
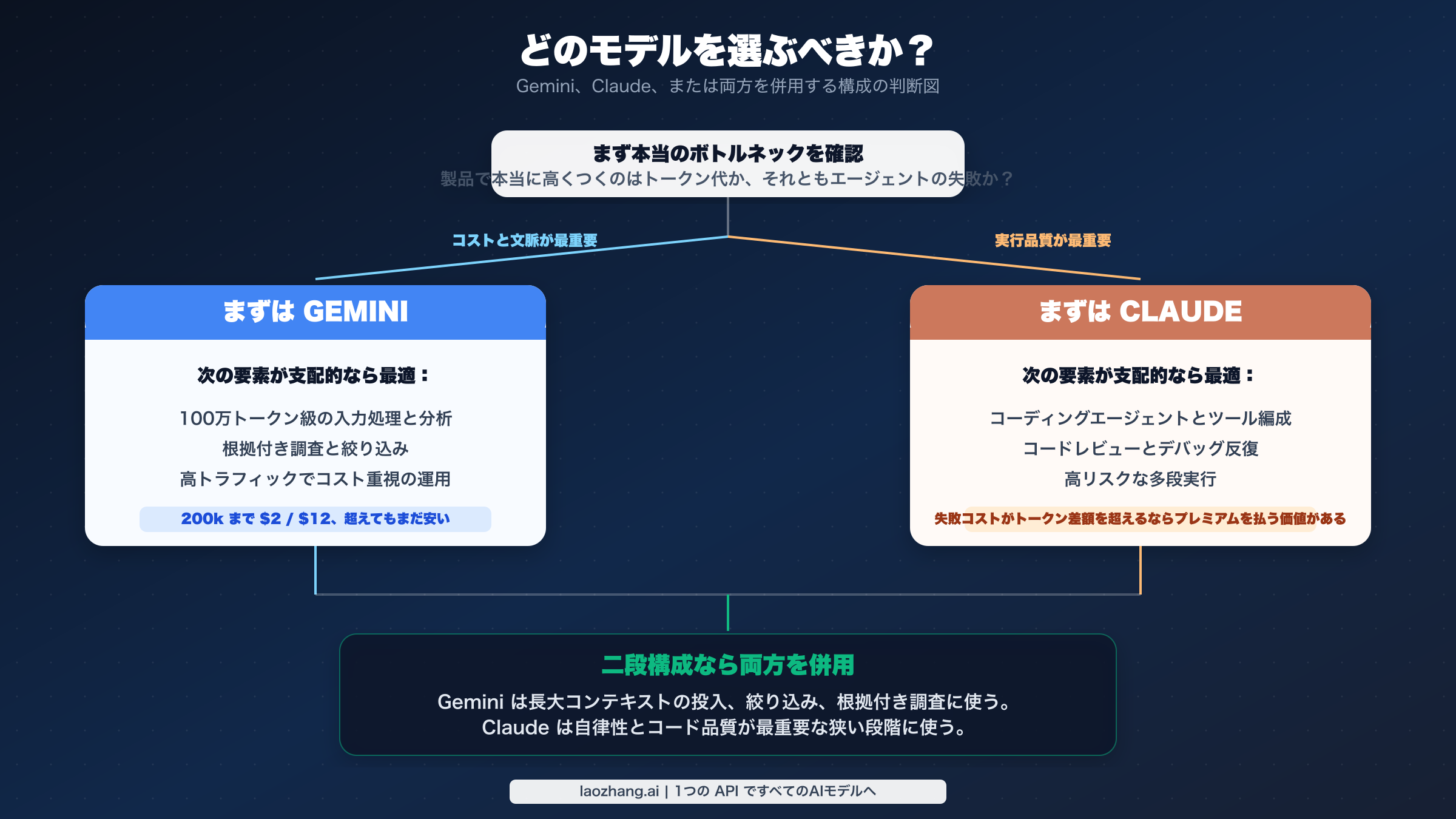
「Gemini 3.1 Pro vs Claude Opus 4.6」を検索する開発者の多くは、モデル比較の思想を読みたいわけではありません。知りたいのはもっと単純で、「結局どちらを先に試すべきか」です。2026年3月時点の実務的な答えは明快です。主な課題が長文脈処理とコスト管理なら Gemini から始める。コードエージェントの信頼性が最重要なら Claude から始める。入力の広い段階と実行の狭い段階が分かれているなら、両方を残して用途別に使い分ける。これがいちばん速くて現実的な判断です。
この答えが成り立つのは、両社の公式根拠が非対称でも、設計判断には十分役立つからです。Google は価格、token 上限、長文脈向けの立ち位置をより明快に示しています。Anthropic は高品質なコーディングと自律実行に関する公開根拠をより強く出しています。問題は benchmark を見ることではなく、benchmark 表、Preview 表記、beta の文脈拡張、別 SKU を一枚の対称的な総合スコアだと見なしてしまうことです。
先に答えだけ知りたい人へ
運用量の大半が文書分析、repository の投入、検索で裏づけた調査、あるいは長い prompt を多く使うコスト重視の処理なら、まず Gemini 3.1 Pro Preview を試すべきです。最難関が code review、patch 生成、多段のツール実行、debugging のように、初回失敗がそのまま人手の手戻りになる仕事なら、まず Claude Opus 4.6 を試すべきです。もしシステムが最初から「広く文脈を集める段階」と「品質重視で実行する段階」に分かれているなら、永久的な勝者を一つ決める必要はありません。両方を維持し、タスク別に使い分ける のが最も合理的です。2026年3月の段階では、この結論が公式価格、上下文制限、製品ポジショニングに最もよく合っています。
| もし主な用途が…… | まず試すべきモデル | 理由 |
|---|---|---|
| 長い文書、repository 取り込み、コスト重視の分析 | Gemini 3.1 Pro Preview | 公式価格が低く、100万 token 入力の扱いも明快 |
| code review、debugging、多段の tool use、patch 生成 | Claude Opus 4.6 | コーディング自律性に関する公開根拠がより強い |
| 広い入力段階 + 狭い実行段階 | 両方を併用 | Gemini が文脈の重い処理を担当し、Claude が高価値な実行を担当できる |
benchmark はどう読むべきか
検索ユーザーが benchmark を気にするのは当然です。問題は benchmark 自体ではなく、この組み合わせに「完全に対称な公開スコア表」が存在しないことです。Anthropic は Opus 4.6 について、Terminal-Bench 2.0、Humanity's Last Exam、BrowseComp、GDPval-AA などを使い、「高品質な coding と autonomy の premium モデルである」と比較的わかりやすく主張しています。Google の Gemini 3.1 Pro Preview は別の方向で強く、価格、100万 token 入力、token efficiency、grounded behavior、開発向け挙動を公開しています。したがって実務的な読み方はこうです。benchmark を見るなら Claude が coding-agent 評価の第一候補かを判断するために使う。価格と token 上限を見るなら Gemini が長文脈・コスト重視システムの第一候補かを判断するために使う。Sonnet、Opus、Preview 変種、beta context を全部混ぜた比較表は、そのまま信じないほうがいいです。
まず何を比較しているのか?

最初に修正すべきなのは比較対象そのものです。「Gemini 3.1」と言うと、Gemini 3.1 Pro Preview、Gemini 3.1 Pro Preview Customtools、あるいは周辺ツールが参照する別バリアントまで混ざりがちです。Claude Opus 4.6 と API 比較をするなら、もっとも筋が良い対象は Gemini 3.1 Pro Preview です。Google がこのモデルについて価格、token 制限、software engineering 向けの位置づけをきちんと公開しているからです。Anthropic 側の対応相手は Claude Opus 4.6 であり、Sonnet 4.6 ではありません。Sonnet は別の価格帯の判断です。Claude の価格階段を広く見たい場合は、別記事の Claude Opus 4.6 pricing guide を読むほうが適切です。
公開日も重要です。Google は 2026年2月19日 に Gemini 3.1 Pro を公開し、公式ページではいまも Preview としています。Anthropic は 2026年2月5日 に Claude Opus 4.6 を公開し、最新の Opus クラスであり複雑推論とコーディングに最も強い選択肢として位置づけています。つまりこの比較は鮮度依存です。Gemini 2.5 や Claude 4.1 の時代の前提で書かれた記事は、少し古いだけでなく、間違った設計判断を誘導します。
ハードスペックだけでも方向性は見えてきます。Google のモデル文書は Gemini 3.1 Pro Preview に 1,048,576 入力 token と 65,536 出力 token を明記しています。Anthropic の model overview は Opus 4.6 に 200k context と 128k max output を示し、別の launch post では 1M-token context window in beta と説明しています。これは細かい仕様ではありません。巨大な入力を扱うワークロードが中心なら、Gemini の公表内容はより明快で安価です。一方、極端に長い生成結果を一度に必要とするなら、Claude の 128k 出力上限は明確な優位になります。
| 項目 | Gemini 3.1 Pro Preview | Claude Opus 4.6 |
|---|---|---|
| 公開日 | 2026-02-19 | 2026-02-05 |
| ステータス | Preview | 現行フラッグシップ |
| 入力価格 | <=200k は $2/MTok、>200k は $4/MTok | $5/MTok |
| 出力価格 | <=200k は $12/MTok、>200k は $18/MTok | $25/MTok |
| 入力コンテキスト | 1,048,576 tokens | overview では 200k、launch post では 1M beta |
| 最大出力 | 65,536 tokens | 128k tokens |
| 公開されている性能シグナル | 長文脈とコスト管理に強い | 高負荷なコーディングと自律実行に強い |
| 公式の強み | better thinking、token efficiency、grounded behavior、software engineering、precise tool usage | complex coding、agentic work、computer use、tool use、search、finance |
この節で一つだけ覚えるなら、「Gemini は安い Claude ではなく、Claude は高い Gemini でもない」という点です。両者は異なる failure profile に対して売られています。Gemini は長文脈を抱え、ツールを正確に使い、なおかつ価格競争力を保つ workhorse です。Opus は、コーディングや高自律な実行での失敗ループを減らすことでプレミアムを回収する前提のモデルです。
価格とコンテキスト:Gemini が標準の価値候補になる理由
結論: コストと prompt サイズが選定を左右するなら、Gemini を出発点にすべきです。
根拠: Google は 200k まで $2/$12、それ以上で $4/$18 という価格を公開し、さらに 1,048,576 token の入力上限を明記しています。
選び方: 文書分析、repository 取り込み、batch 抽出、高流量の評価ループのように、文脈量と単価が重要な処理ではまず Gemini を試します。
公式 API 価格だけを見れば、Gemini 3.1 Pro Preview は最初から強いアドバンテージを持っています。Google の公式 pricing pageによれば、Gemini 3.1 Pro Preview は prompt が 200k token 以下なら 入力 $2.00 / 出力 $12.00 per million tokens、200k を超えると 入力 $4.00 / 出力 $18.00 です。Anthropic のpricing documentationでは Claude Opus 4.6 は 入力 $5.00 / 出力 $25.00 です。つまり一般的な <=200k ケースでは、Gemini は入力で 60%、出力で 52% 安い。長大プロンプト tier に入っても、入力で 20%、出力で 28% 安いままです。
重要なのは、この優位が 閾値依存 だということです。安い tier だけを見て「Gemini は圧倒的に安い」と言ってしまう記事は多いですが、実運用では 200k をどれだけ超えるかで見え方が変わります。普通の interactive coding tool、support copilot、構造化 document Q&A、ほどほどの planning agent であれば、多くのリクエストはこの閾値以下に収まり、Gemini の価格差は大きく感じられます。逆に巨大な repository、長い legal bundle、膨大な research packet を毎回そのまま文脈に投げ込むと、Gemini の価格は上がります。それでも Opus よりは安いですが、差は「圧勝」ではなく、品質と合わせて解釈すべき幅になります。
batch と caching を考えると、比較はさらに実務的になります。Google は Gemini 3.1 Pro Preview の batch pricing を <=200k で $1/$6、>200k で $2/$9 としています。Anthropic は Opus 4.6 の batch を $2.50/$12.50 です。repository indexing、大規模抽出、夜間の分析バッチのような非同期処理では、両社とも標準価格よりかなり実用的になりますが、それでも Gemini のほうが低コストです。キャッシュについては、Google が明示的な価格+保存モデル、Anthropic が write multiplier と低い read multiplier という形で、比較の仕方が異なります。ただ戦略的な結論は同じです。静的コンテキストを毎回送り直さない設計にすると、両社ともかなり効率が上がります。
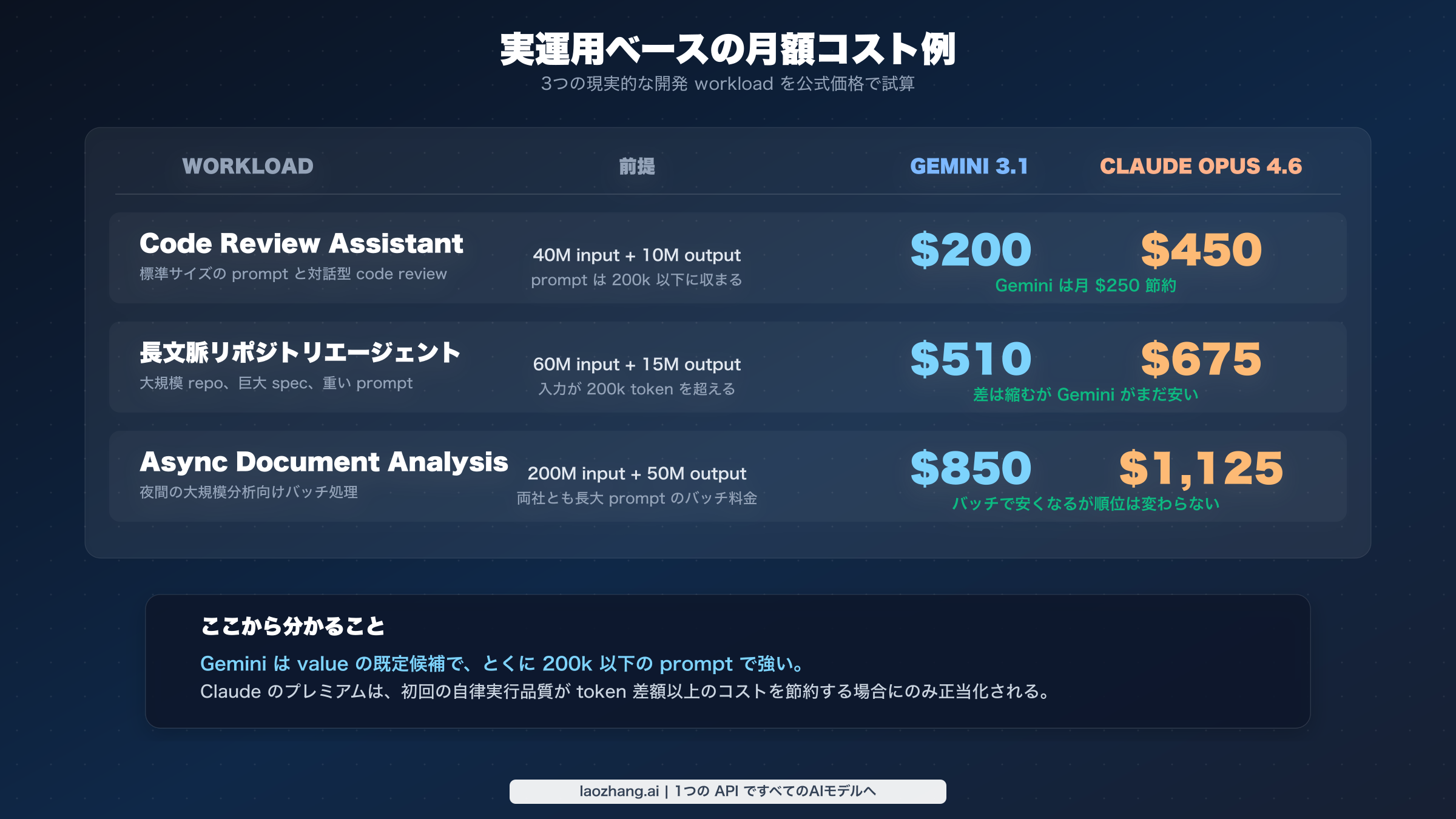
この価格差を、実際の月次シナリオで見ると次のとおりです。
| ワークロード | 前提 | Gemini 3.1 Pro Preview | Claude Opus 4.6 |
|---|---|---|---|
| Code review assistant | 40M input、10M output、prompt <=200k | $200 | $450 |
| Long-context repo agent | 60M input、15M output、prompt >200k | $510 | $675 |
| Async document analysis(batch) | 200M input、50M output、長大 prompt の batch | $850 | $1,125 |
これらはあえて単純化した数字です。search grounding の追加料金、cached context の storage、そしてモデル品質の差は含めていません。示したいのは価格の形です。通常プロンプトでは Gemini の効率は二倍以上に見えます。長文脈では価格差が縮みます。batch にすると両方ラクになりますが、順位は変わりません。
この価格解釈を左右するのがコンテキストです。Gemini 3.1 Pro Preview は 1,048,576 token 入力 を公開値として提示しています。Anthropic の overview は Opus 4.6 を 200k context と示しており、多くのチームはまずそこを既定前提にするでしょう。たとえ launch post に 1M-token context window が beta と書かれていてもです。アプリケーションのロードマップが「100万 token 入力を平常運転で使う」ことを前提にしているなら、Gemini の資料は圧倒的に扱いやすい。一方で、長い生成結果が重要なら、Claude の 128k output が逆方向の説得材料になります。
もう一つ見落とされがちな点があります。Google は Grounding with Google Search を無料枠の後で別料金にしています。Anthropic の価格ページは token、caching、fast mode、batch、regional inference をより前面に出しています。そのため、grounded search を組み込むプロダクトでは Gemini は魅力的ですが、token 単価だけでは請求総額を読めません。そこまで含めて判断したいなら、事前に Gemini 3.1 Pro Preview access guide を見ておくと設計が楽になります。
コーディングとエージェント実行:Claude Opus 4.6 が高くても検討される理由
結論: 失敗のコストが token 料金よりも人間の手戻りとして大きいなら、Claude Opus 4.6 を先に評価する意味があります。
根拠: Anthropic は coding、tool use、debugging、code review、長時間の agentic execution について、Google より直接的な公開根拠を出しています。
選び方: コーディングエージェント、patch 生成、多段のツール実行、debugging 系ワークフローでは、まず Claude を先頭に置きます。
もし価格だけがすべてなら、この比較はとっくに終わっています。それでも Opus 4.6 を真剣に評価すべき理由は、Claude の公式証拠が、現場で最も高くつく失敗箇所にかなり強く寄っているからです。Anthropic の launch post は、Opus 4.6 が coding skill を改善し、より慎重に計画し、agentic task をより長く持続し、大規模 codebase でより安定し、code review や debugging で自分のミスを見つけやすいと明言しています。これは抽象的なブランド表現ではありません。コーディングエージェントが「実際に頼れる相棒」になるか、「後片付けを増やす高価な助手」になるかを分ける挙動そのものです。
ここで重要なのは、間違ったモデルのコストは token 請求額だけではない ということです。安い長文脈モデルでも、誤ったツール操作を繰り返し、repository 全体の副作用を見落とし、何度も retry しないと使いものにならないなら、総コストでは高くつきます。そうした状況では、Opus の価格プレミアムは十分に合理的です。一度で通る結果は、三回のやり直しより安いことが多い。しかも失われるのは token だけではなく、開発者時間、CI 分、レビューの集中力です。
証拠の非対称性はここでも効きます。Google は Gemini 3.1 Pro Preview を software engineering behavior、groundedness、token efficiency、precise tool usage が必要な agentic workflow に最適化したと述べています。これは前向きな材料です。しかし本文で使った公式ソースの範囲では、Google は Anthropic ほど直接的に「Gemini は最高の coding autonomy モデルだ」と benchmark 中心で主張してはいません。つまり、コーディング中心の製品で限られた高コスト評価時間をどちらに先に割くべきかという問いに対しては、Opus のほうが一次情報の裏付けが厚いのです。Gemini は費用対効果の高い長文脈評価に向き、Opus は高品質な coding evaluation に向きます。
別の言い方をすれば、Opus 4.6 の価値は「一回のリクエストにより多くの責任を持たせる」ときに最大化します。patch の作成、ツールの指揮、複数ファイルにまたがる debugging、あるいは高価値の調査結果を人間が細かく付き添わなくても信頼できる形でまとめる、といった場面です。逆に、モデルの役割が長い入力の ingestion、分類、要約、一次分析であり、その後に第二モデルや人間が引き継ぐなら、Gemini の経済性のほうが自然です。
この点を無視して「コーディング勝者」を一つの benchmark 行で決めようとする記事は、重要なものを落とします。実際のソフトウェア開発は code generation だけではありません。タスクの切り分け、tool choice、repository navigation、error recovery、code review、そして多段の実行中に整合性を保つ力まで含まれます。Anthropic は Opus 4.6 でそこを正面から訴求しています。Google の Gemini はより長文脈・grounded・tool-precise なエンジニアリング作業に向けた訴求です。両者は重なりますが同一ではなく、プレミアムの正当性は自社プロダクトがどちら寄りかで決まります。
長文脈・根拠付きの調査・大きな入力で Gemini が前に出る理由
結論: Gemini の最大の強みは、大きな入力を扱う仕事で規模・コスト・grounded behavior を同時に取りやすいことです。
根拠: Google は 100万 token の入力枠、低価格、grounding の料金体系を公開しており、大入力システムへ組み込みやすい条件がそろっています。
選び方: 調査支援、長文書パイプライン、repository 解説のように、入力の取り込みと統合が本当のボトルネックである場合は Gemini を先に試します。
Gemini のもっとも明快な優位は、「十分良いのに安い」ことではありません。公開された 100万 token 入力枠、低価格、そして grounding の料金体系が一つにまとまっており、大きな入力を扱うシステムの既定候補として説明しやすいことです。社内調査ツール、repository explainer、契約分析パイプライン、議事録や transcript の統合分析、あるいは大量の一次資料を一度に読ませる必要があるワークフローなら、Gemini 3.1 Pro Preview は第一原理から見ても魅力的です。Opus 級の flagship 価格を払わずに大きなコンテキストを得られますし、200k 超の tier でもまだ Claude Opus より安い。
Google の公式な位置づけもこの使い方と噛み合っています。model page が強調するのは improved token efficiency、more grounded / factually consistent behavior、そして正確な tool usage が必要な agentic workflow です。これは「最強の自律 coding モデル」というより、「現実のプロダクトで使える長文脈 reasoning engine」と読むほうが近い。pricing page が search grounding の課金を明示しているのも、巨大コンテキストと新しい情報取得を組み合わせる設計には都合が良い。予算設計は面倒になりますが、本番システムを正直に見積もるにはむしろ健全です。
入力が大きくなるほど、Gemini の優位はさらにわかりやすくなります。長文脈ワークロードは表面上 reasoning に見えても、実際には ingestion と recall がボトルネックです。十分な資料を一つの一貫したフレームに押し込めるかどうかが勝負になります。だからこそ、公開済みの 1,048,576 token 入力上限と、既定 200k context の差は運用上の意味が大きい。たとえ Opus の 1M beta context が自社環境で十分機能したとしても、今日の時点で「100万 token を前提に設計しやすい」のは Gemini のほうです。
もちろん、これで最終工程まで Gemini に任せるべきだという意味ではありません。むしろ良い設計は、Gemini で ingestion、filtering、large-context synthesis を行い、その後の hardest coding / autonomy step を Claude に回すことです。それは過剰設計ではなく、二つの異なるボトルネックに別の強みを当てるという自然な分解です。
避けるべき微妙な失敗は、「Gemini が安いから全段に入れる」という発想です。Google の文書から導くべき結論は「Gemini が Claude を置き換える」ではなく、「context size、groundedness、直接コストが、プレミアムな first-pass autonomy より重要な場面では Gemini を既定候補にすべき」というものです。多くの組織では、それだけでかなり大きな割合の本番トラフィックを説明できます。
本番運用の現実:Preview、beta、そのラベルの意味
結論: ステータス表記は補足情報ではなく、設計判断の一部です。
根拠: Gemini 3.1 Pro は公式に Preview のままであり、Opus 4.6 の 1M context も Anthropic の公開資料ではまだ beta とされています。
選び方: rollout を制御しやすく fallback を組める環境なら Gemini は十分候補になります。Opus の 1M context を前提にするなら、まず beta 経路を自分の環境で検証すべきです。
最悪のモデル選定は、ステータスラベルを広告の飾りのように扱うことから始まります。あれは deployment signal です。Google が Gemini 3.1 Pro を Preview と明記している事実は、使い方に直結します。Preview は「使えない」ではありません。より速い反復、挙動の変動、そして成熟モデルより強い回帰テスト要求を受け入れるべき、という意味です。内部ツール、evaluation loop、fallback を持つ長文脈分析システム、厳密に rollout を制御できるプロダクトなら十分許容できます。しかし、対外向けの mission-critical workflow で唯一の判断源にするなら、慎重さは増します。
Anthropic 側は少し違いますが、ノーリスクではありません。Opus 4.6 自体は current flagship として位置づけられ、model overview も通常の本番計画に耐えます。ただし 100万 token の話は launch post で依然 beta と表現されています。したがって、「Claude Opus 4.6 はどこでも完全に正規化された 1M context を持つ」と設計書に書くのは、自社環境で beta path を検証してからにすべきです。安全な言い方は、本稿でも使っているとおり、「overview では 200k が既定、1M は launch announcement 上の beta capability」です。
この整理から、現実的な運用姿勢は次のようになります。
| 運用上の論点 | Gemini 3.1 Pro Preview | Claude Opus 4.6 |
|---|---|---|
| 公式ステータス | Preview | 現行フラッグシップ |
| もっとも安全な前提 | 100万 token 入力は文書化された製品能力 | 200k が文書化された既定、1M は beta capacity とみなす |
| 現時点で自然な用途 | 長文脈の社内ツール、evaluation loop、根拠付きの調査 | プレミアム coding agent、高自律タスク、長い出力の統合生成 |
重要なのは、ラベルそのものが適否を決めるわけではないことです。Preview でも、強みが仕事に合っていて fallback を組めるなら正しい選択になりえます。beta の拡張能力でも、保証ではなく optional capacity として扱うなら十分に使えます。避けるべきなのは、「どちらも 1M と言っているから status は無視できる」と平坦化することです。status は、ベンダーがまだ形を変えつつある挙動に、あなたのアーキテクチャがどれだけ依存しているかを示します。
もしこの運用差分の重さが判断しづらいなら、それ自体が「単一モデルに賭けないほうがいい」サインです。両方を reachable にしておき、各モデルの文書が最も強い段階で使う。そのほうが、不完全な対称性から無理に永久勝者を作るより安全です。
では、どちらを選ぶべきか?
ここまで来れば推奨はかなり明快です。まず Gemini 3.1 Pro Preview を選ぶべきなのは、巨大な prompt を合理的な価格で処理したいとき、grounded research や document-analysis flow を作るとき、または Opus 級の料金を毎回払わずに長文脈プロダクトの仮説検証を回したいときです。高トラフィック帯の多くが ingestion、filtering、retrieval-heavy analysis、一次の engineering assistance に寄るなら、Gemini は素直な出発点です。
まず Claude Opus 4.6 を選ぶべきなのは、プロダクトの hardest part が agentic coding、tool orchestration、code review、大規模 repository 上の debugging、あるいは first pass を外すと痛い premium reasoning であるときです。この領域では Anthropic の一次情報が明確に強い。モデルのミスが manual repair、retry loop、開発者の信頼低下につながるなら、Claude の価格プレミアムは表よりもはるかに理解しやすくなります。
両方をルーティングすべきなのは、実システムがすでに二段構えになっている場合です。高流量の大文脈ステージと、より狭いが品質要求が高い実行ステージです。2026年の多くの技術チームでは、これがもっとも筋の通った答えになるでしょう。Gemini で広い入力を吸収し、grounded analysis を行い、Claude で狭いが価値の高い execution step を担う。単一モデルに寄せたくなるのは運用の気持ちとして自然ですが、その簡単さのために性能と費用の両方を捨てることもあります。
ここで product mention が実際に役立つ形になります。Google と Anthropic の両方を試したいが、最初から鍵管理、請求、routing glue を別々に持ちたくないなら、laozhang.ai のような unified gateway は実務的です。価値は「魔法の安さ」ではなく、dual-model architecture を試しやすくすることにあります。
より大きなパターンとして、2026年の正解は固定的なベンダー忠誠ではなく workload strategy であることが多い。この文章を読んで「本当の問いは二モデル比較より広い」と感じたなら、次に読むべきはさらに狭い benchmark 記事ではなく、この主要プロバイダー比較です。
一週間を無駄にしない評価方法
この比較がネット上で歪みやすい理由の一つは、抽象的な議論で決着をつけようとするからです。Gemini 3.1 Pro Preview と Claude Opus 4.6 の正しい評価は、「派手な一問を両方に投げて見た目のいい回答を選ぶ」ことではありません。実際に production でお金を払う workload bucket ごとに切り分けて評価することです。それをしないと、誤ったものを benchmark し、デモタスクにアーキテクチャを過剰適合させます。
もっともきれいな方法は 三つの workload track を作ることです。第一は large-context synthesis track。長い文書、大きな repository、research packet、仕様書群などを使い、大きな入力をどう ingest し reasoning できるかを見る。第二は coding and agent track。multi-file 変更、tool-using task、debugging、code review、反復的な repository task を使い、行動しながら整合性を保てるかを見る。第三は grounded analysis track。外部情報の利用や、新しい資料の cross-check が必要なタスクを置き、静的 prompt 内の知識だけでは足りない作業を測る。この三つの軸は、まさに本稿が示してきたトレードオフそのものです。
そして測るべきは抽象的な answer quality ではなく、first-pass usefulness です。各タスクで見るべき数字は少なくとも四つあります。初回回答がそのまま使えたか、何回の retry / correction が必要だったか、総 token cost はいくらか、人間の repair time はどれくらいか。前二者は Claude のプレミアムが execution quality に見合うかを教えます。三つ目は Gemini が 200k を超えた後でも安さを維持しているかを示します。四つ目は公開比較で最も欠けがちな指標です。API 請求が安いモデルが、必ずしも総システムコストで安いわけではありません。
Gemini を評価するときは prompt length の分割 を強制したほうが良いです。明確に 200k 未満の bucket と、明確にそれを超える bucket を分けてください。そうしないと、低価格 tier だけ見て「Gemini は劇的に安い」と誤解します。Claude については、公開されている 128k output が、一回の応答で完了できる作業量にどう効くかをよく見てください。長いレポート、大規模 code transform、巨大な structured output が多いプロダクトでは、この出力余裕は benchmark 数行より重要です。
評価ハーネス自体も reversible に作るべきです。同じ instructions、同じ scoring rubric、可能な限り同じ周辺インフラを使う。将来的に両社を route する可能性があるなら、prompt format と success criteria を最初から portable にしておく。ここで自前 router でも laozhang.ai のような unified gateway でも、adapter layer が活きます。目的は便利さそのものではなく、モデル環境がまだ高速で変わる時期に optionality を保つことです。
きちんと評価すると、結論はしばしばネットの見出しより地味です。Gemini がスタックの一部で明確に良く、Claude が別の一部で明確に良い。そして本当の勝ち筋は両方の経路を保持することにある。単一の勝者を無理に決めるより、こちらのほうが長く使える設計になります。
実際にアーキテクチャを変える統合上の違い
この二モデルのもっとも重要な差は headline の能力ではなく、router、予算、運用監視の設計を変える細部です。
第一に、Gemini の価格閾値は routing 前の token counting を要求します。 リクエストが 200k prompt token をまたぐなら、Gemini の安い headline price を定数として扱ってはいけません。これは Gemini が悪い取引だという意味ではなく、router が prompt size を入力に含める必要がある、という意味です。ここを無視すると、コスト見積もりも escalation rule もぶれます。
第二に、Claude の output limit は一回の実行でできる仕事量を実際に変えます。 Opus 4.6 の 128k max output は、patch generation、長文統合、巨大な structured report に直接効きます。Gemini の 65,536 も大きいですが、差は無視できません。
第三に、grounding と caching の経済性はモデル固有です。 Google は search grounding の料金を明示し、Anthropic は prompt caching multiplier や regional inference premium を明示しています。production economics を真面目に見るなら、これらを「その他コスト」に押し込まず、個別にモデル化すべきです。
第四に、一つのモデルに標準化する前に evaluation harness を標準化すべきです。 prompt、test case、success criteria を portable にしておけば、モデル選択は可逆なままです。将来的に両社 routing がありうるなら、docs.laozhang.ai のような窓口を含め、統合レイヤーを早めに入れておく意味があります。
要するに、モデル選定を一度きりのブランド選びとして設計してはいけません。コンテキスト上限、自律性能、価格曲線は今後も動きます。動く前提で設計するべきです。
よくある質問
Gemini 3.1 Pro Preview は Claude Opus 4.6 より安いですか?
はい。公式価格では両 tier で Gemini のほうが安いです。200k token 以下では Gemini が $2/$12、Opus が $5/$25。200k 超では Gemini は $4/$18 に上がりますが、それでも安さは維持します。
Claude Opus 4.6 はコーディングに向いていますか?
公式の裏付けという意味では、はい。Anthropic は coding、debugging、code review、computer use、長時間の agentic work を明示的に訴求しています。Google も Gemini を software engineering 向けと位置づけていますが、本稿で使った一次情報では、同じ強さの benchmark 主張は出していません。
Claude Opus 4.6 は本当に 1M context ですか?
Anthropic の launch post は 1M token context window を beta と述べています。一方で model overview は 200k context を示しています。本番解釈として安全なのは、「200k が文書化された既定、1M は依存前に検証すべき beta capability」と考えることです。
Gemini がまだ Preview なら避けるべきですか?
必ずしもそうではありません。Preview は rollout のしかたを変えるべきだという意味であって、自動的な除外理由ではありません。内部ツール、評価系、長文脈分析、fallback 可能な workflow なら依然として強い選択肢です。
多くのチームは一つに絞るべきですか、それとも両方 route すべきですか?
多くのチームでは routing のほうが合理的です。Gemini は高流量の長文脈作業、Claude はプレミアムな coding と高自律 execution に向いています。システムが両方の仕事を持つなら、単一モデルに固定するより二経路を維持したほうが堅実です。