Si vas a cambiar entre Codex y Claude Code sin perder contexto, no muevas todo el chat. Mueve el estado de trabajo: reglas del repo, objetivo actual, archivos tocados, comandos ejecutados, fallos conocidos, decisiones ya tomadas y siguiente acción. El estado del código debe vivir en Git, las reglas duraderas en AGENTS.md y CLAUDE.md, y el estado temporal en un handoff packet que una persona pueda revisar en dos minutos.
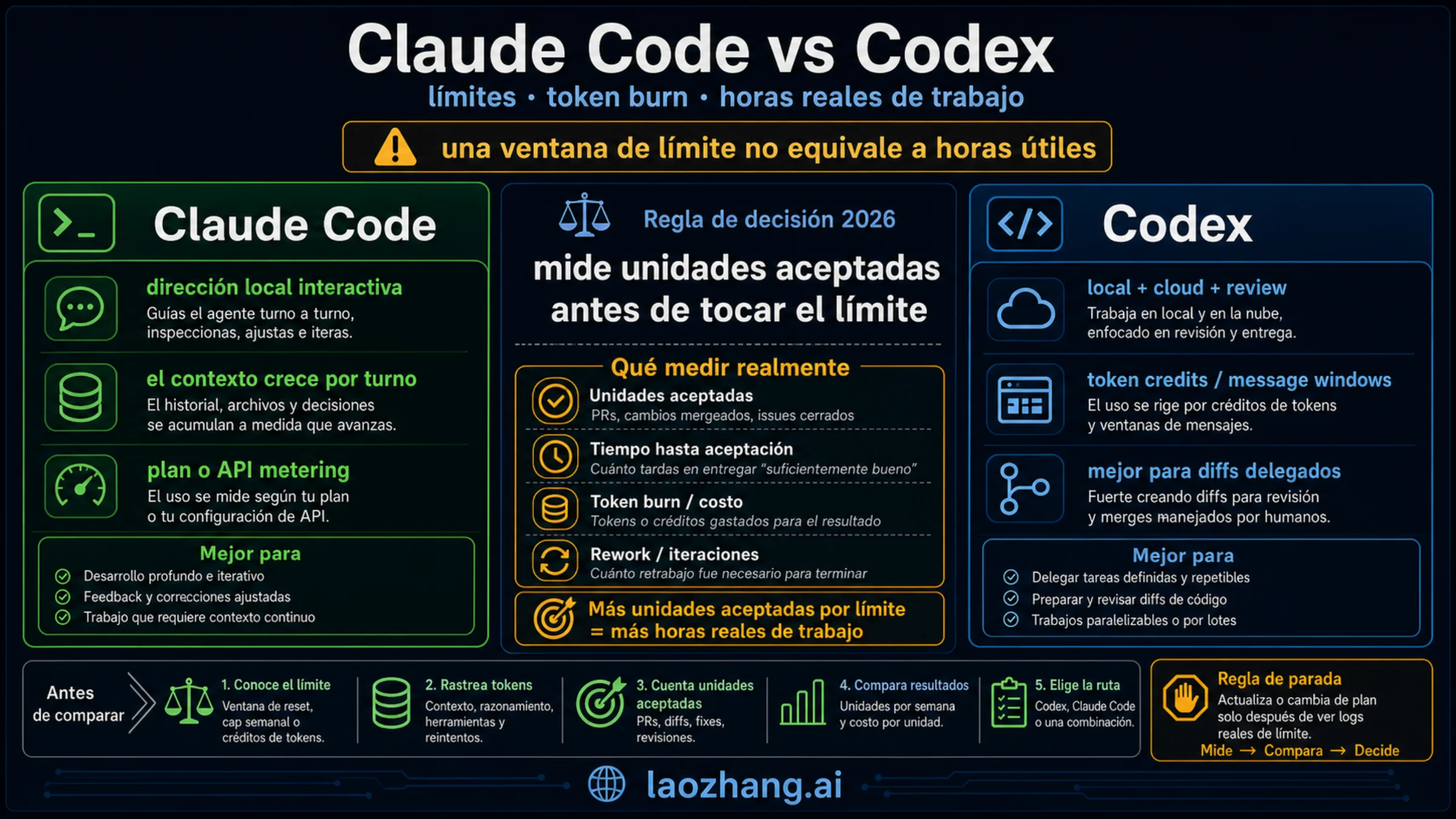
Claude Code y Codex ya no se eligen preguntando cuál "sabe programar". Los dos son lo bastante fuertes para trabajo real. La decisión que suele fallar es otra: pagar por una forma de trabajo que no encaja con tu día, leer mal el medidor de límites y tratar un transcript largo como memoria fiable. Una ventana de cinco horas no significa cinco horas útiles de coding. Lo importante es cuánto trabajo revisable obtienes antes de que contexto, modelo, herramientas, reintentos o setup consuman la capacidad.
La respuesta práctica al 23 de mayo de 2026 es por niveles. Con 20 dólares al mes, empieza por Codex si quieres más superficie de agente y categorías de uso más visibles. Empieza por Claude Code si tu trabajo principal es local, exploratorio y con muchas reglas de permisos. Con 100 o 200 dólares, no compares marcas: compara si haces más sesiones largas de Claude Code o más tareas delegadas, cloud tasks y reviews en Codex. Luego mide diffs aceptados, límites alcanzados y tiempo de retrabajo.
Decisión rápida
| Situación | Primera opción | Motivo |
|---|---|---|
| Cambias de herramienta a mitad de tarea | Escribe primero el handoff packet | El siguiente agente no debe adivinar decisiones desde un transcript largo. |
| 20 dólares al mes y quieres probar mucho | Codex | Plus incluye Codex en web, CLI, IDE, iOS, integraciones cloud y modelos actuales. |
| 20 dólares al mes y trabajas localmente con mucha corrección | Claude Code | Encaja mejor con steering local, permisos y contexto largo. |
| 100 dólares al mes y muchas sesiones Claude | Claude Max 5x | Aumenta el espacio de uso de Claude. |
| 100 dólares al mes y muchas tareas Codex o reviews | Codex Pro 5x | Aumenta las ventanas de Codex por categorías de trabajo. |
| 200 dólares al mes y trabajo pesado paralelo | Separar por tarea | Max 20x para sesiones grandes; Codex Pro 20x para delegar y revisar. |
| Equipo que usa ambos | Regla de enrutamiento | Mejor clasificar tareas que declarar un ganador universal. |
Handoff de contexto: cambiar sin perder el trabajo
El contexto fiable debe estar donde ambas herramientas puedan leerlo otra vez. Codex lee instrucciones de proyecto en AGENTS.md. Claude Code lee CLAUDE.md, no AGENTS.md; si el repo ya usa AGENTS.md, crea un CLAUDE.md pequeño que importe @AGENTS.md y añade debajo solo notas específicas de Claude. Así no mantienes dos versiones casi iguales de las reglas.
| Capa de contexto | Dónde vive | Regla de handoff |
|---|---|---|
| Reglas duraderas del repo | AGENTS.md, importado por CLAUDE.md | Una sola fuente compartida, sin duplicado manual. |
| Estado de la tarea | Issue, nota de PR o HANDOFF.md | Objetivo, progreso, fallos y siguiente acción; no transcript completo. |
| Verdad del código | Git diff, branch, tests, logs | La siguiente herramienta empieza desde archivos y pruebas. |
| Acceso y seguridad | Alcance permitido/prohibido en el task packet | No pegues API keys, tokens ni logs privados. |
| Memoria a largo plazo | Solo reglas repetidas | El ruido de una tarea puntual no debe convertirse en política. |
Usa un paquete corto:
md## Agent handoff packet Goal: Current state: Files touched: Commands/tests run: Known failures: Decisions already made: Do not redo: Next best action: Safety/permissions:
Un buen handoff no dice "continúa lo anterior". Dice qué test falla, qué archivos cambiaron, qué no debe tocarse y qué comando se ejecuta después. Así Codex puede continuar una investigación local hecha en Claude Code, y Claude Code puede explicar un diff de Codex sin rehacer toda la implementación.
Límites, tokens y horas reales
Las discusiones públicas ya repiten frases como "Claude Code 100 hours vs Codex 20 hours" y "5-hour limit" porque la gente intenta traducir planes a tiempo de trabajo. Úsalas como señales, no como fórmula. Las horas reales dependen de cuatro variables: cuánto contexto se reenvía, qué modelo usas, si la tarea corre local o en cloud, y cuánto review humano queda al final.
Codex es más fácil de convertir en un libro de capacidad. La página actual de Codex pricing dice que local messages y cloud tasks comparten una ventana de cinco horas y que también pueden existir límites semanales. El coste de un mensaje cambia con modelo, tamaño del repo, complejidad y superficie de ejecución. Por eso conviene registrar tareas terminadas, diffs aceptados, runs fallidos y tiempo de revisión, no solo el porcentaje restante.
Claude Code se siente más directo durante una sesión, pero también puede quemar cuota cuando la conversación crece. La documentación de Anthropic explica que cada turno envía la conversación previa, el contexto del proyecto y el prompt nuevo. En una sesión larga, archivos leídos, diffs y decisiones anteriores viajan otra vez. '/clear', '/compact', la elección de modelo y desactivar herramientas que no necesitas afectan directamente a la duración útil.
La normalización útil no es "horas por dólar", sino "unidades aceptadas antes de chocar con límites". Si Claude Code resuelve dos investigaciones locales difíciles y Codex produce seis ramas aceptables con dos intentos fallidos, ambos pueden ser rentables. Elige el límite que sea más fácil de recuperar en tu flujo.
En la práctica, registra cada intento con cuatro columnas: objetivo de la tarea, qué leyó o modificó el agente, cuánto tardaste en revisar y si el resultado entró en la rama principal. Claude Code suele ganar cuando reduce vueltas y encuentra antes la dirección correcta. Codex suele ganar cuando permite poner tareas en cola y descartar ramas fallidas sin romper la sesión actual. Esos dos beneficios no se comparan solo con un cronómetro.
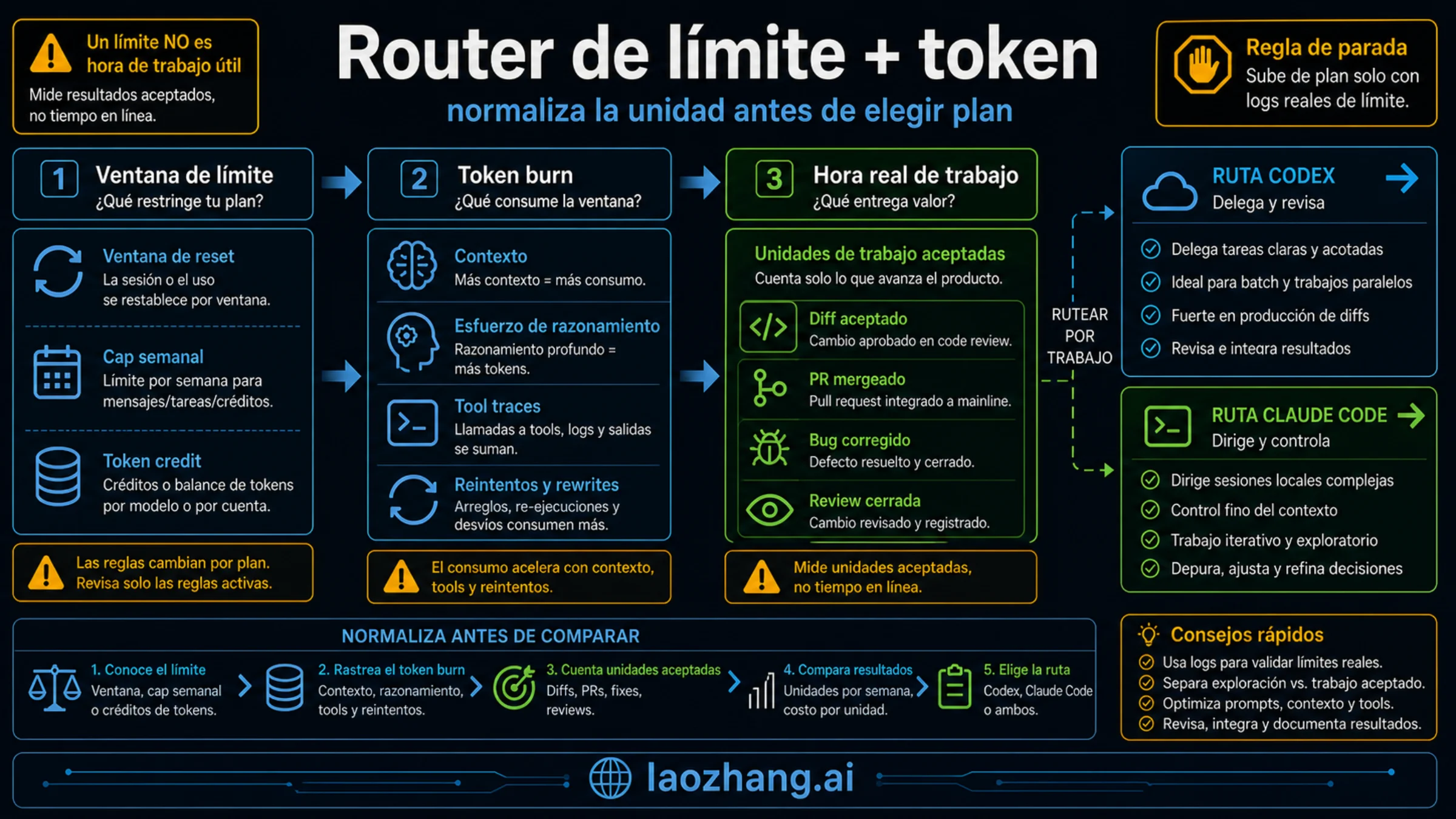
Límites: no reduzcas todo a un número
OpenAI muestra ahora los límites de Codex con más estructura. La página de Codex pricing describe Plus como un plan de 20 dólares al mes para varias sesiones de coding concentradas por semana. Incluye Codex en web, CLI, extensión IDE, iOS, integraciones cloud como automatic code review y Slack, además de GPT-5.5, GPT-5.4, GPT-5.3-Codex y GPT-5.4-mini.
Lo importante es que Codex no tiene un solo contador. Hay local messages, cloud tasks, code reviews y diferencias por modelo. Una afirmación de foro como "Codex da más límite" o "Codex se agota rápido" solo sirve si sabes qué modelo usó, qué tipo de tarea ejecutó y qué ventana midió.
Claude Code se lee de otra manera. La documentación de Claude Code usage dice que la medición depende de cómo inicias sesión. Un Enterprise seat usa una bolsa incluida con rolling reset; una API key usa pay-as-you-go por tokens. La misma documentación insiste en controlar el context window con '/clear' y '/compact', porque una conversación larga arrastra historial, consume más y puede bajar la calidad.
Anthropic anunció el 6 de mayo de 2026 que duplicaba los five-hour rate limits de Claude Code para Pro, Max, Team y seat-based Enterprise, y que eliminaba la reducción en horas pico para Pro y Max. Eso hace que muchas quejas antiguas sean menos útiles, pero no convierte Claude Code en un recurso ilimitado.
Coste: el precio de suscripción no es todo
Las etiquetas se parecen. Claude Pro cuesta 20 dólares al mes, Max 5x cuesta 100 y Max 20x cuesta 200. Codex Plus cuesta 20 dólares al mes y Codex Pro empieza en 100, con límites superiores a Plus.
La diferencia aparece debajo. Claude Code puede entrar por suscripción, pero también por API key. La documentación de costes de Anthropic dice que el uso API se cobra por consumo de tokens; en Pro y Max, el uso está incluido en la suscripción y el dólar que aparece en '/usage' no es una factura de suscripción. Para despliegues empresariales, Anthropic habla de unos 13 dólares por desarrollador activo al día y 150-250 dólares al mes, pero modelo, tamaño del codebase, múltiples instancias, automatización y contexto cambian la cifra.
Codex es más simple para muchos individuos porque Plus y Pro lo incluyen directamente. Aun así, no es gratis en sentido operativo. Un local message con GPT-5.5, una cloud task y un code review consumen una ventana limitada de trabajo. Pagas por capacidad de ejecución escasa, no solo por acceso a una interfaz.
El experimento sensato es un mes a 20 dólares y una semana de notas. Registra dónde chocas con límites, qué herramienta devuelve un diff más revisable, cuál necesita menos corrección y cuál reconoce mejor la incertidumbre. Sin esos datos, subir a 100 dólares compra esperanza, no necesariamente productividad.
Estabilidad: mira el estado y el riesgo de trabajo
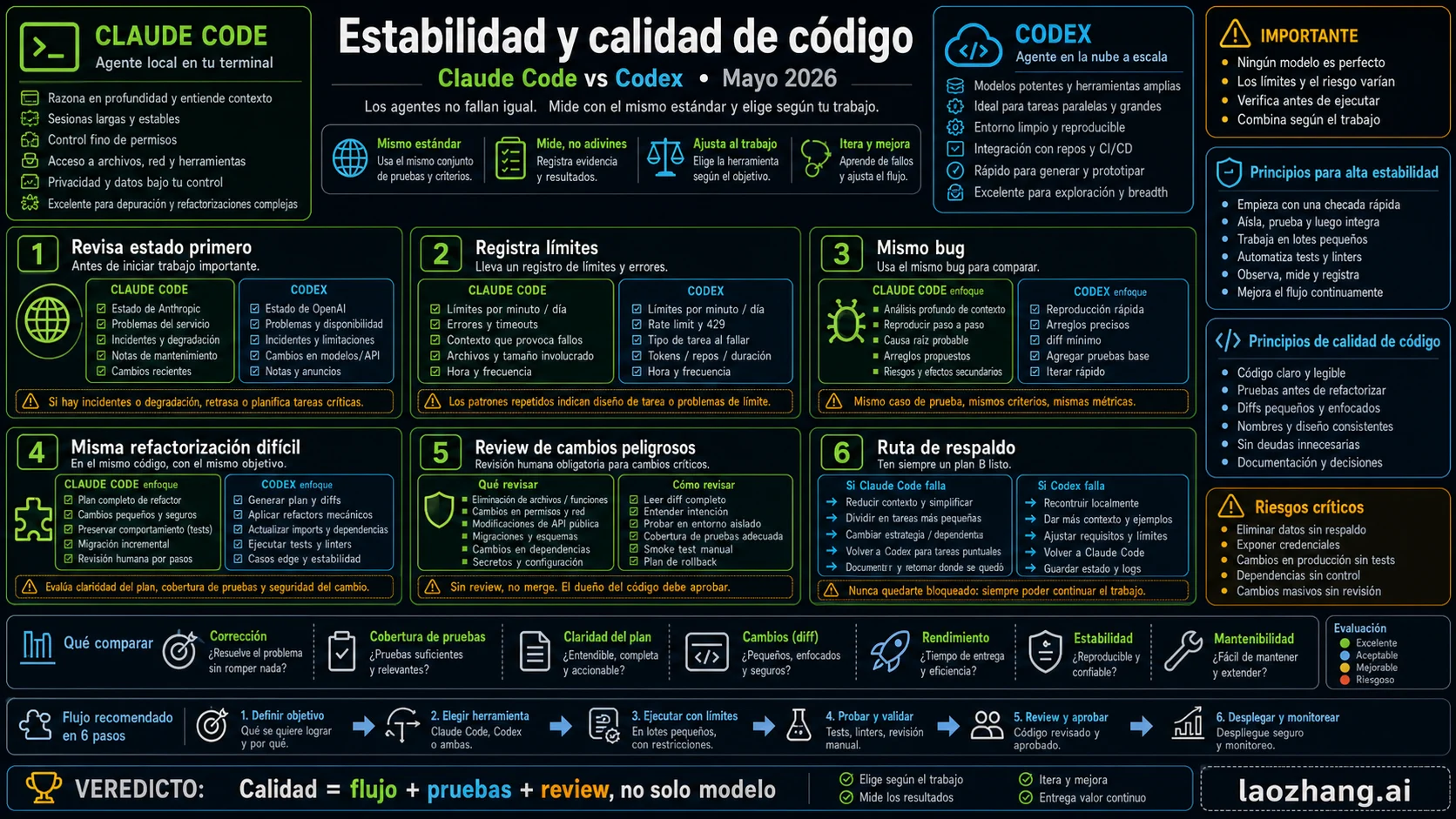
El 23 de mayo de 2026, el estado de OpenAI mostraba un incidente ongoing de Codex rate limits: más usuarios estaban llegando a límites. Al mismo tiempo, Codex aparecía con 99.98% de uptime en la ventana February-May 2026. Las dos cosas pueden ser ciertas. Un uptime agregado alto no impide que la superficie que necesitas hoy tenga problemas.
El estado de Claude no mostraba incidentes para ese día, pero entre el 12 y el 22 de mayo aparecían varios incidentes resueltos en Claude.ai, Opus 4.7, Haiku 4.5, Claude Code login y superficies web. La conclusión no debe ser emocional. Claude puede ser excelente para razonamiento largo y aun así tener interrupciones recientes. Codex puede tener uptime alto y un incidente de límites en el peor momento.
Antes de trabajo crítico, define fallback. En una sesión interactiva, la interrupción rompe foco: ten una tarea menor o un modelo alternativo. En trabajo asíncrono, el riesgo es perder tiempo: usa ramas aisladas y puntos de revisión.
Calidad de código: evalúa el bucle, no solo el modelo
OpenAI argumenta que GPT-5.5 es más fuerte en agentic coding, usa menos tokens en tareas Codex y supera a GPT-5.4 en varias evaluaciones de coding. Eso favorece a Codex cuando la tarea puede delegarse, validarse con herramientas y revisarse como diff.
Anthropic argumenta que Claude Opus 4.7 mejora en advanced software engineering, long-running tasks, instruction following y self-verification. En Claude Code, el esfuerzo por defecto de Opus 4.7 subió a xhigh. Eso favorece trabajos largos donde importan razonamiento, consistencia y resistencia a instrucciones incompletas.
Haz cuatro pruebas iguales: un bug con tests existentes, un refactor con estado local sin commitear, una implementación asíncrona bien acotada y un review donde la respuesta correcta es rechazar un cambio peligroso. Gana la herramienta que produce más diff revisable, menos retrabajo, mejores pruebas y notas de incertidumbre más claras.
Permisos y frontera de confianza
Claude Code tiene vocabulario de permisos más rico. Sus docs describen allow, ask y deny rules que pueden guardarse en version control y distribuirse a una organización. Los modos incluyen 'default', 'acceptEdits', 'plan', 'auto', 'dontAsk' y 'bypassPermissions'; el último debería reservarse para entornos aislados.
Codex tiene una frontera más fácil de explicar. Codex cloud corre en contenedores gestionados por OpenAI: la fase setup puede usar red para dependencias y la fase agent está offline por defecto salvo que actives internet. CLI e IDE usan sandbox del sistema operativo, sin red por defecto y con escritura limitada al workspace activo. Auto preset permite leer, editar y ejecutar comandos dentro del directorio de trabajo; fuera de ese borde pide aprobación.
Si necesitas política local granular, Claude Code gana. Si necesitas presets más simples y una historia local/cloud clara, Codex es más fácil de estandarizar.
Flujo híbrido
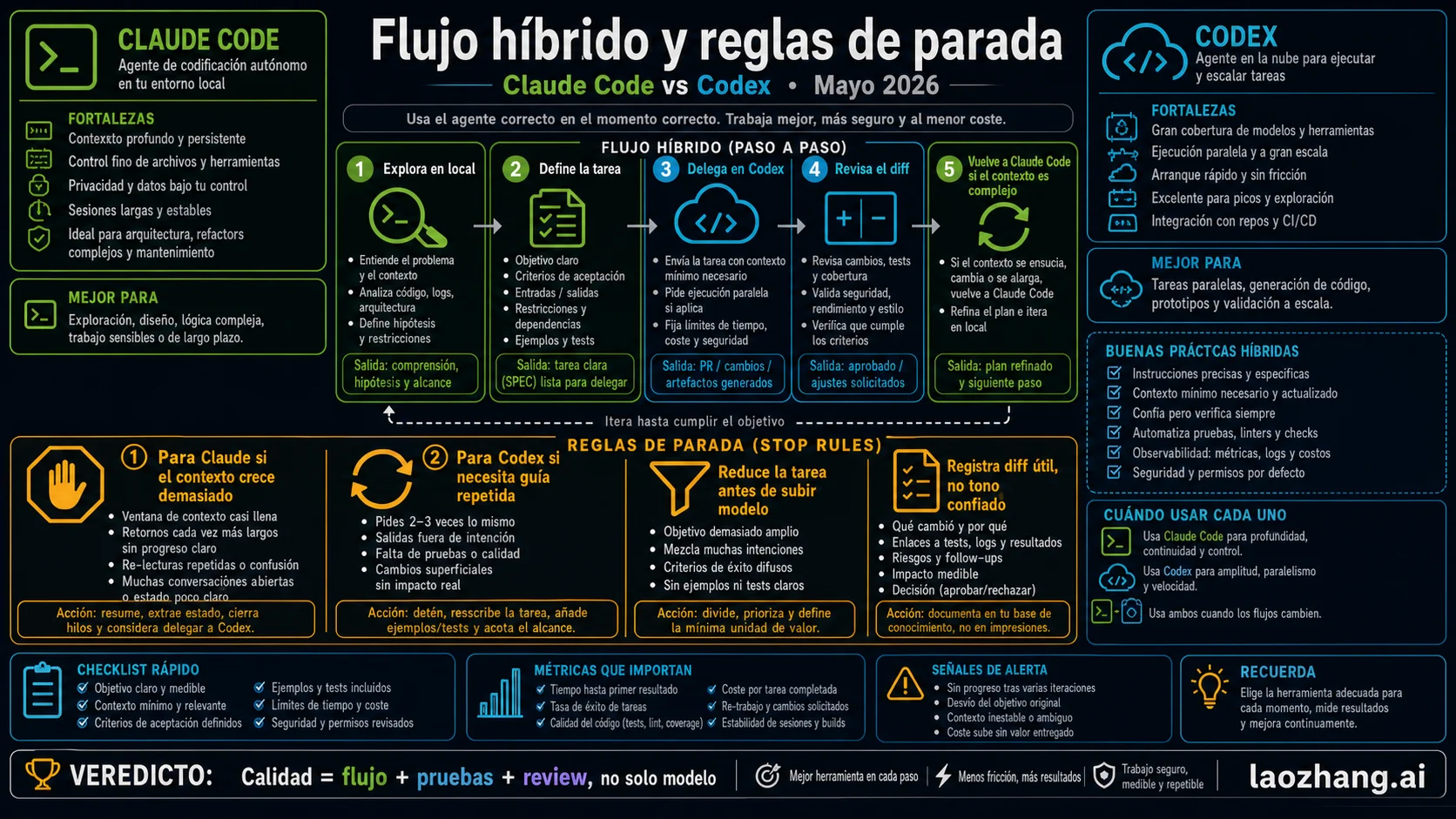
Empieza en Claude Code cuando la tarea todavía es incierta: leer el repo, inspeccionar fallos, validar hipótesis y decidir dónde aterriza el cambio. Cuando el trabajo se convierte en un ticket claro, pásalo a Codex como branch, review o cloud task.
Detén Claude Code si el contexto se hincha, la sesión da vueltas o la tarea ya está limpia para delegar. Detén Codex si pierde contexto del repo, necesita steering constante o devuelve un diff más difícil de revisar que de escribir.
Prueba de una semana antes de subir de plan
No conviene elegir por una demo de una tarde. Durante la primera semana lleva un registro pequeño. El primer día, entrega a Codex una tarea de bajo riesgo con una prueba de aceptación clara y usa Claude Code para leer un repositorio local que ya conoces. No compares el tono ni la confianza del agente. Compara cuánto tarda en producir un diff útil, cuándo aparece un límite, si el contexto largo degrada la salida y si el resultado se puede revisar sin rehacerlo.
Del segundo al cuarto día, separa las tareas en tres grupos. El primer grupo son tareas delegables: añadir pruebas, arreglar un bug bien delimitado, aplicar una migración de configuración o convertir un comentario de review en un cambio. Estas tareas encajan con Codex porque el resultado vuelve como rama, log y diff. El segundo grupo son tareas que requieren dirección continua: investigar una caída ambigua, trabajar con archivos sin commit, leer deuda histórica o decidir el punto correcto del cambio. Ahí Claude Code suele encajar mejor, porque la sesión local y los permisos forman parte del trabajo. El tercer grupo son tareas mal definidas. No las entregues a ningún agente hasta escribir objetivo, comando de verificación, límites de cambio y criterio de parada.
A partir del quinto día, mira coste por resultado usable, no solo precio mensual. Un plan de 20 dólares puede salir barato si reduce revisiones mecánicas cada semana. Un plan de 100 dólares puede salir caro si solo genera más diffs que luego hay que reescribir. Registra cuatro números: diffs aceptables, intentos reescritos por completo, paradas por límite o espera, e investigaciones extra causadas por la salida del agente. Ese registro vale más que una comparación genérica de benchmarks.
Antes de subir a 100 o 200 dólares, formula la pregunta correcta: ¿te falta espacio para sesiones locales largas de Claude Code o te falta capacidad para delegar y revisar con Codex? Si el dolor está en investigación local, permisos y contexto complejo, mira Claude Max. Si el dolor está en backlog, reviews y tareas claras que pueden correr en paralelo, mira Codex Pro. La decisión puede cambiar cuando cambie la forma de trabajo.
Cómo llevarlo a un equipo
En un equipo, la regla inicial no debería ser “todos usamos la misma herramienta”. Es mejor etiquetar el trabajo. local-investigation va por defecto a Claude Code: una persona debe controlar comandos, permisos, contexto y criterio de parada. delegated-implementation va por defecto a Codex: la tarjeta debe incluir archivos objetivo, comando de verificación, directorios prohibidos y tamaño esperado del diff. review-only puede usar Codex review o una explicación de Claude Code, pero la decisión de merge sigue siendo humana. blocked-human-decision no debe ir a un agente hasta que alguien defina el criterio de producto o arquitectura.
La estabilidad también debe registrarse con precisión. No escribas “Codex es inestable” o “Claude falló” como conclusión final. Registra el tipo de evento: fallo de login, rate limit, tarea cloud fallida, comando local bloqueado, caída de calidad, review retrasada o cambio de modelo. Añade fecha, plan, modelo, tipo de tarea e impacto. En pocas semanas tendrás una ruta operativa: qué se manda a Claude Code, qué se manda a Codex, dónde hace falta fallback y dónde el problema era un task packet demasiado vago.
Preguntas frecuentes
¿Claude Code lee AGENTS.md directamente?
No como archivo principal. Claude Code lee CLAUDE.md. Si el proyecto ya usa AGENTS.md para Codex, haz que CLAUDE.md importe @AGENTS.md y mantén las reglas compartidas en un solo lugar.
¿Debo pegar todo el transcript de Codex en Claude Code?
No. Pega un handoff packet: objetivo, archivos, comandos, fallos, decisiones, qué no repetir y siguiente acción. El resto del contexto debe vivir en el repo, el diff, los tests y el paquete de tarea.
Con 20 dólares, ¿cuál pruebo primero?
Codex Plus suele ser mejor si quieres amplitud de agente. Claude Pro y Claude Code son mejores si tu día está centrado en sesiones locales largas.
¿Claude Code todavía puede quedarse sin límite?
Sí. La subida de mayo da más margen, pero modelo, contexto y effort siguen consumiendo uso.
¿Cuál produce mejor código?
Codex encaja mejor con tareas delegadas y revisables. Claude Code encaja mejor con razonamiento local interactivo. La calidad depende de tests, review, contexto y reglas de parada.
¿Cuál es más estable?
Revisa el status antes de trabajo importante. OpenAI tenía un incidente de Codex rate limits el 23 de mayo; Claude no tenía incidente ese día, pero sí varios resueltos en días previos.
¿Un equipo debe elegir solo uno?
Normalmente no. La regla útil es: exploración local y ambigua en Claude Code; implementación acotada, review y cloud task en Codex.