
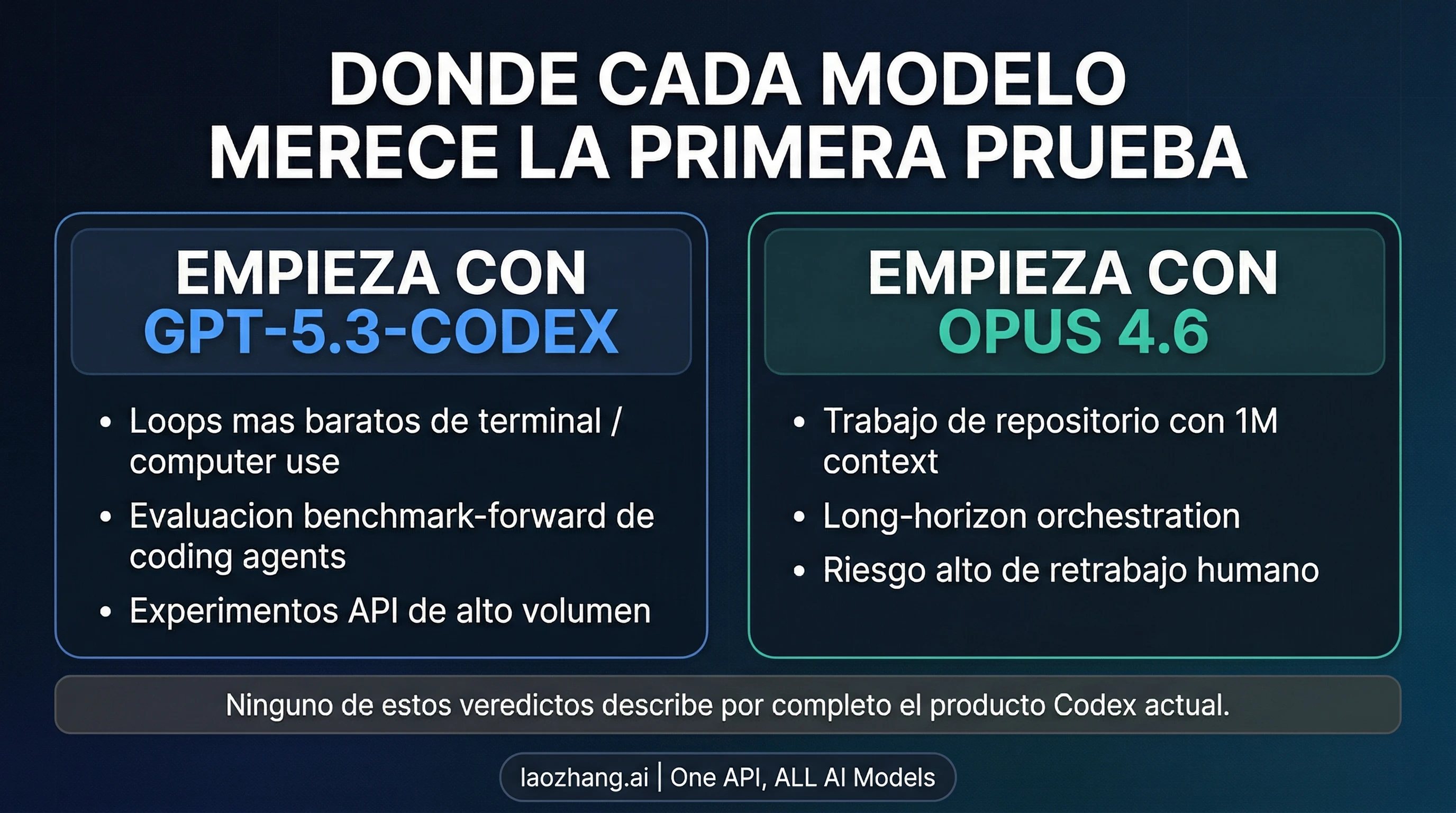
Empieza con GPT-5.3-Codex si tu primera evaluación es una automatización de código más barata, centrada en tareas repetidas de terminal y llamadas a herramientas. Empieza con Claude Opus 4.6 si el coste importante ya no viene del precio por token, sino de tareas largas, de un contexto de repositorio muy grande o de una salida tan amplia que un primer intento flojo termina creando retrabajo humano caro. Esa es la respuesta práctica a 3 de abril de 2026.
Antes de cualquier tabla, hace falta una aclaración. GPT-5.3-Codex sigue siendo un modelo actual y real de OpenAI, pero ya no es una abreviatura segura para todo el Codex actual como producto. OpenAI introdujo GPT-5.4 en Codex el 5 de marzo de 2026, y el 17 de marzo de 2026 explicó un enfoque donde un modelo más grande se encarga de la planificación y la decisión final mientras GPT-5.4 mini asume tareas más acotadas. Por eso, aquí comparamos Claude Opus 4.6 y GPT-5.3-Codex como modelos, no todo el producto Codex actual. Si tu pregunta real es de producto o de flujo de trabajo, el siguiente paso correcto es la guía de OpenAI Codex de marzo de 2026 o la comparación Claude Code vs Codex.
| Si tu cuello de botella se parece a esto | Empieza por | Por qué |
|---|---|---|
| Bucles de código más baratos, centrados en terminal y herramientas | GPT-5.3-Codex | El precio oficial de API es más bajo y OpenAI publica una base más clara de benchmarks propios |
| Ejecución larga a escala de repositorio | Claude Opus 4.6 | 1M de contexto, 128k de salida y una propuesta más convincente cuando repetir sale caro |
| Tu stack tiene las dos etapas | Usa ambos | Deja GPT-5.3-Codex como primer paso barato y sube a Opus cuando crecen el contexto y el coste del retrabajo |
Nota de evidencia: este artículo se verificó contra páginas oficiales actuales de OpenAI y Anthropic revisadas el 3 de abril de 2026. La evidencia pública de benchmark no es simétrica: OpenAI publica un anexo de lanzamiento más rico para GPT-5.3-Codex, mientras Anthropic publica un conjunto más corto pero todavía útil de benchmarks públicos para Opus 4.6. Por eso, lo que sigue debe leerse como base para decidir por dónde empezar, no como un marcador perfecto.
Primero, dejemos claro qué estamos comparando
Esta comparación solo funciona si fijamos bien el objeto que estamos comparando. GPT-5.3-Codex se lanzó el 5 de febrero de 2026, y la documentación actual de API de OpenAI todavía la presenta como modelo vigente para código, con precio, niveles de reasoning, endpoints, ventana de contexto de 400.000 tokens y salida máxima de 128.000 tokens. Eso significa que el nombre del modelo sigue vigente y vale la pena compararlo directamente con Claude Opus 4.6.
Lo que sí cambió fue la historia alrededor del producto. La página actual de modelos de OpenAI ya coloca a GPT-5.4 como la familia principal para agentic, coding y trabajo profesional, y el texto de 17 de marzo de 2026 sobre GPT-5.4 mini describe un Codex donde un modelo más grande toma la planificación y la decisión final, mientras modelos más pequeños asumen trabajo más acotado. Eso no significa que GPT-5.3-Codex haya desaparecido. Significa que muchas personas, cuando dicen "Codex", ya están mezclando una pregunta más amplia que una sola comparación de modelos.
Esa distinción importa porque elegir modelo y elegir producto responde a preguntas distintas. La comparación de modelos debe responder qué modelo conviene probar primero. La comparación de productos debe responder qué herramienta, qué forma de trabajo y qué vía de adopción conviene elegir. Esta página se queda en el nivel de modelo para responder una pregunta más útil: qué modelo merece la primera prueba en un entorno de desarrollo hoy.
Comparación rápida: dónde aparece de verdad la diferencia

Lo importante aquí no es "quién gana más filas", sino qué tipo de fallo apunta cada fila. GPT-5.3-Codex tiene el precio de un modelo que puedes evaluar muchas veces. Claude Opus 4.6 tiene el precio de un modelo que espera ahorrarte errores más caros.
| Dimensión | GPT-5.3-Codex | Claude Opus 4.6 | Cómo leer la fila |
|---|---|---|---|
| Precio oficial de API | $1.75 input / $14 output por 1M tokens | $5 input / $25 output por 1M tokens | GPT-5.3-Codex es mucho más fácil de probar en bucles repetidos |
| Cached input | $0.175 por 1M tokens | Anthropic publica el caché y el precio por separado | OpenAI facilita evaluaciones repetidas |
| Ventana de contexto | 400k | 1M | Opus puede sostener un repositorio o un conjunto de especificaciones mucho más grande de una sola vez |
| Salida máxima | 128k | 128k | El tamaño de salida no es la división principal |
| Public Terminal-Bench 2.0 | 77.3 | 65.4 | OpenAI publica un caso propio más fuerte para una evaluación barata de agentes de código |
| Public OSWorld | 64.7 | 72.7 | Anthropic publica un caso mas fuerte para ejecucion larga en entornos reales |
De ahí ya sale la dirección principal. GPT-5.3-Codex es más fácil de justificar como primer test barato, sobre todo si tu pregunta inmediata es "hasta dónde puedo empujar un agente de código antes de pagar precios premium". Claude Opus 4.6 es más fácil de justificar cuando la profundidad de contexto y el costo del fallo dominan la cuenta, porque mantiene mucho más estado útil al mismo tiempo sin perder margen de salida.
El error es fingir que esas filas forman una historia de benchmark perfectamente simétrica. No es así. Los números de OpenAI vienen de su anexo del 5 de febrero de 2026 y se ejecutaron con xhigh reasoning effort. El caso público actual de Anthropic para Opus 4.6 es más estrecho, pero sigue siendo útil: sus páginas enfatizan 65.4% en Terminal-Bench 2.0, 72.7% en OSWorld, 1M de contexto público y un encaje claro en tareas agentic. Eso basta para decidir por dónde empezar. No basta para declarar un ganador universal.
Cuando GPT-5.3-Codex merece la primera prueba
Conclusión: GPT-5.3-Codex es mejor primer paso cuando tu pregunta cercana es cuánto trabajo de coding agents puedes sacar por menos dinero en loops repetidos de terminal.
Evidencia: la página actual del modelo la fija en $1.75 / $14 por millón de tokens, $0.175 de cached input, 400k de contexto, 128k de salida y niveles ajustables de reasoning. El anexo también le da el caso público de benchmark más claro del lado de OpenAI, con 77.3% en Terminal-Bench 2.0 y 64.7% en OSWorld-Verified.
Lectura práctica: si tu equipo todavía está explorando los límites de un agente de código y espera muchas iteraciones, reintentos y tandas de evaluación, empieza por GPT-5.3-Codex.
La razón real no es la teatralidad del leaderboard, sino la economía. Un sistema de desarrollo que vive en bucles repetidos de terminal, intentos de parche, llamadas a herramientas y autocorrección gasta dinero antes por repetición que por contextos gigantes. En ese tipo de sistema, GPT-5.3-Codex te da una forma más barata de aprender qué exige realmente tu carga de trabajo. Si el modelo falla, aprendes sin pagar tarifas tipo Opus en cada paso. Si funciona suficientemente bien, no hace falta empujar un modelo premium por toda la tubería.
También hay otra ventaja práctica: OpenAI muestra mejor el paquete completo para este tipo de trabajo. No es solo una frase de marketing; hay precio, contexto y benchmarks visibles. Para elegir con qué empezar, eso ayuda mucho.
Cuándo Claude Opus 4.6 vale más la pena primero
Conclusión: si el cuello de botella real no es el precio por token sino el contexto largo, la ejecución larga y el coste de un mal primer intento, entonces merece más la pena empezar con Claude Opus 4.6.
Evidencia: Anthropic publica para Opus 4.6 $5 / $25 por millón de tokens, 1M de contexto y 128k de salida máxima. Sus materiales también destacan 65.4% en Terminal-Bench 2.0, 72.7% en OSWorld y un encaje claro en tareas agentic y de ejecución larga.
Lectura practica: si trabajas con repositorios grandes, tareas de varios pasos o entregables donde un mal primer intento se traduce en mucho retrabajo humano, tiene sentido probar antes Claude Opus 4.6.
La clave aquí no es "es más inteligente", sino otra cosa: hay tareas donde un mal primer intento sale muy caro. Si el modelo debe sostener un repositorio grande, documentos largos, material de incidente o un resultado final voluminoso, entonces 1M de contexto y 128k de salida cambian la forma del trabajo.
En ese punto, el precio del token deja de ser toda la historia. Un modelo más caro puede salir mejor si reduce reintentos, tiempo de revisión y resultados que "casi sirven" pero se rompen varias etapas después. La historia pública de Anthropic va exactamente por ahí. Aunque su conjunto de benchmarks no sea tan simétrico como el de OpenAI, sí alcanza para leer a Opus 4.6 como el mejor primer intento en tareas largas y costosas.
La arquitectura de dos modelos que deberían probar muchos equipos
Para muchos equipos, la respuesta más honesta de 2026 no es un ganador permanente, sino una regla clara de reparto.
Deja GPT-5.3-Codex en el primer paso barato del trabajo de agentes de código: bucles intensivos de terminal, tandas amplias de evaluación y automatización temprana donde todavía estás entendiendo la forma del fallo. Luego, cuando la tarea crece hasta un repositorio grande, una ejecución larga de varios pasos o un entregable donde un mal primer intento genera retrabajo caro, súbela a Claude Opus 4.6. Eso no es un "ambos son buenos" diplomático. Es una arquitectura de dos etapas bastante concreta.

La clave es la regla de escalado. Si la tarea sigue siendo relativamente acotada y tu preocupación principal es el precio de los ciclos de evaluación, la tarea debe quedarse en GPT-5.3-Codex. Si el contexto crece, se multiplican los reintentos o la salida se vuelve un artefacto de alto valor, entonces súbela a Opus. Y esa subida debe medirse por coste de reintento y coste de retrabajo, no solo por el precio del token. Los equipos que miran solo las tarifas oficiales suelen perder de vista el coste real de un primer pase mediocre.
En este punto una mención de producto sí puede ser útil. Si ya sabes que quieres mantener vivas las rutas de OpenAI y Anthropic, una puerta de enlace unificada como laozhang.ai puede reducir la fricción de llevar facturación, autenticación y cambio entre modelos por separado. Se menciona aquí por una razón simple: la mejor respuesta práctica de este artículo muchas veces es usar ambas rutas de forma deliberada.
La lección más amplia es esta: la elección del modelo debe seguir la etapa del trabajo. Un modelo barato para el primer pase y un modelo premium para la ejecución pueden convivir sin contradicción dentro de un mismo sistema de código. En 2026, eso suele ser una respuesta de ingeniería más fuerte que intentar que un solo modelo de punta se quede con todo.
Si tu pregunta real es qué significa Codex hoy
Muchos lectores que escriben "GPT-5.3-Codex" en realidad están preguntando otra cosa: qué es Codex hoy como producto. Sobre esa pregunta, este artículo no debería excederse. El enfoque actual de OpenAI ya se movió hacia una historia de Codex en la era GPT-5.4, con app, CLI, IDE, cloud y una separación más clara entre modelos grandes para planificar y modelos más pequeños para apoyar. Por eso GPT-5.3-Codex sigue siendo un comparador válido aquí, pero ya no es toda la respuesta del producto.
El siguiente paso práctico es sencillo. Si estás eligiendo modelos, quédate en esta página y usa la regla anterior. Si estás eligiendo producto o forma de trabajo, el siguiente paso correcto es la guía de OpenAI Codex de marzo de 2026. Si tu pregunta real es si deberías adoptar la herramienta de Anthropic o la de OpenAI, ve a Claude Code vs Codex. Y si tu duda del lado de Anthropic tiene más que ver con separación de roles o con el coste de ese escenario premium, el siguiente paso más preciso es la guía de Claude 4.6 Agent Teams.
Conclusión
Si hubiera que comprimir todo en una sola frase honesta, sería esta. Empieza con GPT-5.3-Codex cuando el trabajo sea un ciclo barato de agente de código y el objetivo del primer round sea medir cuánta automatización útil puedes obtener sin pagar tarifas premium. Empieza con Claude Opus 4.6 cuando la tarea sea tan larga que la profundidad de contexto, la continuidad de ejecución y el tamaño de salida cuesten más que el precio por token. Y si en tu stack viven claramente esas dos etapas, deja de buscar un ganador universal falso y usa ambos modelos de forma intencional.