
A 21 de mayo de 2026, la respuesta segura no es "el modelo nuevo gana". Usa gemini-3.5-flash cuando la calidad en agentes, código, tool loops o long context reduzca reintentos y tiempo de revisión. Usa gemini-3.1-flash-lite cuando el trabajo sea simple, masivo, sensible al coste y suficientemente preciso.
Respuesta rápida
| Situación | Ruta inicial | Por qué |
|---|---|---|
| Coding agents, tool loops, análisis multi-step, product assistants | Gemini 3.5 Flash | Paga por la ruta fuerte solo si reduce retries, tool failures y review time. |
| Bulk extraction, translation, classification, moderation, short summaries | Gemini 3.1 Flash-Lite | Las filas Standard y Batch/Flex más baratas importan cuando la calidad ya alcanza. |
| Duda o cambio de production default | Mantén ambos | Ejecuta la misma tarea y mide calidad, coste, latency, retries y review. |
| Image output, audio output, Live API, Computer Use | Ninguno | Usa una ruta Gemini que soporte explícitamente ese runtime. |
Esta comparación es workload routing, no solo benchmark. Los dos modelos tienen un public API contract muy parecido, así que la decisión real es quality per task versus cost per task. Si Flash-Lite ya es preciso y barato, reemplazarlo globalmente solo sube el coste. Si Flash-Lite causa retries, tool failures o reparación humana, Gemini 3.5 Flash puede ser más barato en el workflow completo.
Contrato oficial

Las páginas actuales de Google model docs listan gemini-3.5-flash y gemini-3.1-flash-lite como stable Gemini API models. Ambos aceptan text, image, video, audio y PDF input, ambos producen text output, y ambos muestran 1,048,576 input tokens y 65,536 output tokens.
El feature checklist tampoco decide por ti. En el snapshot del 21 de mayo ambos listan Batch API, caching, code execution, file search, function calling, Google Search grounding, Google Maps grounding, structured outputs, thinking, URL context, Flex y Priority. La pregunta no es si Flash-Lite puede usar tools; es si rinde lo suficiente en tu clase de tarea.
| Contract item | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite |
|---|---|---|
| API model ID | gemini-3.5-flash | gemini-3.1-flash-lite |
| Status | Stable | Stable |
| Input and output | Multimodal input, text output | Multimodal input, text output |
| Token window | 1,048,576 input, 65,536 output | 1,048,576 input, 65,536 output |
| Practical read | Quality route | Low-cost volume route |
La regla de parada también importa: no presentes ninguna de estas filas como image generation, audio generation, Live API o Computer Use route hasta que la página oficial cambie.
Precio y coste real del workflow

En el pricing snapshot del 21 de mayo, Gemini 3.5 Flash paid Standard cuesta $1.50 input y $9.00 output por 1M tokens. Gemini 3.1 Flash-Lite cuesta $0.30 input y $2.50 output. Batch/Flex también favorece a Flash-Lite: $0.75/$4.50 para 3.5 Flash frente a $0.15/$1.25 para Flash-Lite. La pricing page muestra Free Tier rows para Standard usage, pero el acceso real depende de account, billing, region, quota y live docs.
No pares en el token price. En agentic work pesan retry count, tool failure, schema failure y human review minutes. Un modelo caro gana si evita dos failed tool loops. Un modelo barato gana si la tarea es verificable, repetible y sencilla.
Workload routing matrix
La mejor división es cost of failure. Si un error crea debugging time, bad code, tool churn o support escalation, prueba 3.5 Flash primero. Si el resultado se verifica barato y se repite a escala, empieza con Flash-Lite.
| Workload | First test | Keep the other route for |
|---|---|---|
| Coding-agent traces | 3.5 Flash | Cheap lint summaries or issue classification. |
| Multimodal support tickets | 3.5 Flash | Tagging and routing once the schema is simple. |
| Translation and rewrite variants | Flash-Lite | Ambiguous source text or brand-sensitive copy. |
| Data extraction | Flash-Lite | Mixed PDFs, long evidence packs, brittle validation. |
| Product-facing assistant | 3.5 Flash | Low-risk background summaries. |
No cambies un global Gemini default por otro global default. Mantén en config una quality route y una margin route, luego enruta por task class.
Same-task switch checklist
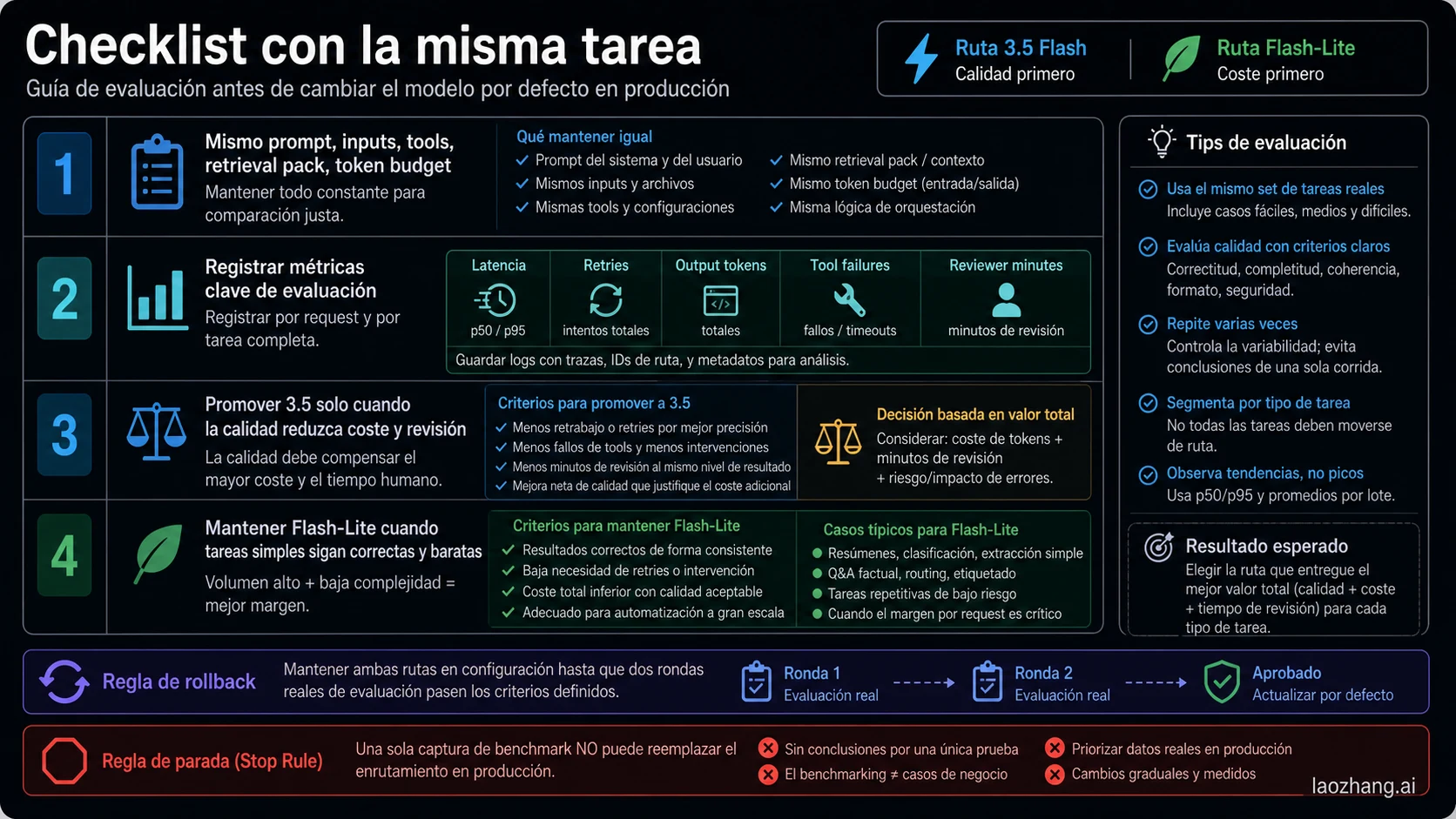
Antes de cambiar production defaults, ejecuta la misma tarea en ambas rutas. Usa el mismo prompt, inputs, retrieval pack, tools, timeout, token budget y validator. Registra model ID, price mode, latency, retries, input tokens, output tokens, tool failures, schema failures, reviewer minutes y accepted result.
Promueve Gemini 3.5 Flash solo cuando reduzca total workflow cost o mejore claramente accepted quality. Mantén Flash-Lite cuando la tarea siga siendo correcta, barata y fácil de verificar. Conserva ambas rutas hasta pasar dos rondas de evaluación real.
Adjacent Gemini decisions
For narrower Gemini follow-ups, use Gemini 3.5 Flash capabilities, Gemini API free tier, Gemini API vs Vertex AI, Flash-family runtime guide. Fuentes verificadas el 21 de mayo de 2026: Google AI model pages, Gemini API pricing, changelog, deprecations y Google launch post. Pricing, free-tier access, model availability, and preview shutdown dates can change, so recheck the live official pages before changing production defaults.
Preguntas frecuentes
¿Gemini 3.5 Flash siempre es mejor?
No. Es la primera prueba para complex agent and coding work, pero Flash-Lite puede ser mejor production default para tareas simples y masivas.
¿Ambos modelos son stable?
En el official model snapshot del 21 de mayo de 2026, gemini-3.5-flash y gemini-3.1-flash-lite aparecen como stable.
¿Sigue siendo seguro usar Flash-Lite preview?
Para production usa la fila stable gemini-3.1-flash-lite. Google deprecations page lista gemini-3.1-flash-lite-preview con shutdown el 25 de mayo de 2026.
¿Cuál es más barato?
En las filas paid Standard y Batch/Flex del snapshot del 21 de mayo, Flash-Lite es más barato. Revisa la official pricing page antes de publicar números duros.
¿Debo mantener ambos en el router?
Sí. Mantén una quality route y una margin route; enruta por task class, no por branding del modelo.