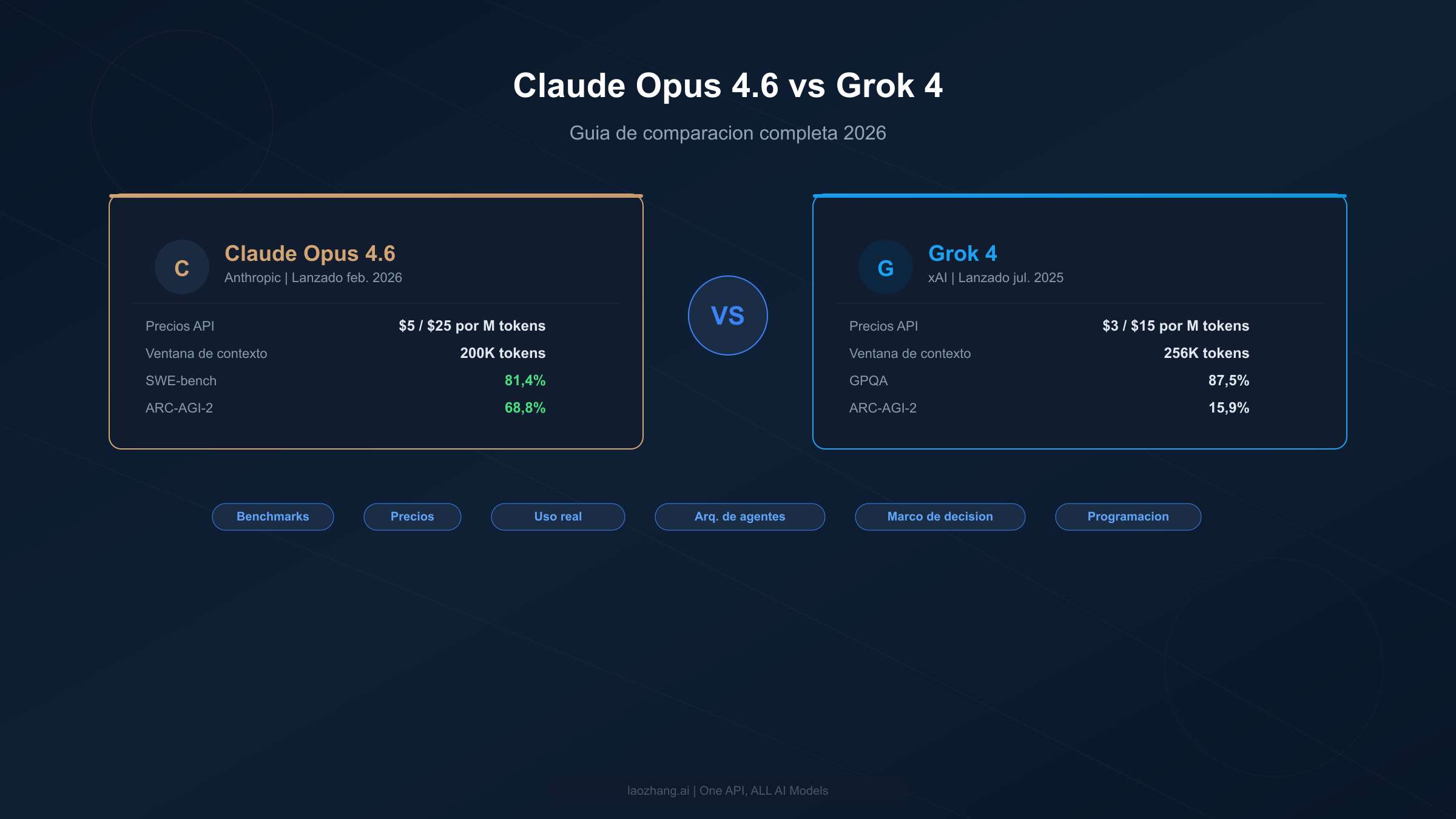
Claude Opus 4.6 supera a Grok 4 en la mayoría de los benchmarks — incluyendo SWE-bench (81,4% vs comparable), ARC-AGI-2 (68,8% vs 15,9%) y tareas de razonamiento — pero cuesta un 67% más a $5/$25 por millón de tokens en comparación con los $3/$15 de Grok 4. Para desarrolladores con presupuesto ajustado, las variantes Grok 4 Fast ofrecen acceso API por solo $0,20/$0,50 por millón de tokens con una ventana de contexto de 2M de tokens, convirtiéndolas en una de las opciones de modelo frontera más rentables disponibles en 2026.
Resumen rápido — Tabla comparativa
Elegir entre Claude Opus 4.6 y Grok 4 se reduce, en última instancia, a lo que priorizas: rendimiento bruto en programación y razonamiento, o eficiencia de costes con sólidas capacidades matemáticas. Ambos modelos representan la frontera de la capacidad de IA en 2026, pero sirven a audiencias y casos de uso claramente diferentes. La tabla a continuación ofrece una instantánea de cómo se comparan en las dimensiones más importantes, desde precios API hasta rendimiento en benchmarks y madurez del ecosistema. Úsala como punto de partida y luego profundiza en las secciones que correspondan a tus necesidades específicas.
| Característica | Claude Opus 4.6 | Grok 4 | Ganador |
|---|---|---|---|
| Precio API entrada | $5,00/M tokens | $3,00/M tokens | Grok 4 |
| Precio API salida | $25,00/M tokens | $15,00/M tokens | Grok 4 |
| Ventana de contexto | 200K tokens | 256K tokens | Grok 4 |
| SWE-bench | 81,4% | ~72% (est.) | Claude |
| ARC-AGI-2 | 68,8% | 15,9% | Claude |
| GPQA | 84,0% | 87,5% | Grok 4 |
| Índice matemático | ~88% | 92,7% | Grok 4 |
| Velocidad | ~80 tok/s | 40,6 tok/s | Claude |
| CLI de código | Claude Code (nativo) | Ninguno | Claude |
| Multi-agente | Agent Teams (API) | 4.20 Beta (consumidor) | Claude |
| Suscripción | $20/mes (Pro) | $30/mes (SuperGrok) | Claude |
| API económica | Haiku 4.5 ($1/$5) | Fast ($0,20/$0,50) | Grok 4 |
El patrón es claro: Claude domina los benchmarks de ingeniería de software y razonamiento, mientras que Grok ofrece mejores precios y un rendimiento matemático superior. Pero la historia real es más matizada de lo que cualquier tabla puede mostrar — particularmente cuando se consideran los enfoques radicalmente diferentes que cada empresa adopta en arquitectura de agentes y herramientas para desarrolladores, que exploraremos en detalle a continuación. Una advertencia importante sobre la fila «API económica»: Grok 4 Fast no es simplemente una versión más barata de Grok 4 — es un modelo fundamentalmente diferente con una ventana de contexto masiva de 2M tokens que lo hace adecuado para casos de uso totalmente distintos al Grok 4 estándar. De manera similar, Claude Haiku 4.5 hace compromisos diferentes entre calidad y velocidad que Opus. Comparar niveles económicos entre sí es útil para la planificación de costes, pero no deben tratarse como sustitutos directos de sus contrapartes premium en aplicaciones críticas de rendimiento.
Entendiendo el panorama de modelos en 2026
Antes de comparar Claude Opus 4.6 y Grok 4 directamente, es esencial entender dónde se sitúa cada modelo dentro de su respectiva familia. Esto es particularmente importante del lado de Grok, donde la línea de modelos se ha vuelto genuinamente confusa — incluso para desarrolladores experimentados. xAI ha lanzado múltiples variantes en diferentes niveles de acceso, y comprender qué "Grok 4" estás evaluando realmente frente a Claude marca una diferencia significativa en cualquier comparación justa.
Claude Opus 4.6 ocupa la posición más alta en la jerarquía de modelos de Anthropic a marzo de 2026. Lanzado el 5 de febrero de 2026, representa el modelo de razonamiento más capaz de Anthropic, posicionado por encima de Claude Sonnet 4.6 (la opción equilibrada a $3/$15 por millón de tokens) y Claude Haiku 4.5 (la opción optimizada para velocidad a $1/$5 por millón de tokens). La nomenclatura es directa: Opus para capacidad máxima, Sonnet para el mejor equilibrio entre rendimiento y coste, y Haiku para velocidad y eficiencia. Cuando la gente discute sobre "Claude" en el contexto de capacidades de IA frontera, casi siempre se refieren al nivel Opus. Para una comparación más profunda entre Opus y Sonnet dentro de la familia Claude, consulta nuestra comparación de Claude Opus vs Sonnet.
La familia de modelos Grok (contexto esencial)
El panorama de Grok es donde surge la mayor confusión, y ningún otro artículo comparativo en los resultados TOP 10 actuales explica esto adecuadamente. Aquí está el desglose completo de la familia Grok 4 a marzo de 2026 (verificado desde docs.x.ai):
Grok 4 (grok-4-0709) es el modelo insignia, lanzado el 9 de julio de 2025. Presenta razonamiento siempre activo (no hay modo sin razonamiento), una ventana de contexto de 256K y precios de $3,00 entrada / $15,00 salida por millón de tokens. Este es el modelo que compite directamente con Claude Opus 4.6. Una distinción importante: el razonamiento de Grok 4 está siempre activo, lo que significa que siempre pagas por el proceso de pensamiento profundo. Claude Opus 4.6, en cambio, ofrece el pensamiento extendido como característica opcional, dando a los desarrolladores un control de costes más granular.
Las variantes Grok 4 Fast incluyen tanto modos de razonamiento como de no razonamiento (grok-4-fast-reasoning y grok-4-fast-non-reasoning), además de sus contrapartes 4.1. Comparten una ventana de contexto masiva de 2M tokens y cuestan solo $0,20/$0,50 por millón de tokens — haciéndolas 15-25 veces más baratas que Claude Opus 4.6. Sacrifican algo de capacidad a cambio de ahorros dramáticos en costes, pero para muchas aplicaciones, el rendimiento es más que adecuado. La ventana de contexto de 2M es particularmente valiosa para procesar bases de código completas o documentos largos que requerirían fragmentación con otros modelos.
Grok 4.20 Beta es el sistema multiagente orientado al consumidor, lanzado el 17 de febrero de 2026. Disponible a través de SuperGrok ($30/mes) y SuperGrok Heavy ($300/mes), cuenta con cuatro agentes especializados — Captain, Research, Logic y Creative — que trabajan juntos en tareas complejas. Esta es la respuesta de xAI a los Agent Teams de Claude, pero con una filosofía fundamentalmente diferente que exploraremos en la sección de arquitectura. Es importante destacar que Grok 4.20 Beta no tiene acceso API todavía, convirtiéndolo en un producto puramente de consumo por ahora.
Por qué esto importa para tu comparación
Cuando ves comparaciones de benchmarks en línea, la mayoría de herramientas de comparación automáticas enfrentan "Claude Opus 4.6" contra "Grok 4" sin especificar qué variante de Grok o si están comparando capacidades API, funciones de consumidor o rendimiento bruto del modelo. Una comparación justa debe emparejar Claude Opus 4.6 contra la API estándar de Grok 4 para el análisis de benchmarks y precios, reconociendo al mismo tiempo las variantes Fast como alternativas económicas convincentes y el 4.20 Beta como un competidor interesante para consumidores frente a Claude Pro.
Desglose de precios — Cada dólar cuenta
Comprender el coste real de estos modelos requiere mirar más allá del precio por token para examinar lo que realmente gastarás en escenarios de uso real. Las cifras principales — $5/$25 para Claude versus $3/$15 para Grok — solo cuentan parte de la historia. La forma en que cada modelo maneja los tokens de razonamiento, el caché y el acceso por niveles crea diferencias de coste significativas que dependen enteramente de tu caso de uso específico. Para un análisis completo de los precios de Claude en todos los niveles, consulta nuestra guía detallada de precios de Claude Opus 4.6.
Precios API: el panorama completo
La comparación de precios API base revela la ventaja de coste del 40% de Grok 4 tanto en tokens de entrada como de salida. Pero varios factores complican esta matemática simple. Claude Opus 4.6 cobra $5,00 por millón de tokens de entrada y $25,00 por millón de tokens de salida (verificado en platform.claude.com, marzo de 2026). Grok 4 cobra $3,00 de entrada y $15,00 de salida por millón de tokens, con tokens de entrada en caché disponibles a $0,75 por millón (docs.x.ai, marzo de 2026). El descuento de caché de prompts de Grok 4 a $0,75 por millón de tokens es más agresivo que el nivel de caché de Claude, lo que puede reducir significativamente los costes para aplicaciones que reutilizan prompts del sistema o documentos de referencia en múltiples llamadas API.
La comparación del nivel económico es donde la brecha se vuelve dramática. La opción más asequible de Anthropic es Claude Haiku 4.5 a $1,00/$5,00 por millón de tokens — una propuesta de valor sólida pero aún 5 veces más cara que los $0,20/$0,50 de Grok 4 Fast. Para aplicaciones de alto volumen donde necesitas capacidad cercana a la frontera sin precios de frontera, las variantes Grok 4 Fast representan uno de los mejores valores del mercado. También ofrecen una ventana de contexto de 2M tokens, comparado con el contexto más modesto de Haiku.
Precios de suscripción para consumidores
Para usuarios que prefieren acceso por suscripción sobre integración API, Claude Pro cuesta $20/mes, proporcionando acceso a Opus 4.6 con generosos límites de uso. SuperGrok, la oferta comparable de xAI, cuesta $30/mes e incluye acceso a Grok 4 además del sistema multiagente 4.20 Beta. SuperGrok Heavy a $300/mes está dirigido a usuarios avanzados y empresas que necesitan límites de tasa más altos y acceso prioritario. Desde una perspectiva pura de valor de suscripción, Claude Pro ofrece acceso de nivel frontera a un menor coste mensual, aunque SuperGrok incluye la capacidad multiagente que Claude no incluye en su nivel de suscripción.
Análisis de coste por tarea: lo que realmente pagarás
Los precios brutos por token cobran sentido solo cuando se mapean a tareas reales. Esto es lo que cinco tareas comunes de desarrollo cuestan realmente con cada modelo, basado en patrones típicos de consumo de tokens. Una revisión de código estándar de un pull request de 500 líneas (aproximadamente 4.000 tokens de entrada y 2.000 tokens de salida) cuesta alrededor de $0,07 con Claude Opus 4.6 versus $0,04 con Grok 4 — una diferencia de unos 3 centavos que apenas se nota a nivel de tarea individual. El análisis de documentos de un documento técnico de 50 páginas (aproximadamente 25.000 tokens de entrada, 5.000 tokens de salida) cuesta unos $0,25 con Claude y $0,15 con Grok. Una conversación de chatbot con un promedio de 10 turnos cuesta aproximadamente $0,05 con Claude versus $0,03 con Grok. Las sesiones de depuración de bugs con contexto extendido típicamente cuestan $0,50-$1,00 con Claude y $0,30-$0,60 con Grok. El análisis completo de una base de código usando la ventana de contexto máxima cuesta aproximadamente $1,00 con Claude (200K tokens) versus $0,77 con Grok (256K tokens).
La diferencia de coste se vuelve significativa a escala. Un equipo de desarrollo que realiza 1.000 llamadas API por día ahorraría aproximadamente $30-$50 diarios eligiendo Grok 4 sobre Claude Opus 4.6 — alrededor de $900-$1.500 por mes. Sin embargo, si Grok 4 Fast es suficiente para una parte de esas llamadas, los ahorros se multiplican dramáticamente. Usar Grok 4 Fast para el 80% de las tareas y reservar Grok 4 para razonamiento complejo podría reducir la factura mensual a menos de $200, comparado con $1.500+ para uso exclusivo de Claude Opus.
Vale la pena señalar que Anthropic también ofrece precios escalonados dentro de la familia Claude. Una estrategia práctica de optimización de costes para usuarios de Claude es dirigir las tareas simples a Claude Haiku 4.5 ($1/$5 por millón de tokens), las tareas de complejidad media a Sonnet 4.6 ($3/$15) y reservar Opus 4.6 para tareas que genuinamente necesiten razonamiento de nivel frontera. Este enfoque puede reducir los costes de la familia Claude en un 60-70% comparado con usar Opus para todo. El mismo principio se aplica del lado de Grok: usa las variantes Fast como tu opción predeterminada y escala al Grok 4 estándar solo cuando sea necesario.
Análisis profundo de benchmarks — Lo que significan realmente los números
Los resultados de benchmarks están por todas partes en las comparaciones de modelos de IA, pero los números brutos sin contexto son peores que inútiles — son engañosos. Una diferencia de 5 puntos porcentuales en GPQA tiene implicaciones prácticas completamente diferentes que la misma brecha en SWE-bench. Esta sección desglosa lo que cada benchmark principal realmente mide, lo que los resultados nos dicen sobre la capacidad en el mundo real, y dónde cada modelo genuinamente sobresale versus dónde las diferencias son insignificantes.
Benchmarks de programación: donde Claude lidera
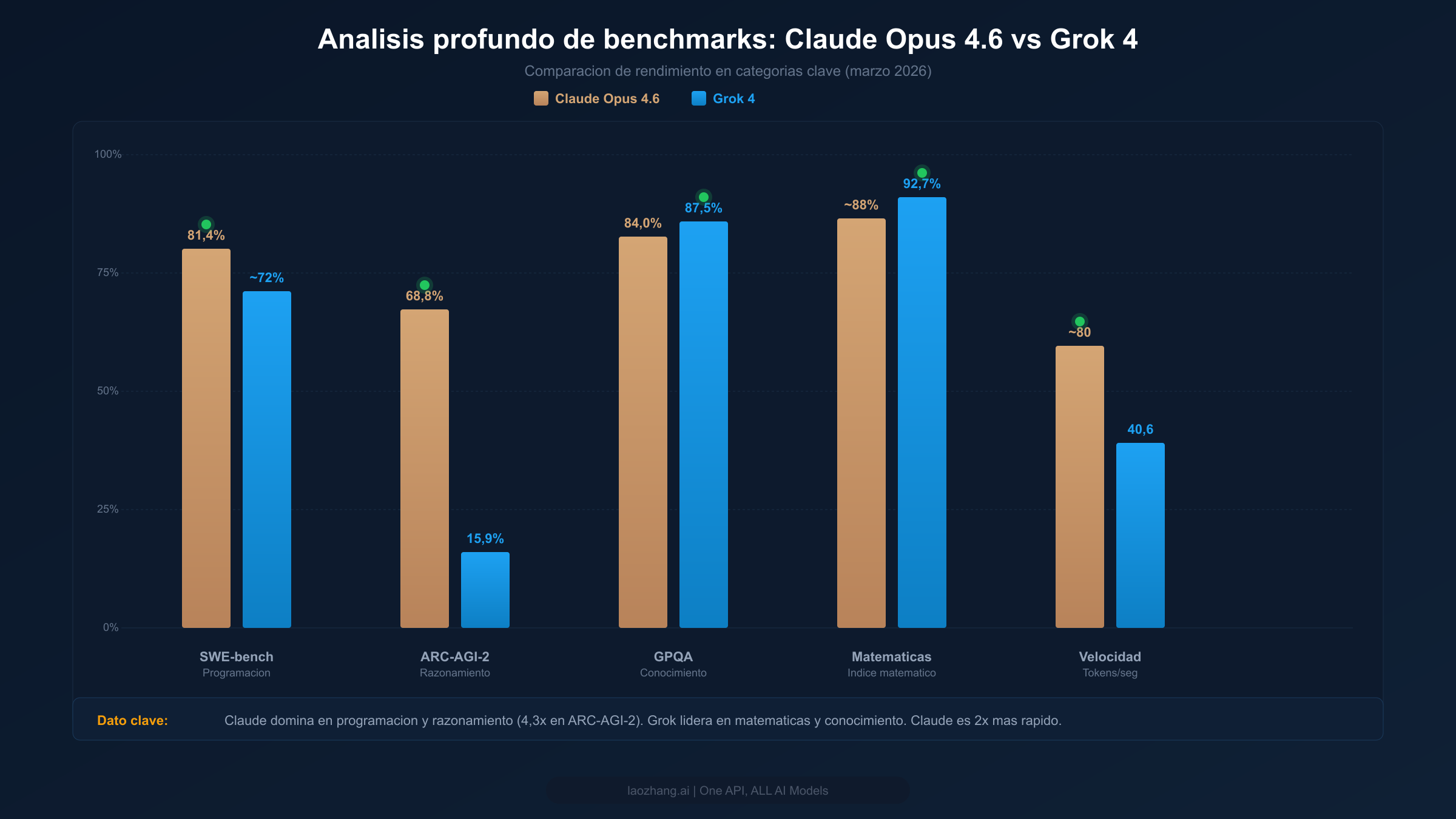
SWE-bench Verified es el estándar de oro para evaluar la capacidad de un modelo para resolver tareas reales de ingeniería de software — corregir bugs reales de repositorios Python populares de código abierto. Claude Opus 4.6 obtiene un 81,4% en este benchmark (anuncio oficial de Anthropic, febrero de 2026), lo que representa una ventaja significativa sobre el estimado ~72% de Grok 4. Esta no es una brecha trivial: significa que Claude resuelve con éxito aproximadamente una de cada diez tareas adicionales de programación del mundo real que Grok no logra. Para equipos de desarrollo que evalúan estos modelos para asistencia de código, esta diferencia se traduce directamente en menos intervenciones manuales y ciclos de iteración más rápidos.
Terminal-Bench mide la capacidad de programación agéntica — qué tan bien un modelo puede operar de manera autónoma en un entorno de terminal, ejecutando comandos, interpretando resultados e iterando en soluciones. Claude Opus 4.6 obtiene un 43,2% aquí, un benchmark donde Grok 4 no ha publicado resultados oficiales. Esta métrica importa cada vez más a medida que los desarrolladores adoptan flujos de trabajo de programación agéntica donde la IA actúa como un programador par semi-autónomo en lugar de solo una herramienta de autocompletado de código. La ausencia de resultados de Grok 4 en Terminal-Bench es reveladora en sí misma — xAI no ha posicionado a Grok como un modelo de programación agéntica, mientras que Anthropic ha construido un producto completo (Claude Code) alrededor de esta capacidad. Para equipos que consideran qué modelo usar para tareas de desarrollo autónomo, esta diferencia en enfoque estratégico importa tanto como los números del benchmark en sí.
Benchmarks de razonamiento: la brecha dramática
ARC-AGI-2 está diseñado para probar la capacidad de razonamiento novedoso — el tipo de inteligencia fluida que requiere comprensión genuina en lugar de reconocimiento de patrones. La brecha aquí es extraordinaria: Claude Opus 4.6 obtiene un 68,8% comparado con el 15,9% de Grok 4. Esta diferencia de 4,3 veces es la mayor brecha de rendimiento entre estos dos modelos en cualquier benchmark importante. ¿Qué significa en la práctica? Las tareas de ARC-AGI-2 requieren que el modelo identifique patrones abstractos y los aplique en contextos novedosos — precisamente el tipo de razonamiento que importa para decisiones complejas de arquitectura de software, resolución creativa de problemas y tareas donde el camino de la solución no está bien definido. Si tu trabajo involucra regularmente desafíos de razonamiento novedoso, esta brecha en el benchmark es altamente predictiva de las diferencias de rendimiento en el mundo real.
Conocimiento y matemáticas: donde Grok sobresale
GPQA (Graduate-level Professional Quality Assurance) evalúa el conocimiento a nivel experto en múltiples dominios científicos. Grok 4 lidera aquí con un 87,5% versus el 84,0% de Claude — una ventaja significativa pero no dramática. Esto sugiere que Grok tiene una ligera ventaja en tareas que requieren conocimiento profundo del dominio en ciencia, medicina y campos técnicos. El Índice Matemático cuenta una historia similar: el 92,7% de Grok 4 versus el aproximado 88% de Claude indica un razonamiento matemático más fuerte. Para aplicaciones centradas en computación matemática, análisis estadístico o razonamiento científico, la ventaja de Grok es real y consistente en múltiples benchmarks enfocados en matemáticas.
Velocidad y latencia: el factor de producción
Para aplicaciones en producción, los resultados brutos de benchmarks importan menos que la combinación de calidad y velocidad. Claude Opus 4.6 genera aproximadamente 80 tokens por segundo, aproximadamente el doble de los 40,6 tokens por segundo de Grok 4 (pricepertoken.com, marzo de 2026). La diferencia en tiempo hasta el primer token (TTFT) es aún más llamativa: la respuesta de Claude comienza en aproximadamente 1,5 segundos, comparado con los 10,79 segundos de Grok 4. Esa diferencia de casi 10 segundos en TTFT es crítica para aplicaciones interactivas — chatbots, asistentes de código y herramientas de análisis en tiempo real donde los usuarios esperan respuesta inmediata. El razonamiento siempre activo de Grok 4 contribuye a su mayor latencia, ya que cada solicitud pasa por el proceso de razonamiento profundo independientemente de si la tarea lo requiere.
Programación y desarrollo: donde Claude sobresale

Para desarrolladores que evalúan estos modelos como asistentes de código, la comparación se extiende mucho más allá de los resultados de benchmarks hacia el ecosistema de herramientas, integraciones y experiencia de desarrollo que cada plataforma proporciona. Aquí es donde la brecha entre Claude y Grok se vuelve más pronunciada — no porque Grok 4 sea un mal modelo de programación, sino porque Anthropic ha invertido fuertemente en construir un flujo de trabajo integral para desarrolladores alrededor de Claude.
Claude Code es la herramienta de línea de comandos nativa de Anthropic que da a Claude acceso directo a tu terminal, sistema de archivos y entorno de desarrollo. No es solo un wrapper de API — es un sistema de programación agéntica que puede leer tu base de código, escribir y editar archivos, ejecutar pruebas, gestionar operaciones git e iterar en soluciones de forma autónoma. No existe una herramienta equivalente en el ecosistema de Grok. Este único producto crea una categoría de experiencia de desarrollo que Grok simplemente no puede igualar con solo acceso API. Para equipos que ya usan Claude Code, el coste de cambio a Grok incluye perder todo este flujo de trabajo de programación agéntica.
Agent Teams, introducido con Claude 4.6, permite a los desarrolladores orquestar múltiples instancias de Claude trabajando en paralelo en diferentes aspectos de una tarea — un agente maneja la escritura de código, otro gestiona las pruebas, un tercero revisa la calidad. Esta capacidad multiagente opera a través de la API con controles de permisos granulares y soporta worktrees git aislados por agente, previniendo interferencias entre flujos de trabajo paralelos. Para un análisis profundo de estas capacidades, consulta nuestra guía de Claude Agent Teams.
La capacidad de programación de Grok 4, aunque no tan extensamente evaluada en benchmarks, aporta sus propias ventajas. El razonamiento siempre activo significa que cada solicitud de código recibe un análisis profundo por defecto, lo cual puede ser beneficioso para problemas algorítmicos complejos y código matemático donde la ventaja del 92,7% en el Índice Matemático de Grok se traduce en mejores soluciones. La ventana de contexto de 2M tokens disponible a través de las variantes Grok 4 Fast es genuinamente útil para análisis de código a gran escala — procesar repositorios completos o cadenas de dependencias largas que excederían el límite de 200K de Claude. Además, el precio de $0,20/$0,50 de Grok 4 Fast lo hace económicamente viable para ejecutar amplias líneas de análisis automatizado de código que serían prohibitivamente caras con Claude Opus 4.6.
La recomendación práctica para la mayoría de los equipos de desarrollo es considerar un enfoque multimodelo. Usa Claude Opus 4.6 (y Claude Code específicamente) para sesiones de programación interactiva, depuración compleja y tareas que requieran comportamiento agéntico. Reserva Grok 4 o Grok 4 Fast para procesamiento por lotes, computación matemática y tareas de análisis de alto volumen donde la eficiencia de costes importa más que el máximo rendimiento en programación. Este enfoque combinado captura las mejores capacidades de cada modelo mientras gestiona los costes de manera efectiva.
Arquitectura de agentes — Dos filosofías diferentes
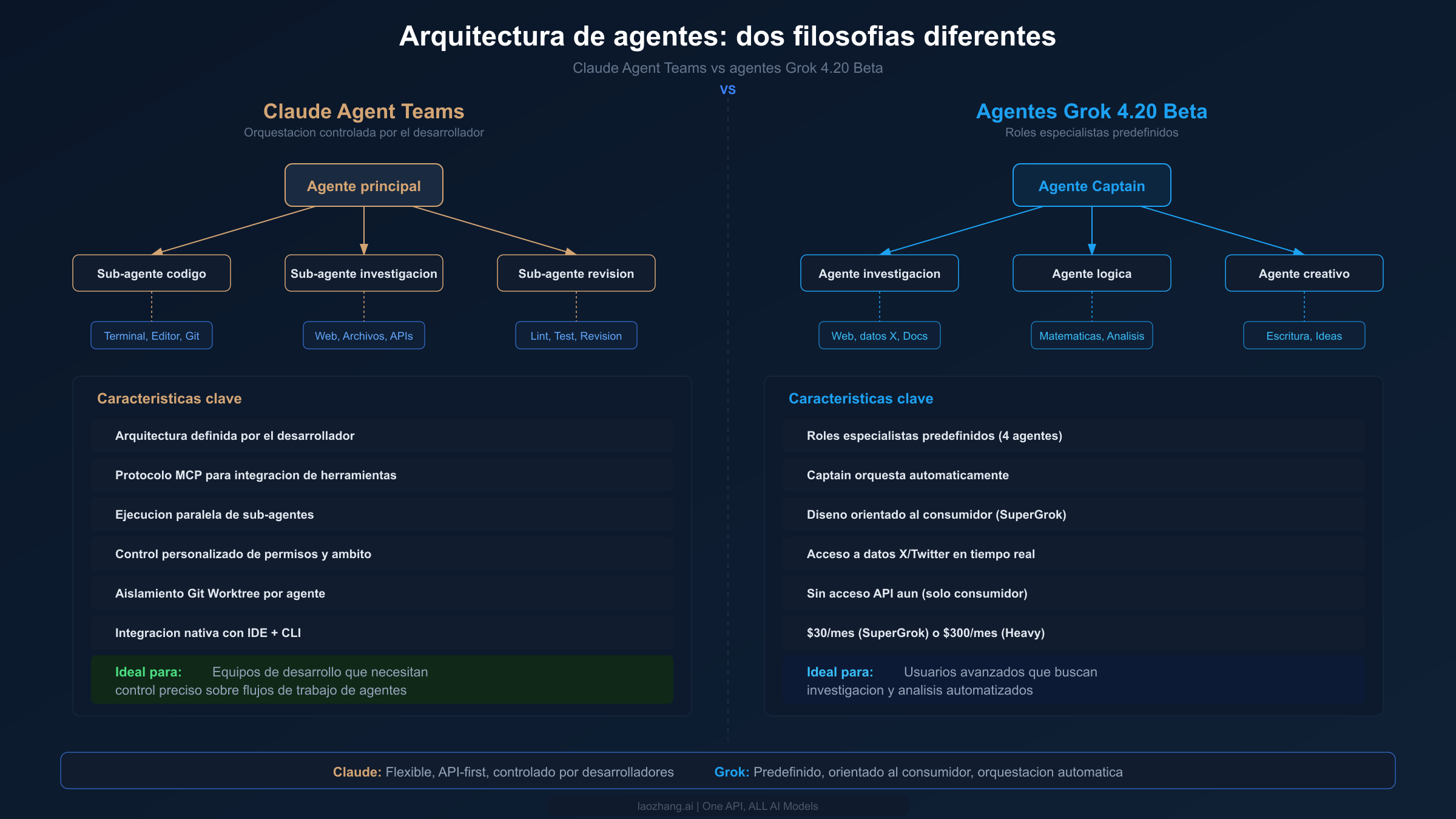
La comparación más visionaria entre Claude y Grok no se trata de resultados de benchmarks o precios — se trata de cómo cada empresa visualiza los sistemas de IA multiagente. Tanto Anthropic como xAI han lanzado capacidades multiagente a principios de 2026, pero sus enfoques revelan filosofías fundamentalmente diferentes sobre quién debería controlar la orquestación, cómo se comunican los agentes y qué problemas deberían resolver los sistemas multiagente. Comprender estas diferencias arquitectónicas es crítico para cualquiera que planee construir sobre estas plataformas a largo plazo.
Claude Agent Teams: orquestación controlada por el desarrollador
Los Agent Teams de Claude, lanzados como parte de la versión Claude 4.6, siguen una filosofía centrada en el desarrollador. El agente principal (o "líder") puede crear sub-agentes con instrucciones, herramientas y ámbitos de permisos específicos. Los desarrolladores definen la arquitectura — qué agentes existen, a qué herramientas puede acceder cada uno y cómo se coordinan. El sistema opera enteramente a través de la API, lo que significa que tienes control programático completo sobre cada aspecto de la orquestación. Los sub-agentes pueden ejecutarse en paralelo, cada uno en worktrees git aislados para prevenir conflictos, y el agente principal sintetiza sus resultados. El Model Context Protocol (MCP) permite que los agentes se integren con herramientas externas — bases de datos, APIs, sistemas de archivos e IDEs — a través de una interfaz estandarizada. Esta composabilidad significa que los desarrolladores pueden construir exactamente el flujo de trabajo multiagente que su caso de uso requiere, desde pipelines simples de código y revisión con dos agentes hasta sistemas complejos de cinco agentes manejando diferentes aspectos de un proyecto grande.
La contrapartida es la complejidad. Construir un flujo de trabajo efectivo de Agent Teams requiere entender patrones de orquestación, definir ámbitos claros para los agentes, gestionar presupuestos de tokens entre agentes paralelos y manejar modos de fallo cuando los sub-agentes producen resultados conflictivos. Es una herramienta poderosa, pero demanda inversión del desarrollador para usarla efectivamente. La recompensa viene en precisión: flujos de trabajo bien diseñados de Agent Teams pueden superar dramáticamente las interacciones con un solo modelo en tareas complejas porque cada agente puede optimizarse para su rol específico con el contexto y herramientas apropiadas.
Agentes Grok 4.20 Beta: roles especialistas predefinidos
El enfoque de Grok con el 4.20 Beta es primero el consumidor. En lugar de requerir que los desarrolladores diseñen arquitecturas de agentes, xAI proporciona cuatro agentes especialistas predefinidos — Captain, Research, Logic y Creative — que se coordinan automáticamente en tareas complejas. El agente Captain sirve como orquestador, dirigiendo subtareas al especialista que mejor se adapte. Los usuarios no necesitan entender la arquitectura multiagente; simplemente envían una solicitud compleja y el sistema maneja la descomposición y coordinación internamente. Este enfoque se alinea con la plataforma SuperGrok orientada al consumidor de xAI, donde el objetivo es hacer accesibles las capacidades avanzadas de IA sin experiencia técnica. El agente Research tiene acceso directo a datos de X/Twitter, dándole capacidades de información en tiempo real que los agentes de Claude no poseen de forma nativa. El agente Logic maneja tareas matemáticas y analíticas, aprovechando el fuerte rendimiento matemático de Grok 4. El agente Creative se enfoca en generación de contenido e ideación.
La contrapartida es la flexibilidad. No puedes personalizar qué agentes participan, definir nuevos roles especialistas o controlar la lógica de orquestación. El sistema funciona bien para tareas complejas de propósito general, pero carece de la precisión que los desarrolladores necesitan para flujos de trabajo especializados. Y, de manera crítica, todavía no hay acceso API — los agentes de Grok 4.20 Beta solo están disponibles a través de la interfaz de consumidor SuperGrok, limitando su utilidad para aplicaciones en producción.
¿Qué arquitectura gana?
Para desarrolladores y equipos de ingeniería, Agent Teams de Claude es el ganador claro en 2026 — está disponible a través de la API, ofrece personalización completa e integra con herramientas de desarrollo existentes mediante MCP. Para usuarios avanzados e investigadores que quieren capacidades multiagente sin escribir código, Grok 4.20 Beta proporciona una alternativa accesible, aunque menos flexible. La verdadera pregunta es si xAI liberará acceso API para su sistema multiagente, lo que haría esta comparación mucho más competitiva. Hasta entonces, cualquier equipo que necesite flujos de trabajo multiagente programáticos tiene solo una opción: Claude.
Observar la trayectoria de ambas empresas revela señales importantes para la planificación a largo plazo. Anthropic ha expandido sistemáticamente el ecosistema de desarrolladores de Claude — desde la API inicial, a Claude Code, a Agent Teams, a integraciones MCP — cada uno construyendo sobre la capa anterior. Esto sugiere una inversión continua en herramientas para desarrolladores que hacen a Claude cada vez más integrado en los flujos de trabajo de ingeniería. La trayectoria de xAI está más enfocada en el consumidor, con SuperGrok y el sistema de agentes 4.20 Beta priorizando accesibilidad sobre programabilidad. Ninguna trayectoria es inherentemente mejor, pero sirven a audiencias diferentes. Si estás construyendo productos que dependen de capacidades de agentes de IA, el enfoque centrado en el desarrollador de Claude ofrece más estabilidad y composabilidad. Si estás creando experiencias de IA para consumidores, el sistema de agentes predefinido de Grok ofrece tiempo de valor más rápido sin ingeniería personalizada.
¿Qué modelo deberías elegir?
Tomar la decisión correcta entre Claude Opus 4.6 y Grok 4 depende menos de qué modelo es "mejor" en términos absolutos y más de qué modelo se ajusta mejor a tu caso de uso específico, presupuesto y requisitos técnicos. Basándonos en nuestro análisis exhaustivo de benchmarks, precios, capacidades de programación y arquitectura, aquí están seis recomendaciones basadas en escenarios diseñadas para ayudarte a tomar una decisión con confianza.
Escenario 1: equipo de desarrollo de software (5-20 desarrolladores). Elige Claude Opus 4.6. La combinación de rendimiento superior en SWE-bench (81,4%), Claude Code para programación agéntica, Agent Teams para flujos de trabajo paralelos y fuertes integraciones con IDE crea un ecosistema diseñado específicamente para el desarrollo profesional de software. El mayor coste API ($5/$25 vs $3/$15) se compensa con ganancias de productividad — resolver un bug adicional por día que Grok no detectaría fácilmente cubre la diferencia de coste. Consejo de ahorro: usa Claude Sonnet 4.6 ($3/$15) para tareas rutinarias y reserva Opus para razonamiento complejo.
Escenario 2: startup o desarrollador independiente con presupuesto ajustado. Elige Grok 4 Fast ($0,20/$0,50). A 25 veces más barato que Claude Opus 4.6, Grok 4 Fast proporciona capacidad cercana a la frontera por una fracción del coste. La ventana de contexto de 2M tokens es un bonus para procesar bases de código grandes. Para el 10-20% de tareas que necesitan máxima capacidad, considera usar Claude Opus 4.6 o Grok 4 estándar puntualmente en lugar de pagar por el nivel premium en cada solicitud.
Escenario 3: ciencia de datos y análisis matemático. Elige Grok 4. Su Índice Matemático del 92,7% y puntuaciones GPQA del 87,5% indican un rendimiento superior en razonamiento matemático y tareas de conocimiento científico. El modo de razonamiento siempre activo, aunque añade latencia, asegura rigor analítico profundo en cada solicitud. Para equipos que realizan análisis estadístico intensivo, entrenamiento de modelos o computación científica, la ventaja matemática de Grok se traduce en mejoras tangibles de calidad.
Escenario 4: empresa con necesidades de flujos de trabajo multiagente. Elige Claude Opus 4.6 con Agent Teams. A marzo de 2026, Claude es la única opción con orquestación multiagente accesible por API. Si tu hoja de ruta empresarial incluye construir flujos de trabajo autónomos, pipelines automatizados de revisión de código o sistemas de análisis complejos de múltiples pasos, Agent Teams de Claude proporciona la base programable que necesitas. El sistema multiagente de Grok 4.20 Beta sigue siendo solo para consumidores.
Escenario 5: aplicaciones en tiempo real y chatbots. Elige Claude Opus 4.6. La ventaja de velocidad de 2x (~80 tok/s vs 40,6 tok/s) y el TTFT dramáticamente más rápido (~1,5s vs 10,79s) hacen de Claude la única opción viable para aplicaciones donde la latencia de respuesta importa. Una espera de 10 segundos para el primer token es inaceptable en la mayoría de casos de uso interactivos.
Escenario 6: procesamiento de alto volumen con presupuesto ajustado. Elige un enfoque mixto con Grok 4 Fast como modelo principal. Dirige el 80% de las solicitudes a través de Grok 4 Fast ($0,20/$0,50), escala las tareas complejas a Grok 4 estándar ($3/$15) y usa Claude Opus 4.6 solo para tareas que requieran máxima capacidad de programación o razonamiento. Este enfoque escalonado puede reducir costes en un 85-95% comparado con el uso exclusivo de Claude Opus mientras mantiene alta calidad para las tareas que más importan.
El hilo conductor en los seis escenarios es que la mejor estrategia rara vez es "usar un solo modelo para todo". El panorama de IA frontera en 2026 recompensa el enrutamiento inteligente — emparejar capacidades y costes de modelos con requisitos específicos de tareas. Incluso dentro de un solo producto, podrías usar Claude para asistencia de código orientada al usuario mientras ejecutas Grok 4 Fast para procesamiento de documentos y extracción de datos en segundo plano. Los días de comprometerse exclusivamente con un solo proveedor de IA han terminado; la ventaja competitiva la obtienen los equipos que aprovechan el modelo correcto para cada trabajo. Implementar esta estrategia multimodelo requiere esfuerzo de ingeniería adicional para la lógica de enrutamiento de modelos y la gestión de múltiples relaciones API, pero los ahorros de costes y las mejoras de calidad justifican la inversión para cualquier equipo que realice más de unos cientos de llamadas API por día.
Primeros pasos y optimización de costes
Tanto Claude como Grok ofrecen acceso API sencillo, pero optimizar tu implementación para coste y rendimiento requiere entender las características específicas de cada plataforma. Aquí tienes una guía práctica para comenzar con cualquiera de los modelos y extraer el máximo valor de tu presupuesto API.
Para comenzar con Claude Opus 4.6 necesitas una clave API de Anthropic desde console.anthropic.com. La API sigue un patrón REST estándar con SDKs disponibles en Python y TypeScript. El proceso de configuración es directo: crea una cuenta, genera una clave API y realiza tu primera solicitud en minutos. Activa el pensamiento extendido solo para tareas que requieran razonamiento profundo — dejarlo activado por defecto infla los costes sin ganancias proporcionales de calidad para tareas más simples. Usa el caché de prompts incluyendo un bloque cache_control en tus prompts del sistema para reducir costes de tokens de entrada en llamadas repetidas. Para flujos de trabajo de programación, instala Claude Code (npm install -g @anthropic-ai/claude-code) para obtener la experiencia completa de desarrollo agéntico sin escribir integraciones API personalizadas. Claude Code soporta acceso directo al terminal, edición de archivos, operaciones git y orquestación multiagente desde tu línea de comandos, convirtiéndolo en el camino más rápido desde "tengo una clave API" hasta "tengo un flujo de trabajo de desarrollo potenciado por IA".
Para comenzar con Grok 4 necesitas una clave API de xAI desde console.x.ai. La API es compatible con OpenAI, lo que hace la migración sencilla para equipos que ya usan el formato del SDK de OpenAI. Aprovecha agresivamente los precios de entrada en caché de Grok 4 ($0,75/M vs $3,00/M estándar) — cualquier prompt del sistema o documento de referencia que se reutilice entre llamadas debería estar en caché. Para aplicaciones sensibles al presupuesto, comienza con Grok 4 Fast y solo escala a Grok 4 estándar cuando la complejidad de la tarea lo demande. La ventana de contexto de 2M tokens en las variantes Fast significa que rara vez necesitas el Grok 4 completo para tareas de procesamiento de documentos.
Las estrategias de optimización de costes que funcionan con ambos modelos incluyen implementar enrutamiento inteligente que analice la complejidad de la tarea antes de seleccionar un nivel de modelo, agrupar solicitudes similares para maximizar la utilización del caché, y establecer límites de presupuesto de tokens por solicitud para prevenir costes descontrolados en tareas que generan salida excesiva. Un sistema de enrutamiento bien diseñado podría usar un clasificador ligero (o incluso una heurística basada en reglas) para determinar si cada solicitud entrante necesita capacidad de nivel frontera o si un modelo económico es suficiente. Esta única optimización puede reducir el gasto total en API en un 50-70% para la mayoría de las aplicaciones.
Para una perspectiva más amplia sobre cómo estos modelos se comparan con otras opciones frontera incluyendo GPT-4o y Gemini, consulta nuestra guía completa de comparación de APIs de IA. El panorama de modelos de IA en 2026 recompensa la flexibilidad — los equipos que mejor rinden son aquellos que emparejan modelos con tareas en lugar de comprometerse exclusivamente con un solo proveedor. Tanto Claude Opus 4.6 como Grok 4 son excelentes modelos, y la estrategia ideal para la mayoría de organizaciones es usar ambos donde cada uno destaque.
Preguntas frecuentes
¿Es Claude Opus 4.6 mejor que Grok 4?
Claude Opus 4.6 supera a Grok 4 en benchmarks de programación (81,4% vs ~72% en SWE-bench), tareas de razonamiento (68,8% vs 15,9% en ARC-AGI-2) y velocidad de respuesta (~80 vs 40,6 tokens/segundo). Sin embargo, Grok 4 lidera en razonamiento matemático (92,7% en Índice Matemático) y tareas de conocimiento (87,5% en GPQA), mientras cuesta un 40% menos. Ningún modelo es universalmente "mejor" — la elección correcta depende de si tu caso de uso principal es programación/razonamiento (Claude) o matemáticas/conocimiento a menor coste (Grok).
¿Cuánto más barato es Grok 4 que Claude Opus 4.6?
Los precios API de Grok 4 son $3/$15 por millón de tokens comparado con los $5/$25 de Claude, haciéndolo un 40% más barato en entrada y salida. Las variantes económicas Grok 4 Fast a $0,20/$0,50 por millón de tokens son 25 veces más baratas que Claude Opus 4.6, convirtiéndolas en uno de los modelos cercanos a la frontera más asequibles disponibles. Grok también ofrece precios de entrada en caché a $0,75 por millón de tokens.
¿Puedo usar tanto Claude como Grok a través de la misma API?
Sí.
¿Qué es Grok 4.20 Beta y cómo se compara con Claude Agent Teams?
Grok 4.20 Beta es el sistema multiagente para consumidores de xAI con cuatro agentes especialistas (Captain, Research, Logic, Creative) disponible a través de SuperGrok ($30/mes). Claude Agent Teams es el marco multiagente orientado a desarrolladores de Anthropic disponible a través de la API. La diferencia clave: el sistema de Claude ofrece control programático completo y personalización, mientras que el de Grok es predefinido y solo para consumidores sin acceso API todavía.
¿Qué modelo es más rápido para aplicaciones en producción?
Claude Opus 4.6 es significativamente más rápido: aproximadamente 80 tokens/segundo versus los 40,6 de Grok 4, con un tiempo hasta el primer token de ~1,5 segundos versus los 10,79 segundos de Grok 4. Para aplicaciones interactivas y chatbots, la ventaja de velocidad de Claude es decisiva. La mayor latencia de Grok 4 resulta de su modo de razonamiento siempre activo, que procesa cada solicitud a través del razonamiento profundo independientemente de la complejidad.