
Gemini ofrece cinco modelos diferentes de generación de imágenes en 2026, cada uno con distintos comportamientos de error, límites de uso y políticas de marcas de agua. Ya sea que estés recibiendo un error 429 RESOURCE_EXHAUSTED que parece idéntico para cuatro problemas completamente diferentes, tratando de entender por qué la API del nivel gratuito genera cero imágenes, o intentando descubrir por qué tus imágenes generadas tienen un logo de estrella de Gemini que tu cliente no quiere, esta guía cubre cada problema en un solo lugar. Todos los datos están verificados contra la documentación oficial de precios y límites de ai.google.dev a fecha de marzo de 2026.
Resumen rápido
- El error 429 tiene 4 causas diferentes que parecen idénticas: sin facturación habilitada (el nivel gratuito tiene 0 IPM para generación de imágenes desde diciembre de 2025), límite de ráfaga RPM, cuota diaria RPD, y el bug "429 fantasma" que afecta a cuentas recientemente actualizadas.
- Cinco modelos, tres niveles, límites muy diferentes. Imagen 4 Fast ($0.02/imagen) tiene disponibilidad en el nivel gratuito. Gemini 3.1 Flash Image ($0.067/imagen) y Gemini 3 Pro Image ($0.134/imagen) tienen 0 IPM en el nivel gratuito. El Nivel 1 comienza simplemente habilitando la facturación. El Nivel 2 requiere $250+ de gasto acumulado.
- IMAGE_SAFETY y blockReason son dos cosas diferentes. IMAGE_SAFETY bloquea la imagen de salida después de la generación. blockReason SAFETY bloquea el prompt antes de la generación (configurable). blockReason OTHER es un filtro de política no configurable que no puedes eludir.
- Dos marcas de agua, dos realidades. El logo visible de estrella de Gemini se puede eliminar con herramientas o evitar completamente usando la API. La marca de agua invisible SynthID está incrustada durante la generación de píxeles y no se puede eliminar sin destruir la imagen.
- Mejor opción gratuita: Usa Imagen 4 Fast a través de AI Studio (nivel gratuito disponible) o habilita la facturación por $0 para desbloquear el Nivel 1 para los modelos Gemini.
Todos los errores de imagen de Gemini explicados
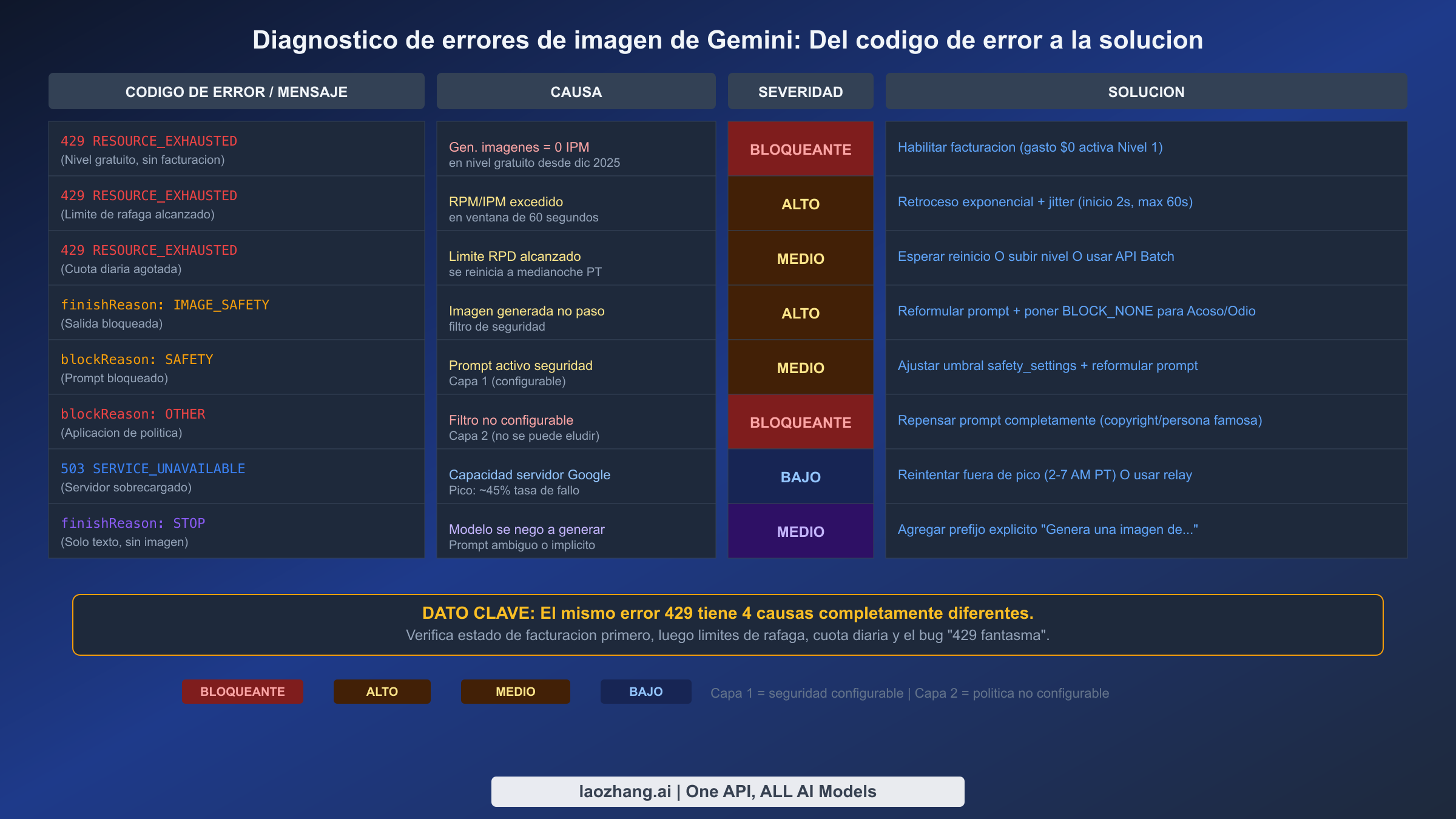
El aspecto más confuso de la generación de imágenes de Gemini es que el mismo código de error puede significar cosas completamente diferentes dependiendo de la configuración de tu cuenta. Entender la causa real detrás de cada error es la diferencia entre solucionar el problema en segundos y desperdiciar horas con la solución equivocada. Basándose en el análisis de la documentación oficial de la API de Gemini, reportes del foro de desarrolladores de Google y registros de producción de múltiples aplicaciones, aquí está lo que cada error realmente significa y cómo solucionarlo.
429 RESOURCE_EXHAUSTED: El problema de cuatro cabezas
El error 429 es, con diferencia, el error más común de generación de imágenes de Gemini, y también es el más engañoso. Google devuelve el código de estado RESOURCE_EXHAUSTED idéntico para cuatro problemas fundamentalmente diferentes, y la solución para cada uno es completamente distinta. La primera y más común causa es que tu proyecto está en el nivel gratuito, que tiene exactamente cero imágenes por minuto (0 IPM) para los modelos de imagen de Gemini desde el 7 de diciembre de 2025. Esto significa que si no has habilitado la facturación en tu proyecto de Google Cloud, cada solicitud de generación de imágenes fallará con un 429, independientemente de si has hecho cero solicitudes o mil. La solución es directa: habilita la facturación en la consola de Google Cloud, incluso si estableces un límite de gasto de $0. Simplemente tener la facturación activa te mueve al Nivel 1, que desbloquea las capacidades de generación de imágenes. Puedes aprender más sobre el panorama completo de los errores 429 de imagen de Gemini y sus soluciones en nuestra guía dedicada de resolución de problemas.
La segunda causa es un límite de ráfaga, donde has excedido el tope de solicitudes por minuto para tu nivel. El Nivel 1 permite 15 solicitudes por minuto para la mayoría de los modelos, así que enviar 16 solicitudes dentro de una ventana de 60 segundos activa este error. La solución es retroceso exponencial con jitter — comienza con un retraso de 2 segundos y duplícalo en cada reintento, hasta 60 segundos, con una variación aleatoria del 25% para prevenir tormentas de reintentos sincronizados entre múltiples clientes. La tercera causa es el agotamiento de la cuota diaria, donde has alcanzado el límite RPD (solicitudes por día). El Nivel 1 permite 1,500 RPD para los modelos Flash Image, y esto se reinicia a medianoche hora del Pacífico. Si tu aplicación genera imágenes durante todo el día sin rastrear el consumo, puedes agotar esta cuota más rápido de lo esperado, especialmente porque cada reintento también cuenta contra el límite diario.
La cuarta y más frustrante causa es el bug "429 fantasma", un problema del lado del servidor con el sistema de seguimiento de cuotas de Google que afecta principalmente a cuentas recientemente actualizadas de Gratuito a Nivel 1. Durante las primeras 24 a 48 horas después de habilitar la facturación, el sistema de aplicación de cuotas puede calcular incorrectamente tu uso, devolviendo errores 429 incluso cuando estás bien dentro de tus límites. La solución temporal, documentada en múltiples hilos del foro de desarrolladores de Google, es cambiar a una variante de modelo diferente — si estás usando gemini-3.1-flash-image-preview, prueba gemini-3-pro-image-preview o viceversa, ya que esto a menudo evita la ruta de aplicación de cuota afectada. En la mayoría de los casos, esperar de 24 a 48 horas resuelve el problema cuando se completa la propagación de cuotas.
IMAGE_SAFETY y filtros de seguridad: Capa 1 vs Capa 2
Los errores relacionados con la seguridad en la generación de imágenes de Gemini operan en un sistema de dos capas que la mayoría de los desarrolladores confunden en un solo problema. La Capa 1 consiste en configuraciones de seguridad configurables que controlas a través del parámetro safety_settings en tu solicitud API. Cuando un prompt activa un bloqueo de Capa 1, recibes un blockReason: SAFETY en la respuesta, y puedes resolverlo ajustando el umbral para categorías de daño específicas (Acoso, Discurso de Odio, Contenido Sexualmente Explícito, Contenido Peligroso) hasta BLOCK_NONE u OFF. Para los modelos Gemini 2.5 y posteriores, el umbral de seguridad predeterminado ya está configurado en OFF, lo que significa que la mayoría de los bloqueos de Capa 1 solo ocurren con configuración de seguridad explícita. Comprender los matices de blockReason OTHER y los filtros de seguridad no configurables es esencial para aplicaciones en producción.
La Capa 2, sin embargo, es una historia completamente diferente. Cuando ves blockReason: OTHER o finishReason: IMAGE_SAFETY, has alcanzado un filtro de aplicación de políticas no configurable que no se puede eludir a través de ningún parámetro de la API. La Capa 2 aplica protección de derechos de autor (generación de imágenes de personajes o logos protegidos), restricciones de personas famosas (imágenes realistas de personas reales identificables) y protecciones obligatorias de seguridad infantil. Ningún ajuste de safety_settings cambiará un bloqueo de Capa 2 — la única solución es reformular fundamentalmente tu prompt para evitar el contenido protegido. Para casos de uso legítimos que están siendo bloqueados incorrectamente, puedes reportar falsos positivos a través del Foro de Desarrolladores de Google AI, aunque los tiempos de respuesta varían significativamente.
Fallos silenciosos y respuestas solo de texto
Quizás el error más confuso no es un error en absoluto. Cuando Gemini devuelve finishReason: STOP con solo contenido de texto y sin imagen, el modelo ha decidido no generar una imagen pero no ha lanzado un error explícito. Esto típicamente sucede con prompts ambiguos que el modelo interpreta como solicitudes solo de texto, prompts que son demasiado vagos para la generación de imágenes, o prompts donde el modelo determina que no puede crear una imagen satisfactoria. La solución es agregar una instrucción explícita de generación de imagen a tu prompt — prefíjalo con "Genera una imagen de..." o "Crea una imagen fotorrealista que muestre..." para señalar tu intención claramente. Errores de nombre de modelo: Un escollo sorprendentemente común
Antes de siquiera encontrar límites de uso o filtros de seguridad, un identificador de modelo incorrecto hará que tu solicitud falle con un 404 Not Found o un error "Invalid model name". La convención de nomenclatura de Google para los modelos de generación de imágenes es inconsistente a lo largo de la documentación, y copiar y pegar nombres de modelos de tutoriales desactualizados es una de las fuentes más comunes de errores para nuevos desarrolladores. Los identificadores de modelo correctos a fecha de marzo de 2026 son: gemini-3.1-flash-image-preview para el modelo Flash Image (no gemini-flash-image ni gemini-3.1-flash-preview-image), gemini-3-pro-image-preview para el modelo Pro Image (no gemini-pro-image ni gemini-3-pro-preview-image), e imagen-4-fast, imagen-4-standard o imagen-4-ultra para la familia Imagen 4. El identificador anterior gemini-2.5-flash-image aún funciona pero redirige al modelo de generación anterior con precios y capacidades diferentes. Siempre verifica tu identificador de modelo contra la página oficial de modelos en ai.google.dev/gemini-api/docs/models antes de depurar otras causas potenciales de fallos en las solicitudes.
El error 503 SERVICE_UNAVAILABLE es más simple de diagnosticar: los servidores de Google están al máximo de capacidad. Durante las horas pico (aproximadamente de 9 AM a 5 PM hora del Pacífico), las tasas de fallo para la generación de imágenes pueden alcanzar aproximadamente el 45% según reportes de la comunidad de diciembre de 2025 a febrero de 2026. La solución es reintentar durante horas de menor actividad (2 a 7 AM hora del Pacífico) o usar un servicio de relay que mantiene su propia gestión de cola y reintentos.
Límites de uso y cuotas: Cada modelo, cada nivel
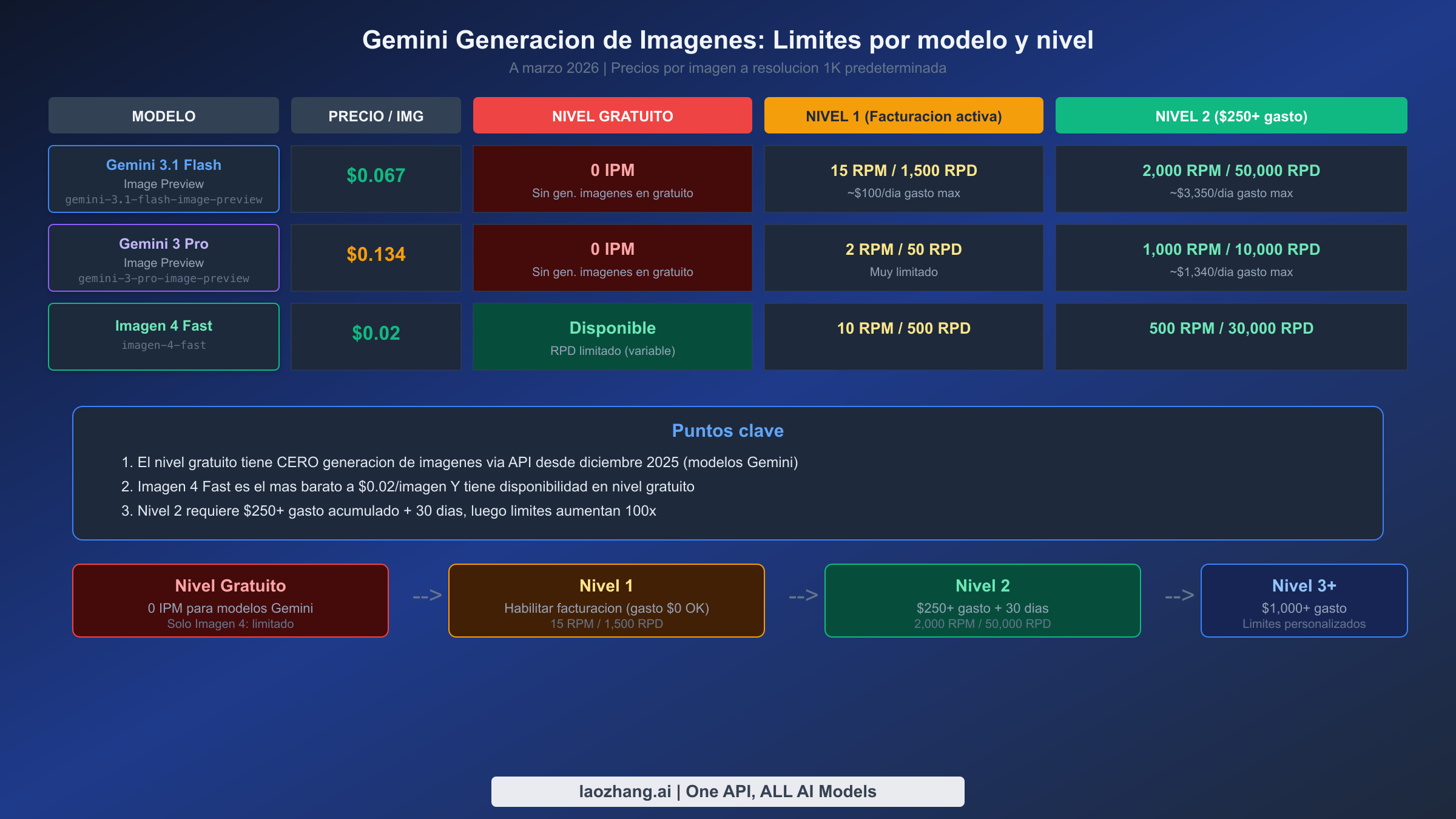
Entender el sistema de límites de uso requiere saber que Google opera tres dimensiones de cuota independientes simultáneamente: RPM (solicitudes por minuto) controla el rendimiento de ráfaga, RPD (solicitudes por día) controla el volumen diario, e IPM (imágenes por minuto) específicamente controla la salida de generación de imágenes. Alcanzar cualquiera de estos límites activa un error 429, y el mensaje de error no te dice cuál límite alcanzaste. Para una exploración más profunda de todos los niveles de la API de Gemini, consulta nuestra guía completa de límites de uso.
El nivel gratuito es la fuente de la mayor confusión. Aunque Google anuncia acceso gratuito a los modelos Gemini con límites de solicitudes generosos (hasta 500 RPD para algunos modelos), la cuota de generación de imágenes (IPM) para los modelos Gemini está establecida en cero en el nivel gratuito. Esto significa que puedes enviar prompts de texto gratis, pero cualquier solicitud que intente generar una imagen fallará con un error 429. La excepción es Imagen 4, que sí tiene disponibilidad limitada en el nivel gratuito a través de AI Studio, aunque el límite diario exacto fluctúa y Google no ha publicado números oficiales. Las pruebas de la comunidad sugieren aproximadamente 500 solicitudes de Imagen 4 por día disponibles en el nivel gratuito, pero este número varía según la región, la antigüedad de la cuenta y la hora del día. La aplicación Gemini (interfaz para consumidores en gemini.google.com) ofrece un pool separado de aproximadamente 100 generaciones de imágenes gratuitas por día, y estas son independientes de las cuotas de la API y AI Studio. Si quieres maximizar tu cuota gratuita de generación de imágenes de Gemini, nuestra guía dedicada cubre cada truco para acumular estos pools independientes.
Los recortes de cuota de diciembre de 2025 representan el cambio más dramático en el nivel gratuito de Gemini en su historia. Antes del 7 de diciembre de 2025, el nivel gratuito de la API permitía generación limitada de imágenes con los modelos Gemini. Después de esa fecha, Google estableció el IPM en exactamente cero para todos los modelos de imagen de Gemini en el nivel gratuito, mientras simultáneamente reducía los límites de solicitudes diarias de Gemini 2.5 Flash de aproximadamente 250 RPD a solo 20 — una reducción del 92%. Estos recortes parecen reflejar la estrategia de Google de mover a los usuarios serios de generación de imágenes a niveles de pago mientras mantienen acceso gratuito generoso para cargas de trabajo solo de texto.
El Nivel 1 se desbloquea cuando simplemente habilitas la facturación en tu proyecto de Google Cloud. No necesitas hacer ningún pago real — activar una cuenta de facturación con una tarjeta de crédito válida es suficiente. El Nivel 1 proporciona 15 RPM y 1,500 RPD para el modelo Flash Image, y 2 RPM y 50 RPD para el modelo Pro Image. La disparidad significativa entre estos dos modelos refleja sus diferentes casos de uso objetivo: Flash para generación de alto volumen a menor costo, Pro para generación ocasional de alta calidad. El Nivel 2 requiere $250 o más en gasto acumulado durante al menos 30 días, después de lo cual los límites aumentan dramáticamente a 2,000 RPM y 50,000 RPD para Flash, y 1,000 RPM y 10,000 RPD para Pro. La API Batch merece mención especial porque opera en un pool de cuota separado con un descuento automático del 50% en el precio de tokens, haciéndola ideal para generación masiva no sensible al tiempo.
La implicación práctica de este sistema escalonado es que el camino más económico para una generación de imágenes significativa comienza con Imagen 4 Fast a $0.02 por imagen (que tiene cierta disponibilidad en el nivel gratuito), avanza a Gemini 3.1 Flash Image a $0.067 por imagen una vez que habilitas la facturación, y solo llega a Gemini 3 Pro Image a $0.134 por imagen cuando necesitas específicamente su calidad superior para aplicaciones profesionales.
Una estrategia frecuentemente pasada por alto para maximizar las cuotas efectivas es usar múltiples métodos de acceso simultáneamente. La aplicación Gemini (interfaz para consumidores), la interfaz web de AI Studio y la API para Desarrolladores operan en pools de cuota completamente independientes. Esto significa que un desarrollador que agota su cuota diaria de API aún puede generar imágenes a través de la interfaz web de AI Studio usando la misma cuenta de Google. Aunque esto no es una estrategia de producción escalable, proporciona una válvula de escape útil durante el desarrollo y las pruebas cuando quieres conservar tu cuota de API para el tráfico de producción. Adicionalmente, diferentes modelos de imagen de Gemini tienen cuotas independientes — alcanzar el límite de uso en gemini-3.1-flash-image-preview no afecta tu cuota para gemini-3-pro-image-preview o imagen-4-fast, haciendo que la rotación de modelos sea una estrategia viable para un rendimiento sostenido cuando los límites de un solo modelo son insuficientes.
Cómo solucionar errores de imagen de Gemini
Las aplicaciones en producción necesitan manejo de errores que distinga entre las diferentes causas del 429 y responda apropiadamente a cada una. La siguiente implementación en Python demuestra un manejador de errores que cubre los modos de fallo más comunes, incluyendo retroceso exponencial con jitter para límites de uso, detección de facturación para bloqueos del nivel gratuito, y fallback de modelo para fallos persistentes.
pythonimport time import random import google.generativeai as genai def generate_image_with_retry(prompt, model_name="gemini-3.1-flash-image-preview", max_retries=5, base_delay=2.0): """Generate image with comprehensive error handling.""" fallback_models = [ "gemini-3.1-flash-image-preview", "gemini-3-pro-image-preview", "imagen-4-fast" ] for attempt in range(max_retries): try: model = genai.GenerativeModel(model_name) response = model.generate_content( f"Generate an image: {prompt}", generation_config={"response_mime_type": "image/png"} ) # Check for safety blocks if response.prompt_feedback and response.prompt_feedback.block_reason: reason = response.prompt_feedback.block_reason if str(reason) == "OTHER": raise Exception("Layer 2 policy block - rephrase prompt") else: raise Exception(f"Safety block: {reason} - adjust safety_settings") # Check for image in response for part in response.candidates[0].content.parts: if hasattr(part, 'inline_data') and part.inline_data: return part.inline_data.data # Image bytes raise Exception("No image in response - add explicit image instruction") except Exception as e: error_str = str(e) if "429" in error_str or "RESOURCE_EXHAUSTED" in error_str: delay = base_delay * (2 ** attempt) * (1 + random.random() * 0.25) delay = min(delay, 60) print(f"Rate limited (attempt {attempt+1}). Waiting {delay:.1f}s...") time.sleep(delay) elif "503" in error_str: # Server overloaded - try fallback model current_idx = fallback_models.index(model_name) if model_name in fallback_models else -1 if current_idx < len(fallback_models) - 1: model_name = fallback_models[current_idx + 1] print(f"Server overloaded. Switching to {model_name}") else: time.sleep(base_delay * (2 ** attempt)) else: raise # Non-retryable error raise Exception(f"Failed after {max_retries} retries")
Más allá de la lógica de reintentos, un detalle de implementación crítico que atrapa a muchos desarrolladores es la estructura de análisis de respuestas. A diferencia de la generación de texto donde response.text te da la salida completa en una sola cadena, las respuestas de generación de imágenes incrustan la imagen generada como inline_data dentro de un objeto Part anidado dentro de candidates[0].content.parts. Acceder a los datos de la imagen requiere iterar a través de las partes y verificar el atributo inline_data, que está completamente ausente cuando el modelo devuelve texto en lugar de una imagen. Intentar acceder a response.text en una respuesta de imagen lanzará un error, e intentar acceder a datos de imagen en una respuesta solo de texto devolverá None sin ningún mensaje de error útil. El código anterior maneja ambos casos explícitamente, lo cual es esencial para cualquier implementación en producción.
Para la configuración de ajustes de seguridad, la idea clave es que ajustar estos parámetros solo afecta a los filtros de seguridad de Capa 1 (configurables) y no tiene ningún efecto en la Capa 2 (aplicación de políticas). La siguiente configuración relaja los filtros de Capa 1 a su mínimo mientras respeta los límites de Capa 2 que no se pueden cambiar.
pythonfrom google.generativeai.types import HarmCategory, HarmBlockThreshold safety_settings = { HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_NONE, } model = genai.GenerativeModel(model_name, safety_settings=safety_settings)
Marcas de agua de Gemini: Logo visible, SynthID y eliminación
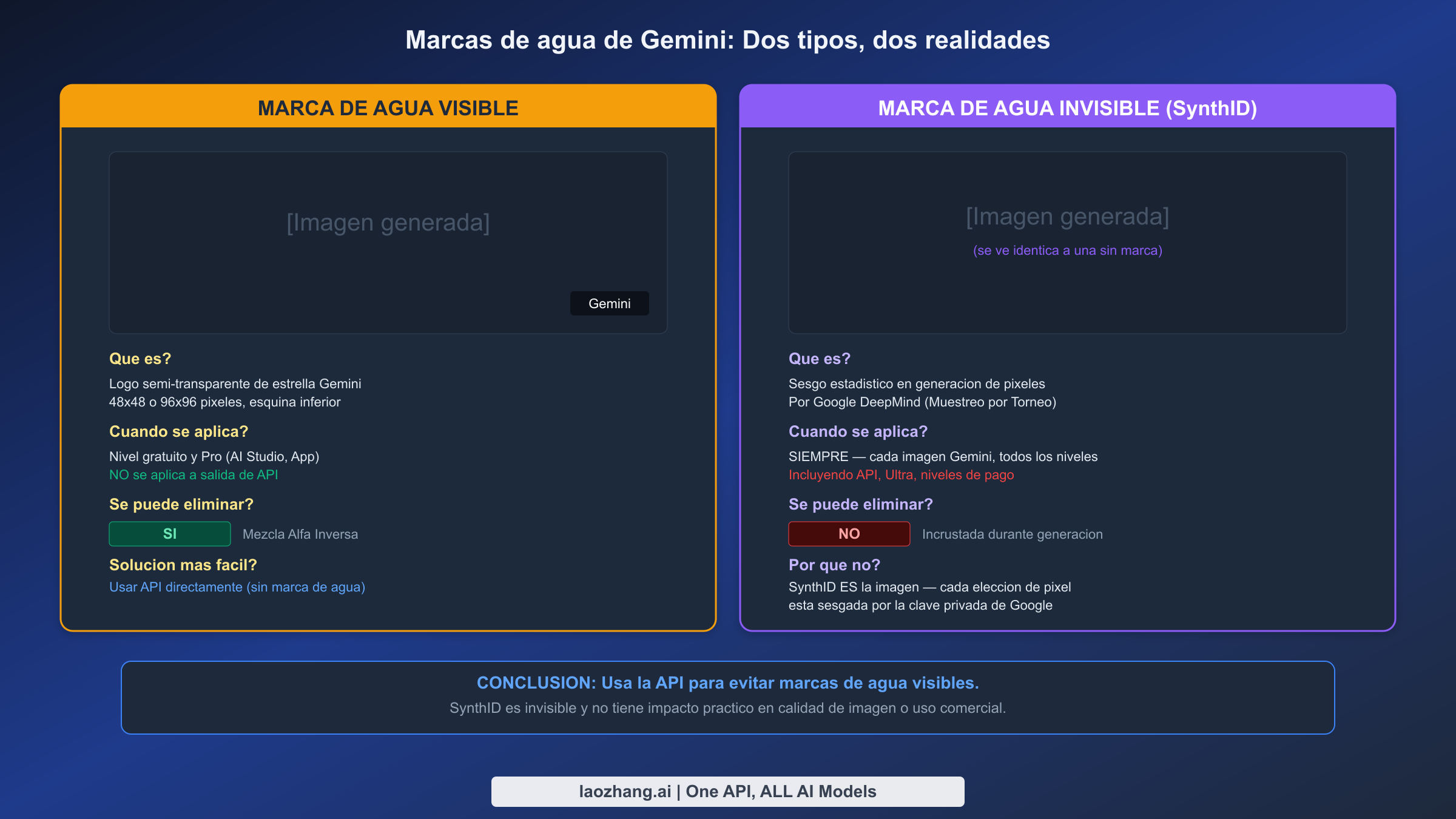
Cada imagen generada por los modelos Gemini de Google lleva dos tipos distintos de marcas de agua, y entender la diferencia fundamental entre ellas es crucial para cualquiera que use imágenes de Gemini comercialmente. La primera es una marca de agua visible — el conocido logo de estrella de Gemini que aparece en la esquina de las imágenes generadas a través de AI Studio y la aplicación Gemini. La segunda es SynthID, una marca de agua invisible desarrollada por Google DeepMind que está incrustada en cada imagen generada por Gemini sin importar cómo fue creada o qué nivel de suscripción uses.
La marca de agua visible: Fácil de manejar
La marca de agua visible de Gemini es una superposición de logo semi-transparente, típicamente de 48 por 48 o 96 por 96 píxeles, posicionada en una de las esquinas inferiores de la imagen generada. Se aplica como un paso de post-procesamiento a las imágenes generadas a través de la aplicación web Gemini y AI Studio, pero, crucialmente, no se aplica a las imágenes generadas a través de la API. Esto significa que la forma más simple de obtener imágenes limpias sin la marca de agua visible es usar la API directamente, ya sea a través de tu propia integración o a través de un servicio de relay. Para imágenes ya generadas con la marca de agua visible, varias herramientas de código abierto implementan un algoritmo de Mezcla Alfa Inversa que elimina precisamente la superposición sin afectar el contenido de la imagen subyacente. Herramientas como GeminiWatermarkTool en GitHub logran una eliminación perfecta a nivel de píxel porque la marca de agua se aplica con un patrón de transparencia alfa conocido que puede revertirse matemáticamente.
SynthID: La marca de agua que ES la imagen
SynthID es fundamentalmente diferente de una marca de agua tradicional. En lugar de ser una superposición aplicada después de la generación de la imagen, SynthID opera durante el proceso de generación mismo. El algoritmo de Muestreo por Torneo de Google DeepMind sesga sutilmente cada elección de píxel durante la creación de la imagen usando una clave criptográfica privada. El resultado es una imagen que se ve idéntica a una versión sin marca de agua pero contiene una firma estadística detectable por las herramientas de verificación de Google. Esta distinción importa porque significa que SynthID no puede "eliminarse" en ningún sentido significativo — la marca de agua no es una capa separada o un patrón añadido a la imagen, sino más bien una propiedad inherente de cómo se generó la imagen. Cada píxel en la imagen lleva una traza de la marca de agua. Algunas herramientas afirman interrumpir SynthID mediante perturbación de píxeles, pero esto típicamente degrada la calidad de la imagen sin eliminar de manera fiable la marca de agua, ya que el sesgo estadístico está distribuido por toda la imagen en lugar de estar concentrado en alguna región detectable.
Para propósitos prácticos, SynthID no tiene impacto en la calidad visual de las imágenes generadas y no afecta su usabilidad comercial. Existe principalmente como una herramienta de procedencia para la detección de contenido generado por IA, y ningún acuerdo de licencia comercial importante actualmente prohíbe el uso de imágenes que contengan marcas de agua SynthID. La preocupación sobre SynthID es en gran medida teórica más que práctica, y para la gran mayoría de casos de uso, puedes tratar las imágenes marcadas con SynthID exactamente como tratarías imágenes sin marca de agua.
Políticas de marcas de agua por método de acceso
El comportamiento de las marcas de agua varía significativamente dependiendo de cómo accedas a la generación de imágenes de Gemini, y entender estas diferencias puede ahorrarte tanto tiempo como dinero. Las imágenes generadas a través de la aplicación de consumo Gemini (gemini.google.com) siempre llevan la marca de agua visible de la estrella, sin importar si estás en una suscripción gratuita, Pro ($19.99/mes) o incluso Ultra ($249.99/mes). Las imágenes generadas a través de AI Studio también llevan la marca de agua visible. Sin embargo, las imágenes generadas a través de la API para Desarrolladores (ai.google.dev) se entregan sin ninguna marca de agua visible — la salida de la API es limpia. Esto significa que la forma más rentable de obtener imágenes sin marca de agua no es pagar una suscripción Ultra a $249.99/mes, sino más bien usar la API a $0.02 a $0.134 por imagen dependiendo del modelo y la resolución que elijas. Para desarrolladores que construyen aplicaciones, este es el enfoque estándar, y para no desarrolladores que necesitan imágenes ocasionales sin marca de agua, los servicios de relay proporcionan acceso a la API a través de interfaces más simples sin requerir ningún código.
Qué modelo de imagen de Gemini elegir
Google actualmente ofrece cinco modelos de generación de imágenes a través de sus APIs, y elegir el correcto depende de tus requisitos específicos de calidad, velocidad, costo y fiabilidad. Gemini 3 Pro Image (gemini-3-pro-image-preview) ofrece la mayor calidad de salida a $0.134 por imagen en resolución 1K, escalando hasta $0.24 en 4K. Soporta hasta 14 imágenes de entrada para tareas de edición y produce los resultados más fotorrealistas, pero sus límites de uso en el Nivel 1 son restrictivos (solo 2 RPM y 50 RPD), haciéndolo inadecuado para aplicaciones de alto volumen sin acceso al Nivel 2. Gemini 3.1 Flash Image (gemini-3.1-flash-image-preview) es el modelo de trabajo pesado a la mitad del costo ($0.067 por imagen en 1K) con límites de uso mucho más altos (15 RPM, 1,500 RPD en el Nivel 1). Genera imágenes más rápido y maneja la mayoría de los casos de uso adecuadamente, aunque la calidad es notablemente inferior a Pro para contenido fotográfico detallado.
Imagen 4 es la opción económica, disponible en tres sub-niveles: Fast ($0.02/imagen), Standard ($0.04/imagen) y Ultra ($0.06/imagen). Imagen 4 no soporta texto-a-imagen con el mismo nivel de comprensión de prompts que los modelos Gemini pero sobresale en tareas específicas como eliminación de fondo, inpainting y transferencia de estilo. Crucialmente, Imagen 4 es la única familia de modelos con cualquier disponibilidad de API en el nivel gratuito, convirtiéndola en el punto de entrada para desarrolladores que no pueden habilitar la facturación inmediatamente. Para la mayoría de los desarrolladores que construyen aplicaciones en producción, la estrategia recomendada es usar Gemini 3.1 Flash Image como modelo principal por su equilibrio de costo y calidad, recurrir a Imagen 4 Fast durante períodos de límite de uso o sobrecargas del servidor, y reservar Gemini 3 Pro Image para casos de uso premium donde la calidad justifica el precio 2x superior.
Al evaluar la fiabilidad junto con el costo, vale la pena señalar que los errores de sobrecarga del servidor (503) no se distribuyen uniformemente entre los modelos. Los reportes de la comunidad de diciembre de 2025 a febrero de 2026 indican que el modelo Pro Image tiene tasas de fallo más altas en horas pico (alrededor del 45%) comparado con Flash Image (aproximadamente 30%) e Imagen 4 (aproximadamente 15%), probablemente porque Pro Image requiere más recursos computacionales por solicitud. Para aplicaciones sensibles al tiempo, construir una cadena de fallback que comience con tu modelo preferido y degrade elegantemente a alternativas más baratas y disponibles mejora significativamente la experiencia del usuario. El ejemplo de código en la sección de manejo de errores arriba demuestra exactamente este patrón, ciclando a través de los modelos Flash, Pro e Imagen 4 en orden de calidad hasta que uno tenga éxito.
La dimensión de resolución añade otra capa al cálculo de costo-calidad. Gemini 3.1 Flash Image soporta cuatro resoluciones — 0.5K ($0.045), 1K ($0.067), 2K ($0.101) y 4K ($0.151) — mientras que Gemini 3 Pro Image soporta 1K ($0.134), 2K ($0.134, mismo costo) y 4K ($0.240). Una optimización interesante es que Pro Image cobra el mismo precio por 1K y 2K, haciendo que 2K sea la opción claramente superior para usuarios de Pro Image que no necesitan 4K. Para Flash Image, el salto de 1K a 2K añade solo $0.034 por imagen, lo cual a menudo vale la pena para aplicaciones comerciales donde la calidad de la imagen importa.
Alternativas rentables y servicios de relay de API
Cuando los límites de uso nativos de Gemini, la fiabilidad del servidor o las tasas de error se convierten en cuellos de botella para tu aplicación, los servicios de relay proporcionan una ruta de acceso alternativa que puede mitigar varios de estos problemas simultáneamente. Servicios como laozhang.ai ofrecen APIs compatibles con OpenAI que enrutan a los modelos de generación de imágenes de Gemini a través de su propia infraestructura, proporcionando beneficios como lógica de reintentos integrada a través de múltiples proyectos de Google Cloud, límites de uso efectivos más altos mediante distribución de solicitudes, fallback automático de modelo durante interrupciones, y una API unificada que funciona entre Gemini, GPT y otros proveedores. Para la generación de imágenes de Gemini específicamente, los servicios de relay a menudo cobran una tarifa fija por imagen (alrededor de $0.05 en laozhang.ai, según su documentación) independientemente de la resolución, lo cual puede ser más económico que los precios nativos basados en tokens para imágenes 2K y 4K.
La API Batch es otra ruta de optimización de costos que vale la pena considerar para cargas de trabajo no sensibles al tiempo. La API Batch de Google proporciona un descuento automático del 50% en todos los precios de tokens, reduciendo los costos de Flash Image de $0.067 a aproximadamente $0.034 por imagen en resolución 1K, e Imagen 4 Fast de $0.02 a solo $0.01 por imagen — convirtiéndola en la opción de generación de imágenes con IA más barata disponible de cualquier proveedor importante. La contrapartida es que los trabajos batch pueden tardar hasta 24 horas en completarse y tienen un límite de 100 trabajos concurrentes, así que este enfoque funciona mejor para procesamiento en segundo plano, pipelines de contenido y flujos de trabajo de generación masiva en lugar de aplicaciones interactivas.
Para equipos que necesitan generar miles de imágenes diariamente en múltiples proyectos, la arquitectura más resistente combina un servicio de relay para solicitudes interactivas en tiempo real (donde la latencia importa) con la API Batch para procesamiento en segundo plano (donde el costo importa). Este enfoque híbrido asegura que las funcionalidades orientadas al usuario siempre reciban imágenes en segundos a través de la infraestructura de reintentos del servicio de relay, mientras que las tareas de procesamiento batch como generación de catálogos, creación de contenido para redes sociales o preparación de datasets se ejecutan al menor costo posible a través de la API Batch. El costo general por imagen en una arquitectura híbrida típicamente cae entre $0.025 y $0.05, dependiendo de la proporción de tiempo real a batch, lo cual se compara favorablemente con el precio estándar de API de $0.067 para Flash Image o el precio estándar de $0.134 para Pro Image a resolución predeterminada.
FAQ
¿Por qué mi generación de imágenes de Gemini devuelve solo texto sin imagen?
Esto es un fallo silencioso donde el modelo decide no generar una imagen sin lanzar un error explícito. La causa más común es un prompt ambiguo que el modelo interpreta como una solicitud solo de texto. Para solucionarlo, siempre incluye una instrucción explícita de generación de imagen como "Genera una imagen fotorrealista de..." al comienzo de tu prompt. También verifica que estás usando un modelo con capacidad de imagen (gemini-3.1-flash-image-preview o gemini-3-pro-image-preview) y que tu solicitud incluye el parámetro response_mime_type correcto para salida de imagen. Si el modelo consistentemente se niega a generar imágenes para un prompt específico, puede estar alcanzando un filtro de seguridad de Capa 2 sin devolver un código de error explícito.
¿Puedo usar imágenes generadas por Gemini comercialmente sin eliminar la marca de agua SynthID?
Sí. SynthID es una marca de agua invisible que no tiene impacto en la calidad de la imagen o la apariencia visual. Actualmente no existe ningún requisito legal para divulgar la presencia de SynthID en imágenes usadas comercialmente, y los términos de servicio de Google para la API de Gemini te otorgan una licencia para usar imágenes generadas con fines comerciales. La marca de agua visible de la estrella de Gemini, sin embargo, debería eliminarse o evitarse (usando la API) para aplicaciones profesionales y comerciales. Siempre revisa los términos de servicio actuales de IA Generativa de Google para los derechos de uso más actualizados.
¿Cuál es la forma más barata de generar imágenes con Gemini en 2026?
La opción absolutamente más barata es Imagen 4 Fast a través de la API Batch a aproximadamente $0.01 por imagen después del descuento del 50% de batch. Para generación en tiempo real, Imagen 4 Fast a $0.02 por imagen es la más barata, seguida de Gemini 3.1 Flash Image a $0.067 por imagen. Si necesitas generación gratuita, AI Studio proporciona cuotas diarias limitadas para Imagen 4 sin costo, y la aplicación Gemini permite aproximadamente 100 generaciones de imágenes gratuitas por día a través de la interfaz de consumo, aunque estas tienen marcas de agua visibles y límites de resolución más bajos.
¿Cómo verifico en qué nivel de límite de uso está mi proyecto de Google Cloud?
Visita el panel de Google AI Studio en aistudio.google.com, navega a la configuración de tu proyecto y verifica el estado de facturación. Los proyectos del nivel gratuito muestran ninguna cuenta de facturación vinculada. Los proyectos del Nivel 1 tienen facturación habilitada pero menos de $250 de gasto acumulado. El Nivel 2 y superiores se muestran en la página de configuración de cuotas en console.cloud.google.com, bajo IAM y Administración, luego Cuotas. También puedes verificar programáticamente enviando una solicitud de prueba y examinando los encabezados de límite de uso en la respuesta.
¿Por qué obtengo un error 429 inmediatamente después de habilitar la facturación?
Esto probablemente es el bug "429 fantasma" que afecta a cuentas recientemente actualizadas de Gratuito a Nivel 1. El sistema de seguimiento de cuotas de Google puede tardar de 24 a 48 horas en propagar completamente los cambios de estado de facturación a todos los servidores. La solución temporal es cambiar a una variante de modelo diferente temporalmente o esperar a que se complete la propagación. Si el problema persiste más allá de 48 horas, verifica que tu cuenta de facturación está activa y que la tarjeta de crédito registrada no ha sido rechazada.
¿Cuál es la diferencia entre blockReason SAFETY y blockReason OTHER?
Estos representan dos sistemas de filtrado completamente diferentes. blockReason SAFETY es un filtro de Capa 1 que puedes configurar usando el parámetro safety_settings en tu solicitud API. Puedes relajar o deshabilitar estos filtros configurando los umbrales a BLOCK_NONE u OFF. blockReason OTHER es un filtro de aplicación de políticas de Capa 2 que no se puede configurar, relajar ni eludir de ninguna manera. La Capa 2 aplica protección de derechos de autor, restricciones de personas famosas y reglas de seguridad infantil. Cuando encuentras blockReason OTHER, la única solución es cambiar fundamentalmente tu prompt para evitar la categoría de contenido protegido. Intentar "engañar" al sistema con versiones reformuladas de la misma intención típicamente seguirá activando el filtro de Capa 2, ya que opera basándose en comprensión semántica en lugar de coincidencia de palabras clave.
¿Cómo manejo errores de imagen de Gemini en una aplicación en producción?
El principio más importante para el manejo de errores en producción es nunca tratar todos los errores 429 de la misma manera. Verifica tu estado de facturación primero (la causa más común de 429 persistentes es simplemente no tener la facturación habilitada). Implementa retroceso exponencial con jitter para límites de ráfaga, comenzando en 2 segundos y duplicando hasta 60 segundos. Rastrea el consumo diario para predecir cuándo alcanzarás los límites RPD. Construye una cadena de fallback de modelos (Flash a Imagen 4 a Pro) para que las interrupciones de modelos individuales no bloqueen tu aplicación. Y siempre registra la respuesta de error completa incluyendo cualquier campo finishReason y blockReason, ya que estos contienen la información diagnóstica necesaria para determinar si un error es transitorio (reintentar) o permanente (reformular prompt o cambiar enfoque).