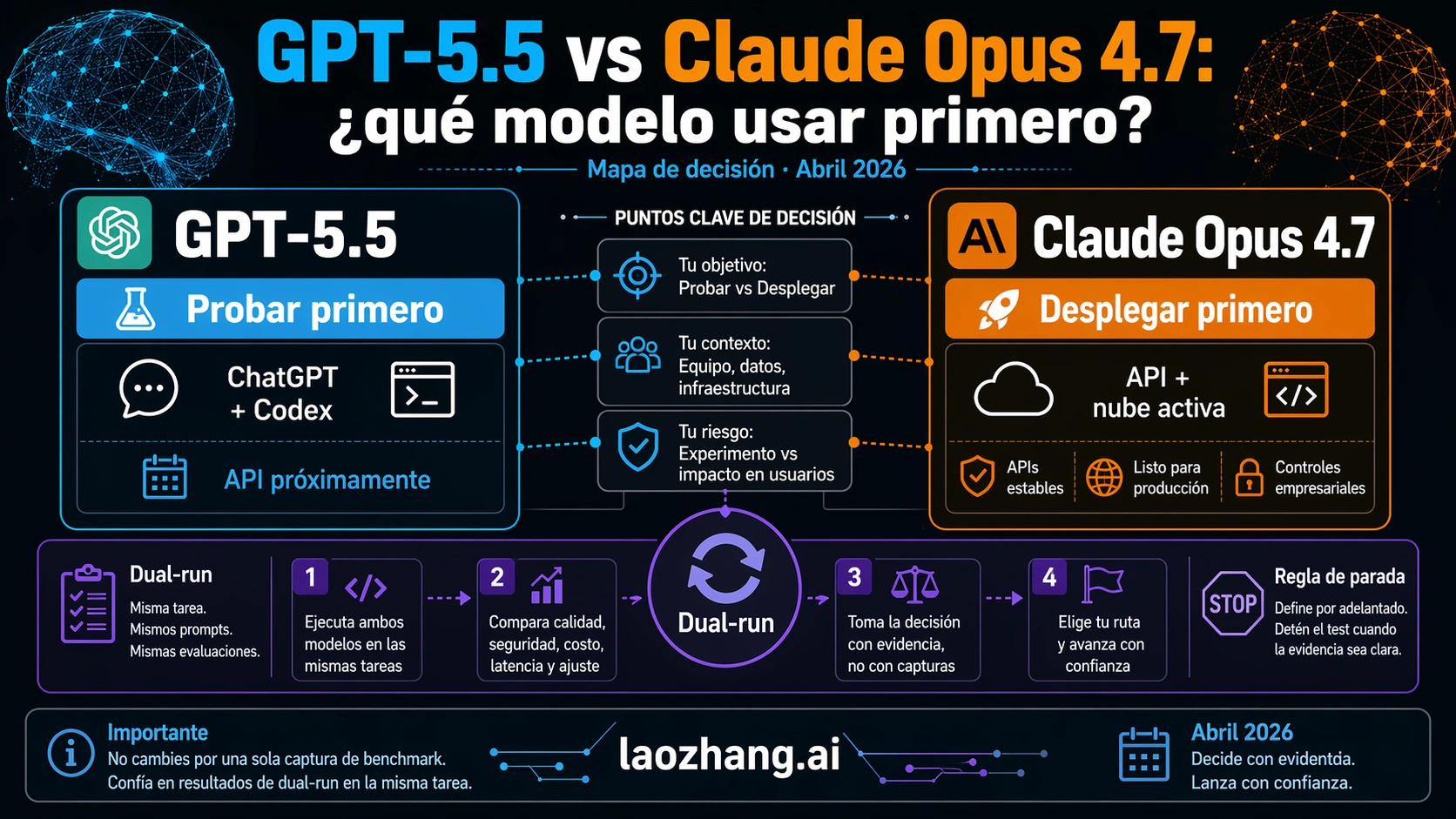
GPT-5.5 y Claude Opus 4.7 todavía no son una elección API simétrica. Al 24 de abril de 2026, GPT-5.5 está disponible en ChatGPT y Codex para superficies de pago de OpenAI, pero el acceso API aparece como coming soon. Claude Opus 4.7 ya está disponible mediante Anthropic API, Amazon Bedrock, Google Vertex AI y Microsoft Foundry.
Por eso la primera pregunta no debería ser "quién gana". La pregunta útil es dónde corre tu trabajo. Si el flujo vive en ChatGPT, Codex, revisión humana y herramientas OpenAI-native, GPT-5.5 merece la primera prueba. Si necesitas API de producción, cloud endpoint, logs, permisos, rollout y fallback hoy, Claude Opus 4.7 debe entrar primero en evaluación. Si vas a reemplazar un modelo por defecto que ya sostiene trabajo pagado, ambos modelos deben correr las mismas tareas antes del cambio.
| Ruta | Primer movimiento | Por qué encaja | Regla de parada |
|---|---|---|---|
| Pruebas en ChatGPT o Codex | Probar GPT-5.5 primero | Es la nueva ruta de OpenAI para trabajo profesional y agentic coding dentro de superficies que ya están activas. | No planifiques una migración API de producción hasta que el API oficial esté abierto para tu cuenta. |
| API de producción o cloud deployment | Evaluar Claude Opus 4.7 primero | Ya está disponible en Claude API, Bedrock, Vertex AI y Microsoft Foundry. | No cambies un default premium por una tabla de benchmarks de la semana de lanzamiento. |
| Workloads con mucha salida o presupuesto sensible | Calcular ambas con prompts reales | GPT-5.5 aparece con precio API coming soon de $5 input y $30 output por millón de tokens; Opus 4.7 está live con $5 input y $25 output. | No apruebes gasto sin revisar cache, batch, region, tokenizer y retries. |
| Reemplazo de un default existente | Hacer dual-run antes | El valor del cambio depende de fallos, minutos de revisión y coste de rollback, no del titular de lanzamiento. | Sin same repo, same prompts, same tool budget y same tests, no hay cambio de default. |
Respuesta rápida
Si quieres la decisión operativa antes de los detalles, decide por ruta y no por nombre de modelo.
| Necesidad | Usa primero | Motivo | Qué volver a revisar |
|---|---|---|---|
| Trabajas sobre todo en ChatGPT, Codex o flujos OpenAI-native de código | GPT-5.5 | OpenAI presenta GPT-5.5 como su nueva ruta frontier para professional y agentic work, y esas superficies ya están disponibles. | API status, model ID, límites de cuenta y restricciones de producción. |
| Necesitas un API o endpoint cloud en producción hoy | Claude Opus 4.7 | Anthropic ya lo tiene en Claude API y en plataformas cloud principales. | Latencia, región, rate limits, uso de tokens y política de despliegue. |
| Tu carga genera mucha salida o el presupuesto es crítico | Opus 4.7 como baseline live | Anthropic publica $5 input y $25 output. GPT-5.5 tiene precio coming-soon, así que debe revalidarse al abrir API. | Cached input, batch discounts, regional multipliers y tokenizer effects. |
| Quieres preparar un pilot de GPT-5.5 API | Espera la ruta callable oficial | Un precio coming soon ayuda a presupuestar, pero no es un endpoint de producción. | OpenAI docs y pricing page el día de inicio. |
| Quieres cambiar un default que funciona | Dual-run en ambos modelos | Las comparativas de lanzamiento no miden tus failure modes, review load ni recovery cost. | Same task set, same tools, same acceptance tests y same cost accounting. |

La conclusión no es "GPT-5.5 gana" ni "Claude gana". GPT-5.5 es la primera prueba cuando el trabajo se queda en superficies live de OpenAI. Claude Opus 4.7 es la primera ruta deployable cuando necesitas API o cloud ahora. Cualquier migración que afecte dinero, clientes, SLA o automatización debe hacer que los dos modelos compitan sobre las mismas tareas reales.
Disponibilidad y precio son la primera división
La comparación de coste empieza por disponibilidad. Si un modelo ya corre en la ruta API que necesitas y el otro sigue como coming soon, la primera decisión no es una decisión de benchmark. Un plan de producción basado en una ruta no disponible se puede romper por model ID, rate limits, tool support, billing behavior o permisos de cuenta.
| Contrato | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| Superficie de usuario actual | OpenAI indica rollout en ChatGPT y Codex para usuarios de pago. | Anthropic muestra Opus 4.7 disponible en productos Claude. |
| Estado API al 24 de abril de 2026 | API access coming soon. No trates el precio como prueba de endpoint live. | Live en Anthropic API y major cloud platforms. |
| API model ID | Revisa OpenAI docs cuando la ruta API esté live; no inventes un nombre. | claude-opus-4-7 en el model overview de Anthropic. |
| Precio API estándar | Coming soon: $5 input, $0.50 cached input y $30 output por millón de tokens. | $5 input y $25 output por millón de tokens, con opciones de cache y batch. |
| Contexto y salida | Revisa cuando GPT-5.5 API esté live para tu cuenta. | 1M context y 128k max output en Messages API. |
| Variante alta | GPT-5.5 Pro es una ruta futura de mayor precisión y coste, no la comparación API base de hoy. | Opus 4.7 ya es la ruta premium de Opus. |
Esa tabla cambia el movimiento por defecto. Un desarrollador que construye una integración de producción hoy puede poner Opus 4.7 en un live evaluation path. Un equipo que quiere GPT-5.5 por API debe guardar su harness y esperar la ruta oficial callable, no construir el despliegue sobre rumores, capturas o model IDs no oficiales.
El precio de salida también importa. Si GPT-5.5 llega al API con el precio listado ahora, su output side será más caro que el output live de Opus 4.7. Eso no significa que Opus sea siempre más barato: cache, batch, longitud del prompt, tokenizer, retries y revisión humana cambian la factura. Sí significa que los trabajos output-heavy no deben asumir que el modelo nuevo será el default presupuestario.
Cómo leer los benchmarks
Una tabla de benchmarks solo ayuda cuando la conectas con el workload. Las filas publicadas por un proveedor son evidencia, no una corona neutral. En una decisión real se mezclan vídeos, comentarios rápidos, noticias, páginas traducidas y titulares de "supera a Claude"; la decisión de ingeniería exige separar coding agents, terminal workflows, browsing, long-context review, seguridad y production API.
| Benchmark | Resultado público de GPT-5.5 | Comparador Claude Opus 4.7 | Lectura práctica |
|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | 69.4% | Razón fuerte para probar GPT-5.5 primero en Codex o flujos terminal-style de OpenAI. |
| GDPval-agentic | 84.9% | 80.3% | Útil para tareas profesionales, pero requiere revisión específica de dominio. |
| OSWorld-Verified | 78.7% | 78.0% | Tan cercano que la ruta de despliegue y el harness pesan más que la fila. |
| BrowseComp | 84.4% | Revisar source table | Señal de browsing/research, no decisión API por sí sola. |
| FrontierMath Tier 4 | 35.4% | Revisar source table | Buen input para pilot de razonamiento, no sustituto de workload tests. |
| CyberGym | 81.8% | Revisar source table | Importa solo si tus tareas se parecen al benchmark. |
Estos datos justifican tomar GPT-5.5 en serio para agentic coding y tareas profesionales. No justifican un reemplazo general. OpenAI controla el contexto de su tabla, Anthropic controla el contrato API de Opus, y tu workload controla la decisión final.
El error más común es comparar un live API model y un not-yet-live API model como si ambos fueran equally deployable. Si eliges qué probar en ChatGPT o Codex, las filas de GPT-5.5 son muy relevantes. Si eliges qué poner detrás de una ruta API hoy, availability sigue siendo el primer filtro y Opus 4.7 tiene el contrato de deployability más claro.
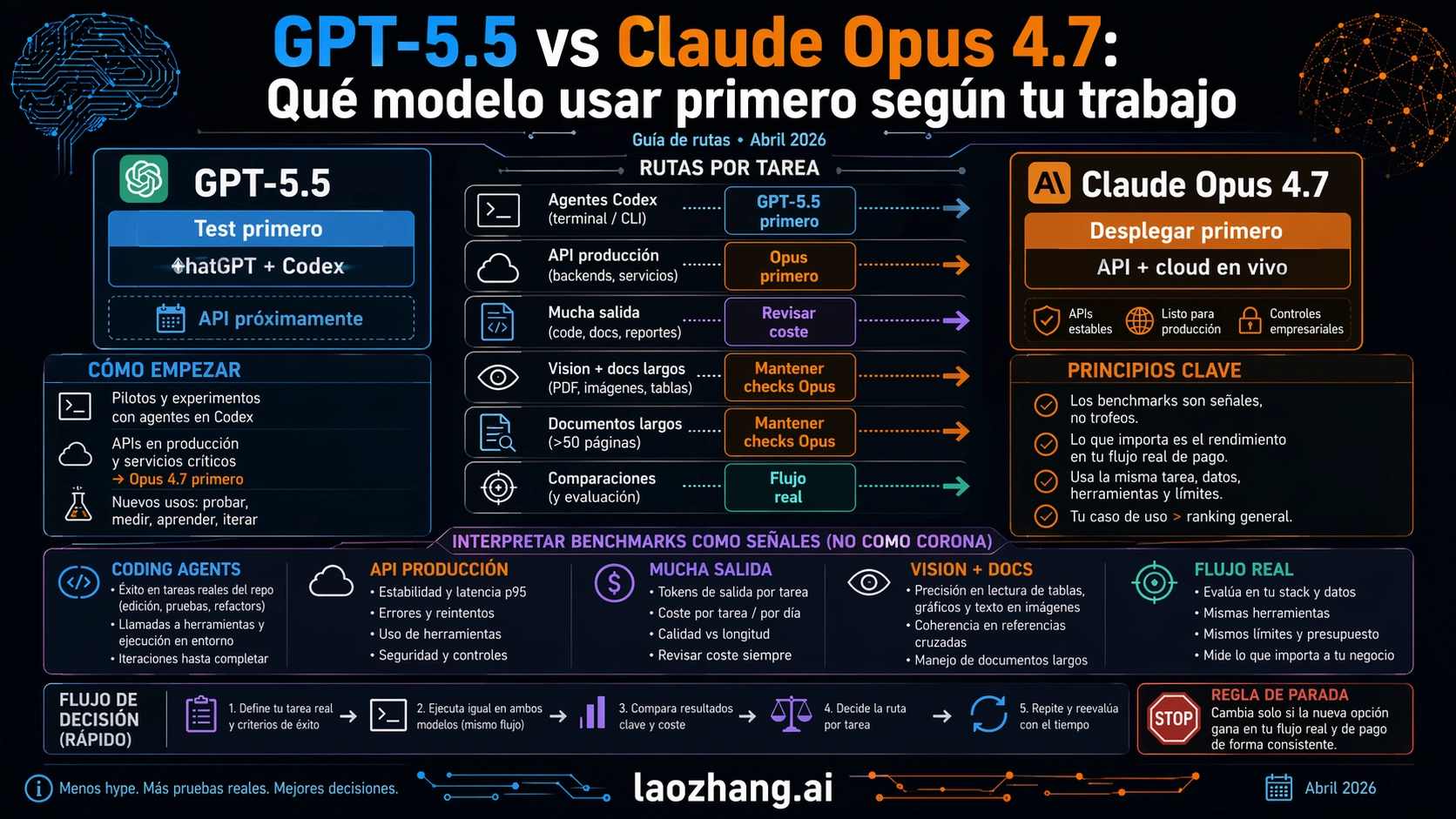
Qué modelo encaja mejor para coding y agents
Usa GPT-5.5 primero cuando la ruta real es OpenAI-native: ChatGPT para análisis, Codex para trabajo de repositorio, terminal tasks, code review o un workflow donde la experiencia del operador importa tanto como el API. En ese caso la pregunta correcta es si GPT-5.5 reduce review load y completa tareas más difíciles dentro de herramientas que ya usas. Puedes responderlo ahora porque la superficie está live.
Usa Claude Opus 4.7 primero cuando la ruta real es API-first, Claude-native o cloud-provider-first. Anthropic lo posiciona alrededor de coding, agents, long context, high-resolution images y higher-effort control. Pero lo más importante es que la ruta ya es deployable. Si necesitas server workflow, scheduled jobs, logs, permisos, regiones, rollout y rollback, ese contrato vale más que el entusiasmo de una API coming soon.
La prueba justa es sencilla. Elige diez tareas que ya consumen tiempo de revisión. Ejecuta GPT-5.5 en la superficie OpenAI donde está live. Ejecuta Opus 4.7 mediante el API o cloud route que usarías en producción. Mide first-pass correctness, tool recovery, format stability, token use, latency, human review minutes y severidad de fallos. Promueve el modelo solo si reduce el trabajo total, no solo si impresiona en una demo.
Si la prueba se basa en repo edits, terminal tasks y OpenAI-native coding, GPT-5.5 merece el primer asiento. Si se trata de un production agent con API budgets, cloud routing, long context y rollout controlado, Opus 4.7 merece el primer asiento.
Contexto, salida y riesgo de migración
Context y output limits importan más cuando la tarea no es un chat corto. Claude Opus 4.7 tiene un live contract claro: Anthropic documenta 1M context window y 128k max output en Messages API. Sus pricing docs también indican que Opus 4.7 incluye el full 1M context at standard pricing, dato relevante porque muchas páginas secundarias mezclan supuestos antiguos de long-context premium.
El contexto API, límites de producción, rate limits, tools y billing behavior de GPT-5.5 deben revalidarse cuando el API esté live para tu cuenta. Hasta entonces, la redacción honesta es planned API route o coming-soon API pricing, no deploy today. Esto no es un detalle menor: model IDs, context windows, limits, tools y billing son justo lo que rompe una migración.
Opus 4.7 también tiene migration hazards. Las notas actuales de Anthropic dicen que non-default sampling parameters como temperature, top_p y top_k devuelven 400; old extended-thinking budget fields fueron removed; y el tokenizer nuevo puede usar hasta cerca de 35% more tokens for fixed text según el contenido. No son razones para evitar Opus. Son razones para probar el harness real antes de cambiar una model string.
En coding agents largos, revisión documental y production workflows, la pregunta no es solo quién tiene más contexto. La pregunta es qué ruta sostiene el contexto necesario, produce la salida necesaria, cabe en el coste y falla de una forma que tu sistema pueda recuperar.
Si ya usas GPT-5.4 u Opus 4.7
Si ya usas GPT-5.4 por API, no la quites solo porque GPT-5.5 se lanzó. GPT-5.5 es el nuevo pilot OpenAI-native correcto, pero GPT-5.4 sigue siendo el baseline deployable de OpenAI API hasta que GPT-5.5 API esté live para tu cuenta. Si tu decisión amplia sigue siendo OpenAI, Anthropic o Google route, la comparación Claude Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro es la página adyacente más adecuada.
Si ya usas Claude Opus 4.7, el lanzamiento de GPT-5.5 debe activar un pilot, no un replacement automático. Conserva Opus 4.7 como ruta deployable si el contrato API, cloud deployment y long context fueron las razones de tu elección. Luego compara GPT-5.5 dentro de superficies live de OpenAI y decide si las mejoras justifican reabrir la ruta de producción cuando el API sea oficial.
Si tu pregunta real es la migración dentro de Anthropic, no la selección OpenAI-vs-Anthropic, usa la guía más estrecha Claude Opus 4.7 vs Claude Opus 4.6. Esa página cubre mejor same-family upgrade, prompt behavior, token drift y cost changes.
Plan práctico de cambio

Un model switch necesita release plan. El plan mínimo útil tiene seis comprobaciones.
| Comprobación | Qué hacer | Condición de paso |
|---|---|---|
| Route check | Confirmar si el modelo está live en la superficie necesaria: ChatGPT, Codex, API o cloud. | Ningún plan de producción depende de un endpoint coming soon. |
| Task set | Elegir representative tasks, no demos cherry-picked. | Incluye tareas fáciles, difíciles, long-context, formato de salida y fallos frecuentes. |
| Harness parity | Ejecutar ambos modelos con same prompts, tools, files y task budgets donde sea posible. | Las diferencias vienen del modelo, no de un setup mejor para un lado. |
| Quality score | Medir correctness, recovery, formatting y human review minutes. | El ganador reduce total work, no solo first impression. |
| Cost score | Medir input, cached input, output, retries y task-level cost. | La ruta elegida es pagable bajo el workload real. |
| Rollback route | Mantener old model o fallback route durante rollout. | Una migración fallida se puede revertir sin rehacer pipeline. |
Para un equipo pequeño, esto puede ser una tarde de testing disciplinado. Para enterprise workflow, debería dividirse en private pilot, shadow run, limited production route y default switch. El umbral es el mismo: no cambies porque el modelo sea nuevo; cambia porque reduce fallos, tiempo o coste en el trabajo que realmente ejecutas.
FAQ
¿GPT-5.5 es mejor que Claude Opus 4.7?
Depende de la ruta y del workload. GPT-5.5 es mejor primera prueba para ChatGPT y Codex en flujos OpenAI-native. Claude Opus 4.7 es mejor primera ruta de despliegue si necesitas API o cloud endpoint live hoy.
¿GPT-5.5 está disponible en API?
Al 24 de abril de 2026, OpenAI describe GPT-5.5 API access como coming soon. La pricing page sirve para planificar, pero no demuestra que el modelo sea callable en producción hoy.
¿Qué modelo es más barato?
Para live API deployment today, Opus 4.7 tiene el precio más claro: $5 input y $25 output por millón de tokens, antes de cache, batch y ajustes regionales. OpenAI lista GPT-5.5 como coming soon a $5 input y $30 output, por lo que workloads output-heavy deben recalcular con prompts reales cuando el API esté live.
¿Cuál es mejor para coding agents?
GPT-5.5 debe probarse primero para Codex y OpenAI-native coding workflows. Opus 4.7 debe probarse primero para Claude API agents, cloud deployment, long-context agent loops y equipos que necesitan endpoint de producción ahora.
¿Opus 4.7 todavía gana en algo?
Sí. Gana hoy en deployability para API y cloud routes, y tiene un contrato live claro de 1M context, 128k output y disponibilidad en varias plataformas.
¿Debo esperar al API de GPT-5.5?
Espera si el objetivo es específicamente una migración de OpenAI API a GPT-5.5. No esperes si tu necesidad inmediata es una ruta API de producción y Opus 4.7 ya encaja. Mantén GPT-5.5 en el plan de pilot y revisa OpenAI docs cuando el API esté live.
¿Qué pasa con GPT-5.5 Pro?
GPT-5.5 Pro es una ruta futura de mayor precisión y precio API listado mucho más alto. No es la comparación por defecto para la mayoría de equipos que decide entre GPT-5.5 y Claude Opus 4.7 hoy. Evalúala aparte solo si la tarea justifica ese coste.
Usa GPT-5.5 primero cuando el trabajo vive dentro de superficies live de OpenAI. Usa Claude Opus 4.7 primero cuando necesitas API o cloud route deployable ahora. Si hay presupuesto o reliability en juego, haz que ambos modelos se ganen el cambio sobre las mismas tareas.