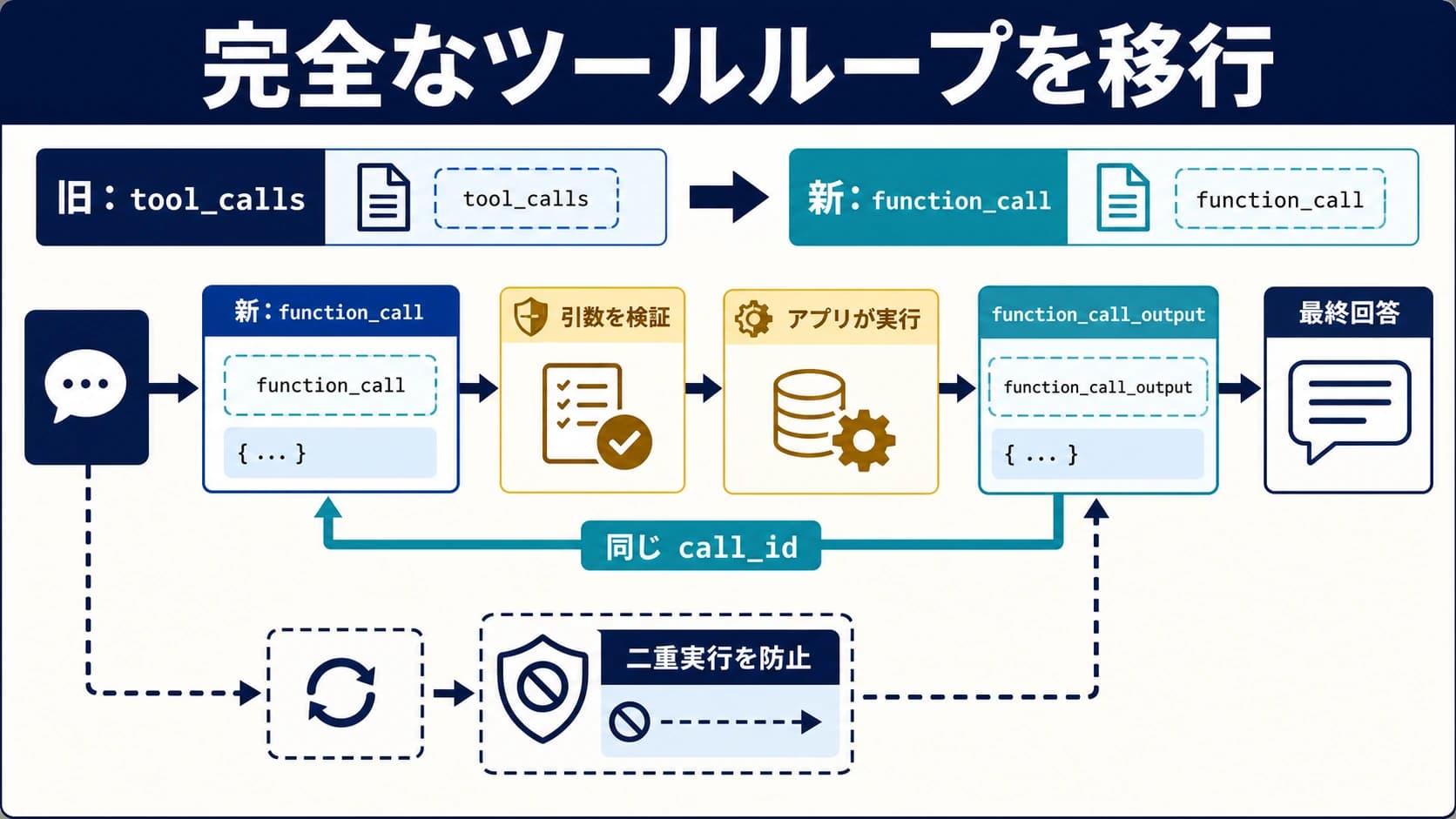
Claude Fable 5 と GLM-5.2 は、いま同じ条件で走らせられる二択ではありません。2026年6月14日に確認した公式情報では、Anthropic は Fable/Mythos のアクセスを停止したと説明しています。つまり Fable 5 は待って再確認する枝です。一方で Z.AI は GLM Coding Plan の中で GLM-5.2 を記載しているため、GLM-5.2 は小さな Coding Agent タスクで先に検証できる枝です。
ただし、GLM-5.2 がそのまま Fable の代替になるわけではありません。可用性はテスト順を決めるだけで、品質や既定モデルを決めません。判断には同じ repo、同じ issue、同じ prompt、同じ tool 権限、同じ acceptance test、そして diff、tests、logs、latency、quota、retry、rollback cost が必要です。
| ルート | 使う場面 | 最初の行動 | ストップルール |
|---|---|---|---|
| Fable 5 を待つ | Anthropic 固有の挙動、課金、policy、fallback を評価したい。 | Anthropic の access statement、model docs、pricing docs を再確認する。 | 実行できない Fable に live task の点数を付けない。 |
| GLM-5.2 を小さく試す | 今週走らせられる Coding Agent ルートが必要。 | Z.AI の documented route を設定し、小さなタスクを実行する。 | diff、tests、logs、latency、quota、rollback が見えないなら代替と言わない。 |
| 後で二重実行する | チームの既定モデルや production route を変えたい。 | 同じ task packet を保存し、Fable が戻ったら同じ条件で走らせる。 | 両方が runnable で同じタスクを通るまで勝者を決めない。 |
証拠メモ: Anthropic の Fable 発表、アクセス、モデル、価格ページと、Z.AI GLM Coding Plan のドキュメントは 2026年6月14日に確認しました。可用性、quota、pricing、routing は変わりやすいため、新しい推奨や既定ルート変更の前に公式情報を再確認してください。
まず可用性で分ける
実務上の答えは、モデル名の強さではなくルートです。Fable 5 は、アクセス停止中に live Coding Agent 評価を始める枝ではありません。大きな context、output ceiling、model ID、pricing row は重要ですが、今走らせられない仕様だけでは同じタスクの結果になりません。
GLM-5.2 は、今すぐ検証したい場合の最初の枝です。Z.AI の latest model と tool integration の文脈では、GLM Coding Plan で GLM-5.2 を扱うルートが見えます。この情報は smoke test の理由になります。ただし、Fable、Opus、Kimi、あるいは現在の既定ルートより優れている証明ではありません。
大事なのは「先に試す」と「勝った」を分けることです。GLM-5.2 は最初に走らせられるかもしれませんが、既定モデルにするには同じタスクの証拠が必要です。
日本語圏で起きやすい誤読
日本語圏の解説では、AI による概要や note、動画が、Fable の自律タスク性能や GLM-5.2 のコストパフォーマンスを並べて見せます。これは比較の入り口としては便利ですが、可用性の停止を弱く扱うと、読者は「どちらが強いか」を先に考えてしまいます。
実務では順序を逆にします。最初に確認するのは、どちらが今走るかです。次に、そのルートがどの公式ドキュメントに支えられているかを見ます。最後に、同じタスクで patch、tests、logs、latency、quota、rollback を測ります。
ローカルの読者に必要なのは、翻訳された強弱表ではありません。必要なのは、今の開発フローで安全に試せる枝と、試してはいけない結論の境界です。
今週変わったのはモデル能力だけではない
Anthropic は 2026年6月9日に Claude Fable 5 を発表しました。その後、別の Fable/Mythos access statement で、Fable 5 と Mythos 5 のアクセスを全顧客に対して停止する必要があると説明しました。この情報により、通常の「Fable vs GLM」表はそのままでは不十分になります。
Z.AI 側は別の証拠です。GLM-5.2 は、ここでは万能 API の単独発表としてではなく、GLM Coding Plan の documented route として扱います。docs が示す route はテスト開始の根拠になりますが、すべての wrapper、比較表、SNS 投稿が同じ事実を持つわけではありません。

安全な順序は、Fable の状態を再確認し、GLM-5.2 の route を確認し、その後で同じタスクを測ることです。Fable が走らないなら点数を付けない。GLM-5.2 が走るなら、まず小さな証拠を保存する。この二つを混ぜないことが重要です。
公式契約で見る比較表
| 確認点 | Claude Fable 5 | GLM-5.2 |
|---|---|---|
| 先に見る公式元 | Anthropic | Z.AI |
| 2026-06-14 の状態 | Fable/Mythos access statement では不可用。 | GLM Coding Plan に記載。 |
| 見るべきラベル | claude-fable-5 | glm-5.2 と glm-5.2[1m] |
| context と output | Anthropic docs は 1M context と 128k output を示すが、停止中は実行証拠にならない。 | Z.AI の coding route は 1M context class を示す。 |
| cost unit | Anthropic の per-million-token price row。 | Coding Plan の quota と multiplier。 |
| Coding Agent での意味 | 仕様は強いが、今は wait-and-recheck。 | route が見えるなら bounded smoke test 候補。 |
| 証明しないこと | 今日 Fable を走らせられること。 | GLM-5.2 が上位または代替であること。 |
この表はランキングではなく、責任の分離です。Fable のアクセス、model ID、pricing は Anthropic が持つ事実です。GLM-5.2 の Coding Plan route は Z.AI が持つ事実です。あなたの repo の patch、tests、review、rollback はあなたの環境が持つ事実です。
Claude Code を使う場合は、route 設定も分けて考えます。provider path や base URL はモデル品質ではなく設定の問題です。関連する設定は Claude Code API configuration、credential と billing の分離は Claude Code API key vs subscription billing を参照してください。
コストは同じ単位にしてから比べる
Fable と GLM-5.2 は、見えているコスト単位が違います。Fable には token price row があります。GLM-5.2 はこの証拠セットでは Coding Plan の quota と multiplier の文脈です。単純に価格セルを並べても、実務のコストは出ません。
Coding Agent のコストには、tokens だけでなく tool calls、long context、retry、review、CI、rollback が含まれます。安く見える失敗は、何度も人が直すなら安くありません。高く見える一回の成功が、実は安いこともあります。
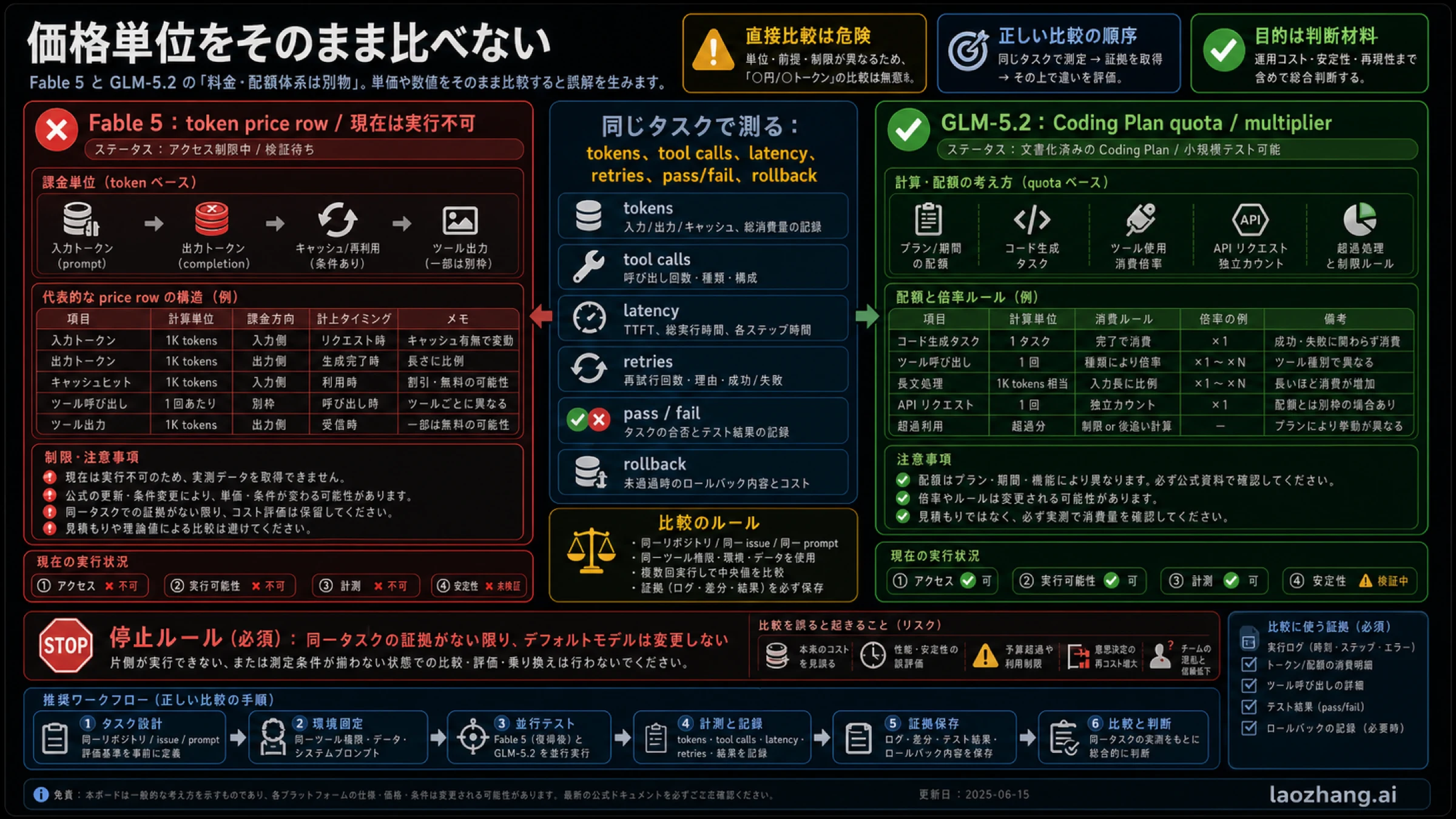
| 測る項目 | 必要な理由 |
|---|---|
| input tokens | repo 全体の文脈が cost や quota を増やす。 |
| output tokens | patch 説明や logs が出力側の負担になる。 |
| tool calls | agent route は tool の使い方で制限や quota が変わる。 |
| latency | 安いが review を止める route は実務では負ける。 |
| pass/fail | 失敗した安い試行は人間の修復コストを生む。 |
| retries | quota、時間、信頼を同時に消費する。 |
| rollback | 悪い patch の本当のコストは請求書に出ない。 |
この表を埋められないなら、まだ比較できないと言うべきです。曖昧な価格勝者より、単位が違うと明示するほうが読者に役立ちます。
GLM-5.2 を先に試す場面
GLM-5.2 を先に試す価値があるのは、実行できる route を今週検証したいときです。再現できる bug、明確な test failure、小さな migration、docs patch、範囲の狭い refactor などが向いています。失敗しても revert しやすいことが条件です。
逆に、Anthropic 固有の policy、billing、fallback、Claude-native route を評価したいなら、Fable が戻るまで待つ必要があります。security、compliance、data migration、深いドメイン判断を含むタスクを、最初の GLM smoke test にするのも避けるべきです。
良いテストは狭いです。architecture、tests、deployment、docs を同時に変えさせないでください。一回の実行で見るのは、issue を理解し、review できる diff を出し、指定 test を通し、失敗時に理由を残せるかです。
既定モデルはまだ替えない
既定モデル変更は production decision です。Fable が停止していることはテスト順を変えますが、GLM-5.2 を既定にする理由にはなりません。GLM-5.2 が一つのタスクを通しても、それはその route とそのタスクでの結果です。
変更前には、同じ task packet、同じ acceptance bar、同じ evidence packet、同じ rollback plan、同じ decision threshold を要求してください。どの結果なら戻すのかを実行前に決められないなら、既定モデルはまだ替えるべきではありません。
| 要件 | 合格条件 |
|---|---|
| 同じ task packet | repo、issue、prompt、files、tools、time budget が同じ。 |
| 同じ acceptance bar | tests、review checklist、failure budget が同じ。 |
| 同じ evidence packet | logs、diff、test output、latency、quota、failure reason を保存。 |
| 同じ rollback plan | revert、isolate、rerun の方法がある。 |
| 同じ threshold | good enough と rollback 条件を先に決める。 |
Fable が戻った場合は、保存した packet を再実行します。新しい GLM タスクを古い Fable 印象と比べないでください。Fable の仕様と GLM の実行ログを比べるのも避けます。
同じタスクの評価チェック
最もきれいな検証は小さいタスクです。一つの repo、一つの issue、一つの acceptance test を選びます。現実的だが review できる大きさであることが重要です。
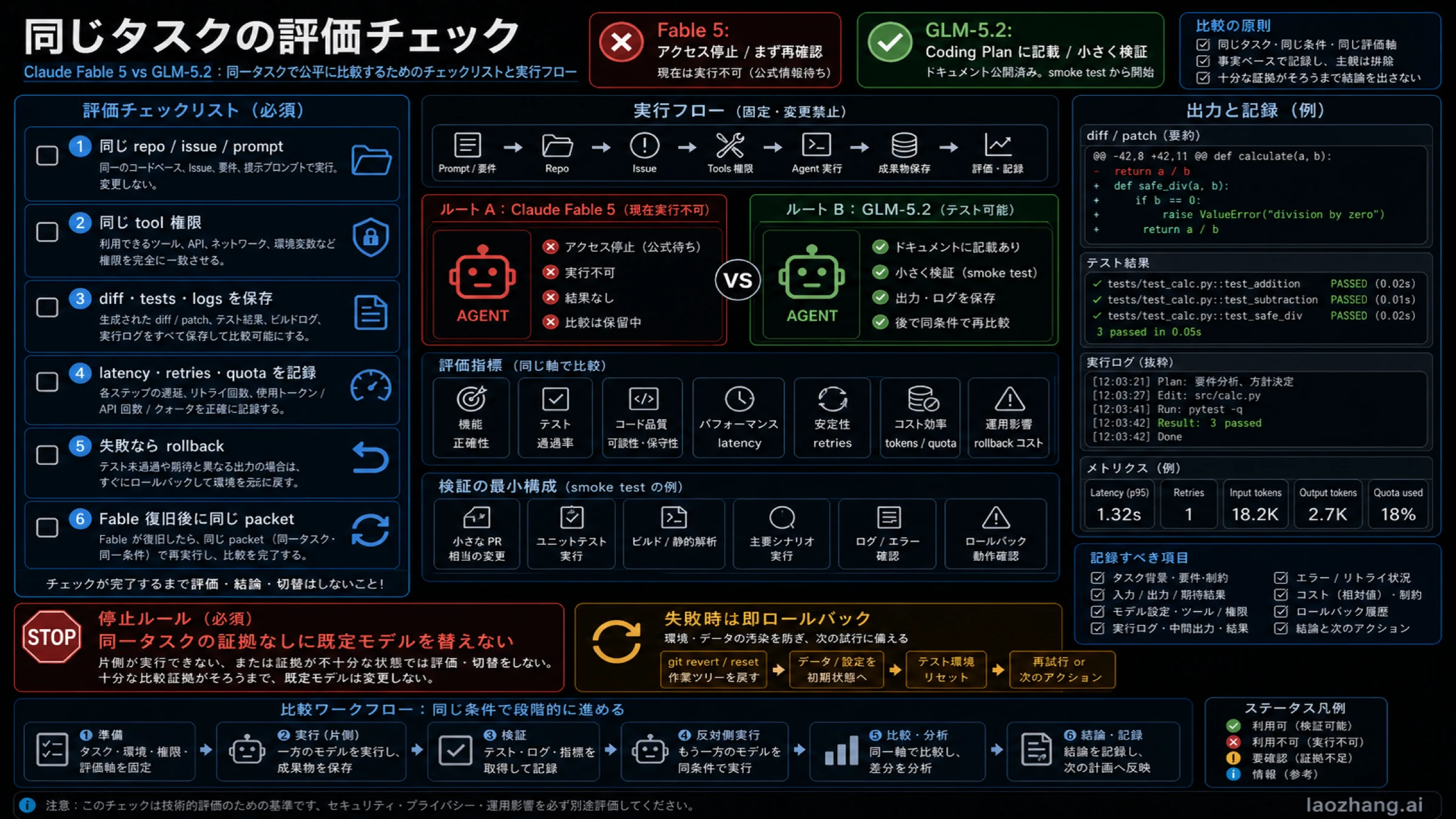
- prompt、branch、files、allowed tools、time budget を固定する。
- Z.AI の documented route で GLM-5.2 を走らせる。
- model label、provider route、diff、logs、tests、latency、quota、failure reason を保存する。
- patch quality、tests pass、retry count、review load、rollback effort だけで判断する。
- Fable が戻ったら、同じ packet を変更せずに実行する。
- 両方が runnable になってから、accepted-task cost と failure mode を比較する。
良い結論は「GLM-5.2 はこの bounded migration task を一回の retry で通し、quota も許容範囲だった」です。悪い結論は「Fable が停止中だから GLM-5.2 が勝った」です。
よくある質問
Claude Fable 5 は今使えますか?
2026年6月14日に確認した Anthropic access statement では、Fable 5 と Mythos 5 のアクセスは全顧客に対して停止されています。テスト前に現在の公式ページを再確認してください。
GLM-5.2 は Claude Fable 5 より良いですか?
Fable が runnable でない間は公平な live claim はできません。GLM-5.2 は先に試せる route ですが、良いかどうかは同じタスク、同じ入力、同じ結果で測る必要があります。
どの model string を見るべきですか?
Fable 側は claude-fable-5 と現在の access status を見ます。GLM 側は Z.AI Coding Plan の glm-5.2 と glm-5.2[1m] を見ます。
GLM-5.2 のほうが安いですか?
単純には言えません。Fable は token price row、GLM-5.2 は quota と multiplier の route です。同じタスクの tokens、tool calls、retries、latency、pass/fail、rollback を測ってから比較します。
GLM-5.2 を Fable の代替にできますか?
現在試せる route として使うことはできます。自動的な代替にはしないでください。Fable が戻ったら同じ packet を走らせ、quality と risk の基準を超えた場合だけ既定変更を検討します。
まとめ
この比較で大切なのは、どちらの名前が強いかではありません。どちらの route を、いま嘘なく検証できるかです。2026年6月14日時点では、Fable 5 は公式 contract を持つが access suspended、GLM-5.2 は Z.AI Coding Plan に documented route があり、小さく検証できます。
まず Fable を再確認し、GLM route を検証し、コスト単位をそろえ、同じタスクを保存してください。同じタスクの証拠がない限り、既定モデルを替えないことが一番安全です。