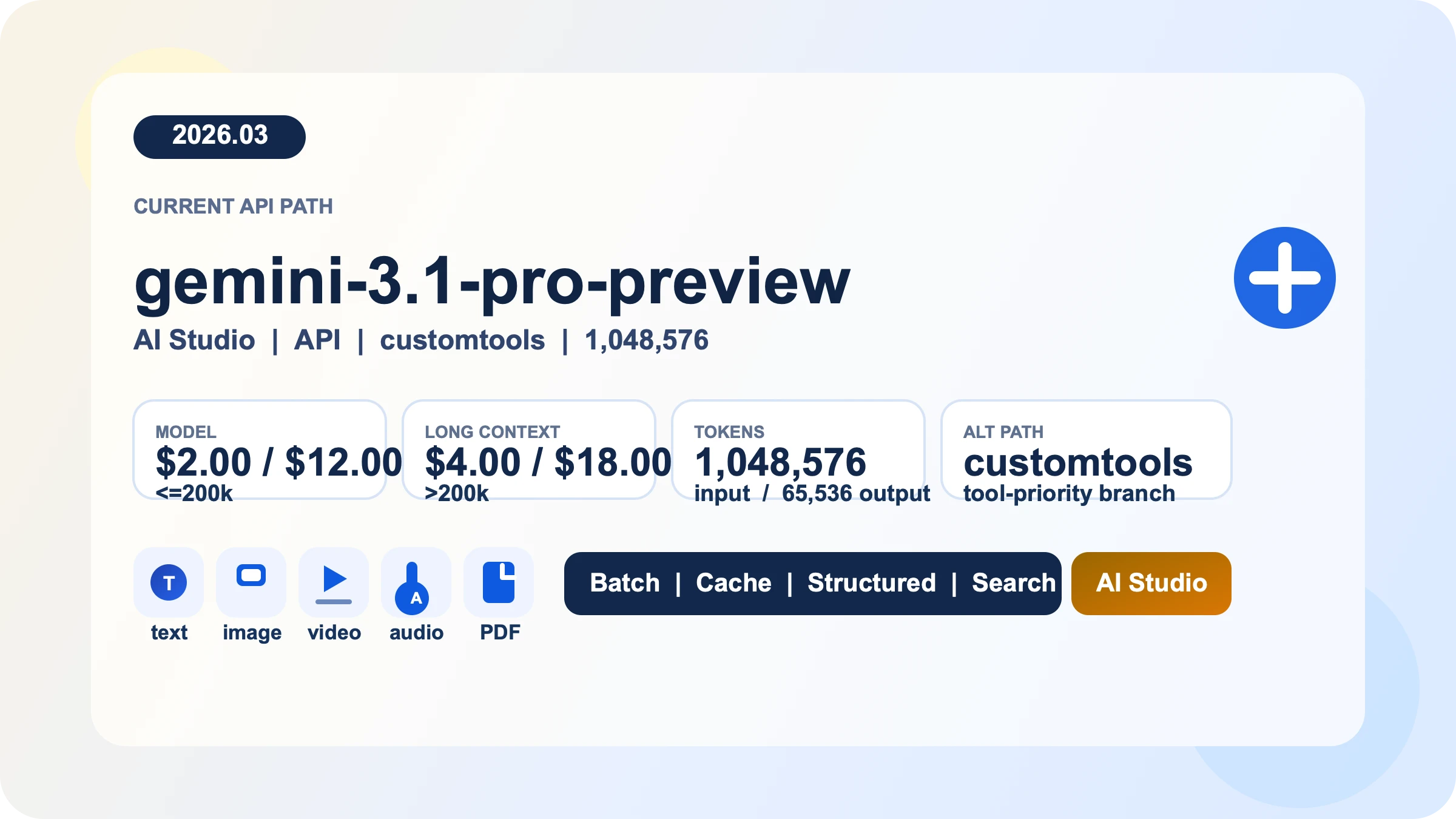
Gemini 3.1 Pro API es la ruta preview de pago que Google ofrece hoy para contexto largo, entrada multimodal y workflows de desarrollo con herramientas. A fecha de 28 de marzo de 2026, la tarifa estandar es $2 de input / $12 de output por 1M tokens hasta 200k; por encima es $4 / $18, y Batch cuesta la mitad. Tras revisar de nuevo la documentacion oficial, el model principal actual es gemini-3.1-pro-preview, el viejo gemini-3-pro-preview ya fue cerrado y ahora apunta al modelo nuevo, y ademas existe gemini-3.1-pro-preview-customtools como endpoint separado para agentes que mezclan bash con herramientas registradas. Si lo que quieres no es leer otro resumen del lanzamiento sino conectar la API hoy, evitar model ID obsoletos y no equivocarte con precios o limites, ese es el angulo correcto.
“Nota de evidencia: esta guia se basa en la pagina del modelo Gemini 3.1 Pro, la pagina de precios, la pagina de rate limits, la guia de API keys, la documentacion de OpenAI compatibility, la Gemini 3 developer guide y las release notes de Google, todas revisadas de nuevo el 28 de marzo de 2026.
TL;DR
- La ruta por defecto es
gemini-3.1-pro-preview. gemini-3.1-pro-preview-customtoolssolo tiene sentido cuando la prioridad de tus herramientas forma parte real del problema.- El acceso programatico a Gemini 3.1 Pro no es gratis, aunque AI Studio sigue siendo la forma mas rapida de probar prompts antes de conectar billing.
- Hasta 200k de prompt size pagas $2.00 / $12.00 por 1M tokens; por encima es $4.00 / $18.00. Batch cuesta la mitad y caching es un verdadero lever de coste.
- Tus RPM, TPM y RPD reales ya no deberian salir de una tabla copiada. Google te dice que los mires en AI Studio.
- Si sigues usando
gemini-3-pro-preview, esto ya es trabajo de migracion y no una simple preferencia de naming.
La forma mas rapida de poner a funcionar tu primer request
Google sigue centrando la creacion del API key de Gemini en Google AI Studio. La secuencia practica es simple: abre AI Studio, crea o importa el proyecto que vayas a usar, genera ahi la key y despues configura en local GEMINI_API_KEY o GOOGLE_API_KEY. La documentacion de API keys de Google aclara que las librerias oficiales detectan cualquiera de las dos y que, si las dos existen, GOOGLE_API_KEY tiene prioridad. Si solo quieres validar prompts y comportamiento, puedes quedarte en AI Studio. Si lo que necesitas es acceso programatico real a Gemini 3.1 Pro, lo sensato es conectar billing desde el principio y no tratar este modelo como si fuera una ruta API sin coste.
Para la mayoria de equipos, la entrada mas limpia es el GenAI SDK oficial. Python, JavaScript y REST pueden quedarse en su forma minima sin capas extra.
pythonfrom google import genai from google.genai import types client = genai.Client() response = client.models.generate_content( model="gemini-3.1-pro-preview", contents="Review this API design and list the main tradeoffs.", config=types.GenerateContentConfig( thinking_config=types.ThinkingConfig(thinking_level="medium") ), ) print(response.text)
javascriptimport { GoogleGenAI } from "@google/genai"; const ai = new GoogleGenAI({}); const response = await ai.models.generateContent({ model: "gemini-3.1-pro-preview", contents: "Review this API design and list the main tradeoffs.", config: { thinkingConfig: { thinkingLevel: "medium", }, }, }); console.log(response.text);
bashcurl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-pro-preview:generateContent" \ -H "x-goog-api-key: $GEMINI_API_KEY" \ -H "Content-Type: application/json" \ -X POST \ -d '{ "contents": [{ "parts": [{"text": "Review this API design and list the main tradeoffs."}] }], "generationConfig": { "thinkingConfig": { "thinkingLevel": "medium" } } }'
Lo importante no es solo que el request funcione, sino que funcione con un model explicito y una configuracion de reasoning explicita. La Gemini 3 developer guide documenta que high es el nivel dinamico por defecto para Gemini 3.1 Pro. Si dejas esa parte totalmente implicita, tambien dejas mas implicitos de la cuenta la latencia y el gasto de output tokens.
Antes del prompt hay que elegir bien el model path
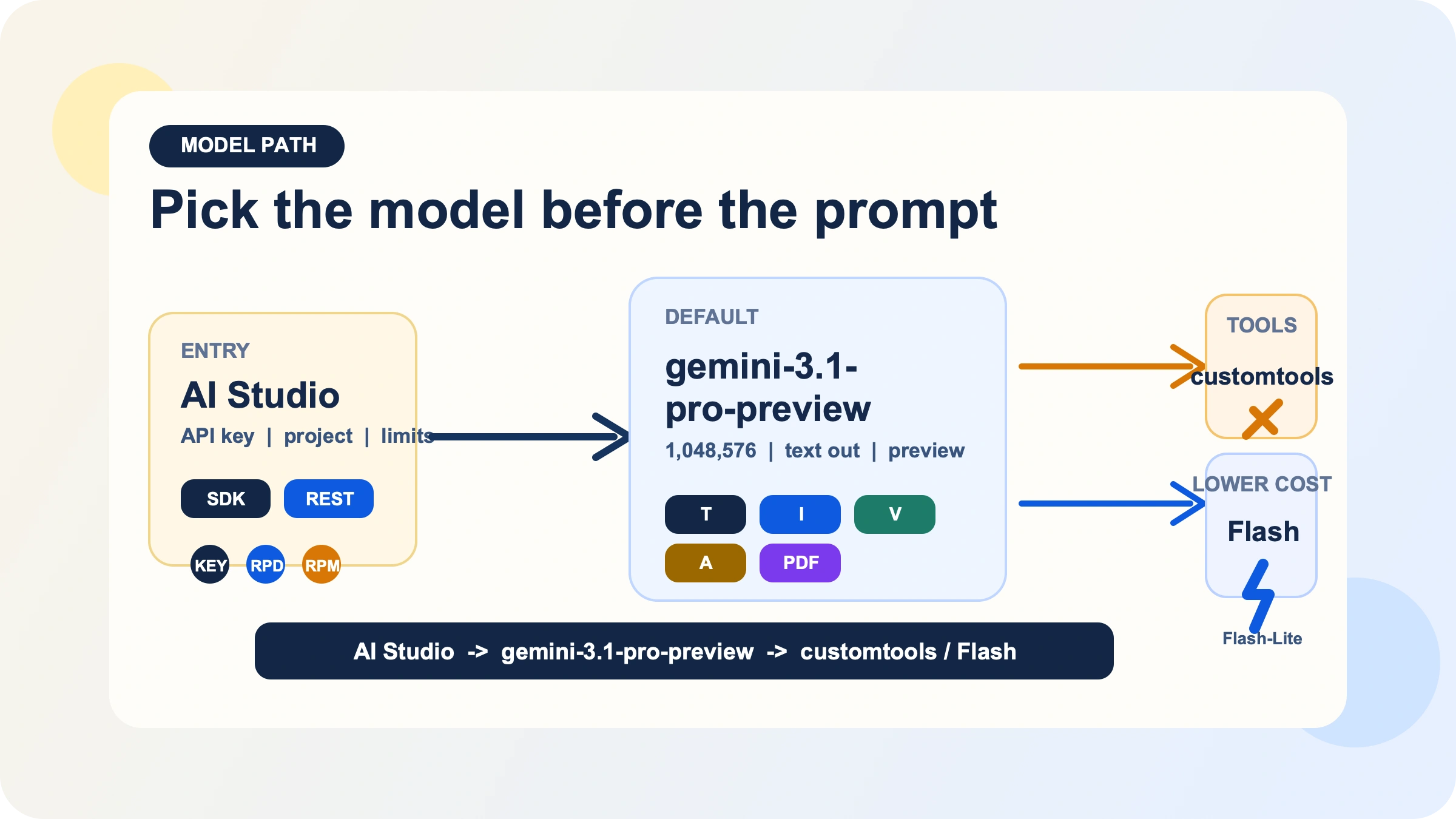
La primera decision no es prompt engineering. Es elegir la ruta del modelo.
La ruta base es gemini-3.1-pro-preview. Google describe esta preview como una evolucion de la serie Gemini 3 Pro con mejor thinking, mejor token efficiency y mejor comportamiento en software engineering y agentic workflows. Acepta text, image, video, audio y PDF como entrada, entrega text como salida y soporta Batch API, caching, code execution, function calling, search grounding, Maps grounding, structured outputs y URL context. Para analisis de documentos largos, reasoning multimodal, extraccion estructurada y workflows con herramientas, es una ruta perfectamente defendible.
Las limitaciones importan igual. Gemini 3.1 Pro Preview no soporta image generation, audio generation ni Live API. Si tu trabajo real consiste en generar imagenes, tener audio en tiempo real o mover mucho texto con el menor coste posible, no tiene sentido empezar por Pro. En esos casos suele encajar mejor Flash, Flash-Lite, una familia image o una ruta live. Si lo que te preocupa es tener una opcion API sin coste, la lectura inicial correcta es nuestra guia del free tier de Gemini API, no forzar Pro en un rol que no le toca.
La otra bifurcacion es gemini-3.1-pro-preview-customtools. No es otro flagship con precios o contexto distintos, sino un endpoint separado pensado para agentes que combinan bash con herramientas registradas. La pagina oficial del modelo explica que prioriza mejor tus custom tools, por ejemplo view_file o search_code, pero tambien avisa de que puede haber quality fluctuation en casos de uso que no se benefician de esas herramientas. La conclusion practica es sencilla: si la prioridad de herramientas es parte del problema, customtools tiene sentido; si haces reasoning general, chat o analisis documental, mejor quedarte en la ruta standard. Si quieres profundizar en esa decision, tenemos una guia dedicada sobre Gemini 3.1 Pro customtools.
Y hay un hecho de migracion que conviene tratar como cerrado. En las release notes, Google indica que gemini-3-pro-preview se apago el 9 de marzo de 2026 y ahora apunta a gemini-3.1-pro-preview. Aunque el alias siga salvando codigo viejo, cualquier implementacion nueva deberia usar la cadena de modelo actual de forma explicita.
Como leer precios y limites sin enganarte

La parte de precios que mas se pasa por alto es el umbral de longitud del prompt. Segun la pagina actual de precios de Google, la banda estandar hasta 200k tokens queda asi:
| Banda | Input | Output | Batch |
|---|---|---|---|
<=200k | $2.00 / 1M | $12.00 / 1M | $1.00 / $6.00 |
>200k | $4.00 / 1M | $18.00 / 1M | $2.00 / $9.00 |
Ese umbral importa precisamente porque Gemini 3.1 Pro vende una ventana de entrada de 1.048.576 tokens. Decir "tiene 1M context" y detenerse ahi no ayuda mucho si luego vas a vivir de verdad en la banda cara. En la practica, antes que otra tabla de benchmarks conviene vigilar cuatro palancas:
- Mantener los prompts rutinarios por debajo de 200k cuando sea posible.
- Mandar a Batch lo que no requiera respuesta en tiempo real.
- Usar caching si repites un bloque grande de instrucciones o contexto.
- Tratar el thinking level como una palanca economica, no como un detalle decorativo.
La pagina de precios aporta numeros concretos para dos lineas que casi siempre se ignoran: context caching y grounding. Caching cuesta $0.20 / $0.40 por 1M tokens (<=200k / >200k) mas $4.50 por 1M tokens por hora de storage, asi que solo compensa si reutilizas bloques grandes. Search y Maps grounding comparten un pool gratuito de 5.000 prompts mensuales (Batch tiene un limite menor) y luego cuestan $14 por 1.000 consultas; si no necesitas hechos web en tiempo real, grounding es un multiplicador de coste evitable.
Con los limites hace falta otro marco mental. La pagina de rate limits de Google dice expresamente que los limites activos dependen del usage tier y del estado de la cuenta y que deben verse en AI Studio. Eso significa que ninguna tabla estatica copiada en un blog deberia tratarse como verdad final para tu proyecto. Aun asi, la documentacion oficial si deja claras varias reglas de operacion:
- el rate limiting se mide por RPM, TPM y RPD
- las cuotas se aplican por proyecto, no por API key
- RPD se reinicia a medianoche hora Pacific
- las preview models tienen limites mas estrictos
- tus active limits viven en AI Studio
La misma pagina describe tambien la progresion de tiers. Tier 1 empieza al activar billing, Tier 2 requiere uso pagado y cierto tiempo desde el primer pago correcto, y Tier 3 exige mas gasto y mas historial. Si vas a hacer capacity planning de verdad, usa la pagina oficial para entender la logica y AI Studio para ver los numeros que de verdad mandan en tu proyecto.
Hay un detalle practico de mitad de marzo que merece una nota aparte. Las release notes indican que el 12 de marzo de 2026 AI Studio anadio project-level spend caps. Si vas a abrir Gemini 3.1 Pro a un equipo, es una buena barrera presupuestaria para activar antes de que llegue el primer workload pesado de contexto largo.
Thinking, contexto largo y cache: donde de verdad se mueve la factura
Gemini 3.1 Pro no es una de esas APIs que conviene dejar en piloto automatico solo porque la superficie se vea limpia. La Gemini 3 developer guide indica que Gemini 3.1 Pro soporta low, medium y high como thinking levels, y que high es el valor dinamico por defecto. La misma guia tambien deja claro que thinking_level no puede convivir en el mismo request con el parametro heredado thinking_budget, porque eso devuelve un 400. Para migraciones, ese detalle importa mucho.
Mi recomendacion practica es tratar medium como el primer default serio para trabajo diario y moverlo hacia abajo o hacia arriba segun el tipo de tarea. Esa recomendacion es una inferencia de ingenieria a partir del comportamiento documentado y la estructura de costes, no una frase literal de Google. Para extraccion, clasificacion, transformaciones cortas y tareas en las que el reasoning profundo no es el cuello de botella, suele tener mas sentido empezar por low. Para analisis complejos, revision de codebases grandes o reasoning en varios pasos, high puede estar justificado, pero deberia ser una eleccion consciente y no el resultado de dejar todo implicito.
Con el contexto largo ocurre lo mismo. La ventana de 1M tokens es real y es una de las mejores razones para elegir Gemini 3.1 Pro. Pero la pregunta util no es "si cabe", sino "cuantas veces necesito pagar la banda larga" y "que partes deberia cachear o resumir antes". Si reenvias una y otra vez el mismo system prompt enorme, el mismo paquete de documentos o el mismo contexto de repositorio, la implementacion mas comoda se convierte muy rapido en la mas cara.
Si quieres una explicacion mas profunda de como conviene rutear el reasoning en Gemini, tenemos una guia dedicada sobre Gemini 3.1 Pro thinking level. A este nivel, basta con recordar tres reglas: fijar el reasoning de forma explicita, no olvidar el umbral de 200k y no convertir el contexto largo en un habito solo porque el modelo lo permita.
Como migrar si venias de Gemini 3 Pro Preview o ya trabajas con OpenAI SDK
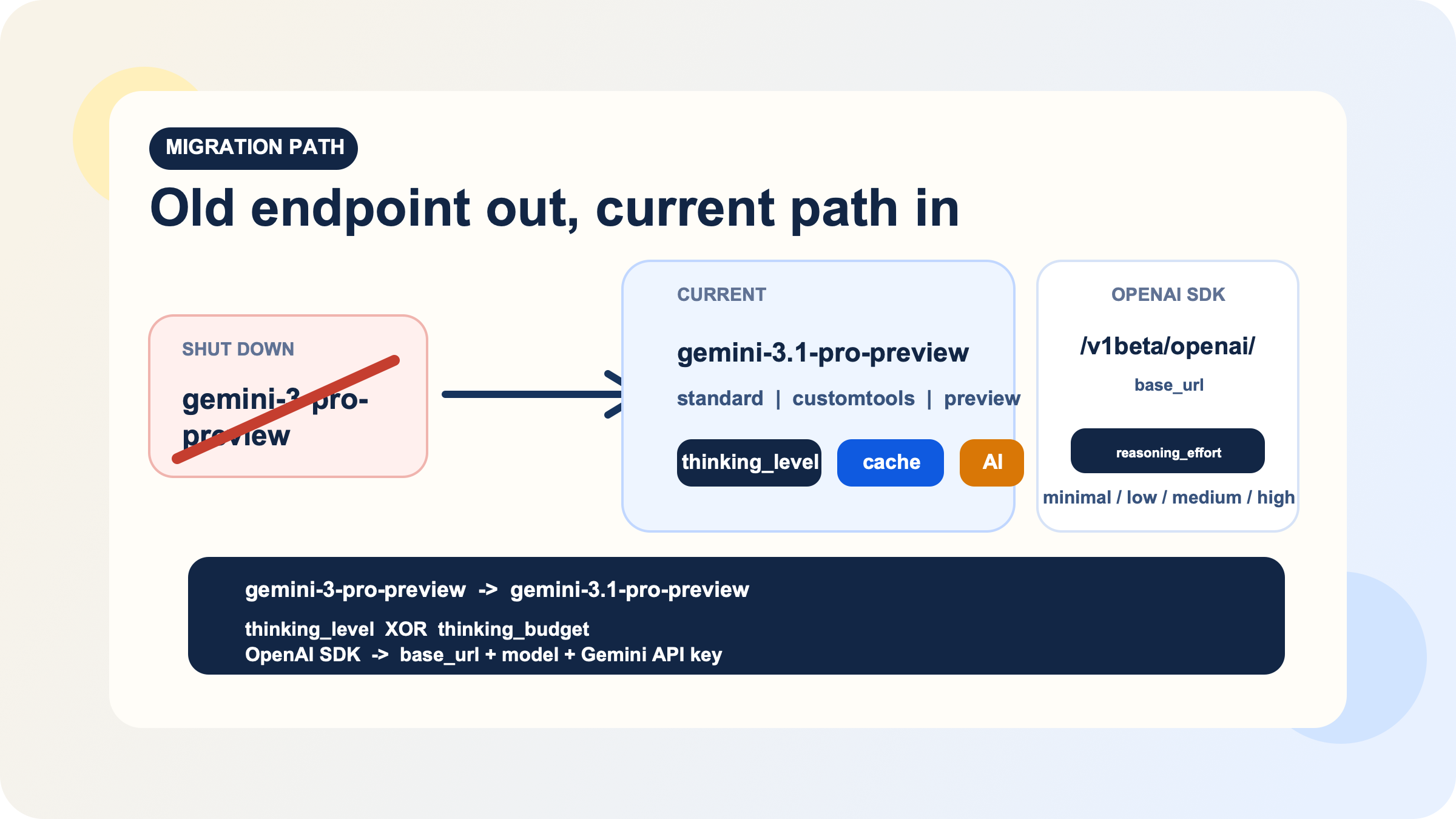
Si antes usabas Gemini 3 Pro Preview, la idea principal de la migracion es simple. Las release notes del 9 de marzo de 2026 dicen que ese modelo se apago y que gemini-3-pro-preview ahora apunta a gemini-3.1-pro-preview. La decision operativa correcta es actualizar el model string de forma explicita, revisar tus supuestos sobre thinking y decidir si tu workload debe quedarse en la ruta standard o moverse a -customtools.
Si tu equipo ya esta muy metido en OpenAI SDK, la capa de OpenAI compatibility de Google es el puente con menos friccion. La documentacion oficial muestra que puedes llamar a Gemini desde las librerias de OpenAI en Python y JavaScript cambiando tres cosas: API key, base URL y model name. Para quien quiere probar Gemini dentro de un stack ya montado sobre clientes OpenAI, es una via bastante util.
pythonfrom openai import OpenAI client = OpenAI( api_key="GEMINI_API_KEY", base_url="https://generativelanguage.googleapis.com/v1beta/openai/" ) response = client.chat.completions.create( model="gemini-3.1-pro-preview", reasoning_effort="medium", messages=[ {"role": "user", "content": "Summarize the migration risks in this API design."} ] ) print(response.choices[0].message.content)
Ese mismo documento de compatibility tambien mapea reasoning_effort con los controles de reasoning de Gemini. minimal y low se corresponden con Gemini low, medium con medium y high con high. La regla importante sigue siendo la misma que en la ruta nativa: no superpongas dos controles de reasoning con funcionalidad equivalente. Si ya usas reasoning_effort por la ruta compatible con OpenAI, no metas ademas otra configuracion de thinking de Gemini salvo que la documentacion oficial diga expresamente que tu caso la soporta.
Este es tambien el mejor momento para auditar tutoriales viejos y snippets internos. En modelos preview, el peligro rara vez es solo un model name anticuado; tambien caducan parametros, supuestos de coste y patrones de uso. La via mas segura es normalizar el model string actual, volver a comprobar el coste y probar prompts representativos en AI Studio antes de volver a poner esa ruta en produccion.
Cuando Gemini 3.1 Pro es la API correcta y cuando no lo es
Gemini 3.1 Pro tiene sentido cuando tu workload necesita a la vez reasoning fuerte, contexto largo y una superficie multimodal orientada a tools. Esa combinacion encaja bien en revision de documentos grandes, analisis de codebases amplios, extraccion estructurada sobre entradas mixtas y workflows de agentes que dependen de code execution, function calling, grounding o URL context. Tambien encaja si tu equipo acepta la realidad operativa de una preview model de pago, con limites mas estrictos que los caminos baratos y de alto volumen.
Elige gemini-3.1-pro-preview-customtools cuando tu agente combine bash con herramientas registradas y el problema de fondo sea la prioridad de esas herramientas. Elige una ruta mas barata como Flash o Flash-Lite cuando importen mas la latencia y el presupuesto que el reasoning flagship. Cambia de familia de modelos si necesitas image output o live audio. Y si tu problema es simplemente "quiero empezar con una API gratis", Pro no deberia ser el primer sitio donde mirar; en ese caso, tiene mas sentido empezar por la guia del free tier de Gemini API y la guia de rate limits de Gemini API.
Si estas comparando Gemini, OpenAI y Claude detras de una sola capa de routing, una pasarela como laozhang.ai puede resultar util porque reduce la fragmentacion de autenticacion y billing. Pero lo importante no es solo que liste el modelo, sino que exponga de verdad la variante y las capacidades que necesitas, especialmente si dependes del comportamiento preview o de la ruta customtools.
La conclusion practica es corta. Gemini 3.1 Pro API merece la pena cuando necesitas su forma real y no solo su nombre. Si tu trabajo de verdad es texto barato, rapido y de alto volumen, pagar Pro no tiene mucho sentido. Si lo que necesitas es un gran contexto multimodal, structured output, grounding y ejecucion multi-step fiable, entonces Gemini 3.1 Pro sigue siendo una ruta fuerte hoy.
FAQ
Gemini 3.1 Pro API es gratis?
No. La pagina de precios actual de Google no muestra free API tier para Gemini 3.1 Pro Preview. Puedes probarlo en AI Studio, pero el acceso programatico es de pago.
Sigue funcionando gemini-3-pro-preview?
Fue apagado el 9 de marzo de 2026. Las release notes dicen que ahora apunta a gemini-3.1-pro-preview, pero el codigo nuevo deberia usar el model string actual de forma explicita.
Debo usar gemini-3.1-pro-preview-customtools en todos los proyectos?
No. Solo tiene sentido cuando la prioridad de custom tools es una parte real del workload. Google tambien advierte de posibles quality fluctuations en casos que no se benefician de ello.
Donde veo mis RPM, TPM y RPD reales?
En AI Studio. La propia pagina de rate limits de Google ahora te remite alli para ver tus active limits.
Puedo llamar a Gemini 3.1 Pro desde OpenAI SDK?
Si. La documentacion de OpenAI compatibility de Google explica que basta con cambiar API key, base URL y model name.
Gemini 3.1 Pro soporta image generation o Live API?
No. La pagina actual del modelo marca image generation, audio generation y Live API como unsupported.