
Un 401 de OpenClaw suele pertenecer a una de tres ramas distintas: invalid bearer token, missing authentication header o falta de credenciales en el agente que falla. Lo más importante no es cambiar keys cuanto antes, sino devolver el error a la rama correcta antes de tocar nada.
Esa separación te permite reparar solo la parte rota. Además te ayuda a decidir, una vez recuperado el servicio, qué método de autenticación merece quedarse en ese host. En un gateway host de larga vida, normalmente conviene la ruta más predecible, no la más cómoda.
Tablero de triage en 30 segundos
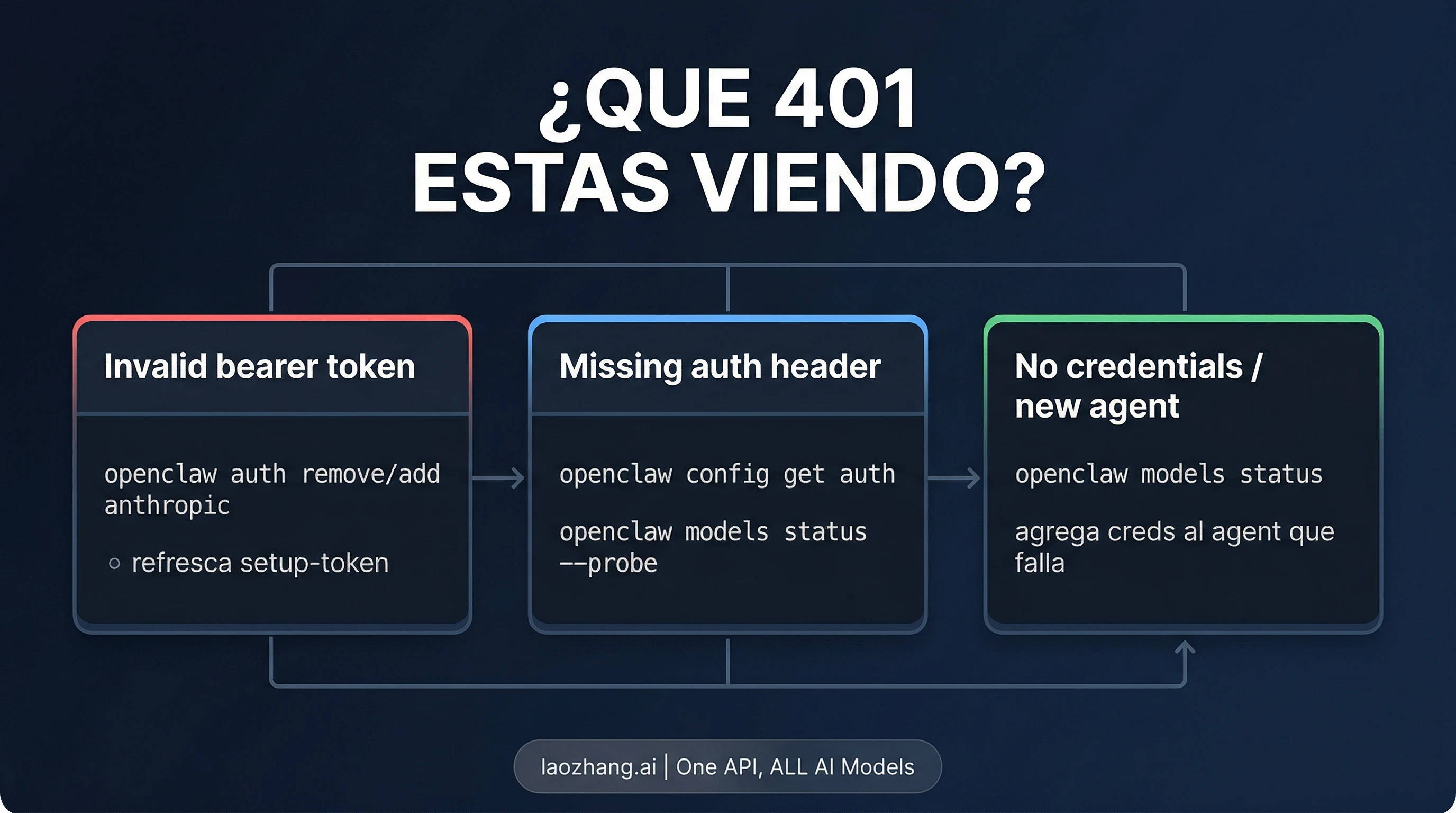
Antes de mover credenciales, separa el error por ramas:
| Si el log dice | Lo que probablemente falla | Primer movimiento más seguro | Qué validar en ese mismo camino | Cuándo ampliar la investigación |
|---|---|---|---|---|
invalid bearer token | Una ruta auth basada en token quedó inválida, fue sobrescrita o es frágil en el build actual | Reautenticar esa ruta exacta | Repetir con el mismo agente y el mismo host para ver si desaparece esa rama | Tras una reauth limpia sigue apareciendo la misma rama |
missing authentication header | Request routing, provider config o una capa que ni siquiera está enviando auth usable | Averiguar qué capa arma la request saliente | Confirmar si el nuevo intento ya sale con auth header | Incluso con credenciales correctas sigue faltando el header |
Un agente funciona, pero otro devuelve 401 o no credentials | El propio agente que falla | Añadir o refrescar credenciales en ese agente | Reprobar solo ese agente | El agente sigue sin tener un profile utilizable |
Esta división no es teórica. La documentación actual de OpenClaw sigue describiendo varias rutas Anthropic, entre ellas API key, Claude CLI reuse y setup-token reuse. A la vez, las provider docs actuales muestran que el auth state es específico por agente. Los issues públicos también separan ramas distintas: issue #23538 documenta invalid bearer token en OpenClaw 2026.2.21-2, mientras que issue #34830 registra otra regresión con 401 missing authentication header.
Por eso la primera pregunta correcta no es “¿qué key cambio?”, sino “¿en qué rama estoy?”. Si te saltas esa pregunta, es fácil romper una ruta que sí funcionaba mientras intentas arreglar otra.
Cuando aparece invalid bearer token
Invalid bearer token suele significar que la request sí salió con una credential, pero el upstream no pudo usarla. En la guía pública actual de OpenClaw, esto suele importar más en rutas como Claude login reuse, Claude CLI reuse o setup-token reuse que en un Anthropic API key directo.
Eso cambia el orden correcto. En esta rama, lo primero es reautenticar, no rehacer toda la configuración. Las Anthropic provider docs de OpenClaw siguen tratando 401 errors / token suddenly invalid como una rama operativa real. Claude Help añade el detalle importante: ANTHROPIC_API_KEY puede sobrescribir la auth de suscripción en Claude Code. En otras palabras, una máquina puede parecer “logueada” y aun así enviar tráfico por otra ruta distinta de la que crees activa.
Tener un token guardado no demuestra que la auth runtime esté sana. Issue #23538 muestra precisamente eso: setup-token fue aceptado y guardado, pero las requests hacia Anthropic siguieron cayendo con HTTP 401 authentication_error: Invalid bearer token. Eso no significa que setup-token esté roto siempre. Significa que “se guardó bien” no basta para tratar esa ruta como fiable en un host de larga vida.
La secuencia segura aquí es:
- Repetir el flow de token o setup-token que ese host debería usar ahora.
- Limpiar stale sessions o revoked tokens que puedan seguir ganando prioridad. Claude explica dónde revocar sesiones activas.
- Verificar si
ANTHROPIC_API_KEYestá activando otra ruta distinta. - Reprobar en el mismo agente y el mismo host, no en otra máquina que casualmente sí funciona.
Si la misma rama sigue fallando tras una reauth limpia, deja de tratarlo como una simple rotación de credenciales. A partir de ahí, la pregunta útil es qué método merece quedarse en ese entorno. En hosts de larga vida, una API key directa suele ser más estable que una ruta frágil de token reuse. Si necesitas profundizar en la rama Anthropic, puedes seguir con la guía en inglés de OpenClaw Anthropic API key errors.
Cuando aparece missing authentication header
Missing authentication header también es un 401, pero no cuenta la misma historia. Aquí el problema suele ser que la request salió sin auth usable. No es “la credential se envió y fue rechazada”, sino “la auth nunca llegó a la request”.
Issue #34830 importa justo por eso: expone 401 missing authentication header como una rama distinta. Si el log ya habla de un header ausente, lo primero es localizar qué capa arma la request saliente y si esa capa tenía realmente credenciales que pudiera enviar.
La secuencia mínima basta:
- Identificar qué provider path o qué agente generó la request que falló.
- Revisar el config, el env y el profile activos de esa ruta.
- Repetir con una credential conocida como buena y comprobar si ahora sí sale el auth header.
Si incluso con una credential buena la request sigue saliendo sin header, ya no estás ante un simple problema de secrets. A partir de ahí toca investigar routing, wiring o comportamiento del build. Seguir rotando tokens suele empeorar el diagnóstico.
Cuando el agente principal funciona y otro no tiene credenciales
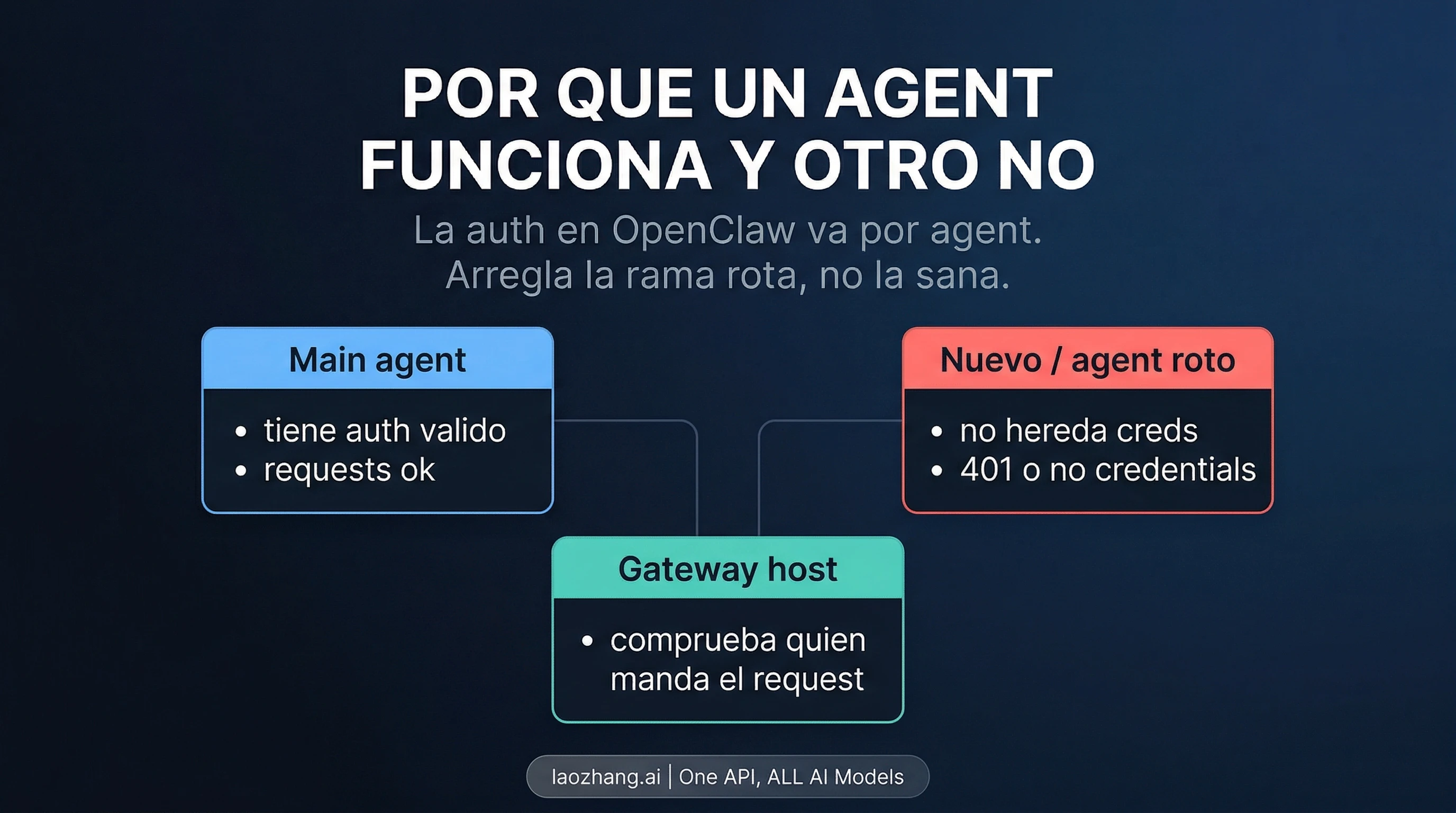
Esta tercera rama también es independiente. Los docs y la estructura CLI actuales colocan los auth profiles en rutas por agente, como ~/.openclaw/agents/<agentId>/agent/auth-profiles.json. Traducido a la práctica: cada agente necesita sus propias credenciales. Que el agente principal esté sano no demuestra que un agente nuevo haya heredado nada útil.
Por eso la reparación correcta no se hace sobre todo el host, sino sobre el agente que falla. Compara su auth state con el de un agente sano, añade o actualiza las credenciales allí y vuelve a probar solo ese agente. Rehacer el onboarding completo del host suele tocar precisamente la parte que no estaba rota.
Esta rama también deja ver el coste de una auth demasiado compleja. Mezclar local sign-in reuse, perfiles per-agent y environment overrides puede funcionar, pero vuelve mucho más difícil aislar qué rama se rompió. Para un gateway de larga vida, la ruta simple suele ser la más resistente.
Qué método de autenticación conviene dejar en este host

Después de recuperar el servicio, la pregunta útil ya no es “¿qué ruta funcionó una vez?”, sino “¿qué método tiene menos probabilidades de volver a caer en este host?”.
La guidance actual de OpenClaw es bastante clara aquí. Gateway authentication docs apuntan a API key como la opción más predecible para un always-on gateway host. Anthropic provider docs siguen permitiendo Claude CLI reuse y setup-token reuse, pero OpenClaw FAQ pone mejor los límites: el Claude login reuse local puede estar soportado, pero no es el default recomendado para producción. El FAQ también recoge un aviso de Anthropic fechado el 4 de abril de 2026: la ruta Claude login en OpenClaw requiere Extra Usage billing aparte de la suscripción.
La regla práctica queda así:
| Entorno | Default más razonable para dejar | Por qué |
|---|---|---|
| Always-on server o shared gateway host | API key directa | Menos estado oculto, menos dependencia de sesiones locales y mejor trazabilidad a largo plazo |
| Máquina personal bajo tu control | Claude CLI o auth enlazada a suscripción pueden ser aceptables | La comodidad puede pesar más cuando máquina y sesión son locales |
| Setup-token reuse | Soportado, pero version-sensitive | Los docs lo mantienen, pero la evidencia pública no permite venderlo como default universal más seguro |
La idea no es declarar un ganador eterno, sino emparejar el método con el host real. Si el host debe sobrevivir reinicios y servir un gateway estable, gana la predictibilidad. Si es una máquina personal, la comodidad puede importar más.
Una comprobación corta después del fix

Muchos 401 repetidos no aparecen porque el primer diagnóstico fuera totalmente incorrecto, sino porque nadie validó la misma ruta una vez arreglada. Una rutina corta suele bastar:
- Reprobar el mismo agente que falló.
- Confirmar que sigue activo el método de autenticación que querías dejar.
- Limpiar stale token paths y sesiones viejas que ya no deberían ganar prioridad.
- Si cambiaste de método, anotar el nuevo default del host.
También conviene no mezclar cooldown con fallo de credenciales. Las provider docs actuales de Anthropic dicen que No available auth profile (all in cooldown/unavailable) debe revisarse con openclaw models status --json. Un cooldown no es lo mismo que invalid bearer token ni que missing authentication header.
El criterio de escalado puede ser simple:
- Si
invalid bearer tokendesaparece con reauth, cierras esa rama y decides aparte si conviene conservar la misma ruta. - Si
missing authentication headerpersiste, sigues investigando routing y build behavior. - Si falla solo un agente, arreglas primero ese agente.
- Si el problema ya parece más amplio que esta familia 401, saltas a la guía general en inglés de OpenClaw troubleshooting o a la installation and deployment guide.
FAQ
¿Todo 401 en OpenClaw significa que mi API key está mal?
No. La evidencia pública actual obliga a separar al menos tres clases: invalid bearer token, missing authentication header y la falta de credentials en un agente concreto.
¿Setup-token sigue soportado?
Sí. Los docs actuales de OpenClaw siguen describiendo setup-token como una ruta soportada. Pero a 7 de abril de 2026, issue #23538 sigue mostrando invalid bearer token en OpenClaw 2026.2.21-2, así que la forma correcta de describirlo es “soportado, pero sensible a la versión”.
¿Por qué funciona un agente y otro no?
Porque los docs actuales gestionan el auth state por agente. Que el principal esté sano no demuestra que el nuevo haya heredado las mismas credenciales.
¿Qué ruta es más segura para un servidor de larga vida?
En long-lived hosts, la guidance actual apunta a la ruta más predecible. En la práctica, una API key directa suele ser la opción más estable.
Regla de trabajo
La forma más rápida de arreglar un 401 de OpenClaw es dejar de preguntar “¿qué credential cambio?” y empezar a preguntar “¿qué rama se rompió?”. Separa primero por el texto exacto del error, corrige solo esa rama, valida el mismo camino y solo después decide qué método de autenticación merece quedarse en ese host.