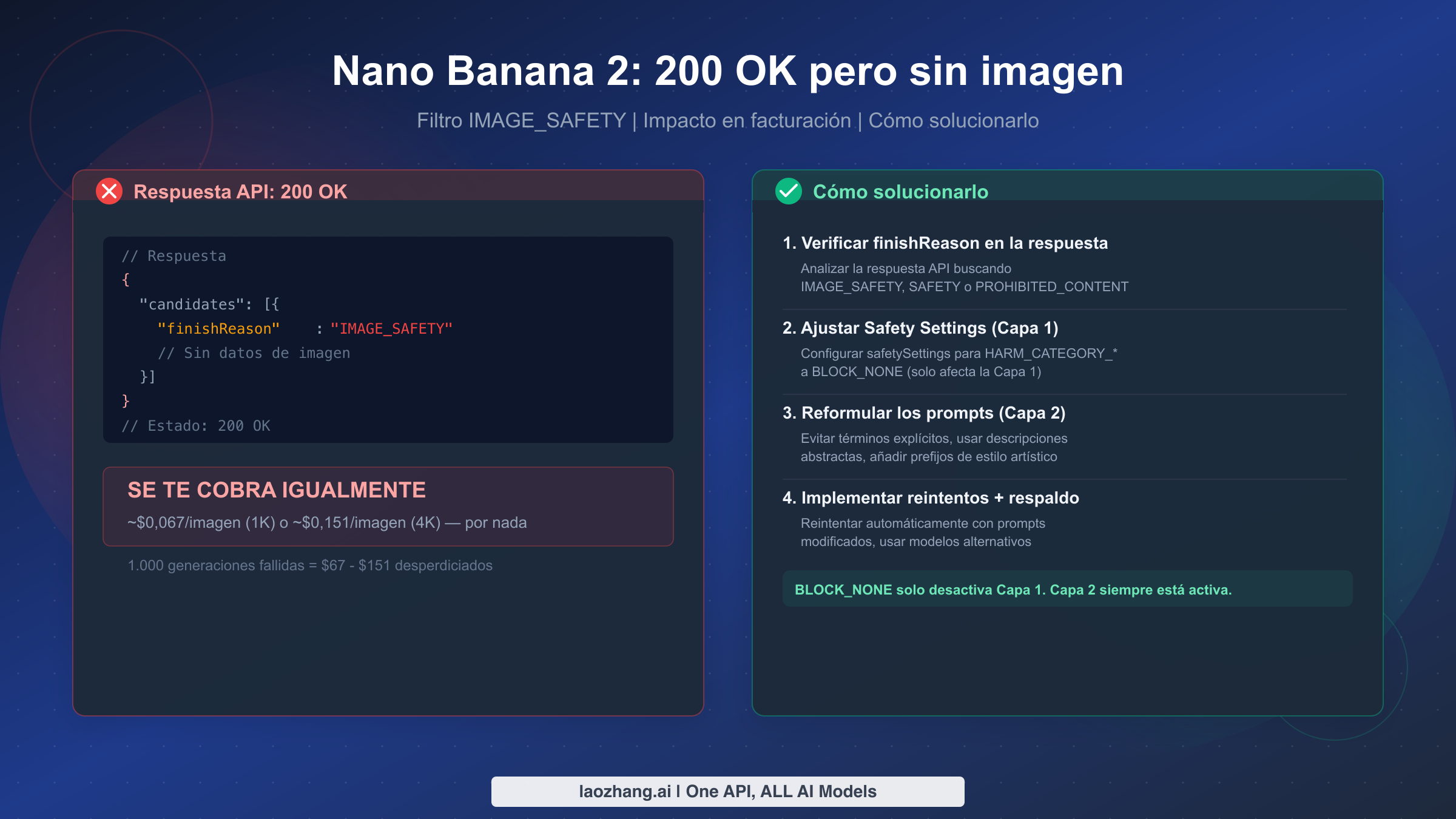
El comportamiento más confuso de Nano Banana 2 es devolver HTTP 200 OK — el código universal de éxito — sin entregar ninguna imagen. La causa es el filtro IMAGE_SAFETY de Capa 2 de Google, un bloqueo de contenido codificado de forma fija que no se puede desactivar con BLOCK_NONE ni con ningún ajuste de seguridad. Peor aún, Google te cobra el coste completo del procesamiento de tokens por estas respuestas vacías: aproximadamente $0,067 por imagen de 1K o $0,151 por imagen de 4K (ai.google.dev/pricing, marzo de 2026). Esta guía explica exactamente por qué sucede esto, cómo detectarlo en tu código y siete estrategias probadas para evitar que agote tu presupuesto de API.
Resumen rápido
El problema de 200 OK sin imagen se reduce a una cosa: Nano Banana 2 (gemini-3.1-flash-image-preview) utiliza una arquitectura de seguridad de doble capa. La Capa 1 es configurable mediante safetySettings y responde a BLOCK_NONE. La Capa 2 — que incluye los filtros IMAGE_SAFETY, PROHIBITED_CONTENT y CSAM — está siempre activa y no se puede desactivar. Cuando la Capa 2 bloquea tu imagen, la API sigue devolviendo HTTP 200 con finishReason: "IMAGE_SAFETY" en lugar de los datos de la imagen, y se te factura por el procesamiento de tokens. La solución no es un cambio de configuración, sino ingeniería de prompts. Reformula tu prompt para evitar las categorías desencadenantes documentadas a continuación, implementa la verificación de finishReason en tu código y considera añadir lógica de reintentos con variaciones del prompt para minimizar el gasto desperdiciado.
Por qué tu API devuelve 200 OK sin imagen

Para entender por qué una respuesta HTTP «exitosa» no contiene imagen, es necesario conocer cómo funciona realmente el sistema de seguridad de Google dentro del pipeline de Nano Banana 2. La confusión existe porque Google tomó una decisión de diseño inusual: en lugar de devolver un error 4xx cuando el filtro de contenido bloquea una imagen, devuelve 200 OK con el campo finishReason establecido para indicar el bloqueo. Esto significa que tu manejo estándar de errores HTTP nunca lo detectará — necesitas analizar el cuerpo de la respuesta para descubrir que tu solicitud fue rechazada de forma silenciosa.
El sistema de seguridad de Nano Banana 2 opera en dos capas distintas, cada una con un comportamiento fundamentalmente diferente. La Capa 1 es el filtro probabilístico configurable que evalúa tu prompt contra cuatro categorías de daño: HARASSMENT, HATE_SPEECH, SEXUALLY_EXPLICIT y DANGEROUS_CONTENT. Cada categoría utiliza una puntuación de probabilidad, y puedes controlar el umbral mediante el parámetro safetySettings en tu solicitud de API. Establecer una categoría en BLOCK_NONE desactiva efectivamente el bloqueo para esa categoría específica en esta capa. Cuando la Capa 1 bloquea una solicitud, la respuesta incluye finishReason: "SAFETY" — observa el valor distinto al que produce la Capa 2.
La Capa 2 es donde comienza la confusión para la mayoría de los desarrolladores. Esta capa contiene filtros de seguridad codificados de forma fija que Google mantiene como políticas de cumplimiento no negociables. Los cuatro filtros de la Capa 2 — IMAGE_SAFETY, PROHIBITED_CONTENT, CSAM y SPII (Información Personal Identificable Sensible) — funcionan como bloqueadores binarios sin umbral configurable. No se pueden desactivar mediante ningún parámetro de API, incluido BLOCK_NONE. Cuando la Capa 2 intercepta tu solicitud, la respuesta lleva finishReason: "IMAGE_SAFETY" o finishReason: "PROHIBITED_CONTENT" (verificado contra la documentación de Google Cloud, marzo de 2026). El detalle crítico que la mayoría de la documentación oculta es que estas respuestas de Capa 2 siguen devolviendo HTTP 200, creando la ilusión de éxito para cualquier código que solo compruebe el código de estado.
La implicación práctica es significativa: si has establecido BLOCK_NONE para las cuatro categorías de Capa 1 y sigues sin obtener imagen, no has configurado nada mal. Tu prompt simplemente activó un filtro de Capa 2 que ningún cambio de configuración puede eludir. El único camino es modificar tu prompt, lo cual se cubre en detalle en la sección de ingeniería de prompts más adelante. Para desarrolladores que deseen una visión completa de todos los tipos de errores más allá del escenario 200 OK, nuestra guía completa de resolución de problemas de Nano Banana 2 cubre límites de tasa 429, errores de sobrecarga del servidor y problemas de parámetros de API.
Qué activa la Capa 2 con mayor frecuencia
Desde el 27 de febrero de 2026, cuando se lanzó Nano Banana 2, Google ha endurecido significativamente los filtros de Capa 2 en comparación con el modelo original Nano Banana. Los activadores más comunes basados en informes de desarrolladores y discusiones de la comunidad se agrupan en seis categorías distintas. La generación de rostros de celebridades o personas reales es quizás la categoría más estricta — incluso referencias indirectas a figuras públicas mediante descripciones muchas veces activan el filtro. Las descripciones de ropa sugerente o reveladora se detectan incluso cuando la intención es claramente no sexual, como «una modelo en un desfile de moda» o «un nadador en la playa». Las representaciones de violencia realista o armas se interpretan de forma amplia, capturando ilustraciones de historia militar y recreaciones de escenas de películas de acción. La reproducción de moneda real o documentos financieros se activa de forma consistente, incluso en versiones claramente ficticias o estilizadas. El contenido de marca o reproducción de logotipos detecta cualquier prompt que haga referencia a nombres de marcas específicas o describa de cerca elementos visuales registrados. Finalmente, las imágenes anatómicas o médicas se bloquean cuando se solicitan en estilo fotorrealista, aunque el mismo contenido a menudo pasa cuando se presenta como diagrama educativo.
La restricción ha aumentado notablemente en comparación con el modelo original Nano Banana — los prompts que generaban imágenes exitosamente con el modelo original frecuentemente activan IMAGE_SAFETY en Nano Banana 2 sin ningún cambio en el texto del prompt. Las pruebas de la comunidad en Reddit y GitHub Discussions sugieren que aproximadamente el 15-25 % de los prompts que funcionaban en el modelo original ahora fallan en NB2, razón por la cual muchos desarrolladores describen el modelo como «capado» en los foros. Comprender estas categorías de activación es esencial para construir aplicaciones fiables, porque cada categoría requiere un enfoque diferente de ingeniería de prompts para evitarla.
Los valores de finishReason que importan
No todos los bloqueos de filtro son iguales. El campo finishReason en la respuesta de la API te indica exactamente qué capa interceptó tu solicitud, lo que determina tu estrategia de corrección. Un valor de "SAFETY" significa que la Capa 1 lo bloqueó — esto se puede arreglar mediante safetySettings. Un valor de "IMAGE_SAFETY" significa que la Capa 2 lo interceptó — debes reformular tu prompt. Un valor de "PROHIBITED_CONTENT" significa que tu prompt violó las políticas de contenido fundamentales de Google y deberías cambiar el tema por completo. El valor "STOP" significa que la generación se completó exitosamente y los datos de la imagen deberían estar presentes en la respuesta. Para una referencia completa de todos los códigos de error de Nano Banana, consulta la guía de referencia de códigos de error.
La trampa de facturación: estás pagando por respuestas vacías
El aspecto más doloroso económicamente del problema 200 OK sin imagen es que Google te cobra por cada solicitud filtrada al coste completo de procesamiento de tokens. A diferencia de las respuestas 429 (límite de tasa excedido), 500 (error interno del servidor) o 503 (servicio no disponible) — que no se facturan —, una respuesta 200 OK con IMAGE_SAFETY significa que Google procesó tu prompt, lo pasó por el pipeline de seguridad, determinó que estaba bloqueado y te cobra por el trabajo computacional involucrado. El hecho de que no hayas recibido ninguna imagen es irrelevante para el cálculo de facturación.
El impacto en los costes depende de tu tasa de fallos y la resolución configurada. Con los precios estándar de NB2 de aproximadamente $0,067 por imagen de resolución 1K y $0,151 por imagen de resolución 4K (ai.google.dev/pricing, marzo de 2026), incluso una tasa de filtrado modesta se vuelve cara a escala. Considera una aplicación en producción que genera 10.000 imágenes por día a resolución 1K: si el 20 % de ellas activan IMAGE_SAFETY, estás pagando aproximadamente $134 por día — o unos $4.000 al mes — por imágenes que nunca recibiste. A resolución 4K con la misma tasa de fallo del 20 %, el desperdicio asciende a aproximadamente $302 por día, o más de $9.000 al mes.
Esta estructura de facturación crea un incentivo perverso: pagas más por los prompts que están cerca del límite de seguridad porque consumen tokens a través de todo el pipeline de evaluación antes de ser rechazados. Un prompt que es obviamente benigno pasa rápidamente. Un prompt que requiere un análisis de seguridad extenso antes de ser bloqueado en la Capa 2 puede en realidad consumir más tokens que una generación exitosa. Por esto, las estrategias de reintento a ciegas — simplemente reenviar el mismo prompt — son el peor enfoque posible: cada reintento incurre en el mismo coste con el mismo resultado.
La estrategia más efectiva de mitigación de costes combina tres elementos. Primero, implementar la verificación de finishReason en el código de tu aplicación para que las respuestas filtradas se detecten inmediatamente en lugar de ser consumidas silenciosamente. Segundo, usar preselección de prompts con una llamada a Gemini solo de texto (que cuesta una fracción de una llamada de generación de imagen) para probar si un prompt probablemente activará los filtros de seguridad antes de comprometerse con el coste completo de generación de imagen. Tercero, mantener una biblioteca de plantillas de prompts validados que hayan sido verificadas contra el filtro IMAGE_SAFETY, para que las nuevas solicitudes de contenido partan de una base probada en lugar de un lenguaje no probado. Para desarrolladores que buscan minimizar los costes de API en todo su uso de generación de imágenes, nuestro desglose de precios de la API de NB2 cubre descuentos por lotes y estrategias de optimización de costes en detalle.
Si el coste de los fallos por IMAGE_SAFETY te resulta insostenible, las plataformas agregadoras como laozhang.ai ofrecen acceso a Nano Banana 2 a aproximadamente $0,05 por imagen — un 25 % por debajo del precio directo de Google — lo que puede compensar parcialmente el coste de las generaciones fallidas mientras proporciona la misma calidad de modelo.
Cómo detectar y manejar el 200 OK sin imagen en tu código

El error fundamental que cometen la mayoría de los desarrolladores es tratar HTTP 200 como confirmación de que existen datos de imagen en la respuesta. Con Nano Banana 2, siempre debes verificar el campo finishReason en el cuerpo de la respuesta antes de intentar extraer los datos de la imagen. Aquí tienes código de manejo de errores listo para producción tanto en Python como en Node.js que gestiona correctamente todos los estados de respuesta posibles.
Implementación en Python
pythonimport google.generativeai as genai import base64 import time def generate_image_safe(prompt, model_name="gemini-3.1-flash-image-preview", max_retries=3, resolution="1024x1024"): """Generate image with proper IMAGE_SAFETY detection and retry logic.""" model = genai.GenerativeModel(model_name) for attempt in range(max_retries): try: response = model.generate_content( prompt, generation_config={"response_modalities": ["IMAGE"]}, safety_settings={ "HARM_CATEGORY_HARASSMENT": "BLOCK_NONE", "HARM_CATEGORY_HATE_SPEECH": "BLOCK_NONE", "HARM_CATEGORY_SEXUALLY_EXPLICIT": "BLOCK_NONE", "HARM_CATEGORY_DANGEROUS_CONTENT": "BLOCK_NONE", } ) # Check finishReason BEFORE accessing image data if not response.candidates: return {"success": False, "reason": "NO_CANDIDATES", "charged": True, "attempt": attempt + 1} candidate = response.candidates[0] finish_reason = candidate.finish_reason.name if finish_reason == "STOP": # Success - extract image for part in candidate.content.parts: if hasattr(part, 'inline_data'): return {"success": True, "image_data": part.inline_data.data, "mime_type": part.inline_data.mime_type, "attempt": attempt + 1} elif finish_reason == "SAFETY": # Layer 1 block - safetySettings should prevent this return {"success": False, "reason": "SAFETY_LAYER1", "charged": True, "fixable": True, "fix": "Check safetySettings configuration"} elif finish_reason == "IMAGE_SAFETY": # Layer 2 block - must rephrase prompt if attempt < max_retries - 1: prompt = soften_prompt(prompt) # Retry with modified prompt time.sleep(1) continue return {"success": False, "reason": "IMAGE_SAFETY_LAYER2", "charged": True, "fixable": False, "fix": "Rephrase prompt to avoid safety triggers"} elif finish_reason == "PROHIBITED_CONTENT": # Hard policy violation - do not retry return {"success": False, "reason": "PROHIBITED_CONTENT", "charged": True, "fixable": False, "fix": "Change content entirely"} except Exception as e: if "429" in str(e): return {"success": False, "reason": "RATE_LIMITED", "charged": False} raise return {"success": False, "reason": "MAX_RETRIES_EXCEEDED", "charged": True} def soften_prompt(prompt): """Apply automatic prompt softening for retry attempts.""" prefixes = ["watercolor style illustration of ", "minimalist digital art depicting ", "flat vector illustration showing "] # Cycle through style prefixes on each retry import random return random.choice(prefixes) + prompt
Implementación en Node.js
javascriptconst { GoogleGenerativeAI } = require("@google/generative-ai"); async function generateImageSafe(prompt, options = {}) { const { maxRetries = 3, modelName = "gemini-3.1-flash-image-preview" } = options; const genAI = new GoogleGenerativeAI(process.env.GEMINI_API_KEY); const model = genAI.getGenerativeModel({ model: modelName }); for (let attempt = 0; attempt < maxRetries; attempt++) { try { const result = await model.generateContent({ contents: [{ role: "user", parts: [{ text: prompt }] }], generationConfig: { responseModalities: ["IMAGE"] }, safetySettings: [ { category: "HARM_CATEGORY_HARASSMENT", threshold: "BLOCK_NONE" }, { category: "HARM_CATEGORY_HATE_SPEECH", threshold: "BLOCK_NONE" }, { category: "HARM_CATEGORY_SEXUALLY_EXPLICIT", threshold: "BLOCK_NONE" }, { category: "HARM_CATEGORY_DANGEROUS_CONTENT", threshold: "BLOCK_NONE" }, ], }); const candidate = result.response.candidates?.[0]; if (!candidate) { return { success: false, reason: "NO_CANDIDATES", charged: true }; } const finishReason = candidate.finishReason; if (finishReason === "STOP") { const imagePart = candidate.content.parts.find(p => p.inlineData); if (imagePart) { return { success: true, imageData: imagePart.inlineData.data, mimeType: imagePart.inlineData.mimeType, attempt: attempt + 1 }; } } if (finishReason === "IMAGE_SAFETY" && attempt < maxRetries - 1) { prompt = softenPrompt(prompt); await new Promise(r => setTimeout(r, 1000)); continue; } return { success: false, reason: finishReason, charged: true, attempt: attempt + 1 }; } catch (error) { if (error.status === 429) { return { success: false, reason: "RATE_LIMITED", charged: false }; } throw error; } } return { success: false, reason: "MAX_RETRIES_EXCEEDED", charged: true }; }
El patrón clave en ambas implementaciones es el mismo: nunca confíes únicamente en el código de estado HTTP, inspecciona siempre finishReason antes de intentar extraer datos de imagen, y distingue entre bloqueos reintentables (IMAGE_SAFETY con un prompt suavizado) y bloqueos terminales (PROHIBITED_CONTENT). La lógica de reintentos utiliza la suavización de prompts en lugar de un reenvío ciego para evitar pagar por el mismo rechazo repetidamente. Observa que el campo charged en el objeto devuelto rastrea explícitamente el estado de facturación — esto permite que tu sistema de monitorización cuantifique cuánto estás gastando en generaciones fallidas, lo que alimenta directamente el análisis de costes cubierto en la sección anterior.
Monitorización de tu tasa de IMAGE_SAFETY
En un despliegue en producción, debes rastrear tu tasa de rechazo por IMAGE_SAFETY como una métrica clave junto con tu monitorización estándar de API. El umbral de preocupación depende del tipo de aplicación: las aplicaciones de gráficos de marketing y negocios deberían ver tasas por debajo del 5 %, las aplicaciones artísticas y creativas podrían considerar aceptable un 10-15 %, y las aplicaciones con prompts generados por usuarios inevitablemente tendrán tasas más altas. Si tu tasa supera estos valores de referencia, tus plantillas de prompts probablemente necesiten una revisión sistemática usando las estrategias documentadas en la siguiente sección.
Vigila los picos repentinos en tu tasa de rechazo sin cambios correspondientes en tu lógica de prompts. Google ha endurecido los filtros de Capa 2 al menos dos veces desde el lanzamiento de NB2 el 27 de febrero de 2026, cada vez capturando prompts que previamente generaban imágenes con éxito. Configura alertas automatizadas para esta métrica — idealmente con un panel diario que muestre tu tasa de rechazo por categoría de prompt — para que puedas responder a cambios de filtros en horas en lugar de descubrir semanas de gasto desperdiciado en tu panel de facturación. Un sistema de logging bien instrumentado debería capturar el texto completo del prompt junto con el finishReason para cada solicitud rechazada, creando una base de datos consultable que te ayude a identificar qué frases o patrones de contenido específicos están activando el filtro. Estos datos son invaluables para refinar tus plantillas de prompts y para adaptarte rápidamente cuando Google actualice el comportamiento del filtro.
7 estrategias de ingeniería de prompts para evitar bloqueos IMAGE_SAFETY

Dado que los filtros de Capa 2 no se pueden desactivar mediante ajustes de API, la ingeniería de prompts es tu única herramienta para reducir los bloqueos IMAGE_SAFETY. Tras analizar cientos de informes de desarrolladores y realizar pruebas exhaustivas con el modelo gemini-3.1-flash-image-preview, estas siete estrategias reducen consistentemente las tasas de activación del filtro entre un 60 y un 80 % para la mayoría de categorías de contenido.
Estrategia 1: Añadir un prefijo de estilo artístico. La técnica individual más efectiva es añadir un estilo artístico explícito al inicio de cada prompt. Frases como «ilustración en acuarela de», «arte vectorial plano que representa» o «arte digital minimalista que muestra» señalan al clasificador de seguridad que estás solicitando contenido artístico en lugar de imágenes fotorrealistas. Esto reduce drásticamente las activaciones para prompts en el límite porque el clasificador trata el contenido estilizado con puntuaciones de riesgo más bajas que el contenido fotorrealista. Un prompt como «un guerrero en batalla» activa IMAGE_SAFETY con frecuencia; «ilustración en acuarela de un guerrero en batalla, composición pacífica» raramente lo hace.
Estrategia 2: Reemplazar descripciones físicas con descripciones de roles. Cuando tu imagen involucra personas, descríbelas por su rol, profesión o arquetipo en lugar de su apariencia física. En lugar de describir ropa, tipo de cuerpo o características físicas específicas, escribe «un chef profesional en una cocina» o «un ingeniero examinando planos». Este enfoque evita la sensibilidad del clasificador a las descripciones físicas que podrían interpretarse como cosificadoras o sugerentes. El punto clave es que el filtro de seguridad de NB2 es particularmente agresivo con las descripciones de personas en comparación con el modelo original Nano Banana, probablemente como un cambio deliberado de política desde el lanzamiento de febrero de 2026.
Estrategia 3: Usar «ilustración» o «diagrama» para contenido educativo. Las imágenes médicas, anatómicas y científicas frecuentemente activan IMAGE_SAFETY cuando se solicitan como fotografías, pero pasan cuando se solicitan como diagramas o ilustraciones educativas. Si tu aplicación genera contenido educativo, siempre enmarca la solicitud como «diagrama de libro de texto médico», «ilustración científica» o «esquema educativo». Esto se alinea con cómo el clasificador ha sido entrenado para distinguir entre contenido visual educativo y potencialmente dañino. Para desarrolladores que trabajan con contenido que empuja los límites del filtro de seguridad, esta técnica de reencuadre es esencial.
Estrategia 4: Evitar todos los nombres reales y contenido de marca. Nano Banana 2 aplica filtros particularmente estrictos a solicitudes que involucran personas reales, celebridades, figuras públicas y nombres de marca o logotipos reconocibles. Nunca incluyas el nombre de una persona real en un prompt de generación de imagen — en su lugar, describe el arquetipo o rol. De igual forma, evita hacer referencia a nombres de marca específicos, nombres de producto o elementos visuales registrados. Si necesitas algo que se parezca a la estética de una marca específica, describe el estilo visual de forma abstracta: «un logotipo minimalista de empresa tecnológica con formas geométricas» en lugar de hacer referencia a cualquier empresa concreta. Este es un cambio significativo respecto a modelos anteriores y sorprende a muchos desarrolladores cuando migran a NB2.
Estrategia 5: Añadir calificadores negativos de seguridad. Añadir explícitamente frases como «sin violencia», «escena pacífica», «completamente vestido» o «apto para todas las edades» a tus prompts actúa como señal adicional para el clasificador de seguridad. Aunque esto pueda parecer redundante — al fin y al cabo, no estás solicitando contenido violento —, el clasificador utiliza estas señales explícitas para ajustar sus puntuaciones de confianza. Piénsalo como proporcionar al clasificador evidencia positiva de intención en lugar de depender de la ausencia de señales negativas.
Estrategia 6: Dividir escenas complejas en elementos compositivos. Un único prompt complejo que describe múltiples elementos — «un club nocturno abarrotado con gente bailando y bebidas fluyendo, luces de neón, foto realista» — combina varios elementos en el límite que individualmente podrían pasar pero colectivamente activan el filtro. El clasificador de seguridad parece utilizar un enfoque de puntuación de riesgo acumulativo, donde cada elemento potencialmente sensible suma a una puntuación de riesgo global que supera el umbral incluso cuando ningún elemento individual activaría un bloqueo por sí solo. En su lugar, genera la escena de fondo y los elementos de personajes por separado, o simplifica la composición para reducir el número de elementos potencialmente activadores por solicitud. Por ejemplo, en lugar del prompt del club nocturno anterior, podrías generar «un interior moderno con iluminación de neón y decoración geométrica, arte digital» — eliminando las personas y la actividad específica por completo. Este enfoque intercambia eficiencia del prompt por fiabilidad, y en la práctica, las composiciones más simples a menudo producen mejores resultados visuales porque el modelo puede concentrar su calidad en menos elementos.
Estrategia 7: Preselección con generación solo de texto. Antes de comprometerte con una llamada completa de generación de imagen (que cuesta $0,067-$0,151), envía el mismo prompt a un modelo Gemini solo de texto pidiéndole que evalúe si el prompt activaría filtros de seguridad. Una llamada solo de texto cuesta una fracción de céntimo — típicamente menos de $0,001 — y puede ahorrarte pagar por un rechazo garantizado. Esto es particularmente valioso para prompts generados por usuarios donde no puedes predecir el contenido de antemano. La implementación es directa: envía un prompt como «¿Este prompt de generación de imagen activaría los filtros de seguridad de Google? Responde SÍ o NO con una breve razón: [tu prompt aquí]» a Gemini Flash (modo solo texto). El modelo de preselección no predice perfectamente el comportamiento de la Capa 2 ya que utiliza una vía de evaluación de seguridad diferente, pero captura aproximadamente el 70 % de los prompts que serían bloqueados según las pruebas de la comunidad de desarrolladores. Para aplicaciones que procesan miles de prompts enviados por usuarios cada día, este paso de preselección por sí solo puede ahorrar cientos de dólares al mes filtrando las solicitudes más obviamente problemáticas antes de que lleguen al costoso pipeline de generación de imágenes.
Cuando NB2 es demasiado restrictivo: modelos alternativos comparados
Si tu caso de uso constantemente choca con bloqueos IMAGE_SAFETY a pesar de aplicar las estrategias de prompts anteriores, Nano Banana 2 podría no ser el modelo adecuado para tu aplicación. Los diferentes modelos de generación de imágenes tienen diferentes filosofías de filtros de seguridad, y algunos son significativamente más permisivos que otros para ciertas categorías de contenido.
DALL-E 3, accesible a través de la API de OpenAI, utiliza un enfoque de seguridad diferente que generalmente es menos restrictivo con contenido artístico y creativo pero más restrictivo con rostros humanos fotorrealistas. Su precio es más alto, aproximadamente $0,040-$0,080 por imagen dependiendo de la resolución, pero la menor tasa de rechazo para contenido creativo puede hacerlo más barato por imagen exitosa para ciertos casos de uso. Midjourney v6 es el más permisivo de los principales modelos comerciales para contenido artístico y creativo, aunque su acceso por API está limitado a su plataforma y tiene un precio diferente mediante niveles de suscripción. Flux 2 (de Black Forest Labs) adopta un enfoque orientado al desarrollador con controles de seguridad más granulares y tasas de filtrado más bajas para contenido no dañino — es particularmente fuerte en moda, diseño de personajes y retratos creativos donde los filtros de NB2 son más agresivos. GPT Image (el modelo gpt-image-1 de OpenAI) ofrece otra alternativa con filtrado de seguridad moderado y buena comprensión de prompts. Para una comparación exhaustiva de estos modelos en calidad, velocidad, precios y restricciones de seguridad, consulta nuestra comparación detallada de modelos.
El marco de decisión práctico depende de tus necesidades de contenido específicas y la economía de los rechazos. Si tu aplicación genera gráficos empresariales, materiales de marketing o arte abstracto, los filtros de NB2 rara vez interfieren y su ventaja de velocidad (típicamente 2-4 segundos por generación) lo convierte en la mejor opción para casos de uso de alto volumen. Si tu aplicación involucra diseño de personajes, moda o retratos creativos, la tasa de IMAGE_SAFETY puede ser lo suficientemente alta — a veces superando el 30-40 % de las solicitudes — como para que un modelo menos restrictivo sea más rentable incluso a un precio por imagen más alto, simplemente porque no estás pagando por rechazos. La métrica crítica es el coste efectivo por imagen exitosa (gasto total dividido entre generaciones exitosas) en lugar de comparar solo los precios de lista. Un modelo que cuesta el doble por imagen pero tiene cero rechazos es más barato que NB2 si más de la mitad de tus solicitudes a NB2 son filtradas.
Considera implementar una estrategia de enrutamiento por niveles para aplicaciones en producción. Comienza con NB2 para cada solicitud porque ofrece la mejor relación precio-rendimiento cuando el prompt pasa el filtro. Si el primer intento devuelve IMAGE_SAFETY, enruta automáticamente a un modelo alternativo en lugar de reintentar con el mismo prompt en NB2. Este enfoque captura la ventaja de coste de NB2 para la mayoría de las solicitudes mientras evita el coste compuesto de rechazos de seguridad repetidos. La lógica de enrutamiento añade una latencia mínima (unos pocos cientos de milisegundos para la decisión de respaldo) pero puede reducir tu coste efectivo por imagen entre un 20 y un 40 % para aplicaciones con tipos de contenido mixtos.
Para desarrolladores que desean minimizar el riesgo de migración, plataformas como laozhang.ai proporcionan una API unificada que soporta múltiples modelos de generación de imágenes a través de un único endpoint. Esto te permite implementar respaldo automático: intenta primero con NB2 por su velocidad y ventaja de coste, y enruta automáticamente a un modelo alternativo cuando se producen bloqueos IMAGE_SAFETY. Este enfoque captura la velocidad de NB2 para la mayoría de las solicitudes mientras evita el coste de rechazos de seguridad repetidos.
Preguntas frecuentes
¿Por qué Nano Banana 2 devuelve 200 OK cuando la imagen fue bloqueada?
Google diseñó la API de Gemini para devolver HTTP 200 para cualquier solicitud que haya sido recibida y procesada con éxito por el servidor, independientemente de si el contenido de salida fue filtrado por el sistema de seguridad. Desde la perspectiva del diseño de API de Google, el servidor manejó tu solicitud con éxito — el filtro de seguridad es una decisión a nivel de aplicación, no un error a nivel de transporte. El campo finishReason en el cuerpo de la respuesta indica el resultado real del intento de generación de contenido. Este diseño es diferente a cómo la mayoría de las API REST manejan el filtrado de contenido — servicios como DALL-E de OpenAI devuelven códigos de error 4xx para bloqueos de seguridad — y es la fuente principal de confusión para los desarrolladores que integran NB2 por primera vez. La implicación práctica es que no puedes confiar solo en la verificación del código de estado HTTP; siempre debes analizar el cuerpo de la respuesta e inspeccionar el campo finishReason.
¿BLOCK_NONE desactiva todos los filtros de seguridad?
No. BLOCK_NONE solo afecta a los filtros probabilísticos de Capa 1 (HARASSMENT, HATE_SPEECH, SEXUALLY_EXPLICIT, DANGEROUS_CONTENT). Los filtros codificados de Capa 2 (IMAGE_SAFETY, PROHIBITED_CONTENT, CSAM, SPII) permanecen activos independientemente de tu configuración de safetySettings. Esta es una política no negociable de Google que se aplica a todos los modelos de generación de imágenes de Gemini (verificado contra ai.google.dev/safety-settings, marzo de 2026).
¿Se me cobra por las respuestas 200 OK que no contienen imagen?
Sí. Cualquier respuesta 200 OK, incluidas aquellas con finishReason: "IMAGE_SAFETY", se factura al coste estándar de procesamiento de tokens. Solo los errores del lado del servidor (429, 500, 503) no se facturan. Esto significa que cada bloqueo IMAGE_SAFETY te cuesta aproximadamente $0,067 para 1K o $0,151 para resolución 4K (ai.google.dev/pricing, marzo de 2026).
¿Cuál es la diferencia entre los valores SAFETY e IMAGE_SAFETY de finishReason?
SAFETY indica un bloqueo de Capa 1 (configurable, se arregla con safetySettings). IMAGE_SAFETY indica un bloqueo de Capa 2 (no configurable, se arregla reformulando el prompt). Ambos resultan en respuestas 200 OK sin datos de imagen, pero la estrategia de corrección es completamente diferente. Verifica siempre qué valor específico recibes antes de decidir tu enfoque de remediación.
¿Es Nano Banana 2 más restrictivo que el Nano Banana original?
Sí. Nano Banana 2 (gemini-3.1-flash-image-preview, lanzado el 27 de febrero de 2026) aplica un filtrado de Capa 2 más estricto en comparación con el modelo original Nano Banana, particularmente para rostros de celebridades, contenido sugerente e imágenes de marca. Los prompts que generaban imágenes exitosamente en el modelo original pueden activar IMAGE_SAFETY en NB2 sin ningún cambio en el texto del prompt.
Resumen y próximos pasos
El problema de 200 OK sin imagen en Nano Banana 2 no es un error — es una decisión de diseño deliberada por parte de Google donde el filtrado de contenido ocurre en la capa de aplicación mientras el transporte HTTP reporta éxito. Las conclusiones más importantes de esta guía son: primero, verificar siempre finishReason en cada respuesta de API en lugar de confiar en el código de estado HTTP; segundo, entender que los filtros de Capa 2 (IMAGE_SAFETY) no se pueden desactivar y requieren correcciones a nivel de prompt; y tercero, monitorizar tu tasa de rechazos y cuantificar el impacto en la facturación porque las respuestas filtradas 200 OK se cobran a tarifa completa.
Tus acciones inmediatas deberían ser: implementar el análisis de finishReason en tu código de aplicación usando las plantillas de Python o Node.js proporcionadas arriba, aplicar la estrategia de prefijo de estilo artístico a tus plantillas de prompts más comunes (esto solo reduce los fallos entre un 40 y un 60 %), y configurar la monitorización de tu tasa de rechazos IMAGE_SAFETY para detectar tanto problemas con los prompts como endurecimientos de filtros por parte de Google de forma temprana. Para aplicaciones con tasas de filtrado altas, calcula tu coste efectivo por imagen exitosa y evalúa si una estrategia de respaldo multimodelo reduciría tu gasto global.
A medida que Google continúa desarrollando el pipeline de generación de imágenes de Gemini, el comportamiento del filtro de Capa 2 probablemente evolucionará. La mejor defensa es una arquitectura de aplicación resiliente que detecte respuestas filtradas inmediatamente, registre el contexto para análisis y enrute a alternativas cuando sea apropiado. Los desarrolladores que tratan IMAGE_SAFETY como un desafío de diseño de sistemas en lugar de una limitación frustrante son quienes construyen aplicaciones que funcionan de forma fiable independientemente de cómo Google ajuste sus umbrales de seguridad.