A 4 de mayo de 2026, DeepSeek V4 Pro, Claude Opus 4.7 y GPT-5.5 no forman una carrera con un único ganador. GPT-5.5 debe probarse primero cuando el flujo ya vive en OpenAI, Codex, herramientas y salida estructurada. Claude Opus 4.7 debe quedar como control premium para agentes y despliegues donde el error cuesta más que el modelo. DeepSeek V4 Pro merece un piloto cuando el coste, el control open-weight o los experimentos de contexto largo justifican medir la misma tarea.
La decisión segura consiste en elegir una ruta verificable, no el nombre que ganó una tabla pública. GPT-5.5 entra en el primer piloto OpenAI-native. Opus 4.7 se mantiene como línea de control premium. DeepSeek V4 Pro se usa como piloto acotado de coste o self-host hasta que demuestre la misma tarea con los mismos archivos, herramientas y criterios de aceptación.
| Necesidad de ruta | Empieza con | Por qué encaja | Regla de parada |
|---|---|---|---|
| Coding nativo de OpenAI, Codex, tool-heavy API, structured output | GPT-5.5 | La documentación de OpenAI lista GPT-5.5, 1M de contexto y 128K de salida máxima, así que es la primera prueba limpia dentro del stack OpenAI. | Antes de tráfico productivo, vuelve a comprobar acceso de cuenta, límites, consola y el conflicto con una nota antigua de Help Center. |
| Agentes sensibles a corrección, cloud/API deployment, control premium | Claude Opus 4.7 | Anthropic sitúa Opus 4.7 en coding exigente, agentes, herramientas, visión y despliegues cloud. | No apruebes el coste premium si no reduce defectos, tiempo de revisión o riesgo de rollback. |
| Pilotos de bajo coste, gobernanza open-weight, pruebas masivas de contexto largo | DeepSeek V4 Pro | DeepSeek documenta descuento V4 Pro, URL compatibles, 1M de contexto y 384K de salida máxima. | Mantén el piloto hasta que pasen calidad, latencia, fidelidad de ruta y rollback. |
| Cambio de default en producción | Dual-run first | Los benchmarks públicos y el precio por token no miden tus modos de fallo. | No cambies sin los mismos prompts, tools, files, budgets, acceptance tests y rollback threshold. |
Empieza por el contrato que puedes llamar
La comparación práctica empieza por el dueño de la ruta. OpenAI controla los hechos de modelo y API de GPT-5.5. Anthropic controla la disponibilidad y el precio de Claude Opus 4.7. DeepSeek controla la API V4 Pro, la ventana de descuento y la ruta open-weight. Los vídeos, foros y comparadores ayudan a hacer preguntas, pero no deben decidir model labels, precios, endpoints, ventanas de contexto o ventanas de descuento.
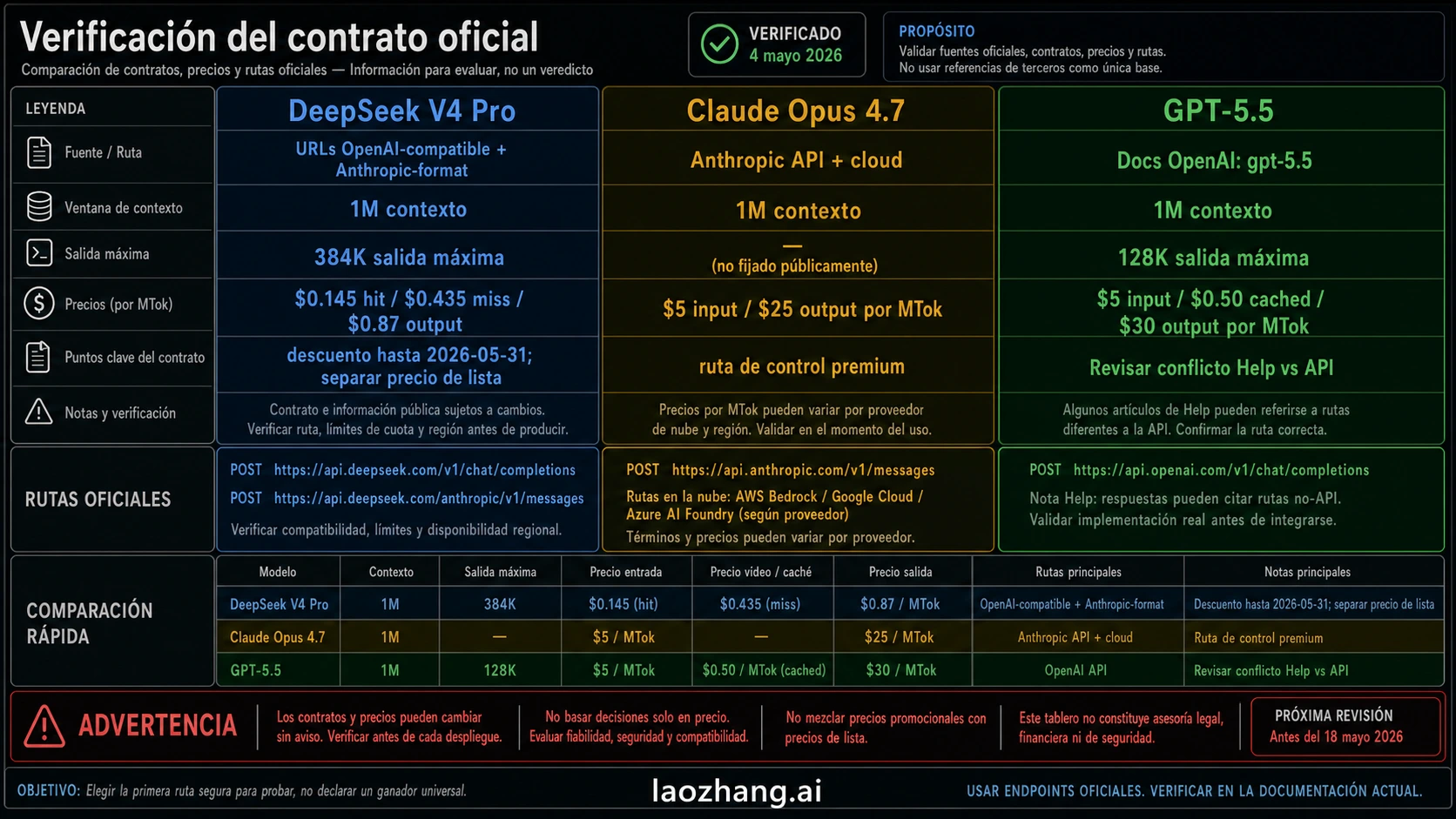
| Punto de contrato | GPT-5.5 | Claude Opus 4.7 | DeepSeek V4 Pro |
|---|---|---|---|
| Ruta principal | OpenAI developer platform y superficies OpenAI-native de producto/herramientas | Anthropic API, Claude products y grandes cloud partners | DeepSeek API más model card oficial open-weight |
| Etiqueta a verificar | OpenAI docs listan GPT-5.5, GPT-5.5 Chat, GPT-5.5 Thinking y variantes con fecha | Verifica el model ID actual en Anthropic docs o consola antes de desplegar | DeepSeek API docs listan deepseek-v4-pro |
| Contexto y salida | OpenAI docs indican 1M de contexto y 128K de salida máxima | Anthropic coloca Opus 4.7 en long-context y agent work exigente, con límites dependientes de la ruta | DeepSeek docs indican 1M de contexto y 384K de salida máxima |
| Dueño del precio | OpenAI docs indican 5 USD input, 0,50 USD cached input y 30 USD output por millón de tokens para la fila standard short-context API | Anthropic launch material indica 5 USD input y 25 USD output por millón de tokens | DeepSeek docs indican descuento hasta 2026-05-31: 0,145 USD cache-hit input, 0,435 USD cache-miss input y 0,87 USD output |
| Límite visible | Una nota antigua de OpenAI Help Center decía que GPT-5.5 no salía a API ese día, mientras los developer docs actuales lo listan. Producción exige comprobación actual. | El precio premium solo se justifica si baja defectos, revisión o riesgo de despliegue. | Una URL compatible no prueba paridad de comportamiento con OpenAI o Anthropic. |
Las páginas de modelos y comparación de OpenAI controlan el contrato API de GPT-5.5. La nota antigua de Help Center sigue importando porque crea un conflicto fechado: describía el rollout de ChatGPT/Codex y decía que GPT-5.5 no salía a API ese día. Si vas a enrutar tráfico pagado, comprueba documentación actual, visibilidad de modelo, límites, consola y llamada real en tu organización.
El lanzamiento de Claude Opus 4.7 de Anthropic dice que el modelo está disponible en Claude products, Anthropic API, Amazon Bedrock, Google Vertex AI y Microsoft Foundry, con precio de 5 USD input y 25 USD output por millón de tokens. La documentación de precios de DeepSeek lista V4 Pro, URL de formato OpenAI y Anthropic, 1M de contexto, 384K de salida máxima y la ventana de descuento temporal. La model card de DeepSeek añade el lado open-weight: 1,6T parámetros totales, 49B activados y 1M de contexto.
Elige según el trabajo real
La forma limpia de comparar DeepSeek V4 Pro, Claude Opus 4.7 y GPT-5.5 es mapearlos al trabajo que vas a ejecutar. Un modelo fuerte en un bucle de herramientas OpenAI-native no tiene por qué ser el control más seguro para un agente desplegable. Un modelo muy barato por millón de tokens puede salir caro si aumenta retries, defectos o carga de revisión.
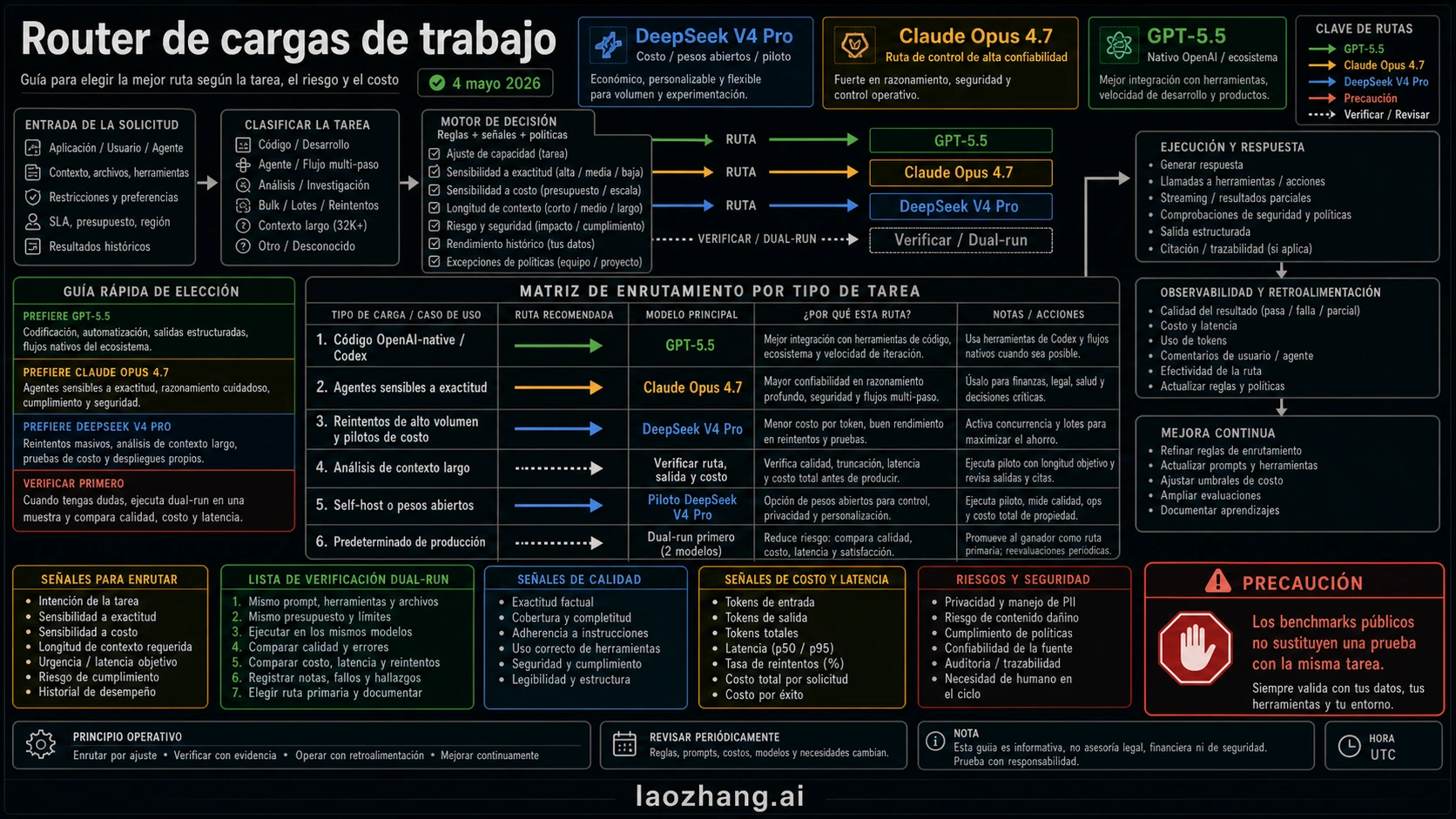
| Workload | Primer modelo a probar | Por qué | Qué medir |
|---|---|---|---|
| OpenAI-native coding, Codex, Responses API tools, structured outputs | GPT-5.5 | Está más cerca del tool surface y los controles de cuenta de OpenAI. | Accepted diffs, tool recovery, format stability, review time, token cost. |
| Correctness-sensitive coding agents o multi-step orchestration | Claude Opus 4.7 | Es el control premium cuando el coste de fallo supera el coste de modelo. | Defect severity, tool-call reliability, rollback behavior, reviewer trust. |
| High-volume retries, batch exploration, cheap long-context tests | DeepSeek V4 Pro | El descuento temporal y la ruta open-weight justifican un cost pilot. | Task success rate, retry rate, latency under load, route fidelity. |
| Documentos, repositorios o evidence analysis de contexto largo | Route-specific test | Las tres rutas soportan gran contexto de maneras distintas. | Truncation, recall quality, output length, cost at full prompt size. |
| Self-host, private cloud, open-weight governance | DeepSeek V4 Pro | GPT-5.5 y Opus son rutas hosted cerradas; DeepSeek ofrece open-weight path. | Deployment complexity, security review, inference cost, maintenance burden. |
| Default ya en producción | Dual-run | El default existente ya tiene historia operativa y fallos conocidos. | Regression count, total cost, human minutes, fallback success. |
Para desarrollo nativo en OpenAI, GPT-5.5 merece la primera prueba porque está más cerca de Codex, herramientas de OpenAI, salida estructurada, archivos y controles de cuenta. Eso no lo convierte en default universal para toda API, pero sí reduce el coste de observarlo cuando el sistema ya depende de OpenAI.
Para fiabilidad premium, Claude Opus 4.7 es la línea de control. Encaja en multi-tool orchestration, cambios complejos de código, revisión de documentos o visión y despliegues conservadores. Si Opus cuesta más pero reduce defectos serios y minutos de revisión senior, el premium puede ser racional.
Para presión de coste y open-weight governance, DeepSeek V4 Pro entra en piloto. El descuento merece medición, los endpoints compatibles reducen fricción y la model card importa para equipos con requisitos de control. Pero precio y forma de endpoint no prueban que recupere errores de herramientas, mantenga JSON, recuerde contexto o se comporte igual con SDKs.
El precio es una entrada, no la decisión
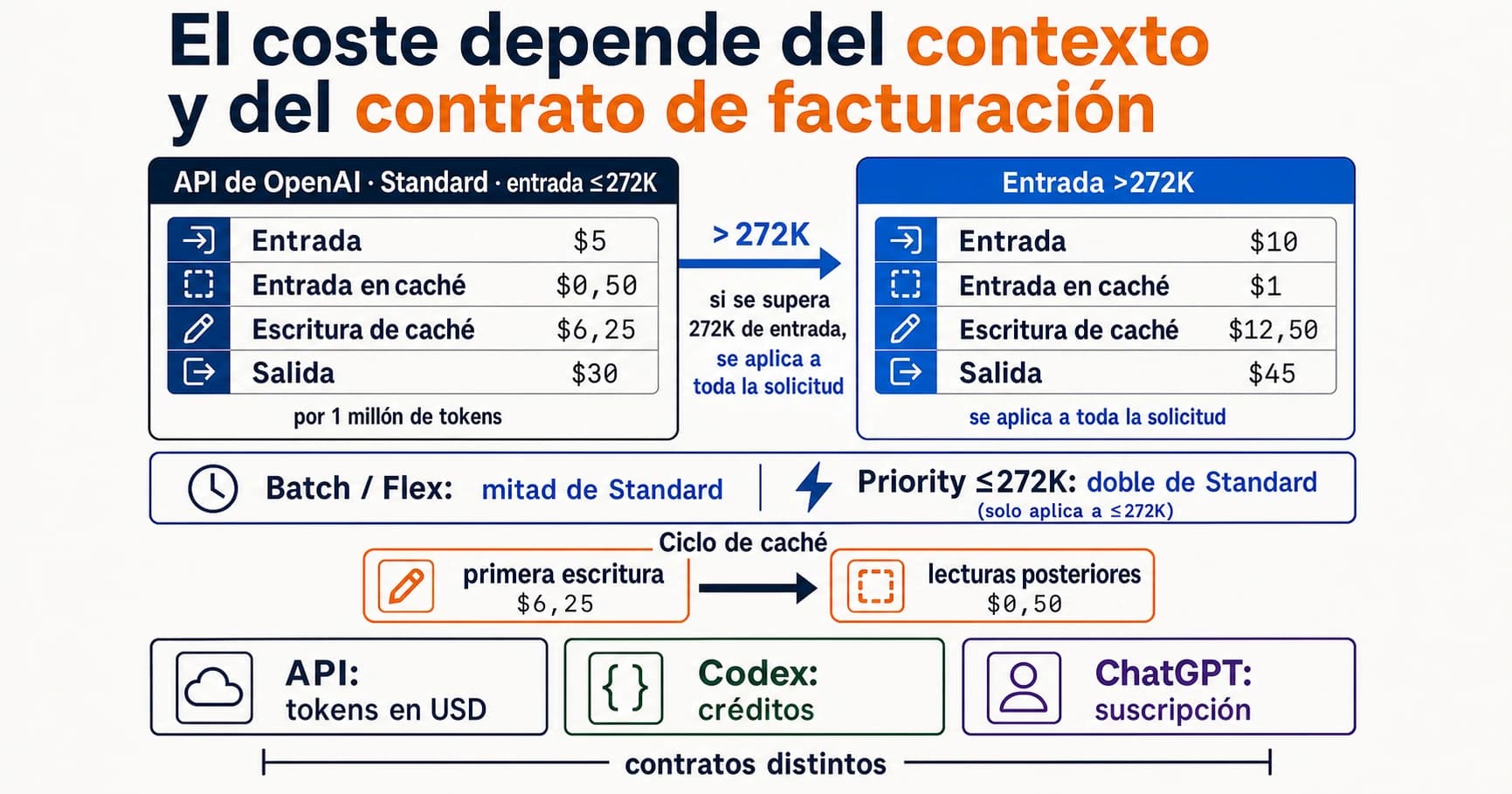
DeepSeek V4 Pro tiene la ventaja de precio más visible. Los docs actuales de DeepSeek muestran descuento V4 Pro hasta el 31 de mayo de 2026 a las 15:59 UTC: 0,145 USD por millón de input tokens con cache hit, 0,435 USD con cache miss y 0,87 USD por output tokens. Las listas de precio sin descuento son 0,58, 1,74 y 3,48 USD. Un piloto iniciado durante el descuento puede cambiar mucho cuando termine la ventana.
GPT-5.5 no es un modelo barato según la tabla actual de OpenAI: la fila standard short-context API indica 5 USD input, 0,50 USD cached input y 30 USD output por millón de tokens. El long-context pricing debe revisarse como otra fila de ruta, no mezclarse con esta fila standard. Claude Opus 4.7 aparece en el lanzamiento de Anthropic con 5 USD input y 25 USD output. En precio hosted bruto, DeepSeek es mucho más barato, Claude es el control premium y GPT-5.5 es la ruta frontier cara de OpenAI-native.
La fila de precio no contesta el despliegue por sí sola. Un modelo barato se vuelve caro si necesita más intentos, rompe structured output, genera más revisión humana o exige mantener otra infraestructura. Un modelo caro puede ser más barato por completed job si reduce minutos humanos y generaciones fallidas.
| Variable de coste | Por qué importa |
|---|---|
| Input y cached input | Long prompts, contexto repetido y cache behavior cambian el ranking. |
| Output length | El precio de salida de GPT-5.5 y el max output de 384K de DeepSeek afectan de forma distinta a long generations. |
| Retry rate | Un token barato pierde si el modelo necesita varios intentos. |
| Human review time | En coding y agentes, lo más caro suele ser la persona senior que lee el resultado. |
Para presupuestar, usa tareas representativas. Ejecuta los mismos prompts, archivos, herramientas, permisos y budget. Cuenta input, cached input, output, retries, task-level cost, p95 latency y review minutes. Si DeepSeek conserva ventaja en la tarea completa, puede ampliarse. Si Opus o GPT-5.5 reducen revisión y rollback, el precio alto puede justificarse.
Lee benchmarks sin convertirlos en corona
Los benchmarks públicos sirven cuando se parecen a tu trabajo. Coding-agent rows, terminal-task evaluations, browsing/research scores, long-context tests y math/security benchmarks miden capacidades distintas. Un buen resultado de GPT-5.5 en un benchmark OpenAI-native es una razón para probarlo en esa ruta. No demuestra que DeepSeek V4 Pro no pueda ser un piloto de coste ni que Opus 4.7 ya no sea el control premium.
Lo mismo aplica al revés. Un claim de price/performance de DeepSeek es una razón para construir un pilot harness. No prueba replacement en un agente de alto riesgo. Un claim de lanzamiento de Anthropic es una razón para incluir Opus como control. No prueba que siempre debas pagar premium si GPT-5.5 o DeepSeek superan la misma tarea.
Usa esta escalera de evidencia:
- Official docs deciden si existe la ruta, cómo se llama, cuánto cuesta y qué límites tiene.
- Provider or third-party benchmarks sugieren qué workloads probar.
- Same-task harness decide si la candidata puede ser default.
- Production rollout comprueba si la mejora sobrevive a permisos, latencia y fallos reales.
La escalera también evita errores de compatibilidad. DeepSeek ofrece OpenAI-compatible y Anthropic-format API URLs, pero la forma de la URL no es paridad de comportamiento. Tool calling, streaming, timeouts, tokenization, output format, safety behavior, retries y SDK edge cases pueden diferir. Compatibility baja el coste inicial, pero no elimina validation.
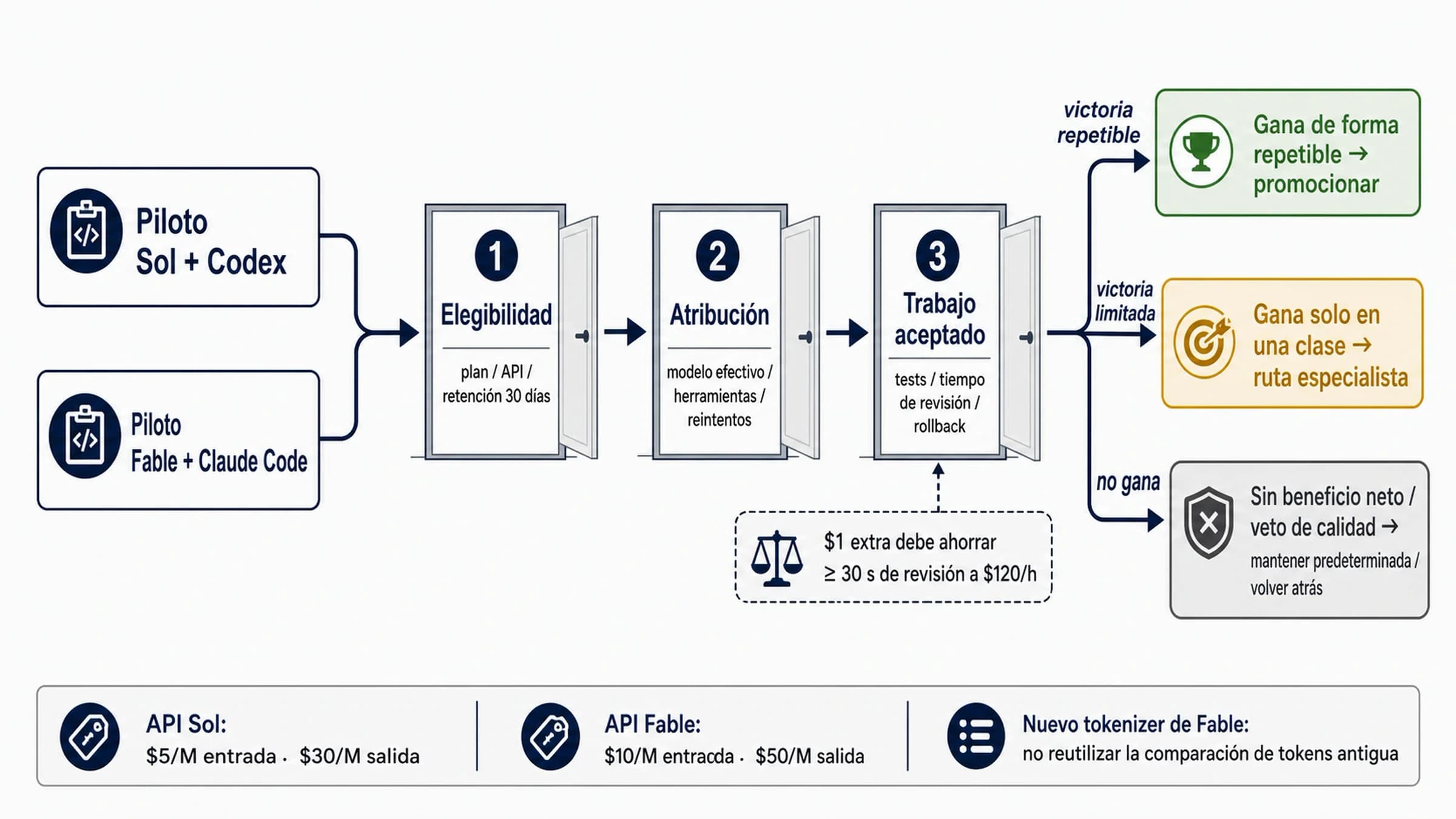
Haz un piloto con la misma tarea antes de cambiar
Un piloto práctico puede ser pequeño. Lo importante es que sea justo. No des a una ruta mejor prompt, más budget o tareas más fáciles y luego declares ganador. La candidata debe competir con los mismos prompts, tools, files, budgets y acceptance tests.

| Pilot gate | Qué hacer | Pass condition |
|---|---|---|
| Route check | Confirmar model label, endpoint, account access, region, quota y fallback. | El equipo puede llamar la ruta que planea desplegar. |
| Same prompt and tools | Usar los mismos system prompt, files, tools, permissions y task budget cuando la superficie lo permita. | La diferencia viene del model behavior, no de un harness mejor. |
| Representative tasks | Incluir easy, hard, long-context, output-format y failure-prone tasks. | La muestra representa el trabajo que cuesta dinero o revisión. |
| Defect scoring | Clasificar correctness, severity, security risk y recovery effort. | La candidata reduce fallos de alta severidad. |
| Review-time scoring | Contar human review minutes y accepted-result rate. | La candidata reduce total work. |
| Cost and latency | Medir input, cached input, output, retries, task-level cost y p95 latency. | El ahorro sobrevive al full-task accounting. |
| Rollback threshold | Definir qué failure rate, latency o cost dispara fallback. | La ruta anterior puede volver sin reconstruir el sistema. |
Un equipo que ya usa GPT-5.4, Opus 4.7 u otro default estable debe exigir más que "el modelo nuevo impresiona". Mantén el default, ejecuta la candidata en sombra y sube tráfico solo si baja el trabajo total, no crea regresiones graves y tiene rollback claro.
Un equipo que elige su primera ruta puede correr GPT-5.5 y Opus 4.7 en high-risk tasks, y luego añadir DeepSeek V4 Pro donde importan coste u open weights. Si DeepSeek supera las mismas tasks, se convierte en candidata seria para ese workload. Si falla y requiere reparación manual, permanece en exploration lane.
Decisiones cercanas
La comparación de DeepSeek V4 Pro, Claude Opus 4.7 y GPT-5.5 decide primer test, control lane y production switch rule. Las preguntas más estrechas o más amplias conviene separarlas.
Si la elección real es solo OpenAI contra Anthropic, usa GPT-5.5 vs Claude Opus 4.7. Puede dedicar más espacio a OpenAI-native testing frente a Anthropic deployability.
Si quieres incluir Kimi en el pool barato, usa Kimi K2.6 vs DeepSeek V4 vs GPT-5.5 vs Claude Opus 4.7. La asignación de cuatro rutas necesita su propio marco.
Si aún comparas rutas frontier API anteriores, usa Claude Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro. Si necesitas contexto de lanzamiento y ruta de DeepSeek, empieza con DeepSeek V4.
Preguntas frecuentes
¿GPT-5.5 es mejor que Claude Opus 4.7 y DeepSeek V4 Pro?
GPT-5.5 es la mejor primera prueba cuando el trabajo es OpenAI-native, sobre todo coding, tool workflows, Codex o structured output. No es un ganador universal. Claude Opus 4.7 sigue como control premium y DeepSeek V4 Pro debe validarse como piloto de coste u open-weight.
¿DeepSeek V4 Pro es más barato?
Sí, según el descuento API documentado actualmente. Pero la ventana de descuento tiene fecha de cierre y debe separarse del list price. El completed-task cost depende de calidad, retries, latency y review time.
¿Conviene usar Claude Opus 4.7 para coding agents?
Usa Claude Opus 4.7 primero cuando el agent es correctness-sensitive, se despliega por Anthropic o cloud routes y el coste de review o rollback es alto. Usa GPT-5.5 primero para OpenAI-native work. Usa DeepSeek V4 Pro como piloto cuando coste u open weights pesan más.
¿DeepSeek V4 Pro puede reemplazar a Claude Opus 4.7?
Solo después de probar la misma tarea en tu workload. DeepSeek V4 Pro puede ser candidato serio para high-volume u open-weight work, pero precio y endpoints compatibles no prueban replacement productivo.
¿GPT-5.5 está disponible por API?
Los OpenAI developer docs actuales listan GPT-5.5 model entries y detalles de API price/context. Una nota antigua de OpenAI Help Center decía que GPT-5.5 no salía a API ese día de rollout. Antes de tráfico productivo, verifica current docs, account access, limits y console behavior.
¿Qué modelo pruebo primero para long-context work?
Prueba la ruta que encaja con tu necesidad de deployment. OpenAI y DeepSeek docs listan 1M context para rutas relevantes, y Anthropic sitúa Opus 4.7 en demanding long-context agent work. Mide truncation, recall, output length, latency y full-task cost.
¿Cuál es la regla más segura para cambiar production default?
No cambies por public benchmarks, price gaps o launch excitement. Ejecuta dual-run con los mismos prompts, tools, files, task budgets y acceptance tests. Promueve solo cuando reduce total work y existe rollback path.
La respuesta útil es un route plan: GPT-5.5 para OpenAI-native first tests, Claude Opus 4.7 para premium deployable control y DeepSeek V4 Pro para cost u open-weight pilots. La production default se gana en las mismas tareas.