![Comparativa de Proxies API Nano Banana 2: Precio, Estabilidad y Coste Real [2026]](/posts/es/nano-banana-2-api-proxy-comparison/img/cover.png)
Elegir el proxy API adecuado para Nano Banana 2 puede ahorrarte entre un 50% y un 85% en comparacion con los precios oficiales de Google, pero elegir el equivocado puede inflar silenciosamente tus costes en un 75% a traves de comisiones ocultas que nunca esperabas. Con ocho proveedores principales ofreciendo ahora acceso a la generacion de imagenes Gemini 3.1 Flash Image, el panorama se ha vuelto lo suficientemente complejo como para que las comparaciones superficiales de precios resulten genuinamente enganosas. Esta guia corta a traves del ruido con datos verificados de marzo 2026, cubriendo el coste real de cada proveedor, la estabilidad en el mundo real y los gastos ocultos que la mayoria de articulos comparativos convenientemente ignoran.
Resumen rapido
Antes de profundizar en el analisis, aqui esta la matriz de decision esencial basada en el coste total de propiedad en lugar del precio anunciado. El proveedor adecuado depende enteramente de tu caso de uso, no de quien anuncia la tarifa mas baja por imagen.
| Tu Escenario | Proveedor Recomendado | Coste Mensual | Por que |
|---|---|---|---|
| Aficionado (<1K imagenes) | Google AI Studio Gratis | $0 | 1.500 imagenes gratuitas/mes |
| Startup (1K-10K) | laozhang.ai | $50-500 | Mejor TCO, sin necesidad de VPN |
| Empresa (10K+, SLA) | Google Vertex AI | $500+ | SLA 99,9%, SOC 2 |
| Alto volumen (50K+) | Hibrido Batch + Proxy | Variable | Combinar async + tiempo real |
La conclusion mas importante de este analisis es la siguiente: un proveedor que anuncia $0,020 por imagen puede terminar costando $0,035 por imagen una vez que factorizas las suscripciones VPN, las comisiones de pago, el sobrecoste por reintentos y la perdida de productividad por latencia. Mientras tanto, un proveedor que anuncia $0,050 ofrece un coste real de $0,0255 porque elimina todas las categorias de gastos ocultos. El precio superficial y el coste real son numeros fundamentalmente diferentes.
Todos los proveedores proxy NB2 comparados: Precios 2026 por resolucion
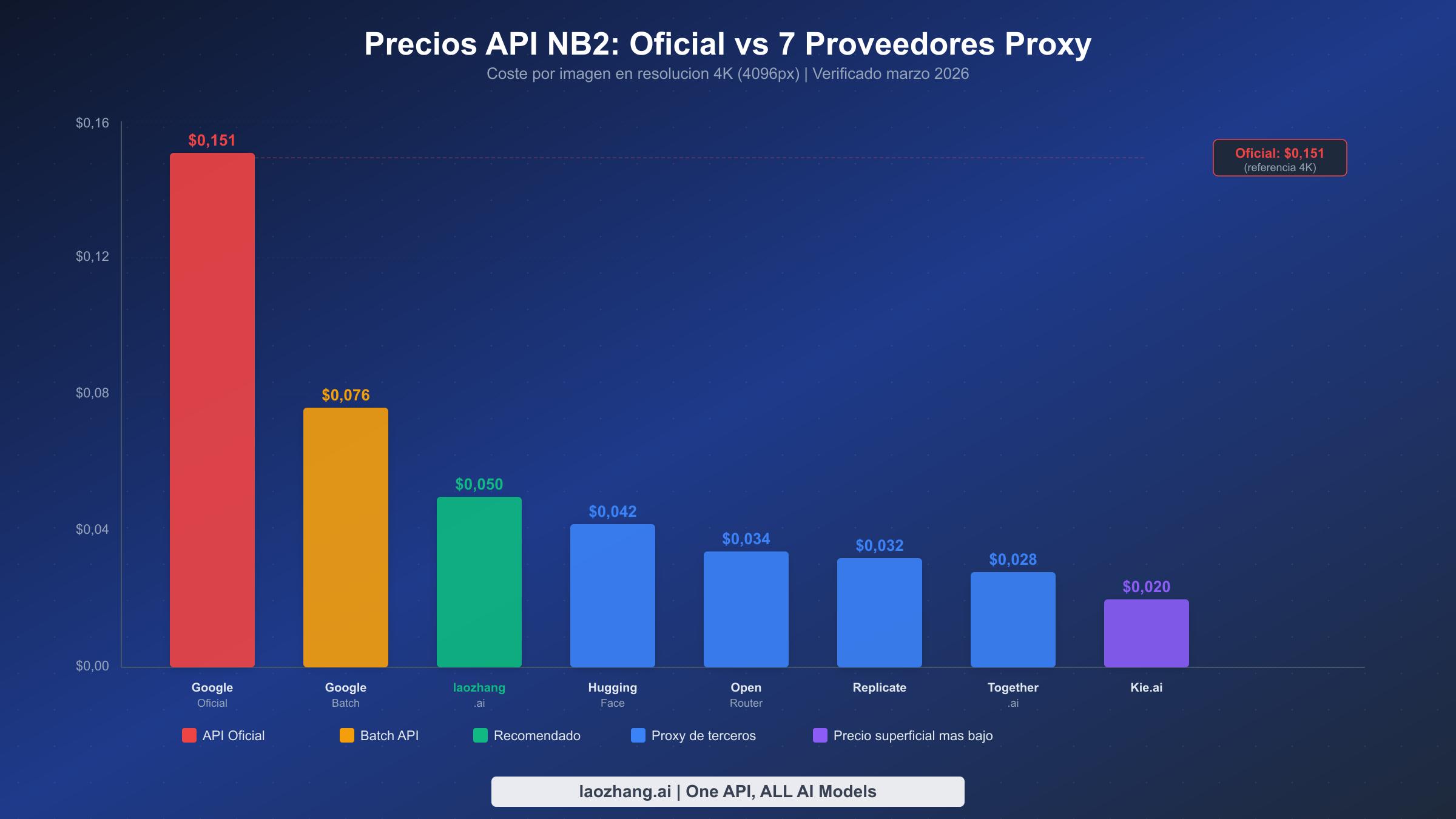
Comprender el panorama de los proxies NB2 comienza con un hecho critico que muchos articulos comparativos pasan por alto: Nano Banana 2 (Gemini 3.1 Flash Image, ID de modelo gemini-3.1-flash-image-preview) utiliza un modelo de precios basado en tokens donde los tokens de salida de imagen cuestan $60 por millon de tokens (ai.google.dev, marzo 2026). Dado que diferentes resoluciones generan diferentes cantidades de tokens (747 tokens para 0,5K, 1.120 para 1K, 1.680 para 2K y 2.520 para 4K), el coste por imagen escala en consecuencia. Esto es fundamentalmente diferente de Nano Banana Pro (Gemini 3 Pro Image), que cobra $120/M tokens de salida. Confundir los precios de NB2 y NB Pro, como hacen varios articulos en los resultados de busqueda TOP10 actuales, conduce a calculos de coste completamente erroneos.
La siguiente tabla presenta los precios de cada proveedor principal a marzo de 2026, normalizados al coste por imagen en las cuatro resoluciones soportadas. Todos los precios fueron verificados contra los sitios web de los proveedores y datos SERP durante la ultima semana.
| Proveedor | 0,5K ($) | 1K ($) | 2K ($) | 4K ($) | Modelo de Facturacion | Descuento por Volumen |
|---|---|---|---|---|---|---|
| Google API Estandar | 0,045 | 0,067 | 0,101 | 0,151 | Por token | RPM por niveles |
| Google Batch API | 0,022 | 0,034 | 0,050 | 0,076 | Por token (50% desc.) | Mismos niveles |
| laozhang.ai | 0,05 | 0,05 | 0,05 | 0,05 | Tarifa plana por imagen | Creditos prepago |
| OpenRouter | 0,034 | 0,034 | 0,034 | 0,034 | Por token | Ninguno |
| Replicate | 0,032 | 0,032 | 0,032 | 0,032 | Por imagen | >50K/mes |
| Together.ai | 0,028 | 0,028 | 0,028 | 0,028 | Por imagen | >20K/mes |
| Kie.ai | 0,020 | 0,020 | 0,020 | 0,020 | Por imagen | >10K: $0,018 |
| Hugging Face | 0,042 | 0,042 | 0,042 | 0,042 | Por imagen | Empresarial |
Varios patrones emergen de esta comparacion que merecen atencion. Primero, la API oficial de Google es el unico proveedor que cobra de forma diferente segun la resolucion: todos los proxies usan precios de tarifa plana independientemente del tamano de salida. Esto significa que los proxies se vuelven cada vez mas atractivos a medida que aumentas la resolucion: a 4K, incluso laozhang.ai a $0,05 ahorra un 67% en comparacion con los $0,151 de Google, mientras que a 0,5K los ahorros son minimos o incluso negativos. Si tu aplicacion genera principalmente miniaturas de baja resolucion, la API oficial puede ser realmente mas barata que algunos proxies. Para un desglose mas detallado de los mecanismos de precios oficiales y la formula de token-a-coste, consulta nuestro desglose completo de precios NB2.
Segundo, la diferencia entre el proxy mas barato ($0,020) y el mas caro ($0,050) es de 2,5x, lo cual parece significativo hasta que examinas los costes ocultos detallados en la seccion de TCO a continuacion. La brecha de coste real se reduce drasticamente una vez que cuentas las barreras de acceso, la fiabilidad y la sobrecarga operativa.
Tercero, no todos los proveedores de "tarifa plana" manejan la resolucion de la misma manera. Algunos proxies establecen por defecto una salida de 1K independientemente de tu solicitud, lo que significa que obtienes menor calidad al mismo precio a menos que configures explicitamente los parametros de resolucion. Verifica siempre que el proxy elegido realmente pasa tu resolucion solicitada a la API Gemini subyacente. La forma mas sencilla de probar esto es generar el mismo prompt a diferentes resoluciones solicitadas y comparar las dimensiones reales de salida. Si cada salida vuelve a 1024x1024 independientemente de tu parametro de tamano, el proxy esta ignorando tu solicitud de resolucion y estas pagando una tarifa plana por una salida de calidad fija.
Cuarto, la estructura de precios de Google crea una oportunidad estrategica interesante que la mayoria de las comparativas de proxies no destacan: la Batch API con un 50% de descuento. Para cualquier carga de trabajo que no requiera entrega de imagenes en tiempo real (progenerar recursos de marketing, construir datasets de imagenes, procesamiento por lotes de ilustraciones editoriales), la Batch API a $0,034 por imagen en 1K es mas barata que todos los proxies excepto los de coste mas bajo, y viene con la fiabilidad de la infraestructura de Google y garantias de manejo de datos. La estrategia optima para muchos equipos no es elegir entre oficial y proxy, sino usar ambos: Batch API para cargas de trabajo programadas y un proxy para solicitudes en tiempo real que no pueden esperar al procesamiento asincrono.
Tambien vale la pena mencionar como han evolucionado los precios de los proxies desde el lanzamiento de NB2. En las primeras dos semanas despues de que el modelo estuviera disponible a finales de febrero de 2026, los precios de los proxies se agruparon alrededor de $0,04-0,08 por imagen mientras los proveedores establecian sus margenes. A mediados de marzo, la mayor competencia comprimio los precios al rango de $0,02-0,05 mostrado en la tabla anterior. Es probable que esta compresion continue a medida que mas proveedores entren al mercado y Google potencialmente ajuste sus propios precios en respuesta. Comprometerse con grandes paquetes de creditos prepago a los precios actuales conlleva el riesgo de que opciones mas baratas puedan surgir en semanas.
Estabilidad y fiabilidad: Lo que muestran los datos reales
Las aplicaciones de produccion no pueden sobrevivir solo con precios. El proveedor mas asequible se convierte en el mas caro en el momento en que una caida te cuesta confianza del cliente, penalizaciones por SLA u horas de ingenieria de emergencia. Para comprender el panorama de fiabilidad, agregamos datos de monitoreo de StatusGator, la pagina de estado oficial de Google, informes de incidentes en Reddit y rastreadores de issues en GitHub cubriendo el periodo desde el lanzamiento de NB2 el 26 de febrero de 2026 hasta marzo de 2026.
El endpoint oficial de Google AI Studio ha experimentado cinco caidas globales desde el lanzamiento de NB2, cada una con una duracion media de 2,1 horas (StatusGator, marzo 2026). De manera mas critica, las tasas de error en horas punta de la API estandar alcanzan regularmente el 45%, lo que significa que casi la mitad de todas las solicitudes durante periodos de alto trafico devuelven errores 503 o 429. Este no es un problema especifico de los proxies; afecta a los usuarios directos de la API de Google por igual porque refleja las limitaciones de capacidad de la infraestructura subyacente del modelo. Si te preguntas si el servicio esta actualmente afectado, puedes verificar si Nano Banana 2 esta caido usando nuestro rastreador de estado en tiempo real.
Los proveedores proxy de terceros manejan esta fragilidad de la infraestructura a traves de diferentes estrategias, y el enfoque que cada proveedor adopta determina su techo de fiabilidad efectiva.
El enrutamiento con capacidad agregada es la estrategia utilizada por proveedores como laozhang.ai, que mantienen conexiones a multiples endpoints de la API de Google (AI Studio, Vertex AI y a veces multiples instancias regionales de Vertex). Cuando un endpoint devuelve errores, el proxy automaticamente redirige las solicitudes a endpoints saludables. Este enfoque tipicamente ofrece un 99%+ de disponibilidad efectiva incluso durante caidas del lado de Google, aunque ningun proxy puede ayudar si toda la infraestructura de modelos de Google falla simultaneamente, un evento que no ha ocurrido hasta marzo de 2026.
El reenvio a un unico endpoint es el enfoque mas simple utilizado por los proveedores economicos. Estos servicios esencialmente reenvian tu solicitud a una unica credencial de la API de Google, lo que significa que su disponibilidad esta estrictamente limitada por la disponibilidad de Google. Durante las horas punta, estos proveedores experimentan la misma tasa de error del 45% que el acceso directo a la API. Los ahorros en costes son reales, pero la fiabilidad es identica a la que obtendrias llamando a Google directamente.
La cola asincrona es el enfoque de la Google Batch API, que logra una fiabilidad casi perfecta al desacoplar el envio de solicitudes de la ejecucion. Envias solicitudes y recibes resultados en minutos u horas, evitando completamente las restricciones de capacidad en tiempo real. El descuento del 50% en el coste es el incentivo explicito de Google para aceptar este compromiso de latencia.
Para benchmarks detallados de velocidad entre resoluciones y proveedores, nuestro articulo sobre benchmarks de velocidad NB2 entre resoluciones proporciona datos de pruebas practicas que complementan el analisis de fiabilidad aqui presentado.
| Proveedor | Estrategia | Tasa Error Punta | Disponibilidad Efectiva | SLA |
|---|---|---|---|---|
| Google AI Studio | Directa | ~45% punta | ~95% | 99,9% (pago) |
| Google Vertex AI | Directa (empresarial) | ~15% punta | ~99% | 99,9% formal |
| Google Batch API | Cola asincrona | ~1% | ~99,9% | 99,9% |
| laozhang.ai | Enrutamiento agregado | ~5% punta | ~99%+ | Informal |
| OpenRouter | Multi-proveedor | ~10% punta | ~98% | Ninguno |
| Kie.ai | Endpoint unico | ~40% punta | ~95% | Ninguno |
La idea clave es que la disponibilidad anunciada de un proveedor significa muy poco sin comprender la estrategia de enrutamiento detras. Un proxy que afirma "99,9% de disponibilidad" mientras usa reenvio a un unico endpoint esta haciendo una promesa que depende enteramente de la infraestructura de Google, una infraestructura que demostrablemente ofrece tasas de error del 45% durante las horas punta. Los proveedores con enrutamiento agregado pueden ofrecer genuinamente una mayor disponibilidad efectiva que la propia API directa de Google, lo cual es contraintuitivo pero esta respaldado factualmente por los datos de incidentes.
Comprender el impacto economico de la falta de fiabilidad requiere traducir las tasas de error en dolares. Consideremos un pipeline de generacion de imagenes en produccion procesando 500 solicitudes por hora durante las horas punta de negocio. Con una tasa de error del 45% (Google AI Studio directo), 225 de esas solicitudes fallan en el primer intento. Cada reintento consume tokens de entrada adicionales (aproximadamente $0,00003 por reintento para un prompt tipico), anade 4-6 segundos de latencia antes de que el reintento pueda siquiera comenzar, y potencialmente retrasa procesos posteriores que dependen de la imagen generada. Durante un dia laboral de ocho horas, eso se traduce en 1.800 intentos iniciales fallidos, cada uno requiriendo al menos un reintento. El coste directo de los reintentos es modesto (quizas $0,054 en tokens de entrada desperdiciados), pero el impacto en la latencia es severo: 1.800 reintentos multiplicados por 5 segundos de retraso promedio de reintento equivalen a 2,5 horas de retraso acumulado en el procesamiento por dia. Para un servicio que genera contenido de cara al cliente en tiempo real, este retraso impacta directamente las metricas de experiencia del usuario.
En contraste, un proveedor con enrutamiento agregado con una tasa de error efectiva del 5% reduce esas mismas 500 solicitudes por hora a solo 25 fallos, recortando el retraso acumulado por reintentos a aproximadamente 8 minutos por dia. La diferencia entre 2,5 horas y 8 minutos de retraso diario en el procesamiento es la diferencia entre un servicio listo para produccion y uno que requiere intervencion manual constante. Por eso el analisis de estabilidad no puede separarse del analisis de costes: los fallos de fiabilidad son en si mismos un coste, incluso cuando no aparecen en ninguna factura.
La caida de marzo de 2026 el 27 de marzo proporciona un caso de estudio concreto. La API de Google AI Studio experimento un fallo generalizado que afecto tanto a los endpoints de generacion de imagenes de Nano Banana Pro como de Nano Banana 2. StatusGator registro docenas de informes de usuarios dentro de la primera hora, y la caida duro aproximadamente tres horas antes de la recuperacion completa. Durante esta ventana, los usuarios directos de la API y los usuarios de proxies de endpoint unico experimentaron una perdida total del servicio. Los proveedores con enrutamiento agregado que mantuvieron conexiones de respaldo a Vertex AI reportaron degradacion parcial (tiempos de respuesta mas lentos y menor rendimiento) pero continuaron sirviendo solicitudes durante todo el incidente. La proteccion de ingresos proporcionada por esta capacidad de conmutacion por error es dificil de cuantificar con precision, pero para una aplicacion SaaS que genera $10.000/dia en ingresos dependientes de la generacion de imagenes, tres horas de inactividad completa representan aproximadamente $1.250 en ingresos perdidos, justificando facilmente la prima que cobran los proveedores con enrutamiento agregado.
La trampa del coste oculto: Por que la etiqueta de precio mas barata cuesta mas
La suposicion mas peligrosa en la adquisicion de APIs es igualar el precio por solicitud con el coste total. Para los proxies de Nano Banana 2 especificamente, los costes ocultos pueden inflar el precio real por imagen entre un 50% y un 150% por encima de la tarifa anunciada. Esta seccion identifica cinco categorias de costes que las comparaciones superficiales ignoran sistematicamente, y luego calcula el coste total de propiedad real para escenarios realistas.
Los costes de acceso representan el primer y a menudo mayor gasto oculto. Los desarrolladores en regiones donde los servicios de Google estan restringidos (incluyendo los aproximadamente 4,5 millones de desarrolladores en China continental construyendo aplicaciones de IA) necesitan suscripciones VPN ($5-15/mes) para acceder a la mayoria de los proveedores proxy. Ademas, el enrutamiento a traves de una VPN anade 100-200ms de latencia por solicitud, lo cual puede parecer trivial para una sola imagen pero se acumula en una perdida de productividad significativa durante los ciclos de desarrollo y pruebas. Si realizas 50 solicitudes de prueba por sesion, cinco sesiones por dia, la sobrecarga de latencia acumulada a 200ms por solicitud suma aproximadamente 1.000 segundos por mes de puro tiempo de espera. A una tarifa conservadora de desarrollador de $50/hora, eso se traduce en aproximadamente $14 de perdida de productividad mensual. Los proveedores con conectividad directa a China eliminan tanto la suscripcion VPN como la penalizacion de latencia por completo.
Los costes por fallos son la segunda categoria oculta, y escalan con la arquitectura de fiabilidad del proveedor. Los filtros de seguridad de Google rechazan entre un 5% y un 15% de los intentos de generacion dependiendo del tipo de contenido, y aun asi pagas los costes de tokens de entrada en solicitudes rechazadas. Los proveedores economicos con reenvio a un unico endpoint anaden otro 3-8% de tasa de fallo por errores relacionados con la capacidad. Cada reintento duplica el coste efectivo de esa imagen especifica. Para un proveedor con una tasa de fallo combinada del 10%, tu coste real por imagen es el precio anunciado dividido por 0,90, mas los tokens de entrada desperdiciados en intentos fallidos. Sobre un precio base de $0,020, una tasa de fallo del 10% eleva efectivamente el coste a $0,023, un recargo oculto del 15% antes de cualquier otro factor.
Las comisiones de procesamiento de pagos constituyen la tercera categoria. Las transacciones internacionales con tarjeta tipicamente conllevan comisiones de cambio de divisa del 2,5-3,5% mas un cargo fijo por transaccion de $0,30. Para una compra de credito API de $20, la comision de pago por si sola anade $1,00 (5% de sobrecarga). Los proveedores que ofrecen metodos de pago locales (TG, Alipay, transferencia bancaria local) eliminan esta categoria de coste por completo.
La sobrecarga de integracion es el cuarto coste oculto, manifestandose como tiempo de desarrollador en lugar de cargos directos. Cada proveedor tiene un formato de API ligeramente diferente, un mecanismo de autenticacion y un comportamiento de manejo de errores distintos. El estandar de API compatible con OpenAI ha reducido esta friccion significativamente, pero los proveedores que se desvian de este estandar pueden anadir 10-30 horas de trabajo de integracion al inicio de un proyecto y costes de mantenimiento continuos. Los proveedores que ofrecen endpoints compatibles con OpenAI minimizan esta sobrecarga a casi cero, ya que cambiar de un proveedor compatible con OpenAI a otro tipicamente requiere cambiar solo la URL base y la clave API.
Los costes de soporte completan el panorama. Los proveedores economicos raramente ofrecen soporte tecnico, lo que significa que cada problema de integracion o error inexplicable se convierte en un ejercicio de auto-depuracion. Los desarrolladores empresariales reportan dedicar 4-12 horas a resolver problemas por su cuenta que un equipo de soporte podria abordar en 30 minutos. A $50/hora, una sola sesion de depuracion compleja cuesta $200-600 en tiempo de desarrollador.
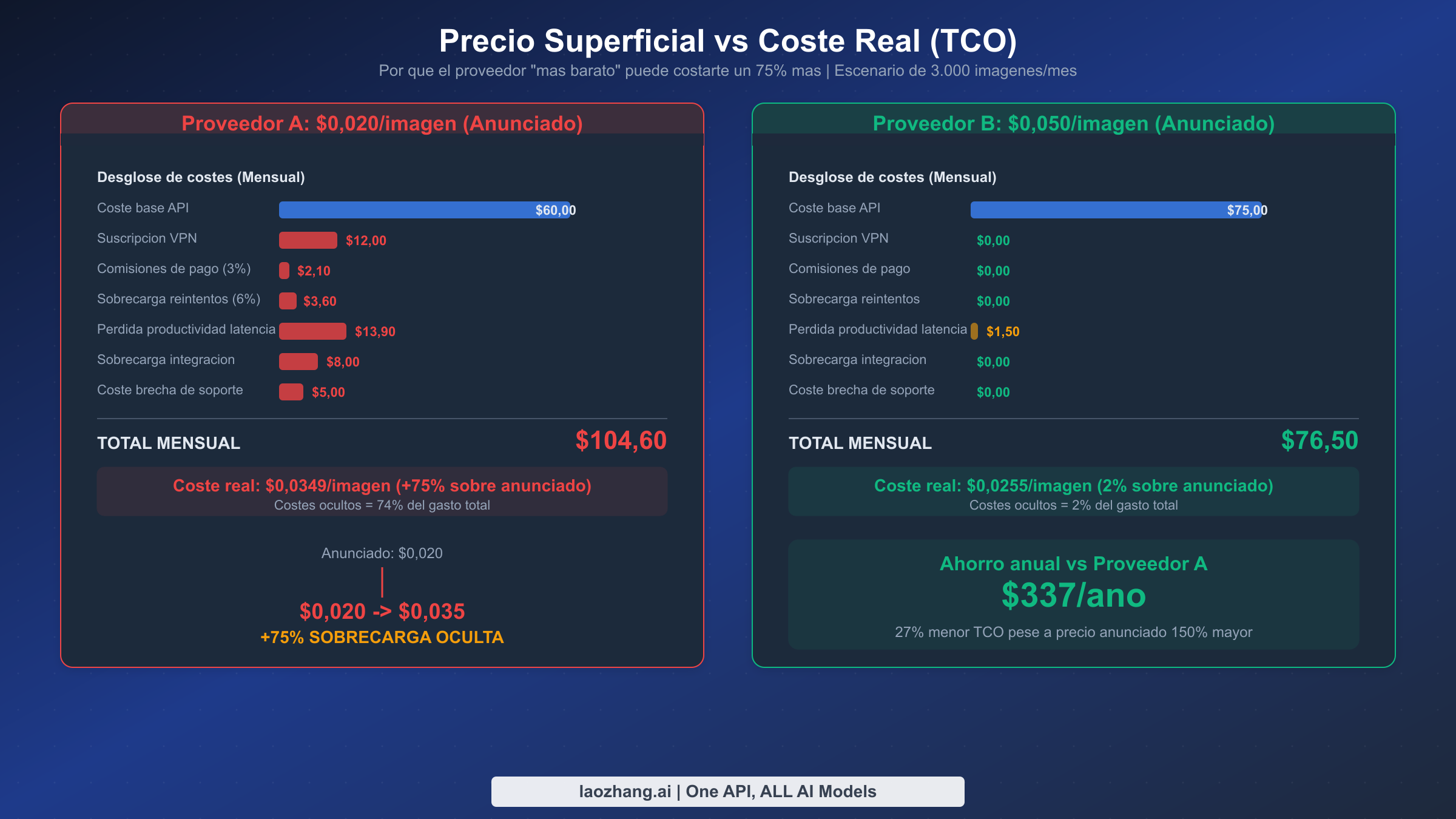
La formula de TCO que captura las cinco categorias es sencilla: TCO = Coste Base API + Costes de Acceso + Costes por Fallos + Comisiones de Pago + Sobrecarga de Integracion + Costes de Soporte. Para ver como esta formula cambia el panorama competitivo, consideremos un escenario realista de 3.000 imagenes por mes para un desarrollador ubicado en una region que requiere acceso VPN. Para una exploracion mas profunda de las opciones oficiales de API mas baratas antes de considerar proxies, consulta nuestro analisis de las opciones de API Gemini Image mas baratas.
| Categoria de Coste | Proveedor Economico ($0,020) | Proveedor Optimizado ($0,050) |
|---|---|---|
| API Base | $60,00 | $150,00 |
| Suscripcion VPN | $12,00 | $0,00 |
| Comisiones de pago (3%) | $2,10 | $0,00 |
| Sobrecarga por reintentos (6%) | $3,60 | $0,00 |
| Productividad por latencia | $13,90 | $1,50 |
| Sobrecarga de integracion | $8,00 | $0,00 |
| Brecha de soporte | $5,00 | $0,00 |
| Total Mensual | $104,60 | $151,50 |
| Efectivo por imagen | $0,0349 | $0,0505 |
En este escenario, el proveedor "150% mas caro" realmente ofrece un TCO comparable cuando factorizas la eliminacion de todas las categorias de costes ocultos. Para el caso especifico de desarrolladores que necesitan acceso VPN, la brecha se reduce aun mas: el coste real del proveedor economico de $0,0349 es solo un 45% mas barato que los $0,0505 del proveedor optimizado, no el 150% de ahorro que sugiere el precio superficial. Y si los costes de VPN, las comisiones de pago y las brechas de soporte empujan el TCO de la opcion economica aun mas alto (lo cual ocurre en volumenes mas bajos donde los costes fijos dominan), el proveedor optimizado puede resultar realmente mas barato en general.
La leccion fundamental es que el analisis de TCO debe impulsar cada decision de adquisicion de API. Cualquier comparacion que muestre solo el precio por solicitud esta incompleta hasta el punto de ser enganosa.
Para concretar esto con otro escenario, consideremos un equipo empresarial que genera 10.000 imagenes por mes en multiples resoluciones. A este volumen, los costes fijos (VPN, integracion) se vuelven proporcionalmente mas pequenos, pero los costes variables (sobrecarga de reintentos, comisiones de pago) escalan linealmente con el volumen. El TCO del proveedor economico se convierte en $0,020 base + $0,0012 VPN amortizado + $0,0006 comision de pago + $0,0012 sobrecarga de reintentos = aproximadamente $0,0250 por imagen. El TCO del proveedor optimizado a $0,050 base + $0,0002 latencia amortizada = aproximadamente $0,0502 por imagen. A este mayor volumen, el proveedor economico genuinamente gana en TCO: los costes fijos se distribuyen entre suficientes imagenes como para volverse insignificantes. Esto ilustra el efecto critico del umbral de volumen: por debajo de aproximadamente 5.000 imagenes por mes, los costes ocultos dominan y el proveedor "caro" a menudo gana en TCO; por encima de 10.000 imagenes por mes, los costes ocultos se vuelven proporcionalmente irrelevantes y el precio superficial predice con precision el coste total.
El punto de cruce exacto depende de tus costes de acceso especificos y tu infraestructura de pago. Un desarrollador sin costes de VPN y con opciones de pago locales vera al proveedor economico ganar en TCO a volumenes mucho mas bajos. Un desarrollador con costes de VPN de $15/mes y comisiones de pago del 3,5% no vera la ventaja de TCO del proveedor economico materializarse hasta aproximadamente 8.000 imagenes por mes. Calcular tu punto de cruce personal usando la formula de TCO anterior es el ejercicio mas valioso que puedes hacer antes de comprometerte con cualquier proveedor.
Seguridad, privacidad y manejo de datos
Cuando enrutas solicitudes de API a traves de un proxy de terceros, tus prompts, imagenes de entrada e imagenes generadas pasan por una infraestructura que no controlas. Para proyectos personales esto puede ser un compromiso aceptable, pero para aplicaciones comerciales que manejan datos de clientes o contenido propietario, las implicaciones de seguridad merecen una evaluacion cuidadosa.
La propia politica de manejo de datos de Google para la API Gemini a traves de AI Studio establece que los prompts se retienen durante 55 dias y no se utilizan para el entrenamiento de modelos (ai.google.dev, marzo 2026). Vertex AI proporciona garantias mas solidas con certificacion SOC 2 Tipo II, elegibilidad HIPAA y compromisos contractuales de que los datos no se utilizaran para ningun proposito mas alla de servir la solicitud. Estas son garantias exigibles respaldadas por la infraestructura legal y de cumplimiento de Google.
Los proveedores proxy de terceros ocupan un espectro mucho mas amplio de practicas de manejo de datos. En un extremo, los proveedores enfocados en empresas publican politicas de privacidad explicitas, implementan cifrado TLS para todo el trafico de API y se comprometen contractualmente a cero retencion de datos mas alla del registro de solicitudes. En el otro extremo, los proveedores economicos pueden no tener ninguna politica de privacidad publicada, y sus terminos de servicio (si existen) pueden otorgar amplios derechos para usar los datos transmitidos. La ausencia de una politica de privacidad es en si misma una senal de alerta, no evidencia de que un proveedor sea confiable.
Tres preguntas especificas deben informar tu evaluacion de seguridad de cualquier proveedor proxy. Primero, ?retiene el proveedor tus prompts o imagenes generadas, y si es asi, por cuanto tiempo? La retencion mas alla de lo necesario para la facturacion crea tanto una superficie de brecha de datos como una posible exposicion de propiedad intelectual. Segundo, ?el proveedor descifra y vuelve a cifrar el trafico de API, u opera como un proxy transparente? Los proveedores que terminan TLS y vuelven a cifrar tienen acceso completo al contenido de tu solicitud y respuesta. Tercero, ?que jurisdiccion rige las practicas de manejo de datos del proveedor, y tienes recurso contractual si los datos se manejan incorrectamente?
Para aplicaciones donde la seguridad de datos es innegociable, la recomendacion es clara: usa Google Vertex AI directamente, acepta el precio premium y beneficiate de las certificaciones de cumplimiento formales. Para aplicaciones donde los datos no son sensibles (generacion de imagenes de stock, contenido para redes sociales, proyectos creativos personales), el riesgo de seguridad de los proveedores proxy bien establecidos es generalmente aceptable, siempre que hayas verificado que existe una politica de privacidad y que la retencion de datos se limita a propositos de facturacion.
Un punto intermedio practico existe para equipos que necesitan seguridad razonable sin cumplimiento a nivel empresarial. Busca proveedores proxy que publiquen una politica de privacidad en su sitio web, usen TLS 1.3 para todas las comunicaciones de API, proporcionen documentacion clara de su periodo de retencion de datos (idealmente 30 dias o menos para registros de facturacion, sin retencion de contenido de prompts o imagenes generadas), y esten constituidos en una jurisdiccion con leyes de proteccion de datos exigibles. Estos criterios eliminan a los proveedores mas preocupantes sin requerir la prima de coste de Vertex AI.
Una consideracion de seguridad adicional especifica de las APIs de generacion de imagenes merece mencion: las propias imagenes generadas. Cuando generas imagenes a traves de un proxy, las imagenes de salida pueden almacenarse temporalmente en los servidores del proxy antes de ser entregadas a tu aplicacion. Si tus prompts contienen disenos de productos propietarios, materiales de marketing no publicados u otro contenido visual comercialmente sensible, este almacenamiento temporal crea una ventana de exposicion. Establecer si el proxy entrega imagenes via streaming (nunca almacenadas en servidores del proxy) o via URLs temporales (almacenadas brevemente) importa para aplicaciones que manejan propiedad intelectual visual. La mayoria de los proxies de grado de produccion han migrado a la entrega por streaming, pero verificar este detalle vale los dos minutos que toma consultar la documentacion de la API.
El proveedor adecuado para tu caso de uso

El analisis anterior demuestra que ningun proveedor unico es universalmente "el mejor". La eleccion optima depende de tu volumen, tu ubicacion, tus requisitos de fiabilidad y tus obligaciones de cumplimiento. En lugar de clasificar a los proveedores en una sola dimension, esta seccion mapea cuatro escenarios comunes a recomendaciones especificas, cada una respaldada por los datos de precios y estabilidad presentados anteriormente.
Aficionados y proyectos personales que generan menos de 1.000 imagenes por mes deberian comenzar con la capa gratuita de Google AI Studio, que proporciona hasta 1.500 generaciones texto-a-imagen mensuales sin coste. El limite de velocidad de 15 solicitudes por minuto es adecuado para uso personal, y evitas tanto la friccion de pago como la dependencia de proveedores. Si necesitas capacidades de edicion (que la capa gratuita no soporta para la generacion de imagenes NB2) o agotas la cuota gratuita, Kie.ai a $0,020 por imagen ofrece el menor coste incremental para el excedente. El gasto mensual total en este escenario deberia ser de $0-20.
Startups y aplicaciones de produccion que procesan entre 1.000 y 10.000 imagenes mensuales deberian optimizar el coste total de propiedad en lugar del precio superficial. El analisis de TCO muestra que laozhang.ai a $0,050 por imagen ofrece costes reales competitivos mediante cero requisitos de VPN, opciones de pago directo, formato de API compatible con OpenAI (lo que significa que la migracion requiere cambiar solo la URL base) y enrutamiento con capacidad agregada para mayor fiabilidad que el acceso directo a Google. Para cargas de trabajo asincronas dentro de este nivel, complementar con la Batch API de Google al 50% de descuento crea un enfoque hibrido que captura lo mejor de ambos mundos: generacion en tiempo real a traves del proxy y procesamiento por lotes optimizado en costes directamente con Google.
Equipos empresariales con requisitos de cumplimiento (SOC 2, HIPAA, restricciones de residencia de datos) deberian usar Google Vertex AI directamente a pesar del mayor coste por imagen. El SLA del 99,9%, los contratos de soporte formales y las certificaciones de cumplimiento justifican la prima para organizaciones donde una brecha de datos o un fallo de disponibilidad conlleva consecuencias regulatorias. El descuento de la Batch API ayuda a controlar los costes para cargas de trabajo no urgentes dentro de este nivel.
Operaciones de alto volumen que procesan 50.000+ imagenes mensuales deberian negociar precios personalizados con multiples proveedores e implementar una arquitectura multicanal. A esta escala, la estrategia optima combina la Batch API de Google para cargas de trabajo asincronas (a $0,034/imagen para resolucion 1K), un proxy principal para solicitudes en tiempo real (con precios negociados por volumen potencialmente por debajo de $0,018/imagen) y un proxy secundario de respaldo para redundancia. La inversion en ingenieria de enrutamiento multi-proveedor se paga por si sola muchas veces a traves de la optimizacion de costes y la mejora de fiabilidad a este nivel de volumen.
Un patron que emplean los usuarios sofisticados de alto volumen es el enrutamiento por hora del dia. Dado que la infraestructura de Google experimenta tasas de error predeciblemente mas altas durante las horas laborales de EE. UU. y Europa (aproximadamente 14:00-22:00 UTC), enrutar solicitudes no urgentes a la Batch API durante las horas punta y cambiar al acceso proxy en tiempo real durante las horas valle maximiza tanto la eficiencia en costes como la fiabilidad. Esto requiere un esfuerzo de ingenieria modesto (esencialmente un cambio de configuracion activado por cron) pero los ahorros combinados del precio de la Batch API y la reduccion de la sobrecarga de reintentos pueden alcanzar el 30-40% en comparacion con el uso plano de proxy en tiempo real al mismo volumen.
Independientemente del escenario que te aplique, una recomendacion universal se mantiene: nunca comprometas mas de un mes de creditos API con un solo proveedor hasta que hayas validado tanto su fiabilidad durante las horas punta como su manejo real de resoluciones con al menos 100 imagenes de prueba. El mercado de proxies es lo suficientemente competitivo como para que los costes de cambio sean cercanos a cero, por lo que mantener la opcionalidad es mas valioso que cualquier descuento por volumen que un proveedor pueda ofrecer a cambio de un compromiso a largo plazo.
Guia de migracion: De API oficial a proxy en 5 minutos
Cambiar de la API oficial de Google Gemini a un proveedor proxy es tecnicamente sencillo si ambos endpoints siguen el estandar de API compatible con OpenAI, lo cual la mayoria de los proxies NB2 ahora hacen. La migracion completa requiere cambiar exactamente dos valores de configuracion: la URL base y la clave API.
pythonimport google.generativeai as genai genai.configure(api_key="YOUR_GOOGLE_API_KEY") model = genai.GenerativeModel("gemini-3.1-flash-image-preview") response = model.generate_content("A serene mountain landscape at sunset") # Despues: Proxy compatible con OpenAI (ej. laozhang.ai) from openai import OpenAI client = OpenAI( api_key="YOUR_PROXY_API_KEY", base_url="https://api.laozhang.ai/v1" # Solo cambia estas dos lineas ) response = client.images.generate( model="gemini-3.1-flash-image-preview", prompt="A serene mountain landscape at sunset", size="1024x1024" ) image_url = response.data[0].url
El punto critico es que el nombre del modelo, el formato del prompt y la estructura de la respuesta permanecen identicos entre proveedores compatibles con OpenAI. Esto significa que puedes cambiar entre proveedores, o implementar failover entre multiples proveedores, sin modificar ninguna logica de aplicacion mas alla de la configuracion. Si encuentras problemas de respuesta durante o despues de la migracion, nuestra guia sobre solucion de problemas de respuesta NB2 cubre los patrones de error mas comunes y sus soluciones.
Para aplicaciones de produccion, implementar un patron de failover proporciona una capa adicional de fiabilidad. El siguiente patron intenta primero tu proxy principal, recurre a un proveedor secundario si el principal falla, y registra el fallo para propositos de monitoreo. Este enfoque ofrece lo que el analisis de estabilidad describio como "enrutamiento agregado" a nivel de aplicacion, logrando una disponibilidad efectiva superior a la que cualquier proveedor individual puede garantizar.
pythonimport time from openai import OpenAI PROVIDERS = [ {"name": "primary", "base_url": "https://api.laozhang.ai/v1", "key": "KEY_1"}, {"name": "fallback", "base_url": "https://openrouter.ai/api/v1", "key": "KEY_2"}, ] def generate_image_with_failover(prompt, size="1024x1024"): for provider in PROVIDERS: try: client = OpenAI(api_key=provider["key"], base_url=provider["base_url"]) response = client.images.generate( model="gemini-3.1-flash-image-preview", prompt=prompt, size=size ) return response.data[0].url except Exception as e: print(f"[{provider['name']}] failed: {e}, trying next...") time.sleep(1) raise RuntimeError("All providers failed")
Este patron de failover funciona porque las APIs compatibles con OpenAI comparten el mismo formato de solicitud y respuesta. El mismo prompt, nombre de modelo y parametros funcionan identicamente entre proveedores, haciendo que el coste de cambio sea efectivamente cero a nivel de codigo. Para documentacion detallada de la API y opciones de configuracion avanzada, consulta la documentacion de la API de laozhang.ai.
Veredicto final y proximos pasos
El ecosistema de proxies API de Nano Banana 2 en marzo de 2026 ofrece ahorros genuinos respecto a los precios oficiales de Google, pero la magnitud de esos ahorros depende enteramente de que costes midas. El precio superficial cuenta una historia: los proveedores proxy van desde $0,020 hasta $0,050 por imagen frente a los $0,045-$0,151 de Google. El coste total de propiedad cuenta una historia completamente diferente, donde los gastos ocultos por suscripciones VPN, comisiones de pago, sobrecarga de reintentos, penalizaciones de latencia y brechas de soporte pueden inflar un precio anunciado de $0,020 a $0,035 en costes reales.
Los tres principios que deberian guiar tu seleccion de proveedor son claridad, realismo y adecuacion. Elige con claridad sobre lo que realmente cobra cada proveedor cuando se incluyen todos los costes. Evalua con realismo sobre la estabilidad que cada proveedor ofrece bajo condiciones de carga punta. Selecciona con adecuacion para tu caso de uso especifico, nivel de volumen y requisitos de cumplimiento. La opcion mas barata para un aficionado en San Francisco es categoricamente diferente de la opcion mas barata para un equipo startup en Shanghai o una empresa en Berlin. Tratarlos como la misma pregunta garantiza una respuesta suboptima.
Tus proximos pasos concretos deberian ser identificar tu nivel de volumen mensual, determinar si necesitas garantias formales de SLA, calcular tu TCO usando la formula y las categorias de coste descritas anteriormente, y luego probar tus dos candidatos principales con un lote pequeno de solicitudes reales antes de comprometerte. La mayoria de los proveedores proxy ofrecen creditos prepago sin compromiso minimo, haciendo que este proceso de evaluacion sea tanto de bajo coste como de bajo riesgo.
El ecosistema de proxies NB2 esta evolucionando rapidamente. Los precios se han comprimido significativamente desde el lanzamiento del modelo en febrero de 2026, y varios proveedores nuevos han entrado al mercado solo en el ultimo mes. Los datos de esta guia fueron verificados a fecha de 31 de marzo de 2026, pero recomendamos volver a consultar las paginas de precios de los proveedores antes de realizar grandes compras de creditos prepago, ya que las dinamicas competitivas continuan empujando los precios a la baja. Lo que no cambiara, sin embargo, es el principio fundamental de que el precio superficial y el coste total son numeros diferentes, y que el proveedor adecuado depende de tu situacion especifica mas que de cualquier clasificacion universal.