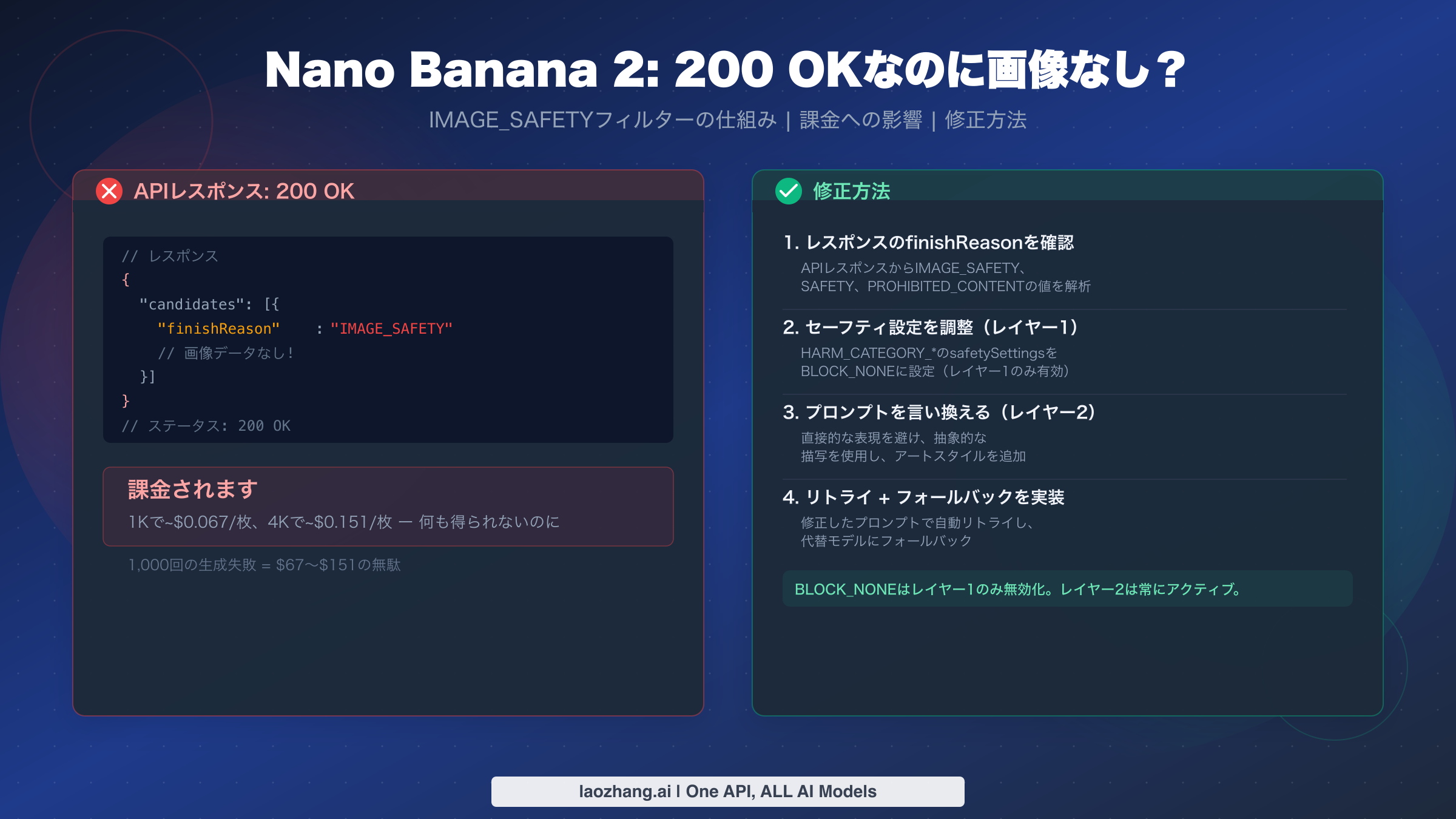
Nano Banana 2で最も混乱を招く動作は、HTTP 200 OK(成功を意味する汎用コード)を返しながら、画像をまったく生成しないことです。その原因はGoogleのレイヤー2 IMAGE_SAFETYフィルターであり、これはBLOCK_NONEやその他のセーフティ設定では無効化できないハードコードされたコンテンツブロックです。さらに厄介なことに、Googleはこれらの空レスポンスに対しても完全なトークン処理コストを課金します。1K画像あたり約$0.067、4K画像あたり約$0.151です(ai.google.dev/pricing、2026年3月時点)。本ガイドでは、なぜこの問題が発生するのか、コード内でどのように検出するのか、そしてAPIの予算を無駄にしないための7つの実証済み戦略を詳しく解説します。
まとめ
200 OKで画像が生成されない問題は、結局1つのことに帰結します。Nano Banana 2(gemini-3.1-flash-image-preview)は二重レイヤーセーフティアーキテクチャを使用しています。レイヤー1はsafetySettingsで設定可能で、BLOCK_NONEに応答します。レイヤー2(IMAGE_SAFETY、PROHIBITED_CONTENT、CSAMフィルターを含む)は常にアクティブであり、無効化できません。レイヤー2が画像をブロックすると、APIは画像データの代わりにfinishReason: "IMAGE_SAFETY"を含むHTTP 200を返し、トークン処理分が課金されます。修正方法は設定変更ではなく、プロンプトエンジニアリングです。以下に記載されたトリガーカテゴリーを避けるようプロンプトを言い換え、コードにfinishReasonチェックを実装し、無駄な支出を最小限に抑えるためのプロンプトバリエーション付きリトライロジックの追加を検討してください。
APIが200 OKを返すのに画像がない理由

「成功した」HTTPレスポンスに画像が含まれない理由を理解するには、Nano Banana 2パイプライン内部でGoogleのセーフティシステムが実際にどのように動作しているかを知る必要があります。この混乱が生じるのは、Googleが通常とは異なる設計判断を行ったためです。コンテンツフィルタリングが画像をブロックした際に4xxエラーを返すのではなく、finishReasonフィールドにブロックを示す値を設定した200 OKを返します。これは、標準的なHTTPエラーハンドリングではこの状況を検知できないことを意味します。リクエストが静かに拒否されたことを発見するには、レスポンスボディを解析する必要があるのです。
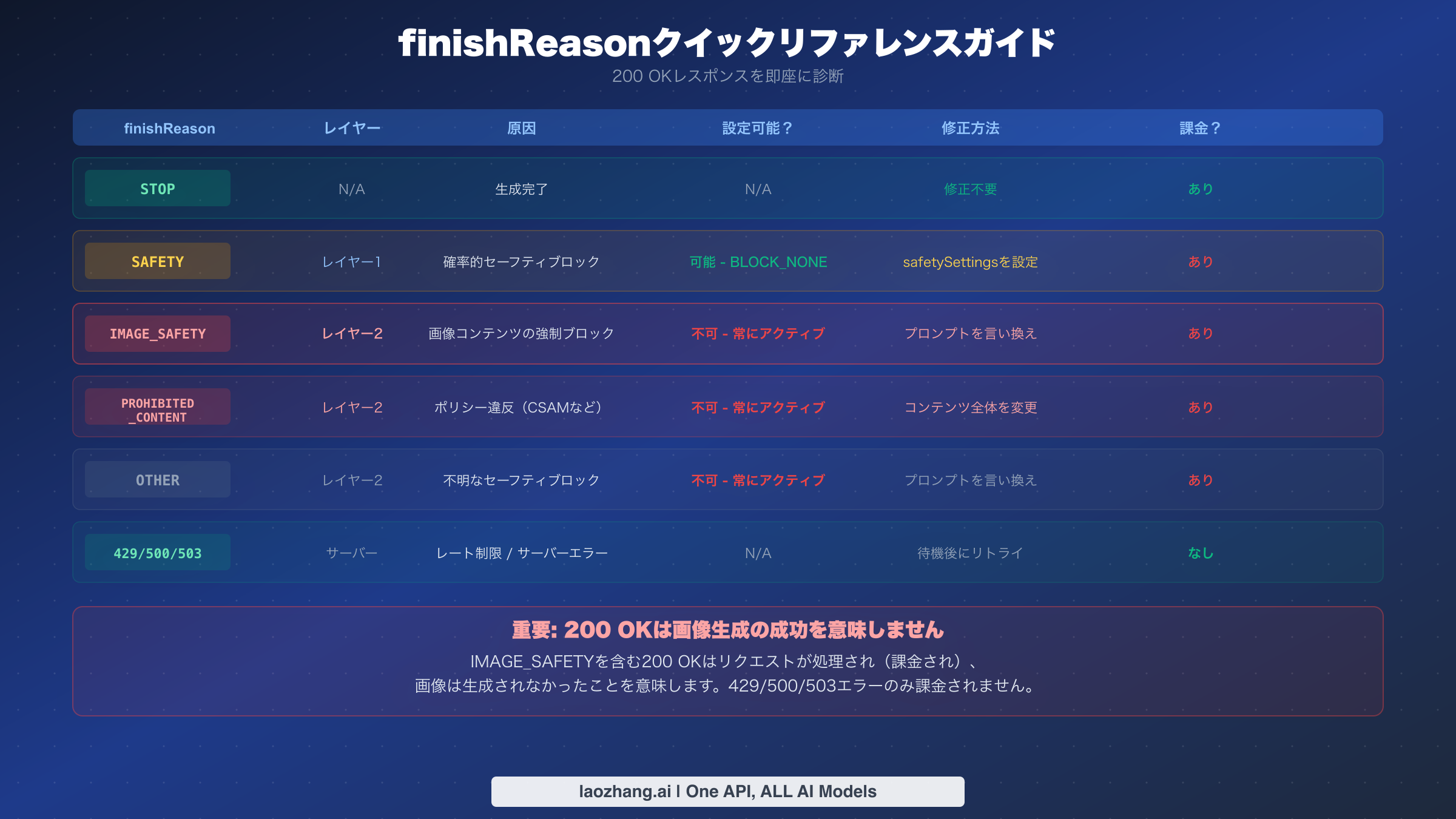
Nano Banana 2のセーフティシステムは、根本的に異なる動作を持つ2つの異なるレイヤーで動作します。レイヤー1は設定可能な確率的フィルターで、プロンプトを4つの有害カテゴリー(HARASSMENT、HATE_SPEECH、SEXUALLY_EXPLICIT、DANGEROUS_CONTENT)に対して評価します。各カテゴリーは確率スコアを使用し、APIリクエストのsafetySettingsパラメータを通じてしきい値を制御できます。カテゴリーをBLOCK_NONEに設定すると、このレイヤーでの特定カテゴリーのブロックを事実上無効化できます。レイヤー1がリクエストをブロックした場合、レスポンスにはfinishReason: "SAFETY"が含まれます。レイヤー2が生成する値とは異なることに注意してください。
レイヤー2こそが、ほとんどの開発者にとって混乱の始まりです。このレイヤーには、Googleが交渉不可能なポリシー適用として維持するハードコードされたセーフティフィルターが含まれています。4つのレイヤー2フィルター(IMAGE_SAFETY、PROHIBITED_CONTENT、CSAM、SPII(機密個人識別情報))は、設定可能なしきい値を持たないバイナリブロッカーとして動作します。BLOCK_NONEを含むいかなるAPIパラメータでも無効化できません。レイヤー2がリクエストをインターセプトすると、レスポンスにはfinishReason: "IMAGE_SAFETY"またはfinishReason: "PROHIBITED_CONTENT"が含まれます(Google Cloudドキュメントにて2026年3月に確認済み)。ほとんどのドキュメントが深く埋もれさせている重要な詳細は、これらのレイヤー2レスポンスがHTTP 200を返すという点です。ステータスコードのみをチェックするコードにとっては成功の錯覚を生み出します。
実務上の影響は重大です。すべてのレイヤー1カテゴリーにBLOCK_NONEを設定していても画像が得られない場合、設定ミスではありません。プロンプトが、いかなる設定変更でもバイパスできないレイヤー2フィルターをトリガーしただけです。唯一の前進方法はプロンプトの修正であり、以下のプロンプトエンジニアリングセクションで詳しく解説します。200 OKシナリオ以外のすべてのエラータイプを包括的に把握したい開発者は、Nano Banana 2の完全トラブルシューティングガイドで429レート制限、サーバーオーバーロードエラー、APIパラメータの問題について解説しています。
レイヤー2を最も頻繁にトリガーするもの
2026年2月27日のNano Banana 2リリース以降、Googleはオリジナルのナノバナナモデルと比較してレイヤー2フィルターを大幅に厳格化しています。開発者のレポートやコミュニティでの議論に基づく最も一般的なトリガーは、6つの明確なカテゴリーに分類されます。有名人や実在の人物の顔生成はおそらく最も厳格なカテゴリーで、説明的な表現による間接的な言及でもフィルターがトリガーされることがよくあります。露出の多い衣服の説明は、「ファッションショーのモデル」や「ビーチの水泳選手」のように明らかに性的でない意図でも検出されます。リアルな暴力や武器の描写は広く解釈され、軍事史のイラストやアクション映画シーンの再現も検出対象となります。実際の通貨や金融文書の複製は、明らかに架空やスタイル化されたバージョンでも一貫してトリガーされます。ブランドコンテンツやロゴの再現は、特定のブランド名を参照したり、商標登録されたビジュアル要素を詳しく記述するプロンプトを検出します。最後に、解剖学的・医学的画像は写実的なスタイルでリクエストされた場合にブロックされますが、教育的な図表としてフレーミングされた場合は通過することが多いです。
オリジナルのナノバナナモデルと比較して厳格さが顕著に増しています。オリジナルモデルで正常に画像を生成できたプロンプトが、プロンプトテキストを変更していないにもかかわらず、Nano Banana 2ではIMAGE_SAFETYをトリガーすることが頻繁にあります。RedditやGitHub Discussionsでのコミュニティテストによると、オリジナルモデルで動作していたプロンプトの約15~25%がNB2で失敗しており、多くの開発者がフォーラムでこのモデルを「弱体化された」と表現しています。信頼性の高いアプリケーションを構築するためには、これらのトリガーカテゴリーを理解することが不可欠です。各カテゴリーには異なるプロンプトエンジニアリングアプローチが必要だからです。
重要なfinishReason値
すべてのフィルターブロックが同等ではありません。APIレスポンスのfinishReasonフィールドは、どのレイヤーがリクエストをキャッチしたかを正確に示し、修正戦略を決定します。"SAFETY"の値はレイヤー1がブロックしたことを意味し、safetySettingsで修正可能です。"IMAGE_SAFETY"の値はレイヤー2がキャッチしたことを意味し、プロンプトを言い換える必要があります。"PROHIBITED_CONTENT"の値はGoogleのコアコンテンツポリシーに違反したことを意味し、題材そのものを変更すべきです。"STOP"の値は生成が正常に完了し、レスポンスに画像データが含まれるはずであることを意味します。すべてのNano Bananaエラーコードの完全なリファレンスについては、エラーコードリファレンスガイドをご覧ください。
課金の落とし穴 ー 空レスポンスに対して支払っている
200 OKで画像なし問題の最も経済的に痛い側面は、Googleがフィルターされたリクエストごとに完全なトークン処理レートで課金することです。429(レート制限超過)、500(内部サーバーエラー)、503(サービス利用不可)レスポンスとは異なり、これらは課金されません。一方、IMAGE_SAFETYを伴う200 OKレスポンスは、Googleがプロンプトを処理し、セーフティパイプラインを通し、ブロックを判断した上で、関連する計算コストを課金することを意味します。画像を受け取れなかったという事実は、課金計算には無関係です。
コストへの影響は、失敗率と解像度設定に依存します。NB2の標準価格は1K解像度の画像あたり約$0.067、4K解像度の画像あたり約$0.151です(ai.google.dev/pricing、2026年3月時点)。控えめなフィルター率でも、大規模では高額になります。1日に10,000枚の画像を1K解像度で生成する本番アプリケーションを考えてみましょう。そのうち20%がIMAGE_SAFETYをトリガーした場合、1日あたり約$134、つまり月あたり約$4,000を、一度も受け取っていない画像に支払っていることになります。4K解像度で同じ20%の失敗率では、無駄は1日あたり約$302、月あたり$9,000を超えます。
この課金構造は逆説的なインセンティブを生み出します。セーフティ境界に近いプロンプトほど、拒否される前にフル評価パイプラインを通じてトークンを消費するため、より多く支払うことになります。明らかに無害なプロンプトはすぐに通過します。レイヤー2でブロックされる前に広範なセーフティ分析を必要とするプロンプトは、成功した生成よりも実際に多くのトークンを消費する可能性があります。これが、同じプロンプトを単純に再送信するブラインドリトライ戦略が最悪のアプローチである理由です。各リトライは同じ結果で同じコストが発生します。
最も効果的なコスト軽減戦略は3つの要素を組み合わせます。第一に、フィルターされたレスポンスが静かに消費される代わりにすぐに検出されるよう、アプリケーションコードにfinishReasonチェックを実装します。第二に、テキストのみのGemini呼び出し(画像生成呼び出しのごく一部のコスト)でプロンプトのプリスクリーニングを行い、完全な画像生成コストをかける前にセーフティフィルターをトリガーしそうかどうかをテストします。第三に、IMAGE_SAFETYフィルターに対して検証済みの既知の安全なプロンプトテンプレートライブラリを維持し、新しいコンテンツリクエストがテストされていない言語ではなく、実証済みのベースラインから始まるようにします。すべての画像生成使用においてAPIコストを最小化したい開発者は、NB2 API価格の詳細分析でバッチ割引やコスト最適化戦略について詳しく解説しています。
IMAGE_SAFETYの失敗コストが持続不可能であると感じている場合、laozhang.aiのようなアグリゲータープラットフォームでは、1画像あたり約$0.05でNano Banana 2にアクセスできます。これはGoogleの直接価格より約25%安く、同じモデル品質を提供しながら、失敗した生成のコストを部分的に相殺できます。
コードで200 OKの画像なしを検出・処理する方法
ほとんどの開発者が犯す根本的なミスは、HTTP 200をレスポンスに画像データが存在する確認として扱うことです。Nano Banana 2では、画像データを抽出しようとする前に、必ずレスポンスボディのfinishReasonフィールドをチェックする必要があります。以下は、すべての可能なレスポンス状態を正しく処理するPythonとNode.jsの本番対応エラーハンドリングです。
Pythonの実装
pythonimport google.generativeai as genai import base64 import time def generate_image_safe(prompt, model_name="gemini-3.1-flash-image-preview", max_retries=3, resolution="1024x1024"): """Generate image with proper IMAGE_SAFETY detection and retry logic.""" model = genai.GenerativeModel(model_name) for attempt in range(max_retries): try: response = model.generate_content( prompt, generation_config={"response_modalities": ["IMAGE"]}, safety_settings={ "HARM_CATEGORY_HARASSMENT": "BLOCK_NONE", "HARM_CATEGORY_HATE_SPEECH": "BLOCK_NONE", "HARM_CATEGORY_SEXUALLY_EXPLICIT": "BLOCK_NONE", "HARM_CATEGORY_DANGEROUS_CONTENT": "BLOCK_NONE", } ) # Check finishReason BEFORE accessing image data if not response.candidates: return {"success": False, "reason": "NO_CANDIDATES", "charged": True, "attempt": attempt + 1} candidate = response.candidates[0] finish_reason = candidate.finish_reason.name if finish_reason == "STOP": # Success - extract image for part in candidate.content.parts: if hasattr(part, 'inline_data'): return {"success": True, "image_data": part.inline_data.data, "mime_type": part.inline_data.mime_type, "attempt": attempt + 1} elif finish_reason == "SAFETY": # Layer 1 block - safetySettings should prevent this return {"success": False, "reason": "SAFETY_LAYER1", "charged": True, "fixable": True, "fix": "Check safetySettings configuration"} elif finish_reason == "IMAGE_SAFETY": # Layer 2 block - must rephrase prompt if attempt < max_retries - 1: prompt = soften_prompt(prompt) # Retry with modified prompt time.sleep(1) continue return {"success": False, "reason": "IMAGE_SAFETY_LAYER2", "charged": True, "fixable": False, "fix": "Rephrase prompt to avoid safety triggers"} elif finish_reason == "PROHIBITED_CONTENT": # Hard policy violation - do not retry return {"success": False, "reason": "PROHIBITED_CONTENT", "charged": True, "fixable": False, "fix": "Change content entirely"} except Exception as e: if "429" in str(e): return {"success": False, "reason": "RATE_LIMITED", "charged": False} raise return {"success": False, "reason": "MAX_RETRIES_EXCEEDED", "charged": True} def soften_prompt(prompt): """Apply automatic prompt softening for retry attempts.""" prefixes = ["watercolor style illustration of ", "minimalist digital art depicting ", "flat vector illustration showing "] # Cycle through style prefixes on each retry import random return random.choice(prefixes) + prompt
Node.jsの実装
javascriptconst { GoogleGenerativeAI } = require("@google/generative-ai"); async function generateImageSafe(prompt, options = {}) { const { maxRetries = 3, modelName = "gemini-3.1-flash-image-preview" } = options; const genAI = new GoogleGenerativeAI(process.env.GEMINI_API_KEY); const model = genAI.getGenerativeModel({ model: modelName }); for (let attempt = 0; attempt < maxRetries; attempt++) { try { const result = await model.generateContent({ contents: [{ role: "user", parts: [{ text: prompt }] }], generationConfig: { responseModalities: ["IMAGE"] }, safetySettings: [ { category: "HARM_CATEGORY_HARASSMENT", threshold: "BLOCK_NONE" }, { category: "HARM_CATEGORY_HATE_SPEECH", threshold: "BLOCK_NONE" }, { category: "HARM_CATEGORY_SEXUALLY_EXPLICIT", threshold: "BLOCK_NONE" }, { category: "HARM_CATEGORY_DANGEROUS_CONTENT", threshold: "BLOCK_NONE" }, ], }); const candidate = result.response.candidates?.[0]; if (!candidate) { return { success: false, reason: "NO_CANDIDATES", charged: true }; } const finishReason = candidate.finishReason; if (finishReason === "STOP") { const imagePart = candidate.content.parts.find(p => p.inlineData); if (imagePart) { return { success: true, imageData: imagePart.inlineData.data, mimeType: imagePart.inlineData.mimeType, attempt: attempt + 1 }; } } if (finishReason === "IMAGE_SAFETY" && attempt < maxRetries - 1) { prompt = softenPrompt(prompt); await new Promise(r => setTimeout(r, 1000)); continue; } return { success: false, reason: finishReason, charged: true, attempt: attempt + 1 }; } catch (error) { if (error.status === 429) { return { success: false, reason: "RATE_LIMITED", charged: false }; } throw error; } } return { success: false, reason: "MAX_RETRIES_EXCEEDED", charged: true }; }
両方の実装における重要なパターンは同じです。HTTPステータスコードだけを信頼せず、画像データを抽出する前に必ずfinishReasonを検査し、リトライ可能なブロック(ソフト化されたプロンプトによるIMAGE_SAFETY)と終端ブロック(PROHIBITED_CONTENT)を区別します。リトライロジックは、同じ拒否に対して繰り返し支払うことを避けるため、ブラインドリサブミットではなくプロンプトソフト化を使用します。戻り値オブジェクトのchargedフィールドは課金ステータスを明示的に追跡していることに注目してください。これにより、モニタリングシステムが失敗した生成にどれだけ費やしているかを定量化でき、前セクションで取り上げたコスト分析に直接つながります。
IMAGE_SAFETY率のモニタリング
本番デプロイメントでは、IMAGE_SAFETYの拒否率を標準的なAPIモニタリングと並ぶ重要なメトリクスとして追跡すべきです。懸念すべきしきい値はアプリケーションの種類によって異なります。マーケティングやビジネスグラフィックアプリケーションでは5%未満が望ましく、クリエイティブやアーティスティックなアプリケーションでは10~15%が許容範囲であり、ユーザー生成プロンプトアプリケーションでは必然的に高くなります。これらのベンチマークを超えている場合、プロンプトテンプレートに次のセクションで記載されている戦略を用いた体系的な修正が必要です。
プロンプトロジックの変更なしに拒否率が急上昇していないか監視してください。Googleは2026年2月27日のNB2リリース以降、少なくとも2回レイヤー2フィルターを強化しており、以前は正常に生成できていたプロンプトがキャッチされるようになっています。このメトリクスに対して自動アラートを設定してください。理想的にはプロンプトカテゴリー別の拒否率を表示する日次ダッシュボードを使用し、課金ダッシュボードで数週間分の無駄な支出を発見するのではなく、フィルター変更に数時間以内に対応できるようにしましょう。適切に計装されたログシステムは、拒否されたすべてのリクエストについてfinishReasonと共に完全なプロンプトテキストをキャプチャし、フィルターをトリガーしている具体的なフレーズやコンテンツパターンを特定するのに役立つ検索可能なデータベースを作成すべきです。このデータは、プロンプトテンプレートの改善やGoogleがフィルター動作を更新した際の迅速な適応に非常に有用です。
IMAGE_SAFETYブロックを回避する7つのプロンプトエンジニアリング戦略

レイヤー2フィルターはAPI設定では無効化できないため、プロンプトエンジニアリングがIMAGE_SAFETYブロックを減らす唯一のツールです。数百の開発者レポートを分析し、gemini-3.1-flash-image-previewモデルで広範にテストした結果、以下の7つの戦略がほとんどのコンテンツカテゴリーでフィルタートリガー率を60~80%一貫して削減します。
戦略1:アートスタイルをプレフィックスとして付ける。 最も効果的な単一テクニックは、すべてのプロンプトの先頭に明示的なアートスタイルを追加することです。「watercolor illustration of」「flat vector art depicting」「minimalist digital artwork showing」などのフレーズは、写実的な画像ではなく芸術的なコンテンツをリクエストしていることをセーフティ分類器に伝えます。これにより、境界線上のプロンプトのトリガーが劇的に減少します。分類器はスタイル化されたコンテンツを写実的なコンテンツよりも低いリスクスコアで扱うためです。たとえば「a warrior in battle」というプロンプトはIMAGE_SAFETYを頻繁にトリガーしますが、「watercolor illustration of a warrior in battle, peaceful composition」ではほとんどトリガーされません。
戦略2:身体的特徴の描写を役割の描写に置き換える。 画像に人物が含まれる場合、外見ではなく役割、職業、または原型で描写します。衣服、体型、具体的な身体的特徴を描写する代わりに、「a professional chef in a kitchen」や「an engineer examining blueprints」と記述します。このアプローチは、物体化や暗示的と解釈される可能性のある身体的描写に対する分類器の感度を回避します。重要な洞察は、NB2のセーフティフィルターがオリジナルのナノバナナモデルと比較して、人物の描写に対して特に積極的であるということです。これは2026年2月のリリース以降の意図的なポリシー変更と思われます。
戦略3:教育コンテンツには「illustration」や「diagram」を使用する。 医学的、解剖学的、科学的な画像は、写真としてリクエストされた場合にIMAGE_SAFETYを頻繁にトリガーしますが、図表や教育的イラストとしてリクエストされた場合は通過します。アプリケーションが教育コンテンツを生成する場合、常にリクエストを「medical textbook diagram」「scientific illustration」「educational schematic」としてフレーミングしてください。これは、教育的コンテンツと潜在的に有害なビジュアルコンテンツを区別するために分類器がどのように訓練されたかに対応しています。セーフティフィルターの境界を押し広げるコンテンツに取り組む開発者にとって、この再フレーミングテクニックは不可欠です。
戦略4:すべての実名とブランドコンテンツを避ける。 Nano Banana 2は、実在の人物、有名人、公人、認識可能なブランド名やロゴを含むリクエストに特に厳格なフィルタリングを適用します。画像生成プロンプトに実在の人物の名前を含めないでください。代わりに原型や役割を描写します。同様に、特定のブランド名、製品名、商標登録されたビジュアル要素の参照も避けてください。特定のブランドの美学に似たものが必要な場合は、ビジュアルスタイルを抽象的に描写します。特定の企業を参照するのではなく「a minimalist tech company logo with geometric shapes」とします。これは以前のモデルからの大きな変更であり、NB2に移行する際に多くの開発者を驚かせます。
戦略5:ネガティブセーフティ修飾子を追加する。 「no violence」「peaceful scene」「fully clothed」「family-friendly」などのフレーズをプロンプトに明示的に追加することは、セーフティ分類器への追加シグナルとして機能します。これは冗長に思えるかもしれません。結局のところ暴力的なコンテンツをリクエストしているわけではないのですから。しかし分類器はこれらの明示的なシグナルを使用して信頼度スコアを調整します。ネガティブシグナルの不在に頼るのではなく、意図のポジティブな証拠を分類器に提供すると考えてください。
戦略6:複雑なシーンを構成要素に分解する。 複数の要素を記述する単一の複雑なプロンプト(たとえば「a crowded nightclub with people dancing and drinks flowing, neon lights, realistic photo」)は、個別には通過しても集合的にフィルターをトリガーする複数の境界線上の要素を組み合わせます。セーフティ分類器は累積リスクスコアリングアプローチを使用しているようで、単一の要素ではブロックをトリガーしなくても、潜在的にセンシティブな各要素が全体のリスクスコアに加算されてしきい値を超えます。代わりに、背景シーンとキャラクター要素を別々に生成するか、構図を簡素化してリクエストあたりの潜在的なトリガー要素の数を減らします。たとえば上記のナイトクラブプロンプトの代わりに「a modern interior with neon lighting and geometric decor, digital art」と生成します。人物と特定のアクティビティを完全に削除します。このアプローチはプロンプトの効率と信頼性をトレードオフしますが、実際にはよりシンプルな構図がより少ない要素に品質を集中できるため、より良いビジュアル結果を生み出すことが多いです。
戦略7:テキストのみの生成でプリスクリーニングする。 完全な画像生成呼び出し($0.067~$0.151のコスト)にコミットする前に、同じプロンプトをテキストのみのGeminiモデルに送信し、セーフティフィルターをトリガーするかどうかを評価させます。テキストのみの呼び出しはわずか数分の1セント(通常$0.001未満)で、確実に拒否されるものに支払うことを節約できます。これはユーザー生成プロンプトでコンテンツを事前に予測できない場合に特に価値があります。実装は簡単です。「Would this image generation prompt trigger Google's safety filters? Respond YES or NO with a brief reason: [あなたのプロンプト]」というプロンプトをGemini Flash(テキストのみモード)に送信します。プリスクリーニングモデルは異なるセーフティ評価パスウェイを使用するためレイヤー2の動作を完全に予測するわけではありませんが、開発者コミュニティのテストに基づくと、ブロックされるプロンプトの約70%をキャッチします。1日に数千のユーザー送信プロンプトを処理するアプリケーションの場合、このプリスクリーニングステップだけで、最も明らかに問題のあるリクエストを高コストな画像生成パイプラインに到達する前にフィルタリングすることで、月に数百ドルの節約が可能です。
NB2が制限的すぎる場合 ー 代替モデルの比較
上記のプロンプト戦略を適用してもIMAGE_SAFETYブロックに一貫して遭遇する場合、Nano Banana 2はあなたのアプリケーションに適したモデルではないかもしれません。異なる画像生成モデルは異なるセーフティフィルターの方針を持っており、特定のコンテンツカテゴリーにおいて他よりも大幅に寛容なものがあります。
DALL-E 3はOpenAI APIを通じてアクセスでき、芸術的・クリエイティブなコンテンツに対しては一般的にNB2より制限が緩やかですが、写実的な人物の顔に対してはより厳格な別のセーフティアプローチを使用しています。価格は解像度に応じて1画像あたり約$0.040~$0.080と高めですが、クリエイティブコンテンツでの拒否率が低いため、特定のユースケースでは成功画像あたりのコストが安くなる場合があります。Midjourney v6は、芸術的・クリエイティブなコンテンツに対して主要な商用モデルの中で最も寛容ですが、APIアクセスはそのプラットフォームに限定され、サブスクリプションティアによって異なる価格設定です。Flux 2(Black Forest Labs提供)は、より細かいセーフティコントロールと有害でないコンテンツに対する低いフィルター率を持つ開発者フレンドリーなアプローチを採用しています。NB2のフィルターが最も積極的なファッション、キャラクターデザイン、クリエイティブポートレートに特に強みがあります。GPT Image(OpenAIのgpt-image-1モデル)は、適度なセーフティフィルタリングと強力なプロンプト理解力を持つ別の代替手段を提供します。これらのモデルの品質、速度、価格、セーフティの厳格さにわたる包括的な比較については、詳細なモデル比較をご覧ください。
実用的な意思決定フレームワークは、特定のコンテンツニーズと拒否の経済性に依存します。アプリケーションがビジネスグラフィック、マーケティング素材、抽象アートを生成する場合、NB2のフィルターがほとんど干渉することはなく、その速度の優位性(通常1生成あたり2~4秒)が大量生産のユースケースに最適です。アプリケーションがキャラクターデザイン、ファッション、クリエイティブポートレートを含む場合、IMAGE_SAFETY率が十分に高い(リクエストの30~40%を超えることもある)ため、より寛容なモデルが1画像あたり高い価格でも、拒否に支払わないだけでコスト効果が高くなります。重要なメトリクスは、リスト価格の単純な比較ではなく、成功画像あたりの実効コスト(総支出を成功した生成数で割ったもの)です。1画像あたり2倍のコストがかかるモデルでも、拒否がゼロであれば、NB2リクエストの半分以上がフィルターされる場合はNB2より安くなります。
本番アプリケーションには階層的ルーティング戦略の実装を検討してください。フィルターを通過した場合に最良の価格パフォーマンス比を提供するNB2からすべてのリクエストを開始します。最初の試行がIMAGE_SAFETYを返した場合、NB2で同じプロンプトをリトライするのではなく、自動的にフォールバックモデルにルーティングします。このアプローチは、大多数のリクエストでNB2のコスト優位性を捉えつつ、繰り返されるセーフティ拒否の複合コストを回避します。ルーティングロジックは最小限のレイテンシー(フォールバック決定に数百ミリ秒)しか追加しませんが、混合コンテンツタイプのアプリケーションでは実効画像あたりのコストを20~40%削減できます。
移行リスクを最小化したい開発者にとって、laozhang.aiのようなプラットフォームは単一のエンドポイントを通じて複数の画像生成モデルをサポートする統合APIを提供しています。これにより自動フォールバックの実装が可能です。速度とコスト優位性のためにまずNB2を試し、IMAGE_SAFETYブロックが発生した場合は自動的に代替モデルにルーティングします。このアプローチは大多数のリクエストでNB2の速度を捉えつつ、繰り返されるセーフティ拒否のコストを回避します。
よくある質問
なぜNano Banana 2は画像がブロックされたのに200 OKを返すのですか?
GoogleはGemini APIを、出力コンテンツがセーフティシステムによってフィルタリングされたかどうかに関係なく、サーバーが正常に受信・処理したすべてのリクエストに対してHTTP 200を返すように設計しました。GoogleのAPI設計の観点からは、サーバーはリクエストを正常に処理しました。セーフティフィルターはアプリケーションレベルの判断であり、トランスポートレベルのエラーではありません。レスポンスボディのfinishReasonフィールドが、コンテンツ生成試行の実際の結果を示します。この設計は、ほとんどのREST APIがコンテンツフィルタリングを処理する方法とは異なります。たとえばOpenAIのDALL-Eはセーフティブロックに対して4xxエラーコードを返します。これが初めてNB2を統合する開発者にとって主な混乱の原因です。実務上の含意として、HTTPステータスコードのチェックだけでは不十分であり、常にレスポンスボディを解析してfinishReasonフィールドを検査する必要があります。
BLOCK_NONEですべてのセーフティフィルターが無効化されますか?
いいえ。BLOCK_NONEはレイヤー1の確率的フィルター(HARASSMENT、HATE_SPEECH、SEXUALLY_EXPLICIT、DANGEROUS_CONTENT)にのみ影響します。レイヤー2のハードコードされたフィルター(IMAGE_SAFETY、PROHIBITED_CONTENT、CSAM、SPII)はsafetySettingsの設定に関係なく常にアクティブのままです。これはすべてのGemini画像生成モデルに適用されるGoogleの交渉不可能なポリシーです(ai.google.dev/safety-settings、2026年3月に確認済み)。
画像のない200 OKレスポンスでも課金されますか?
はい。finishReason: "IMAGE_SAFETY"を含むものを含め、すべての200 OKレスポンスは標準のトークン処理レートで課金されます。サーバー側のエラー(429、500、503)のみが課金されません。これは、IMAGE_SAFETYブロックのたびに1Kで約$0.067、4Kで約$0.151のコストが発生することを意味します(ai.google.dev/pricing、2026年3月時点)。
SAFETYとIMAGE_SAFETYのfinishReason値の違いは何ですか?
SAFETYはレイヤー1のブロック(設定可能、safetySettingsで修正)を示します。IMAGE_SAFETYはレイヤー2のブロック(設定不可、プロンプトの言い換えで修正)を示します。どちらも画像データのない200 OKレスポンスとなりますが、修正戦略はまったく異なります。修復アプローチを決定する前に、どの具体的な値を受け取ったかを必ず確認してください。
Nano Banana 2はオリジナルのナノバナナより制限的ですか?
はい。Nano Banana 2(gemini-3.1-flash-image-preview、2026年2月27日リリース)は、特に有名人の顔、暗示的なコンテンツ、ブランド画像に関して、オリジナルのナノバナナモデルと比較してより厳格なレイヤー2フィルタリングを適用します。オリジナルモデルで正常に画像を生成できたプロンプトが、プロンプトテキストを変更していないにもかかわらず、NB2ではIMAGE_SAFETYをトリガーする可能性があります。
まとめと次のステップ
Nano Banana 2における200 OKで画像なしの問題はバグではありません。コンテンツフィルタリングがアプリケーションレイヤーで行われる一方でHTTPトランスポートが成功を報告するという、Googleによる意図的な設計選択です。本ガイドからの最も重要なポイントは以下の通りです。第一に、HTTPステータスコードを信頼するのではなく、すべてのAPIレスポンスでfinishReasonをチェックすること。第二に、レイヤー2フィルター(IMAGE_SAFETY)は無効化できず、プロンプトレベルの修正が必要であることを理解すること。第三に、拒否率をモニタリングし課金への影響を定量化すること。なぜなら、フィルターされた200 OKレスポンスは全額課金されるからです。
直ちに取るべきアクションは以下の通りです。上記で提供されたPythonまたはNode.jsテンプレートを使用してアプリケーションコードにfinishReasonの解析を実装すること。最も一般的なプロンプトテンプレートにアートスタイルプレフィックス戦略を適用すること(これだけで失敗を40~60%削減します)。そしてIMAGE_SAFETY拒否率にモニタリングを設定し、プロンプトの問題とGoogle側のフィルター強化の両方を早期に検出すること。フィルター率が高いアプリケーションでは、成功画像あたりの実効コストを計算し、マルチモデルフォールバック戦略が全体の支出を削減するかどうかを評価してください。
Googleが引き続きGemini画像生成パイプラインを開発するにつれて、レイヤー2フィルターの動作は進化する可能性が高いです。最善の防御は、フィルターされたレスポンスを即座に検出し、分析のためにコンテキストをログに記録し、適切な場合に代替手段にルーティングする回復力のあるアプリケーションアーキテクチャです。IMAGE_SAFETYをフラストレーションの溜まる制限ではなくシステム設計の課題として扱う開発者こそが、Googleがセーフティしきい値をどのように調整しても確実に動作するアプリケーションを構築する人々です。