
blockReason OTHER en Nano Banana 2 (Gemini 3.1 Flash Image, ID de modelo gemini-3.1-flash-image-preview) significa que tu solicitud fue bloqueada por el sistema de aplicación de políticas de la Capa 2 de Google, un filtro del lado del servidor no configurable que no se puede eludir configurando los umbrales de seguridad en BLOCK_NONE u OFF. A marzo de 2026, este filtro cubre 8 categorías de contenido que incluyen personajes con derechos de autor, figuras públicas y contenido NSFW. Esta guía explica el mapeo completo de blockReason vs finishReason, la arquitectura de seguridad de doble capa y proporciona 5 soluciones probadas con código listo para producción.
Resumen rápido
- blockReason OTHER ≠ blockReason SAFETY: OTHER proviene de la Capa 2 (aplicación de políticas no configurable), mientras que SAFETY proviene de la Capa 1 (ajustable mediante
harm_block_threshold). ConfigurarBLOCK_NONEuOFFsolo afecta a la Capa 1 y nunca resolverá un bloqueo de la Capa 2. - 8 categorías de contenido activan blockReason OTHER: contenido NSFW, personajes con derechos de autor/IP famosa, figuras públicas, protección de menores, eliminación de marcas de agua, modificación de información financiera, intercambio de atuendo/rostro y contenido implícitamente sugestivo. En marzo de 2026 se reforzó la aplicación en 4 de estas categorías.
- blockReason y finishReason son campos diferentes:
blockReasonaparece cuando el prompt es rechazado antes de que comience la generación (cero tokens consumidos).finishReasonaparece cuando el contenido se bloquea durante o después de la generación (tokens ya consumidos). Ambos pueden devolver valores relacionados con OTHER. - Bug del SDK python-genai: acceder a
response.candidates[0].finish_reasonen una respuesta bloqueada se cuelga indefinidamente porque el arreglo de candidatos está vacío. Siempre verificalen(response.candidates) > 0primero. - Existen 5 soluciones probadas: reformular prompts, eliminar referencias con derechos de autor, dividir prompts complejos, agregar timeout con respaldo a otro modelo, o usar modelos de imagen alternativos (GPT Image, FLUX.2) como pipeline de respaldo.
¿Qué significa realmente blockReason OTHER?

Cuando envías una solicitud de generación de imagen a Nano Banana 2 y recibes blockReason: "OTHER" en la respuesta de la API, significa que tu prompt fue interceptado por la segunda capa de filtrado de contenido de Google antes de que comenzara cualquier generación de imagen. Esto es fundamentalmente diferente de una respuesta blockReason: "SAFETY", que proviene de la primera capa de filtrado que puedes controlar a través de la configuración de seguridad. Entender esta distinción es el paso más importante para resolver el error, porque determina si puedes solucionar el problema mediante cambios de configuración o si necesitas tomar un enfoque completamente diferente.
La confusión entre blockReason y finishReason es la segunda fuente más común de frustración entre los desarrolladores que trabajan con la API de generación de imágenes de Gemini. Estos dos campos aparecen en diferentes partes de la respuesta, tienen implicaciones diferentes para la facturación y requieren estrategias de solución distintas. La tabla a continuación proporciona el mapeo completo que, hasta ahora, necesitarías leer cinco artículos separados para poder armar.
Valores de blockReason (bloqueo a nivel de prompt)
El campo blockReason aparece en la sección prompt_feedback de la respuesta de la API. Cuando está presente, significa que el prompt fue rechazado antes de que comenzara cualquier generación, por lo que no se consumieron tokens y no existe ninguna imagen parcial.
| Valor de blockReason | Capa de origen | ¿Configurable? | Significado |
|---|---|---|---|
SAFETY | Capa 1 | Sí (mediante harm_block_threshold) | Una de las 4 categorías de daño superó tu umbral configurado. Configura BLOCK_NONE u OFF para resolver. |
OTHER | Capa 2 | No | La aplicación de políticas del servidor detectó contenido prohibido en tu prompt. No se puede eludir. |
BLOCKED_REASON_UNSPECIFIED | Cualquiera | Variable | Caso general poco frecuente. Verifica tanto las calificaciones de seguridad como el contenido del prompt. |
Cuando recibes una respuesta blockReason OTHER, la estructura JSON se ve así:
json{ "promptFeedback": { "blockReason": "OTHER" }, "candidates": [] }
Observa que el arreglo candidates está completamente vacío. No hay calificaciones de seguridad para inspeccionar, no hay contenido parcial para recuperar y no hay ninguna categoría específica que te indique exactamente qué activó el bloqueo. Esto es por diseño: el filtro de la Capa 2 de Google intencionalmente no revela qué regla de política fue violada, ya que hacerlo podría ayudar a usuarios malintencionados a crear prompts que eviten la detección por poco margen.
Valores de finishReason (bloqueo a nivel de generación)
El campo finishReason aparece dentro de cada objeto candidato e indica por qué se detuvo la generación. A diferencia de blockReason, estos bloqueos ocurren durante la generación, lo que significa que los tokens ya fueron consumidos y es posible que veas texto parcial de salida (aunque nunca una imagen parcial).
| Valor de finishReason | Capa de origen | Significado |
|---|---|---|
STOP | N/A | Finalización normal. Imagen generada exitosamente. |
SAFETY | Capa 1 | El contenido generado activó un filtro de seguridad configurable. Ajustable mediante configuración. |
IMAGE_SAFETY | Capa 2 | Violación de seguridad específica de imagen detectada durante la generación. No configurable. |
OTHER | Capa 2 | Derechos de autor, marca registrada o IP famosa detectada en el contenido generado. No configurable. |
PROHIBITED_CONTENT | Capa 2 | Seguridad infantil o contenido legalmente prohibido. Aplicación más estricta, no configurable. |
La distinción crítica es el momento: blockReason se activa antes de la generación (no cuesta nada), mientras que finishReason se activa durante la generación (cuesta tokens). Si estás viendo finishReason: "OTHER" en lugar de blockReason: "OTHER", significa que tu prompt pasó el filtro inicial pero la imagen generada fue detectada por la segunda capa. Esto típicamente indica contenido con derechos de autor o marca registrada que solo se hace evidente durante la síntesis de la imagen; por ejemplo, un prompt como "un ratón de caricatura con orejas redondas" podría pasar el filtro del prompt pero activar finishReason: OTHER cuando la imagen generada se parece a un personaje con derechos de autor.
Como se confirmó en el Issue #276 de GitHub, Google ha declarado que los filtros obligatorios, incluyendo las protecciones de seguridad infantil, no pueden desactivarse, y no existe una solución programática para los bloqueos de la Capa 2. Esta es una decisión arquitectónica deliberada, no un error.
Por qué BLOCK_NONE no puede solucionar blockReason OTHER
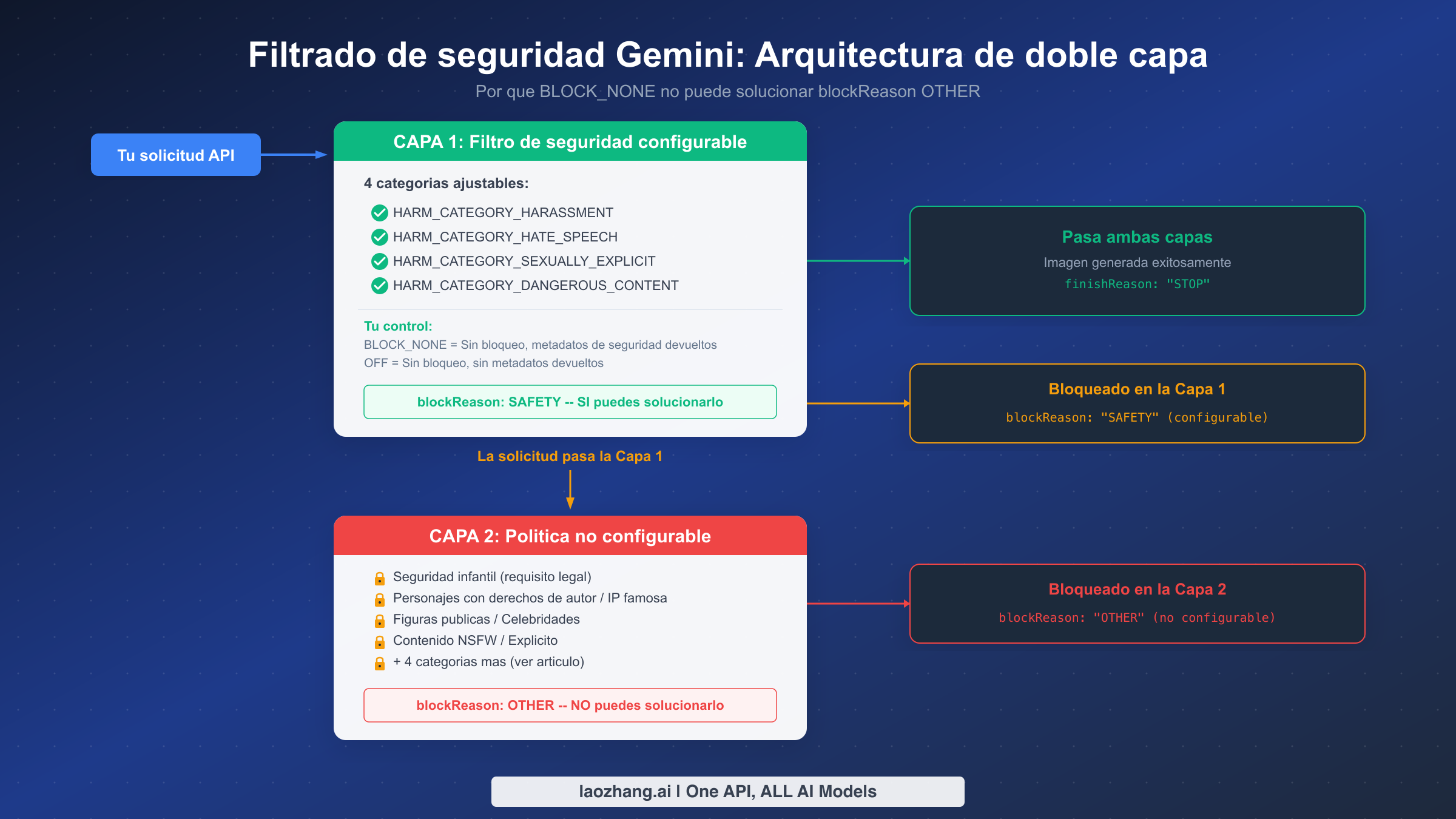
El error más común que cometen los desarrolladores al encontrar blockReason OTHER es intentar inmediatamente configurar todas las categorías de seguridad en BLOCK_NONE u OFF, esperando que esto resuelva el error. Este enfoque falla porque malinterpreta fundamentalmente cómo funciona la arquitectura de filtrado de seguridad de Gemini. El sistema opera en dos capas completamente independientes, y tu configuración de seguridad solo controla la primera. Para una comprensión más profunda de todas las configuraciones de seguridad disponibles, consulta nuestra guía detallada de configuración de seguridad de Gemini.
Capa 1: Filtro de seguridad configurable
La Capa 1 evalúa tu prompt y el contenido generado contra cuatro categorías de daño que puedes configurar individualmente: HARM_CATEGORY_HARASSMENT, HARM_CATEGORY_HATE_SPEECH, HARM_CATEGORY_SEXUALLY_EXPLICIT y HARM_CATEGORY_DANGEROUS_CONTENT. Para cada categoría, estableces un harm_block_threshold que determina qué tan sensible debe ser el filtro. Cuando un filtro de la Capa 1 se activa, recibes blockReason: "SAFETY" con calificaciones de seguridad detalladas que te indican exactamente qué categoría fue activada y con qué nivel de confianza.
Tienes dos opciones para controlar la Capa 1. Configurar el umbral en BLOCK_NONE desactiva el bloqueo automático pero aún devuelve metadatos de seguridad en la respuesta, lo cual es útil para monitoreo y registro. Configurar el umbral en OFF (disponible desde gemini-2.5-flash y modelos más recientes, según la documentación de Vertex AI a enero de 2026) desactiva tanto el bloqueo como la recopilación de metadatos por completo. Para Nano Banana 2, que está construido sobre Gemini 3.1 Flash, ambas opciones están disponibles y cualquiera de las dos elimina completamente los bloqueos de la Capa 1.
Así es como se configura la Capa 1 para que sea lo más permisiva posible:
pythonfrom google import genai from google.genai import types client = genai.Client(api_key="YOUR_API_KEY") safety_settings_block_none = [ types.SafetySetting( category="HARM_CATEGORY_HARASSMENT", threshold="BLOCK_NONE" ), types.SafetySetting( category="HARM_CATEGORY_HATE_SPEECH", threshold="BLOCK_NONE" ), types.SafetySetting( category="HARM_CATEGORY_SEXUALLY_EXPLICIT", threshold="BLOCK_NONE" ), types.SafetySetting( category="HARM_CATEGORY_DANGEROUS_CONTENT", threshold="BLOCK_NONE" ), ] # Opción 2: OFF - sin bloqueo Y sin metadatos de seguridad safety_settings_off = [ types.SafetySetting( category="HARM_CATEGORY_HARASSMENT", threshold="OFF" ), # ... lo mismo para las otras categorías ]
Capa 2: Aplicación de políticas no configurable
La Capa 2 es un sistema completamente separado que opera de manera independiente a tu configuración de seguridad. Aplica las políticas de contenido de Google, los requisitos legales y los términos de servicio a través de filtros del lado del servidor que no pueden ser accedidos, modificados o eludidos mediante ningún parámetro de la API. Cuando la Capa 2 se activa, recibes blockReason: "OTHER" sin calificaciones de seguridad, sin información de categoría y sin forma de determinar qué política específica fue violada.
La Capa 2 cubre categorías de contenido que van más allá de las preocupaciones generales de seguridad y entran en territorio de responsabilidad legal: seguridad infantil (un requisito legal en la mayoría de las jurisdicciones), personajes con derechos de autor e identidades visuales registradas, figuras públicas identificables y celebridades, contenido NSFW que viola los términos de servicio de Google, y varias otras categorías detalladas en la siguiente sección. Estos filtros existen porque Google enfrenta responsabilidad legal directa si su API de generación de imágenes produce ciertos tipos de contenido, independientemente del caso de uso que el desarrollador tenga en mente.
La implicación práctica es directa: si estás recibiendo blockReason: "OTHER", ninguna cantidad de configuración de seguridad ayudará. Ya lo has confirmado al configurar las cuatro categorías en BLOCK_NONE u OFF y seguir recibiendo el bloqueo. El bloqueo no proviene del sistema que controlas. Proviene de un sistema que está detrás de él, y el único camino hacia adelante es modificar tu prompt o usar un enfoque alternativo, que cubrimos en la sección de soluciones más adelante.
Diagrama de diagnóstico paso a paso
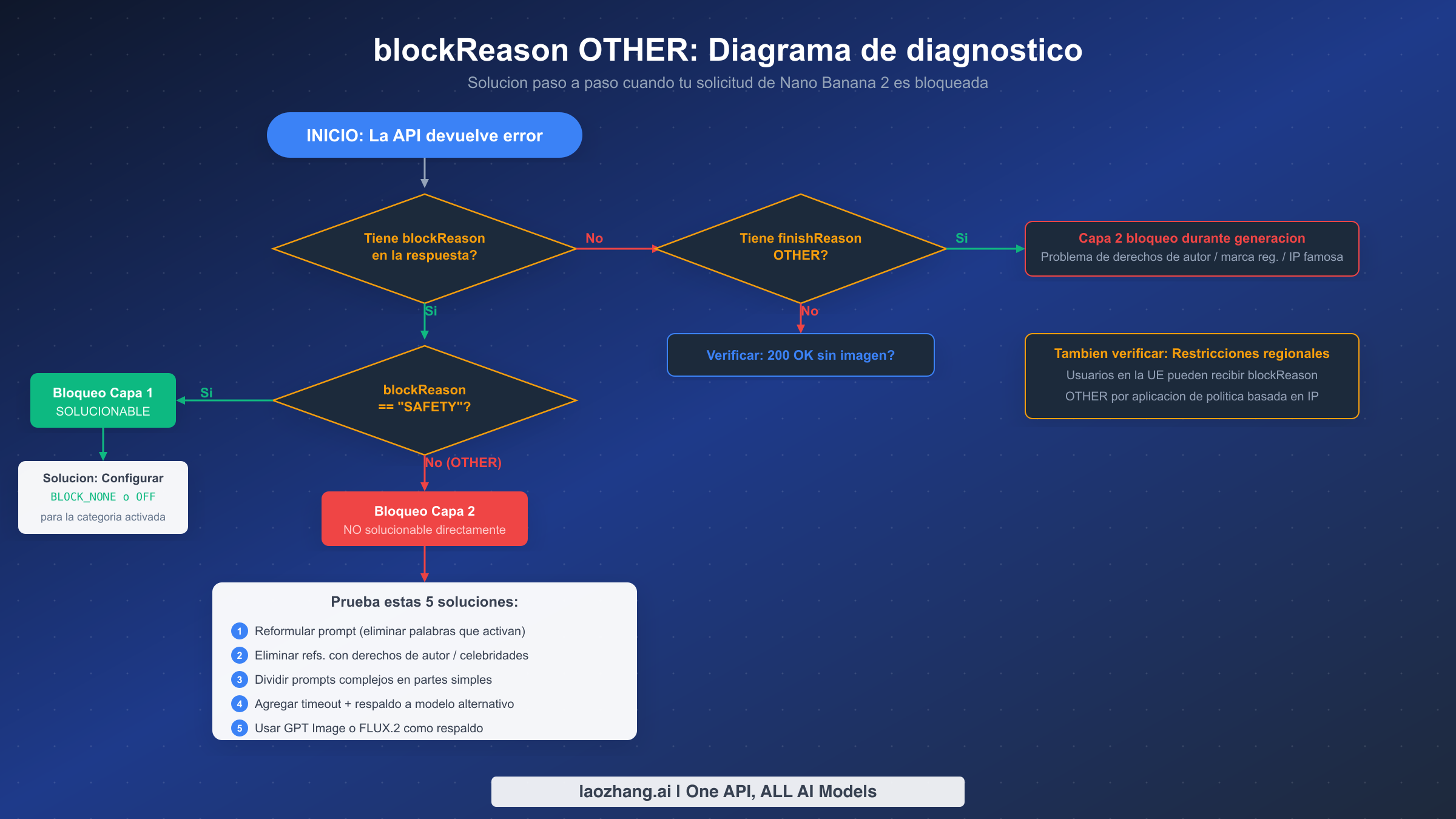
Cuando tu llamada a la API de Nano Banana 2 devuelve un error, el primer paso no es cambiar inmediatamente la configuración de seguridad, sino determinar exactamente qué tipo de error estás enfrentando. Los diferentes tipos de errores requieren soluciones completamente diferentes, y aplicar la corrección incorrecta desperdicia tiempo y cuota de API. Este diagrama de diagnóstico proporciona un enfoque sistemático que elimina las conjeturas.
Comienza verificando si tu respuesta contiene un campo blockReason en la sección prompt_feedback. Si no hay blockReason presente, el problema podría ser un tipo de error completamente diferente. Verifica si hay finishReason: "OTHER" en el arreglo de candidatos, lo que indica que el prompt pasó pero el contenido generado fue bloqueado a mitad de la generación debido a problemas de derechos de autor o marca registrada. Si no hay ni blockReason ni finishReason OTHER presente, podrías estar enfrentando un escenario de 200 OK pero sin imagen generada o un error 503 de sobrecarga, que requieren sus propias rutas de solución. Para otros errores comunes de Nano Banana 2, consulta nuestra guía sobre el error de thought signature.
Si blockReason está presente, verifica su valor. Si el valor es SAFETY, estás enfrentando un bloqueo de la Capa 1 que se puede solucionar mediante la configuración de seguridad. Inspecciona las calificaciones de seguridad en la respuesta para identificar qué categoría fue activada, luego configura el umbral de esa categoría en BLOCK_NONE u OFF. Si el valor es OTHER, has confirmado un bloqueo de la Capa 2, y las soluciones en esta guía aplican.
Aquí está el código de diagnóstico que automatiza este proceso:
pythondef diagnose_block(response): """Systematically diagnose why a Nano Banana 2 request was blocked.""" # Step 1: Check for prompt-level blocking if hasattr(response, 'prompt_feedback') and response.prompt_feedback: block_reason = getattr(response.prompt_feedback, 'block_reason', None) if block_reason == 'SAFETY': # Layer 1 block - fixable via safety settings ratings = response.prompt_feedback.safety_ratings triggered = [r for r in ratings if r.blocked] return { 'type': 'LAYER_1_BLOCK', 'fixable': True, 'categories': [r.category for r in triggered], 'action': 'Set triggered categories to BLOCK_NONE or OFF' } elif block_reason == 'OTHER': # Layer 2 block - not fixable via settings return { 'type': 'LAYER_2_BLOCK', 'fixable': False, 'action': 'Rephrase prompt or use alternative model' } # Step 2: Check for generation-level blocking if len(response.candidates) > 0: finish_reason = response.candidates[0].finish_reason if finish_reason == 'OTHER': return { 'type': 'LAYER_2_GENERATION_BLOCK', 'fixable': False, 'action': 'Copyright/trademark detected during generation' } if finish_reason == 'IMAGE_SAFETY': return { 'type': 'IMAGE_SAFETY_BLOCK', 'fixable': False, 'action': 'Image content violated safety policy' } # Step 3: No candidates and no block reason if len(response.candidates) == 0: return { 'type': 'EMPTY_RESPONSE', 'fixable': False, 'action': 'Check for 200 OK no-image scenario' } return {'type': 'UNKNOWN', 'action': 'Inspect full response JSON'}
Un detalle crítico que deben tener en cuenta los desarrolladores de Python que usan el SDK google-genai: intentar acceder a response.candidates[0].finish_reason cuando el arreglo de candidatos está vacío hará que el SDK se cuelgue indefinidamente en lugar de lanzar una excepción. Este es un bug conocido (a marzo de 2026) donde el SDK intenta evaluar de forma lazy el objeto candidato y entra en un estado de espera infinita. Siempre verifica len(response.candidates) > 0 antes de acceder a cualquier propiedad del candidato. Si encuentras este cuelgue, la única recuperación es terminar el proceso.
Consideraciones regionales
Los desarrolladores en la UE deben tener en cuenta que la aplicación de políticas basada en IP puede activar blockReason OTHER incluso para prompts que funcionan correctamente desde otras regiones. Esto se debe a que Google aplica políticas de contenido más estrictas en jurisdicciones con regulaciones más restrictivas sobre imágenes generadas por IA. Si sospechas un bloqueo regional, probar el mismo prompt desde una región geográfica diferente puede ayudar a confirmar si el bloqueo es basado en contenido o basado en región.
8 categorías de contenido que activan blockReason OTHER
Entender exactamente qué contenido activa el bloqueo de la Capa 2 te ayuda a crear prompts que eviten rechazos innecesarios. Al cruzar referencias de la documentación oficial de Google, reportes de la comunidad y pruebas sistemáticas documentadas en múltiples fuentes, hemos identificado 8 categorías de contenido distintas que activan consistentemente blockReason OTHER en Nano Banana 2. A marzo de 2026, Google ha reforzado la aplicación en 4 de estas categorías, lo que explica por qué prompts que funcionaban anteriormente ahora pueden ser bloqueados.
Contenido NSFW y sexualmente explícito es la categoría más amplia y detecta cualquier prompt que solicite desnudez, actos sexuales o contenido fetichista. A diferencia de HARM_CATEGORY_SEXUALLY_EXPLICIT de la Capa 1, que puedes configurar en BLOCK_NONE, el filtro NSFW de la Capa 2 opera de manera independiente y no puede desactivarse. Esto detecta prompts que la Capa 1 habría permitido con el umbral BLOCK_NONE, creando la situación confusa donde tu configuración de seguridad dice "permitir todo" pero la solicitud sigue siendo bloqueada.
Personajes con derechos de autor e IP famosa se activa cuando tu prompt hace referencia a personajes propiedad de grandes titulares de propiedad intelectual, como personajes animados icónicos, protagonistas de videojuegos o superhéroes de cómics. Esta es una de las categorías donde es más probable que veas finishReason: OTHER en lugar de blockReason: OTHER, porque la detección de derechos de autor frecuentemente ocurre durante la síntesis de la imagen cuando la imagen generada comienza a parecerse a un personaje protegido, incluso si el texto de tu prompt no lo nombró explícitamente.
Figuras públicas y celebridades fue reforzada significativamente en marzo de 2026. Anteriormente, los prompts que hacían referencia a figuras públicas en contextos no controversiales (como "una persona que se parece a [celebridad] dando un discurso") a veces pasaban. La actualización de política de marzo de 2026 amplió la detección para capturar referencias más indirectas e imitaciones de estilo artístico. Si tus prompts que anteriormente generaban imágenes de figuras públicas reconocibles ahora devuelven blockReason OTHER, este cambio de política es la explicación más probable.
Protección de menores es la categoría más estricta con tolerancia cero. Cualquier prompt que potencialmente pueda generar imágenes de menores en contextos inapropiados o de explotación se bloquea inmediatamente. Como se confirmó en el Issue #276 de GitHub, este es un requisito legal que Google ha declarado que nunca tendrá una solución alternativa. Este filtro tiene la tasa más alta de falsos positivos, a veces detectando prompts inocentes sobre ilustraciones infantiles o fotos familiares.
Eliminación de marcas de agua apunta a prompts que solicitan eliminar, reemplazar u oscurecer marcas de agua en imágenes de referencia. Esto aplica específicamente a flujos de trabajo de edición de imágenes donde se proporciona una imagen de referencia y el prompt instruye al modelo a eliminar marcas o avisos de derechos de autor.
Modificación de información financiera es una categoría añadida en la actualización de política de marzo de 2026. Los prompts que solicitan la generación o modificación de documentos financieros, moneda, cheques, estados de cuenta bancarios o documentos de identificación oficial ahora activan blockReason OTHER. Anteriormente se manejaba con menor prioridad y frecuentemente pasaba a través de la Capa 2.
Intercambio de atuendo y rostro tuvo un aumento de aplicación en marzo de 2026. Los prompts que solicitan intercambiar rostros entre imágenes, colocar la apariencia de una persona en un cuerpo diferente o cambiar la ropa de una persona de una manera que pueda crear imágenes engañosas ahora se detectan de manera más agresiva. Esto se superpone con la categoría de figuras públicas cuando el sujeto es reconocible.
Contenido implícitamente sugestivo es la categoría más matizada y la más difícil de predecir. Detecta prompts que no solicitan explícitamente contenido inapropiado pero usan lenguaje codificado, eufemismos o combinaciones contextuales que el modelo interpreta como sugestivas. Esta categoría fue expandida en marzo de 2026 para detectar más patrones de fraseo indirecto, razón por la cual prompts que antes parecían inofensivos ahora pueden activar bloqueos.
La conclusión práctica es que la Capa 2 opera con un análisis a nivel de contenido, no a nivel de palabras clave. Simplemente evitar ciertas palabras no es suficiente: el modelo evalúa el significado semántico y la salida visual probable de todo tu prompt. La sección de soluciones a continuación proporciona estrategias específicas para evitar el filtrado de contenido mientras logras el resultado creativo deseado.
5 soluciones probadas para resolver blockReason OTHER
Dado que blockReason OTHER no se puede resolver mediante la configuración de seguridad, las siguientes soluciones toman un enfoque diferente: modificar tu entrada, reestructurar tu flujo de trabajo o redirigir a modelos alternativos. Estas soluciones están ordenadas de la más simple a la más robusta, y en entornos de producción, probablemente querrás implementar múltiples soluciones como una estrategia de respaldo en capas.
Solución 1: Reformula tu prompt para eliminar patrones que activan el bloqueo. El enfoque más directo es identificar y eliminar los patrones de lenguaje específicos que activaron el bloqueo. Dado que la Capa 2 analiza el significado semántico y no solo las palabras clave, una reformulación efectiva va más allá de la simple sustitución de palabras. Reemplaza nombres de personajes con descripciones genéricas ("un simpático animal de caricatura" en lugar de un nombre de personaje específico), reemplaza referencias a celebridades con descripciones de atributos ("una mujer profesional con cabello oscuro corto dando una presentación" en lugar de nombrar a alguien), y descompón conceptos compuestos en prompts separados y más simples. Si una descripción de escena compleja activa un bloqueo, intenta generar los elementos individuales por separado y componerlos después.
Solución 2: Elimina todas las referencias con derechos de autor y de celebridades. Esta es una versión más agresiva de la Solución 1 que apunta específicamente a las dos categorías responsables de la mayoría de los errores blockReason OTHER. Audita tu prompt buscando cualquier referencia a personajes de marca, estilos visuales registrados, estilos artísticos reconocibles asociados con artistas específicos, nombres de celebridades o descripciones que puedan identificar a una figura pública, y cualquier logo de marca o diseño de producto. Incluso las referencias indirectas como "al estilo de [artista famoso]" pueden activar bloqueos si el estilo está estrechamente asociado con obras protegidas por derechos de autor.
Solución 3: Divide los prompts complejos en partes más simples. Los prompts complejos que combinan múltiples conceptos tienen mayor probabilidad de activar la Capa 2 porque cada concepto adicional aumenta la posibilidad de que el significado semántico combinado cruce un límite de política. Dividir un prompt complejo en 2-3 solicitudes de generación más simples y luego componer los resultados, frecuentemente tiene éxito donde el prompt combinado falla. Por ejemplo, en lugar de "una persona con un atuendo específico en un monumento específico realizando una acción específica", genera la escena y el sujeto por separado.
Solución 4: Agrega timeout y respaldo automático de modelo. Para aplicaciones en producción, el enfoque más confiable es implementar un respaldo automático a un modelo de imagen alternativo cuando Nano Banana 2 devuelve blockReason OTHER. Esto reconoce la realidad de que algunos prompts siempre serán bloqueados por la Capa 2, y asegura que tu aplicación siga siendo funcional. Algunos servicios de proxy de API como laozhang.ai agregan múltiples modelos de imagen detrás de un endpoint unificado, lo que facilita implementar respaldo entre Nano Banana 2 y modelos alternativos sin gestionar múltiples integraciones de API.
pythonimport asyncio from google import genai async def generate_with_fallback(prompt, timeout_seconds=30): """Generate image with Nano Banana 2, falling back to alternatives.""" client = genai.Client(api_key="YOUR_GEMINI_KEY") try: # Attempt Nano Banana 2 with timeout response = await asyncio.wait_for( asyncio.to_thread( client.models.generate_content, model="gemini-3.1-flash-image-preview", contents=prompt, config=types.GenerateContentConfig( response_modalities=["IMAGE", "TEXT"], ) ), timeout=timeout_seconds ) # Check for blockReason OTHER if hasattr(response, 'prompt_feedback') and response.prompt_feedback: if getattr(response.prompt_feedback, 'block_reason', None) == 'OTHER': print("Layer 2 block detected, falling back...") return await fallback_generate(prompt) # Check for empty candidates (SDK hang prevention) if not response.candidates or len(response.candidates) == 0: print("Empty candidates, falling back...") return await fallback_generate(prompt) return response except asyncio.TimeoutError: print(f"Timeout after {timeout_seconds}s, falling back...") return await fallback_generate(prompt) async def fallback_generate(prompt): """Fallback to alternative image model.""" # Example: Use GPT Image or FLUX.2 via alternative API # Implementation depends on your fallback model choice pass
Solución 5: Usa GPT Image o FLUX.2 como respaldo principal. Cuando tus requisitos de contenido entran inherentemente en conflicto con las políticas de la Capa 2 de Google, por ejemplo, si necesitas generar imágenes de figuras públicas reconocibles para propósitos de noticias o editoriales, la única solución confiable es usar un modelo de generación de imágenes diferente con políticas de contenido distintas. GPT Image (DALL-E 4o) de OpenAI tiene límites de política diferentes y puede aceptar prompts que Nano Banana 2 rechaza, y viceversa. Los modelos FLUX.2 disponibles a través de diversos proveedores ofrecen otro conjunto diferente de políticas de contenido. En producción, mantener acceso a 2-3 APIs de generación de imágenes diferentes asegura que las diferencias de política entre proveedores se conviertan en tu red de seguridad en lugar de tu cuello de botella.
Manejo de errores de nivel producción
Pasar de la depuración en desarrollo a la confiabilidad en producción requiere un manejo de errores integral que contemple todos los modos de fallo que hemos discutido. La siguiente implementación proporciona un wrapper completo de manejo de errores para Nano Banana 2 que previene el bug de cuelgue del SDK python-genai, diferencia correctamente entre bloqueos de la Capa 1 y la Capa 2, implementa reintentos automáticos con respaldo y proporciona registro estructurado para monitoreo.
pythonimport time import logging from dataclasses import dataclass from enum import Enum from typing import Optional logger = logging.getLogger(__name__) class BlockType(Enum): NONE = "none" LAYER_1_SAFETY = "layer_1_safety" LAYER_2_OTHER = "layer_2_other" LAYER_2_IMAGE_SAFETY = "layer_2_image_safety" LAYER_2_COPYRIGHT = "layer_2_copyright" LAYER_2_PROHIBITED = "layer_2_prohibited" SDK_HANG = "sdk_hang" UNKNOWN = "unknown" @dataclass class GenerationResult: success: bool block_type: BlockType image_data: Optional[bytes] = None error_message: str = "" latency_ms: int = 0 model_used: str = "" def safe_generate_image(client, prompt: str, model: str = "gemini-3.1-flash-image-preview") -> GenerationResult: """Production-safe image generation with comprehensive error handling.""" start_time = time.time() try: response = client.models.generate_content( model=model, contents=prompt, config=types.GenerateContentConfig( response_modalities=["IMAGE", "TEXT"], safety_settings=[ types.SafetySetting(category=cat, threshold="BLOCK_NONE") for cat in [ "HARM_CATEGORY_HARASSMENT", "HARM_CATEGORY_HATE_SPEECH", "HARM_CATEGORY_SEXUALLY_EXPLICIT", "HARM_CATEGORY_DANGEROUS_CONTENT", ] ], ), ) latency = int((time.time() - start_time) * 1000) # Check 1: Prompt-level blocking (blockReason) if hasattr(response, 'prompt_feedback') and response.prompt_feedback: block_reason = getattr(response.prompt_feedback, 'block_reason', None) if block_reason == 'SAFETY': logger.warning(f"Layer 1 block: {prompt[:80]}...") return GenerationResult( success=False, block_type=BlockType.LAYER_1_SAFETY, error_message="Layer 1 safety filter triggered. Adjust safety_settings.", latency_ms=latency, model_used=model, ) if block_reason == 'OTHER': logger.warning(f"Layer 2 block: {prompt[:80]}...") return GenerationResult( success=False, block_type=BlockType.LAYER_2_OTHER, error_message="Layer 2 policy block. Cannot bypass via settings.", latency_ms=latency, model_used=model, ) # Check 2: Empty candidates (prevents SDK hang) if not response.candidates or len(response.candidates) == 0: logger.warning(f"Empty candidates for: {prompt[:80]}...") return GenerationResult( success=False, block_type=BlockType.SDK_HANG, error_message="Empty candidates array. Likely silent Layer 2 block.", latency_ms=latency, model_used=model, ) # Check 3: Generation-level blocking (finishReason) candidate = response.candidates[0] finish_reason = getattr(candidate, 'finish_reason', 'STOP') finish_reason_map = { 'SAFETY': BlockType.LAYER_1_SAFETY, 'IMAGE_SAFETY': BlockType.LAYER_2_IMAGE_SAFETY, 'OTHER': BlockType.LAYER_2_COPYRIGHT, 'PROHIBITED_CONTENT': BlockType.LAYER_2_PROHIBITED, } if finish_reason in finish_reason_map: return GenerationResult( success=False, block_type=finish_reason_map[finish_reason], error_message=f"Generation blocked: finishReason={finish_reason}", latency_ms=latency, model_used=model, ) # Check 4: Extract image data for part in candidate.content.parts: if hasattr(part, 'inline_data') and part.inline_data: return GenerationResult( success=True, block_type=BlockType.NONE, image_data=part.inline_data.data, latency_ms=latency, model_used=model, ) # No image found in response return GenerationResult( success=False, block_type=BlockType.UNKNOWN, error_message="Response contained no image data.", latency_ms=latency, model_used=model, ) except Exception as e: latency = int((time.time() - start_time) * 1000) logger.error(f"Exception during generation: {e}") return GenerationResult( success=False, block_type=BlockType.UNKNOWN, error_message=str(e), latency_ms=latency, model_used=model, )
Los patrones clave de programación defensiva en esta implementación merecen ser destacados. Primero, cada acceso a response.candidates está protegido por una verificación de longitud, lo que previene el bug de cuelgue del SDK python-genai que ha sorprendido a muchos desarrolladores. Segundo, la función devuelve un objeto de resultado estructurado en lugar de lanzar excepciones, lo que la hace segura para usar en pipelines asíncronos y lógica de reintentos. Tercero, la clasificación del tipo de bloqueo permite que tu sistema de monitoreo rastree exactamente qué tipos de bloqueos están ocurriendo y con qué frecuencia, dándote los datos que necesitas para optimizar tus prompts con el tiempo.
Para despliegues en producción, plataformas como laozhang.ai proporcionan endpoints de API unificados a través de múltiples modelos de generación de imágenes, lo que simplifica la implementación de la estrategia de respaldo descrita en la Solución 4. En lugar de gestionar clientes de API separados para cada modelo de respaldo, puedes enrutar a través de un único endpoint y dejar que la plataforma maneje la selección de modelo y la recuperación de errores.
El registro en esta implementación está intencionalmente estructurado para soportar dashboards de monitoreo. Al rastrear block_type, latency_ms y model_used para cada solicitud, puedes construir alertas para picos inusuales en bloqueos de la Capa 2 (que pueden indicar un cambio de política), rastrear la efectividad de los esfuerzos de reformulación de prompts e identificar qué prompts necesitan ser redirigidos a modelos alternativos.
Preguntas frecuentes
¿Puedo desactivar completamente los filtros de seguridad en Nano Banana 2?
Puedes desactivar los filtros de seguridad de la Capa 1 configurando las cuatro categorías de daño (HARM_CATEGORY_HARASSMENT, HARM_CATEGORY_HATE_SPEECH, HARM_CATEGORY_SEXUALLY_EXPLICIT, HARM_CATEGORY_DANGEROUS_CONTENT) en BLOCK_NONE u OFF. Sin embargo, la aplicación de políticas de la Capa 2 no puede desactivarse mediante ningún parámetro de API, configuración de SDK o ajuste de cuenta. Esto significa que incluso con todos los ajustes de seguridad configurables eliminados, el contenido que viole los términos de servicio de Google, la ley de derechos de autor o los requisitos de seguridad infantil seguirá siendo bloqueado. La distinción es que la Capa 1 protege a los usuarios de resultados de IA potencialmente dañinos, mientras que la Capa 2 protege a Google de responsabilidad legal. Ambas son necesarias, pero solo la primera es configurable.
¿Cuál es la diferencia entre BLOCK_NONE y OFF?
Ambas configuraciones previenen el bloqueo automático en la Capa 1, pero difieren en el comportamiento de los metadatos. BLOCK_NONE desactiva el bloqueo pero aún devuelve calificaciones de seguridad en la respuesta, lo que te indica qué categorías fueron detectadas y con qué nivel de confianza. Esto es útil para monitoreo y auditoría. OFF desactiva tanto el bloqueo como la recopilación de metadatos por completo, lo que significa que no recibes ninguna información de seguridad en la respuesta. Para modelos a partir de gemini-2.5-flash (según la documentación de Vertex AI a enero de 2026), OFF es la configuración predeterminada. La recomendación práctica es usar BLOCK_NONE durante el desarrollo (para poder ver qué activa las calificaciones de seguridad) y OFF en producción si no necesitas los metadatos de seguridad (para respuestas marginalmente más rápidas).
¿Por qué mis prompts que antes funcionaban ahora están siendo bloqueados?
Si los prompts que funcionaban en enero o febrero de 2026 ahora devuelven blockReason OTHER, la explicación más probable es la actualización de política de Google de marzo de 2026. Esta actualización reforzó la aplicación en cuatro categorías específicas: figuras públicas y celebridades (detección más amplia de referencias indirectas), modificación de información financiera (anteriormente de menor prioridad), intercambio de atuendo y rostro (detección más agresiva) y contenido implícitamente sugestivo (reconocimiento de patrones expandido). Si tus prompts tocan alguna de estas áreas, ahora pueden activar bloqueos que antes no activaban. La solución es auditar y reformular los prompts afectados, eliminando específicamente cualquier referencia indirecta a individuos reconocibles o documentos financieros.
¿El plan gratuito de la API soporta generación de imágenes con Nano Banana 2?
El plan gratuito de Google AI Studio proporciona acceso a modelos Gemini para generación de texto, pero la generación de imágenes a través de la API requiere un plan de pago. Aunque puedes experimentar con la generación de imágenes en la interfaz web de Google AI Studio con el plan gratuito, el acceso programático a la API para generación de imágenes con Nano Banana 2 (gemini-3.1-flash-image-preview) requiere que la facturación esté habilitada en tu proyecto de Google Cloud. Esto es independiente del problema de blockReason OTHER, que puede ocurrir tanto en planes gratuitos como de pago; la distinción es que los usuarios del plan gratuito pueden no llegar al punto donde blockReason OTHER aparece porque las solicitudes de generación de imágenes son rechazadas primero a nivel de cuota.
¿Cómo puedo determinar si blockReason OTHER es causado por restricciones regionales?
Los desarrolladores en la UE pueden encontrar blockReason OTHER con más frecuencia debido a la aplicación de políticas basada en IP que aplica filtros de contenido más estrictos en ciertas jurisdicciones. Para determinar si tu bloqueo es basado en región en lugar de basado en contenido, prueba exactamente el mismo prompt desde una región geográfica diferente (usando una VPN o una función en la nube desplegada en una región diferente). Si el prompt tiene éxito desde otra región pero falla desde la tuya, el bloqueo es regional. En este caso, desplegar tus llamadas a la API desde un servidor en una región con políticas menos restrictivas (como infraestructura de nube basada en EE.UU.) es una solución legítima, siempre y cuando tu caso de uso cumpla con los términos de servicio aplicables en esa región.