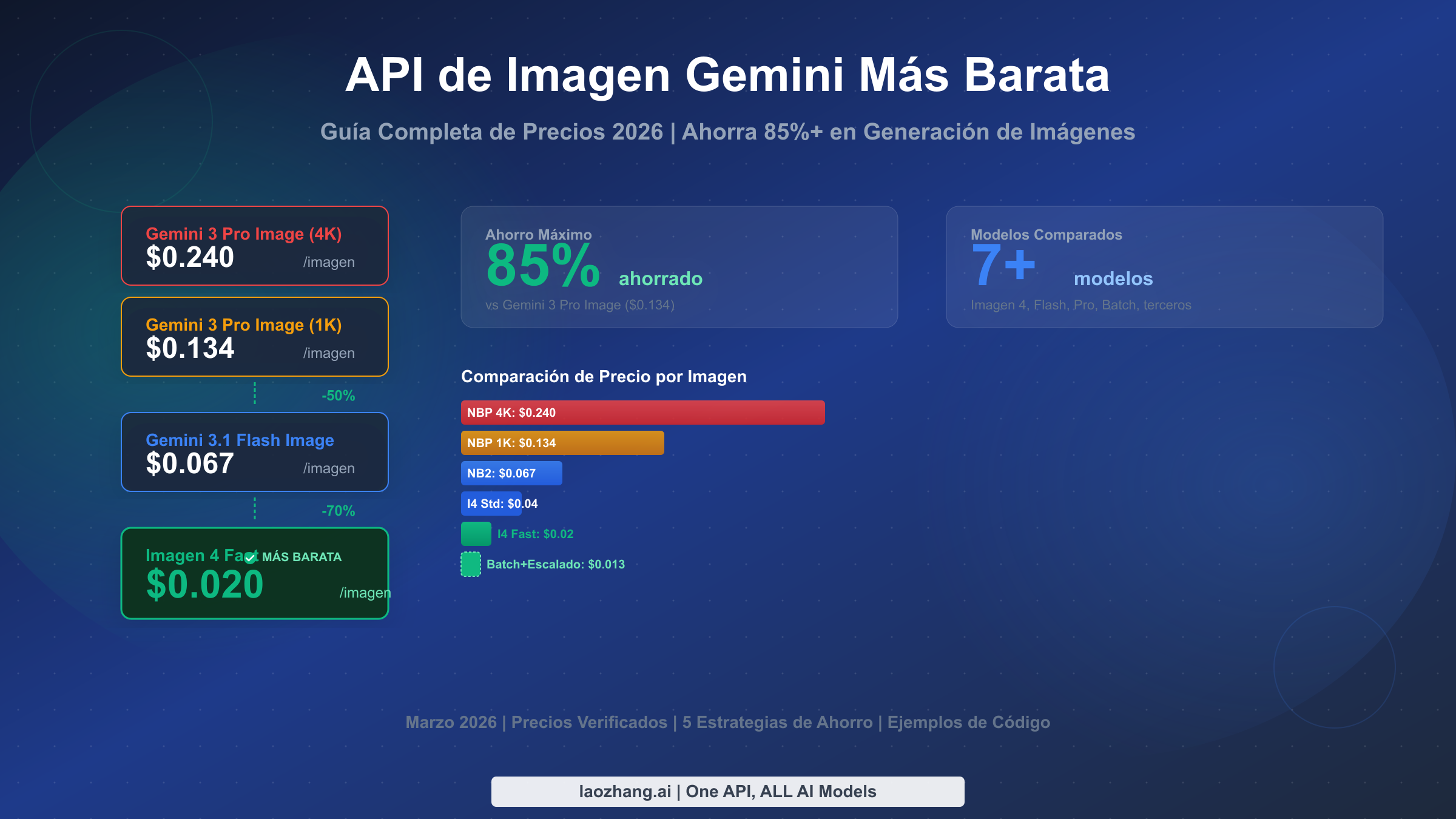
La API Imagen 4 Fast de Google genera imágenes a solo $0.02 cada una, convirtiéndola en la opción oficial más barata de generación de imágenes Gemini a marzo de 2026. Combinada con el descuento automático del 50% de la Batch API, puedes reducir ese costo a $0.01 por imagen — una reducción del 92% en comparación con los $0.134 por imagen de Gemini 3 Pro Image a resolución estándar. Esta guía analiza cada modelo disponible, revela costos ocultos que la mayoría de los artículos ignoran, y proporciona cinco estrategias concretas para minimizar tu gasto sin sacrificar la calidad que tu aplicación necesita.
Resumen rápido
Esto es lo que necesitas saber sobre los precios de la API de imagen Gemini en marzo de 2026. La opción oficial más barata es Imagen 4 Fast a $0.02 por imagen, que es un 85% más económica que Gemini 3 Pro Image a $0.134. Puedes acumular ahorros usando la Batch API (50% de descuento), generando a resoluciones más bajas y escalando ($0.003), o enrutando a través de proveedores externos como laozhang.ai a una tarifa fija de $0.05 por imagen sin importar la resolución. El modelo óptimo depende completamente de tu volumen y requisitos de calidad — un proyecto personal que genera 500 imágenes por mes enfrenta una economía completamente diferente a la de una empresa que procesa 100,000 imágenes mensuales. La matriz de decisión más adelante en este artículo te ayudará a elegir la combinación correcta para tu situación específica.
Todos los modelos de API de imagen Gemini y su costo en marzo de 2026
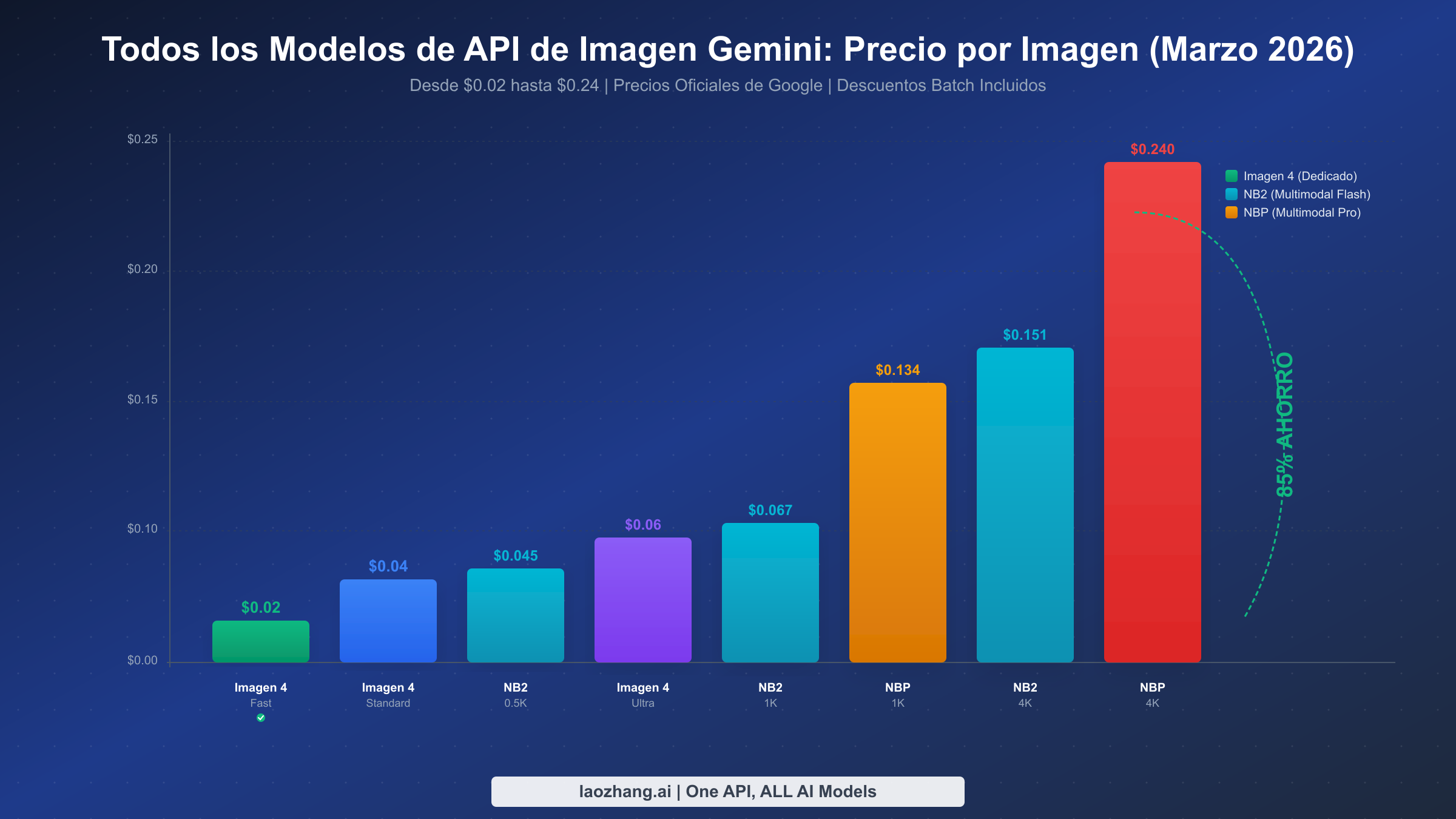
El ecosistema de generación de imágenes de Google ha crecido notablemente en complejidad durante el último año, con siete modelos distintos ahora disponibles a través de diferentes endpoints de API. Comprender lo que ofrece cada modelo — y más importante aún, lo que cuesta — es la base de cualquier estrategia de optimización de costos. La tabla de precios a continuación consolida datos verificados directamente contra la página oficial de precios de Google AI for Developers y la documentación de precios de Vertex AI, ambas actualizadas en la última semana a marzo de 2026.
Los modelos se dividen en dos categorías arquitectónicas que impactan directamente tanto en el precio como en la capacidad. Imagen 4 (Fast, Standard y Ultra) es un modelo dedicado de generación de imágenes optimizado exclusivamente para producción visual. Utiliza precios fijos por imagen, lo que hace que el presupuesto sea sencillo. Los modelos nativos de imagen Gemini (3.1 Flash Image y 3 Pro Image, también conocidos por sus nombres en código Nano Banana 2 y Nano Banana Pro) son modelos de lenguaje multimodal que generan imágenes como parte de interacciones conversacionales. Estos utilizan precios basados en tokens, lo que significa que tu costo varía según la resolución y la complejidad del prompt.
| Modelo | Tipo | Precio/Imagen (1K) | Precio/Imagen (4K) | Precio Batch | Ideal Para |
|---|---|---|---|---|---|
| Imagen 4 Fast | Dedicado | $0.02 | N/A (máx 2K) | $0.01 | Alto volumen, apps económicas |
| Imagen 4 Standard | Dedicado | $0.04 | N/A (máx 2K) | $0.02 | Equilibrio calidad/costo |
| Imagen 4 Ultra | Dedicado | $0.06 | N/A (máx 2K) | $0.03 | Mejor calidad dedicada |
| Gemini 3.1 Flash Image (NB2) | Multimodal | $0.067 | $0.151 | $0.034 | Multimodal + edición |
| Gemini 3 Pro Image (NBP) | Multimodal | $0.134 | $0.240 | $0.067 | Mejor calidad + texto |
| Imagen 4 + Escalado (combo) | Dedicado + Post | $0.023 (escalado a 4K) | $0.023 | $0.013 | Salida 4K económica |
| Terceros (laozhang.ai) | Proxy | $0.05 | $0.05 | N/A | Tarifa fija, sin límites |
Varios detalles de precios merecen atención especial. Primero, los modelos Imagen 4 tienen una resolución nativa máxima de 2K (2048x2048), lo que significa que no puedes generar directamente imágenes 4K con ellos. Si necesitas salida 4K, debes usar los modelos multimodales Gemini a mayor costo o combinar Imagen 4 con la API de escalado de Google a $0.003 por operación (ai.google.dev/pricing, verificado en marzo de 2026). Segundo, el descuento Batch API del 50% se aplica a todos los modelos de pago y procesa solicitudes de forma asíncrona — típicamente en minutos para lotes pequeños, pero potencialmente horas durante picos de demanda. Tercero, el nivel gratuito en Google AI Studio proporciona de 500 a 1,000 imágenes por día dependiendo de la carga del servidor, pero esto está limitado a la interfaz web y no soporta acceso programático por API para generación de imágenes. Para una comparación más amplia que incluya opciones fuera de Google, nuestra comparación de APIs de imagen AI para 2026 cubre GPT Image 1.5, FLUX.2 y Grok Imagine junto a los modelos Gemini.
Imagen 4 vs generación nativa de imágenes Gemini: ¿cuál es la diferencia?
La distinción entre Imagen 4 y la generación nativa de imágenes de Gemini confunde a muchos desarrolladores, en parte porque Google los comercializa a través de canales superpuestos y usa terminología similar. Una búsqueda de "generación de imágenes Gemini" muestra resultados sobre ambas familias de modelos sin distinguirlos claramente, lo que lleva a situaciones donde los desarrolladores eligen el modelo incorrecto y pagan 5 veces más de lo necesario. Comprender la diferencia arquitectónica es esencial para tomar la decisión correcta en cuanto a costos, porque la opción más barata no siempre es la mejor para cada caso de uso.
Imagen 4 es un modelo dedicado de texto a imagen construido específicamente para la generación de imágenes. Cuando le envías un prompt de texto, genera una imagen — esa es su única función. No entiende el contexto de conversación, no puede editar imágenes existentes mediante diálogo y no soporta interacciones de múltiples turnos. Lo que le falta en flexibilidad, lo compensa en eficiencia de costos y velocidad. Imagen 4 Fast típicamente devuelve resultados en 2 a 4 segundos, haciéndolo adecuado para aplicaciones en tiempo real donde los usuarios esperan retroalimentación casi instantánea. El precio fijo por imagen ($0.02 a $0.06) también hace que el presupuesto sea completamente predecible — sabes exactamente cuánto costará cada solicitud antes de enviarla.
La generación nativa de imágenes de Gemini funciona de manera fundamentalmente diferente. Modelos como Gemini 3 Pro Image (con nombre en código interno Nano Banana Pro) y Gemini 3.1 Flash Image (Nano Banana 2) son modelos de lenguaje multimodal que generan imágenes como una de sus capacidades. Esto significa que puedes tener una conversación con el modelo, pedirle que genere una imagen, luego pedirle que modifique esa imagen, todo dentro de una misma ventana de contexto. El modelo entiende lo que generó previamente y puede iterar sobre ello. Esta capacidad de edición conversacional es algo que Imagen 4 simplemente no puede hacer. Para una comparación detallada de calidad de imagen entre estos modelos y sus competidores, consulta nuestra comparación de Gemini Flash vs GPT Image vs FLUX.
La compensación es directa. Si necesitas generación pura de texto a imagen al menor costo posible — miniaturas, fotos de productos, visuales de marketing donde proporcionas un prompt completo — Imagen 4 Fast a $0.02 por imagen es el claro ganador. Si necesitas edición conversacional, refinamiento en múltiples turnos o la capacidad de generar imágenes que incorporen comprensión de una conversación de texto, los modelos nativos Gemini justifican su precio más alto. La precisión del 94-96% en renderizado de texto de Gemini 3 Pro Image (benchmark de spectrumailab, marzo de 2026) también lo hace significativamente mejor para imágenes que contienen texto legible, donde Imagen 4 tiende a producir tipografía menos precisa.
Hay una distinción más que importa para desarrolladores que construyen aplicaciones multilingües. Gemini 3 Pro Image maneja scripts no latinos — caracteres chinos, kanji japonés, hangul coreano, texto árabe — significativamente mejor que Imagen 4, que fue entrenado principalmente en renderizado de texto con script latino. Si tu aplicación necesita generar imágenes con texto CJK integrado u otros scripts complejos, los modelos nativos Gemini son efectivamente tu única opción viable dentro del ecosistema de Google, y la prima de precio está justificada por la precisión dramáticamente superior en estos scripts. Para requisitos de solo texto latino, o para imágenes que no contienen texto en absoluto, esta ventaja es irrelevante e Imagen 4 sigue siendo la opción más económica.
Cinco estrategias para reducir tu factura de API de imagen Gemini en más de un 80%

La mayoría de los desarrolladores comienzan con el modelo que la documentación de Google destaca más prominentemente — generalmente Gemini 3 Pro Image a $0.134 por imagen — y nunca investigan alternativas más baratas. Las estrategias a continuación están ordenadas de la más simple a la más sofisticada, y pueden combinarse para obtener el máximo ahorro. Un desarrollador que actualmente gasta $134 por mes en 1,000 imágenes a través de Gemini 3 Pro Image podría reducir esa factura a menos de $15 aplicando solo las dos primeras estrategias.
Estrategia 1: Cambiar a Imagen 4 Fast para tareas de generación simples. Este es el cambio individual de mayor impacto que puedes hacer. Imagen 4 Fast cuesta $0.02 por imagen versus $0.134 de Gemini 3 Pro Image — una reducción del 85% sin complejidad de código adicional. La calidad es suficiente para la mayoría de aplicaciones en producción que no requieren renderizado de texto ni edición conversacional. Para flujos de trabajo de procesamiento por lotes donde las imágenes se generan con anticipación en lugar de bajo demanda, nuestra guía de optimización de costos de Batch API cubre el proceso completo de configuración incluyendo gestión de colas y manejo de errores.
Estrategia 2: Habilitar el procesamiento Batch API para cargas de trabajo no en tiempo real. La Batch API de Google aplica automáticamente un descuento del 50% a cualquier modelo compatible. Imagen 4 Fast baja de $0.02 a $0.01 por imagen. Gemini 3.1 Flash Image baja de $0.067 a $0.034. El único requisito es que tu aplicación pueda tolerar procesamiento asíncrono — envías un lote de solicitudes y recibes resultados de minutos a horas después. Para aplicaciones como generación nocturna de contenido, creación de imágenes de catálogo o pipelines de activos de marketing, esto es ahorro puro sin compromiso de calidad. La Batch API procesa solicitudes a través de los mismos modelos con calidad de salida idéntica, solo en una cola de menor prioridad que Google puede programar de manera más eficiente.
Estrategia 3: Generar a menor resolución y escalar. Esta estrategia rara vez se discute pero puede ser notablemente efectiva. Imagen 4 Fast genera una imagen de 1K (1024x1024) por $0.02. La API de escalado de Google puede ampliarla a 4K por $0.003 por operación (IntuitionLabs, datos de precios de marzo de 2026). El costo total de una imagen 4K por esta vía es $0.023 — comparado con $0.240 por una imagen 4K nativa de Gemini 3 Pro Image. Eso representa un 90% de ahorro en salida 4K. El resultado escalado no será idéntico a una imagen 4K generada nativamente, ya que los algoritmos de escalado no pueden añadir detalles que no estaban en el original, pero para muchos casos de uso la diferencia es imperceptible para los usuarios finales. Este enfoque funciona mejor para imágenes con sujetos claros y menos detalles finos — fotos de productos, paisajes y diagramas tienden a escalar bien, mientras que ilustraciones muy detalladas con texto pequeño pueden mostrar artefactos.
Estrategia 4: Enrutar a través de proveedores de API de terceros. Servicios como laozhang.ai ofrecen acceso a modelos de imagen Gemini a una tarifa fija de $0.05 por imagen sin importar la resolución, sin limitación de velocidad y facturación simplificada. Esto es un 63% más barato que el precio oficial de Gemini 3 Pro Image y ofrece la ventaja de una única API unificada que agrega múltiples modelos de IA. La compensación es que introduces una dependencia de terceros en tu infraestructura. Para aplicaciones donde la simplicidad y los precios predecibles superan la necesidad de acceso directo a la API de Google, esta puede ser una opción intermedia atractiva — más barata que NBP, sin ninguno de los problemas de limitación de velocidad que pueden afectar el uso directo de la API de Google. Si has experimentado problemas de limitación de velocidad, nuestra guía sobre manejo de límites de la API de imagen Gemini cubre tanto estrategias de prevención como patrones de recuperación.
Estrategia 5: Implementar enrutamiento híbrido de modelos basado en requisitos de calidad. Este es el enfoque más sofisticado y ofrece la mejor relación costo-calidad general. En lugar de usar un solo modelo para toda la generación de imágenes, construyes una capa de enrutamiento que envía cada solicitud al modelo más rentable según los requisitos de calidad específicos de esa solicitud. Las miniaturas e imágenes de vista previa se enrutan a Imagen 4 Fast ($0.02). Las imágenes de producción de calidad estándar se enrutan a Gemini 3.1 Flash Image ($0.067). Las imágenes premium que requieren renderizado de texto o edición conversacional se enrutan a Gemini 3 Pro Image ($0.134). Con una distribución típica de 60% baja calidad, 30% estándar y 10% premium, el costo promedio ponderado baja a aproximadamente $0.038 por imagen — una reducción del 72% respecto a la tarifa fija de NBP. Este enfoque requiere más esfuerzo de ingeniería para implementar pero se amortiza rápidamente a escala.
Los costos ocultos de los que nadie habla
Cada guía de precios que encontrarás en línea — incluyendo la que publica Google — te muestra el costo por imagen o por token y se detiene ahí. En producción, el costo real por imagen entregada exitosamente es significativamente más alto que la tarifa publicada, y comprender estos costos ocultos es crítico para una planificación presupuestaria precisa. Esta sección cubre los componentes de costo que la mayoría de las guías pasan por alto completamente, basándose en patrones de uso del mundo real reportados por desarrolladores en entornos de producción.
Las solicitudes fallidas representan el costo más comúnmente subestimado. Cuando una solicitud de generación de imágenes Gemini falla debido a filtros de seguridad de contenido (las razones de finalización IMAGE_SAFETY o PROHIBITED_CONTENT), aún se te cobra por los tokens de entrada que se procesaron antes de que se bloqueara la generación. Google no reembolsa el costo de procesamiento de entrada para solicitudes que fallan en la etapa de salida. Dependiendo del contenido de tu prompt y la sensibilidad de los filtros de seguridad del modelo, las tasas de fallo pueden variar del 2% para imágenes genéricas de productos hasta el 15% o más para prompts que involucran personas, moda o cualquier cosa que las políticas de seguridad reforzadas de marzo de 2026 puedan marcar. Con una tasa de fallo del 10%, tu costo efectivo por imagen exitosa aumenta aproximadamente un 11% — $0.02 se convierte en $0.022 para Imagen 4 Fast, y $0.134 se convierte en $0.149 para Gemini 3 Pro Image.
Los costos de infraestructura añaden otra capa que es invisible en las comparaciones de precios por imagen. Si accedes a la API a través de Google Cloud, estás pagando por los recursos de cómputo que ejecutan tu cliente API, la salida de red para descargar imágenes generadas (que a resolución 1K promedian entre 200KB y 500KB cada una), y el Cloud Storage o servicio equivalente que usas para almacenar esas imágenes. Para un pipeline que procesa 10,000 imágenes por mes, estos costos de infraestructura típicamente añaden de $5 a $20 por mes dependiendo de tu arquitectura y región. Este es un gasto fijo que es despreciable a alto volumen pero puede representar el 10% o más de tu costo total a bajo volumen.
La gestión de límites de velocidad crea costos indirectos que son fáciles de pasar por alto. Google impone límites tanto de RPM (solicitudes por minuto) como de IPM (imágenes por minuto) que varían según el modelo y el nivel de cuenta. Cuando tu aplicación alcanza un límite de velocidad, necesita reintentar (añadiendo latencia y llamadas API adicionales para backoff exponencial) o encolar solicitudes (requiriendo infraestructura para gestión de colas). El patrón de reintento es particularmente costoso porque cada intento de reintento puede consumir tokens de entrada adicionales si la solicitud fue parcialmente procesada antes de ser limitada. Construir un manejo robusto de límites de velocidad — incluyendo circuit breakers, sistemas de colas y monitoreo — requiere tiempo de ingeniería que debería considerarse en el costo total de propiedad. Para la mayoría de los equipos, el costo de ingeniería de la gestión de límites de velocidad supera los costos reales de la API durante los primeros meses de implementación.
Los costos de monitoreo y observabilidad representan otro gasto oculto más. Para mantener visibilidad de tu pipeline de generación de imágenes, necesitas logging de cada solicitud y respuesta, dashboards de métricas para rastrear tasas de éxito y latencia, y alertas para patrones de gasto anómalos. La suite de operaciones de Google Cloud (anteriormente Stackdriver) no es gratuita — Cloud Logging cobra $0.50 por GB de datos de log ingeridos después de los primeros 50 GB por mes, y Cloud Monitoring cobra por métricas personalizadas. Un pipeline que genera 10,000 imágenes por mes con logging detallado de solicitud y respuesta puede generar fácilmente de 1 a 2 GB de datos de log mensuales, añadiendo de $0.50 a $1.00 a tus costos. Esto es trivial en aislamiento pero se acumula junto con los otros costos ocultos.
La conclusión es que tu costo real por imagen en producción es típicamente del 15% al 30% más alto que el precio publicado por imagen cuando consideras fallos, infraestructura, sobrecarga de límites de velocidad y monitoreo. Para fines de planificación presupuestaria, multiplica el costo nominal por imagen por 1.2 para obtener una estimación más realista. Un proyecto presupuestado en $200 por mes usando la tarifa nominal de $0.02 por imagen (10,000 imágenes) debería presupuestar realmente $240 para cubrir estos costos ocultos. Este margen se vuelve aún más importante durante períodos de alta demanda, cuando la infraestructura de Google experimenta mayor carga y las tasas de fallo pueden dispararse temporalmente por encima de su línea base habitual.
Matriz de decisión: ¿qué modelo se ajusta a tu presupuesto y necesidades de calidad?
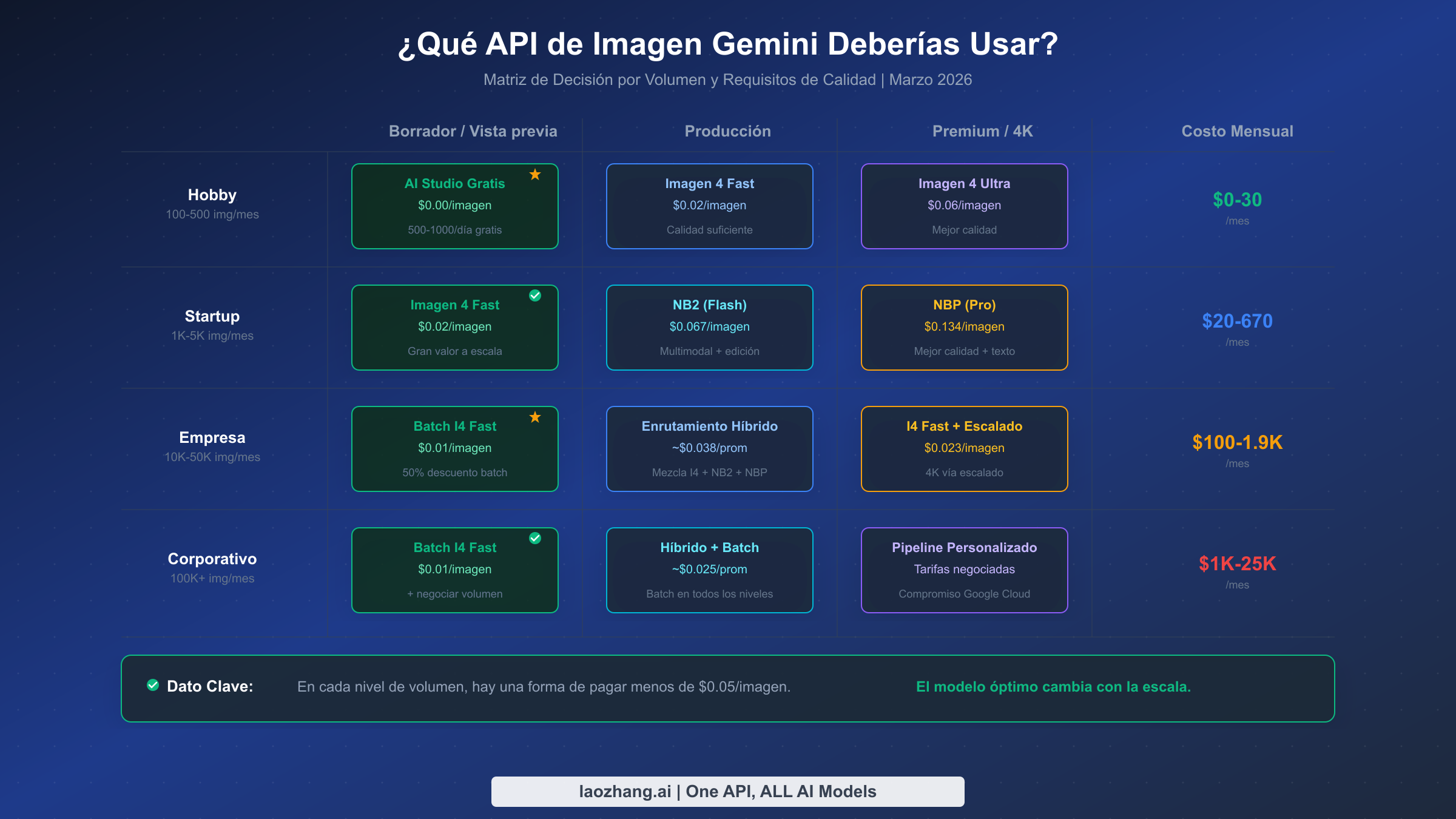
Elegir el modelo correcto no es una decisión única para todos — depende de tu volumen mensual, tus requisitos de calidad y si tu aplicación necesita procesamiento en tiempo real o asíncrono. La matriz a continuación mapea escenarios de uso comunes a sus configuraciones de modelo óptimas y costos mensuales estimados. Todas las estimaciones de costos incluyen un margen del 20% para los costos ocultos discutidos en la sección anterior.
Para proyectos personales y secundarios que generan de 100 a 500 imágenes por mes, el nivel gratuito de Google AI Studio es el punto de partida obvio. Puedes generar de 500 a 1,000 imágenes por día a costo cero a través de la interfaz web. Cuando superes el nivel gratuito o necesites acceso programático, Imagen 4 Fast a $0.02 por imagen mantiene tu factura mensual entre $2 y $10 — menos que un café. A este volumen, los costos ocultos son despreciables y no deberías complicar tu arquitectura con procesamiento por lotes o enrutamiento híbrido.
Las startups y equipos pequeños que generan de 1,000 a 5,000 imágenes por mes enfrentan la primera decisión de precios significativa. A esta escala, Imagen 4 Fast sigue siendo la opción más rentable para generación básica a $20 a $100 por mes. Si necesitas capacidades multimodales (edición de imágenes, refinamiento conversacional), Gemini 3.1 Flash Image a $0.067 por imagen ofrece el mejor equilibrio entre capacidad y costo, llevando tu factura mensual a $67 a $335. Solo recurre a Gemini 3 Pro Image ($0.134/imagen) para el subconjunto de imágenes que requieren renderizado de texto premium o la máxima fidelidad visual, y considera la estrategia de enrutamiento híbrido para mantener tu costo promedio más cerca de $0.04 por imagen.
Las aplicaciones empresariales que procesan de 10,000 a 50,000 imágenes por mes deberían invertir en procesamiento por lotes y enrutamiento híbrido. La Batch API reduce Imagen 4 Fast a $0.01 por imagen, lo que significa que 10,000 imágenes cuestan solo $100 por mes antes del margen de costos ocultos. Un enfoque híbrido que mezcle batch Imagen 4 Fast (60%), batch Gemini 3.1 Flash Image (30%) y Gemini 3 Pro Image bajo demanda (10%) promedia aproximadamente $0.025 por imagen, o de $250 a $1,250 por mes dependiendo del volumen. A esta escala, la inversión en ingeniería para construir una capa de enrutamiento basada en calidad se amortiza en uno o dos meses.
Los despliegues empresariales que superan las 100,000 imágenes por mes deberían negociar directamente con Google Cloud descuentos por compromiso de uso, que pueden reducir los precios entre un 20% y un 40% adicional más allá de la tarifa estándar. A este volumen, incluso pequeños ahorros por imagen se multiplican significativamente — una reducción de $0.005 por imagen ahorra $500 por mes con 100,000 imágenes. El precio de batch exclusivo de Imagen 4 Fast de $0.01 por imagen significa que 100,000 imágenes cuestan $1,000 por mes, haciendo que la generación de imágenes con IA sea sorprendentemente asequible incluso a escala.
Un patrón que está ganando tracción entre las empresas que operan en los niveles empresariales es mantener cuentas con múltiples proveedores simultáneamente. Al ejecutar Imagen 4 para la mayor parte de la generación, un modelo nativo Gemini para solicitudes premium y un proveedor externo como respaldo cuando los límites de velocidad o filtros de seguridad de Google bloquean solicitudes, los equipos logran tanto optimización de costos como fiabilidad. El respaldo de terceros es particularmente valioso durante interrupciones de Google Cloud o durante períodos en que los filtros de seguridad son temporalmente más agresivos de lo habitual — en lugar de fallar completamente, el sistema degrada elegantemente a un proveedor alternativo. Esta arquitectura multi-proveedor típicamente añade del 10% al 15% de complejidad en infraestructura pero puede mejorar la disponibilidad general del 99.5% al 99.9% o superior.
Ejemplos de costos mensuales reales para casos de uso comunes
Las tablas de precios abstractas son útiles para comparación, pero no te dicen cómo será tu factura mensual real. Estos tres escenarios, basados en cargas de trabajo de producción reales, ilustran cómo las estrategias anteriores se traducen en números de presupuesto concretos. Cada escenario incluye el margen de costos ocultos del 20% discutido anteriormente.
Un producto SaaS con contenido generado por usuarios típicamente necesita alrededor de 3,000 imágenes por mes — una mezcla de avatares de usuario, miniaturas de contenido e imágenes destacadas. Usando la estrategia de enrutamiento híbrido, el desglose se ve así: 1,800 miniaturas a través de batch Imagen 4 Fast a $0.01 cada una ($18), 900 imágenes de contenido a través de Gemini 3.1 Flash Image a $0.067 ($60.30), y 300 imágenes premium a través de Gemini 3 Pro Image a $0.134 ($40.20). El subtotal es $118.50, más un margen del 20% de costos ocultos lleva el presupuesto mensual realista a $142. Compara esto con el enfoque ingenuo de ejecutar todo a través de Gemini 3 Pro Image: 3,000 imágenes a $0.134 equivale a $402 más margen equivale a $482. El enfoque híbrido ahorra $340 por mes, o $4,080 por año.
Una plataforma de comercio electrónico que genera imágenes de productos podría procesar 15,000 imágenes por mes en múltiples categorías. Con la estrategia de batch más escalado: 12,000 fotos estándar de productos a través de batch Imagen 4 Fast a $0.01 ($120), luego escaladas a 4K por $0.003 cada una ($36), más 3,000 imágenes de estilo de vida a través de batch Gemini 3.1 Flash Image a $0.034 ($102). Subtotal $258, con margen $310 por mes. El mismo volumen a través de Gemini 3 Pro Image a tarifas estándar costaría $2,010 más margen equivale a $2,412. El enfoque optimizado entrega un 87% de ahorro.
Una agencia de marketing que produce activos de campaña podría generar 500 imágenes de alta calidad por mes, todas requiriendo fidelidad visual premium y renderizado de texto. En este caso, hay menos margen para optimización de costos porque la calidad es la preocupación principal. Ejecutar todo a través de Gemini 3 Pro Image a $0.134 cuesta $67 más margen equivale a $80 por mes. Esta es una situación donde el modelo premium justifica su costo — $80 por mes por 500 imágenes de calidad profesional es extraordinariamente asequible comparado con fotografía de stock a $5 a $50 por imagen o contratar un fotógrafo profesional a $500 o más por sesión. La idea clave aquí es que la optimización de costos importa más a escala; a bajo volumen con altos requisitos de calidad, el modelo premium es la opción correcta y el monto absoluto en dólares sigue siendo modesto.
Vale la pena señalar cuán dramáticamente han caído estos costos durante el último año. A principios de 2025, generar 1,000 imágenes a través de las mejores APIs disponibles costaba aproximadamente de $400 a $800 por mes. Hoy, usando Imagen 4 Fast con la Batch API, ese mismo volumen cuesta solo $10 — una reducción del 95% o más. Esta tendencia no muestra señales de desaceleración, con Google, OpenAI y competidores emergentes como Seedream 5.0 Lite de ByteDance a $0.035 por imagen, todos compitiendo agresivamente en precio. La implicación práctica para los desarrolladores es que los costos de generación de imágenes se están volviendo despreciables en relación con otros gastos de infraestructura, y el esfuerzo de optimización debería ser proporcional a tu gasto real. Si tu factura total de generación de imágenes está por debajo de $50 por mes, el tiempo invertido implementando estrategias de optimización complejas puede superar el dinero ahorrado.
Cómo empezar con la opción más barata
La forma más rápida de empezar a generar imágenes al menor costo posible es a través del modelo Imagen 4 Fast mediante la API Gemini de Google. El siguiente código Python demuestra un ejemplo funcional completo que puedes ejecutar inmediatamente después de configurar tu clave API de Google AI.
pythonimport google.generativeai as genai from PIL import Image import io genai.configure(api_key="YOUR_API_KEY") # Use Imagen 4 Fast for cheapest generation ($0.02/image) imagen = genai.ImageGenerationModel("imagen-4-fast") # Generate a single image result = imagen.generate_images( prompt="A professional product photo of a modern wireless headphone on white background", number_of_images=1, aspect_ratio="1:1", ) # Save the result for i, image in enumerate(result.images): img = Image.open(io.BytesIO(image._pil_image.tobytes())) img.save(f"output_{i}.png") print(f"Image saved: output_{i}.png")
Para la Batch API (descuento del 50%), necesitas usar la biblioteca cliente de Google Cloud en lugar del SDK de IA generativa. Las solicitudes batch se envían como archivos JSON a un bucket de Cloud Storage, se procesan de forma asíncrona y los resultados se escriben en otro bucket. La configuración requiere un proyecto de Google Cloud con facturación habilitada, pero el descuento del 50% más que compensa la complejidad adicional. Un pipeline completo de procesamiento por lotes — incluyendo manejo de errores, lógica de reintentos y recuperación de resultados — está cubierto en nuestra guía de optimización de costos de Batch API con ejemplos de código listos para producción.
Para desarrolladores que prefieren Node.js, la configuración equivalente usando el SDK JavaScript de Google AI es igualmente sencilla. La diferencia clave es que el SDK de JavaScript usa una API basada en promesas y devuelve imágenes como cadenas codificadas en base64 en lugar de objetos PIL Image, que luego puedes decodificar y escribir en disco o enviar directamente a un endpoint de carga CDN.
javascriptconst { GoogleGenerativeAI } = require("@google/generative-ai"); const fs = require("fs"); const genAI = new GoogleGenerativeAI("YOUR_API_KEY"); async function generateImage() { const model = genAI.getGenerativeModel({ model: "imagen-4-fast" }); const result = await model.generateImages({ prompt: "A professional product photo of a modern wireless headphone on white background", numberOfImages: 1, }); for (const [i, image] of result.images.entries()) { const buffer = Buffer.from(image.data, "base64"); fs.writeFileSync(`output_${i}.png`, buffer); console.log(`Image saved: output_${i}.png`); } } generateImage();
Al implementar tu pipeline de generación, hay tres detalles técnicos que te ahorrarán tiempo de depuración. Primero, siempre verifica el finish_reason en la respuesta de la API antes de intentar acceder a la imagen generada. Un finish_reason de SAFETY, IMAGE_SAFETY o PROHIBITED_CONTENT significa que no se generó imagen, e intentar acceder a los datos de la imagen lanzará una excepción en la mayoría de los SDKs. Segundo, implementa backoff exponencial para respuestas 429 (límite de velocidad) comenzando en 1 segundo con un máximo de 32 segundos — los límites de velocidad de Google usan un algoritmo de token bucket que se recarga rápidamente, por lo que la mayoría de las situaciones de limitación se resuelven en pocos segundos. Tercero, si usas el SDK Python google-genai, ten en cuenta un bug conocido donde acceder al finish_reason en una respuesta bloqueada puede hacer que el SDK se congele indefinidamente. Envuelve cualquier acceso a finish_reason en un manejador de timeout para evitar que tu pipeline se detenga.
Preguntas frecuentes
¿Existe un nivel gratuito para la generación de imágenes Gemini por API?
Google AI Studio proporciona un nivel gratuito que permite de 500 a 1,000 generaciones de imágenes por día a través de la interfaz web, con el límite exacto variando según la carga del servidor (aifreeapi.com, marzo de 2026). Sin embargo, este nivel gratuito aplica solo a la interfaz web — el acceso programático por API para generación de imágenes requiere una cuenta pagada de Google Cloud. El nivel gratuito de API que existe para modelos Gemini basados en texto no se extiende a los endpoints de generación de imágenes. Para desarrolladores que necesitan generación programática gratuita de imágenes, la única vía viable es usar el nivel gratuito dentro de los límites diarios y construir un wrapper que interactúe con la interfaz de AI Studio, aunque este enfoque es frágil y no se recomienda para uso en producción.
¿Cómo se compara la calidad de Imagen 4 con Gemini 3 Pro Image?
Imagen 4 Ultra y Gemini 3 Pro Image producen imágenes de calidad visual comparable para la mayoría de los sujetos, pero cada uno destaca en áreas diferentes. Gemini 3 Pro Image logra un 94-96% de precisión en renderizado de texto (benchmark de spectrumailab) y soporta edición de múltiples turnos, haciéndolo superior para imágenes que contienen texto legible o que requieren refinamiento iterativo. Los modelos Imagen 4 son más rápidos (2-4 segundos versus 8-12 segundos para NBP a 4K) y más rentables, pero su renderizado de texto es notablemente menos preciso. Para aplicaciones donde el contenido de la imagen no incluye texto — fotografía de productos, ilustraciones, paisajes — Imagen 4 Fast o Standard proporciona una calidad percibida equivalente a una fracción del costo.
¿Puedo usar múltiples modelos juntos en la misma aplicación?
Sí, y este es en realidad el enfoque recomendado a cualquier escala significativa. La estrategia de enrutamiento híbrido descrita en la Estrategia 5 usa múltiples modelos dentro de la misma aplicación, enrutando cada solicitud al modelo más rentable según los requisitos de calidad de esa imagen específica. Esto requiere mantener acceso API a múltiples modelos y construir una capa de enrutamiento en el código de tu aplicación, pero el esfuerzo de ingeniería es modesto — un simple if/else basado en un parámetro de calidad es suficiente para la mayoría de las implementaciones. El SDK de la API Gemini soporta todos los modelos a través del mismo mecanismo de autenticación, así que no necesitas credenciales separadas ni cuentas de facturación diferentes.
¿Qué pasa si mi solicitud es bloqueada por filtros de seguridad?
Cuando una solicitud es bloqueada por el sistema de seguridad de contenido de Google, aún se te cobra por los tokens de entrada que se procesaron antes de que se activara el bloqueo. La respuesta incluirá un finish_reason de SAFETY, IMAGE_SAFETY o PROHIBITED_CONTENT dependiendo de qué capa de filtro detectó el contenido. A marzo de 2026, Google ha reforzado estos filtros para semejanzas de celebridades, superposiciones de información financiera y contenido implícitamente sugestivo. No hay forma de eludir los filtros de Capa 2 (políticas/términos) independientemente de la configuración de seguridad. Para fotografía de moda y prendas donde los falsos positivos son comunes, usar lenguaje orientado al producto en tus prompts (describiendo la prenda en lugar de la persona que la usa) puede reducir significativamente la tasa de bloqueo.
¿Son confiables los proveedores de API de terceros para uso en producción?
Los proveedores de terceros como laozhang.ai agregan acceso a múltiples modelos de IA a través de un solo endpoint de API, ofreciendo facturación simplificada y a menudo eliminando los límites de velocidad que restringen el acceso directo a la API de Google. La fiabilidad depende del proveedor específico — servicios establecidos con SLAs de tiempo de actividad documentados y precios transparentes pueden ser adecuados para uso en producción, mientras que servicios más nuevos o sin documentar conllevan más riesgo. La compensación principal es introducir una dependencia de un tercero para una parte crítica de tu infraestructura. Para aplicaciones donde la simplicidad, precios fijos y libertad de límites de velocidad superan la necesidad de relaciones directas con el proveedor, los proveedores de terceros pueden ser una palanca efectiva de optimización de costos. Puedes probar la calidad y velocidad de generación de imágenes en images.laozhang.ai antes de comprometerte.