
もし今日すぐに本番のモデル選定をしなければならないなら、DeepSeek V4、Claude Opus 4.6、GPT-5.4 を最初から同じ精度で公開されている三つの契約だと考えないほうが安全です。考え方の順序はこうです。GPT-5.4 は、いま最も明確な OpenAI の現行契約、computer use と tool use に関する公式な説明、そして Codex とつながる運用面を重視するなら先に試す価値があります。Claude Opus 4.6 は、長い coding タスク、大きい working set、あるいは弱い first pass がそのまま高い手戻りコストになる仕事なら先に試す意味があります。現在の DeepSeek は、最優先がコスト下限である場合に依然として有力ですが、そのときも前提にすべきなのは今日 docs で確認できる DeepSeek-V3.2 ベースの public API であって、まだ確認できていない公開 V4 row ではありません。
ここは単なる言葉の厳密さではなく、比較対象の定義そのものです。2026年4月4日 時点で、OpenAI と Anthropic は GPT-5.4 と Claude Opus 4.6 の current model page と pricing を公開しています。一方、DeepSeek の current public API docs では deepseek-chat と deepseek-reasoner が依然として DeepSeek-V3.2 を指しています。これは DeepSeek が無関係だという意味ではありません。意味するのは、今日の正直な比較は「三者で勝敗を決めること」ではなく、「公開済みの二つの frontier contract をまず直接比較し、そのあと現在の DeepSeek をどの stage に置くか決めること」だということです。
| もし bottleneck がこう見えるなら | 最初に route する先 | 理由 |
|---|---|---|
| 最も明確な OpenAI の現行契約と、公開資料で確認できる computer use / tool use の強みが欲しい | GPT-5.4 | OpenAI は pricing、benchmark、標準 context と Codex の experimental 1M support の境界をかなり明確に書いています |
| long-horizon coding や high-cost cleanup が本当のコストになる | Claude Opus 4.6 | Anthropic は 1M context と 128k max output を持つ current flagship をはっきり提示しています |
| まず必要なのが最も安い public API stage である | 現在の DeepSeek API | DeepSeek の public docs は V3.2-backed contract を示しており、価格は GPT-5.4 や Opus よりかなり低いです |
確認メモ: OpenAI、Anthropic、DeepSeek の current docs はいずれも 2026年4月4日 に再確認しました。その時点で、DeepSeek V4 の public API model page または public pricing row は current docs では確認できず、公開行は DeepSeek-V3.2 を指していました。
まず「何を比較しているのか」を正しく定義する
ここでいちばん大きい修正は、思想ではなく compare object の修正です。GPT-5.4 と Claude Opus 4.6 は current public contract として直接比較できます。両者とも model identity、pricing、context、capability surface が vendor 自身の current page にあります。DeepSeek はそこが非対称です。current public API docs に見えるのは DeepSeek-V3.2、128K context、thinking mode における tool use、そして $0.28 / $0.42 という current pricing です。これは十分に real で useful な contract ですが、「確認済みの public DeepSeek V4 row」と同じ意味ではありません。
だから、この query に対するよくある "誰が何カテゴリー勝ちか" という構図は粗すぎます。クリーンな比較は、三つの行が同じだけ public で、同じだけ documented で、同じだけ current であることを暗黙に前提にしています。今回はそれが成り立ちません。OpenAI 側では gpt-5.4 が current public route であり、より上位の tier には gpt-5.4-pro もあります。Anthropic 側では claude-opus-4-6 が current public flagship で、current docs は 1M context と 128k max output を明示しています。DeepSeek 側で安全に言えるのは、public docs 上の V3.2-backed API contract です。比較が無意味なのではありません。正直に言える比較の範囲が違う だけです。
実務的な意味ははっきりしています。誰かが「DeepSeek V4 は Claude Opus 4.6 より何十倍も安い」とか「DeepSeek V4 は GPT-5.4 の真正面の相手だ」と言ったら、最初の返答は "その public contract は current docs のどこで確認したのか" であるべきです。これは細かい言い方の問題ではなく、evaluation と procurement の質を守るための境界です。

| ルート | 2026年4月4日に確認できた current public contract | 価格 | コンテキスト | 今 vendor が明確に書いていること | 勝手に前提化しないこと |
|---|---|---|---|---|---|
| GPT-5.4 | OpenAI API model gpt-5.4 | $2.50 input / $15 output | 標準 272K、Codex では experimental 1M | pricing、API availability、benchmark row、Codex support | 標準 272K contract をそのまま「どこでも 1M」と平坦化しない |
| Claude Opus 4.6 | Anthropic API model claude-opus-4-6 | $5 input / $25 output | 1M context、128k max output | flagship としての agents / coding 位置付け、launch status、output window | 古い third-party page の 192K / 200K などを current fact として持ち込まない |
| 現在の DeepSeek API | deepseek-chat と deepseek-reasoner は DeepSeek-V3.2 を指す | $0.28 input / $0.42 output | 128K | 低価格、V3.2-backed public API、thinking mode での tool use | 未確認の DeepSeek V4 pricing row を既成事実にしない |
この table が正しい first screen です。これを見た時点で、記事全体は「三者で誰が勝つか」ではなく「どの stage を誰に 맡せるべきか」という routing の話になります。
GPT-5.4 を先に回すべき場面
GPT-5.4 を先に試す価値が高いのは、OpenAI の現行契約がいちばん明確であること自体 が利点になる場合です。単に price がどうかではなく、current OpenAI stack の上で評価を進めたい、officially documented な computer use / tool use を持つモデルを入り口にしたい、Codex との距離を短く保ちたい。そういう条件なら GPT-5.4 の役割はかなりはっきりしています。OpenAI の launch page はこの点で使いやすく、current pricing、API での availability、standard 272K context と Codex 内の experimental 1M support の違い、さらに Terminal-Bench 2.0、OSWorld-Verified、BrowseComp といった benchmark row を直接見せています。
この distinction が大事なのは、比較記事がいちばん雑になりやすいのが context claim だからです。設計判断で必要なのは「GPT-5.4 は 1M context だ」と雑にまとめることではなく、「標準 contract は 272K で、Codex では experimental 1M support も documented されている」と分けて理解することです。そこを分けると GPT-5.4 の役割は自然に見えてきます。つまり、current OpenAI surface に乗りながら tool use と computer use の documented upside を取りにいく middle route です。
benchmark の扱いも同じです。GPT-5.4 の current page は public case を補強してくれますが、それは "Opus 4.6 に万能勝利している" という意味ではありません。意味するのは、real environment、tool、terminal work を含む評価において、OpenAI 側でいま最も current で clear な contract を持つ first test 候補だということです。もし次に知りたいのが model theory ではなく、OpenAI の current product surface そのものなら、続けて読むべきなのは OpenAI Codex 2026年3月アップデート です。
ただし注意点も同じくらい重要です。GPT-5.4 は cheapest route ではありませんし、current official material は「どんな coding task でも Opus 4.6 より上」と書けるほど単純な証拠にはなっていません。GPT-5.4 の strongest case は、明確な official OpenAI contract が必要であること自体が勝ち筋になるとき です。
Claude Opus 4.6 が premium を正当化する場面
Claude Opus 4.6 を先に置くべきなのは、「一番賢そうだから」ではなく、弱い first pass の代償が高すぎる仕事 のときです。これが Opus 4.6 を理解するうえで一番安定した framing です。Anthropic 側は大げさな benchmark theater をしなくても十分で、current contract だけでかなりのことが言えます。1M context、128k max output、そして agents / coding における current top model という位置付け。これは、長い horizon と大きな working set が job の中心にあるときに初めて効いてくる強みです。
なぜここで token price だけを見てはいけないのか。理由は simple です。repo-scale の coding、長い execution chain、大きい output、review で救済したくない first draft。こうした workload では invoice よりも bad first pass の後始末 が本当の bill になります。Claude Opus 4.6 の premium は、その cleanup cost が price difference を上回るときに最も説明しやすい。
1M context と 128k output も、数字そのものが偉いのではなく、仕事の組み方を変えるから価値があります。問題を早すぎる段階で圧縮したり、context を過剰に分割したり、狭すぎる slice で reasoning させたりする必要が減るからです。もしここで Anthropic 側の pricing をもう少し詳しく見たいなら、次に読むのは Claude Opus 4.6 pricing guide が適切です。日本語版がまだないので、ここは英語記事へのフォールバックが一番安全です。
もちろん制約もあります。Claude Opus 4.6 は、price sensitivity が最優先の workload や、OpenAI の current official contract を基盤にしたい場面では default answer になりません。だからこそ、この比較は "誰が王者か" ではなく、"どの failure profile を先に潰したいか" で読むべきです。
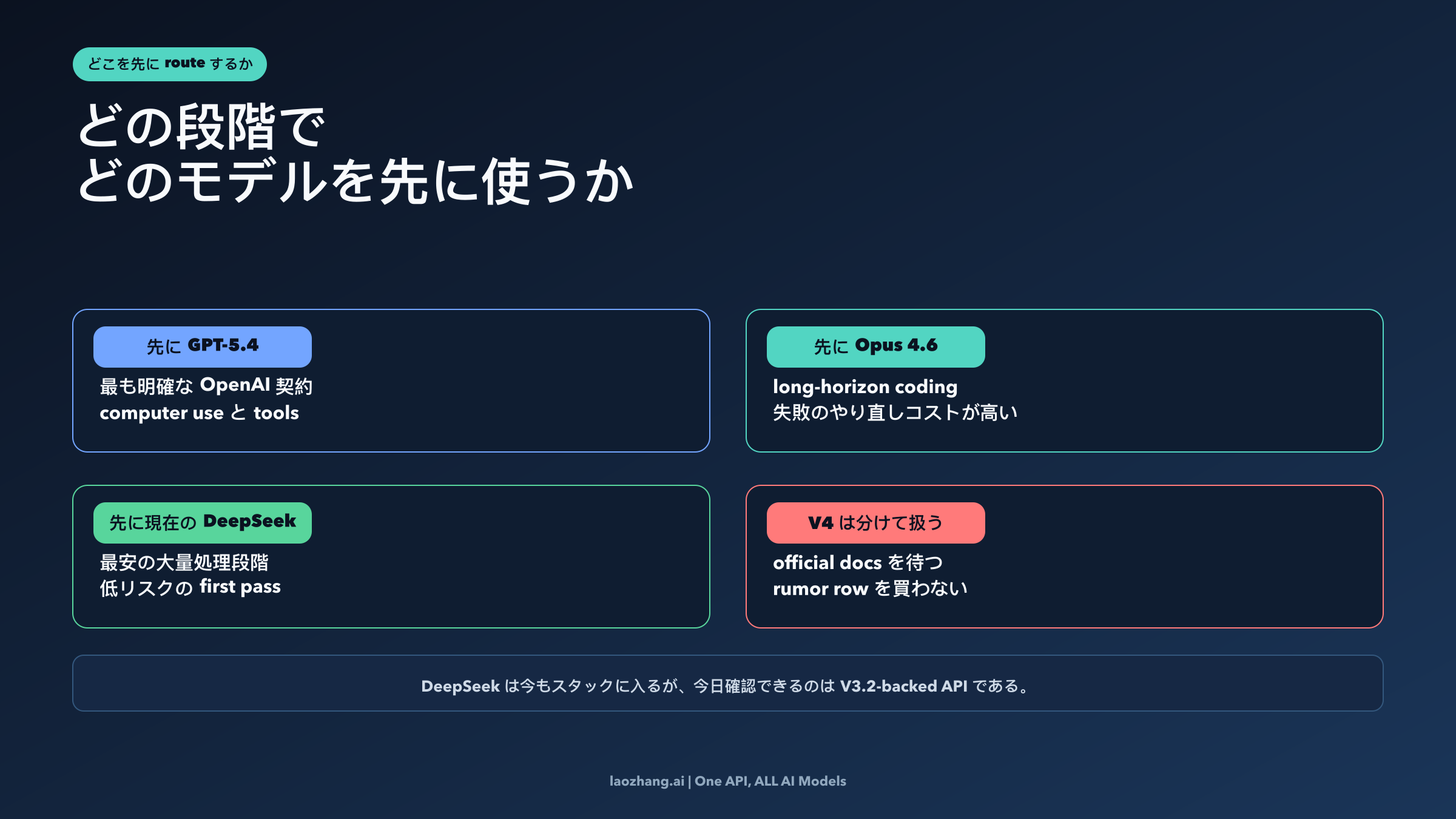
なぜ current DeepSeek をまだ stack から外すべきではないのか
ここでよくある過修正は、V4 の public proof が曖昧だと分かった瞬間に DeepSeek 全体を比較から外してしまうことです。正しい修正はもっと狭いです。DeepSeek を、今日 docs で確認できる contract のまま stack に置くこと。 そして今日その役割を持つのは V3.2-backed public API です。
それでも DeepSeek の位置は十分に強いです。$0.28 input / $0.42 output という current pricing は GPT-5.4 や Claude Opus 4.6 に比べて大きな差があります。しかもこれは空想上の price advantage ではなく、actual public API contract の数字です。加えて docs では 128K context と thinking mode での tool use も確認できます。これだけあれば、low-risk で cost-sensitive な stage、たとえば大量の要約、bulk classification、初期 draft、もしくは「まず安く処理量を回したい」系の仕事では十分に採用理由になります。
ただし、これらの facts は「DeepSeek V4 はすでに GPT-5.4 や Opus 4.6 と同格の public proof を持つ frontier peer だ」と書く根拠にはなりません。そこを越える comparison page が多すぎるのです。もし本当の問いが「今日 DeepSeek を stack に入れてよいか」なら答えは yes です。もし本当の問いが「確認済みの public V4 row を今日そのまま横に並べてよいか」なら、2026年4月4日 時点の安全な答えはまだ no です。
これは anti-DeepSeek ではありません。意思決定の品質を守るための correction です。モデルは、より強い public contract を fiction で足さなくても、今のままで十分 useful でありえます。
多くのチームが実際に試すべき三段 routing stack
fake universal winner を探すのをやめると、むしろ system design はかなりシンプルになります。
Stage 1: current DeepSeek を cheapest public first pass に使う。 価格が大きな制約で、量が多く、失敗コストが低い stage なら current DeepSeek API はまだ強いです。ここでの goal は frontier crown ではなく token discipline です。
Stage 2: GPT-5.4 を current official middle route に置く。 tool use、computer use、OpenAI の current platform continuity が必要になった時点で GPT-5.4 に上げる。この middle route は、多くのチームにとって一番説明しやすく、一番 current docs と整合します。次に必要なのが access planning なら、うちの GPT-5.4 アクセスガイド が次の読み物になります。
Stage 3: Claude Opus 4.6 を expensive-failure tier に使う。 bad first pass のコストが token bill より高くなる 순간に Opus 4.6 を使う。repo-scale coding、長い execution、review で救いたくない大きな output。そこでは premium の説明が一番しやすくなります。

これは複雑さのための複雑さではありません。public evidence が非対称で、pricing も十分に離れている以上、自然にこうなります。チームによっては二段に縮みます。price をほぼ気にしないなら current DeepSeek を飛ばして GPT-5.4 と Opus 4.6 だけを見るでしょう。長い high-stakes coding に上がらないなら Opus 4.6 まで上げる必要はありません。大事なのは考え方で、同じ種類の公開証拠を持っていない三行から一人の winner を選ぶ という悪い問いをやめることです。
本当の関心が model contract ではなく toolchain なら
この query を打つ人の一部は、実は model contract ではなく workflow を知りたいはずです。つまり、「どのモデルが strongest か」より「どの toolchain で仕事を回すべきか」です。それは別の意思決定レイヤーです。OpenAI の current product side を整理したいなら OpenAI Codex 2026年3月アップデート へ。live steering と async delegation の違いを知りたいなら Claude Code vs Codex 2026 へ進むほうが正確です。このページは intentionally model contract layer に留まり、話を広げすぎないようにしています。
FAQ
DeepSeek V4 はもう公式に公開済みですか
2026年4月4日 時点では、current public API docs の中で DeepSeek V4 の独立した public model page や pricing row は確認できませんでした。公開されている行は依然として DeepSeek-V3.2 を指していました。
開発者はどのモデルを先に試すべきですか
最も明確な OpenAI の現行契約と documented tool / computer use を重視するなら GPT-5.4 です。long-horizon coding と expensive cleanup が支配的なら Claude Opus 4.6 です。価格下限を優先するなら current DeepSeek API を先に試す価値があります。
GPT-5.4 は 1M context model だと言ってよいですか
慎重な書き方はこうです。OpenAI の current material は 標準 272K context と、Codex 内での experimental 1M support を別々に説明しています。関連はありますが同じ operating contract ではないので、一つの generic claim に flatten しないほうが安全です。
V4 が未確認でも current DeepSeek を使う意味はありますか
あります。修正すべきなのは「DeepSeek を外すこと」ではなく、「今 public に出ている contract で使うこと」です。cost-sensitive で low-risk な stage では、current DeepSeek API は依然として十分に強い選択肢です。
DeepSeek を GPT-5.4 や Opus 4.6 と比較する意味はまだありますか
あります。ただし current public DeepSeek と 想定上の public DeepSeek V4 を分けて考えたあとに限ります。そうすると比較は、fake scoreboard ではなく、cost・proof quality・failure cost の staged routing decision として再び useful になります。
Bottom line
最短で正直な答えはこれです。今日の clean frontier contract としては GPT-5.4 と Claude Opus 4.6 を直接比べ、DeepSeek は current V3.2-backed public API の位置で判断する。未確認の V4 row を先に事実化しない。 最も明確な OpenAI contract が必要なら GPT-5.4 から。long-horizon coding と costly cleanup が支配的なら Claude Opus 4.6 から。cost floor が主問題なら current DeepSeek から。問いをそう置き直すだけで、この比較はかなり実用的になります。