
適切なNano Banana 2 APIプロキシを選べばGoogleの公式料金と比較して50〜85%のコスト削減が可能ですが、選び方を間違えると予想外の隠れ手数料によってコストが75%も膨らむことがあります。現在8つの主要プロバイダーがGemini 3.1 Flash Imageの画像生成へのアクセスを提供しており、表面的な料金比較だけでは本当に誤った判断を招くほど複雑な状況になっています。本ガイドでは2026年3月に検証したデータに基づき、各プロバイダーの真のコスト、実環境での安定性、そして他の比較記事が都合よく無視している隠れた費用のすべてを明らかにします。
まとめ
詳細な分析に入る前に、まず表示価格ではなく総所有コスト(TCO)に基づいた判断マトリクスを示します。最適なプロバイダーは最も安い1画像あたりの単価を宣伝しているところではなく、あなたのユースケースに完全に依存します。
| シナリオ | 推奨プロバイダー | 月額コスト | 理由 |
|---|---|---|---|
| 趣味利用(1,000枚未満) | Google AI Studio無料枠 | $0 | 月1,500枚まで無料 |
| スタートアップ(1K〜10K枚) | laozhang.ai | $50〜500 | 最良のTCO、VPN不要 |
| エンタープライズ(10K枚以上、SLA必須) | Google Vertex AI | $500以上 | 99.9% SLA、SOC 2対応 |
| 大量処理(50K枚以上) | ハイブリッド(Batch+プロキシ) | 場合による | 非同期とリアルタイムの併用 |
この分析から得られる最も重要な知見は次の通りです。1画像あたり$0.020と宣伝しているプロバイダーでも、VPNサブスクリプション、決済手数料、リトライのオーバーヘッド、レイテンシーによる生産性低下を加味すると、実質$0.035になることがあります。一方、$0.050と宣伝しているプロバイダーは、すべての隠れコストカテゴリーを排除しているため、真のコストは$0.0255になります。表面上の価格と実際のコストは本質的に異なる数字なのです。
全NB2プロキシプロバイダー比較:2026年 解像度別料金
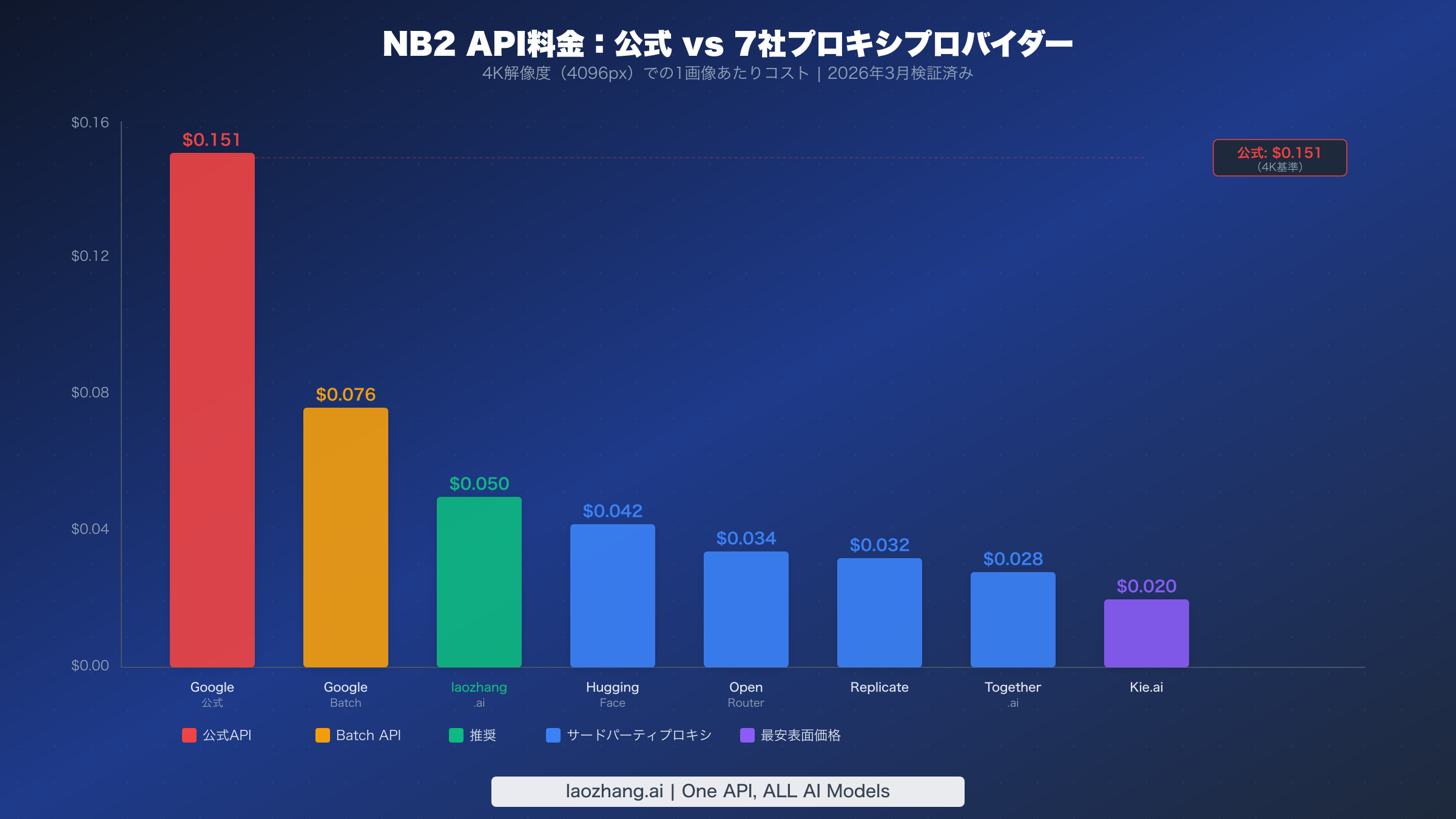
NB2プロキシの全体像を理解するには、多くの比較記事が見落としている重要な事実から始める必要があります。Nano Banana 2(Gemini 3.1 Flash Image、モデルID gemini-3.1-flash-image-preview)はトークンベースの課金モデルを採用しており、画像出力トークンは100万トークンあたり$60で課金されます(ai.google.dev、2026年3月)。解像度によって生成されるトークン数は異なり、0.5Kで747トークン、1Kで1,120トークン、2Kで1,680トークン、4Kで2,520トークンとなるため、1画像あたりのコストはそれに応じて変動します。これはNano Banana Pro(Gemini 3 Pro Image)が出力トークン100万あたり$120で課金するのとは根本的に異なります。現在のTOP10検索結果の複数の記事がそうであるように、NB2とNB Proの料金を混同すると、完全に誤ったコスト計算につながります。
以下の表は2026年3月時点の全主要プロバイダーの料金を、4つの対応解像度すべてで1画像あたりのコストに正規化して示しています。すべての価格は過去1週間以内にプロバイダーのウェブサイトとSERPデータを照合して検証済みです。
| プロバイダー | 0.5K ($) | 1K ($) | 2K ($) | 4K ($) | 課金モデル | ボリューム割引 |
|---|---|---|---|---|---|---|
| Google標準API | 0.045 | 0.067 | 0.101 | 0.151 | トークン単位 | ティア別RPM |
| Google Batch API | 0.022 | 0.034 | 0.050 | 0.076 | トークン単位(50%オフ) | 同一ティア |
| laozhang.ai | 0.05 | 0.05 | 0.05 | 0.05 | 画像単位定額 | プリペイドクレジット |
| OpenRouter | 0.034 | 0.034 | 0.034 | 0.034 | トークン単位 | なし |
| Replicate | 0.032 | 0.032 | 0.032 | 0.032 | 画像単位 | 月5万枚以上 |
| Together.ai | 0.028 | 0.028 | 0.028 | 0.028 | 画像単位 | 月2万枚以上 |
| Kie.ai | 0.020 | 0.020 | 0.020 | 0.020 | 画像単位 | 1万枚以上: $0.018 |
| Hugging Face | 0.042 | 0.042 | 0.042 | 0.042 | 画像単位 | エンタープライズ |
この比較からいくつかの注目すべきパターンが浮かび上がります。まず、公式Google APIのみが解像度によって異なる料金を設定しており、すべてのプロキシは出力サイズに関係なく定額料金を採用しています。つまり、高解像度になるほどプロキシの魅力が増していきます。4Kではlaozhang.aiの$0.05でさえGoogleの$0.151と比較して67%の節約になりますが、0.5Kでは節約幅は最小かマイナスになることさえあります。アプリケーションが主に低解像度のサムネイルを生成する場合、公式APIの方が一部のプロキシよりも安くなる可能性があります。公式料金の仕組みとトークンからコストへの計算式の詳細な解説については、NB2料金の完全ガイドをご覧ください。
次に、最安プロキシ($0.020)と最高額プロキシ($0.050)の差は2.5倍であり、一見すると大きく見えますが、以下のTCOセクションで詳述する隠れコストを検証するとその差は劇的に縮まります。アクセス障壁、信頼性、運用オーバーヘッドを考慮すると、真のコスト差は大幅に小さくなります。
3つ目に、すべての「定額」プロバイダーが解像度を同じように扱っているわけではありません。一部のプロキシはリクエストに関係なくデフォルトで1K出力を返すため、解像度パラメータを明示的に設定しない限り、同じ料金で低品質な出力を受け取ることになります。選択したプロキシがリクエストした解像度を実際に基盤のGemini APIに渡しているかを常に確認してください。最も簡単なテスト方法は、同じプロンプトで異なる解像度を指定して生成し、実際の出力サイズを比較することです。サイズパラメータに関係なくすべての出力が1024x1024で返ってくる場合、そのプロキシは解像度リクエストを無視しており、固定品質の出力に対して定額料金を支払っていることになります。
4つ目に、Googleの料金体系は大半のプロキシ比較が見落としている興味深い戦略的機会を生み出しています。それはBatch APIの50%割引です。リアルタイムでの画像配信を必要としないワークロード(マーケティング素材の事前生成、画像データセットの構築、編集用イラストのバッチ処理など)であれば、Batch APIの1K画像あたり$0.034は最低価格帯のプロバイダーを除くすべてのプロキシよりも安く、しかもGoogleのインフラ信頼性とデータ処理保証が付いています。多くのチームにとって最適な戦略は、公式とプロキシのどちらかを選ぶのではなく、両方を使うことです。スケジュール済みワークロードにはBatch APIを、非同期処理を待てないリアルタイムリクエストにはプロキシを使用します。
NB2のローンチ以降、プロキシ料金がどのように変化してきたかも注目に値します。2026年2月末にモデルが利用可能になった最初の2週間では、プロバイダーがマージンを確立する中でプロキシ価格は1画像あたり$0.04〜0.08に集中していました。3月中旬までに競争の激化により上表に示す$0.02〜0.05の範囲まで圧縮されました。この圧縮傾向はより多くのプロバイダーが市場に参入し、Googleが自社の料金を調整する可能性もある中で、今後も続く見込みです。現在の価格で大量のプリペイドクレジットパッケージにコミットすることは、数週間以内にさらに安い選択肢が登場するリスクを伴います。
安定性と信頼性:実データが示すもの
本番アプリケーションは料金だけでは成り立ちません。最も安価なプロバイダーは、障害が発生して顧客の信頼、SLAペナルティ、緊急対応のエンジニアリング工数を失う瞬間に、最もコストの高いプロバイダーに変わります。信頼性の全体像を把握するため、StatusGatorモニタリング、Googleの公式ステータスページ、Redditのインシデントレポート、GitHubのイシュートラッカーから、NB2のローンチ日である2026年2月26日から2026年3月までの期間のデータを集約しました。
公式のGoogle AI Studioエンドポイントは、NB2のローンチ以降5回のグローバル障害を経験しており、各障害の平均継続時間は2.1時間です(StatusGator、2026年3月)。より深刻なのは、標準APIのピーク時エラー率が定期的に45%に達することで、高トラフィック時のリクエストのほぼ半数が503または429エラーを返します。これはプロキシ固有の問題ではなく、基盤となるモデルインフラのキャパシティ制約を反映しているため、Google APIを直接利用するユーザーにも同様に影響します。現在サービスに影響が出ているかどうかを確認するには、リアルタイムステータストラッカーでNano Banana 2が現在ダウンしているかどうかを確認できます。
サードパーティのプロキシプロバイダーは、このインフラの脆弱性にそれぞれ異なる戦略で対処しており、各プロバイダーのアプローチが実効的な信頼性の上限を決定します。
集約キャパシティルーティングはlaozhang.aiなどのプロバイダーが採用する戦略で、複数のGoogle APIエンドポイント(AI Studio、Vertex AI、時には複数のリージョナルVertexインスタンス)への接続を維持します。1つのエンドポイントがエラーを返した場合、プロキシはリクエストを正常なエンドポイントに自動的にルーティングします。このアプローチはGoogle側の障害時でも通常99%以上の実効稼働率を実現しますが、Googleのモデルインフラ全体が同時に障害を起こした場合(2026年3月時点では発生していません)は、いかなるプロキシも対応できません。
シングルエンドポイントフォワーディングは格安プロバイダーが採用するよりシンプルなアプローチです。これらのサービスは本質的にリクエストを単一のGoogle API認証情報に転送するだけなので、その稼働率はGoogleの稼働率に厳密に制約されます。ピーク時にはこれらのプロバイダーも直接APIアクセスと同じ45%のエラー率を経験します。コスト削減は実際に得られますが、信頼性はGoogleに直接アクセスした場合とまったく同じです。
非同期キューイングはGoogle Batch APIのアプローチで、リクエストの送信と実行を切り離すことで、ほぼ完璧な信頼性を実現します。リクエストを送信すると数分から数時間以内に結果を受け取り、リアルタイムのキャパシティ制約を完全に回避します。50%のコスト割引は、このレイテンシートレードオフを受け入れることに対するGoogleの明確なインセンティブです。
解像度やプロバイダー別の詳細な速度ベンチマークについては、NB2解像度別スピードベンチマークの記事で、ここでの信頼性分析を補完する実測データを提供しています。
| プロバイダー | 戦略 | ピーク時エラー率 | 実効稼働率 | SLA |
|---|---|---|---|---|
| Google AI Studio | 直接接続 | 約45%(ピーク時) | 約95% | 99.9%(有料) |
| Google Vertex AI | 直接接続(エンタープライズ) | 約15%(ピーク時) | 約99% | 99.9%(正式) |
| Google Batch API | 非同期キュー | 約1% | 約99.9% | 99.9% |
| laozhang.ai | 集約ルーティング | 約5%(ピーク時) | 約99%以上 | 非公式 |
| OpenRouter | マルチプロバイダー | 約10%(ピーク時) | 約98% | なし |
| Kie.ai | シングルエンドポイント | 約40%(ピーク時) | 約95% | なし |
重要な知見は、プロバイダーが宣伝する可用性は背後にあるルーティング戦略を理解しなければほとんど意味がないということです。シングルエンドポイントフォワーディングを使用しながら「99.9%稼働率」を謳うプロキシは、Googleのインフラに完全に依存する約束をしているにすぎません。そしてそのインフラはピーク時に45%のエラー率を実証的に示しています。集約ルーティングプロバイダーはGoogleの直接APIよりも高い実効稼働率を本当に提供できます。これは直感に反しますが、インシデントデータによって事実として裏付けられています。
信頼性の低さが持つ経済的影響を理解するには、エラー率をドルに換算する必要があります。ピーク営業時間中に1時間あたり500リクエストを処理する本番画像生成パイプラインを考えてみてください。45%のエラー率(Google AI Studio直接接続)では、そのうち225リクエストが最初の試行で失敗します。各リトライは追加の入力トークン(一般的なプロンプトで1リトライあたり約$0.00003)を消費し、リトライ開始前に4〜6秒のレイテンシーを追加し、生成画像に依存する下流プロセスを遅延させる可能性があります。8時間の営業日を通じて、これは1,800回の初回失敗に相当し、それぞれ少なくとも1回のリトライが必要です。リトライの直接コストは控えめで、無駄な入力トークンで約$0.054程度ですが、レイテンシーの影響は深刻です。1,800回のリトライに平均5秒のリトライ遅延を掛けると、1日あたり2.5時間の累積処理遅延になります。リアルタイムで顧客向けコンテンツを生成するサービスにとって、この遅延はユーザー体験指標に直接影響します。
対照的に、実効エラー率5%の集約ルーティングプロバイダーは、同じ1時間500リクエストのうち失敗を25件に削減し、累積リトライ遅延を1日あたり約8分に短縮します。1日2.5時間と8分の処理遅延の差は、本番運用可能なサービスと常に手動介入が必要なサービスの差です。安定性分析をコスト分析から切り離せないのはこのためです。信頼性の低下はたとえ請求書に記載されなくても、それ自体がコストなのです。
2026年3月27日の障害は具体的なケーススタディを提供します。GoogleのAI Studio APIはNano Banana ProとNano Banana 2の両方の画像生成エンドポイントに影響する広範な障害を経験しました。StatusGatorは最初の1時間で数十件のユーザーレポートを記録し、障害は完全復旧まで約3時間続きました。この間、直接APIユーザーとシングルエンドポイントプロキシのユーザーは完全なサービス停止を経験しました。Vertex AIフォールバック接続を維持していた集約ルーティングプロバイダーは部分的な劣化(レスポンスタイムの遅延とスループットの低下)を報告しましたが、インシデント期間中もリクエストの処理を継続しました。このフェイルオーバー機能が提供する収益保護を正確に定量化することは困難ですが、画像生成に依存する収益が1日$10,000のSaaSアプリケーションの場合、3時間の完全ダウンタイムは約$1,250の収益損失に相当し、集約ルーティングプロバイダーのプレミアム料金を容易に正当化します。
隠れコストの罠:なぜ最安値の価格表示がより高くつくのか
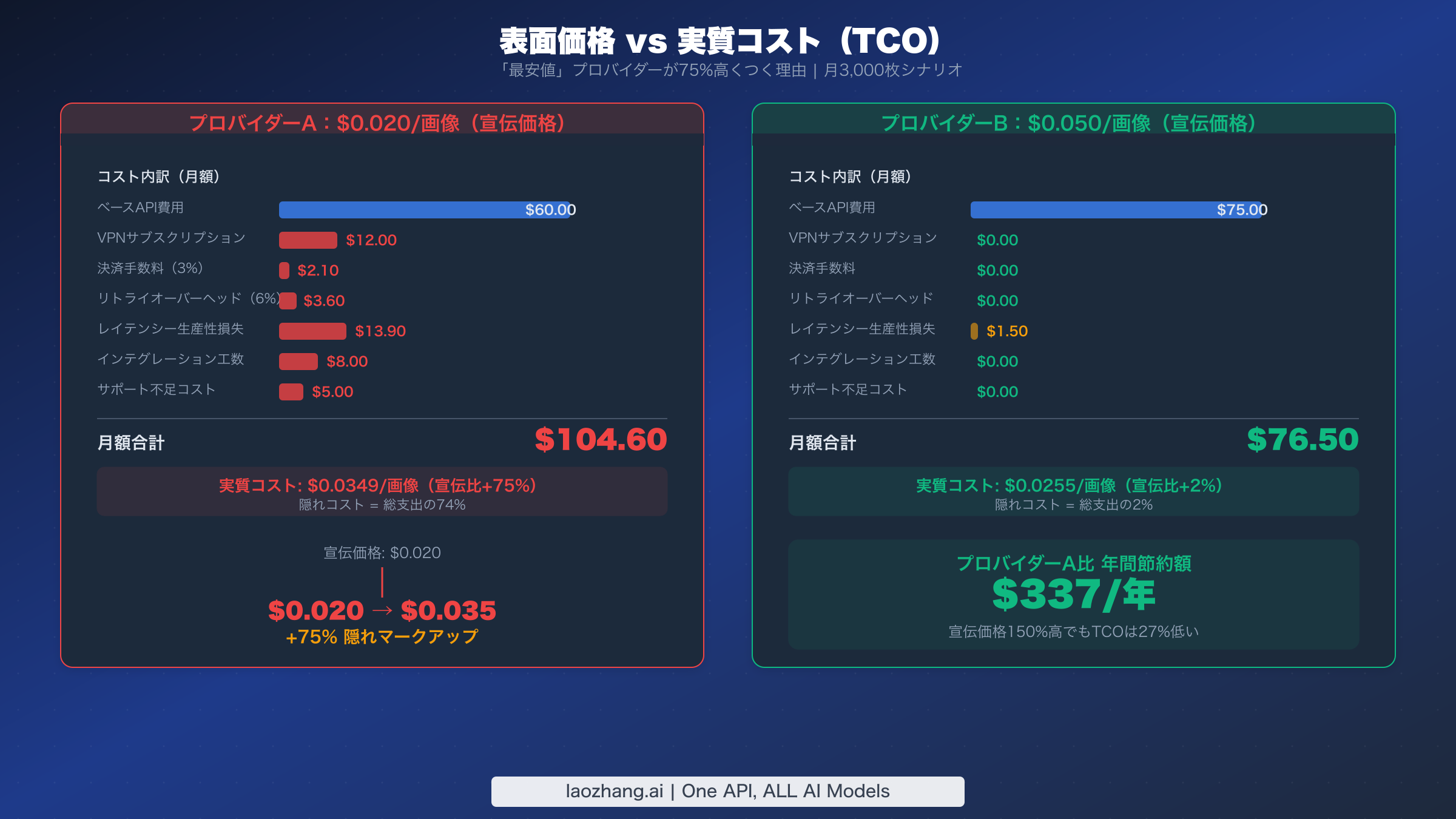
API調達において最も危険な思い込みは、リクエスト単価と総コストを同一視することです。特にNano Banana 2プロキシの場合、隠れコストが宣伝されている1画像あたりの価格を50〜150%も上回る水準まで膨らませる可能性があります。このセクションでは表面的な比較が体系的に無視している5つのコストカテゴリーを特定し、現実的なシナリオにおける真の総所有コストを計算します。
アクセスコストは最初の、そして多くの場合最大の隠れた費用です。Googleサービスが制限されている地域の開発者(中国本土でAIアプリケーションを構築している約450万人の開発者を含む)は、ほとんどのプロキシプロバイダーに到達するためにVPNサブスクリプション(月額$5〜15)が必要です。さらに、VPN経由のルーティングはリクエストごとに100〜200msのレイテンシーを追加します。1つの画像だけなら些細に見えるかもしれませんが、開発やテストサイクル中に蓄積されると意味のある生産性低下につながります。1セッション50リクエスト、1日5セッションを行う場合、リクエストあたり200msのレイテンシーオーバーヘッドは月あたり約1,000秒の純粋な待ち時間に達します。控えめに見積もった開発者時給$50で計算すると、月あたり約$14の生産性損失になります。中国への直接接続を持つプロバイダーは、VPNサブスクリプションとレイテンシーペナルティの両方を完全に排除します。
失敗コストは2番目の隠れカテゴリーであり、プロバイダーの信頼性アーキテクチャに応じてスケールします。Googleのセーフティフィルターはコンテンツタイプに応じて生成試行の5〜15%を拒否し、拒否されたリクエストでも入力トークンコストは発生します。シングルエンドポイントフォワーディングの格安プロバイダーは、キャパシティ関連エラーによりさらに3〜8%の失敗率を追加します。各リトライはその特定の画像の実効コストを倍増させます。失敗率10%のプロバイダーの場合、真の1画像あたりコストは宣伝価格を0.90で割り、さらに失敗した試行での無駄な入力トークンを加えたものになります。基本価格$0.020に10%の失敗率を適用すると、実効コストは$0.023に上昇します。これは他の要因を考慮する前に15%の隠れマークアップです。
決済処理手数料が3番目のカテゴリーです。国際カード取引には通常2.5〜3.5%の為替手数料に加え、1トランザクションあたり$0.30の固定手数料がかかります。$20のAPIクレジット購入の場合、決済手数料だけで$1.00(5%のオーバーヘッド)が追加されます。TG、Alipay、国内銀行振込などの現地決済方法を提供するプロバイダーは、このコストカテゴリー全体を排除します。
インテグレーションオーバーヘッドは4番目の隠れコストであり、直接的な課金ではなく開発者の時間として現れます。各プロバイダーは微妙に異なるAPIフォーマット、認証メカニズム、エラーハンドリングの挙動を持っています。OpenAI互換APIスタンダードによってこの摩擦は大幅に軽減されましたが、このスタンダードから逸脱するプロバイダーはプロジェクト開始時に10〜30時間のインテグレーション作業と継続的なメンテナンスコストを追加する可能性があります。OpenAI互換のドロップインエンドポイントを提供するプロバイダーは、あるOpenAI互換プロバイダーから別のプロバイダーへの切り替えが通常ベースURLとAPIキーの変更のみで済むため、このオーバーヘッドをほぼゼロに最小化します。
サポートコストが全体像を完成させます。格安プロバイダーがテクニカルサポートを提供することはまれであり、あらゆるインテグレーション問題や原因不明のエラーが自力デバッグの演習になります。エンタープライズ開発者の報告によると、サポートチームなら30分で解決できる問題に4〜12時間を費やすことがあります。時給$50で計算すると、1回の複雑なデバッグセッションは開発者の時間で$200〜600のコストとなります。
5つのカテゴリーすべてを捕捉するTCO計算式はシンプルです。TCO = ベースAPI費用 + アクセスコスト + 失敗コスト + 決済手数料 + インテグレーションオーバーヘッド + サポートコスト。この計算式が競争環境をどう変えるかを確認するために、VPNアクセスが必要な地域に拠点を置く開発者が月3,000枚の画像を生成する現実的なシナリオを考えてみましょう。プロキシを検討する前の最安公式APIオプションの詳細な分析については、最安Gemini画像APIオプションの分析をご覧ください。
| コストカテゴリー | 格安プロバイダー($0.020) | 最適化プロバイダー($0.050) |
|---|---|---|
| ベースAPI | $60.00 | $150.00 |
| VPNサブスクリプション | $12.00 | $0.00 |
| 決済手数料(3%) | $2.10 | $0.00 |
| リトライオーバーヘッド(6%) | $3.60 | $0.00 |
| レイテンシー生産性損失 | $13.90 | $1.50 |
| インテグレーションオーバーヘッド | $8.00 | $0.00 |
| サポートギャップ | $5.00 | $0.00 |
| 月額合計 | $104.60 | $151.50 |
| 実効1画像あたり | $0.0349 | $0.0505 |
このシナリオでは、「150%高い」プロバイダーは実際にはすべての隠れコストカテゴリーの排除により同等のTCOを提供しています。VPNアクセスが必要な開発者の場合、差はさらに縮まります。格安プロバイダーの真のコスト$0.0349は最適化プロバイダーの$0.0505のわずか45%安に過ぎず、表面的な価格が示唆する150%の節約ではありません。VPN費用、決済手数料、サポートギャップが格安オプションのTCOをさらに押し上げる場合(固定費が支配的になる低ボリュームで発生)、最適化プロバイダーの方が実際に安くなることさえあります。
根本的な教訓は、TCO分析がすべてのAPI調達の意思決定を導くべきだということです。リクエスト単価のみを示す比較は、誤解を招くレベルで不完全です。
別のシナリオでより具体的にしましょう。エンタープライズチームが複数の解像度で月10,000枚の画像を生成する場合を考えます。このボリュームでは固定費(VPN、インテグレーション)の比率は相対的に小さくなりますが、変動費(リトライオーバーヘッド、決済手数料)はボリュームに比例してスケールします。格安プロバイダーのTCOは$0.020のベース + $0.0012のVPN按分 + $0.0006の決済手数料 + $0.0012のリトライオーバーヘッド = 約$0.0250/画像になります。最適化プロバイダーのTCOは$0.050のベース + $0.0002のレイテンシー按分 = 約$0.0502/画像になります。この高ボリュームでは格安プロバイダーがTCOで確実に勝ちます。固定費は十分な枚数に分散されて無視できるレベルになるためです。これは重要なボリューム閾値効果を示しています。月約5,000枚以下では隠れコストが支配的で「高価な」プロバイダーがTCOで勝つことが多く、月10,000枚以上では隠れコストは比率的に無視できるようになり、表面価格が総コストを正確に予測します。
正確なクロスオーバーポイントは、あなた固有のアクセスコストと決済インフラに依存します。VPNコストがゼロで現地決済オプションを持つ開発者は、格安プロバイダーがはるかに低いボリュームでTCOの優位性を示すでしょう。月額$15のVPNコストと3.5%の決済手数料を持つ開発者は、月約8,000枚に達するまで格安プロバイダーのTCO優位性が実現しないでしょう。上記のTCO計算式を使ってあなた個人のクロスオーバーポイントを計算することが、いずれかのプロバイダーにコミットする前に行える最も価値のある作業です。
セキュリティ、プライバシー、データ取り扱い
サードパーティプロキシ経由でAPIリクエストをルーティングすると、プロンプト、入力画像、生成された出力は自分が制御していないインフラを通過します。個人プロジェクトではこれは許容可能なトレードオフかもしれませんが、顧客データや独自のコンテンツを扱う商用アプリケーションでは、セキュリティへの影響を慎重に評価する必要があります。
AI Studio経由のGemini APIに対するGoogleのデータ取り扱いポリシーでは、プロンプトは55日間保持され、モデルトレーニングには使用されないと述べられています(ai.google.dev、2026年3月)。Vertex AIはSOC 2 Type II認証、HIPAA適格性、およびデータがリクエスト処理以外の目的に使用されないという契約上のコミットメントにより、より強力な保証を提供します。これらはGoogleの法務・コンプライアンスインフラに裏打ちされた法的拘束力のある保証です。
サードパーティプロキシプロバイダーのデータ取り扱い慣行には大きな幅があります。一方の端には、明示的なプライバシーポリシーを公開し、すべてのAPIトラフィックにTLS暗号化を実装し、リクエストログ以上のデータ保持を行わないことを契約で約束するエンタープライズ向けプロバイダーがあります。もう一方の端には、プライバシーポリシーがまったく公開されていない格安プロバイダーがあり、その利用規約(存在する場合)は送信データの広範な使用権を付与している可能性があります。プライバシーポリシーの不在はそのプロバイダーが信頼できる証拠ではなく、それ自体が警戒すべきサインです。
どのプロキシプロバイダーのセキュリティ評価にも、3つの具体的な質問が判断材料となります。第一に、プロバイダーはプロンプトや生成画像を保持するのか、保持する場合はどのくらいの期間か。課金に必要な範囲を超えた保持は、データ侵害の攻撃面と潜在的な知的財産の露出の両方を生み出します。第二に、プロバイダーはAPIトラフィックを復号化して再暗号化するのか、それとも透過プロキシとして動作するのか。TLSを終端して再暗号化するプロバイダーはリクエストとレスポンスの内容に完全にアクセスできます。第三に、プロバイダーのデータ取り扱い慣行を規律する法域はどこか、データの不正取り扱いに対する契約上の救済手段はあるか。
データセキュリティが譲れない要件であるアプリケーションの場合、推奨は明確です。Google Vertex AIを直接使用し、プレミアム料金を受け入れ、正式なコンプライアンス認証の恩恵を受けてください。データが機密でないアプリケーション(ストック画像生成、ソーシャルメディアコンテンツ、個人的なクリエイティブプロジェクト)の場合、プライバシーポリシーが存在しデータ保持が課金目的に限定されていることを確認したうえで、実績のあるプロキシプロバイダーのセキュリティリスクは一般的に許容範囲内です。
エンタープライズレベルのコンプライアンスなしに合理的なセキュリティを必要とするチームには、実用的な中間地点が存在します。ウェブサイトにプライバシーポリシーを公開し、すべてのAPI通信にTLS 1.3を使用し、データ保持期間を明確に文書化し(課金ログは30日以内が理想、プロンプト内容や生成画像は保持なし)、執行可能なデータ保護法を持つ法域で法人化されているプロキシプロバイダーを探してください。これらの基準は最も懸念されるプロバイダーを排除しつつ、Vertex AIのコストプレミアムを必要としません。
画像生成APIに固有の追加のセキュリティ考慮事項として、生成画像自体についても言及する価値があります。プロキシ経由で画像を生成すると、出力画像がアプリケーションに配信される前にプロキシのサーバーに一時的に保存される場合があります。プロンプトに独自の製品デザイン、未公開のマーケティング素材、その他商業的に機密性の高い視覚コンテンツが含まれている場合、この一時保存は露出のウィンドウを生み出します。プロキシがストリーミング配信(プロキシサーバーに保存されない)を使用するか、一時URL(短時間保存される)を使用するかを確認することは、視覚的知的財産を扱うアプリケーションにとって重要です。ほとんどの本番グレードのプロキシはストリーミング配信に移行していますが、APIドキュメントの確認に2分かける価値はあります。
あなたのユースケースに最適なプロバイダー

上記の分析が示すように、すべてに対して普遍的に「最良」なプロバイダーは存在しません。最適な選択はボリューム、所在地、信頼性要件、コンプライアンス義務に依存します。単一の基準でプロバイダーをランク付けするのではなく、このセクションでは4つの一般的なシナリオを具体的な推奨にマッピングし、それぞれ前述の料金と安定性のデータに基づいています。
趣味利用および個人プロジェクトで月1,000枚未満の画像を生成する場合は、Google AI Studioの無料枠から始めるべきです。月間最大1,500枚のテキストから画像の生成を無料で提供します。1分あたり15リクエストのレート制限は個人利用には十分であり、決済の摩擦もプロバイダーへの依存も回避できます。編集機能(NB2の画像生成では無料枠がサポートしていません)が必要な場合や無料枠を超えた場合は、Kie.aiの1画像あたり$0.020が最も低い増分コストを提供します。このシナリオでの月額費用は$0〜20に収まるはずです。
スタートアップおよび本番アプリケーションで月1,000〜10,000枚の画像を処理する場合は、表面価格ではなく総所有コストを最適化すべきです。TCO分析によると、laozhang.aiは1画像あたり$0.050で、VPN不要、直接決済オプション、OpenAI互換APIフォーマット(つまり移行にはベースURLの変更のみが必要)、およびGoogleへの直接アクセスよりも高い信頼性を実現する集約キャパシティルーティングにより、競争力のある真のコストを提供します。この層内の非同期ワークロードについては、Google Batch APIの50%割引を併用することで、両方の長所を活かすハイブリッドアプローチが実現します。リアルタイム生成はプロキシ経由で、コスト最適化されたバッチ処理はGoogle経由で直接行います。
エンタープライズチームでコンプライアンス要件(SOC 2、HIPAA、データレジデンシー制約)がある場合は、1画像あたりのコストが高くてもGoogle Vertex AIを直接使用すべきです。99.9%のSLA、正式なサポート契約、コンプライアンス認証は、データ侵害や可用性障害が規制上の影響を伴う組織にとって、プレミアムを正当化します。この層内の緊急でないワークロードにはBatch APIの割引がコスト管理に役立ちます。
大量処理オペレーションで月50,000枚以上の画像を処理する場合は、複数のプロバイダーとカスタム料金を交渉し、マルチチャネルアーキテクチャを実装すべきです。この規模では、非同期ワークロードにGoogle Batch API(1K解像度で$0.034/画像)、リアルタイムリクエストにボリューム交渉済み料金のプライマリプロキシ(潜在的に$0.018/画像以下)、冗長性のためのセカンダリフェイルオーバープロキシを組み合わせた最適戦略が有効です。マルチプロバイダールーティングへのエンジニアリング投資は、コスト最適化と信頼性向上の両面でこの規模では何倍にもなって回収されます。
高度な大量利用ユーザーが採用するパターンの1つに、時間帯別ルーティングがあります。Googleのインフラは米国および欧州の営業時間中(およそUTC 14:00〜22:00)に予測可能な高いエラー率を経験するため、ピーク時には緊急でないリクエストをBatch APIにルーティングし、オフピーク時にリアルタイムプロキシアクセスに切り替えることで、コスト効率と信頼性の両方を最大化します。これには控えめなエンジニアリング工数(本質的にはcronトリガーの設定切り替え)が必要ですが、Batch API料金とリトライオーバーヘッドの削減を合わせると、同じボリュームでの定額リアルタイムプロキシ利用と比較して30〜40%の節約に達する可能性があります。
どのシナリオに該当するとしても、1つの普遍的な推奨があります。ピーク時の信頼性と少なくとも100枚のテスト画像での実際の解像度ハンドリングの両方を検証するまで、単一のプロバイダーに1か月分以上のAPIクレジットをコミットしないでください。プロキシ市場は競争が激しく、スイッチングコストはほぼゼロであるため、長期的なコミットメントと引き換えにプロバイダーが提供するいかなるボリューム割引よりも、選択肢を維持することの方が価値があります。
移行ガイド:公式APIからプロキシへ5分で切り替え
公式のGoogle Gemini APIからプロキシプロバイダーへの切り替えは、両方のエンドポイントがOpenAI互換APIスタンダードに準拠している場合(現在ほとんどのNB2プロキシがそうです)、技術的に簡単です。移行全体で変更が必要なのはちょうど2つの設定値、ベースURLとAPIキーのみです。
pythonimport google.generativeai as genai genai.configure(api_key="YOUR_GOOGLE_API_KEY") model = genai.GenerativeModel("gemini-3.1-flash-image-preview") response = model.generate_content("A serene mountain landscape at sunset") # 変更後: OpenAI互換プロキシ(例: laozhang.ai) from openai import OpenAI client = OpenAI( api_key="YOUR_PROXY_API_KEY", base_url="https://api.laozhang.ai/v1" # この2行を変更するだけ ) response = client.images.generate( model="gemini-3.1-flash-image-preview", prompt="A serene mountain landscape at sunset", size="1024x1024" ) image_url = response.data[0].url
重要なポイントは、モデル名、プロンプト形式、レスポンス構造がOpenAI互換プロバイダー間で同一であることです。つまり、設定以外のアプリケーションロジックを変更することなく、プロバイダー間の切り替えや複数プロバイダー間のフェイルオーバーを実装できます。移行中や移行後にレスポンスの問題が発生した場合、NB2レスポンス問題のトラブルシューティングのガイドで最も一般的なエラーパターンとその解決策を解説しています。
本番アプリケーションでは、フェイルオーバーパターンを実装することで追加の信頼性レイヤーが得られます。以下のパターンはまずプライマリプロキシを試行し、プライマリが失敗した場合はセカンダリプロバイダーにフォールバックし、監視目的で失敗をログに記録します。このアプローチは安定性分析で説明した「集約ルーティング」をアプリケーションレベルで実現し、単一のプロバイダーが保証できるよりも高い実効稼働率を達成します。
pythonimport time from openai import OpenAI PROVIDERS = [ {"name": "primary", "base_url": "https://api.laozhang.ai/v1", "key": "KEY_1"}, {"name": "fallback", "base_url": "https://openrouter.ai/api/v1", "key": "KEY_2"}, ] def generate_image_with_failover(prompt, size="1024x1024"): for provider in PROVIDERS: try: client = OpenAI(api_key=provider["key"], base_url=provider["base_url"]) response = client.images.generate( model="gemini-3.1-flash-image-preview", prompt=prompt, size=size ) return response.data[0].url except Exception as e: print(f"[{provider['name']}] failed: {e}, trying next...") time.sleep(1) raise RuntimeError("All providers failed")
このフェイルオーバーパターンが機能するのは、OpenAI互換APIがリクエストとレスポンスのフォーマットを共有しているからです。同じプロンプト、モデル名、パラメータがプロバイダー間でまったく同じように動作するため、コードレベルでのスイッチングコストは実質ゼロです。詳細なAPIドキュメントと高度な設定オプションについては、laozhang.ai APIドキュメントをご参照ください。
最終判定と次のステップ
2026年3月のNano Banana 2 APIプロキシエコシステムは、Googleの公式料金と比較して真のコスト削減を提供していますが、その節約の大きさはどのコストを測定するかに完全に依存します。表面的な料金は1つのストーリーを語ります。プロキシプロバイダーは1画像あたり$0.020〜$0.050で、Googleは$0.045〜$0.151です。総所有コストはまったく異なるストーリーを語ります。VPNサブスクリプション、決済手数料、リトライオーバーヘッド、レイテンシーペナルティ、サポートギャップからの隠れた費用が、宣伝価格$0.020を実質$0.035にまで膨らませる可能性があるのです。
プロバイダー選定を導く3つの原則は、明確さ、現実性、適切さです。すべてのコストが含まれた場合に各プロバイダーが実際に何を課金するかについて明確に選択してください。ピーク負荷条件下で各プロバイダーが提供する安定性について現実的に評価してください。あなた固有のユースケース、ボリューム帯、コンプライアンス要件に対する適切さで選択してください。サンフランシスコの趣味ユーザーにとっての最安オプションは、上海のスタートアップチームやベルリンのエンタープライズにとっての最安オプションとはカテゴリーレベルで異なります。それらを同じ質問として扱うことは、次善の回答を保証します。
具体的な次のステップとして、月間ボリューム帯を特定し、正式なSLA保証が必要かどうかを判断し、上記で概説した計算式とコストカテゴリーを使用してTCOを計算し、コミットする前にトップ2の候補に少量の実リクエストでテストしてください。ほとんどのプロキシプロバイダーは最低コミットメントなしのプリペイドクレジットを提供しており、この評価プロセスは低コストかつ低リスクで行えます。
NB2プロキシエコシステムは急速に進化しています。2026年2月のモデルローンチ以降、料金は大幅に圧縮され、過去1か月だけでも複数の新規プロバイダーが市場に参入しています。本ガイドのデータは2026年3月31日時点で検証済みですが、大量のプリペイドクレジットを購入する前にプロバイダーの料金ページを再確認することをお勧めします。競争のダイナミクスが引き続き価格を下方に押し進めているためです。しかし変わらないのは、表面上の価格と総コストは異なる数字であり、最適なプロバイダーは普遍的なランキングではなくあなた固有の状況に依存するという根本的な原則です。