Los errores de la API de imágenes de Gemini se dividen en tres categorías: límites de velocidad 429 (causados por límite de facturación cero, IPM superado, Bug Fantasma o Cuota Dinámica Compartida), fallos silenciosos de generación (endpoint incorrecto, configuración incorrecta de responseModalities o facturación no habilitada) y problemas de parámetros (imageConfig ignorado, image_size sensible a mayúsculas/minúsculas, TEXT ausente en responseModalities). Comienza verificando el panel de cuotas de tu consola de GCP, luego verifica que la facturación esté habilitada: el IPM del nivel gratuito ha sido 0 desde el 7 de diciembre de 2025. Usa el endpoint correcto /v1beta/ con responseModalities: ["TEXT", "IMAGE"].
Resumen rápido
Tres categorías de error, tres rutas de diagnóstico. Los errores 429 tienen cuatro causas raíz distintas, cada una con una solución diferente: no te limites a "esperar y reintentar" sin identificar cuál es tu caso. Los fallos silenciosos (HTTP 200 sin imagen en la respuesta) son casi siempre una configuración incorrecta de responseModalities. Los fallos de parámetros (configuración aceptada pero ignorada) suelen involucrar distinción de mayúsculas/minúsculas en image_size o que imageConfig sea eliminado por el middleware. Verifica primero la facturación, luego el endpoint, luego los parámetros, en ese orden.
Comprensión de los errores de la API de imágenes de Gemini: un mapa de diagnóstico
Cuando la generación de imágenes de Gemini falla, los desarrolladores suelen enfrentarse a uno de tres modos de fallo distintos, que requieren enfoques de diagnóstico completamente diferentes. El primero es un error explícito: tu llamada a la API devuelve HTTP 429 o HTTP 400, y la solicitud es rechazada antes de que comience ninguna generación. El segundo es un fallo silencioso en el que tu llamada tiene éxito con HTTP 200, pero la respuesta no contiene datos de imagen. El tercero es un fallo de configuración en el que las imágenes se generan correctamente, pero la salida no coincide con lo que configuraste: resolución incorrecta, relación de aspecto incorrecta o configuraciones completamente diferentes a las que especificaste.
Identificar en qué modo de fallo te encuentras es el primer paso crítico. Confundirlo lleva a los desarrolladores por el camino de diagnóstico equivocado, desperdiciando horas. La tabla a continuación mapea cada tipo de error con su estado HTTP, código de estado gRPC y el capítulo de esta guía que lo cubre.
| Tipo de error | Estado HTTP | Estado gRPC | Síntoma típico | Capítulo de solución |
|---|---|---|---|---|
| Límite de facturación = 0 | 429 | RESOURCE_EXHAUSTED | Nivel gratuito, sin imágenes | Capítulo 2 |
| Límite de velocidad IPM | 429 | RESOURCE_EXHAUSTED | Genera, luego falla | Capítulo 2 |
| Bug Fantasma 429 | 429 | RESOURCE_EXHAUSTED | Después de actualización de facturación | Capítulo 2 |
| Cuota Dinámica Compartida | 429 | RESOURCE_EXHAUSTED | Tráfico de modelo en vista previa | Capítulo 2 |
| responseModalities incorrecto | 200 | — | Array parts[] vacío | Capítulo 3 |
| Endpoint incorrecto | 404/400 | NOT_FOUND | Operación no compatible | Capítulo 3 |
| Nombre de modelo incorrecto | 400 | INVALID_ARGUMENT | Modelo no encontrado | Capítulo 3 |
| Facturación no habilitada | 400 | FAILED_PRECONDITION | Mensaje de error explícito | Capítulo 3 |
| Error de mayúsculas en image_size | 200 | — | Resolución de salida incorrecta | Capítulo 4 |
| imageConfig eliminado | 200 | — | Configuración ignorada silenciosamente | Capítulo 4 |
| Falta la modalidad TEXT | 200 | — | Respuesta vacía | Capítulo 4 |
Para los errores generales de la API de Gemini que no son específicos de imágenes, nuestra guía general de resolución de errores de la API de Gemini cubre la gama completa de errores que no son de imagen. Este artículo se centra exclusivamente en las tres categorías de error que son exclusivas de la generación de imágenes: errores que las guías generales de la API de Gemini no abordan. La API de imágenes tiene su propia dimensión de cuota (IPM: imágenes por minuto), sus propios parámetros requeridos y sus propios endpoints de modelos que no se aplican a la generación de texto.
El principio de diagnóstico más importante es este: nunca asumas que un error 429 es solo un "límite de velocidad" que hay que esperar. Cuatro causas raíz completamente diferentes producen respuestas 429 idénticas, y esperar solo es la respuesta correcta para una de ellas. Del mismo modo, nunca asumas que una respuesta HTTP 200 exitosa significa que tu imagen fue generada: el 200 puede enmascarar un error de configuración que produce una respuesta vacía.
El error 429: cuatro causas raíz, cuatro soluciones diferentes

El error 429 RESOURCE_EXHAUSTED es el error más común de la API de imágenes de Gemini, pero es engañoso porque se ve idéntico independientemente de cuál de los cuatro problemas completamente diferentes lo desencadenó. Todos los desarrolladores de imágenes de Gemini lo encuentran, y casi todos los recursos en línea lo tratan como un problema único: "superaste tu límite de velocidad." Ese enfoque lleva a tiempo desperdiciado, porque las cuatro causas raíz tienen cuatro soluciones completamente diferentes, y aplicar la solución incorrecta no ayuda.
Causa raíz 1: Límite de facturación = 0 (nivel gratuito)
La causa más común del error 429 para nuevos desarrolladores es la más simple: el nivel gratuito ha tenido una cuota por imagen (IPM) de exactamente cero desde el 7 de diciembre de 2025 (verificado en la documentación de Firebase AI Logic, 2026-03-16). Esto significa que las cuentas del nivel gratuito no pueden generar ninguna imagen a través de la API, no es un límite bajo, es cero. Cuando encuentras esto, el 429 no te dice "superaste tu límite," te dice que tu límite ya está en cero.
Para verificar si este es tu problema, navega a Consola de GCP → APIs y servicios → API de lenguaje generativo → Cuotas y límites. Filtra por "image" y observa la cuota IPM (imágenes por minuto). Si muestra 0, estás en la Causa raíz 1. La solución es habilitar la facturación en tu proyecto de Google Cloud y actualizar al menos al Nivel de pago 1. Ten en cuenta que habilitar la facturación por sí solo no siempre restaura inmediatamente tu cuota: puede haber un retraso de propagación de 15 a 30 minutos.
Causa raíz 2: Límite de velocidad IPM superado (nivel de pago)
Una vez habilitada la facturación, tienes una cuota de generación de imágenes por minuto. Según los datos verificados de nuestra guía detallada sobre el límite de velocidad 429 de imágenes de Gemini, el Nivel de pago 1 admite aproximadamente 10 IPM (imágenes por minuto), y el Nivel de pago 2 aproximadamente 20 IPM. Estas son independientes del RPM (solicitudes por minuto): los modelos de imagen tienen su propia cuota IPM distinta que se aplica específicamente a las llamadas de generación de imágenes.
La señal de diagnóstico de la Causa raíz 2 es el patrón: tu aplicación funciona bien inicialmente, luego comienza a recibir errores 429 después de generar varias imágenes en rápida sucesión. El panel de cuotas de la Consola de GCP mostrará tu uso actual acercándose o alcanzando el límite de IPM. La solución es el retroceso exponencial: comienza con un retraso de 2 segundos después del primer 429, duplicando con cada reintento (2s, 4s, 8s, 16s). Los trabajos de procesamiento por lotes deben calcular previamente el retraso necesario para mantenerse dentro de los límites de IPM en lugar de alcanzar el límite y retroceder de forma reactiva.
Causa raíz 3: Bug Fantasma 429 (febrero de 2026)
Este error afecta a las cuentas que recientemente actualizaron su nivel de facturación. El síntoma es que los errores 429 persisten incluso después de una actualización de facturación exitosa: la Consola de GCP muestra una cuota IPM diferente de cero, la facturación está habilitada, pero la generación de imágenes sigue devolviendo 429. Google confirmó esto como un problema conocido en el Foro de desarrolladores de IA en febrero de 2026. El error afecta la capa de cumplimiento de cuotas a nivel de cuenta, donde la nueva asignación de cuotas no se propaga correctamente.
La solución temporal es cambiar a una variante de modelo diferente. Si estás usando gemini-3.1-flash-image-preview, prueba cambiar a gemini-2.5-flash-image o viceversa. En muchos casos, esto omite la ruta de cumplimiento de cuotas afectada. Además, esperar 24-48 horas a menudo resuelve el problema a medida que se completa la propagación de cuotas. Si el error persiste, presentar un ticket de soporte con Google Cloud haciendo referencia explícita al problema de Bug Fantasma 429 de febrero de 2026 acelera la resolución.
Para los errores 503 de sobrecarga que pueden verse similares, consulta nuestra guía sobre cómo corregir errores 503 de sobrecarga.
Causa raíz 4: Cuota Dinámica Compartida (modelos en vista previa)
Los modelos en vista previa, gemini-3.1-flash-image-preview y gemini-3-pro-image-preview, no utilizan la asignación de cuotas por proyecto de la misma manera que los modelos de producción. En cambio, utilizan lo que Google llama Cuota Dinámica Compartida, donde la capacidad disponible se comparte entre todos los usuarios del modelo en vista previa a nivel global, y los errores 429 ocurren cuando la congestión del sistema global es alta, independientemente de tu nivel de uso individual. Google confirmó este comportamiento en un hilo de soporte del 29 de enero de 2026 en support.google.com.
Esta es la única causa raíz donde esperar genuinamente es la respuesta correcta. El 429 no es porque hayas hecho algo mal, sino porque la capacidad global del modelo en vista previa está temporalmente limitada. El retroceso exponencial con retrasos más largos (comienza en 5 segundos en lugar de 2) funciona aquí. Para aplicaciones de producción con requisitos de confiabilidad, la respuesta arquitectónica correcta es usar un modelo de producción como gemini-2.5-flash-image o usar Vertex AI con rendimiento provisionado, que te da capacidad dedicada en lugar de compartida.
Aquí hay una implementación completa de retroceso exponencial que identifica qué tipo de 429 estás viendo:
pythonimport time import google.generativeai as genai def generate_image_with_backoff(prompt: str, max_retries: int = 5) -> dict: """Generate image with exponential backoff for 429 errors.""" client = genai.GenerativeModel("gemini-3.1-flash-image-preview") for attempt in range(max_retries): try: response = client.generate_content( contents=prompt, generation_config={ "responseModalities": ["TEXT", "IMAGE"], } ) return response except Exception as e: error_str = str(e) if "429" not in error_str and "RESOURCE_EXHAUSTED" not in error_str: raise # Not a rate limit error if attempt == max_retries - 1: raise # Exhausted retries # Exponential backoff: 2s, 4s, 8s, 16s, 32s delay = 2 ** (attempt + 1) print(f"429 on attempt {attempt + 1}, waiting {delay}s...") time.sleep(delay) raise Exception("Max retries exceeded")
La generación de imágenes no devuelve nada: corrección de fallos silenciosos
Los fallos silenciosos son el tipo de error de imagen de Gemini más frustrante porque no te dan ningún comentario accionable. Tu llamada a la API devuelve HTTP 200 (éxito), la respuesta es JSON válido, pero cuando buscas los datos de imagen, el array parts está vacío o contiene solo texto. No se lanza ninguna excepción, ningún mensaje de error explica qué salió mal. Esta categoría de fallo tiene cuatro causas distintas, y cada una requiere una investigación diferente.
La causa más común: configuración incorrecta de responseModalities
El fallo silencioso más frecuente proviene de una sola palabra faltante en tu configuración. La API de imágenes de Gemini requiere que responseModalities incluya tanto "TEXT" como "IMAGE": incluir solo ["IMAGE"] resulta en una respuesta HTTP 200 exitosa con un array de partes vacío. No se lanza ningún error. La API acepta la solicitud, la procesa y devuelve nada útil sin decirte por qué.
Este requisito está documentado en los documentos oficiales de generación de imágenes de Gemini (ai.google.dev/gemini-api/docs/image-generation, verificado el 2026-03-16), pero muchos desarrolladores se encuentran con esto porque los ejemplos de fuentes no oficiales muestran ["IMAGE"] solo, o asumen que especificar la modalidad "IMAGE" es suficiente ya que eso es lo que quieren. La configuración correcta:
pythongeneration_config = { "responseModalities": ["TEXT", "IMAGE"], # Both required "imageConfig": { "image_size": "1K" # Note: uppercase K } }
¿Por qué se requiere TEXT? Los modelos de imagen de Gemini son multimodales por diseño: generan una respuesta de texto junto con la imagen (normalmente una descripción o pie de foto). La API está construida alrededor de este modelo de salida dual, y tratar de suprimir la salida de texto omitiendo TEXT de responseModalities hace que toda la respuesta falle en lugar de devolver solo la imagen. Actualmente no hay forma de obtener solo la salida de imagen sin incluir también TEXT en la lista de modalidades.
Endpoint de API incorrecto
Algunos desarrolladores integran la generación de imágenes de Gemini a través de clientes compatibles con OpenAI o usan el endpoint /v1/ en lugar de /v1beta/. La API de generación de imágenes de Gemini requiere la ruta de endpoint /v1beta/. Las solicitudes al endpoint compatible con OpenAI (/v1/images/generations) o a la ruta estable /v1/ devuelven errores 404 o mensajes explícitos de "operación no compatible."
La estructura correcta del endpoint es:
POST https://generativelanguage.googleapis.com/v1beta/models/{model-name}:generateContent
Si estás usando una biblioteca compatible con OpenAI con Gemini, asegúrate de haber configurado correctamente la URL base. Muchos desarrolladores que usan la biblioteca Python openai con Gemini cambian la base_url para apuntar a los servidores de Gemini, pero si apuntan a la ruta /v1/, los modelos de imagen no serán accesibles.
Nombre de modelo incorrecto
Los tres modelos de imagen de Gemini actuales tienen nombres específicos que deben usarse exactamente como se documentan. En el momento de escribir esto (verificado en ai.google.dev, 2026-03-16), los nombres de modelo actuales son:
gemini-3.1-flash-image-preview— Generación rápida, modelo en vista previagemini-3-pro-image-preview— Alta calidad, modelo en vista previagemini-2.5-flash-image— Modelo estable y eficiente
Los errores comunes incluyen usar gemini-2.5-flash-preview-image (orden de sufijo incorrecto), gemini-flash-image (versión faltante) o nombres de modelos más antiguos que han sido obsoletos. Los errores de nombre de modelo suelen devolver un 400 INVALID_ARGUMENT o 404 NOT_FOUND: generalmente no producen la respuesta silenciosa 200. Pero causan un fallo de generación con una firma de error diferente a los límites de velocidad.
Facturación no habilitada: el error 400 que podrías confundir con un error de configuración
Cuando la facturación no está habilitada y estás más allá del límite de cuota cero del nivel gratuito, podrías esperar un error claro. La API de imágenes de Gemini en realidad devuelve HTTP 400 con el estado gRPC FAILED_PRECONDITION y un mensaje que incluye "billing." Esto es distinto del 429 que obtendrías si la facturación estuviera habilitada pero la cuota agotada. El estado FAILED_PRECONDITION significa que una condición previa para la operación no se ha cumplido: en este caso, la condición previa es que la facturación debe estar habilitada para usar la API de generación de imágenes en absoluto.
Si ves FAILED_PRECONDITION en tu respuesta de error, la solución siempre es habilitar la facturación en la Consola de GCP, no ajustar tus parámetros de API. Este error no se resolverá cambiando tu responseModalities o imageConfig.
Parámetros que fallan silenciosamente: imageConfig y responseModalities
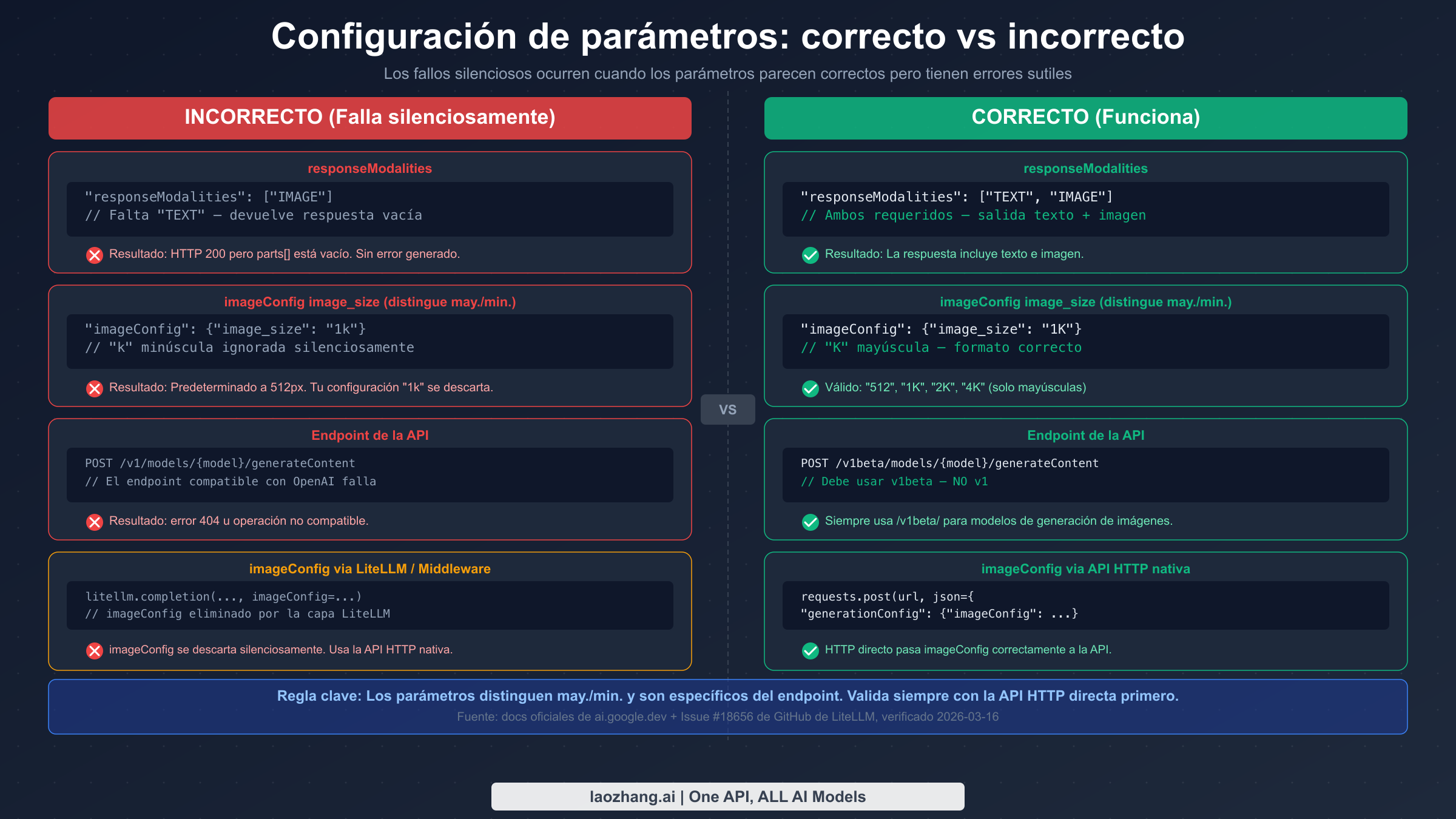
Los fallos de parámetros son una categoría especial de frustración con la API de imágenes de Gemini porque la API acepta tu solicitud sin quejarse, genera una imagen y la devuelve, pero la imagen no coincide con tus especificaciones. Pediste resolución 2K y obtuviste 512px. Configuraste una relación de aspecto y obtuviste 1:1. Configuraste imageConfig y no tuvo ningún efecto. La API no rechazó tus parámetros; simplemente los ignoró.
La trampa de distinción de mayúsculas/minúsculas en image_size
El parámetro image_size dentro de imageConfig distingue mayúsculas/minúsculas de una manera no obvia. Los valores válidos usan "K" mayúscula: "512", "1K", "2K", "4K". Usar "1k" en minúscula no produce un error; silenciosamente vuelve a la resolución predeterminada (512px). Esto significa que puedes escribir código que parece correcto, probarlo y nunca darte cuenta de que tu configuración de resolución está siendo ignorada.
Este problema específico fue verificado en la documentación oficial de la API de Gemini (ai.google.dev, 2026-03-16). La trampa es particularmente insidiosa para los desarrolladores que provienen de lenguajes o APIs con convenciones de minúsculas donde los valores de cadena no distinguen mayúsculas/minúsculas. No hay advertencia en la respuesta de que tu "1k" era inválido: la imagen simplemente sale más pequeña de lo esperado.
La lista completa de valores válidos de image_size es: "512", "1K", "2K", "4K". El parámetro de relación de aspecto (aspect_ratio) acepta "1:1", "3:4", "4:3", "9:16", "16:9": estos no distinguen mayúsculas/minúsculas y usan notación de dos puntos.
Por qué responseModalities debe incluir TEXT
Como se mencionó en la sección de fallos silenciosos, responseModalities debe incluir tanto "TEXT" como "IMAGE". Pero hay un matiz adicional relacionado con el orden de los parámetros. El array responseModalities debe enumerar "TEXT" primero y "IMAGE" segundo: aunque la API actualmente acepta cualquier orden, el orden documentado es ["TEXT", "IMAGE"], y desviarse de esto puede causar problemas en versiones futuras de la API. Es algo menor, pero el código de producción debe seguir la convención documentada.
python"responseModalities": ["TEXT", "IMAGE"] # Accepted but not recommended "responseModalities": ["IMAGE", "TEXT"] # WRONG - silently returns empty response "responseModalities": ["IMAGE"] # WRONG - no images even requested "responseModalities": ["TEXT"]
imageConfig eliminado por el middleware
Este es el modo de fallo de parámetros más sutil. Cuando se usan capas de middleware como LiteLLM para proxy de llamadas a la API de Gemini, el parámetro imageConfig a menudo se elimina de la solicitud antes de que llegue a la API de Gemini. El problema #18656 de GitHub de LiteLLM documenta este comportamiento: LiteLLM normaliza los parámetros a su formato interno, y imageConfig no sobrevive a esta normalización.
El síntoma: tus imágenes se generan, pero la configuración de resolución y relación de aspecto no tiene efecto. La solución es omitir el middleware para la generación de imágenes de Gemini y usar la API HTTP nativa directamente. Si debes usar LiteLLM o herramientas similares para tu infraestructura, necesitarás enrutar las solicitudes de generación de imágenes directamente mientras enrutas la generación de texto a través del middleware.
Así es como llamar a la API directamente, omitiendo cualquier middleware:
pythonimport requests import base64 def generate_image_direct(prompt: str, api_key: str, size: str = "1K") -> bytes: """Direct HTTP call to Gemini Image API — bypasses middleware.""" url = "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent" headers = {"Content-Type": "application/json"} params = {"key": api_key} payload = { "contents": [{"parts": [{"text": prompt}]}], "generationConfig": { "responseModalities": ["TEXT", "IMAGE"], "imageConfig": { "image_size": size, # Must be "512", "1K", "2K", or "4K" "aspect_ratio": "16:9" # Optional } } } response = requests.post(url, json=payload, headers=headers, params=params) response.raise_for_status() data = response.json() for part in data["candidates"][0]["content"]["parts"]: if "inlineData" in part: return base64.b64decode(part["inlineData"]["data"]) raise ValueError("No image data in response — check responseModalities config")
Ten en cuenta que generationConfig envuelve imageConfig en el payload HTTP directo. Algunas versiones de SDK usan un dict generation_config plano, pero la API REST nativa usa la estructura anidada que se muestra arriba. Esta es otra fuente de confusión de parámetros: la interfaz del SDK no siempre coincide con la estructura de solicitud HTTP subyacente.
Verificación de tu cuota: guía de diagnóstico de la Consola de GCP
Comprender tu situación de cuota es esencial para diagnosticar errores 429, pero muchos desarrolladores no saben dónde encontrar información precisa sobre la cuota o qué significan los números. La Consola de GCP tiene los datos autoritativos, pero navegar hasta ellos no es obvio.
Cómo encontrar tu cuota de generación de imágenes
La ruta de navegación exacta en la Consola de GCP (verificada el 2026-03-16):
- Ve a console.cloud.google.com
- Selecciona tu proyecto en el menú desplegable en la parte superior
- Navega a APIs y servicios → API de lenguaje generativo
- Haz clic en Cuotas y límites del sistema en la barra lateral izquierda
- En la barra de filtro, escribe "image" para filtrar las cuotas específicas de imagen
La vista de cuota muestra múltiples dimensiones. Para la generación de imágenes, la crítica es IPM (imágenes por minuto): esta es la dimensión contra la que se limita la generación de imágenes de Gemini. No la confundas con RPM (solicitudes por minuto), que rige las llamadas de generación de texto y no es la restricción vinculante para las llamadas de API de imagen.
Comprensión de las dimensiones de cuota
Los modelos de imagen de Gemini tienen tres dimensiones de cuota:
| Dimensión | Qué limita | Alcance típico |
|---|---|---|
| RPM (solicitudes por minuto) | Llamadas a API por minuto | Compartida con modelos de texto |
| RPD (solicitudes por día) | Llamadas a API por día | Modelos en vista previa: 1.500/día |
| IPM (imágenes por minuto) | Imágenes generadas por minuto | Específico de imagen; más crítico |
A partir del 7 de diciembre de 2025, el IPM del nivel gratuito es 0, lo que significa que las cuentas gratuitas no pueden generar ninguna imagen a través de la API. Este fue un cambio respecto al nivel gratuito anterior que permitía una generación de imágenes limitada. Si actualizaste antes de esta fecha y tienes una cuota heredada, la Consola de GCP mostrará tu asignación actual. Si creaste una cuenta o habilitaste la API por primera vez después del 7 de diciembre de 2025, tu IPM será 0 hasta que habilites la facturación.
Para las cuentas del Nivel de pago 1 (facturación habilitada, por debajo de los umbrales del Nivel 2), los datos verificados de nuestro análisis SERP (wentuo.ai, documentos de Firebase, 2026-03-16) muestran aproximadamente 10 IPM. El Nivel de pago 2 (mayor volumen de uso) proporciona aproximadamente 20 IPM. Vertex AI con Rendimiento provisionado da una cuota dedicada negociada con Google, eliminando las restricciones de grupo compartido.
Interpretación del panel de cuotas
El panel de cuotas muestra el uso actual como porcentaje del límite. Una lectura de "100%" significa que has alcanzado el límite para esa ventana de tiempo. Importante: los restablecimientos de cuota son ventanas móviles, no minutos de reloj fijos. Tu cuota IPM se calcula sobre una ventana móvil de 60 segundos, por lo que si generaste 10 imágenes a las 12:00:00 y estás en el Nivel de pago 1 (límite de 10 IPM), no podrás generar más hasta las 12:01:00.
Si ves la cuota al 0% pero sigues recibiendo errores 429, esa es una señal de diagnóstico fuerte del Bug Fantasma 429 (Causa raíz 3 del Capítulo 2) o un problema de propagación de cuota después de un cambio de facturación reciente. En ese caso, espera 15-30 minutos para que los cambios de cuota se propaguen y, si el problema persiste durante más de unas pocas horas, revisa la guía del Bug Fantasma 429 en el Capítulo 2.
Elección del nivel correcto para la generación de imágenes de Gemini
El nivel que uses tiene implicaciones importantes tanto para el costo como para la confiabilidad, especialmente para las aplicaciones de producción. Comprender las compensaciones te ayuda a tomar la decisión de infraestructura correcta en lugar de descubrir las limitaciones bajo carga de producción.
| Nivel | IPM | RPM | RPD | Mejor para |
|---|---|---|---|---|
| Gratuito | 0 | 10 | 1.500 | Solo aprendizaje (sin imágenes) |
| Nivel de pago 1 | ~10 | 10 | 1.500 | Uso de producción ligero |
| Nivel de pago 2 | ~20 | 20+ | 3.000+ | Producción moderada |
| Vertex AI | Negociado | Negociado | Negociado | Producción de alto volumen |
Modelos en vista previa vs. modelos de producción
Los modelos gemini-3.1-flash-image-preview y gemini-3-pro-image-preview son modelos en vista previa: se ejecutan en Cuota Dinámica Compartida y no ofrecen las mismas garantías de confiabilidad que los modelos de producción. Para las capacidades de generación de imágenes de Gemini, solo gemini-2.5-flash-image es un modelo estable (no en vista previa) en el momento de escribir esto.
Para los casos de uso de producción, esto importa de dos maneras. Primero, los errores 429 de modelos en vista previa pueden ocurrir incluso cuando estás dentro de tu cuota personal, ya que reflejan la congestión global, no tu uso. Segundo, los modelos en vista previa pueden ser obsoletos o tener su comportamiento cambiado sin el aviso completo de obsolescencia que reciben los modelos de producción. Si estás construyendo algo que necesita ejecutarse de manera confiable durante meses, el modelo estable es una mejor base incluso si tiene capacidades ligeramente diferentes. Para un desglose completo de lo que ofrecen los modelos en vista previa, consulta nuestra guía sobre capacidades del modelo Gemini 3.1 Flash Image Preview.
Cuándo considerar proveedores de API alternativos
Si necesitas un mayor rendimiento del que proporcionan los niveles de AI Studio pero no estás listo para configurar una integración completa de Vertex AI, los agregadores de API de terceros como laozhang.ai ofrecen modelos de imagen de Gemini con diferentes estructuras de límite de velocidad. Estos pueden ser útiles para el desarrollo, las pruebas o para complementar tu acceso principal a la API durante el uso máximo. El enfoque de agregador agrega un salto de red y no debería ser tu infraestructura de producción principal para aplicaciones críticas, pero puede servir como una alternativa útil cuando tu cuota principal está agotada.
Para la generación de imágenes a escala de producción, Vertex AI con Rendimiento provisionado es la solución correcta a largo plazo: negocias capacidad dedicada en lugar de competir con otros usuarios en cuotas de grupos compartidos.
Código de manejo de errores listo para producción
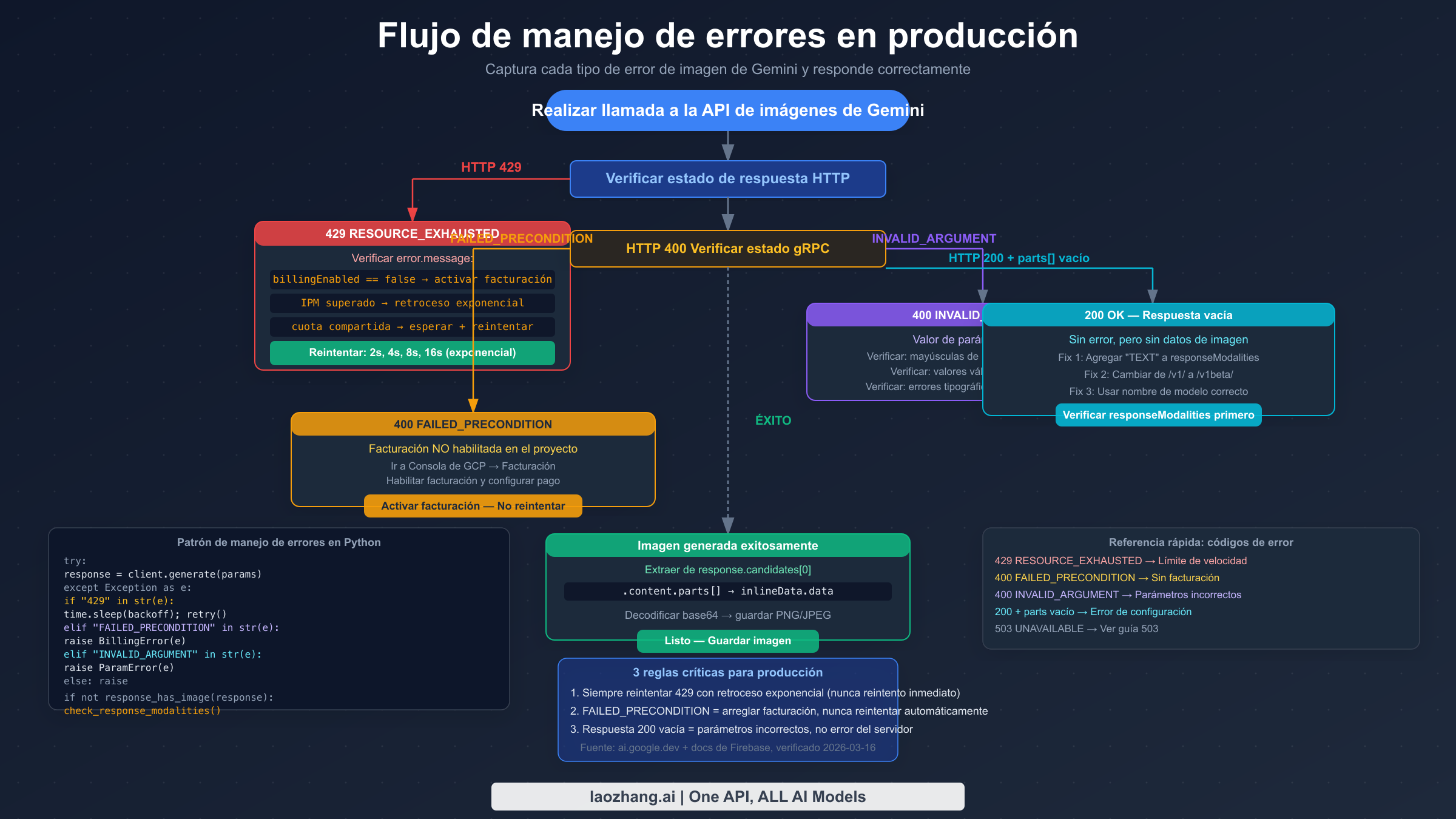
La generación de imágenes de Gemini en producción necesita manejar las tres categorías de error de manera sistemática. El código a continuación proporciona una implementación completa de Python con clasificación adecuada de errores, retroceso exponencial, validación de parámetros y detección de respuesta vacía.
pythonimport time import base64 import requests from typing import Optional from dataclasses import dataclass # Valid parameter constants (from official docs, verified 2026-03-16) VALID_IMAGE_SIZES = {"512", "1K", "2K", "4K"} VALID_ASPECT_RATIOS = {"1:1", "3:4", "4:3", "9:16", "16:9"} GEMINI_IMAGE_ENDPOINT = ( "https://generativelanguage.googleapis.com/v1beta/models/" "{model}:generateContent" ) @dataclass class ImageGenerationError(Exception): """Base class for Gemini image generation errors.""" message: str error_type: str # "rate_limit", "billing", "parameter", "empty_response" retryable: bool def validate_image_config(image_size: str, aspect_ratio: Optional[str] = None): """Validate imageConfig parameters before API call.""" if image_size not in VALID_IMAGE_SIZES: raise ImageGenerationError( message=f"Invalid image_size '{image_size}'. Valid values: {VALID_IMAGE_SIZES}. " f"Note: case-sensitive — use '1K' not '1k'.", error_type="parameter", retryable=False ) if aspect_ratio and aspect_ratio not in VALID_ASPECT_RATIOS: raise ImageGenerationError( message=f"Invalid aspect_ratio '{aspect_ratio}'. Valid: {VALID_ASPECT_RATIOS}", error_type="parameter", retryable=False ) def classify_error(response_or_exception) -> ImageGenerationError: """Classify API error into actionable categories.""" if isinstance(response_or_exception, requests.Response): status = response_or_exception.status_code try: body = response_or_exception.json() error_msg = str(body.get("error", {}).get("message", "")) grpc_status = body.get("error", {}).get("status", "") except Exception: error_msg = response_or_exception.text grpc_status = "" else: error_msg = str(response_or_exception) status = 500 grpc_status = "" if status == 429 or "RESOURCE_EXHAUSTED" in grpc_status: return ImageGenerationError( message=f"Rate limit exceeded: {error_msg}", error_type="rate_limit", retryable=True ) elif "FAILED_PRECONDITION" in grpc_status or "billing" in error_msg.lower(): return ImageGenerationError( message="Billing not enabled. Enable billing in GCP Console.", error_type="billing", retryable=False # Retrying won't help — fix billing first ) elif "INVALID_ARGUMENT" in grpc_status or status == 400: return ImageGenerationError( message=f"Invalid parameter: {error_msg}", error_type="parameter", retryable=False ) else: return ImageGenerationError( message=f"Unexpected error ({status}): {error_msg}", error_type="unknown", retryable=False ) def generate_image( prompt: str, api_key: str, model: str = "gemini-3.1-flash-image-preview", image_size: str = "1K", aspect_ratio: Optional[str] = None, max_retries: int = 5, initial_backoff: float = 2.0 ) -> bytes: """ Generate image with full error handling. Returns raw image bytes (PNG format). Raises ImageGenerationError with retryable flag for caller to handle. """ # Validate parameters before making API call validate_image_config(image_size, aspect_ratio) url = GEMINI_IMAGE_ENDPOINT.format(model=model) headers = {"Content-Type": "application/json"} params = {"key": api_key} image_config = {"image_size": image_size} if aspect_ratio: image_config["aspect_ratio"] = aspect_ratio payload = { "contents": [{"parts": [{"text": prompt}]}], "generationConfig": { "responseModalities": ["TEXT", "IMAGE"], # Both required "imageConfig": image_config } } last_error = None for attempt in range(max_retries): try: response = requests.post( url, json=payload, headers=headers, params=params, timeout=60 ) if not response.ok: error = classify_error(response) if not error.retryable: raise error last_error = error backoff = initial_backoff * (2 ** attempt) print(f"Attempt {attempt + 1}: {error.error_type}, retrying in {backoff}s") time.sleep(backoff) continue # HTTP 200 — check for actual image data data = response.json() candidates = data.get("candidates", []) if not candidates: raise ImageGenerationError( message="No candidates in response. Check model name and quota.", error_type="empty_response", retryable=False ) parts = candidates[0].get("content", {}).get("parts", []) for part in parts: if "inlineData" in part: return base64.b64decode(part["inlineData"]["data"]) # 200 OK but no image data — common config error raise ImageGenerationError( message=( "HTTP 200 but no image in response. " "Verify responseModalities includes both 'TEXT' and 'IMAGE'. " "Check you're using /v1beta/ endpoint." ), error_type="empty_response", retryable=False ) except ImageGenerationError: raise # Don't retry non-retryable errors except requests.RequestException as e: last_error = classify_error(e) if attempt < max_retries - 1: backoff = initial_backoff * (2 ** attempt) time.sleep(backoff) raise last_error or ImageGenerationError( message="Max retries exceeded", error_type="rate_limit", retryable=True ) # Usage example if __name__ == "__main__": try: image_bytes = generate_image( prompt="A serene mountain lake at sunset", api_key="YOUR_API_KEY", model="gemini-3.1-flash-image-preview", image_size="1K", aspect_ratio="16:9" ) with open("output.png", "wb") as f: f.write(image_bytes) print("Image saved to output.png") except ImageGenerationError as e: print(f"Error type: {e.error_type}") print(f"Message: {e.message}") print(f"Retryable: {e.retryable}") if e.error_type == "billing": print("Action: Enable billing at console.cloud.google.com/billing") elif e.error_type == "parameter": print("Action: Fix parameters — check image_size casing and aspect_ratio format") elif e.error_type == "empty_response": print("Action: Add 'TEXT' to responseModalities and verify /v1beta/ endpoint")
Versión JavaScript/Node.js
javascriptconst fetch = require('node-fetch'); const VALID_IMAGE_SIZES = new Set(['512', '1K', '2K', '4K']); async function generateImage(prompt, apiKey, options = {}) { const { model = 'gemini-3.1-flash-image-preview', imageSize = '1K', aspectRatio = null, maxRetries = 5, } = options; if (!VALID_IMAGE_SIZES.has(imageSize)) { throw new Error(`Invalid imageSize '${imageSize}'. Use: ${[...VALID_IMAGE_SIZES].join(', ')}`); } const url = `https://generativelanguage.googleapis.com/v1beta/models/${model}:generateContent?key=${apiKey}`; const imageConfig = { image_size: imageSize }; if (aspectRatio) imageConfig.aspect_ratio = aspectRatio; const payload = { contents: [{ parts: [{ text: prompt }] }], generationConfig: { responseModalities: ['TEXT', 'IMAGE'], imageConfig, }, }; for (let attempt = 0; attempt < maxRetries; attempt++) { const response = await fetch(url, { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify(payload), }); if (response.status === 429) { if (attempt === maxRetries - 1) throw new Error('Max retries exceeded (429)'); const delay = Math.pow(2, attempt + 1) * 1000; await new Promise(r => setTimeout(r, delay)); continue; } if (!response.ok) { const body = await response.json(); const status = body?.error?.status || ''; if (status === 'FAILED_PRECONDITION') { throw new Error('Billing not enabled. Enable billing in GCP Console.'); } throw new Error(`API error ${response.status}: ${JSON.stringify(body?.error)}`); } const data = await response.json(); const parts = data?.candidates?.[0]?.content?.parts || []; const imagePart = parts.find(p => p.inlineData); if (!imagePart) { throw new Error( 'HTTP 200 but no image data. Check responseModalities includes TEXT and IMAGE.' ); } return Buffer.from(imagePart.inlineData.data, 'base64'); } }
Para escenarios de producción de alta concurrencia donde necesitas manejar múltiples modelos y estrategias de respaldo, los agregadores de API como el endpoint de imágenes de laozhang.ai pueden servir como alternativa cuando tu cuota principal está agotada. El agregador maneja internamente la limitación de velocidad, lo que simplifica tu código de manejo de errores cuando la API principal está siendo limitada.
Preguntas frecuentes
¿Por qué mi llamada a la API de imágenes de Gemini devuelve HTTP 200 pero sin imagen?
La causa más común es que responseModalities está configurado como ["IMAGE"] en lugar de ["TEXT", "IMAGE"]. La API de imágenes de Gemini requiere las modalidades TEXT e IMAGE: omitir TEXT hace que la API devuelva una respuesta vacía sin un error. Verifica tu generationConfig y asegúrate de que incluya ambos valores. Si eso es correcto, verifica que estés usando el endpoint /v1beta/, no /v1/ ni el endpoint compatible con OpenAI.
¿Cómo corrijo los errores 429 de la API de imágenes de Gemini después de actualizar a un plan de pago?
Primero verifica cuándo actualizaste. Si fue en las últimas 24-48 horas, podrías estar afectado por el Bug Fantasma 429 (un problema conocido de febrero de 2026 donde las nuevas activaciones de facturación no propagan inmediatamente la cuota). Intenta cambiar temporalmente a una variante de modelo diferente. Si el 429 persiste más de 48 horas con una cuota diferente de cero mostrada en la Consola de GCP, presenta un ticket de soporte haciendo referencia al problema de propagación de cuota. También verifica en la Consola de GCP que tu cuota IPM (imágenes por minuto) sea realmente diferente de cero: habilitar la facturación no significa automáticamente que tu cuota de imagen esté configurada en un valor diferente de cero.
¿Por qué se está ignorando mi configuración de imageConfig?
Dos causas comunes: distinción de mayúsculas/minúsculas o eliminación por middleware. Para la distinción de mayúsculas/minúsculas, verifica que el valor de tu image_size use K mayúscula: "1K" no "1k". Para la eliminación por middleware, si estás enrutando a través de LiteLLM o una capa de proxy similar, imageConfig puede ser eliminado antes de llegar a la API de Gemini. La solución es hacer llamadas HTTP directas a la API de Gemini para la generación de imágenes en lugar de pasar por el proxy.
¿Cuál es la diferencia entre la cuota IPM y RPM para los modelos de imagen de Gemini?
RPM (solicitudes por minuto) limita cuántas llamadas a API puedes hacer por minuto y se aplica a todos los modelos de Gemini. IPM (imágenes por minuto) es específico de imagen y limita cuántas imágenes individuales se pueden generar por minuto. Una llamada a la API puede generar múltiples imágenes si numberOfImages está configurado en más de 1, y cada imagen cuenta individualmente contra tu cuota IPM. La cuota IPM es típicamente la restricción vinculante para la generación de imágenes: alcanzarás IPM antes que RPM en la mayoría de los patrones de uso.
¿Es seguro usar los modelos de imagen en vista previa de Gemini en producción?
Los modelos en vista previa (gemini-3.1-flash-image-preview, gemini-3-pro-image-preview) usan Cuota Dinámica Compartida, lo que significa que pueden devolver errores 429 debido a la congestión global incluso cuando estás dentro de tus límites de cuota personales. Están bien para el desarrollo y el uso de producción ligero, pero para aplicaciones con requisitos de SLA, usa el modelo estable gemini-2.5-flash-image o Vertex AI con Rendimiento provisionado. Los modelos en vista previa también pueden ser cambiados u obsoletos con menos aviso que los modelos de producción.
Conclusión y próximos pasos
Los errores de la API de imágenes de Gemini son genuinamente confusos porque diferentes problemas producen síntomas de apariencia idéntica. Un 429 puede significar que tu nivel gratuito tiene cuota cero, o que tu cuota de pago está agotada, o que has encontrado un error conocido, o que estás experimentando congestión global: y cada escenario necesita una respuesta completamente diferente. Un HTTP 200 vacío puede significar una configuración incorrecta de parámetros, un endpoint incorrecto o interferencia del middleware.
La secuencia de diagnóstico que funciona en todos los tipos de error: verifica primero la facturación (Consola de GCP → APIs y servicios → API de lenguaje generativo → Cuotas), luego verifica tus parámetros (responseModalities: ["TEXT", "IMAGE"], image_size: "1K" en mayúsculas), luego confirma tu endpoint (/v1beta/ no /v1/). La mayoría de los problemas se resuelven en uno de estos tres puntos de control.
Para las aplicaciones de producción, incorpora la clasificación de errores en tu código desde el principio: distinguir los errores 429 reintentables de los errores de facturación y parámetros no reintentables ahorra problemas operativos más adelante. El ejemplo de código completo en el Capítulo 7 proporciona esta clasificación de forma inmediata.
Si constantemente estás alcanzando los límites de cuota y necesitas más rendimiento sin la complejidad del aprovisionamiento de Vertex AI, considera revisar tu estrategia de generación por lotes para mantenerte dentro de los límites de IPM, o explorar si los umbrales de cuota del Nivel 2 satisfacen tus requisitos. La estructura de cuotas está diseñada para escalar con el uso: lo que comienza como un límite se vuelve manejable una vez que entiendes qué dimensión es la restricción vinculante para tu carga de trabajo.