていますか?
route と workload 次第です。OpenAI-native の ChatGPT と Codex 作業では GPT-5.5 を先に試す価値があります。今日 live API または cloud endpoint が必要なら Claude Opus 4.7 を先に評価する方が現実的です。
GPT-5.5 は API で使えますか?
2026年4月24日時点で、OpenAI は GPT-5.5 API access を coming soon と説明しています。pricing page は planning には使えますが、今日 production で callable という証明にはなりません。
どちらが安いですか?
今日の live API deployment では、Opus 4.7 の price が明確です。input $5、output $25 per million tokens で、cache、batch、regional adjustment は別です。GPT-5.5 は coming soon price として input $5、output $30 が示されているため、output-heavy work は API live 後に real prompts で再計算します。
Coding agents にはどちらが良いですか?
Codex と OpenAI-native coding workflow では GPT-5.5 を先に試します。Claude API agents、cloud deployment、long-context loop、production endpoint が必要な team では Opus 4.7 を先に試します。
Opus 4.7 がまだ勝つ領域はありますか?
あります。今日の API と cloud route での deployability、1M context、128k output、多 platform availability は Opus 4.7 の明確な強みです。
GPT-5.5 API を待つべきですか?
目的が OpenAI API migration to GPT-5.5 なら待つべきです。直近の必要が production API route で、Opus 4.7 が要件に合うなら待つ必要はありません。GPT-5.5 は pilot plan に残し、API が live になった日に再確認します。
GPT-5.5 Pro はどう考えるべきですか?
GPT-5.5 Pro は future higher-accuracy route で、listed API price もかなり高い route です。多くの team にとって、今日の GPT-5.5 vs Claude Opus 4.7 の標準比較ではありません。高価格を払う理由が明確な場合だけ別枠で評価します。
OpenAI の live surfaces で作業するなら GPT-5.5 を先に試します。今日 deployable API または cloud route が必要なら Claude Opus 4.7 を先に評価します。予算や reliability が関係する場合は、同じタスクで両方を走らせ、切替を勝ち取らせてください。