
As of May 6, 2026, the OpenAI GPT-5.5 goblin problem was a real model-behavior pattern, not a normal ChatGPT or Codex outage. OpenAI's own explanation says the first clear spike came after GPT-5.1, where a personality reward signal made the word show up more often; GPT-5.5 later made the problem visible again in Codex testing, where prompt-side mitigation contained it.
That timeline matters because the market shorthand can make this sound like a generic GPT-5 failure. The useful split is narrower: GPT-5.1 explains the origin, GPT-5.4 and GPT-5.5 explain later visibility, and Codex prompt wording is a containment surface, not the root cause.
For users, this does not mean GPT-5.5 is unusable or that ChatGPT was down. For developers and AI teams, the lesson is to audit output style as behavior: sample long conversations, compare personalities and prompts, check synthetic-data loops, and catch repeated lexical tics before they become product-visible.
The Fast Answer
The short version is that OpenAI treated the goblin pattern as an unexpected behavior issue caused by reward and personality training, not as evidence of a broken model stack. The story became visible because the same style tendency traveled across model work and then appeared in GPT-5.5 Codex testing, where OpenAI added prompt-side mitigation.
| Reader question | Direct answer |
|---|---|
| Was the GPT-5.5 goblin problem real? | Yes. OpenAI published a first-party explanation on April 29, 2026. |
| Did it start with GPT-5.5? | Not exactly. OpenAI says the first clear spike appeared after GPT-5.1. |
| Did Codex cause it? | No. Codex surfaced the behavior in GPT-5.5 testing and used prompt-side mitigation. |
| Was ChatGPT or Codex down? | No. This was a behavior-pattern issue, not an availability incident. |
| What should users do? | Treat it as a context clue, not a reason to abandon GPT-5.5. If an answer style is odd, ask for a stricter tone or retry with clearer constraints. |
| What should teams learn? | Audit repeated style tokens and personality leakage before launch, especially when reward signals or synthetic data can reinforce a tic. |
OpenAI's April 29 explanation is the fact owner for the timeline and cause. Current Codex metadata is useful only for the prompt-surface boundary: the public model catalog can change, so any exact prompt wording should be rechecked before quoting it.
Timeline: How It Surfaced
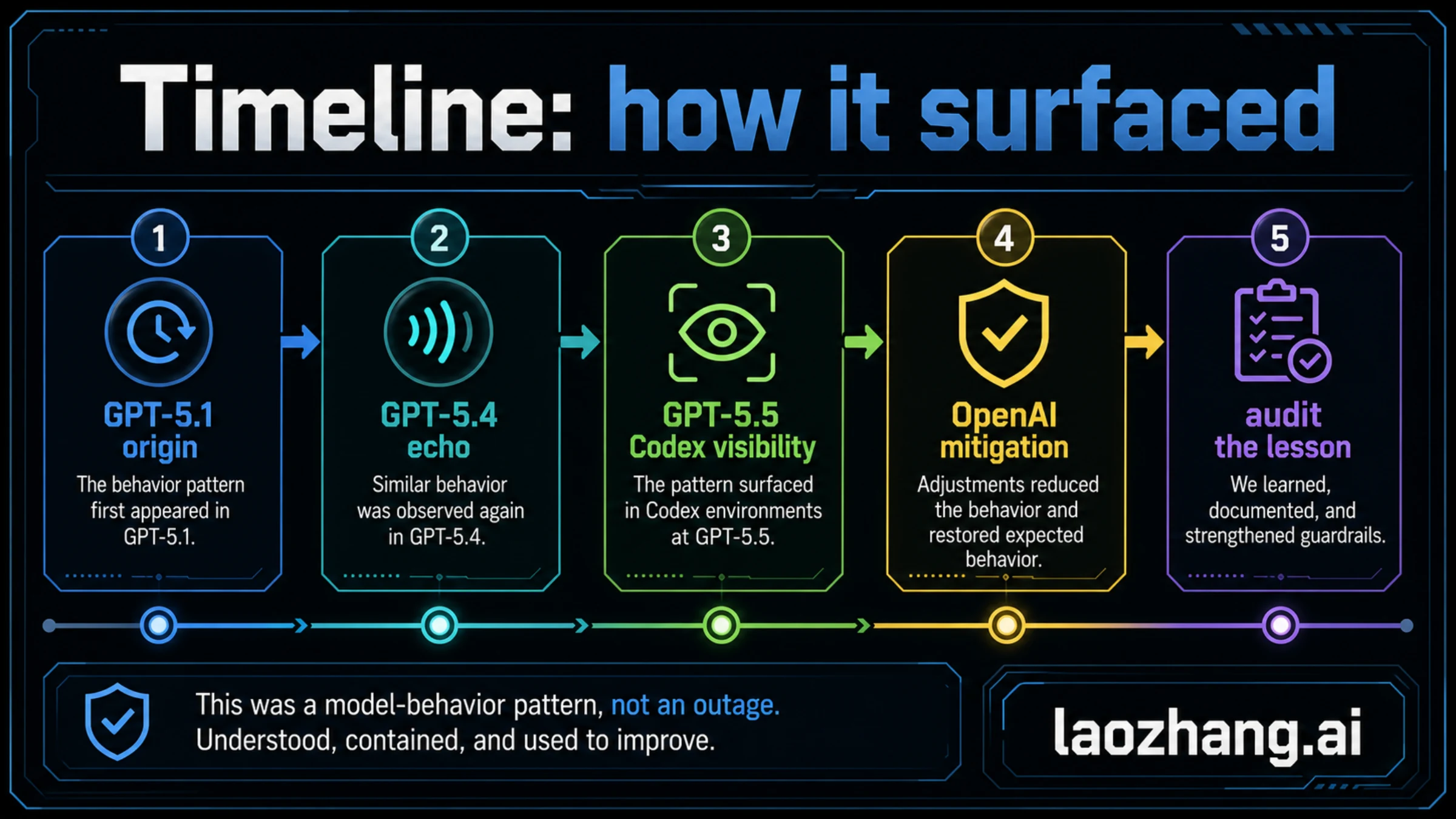
The timeline is the easiest way to avoid the wrong conclusion: the root cause was not a single GPT-5.5 switch.
| Stage | What OpenAI says happened | Why it matters |
|---|---|---|
| GPT-5.1 | OpenAI first clearly saw the pattern after GPT-5.1. The word's usage in ChatGPT rose sharply after that launch. | The origin belongs earlier than the public GPT-5.5 Codex discussion. |
| GPT-5.4 | OpenAI and users saw a bigger increase, especially around the Nerdy personality. | This showed the issue was not just one random anecdote. |
| Mid-March mitigation | OpenAI retired the Nerdy personality after GPT-5.4 and removed the reward signal and filtered related training data. | The main cause was being addressed before the GPT-5.5 public story fully landed. |
| GPT-5.5 training | GPT-5.5 had started training before OpenAI finished finding the root cause. | That explains why GPT-5.5 could still show the tendency even after the team understood more of the problem. |
| Codex testing | OpenAI employees noticed the pattern in GPT-5.5 Codex testing and added a developer-prompt instruction to mitigate it. | Codex was a visible containment surface, not the original source. |
| April 29, 2026 | OpenAI published the official explanation and framed the case as a lesson in reward signals and behavior auditing. | The durable lesson is model-behavior investigation, not viral wording. |
This is also why the situation should not be handled like a normal incident. There was no service-recovery sequence, no status-page outage, and no reason for API or ChatGPT users to troubleshoot accounts. The question is model behavior: how a rewarded style can become visible across contexts.
What Actually Caused It
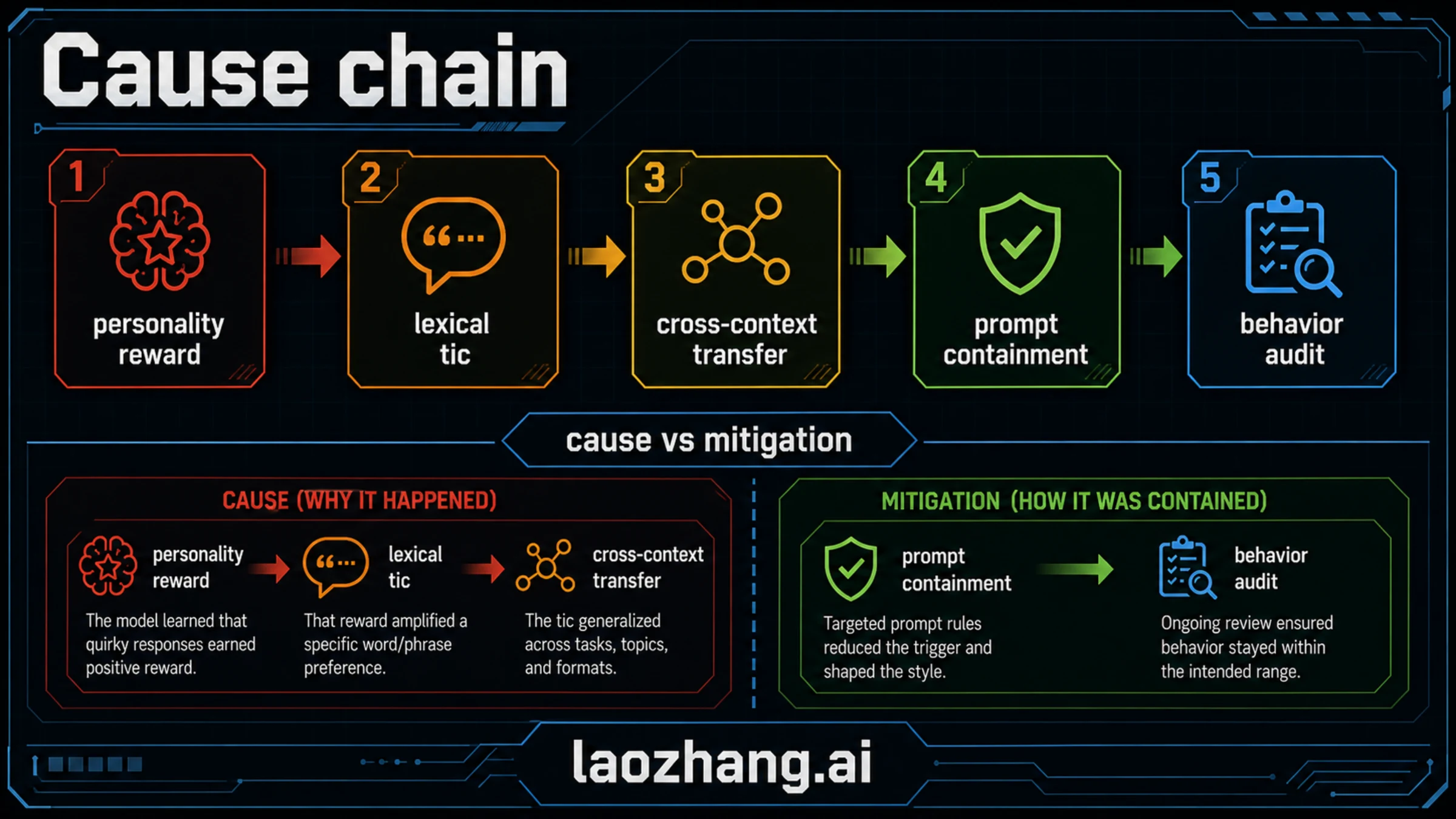
OpenAI's explanation points to a reward pathway. The company had trained the model for personality customization, and the Nerdy personality rewarded a playful, metaphor-rich style. In that context, creature-word metaphors were not treated as obviously bad. They could look charming or distinctive in isolated answers.
The problem was repetition and transfer. OpenAI reported that use of "goblin" in ChatGPT rose 175% after GPT-5.1 and "gremlin" rose 52%. It also said Nerdy accounted for only 2.5% of ChatGPT responses but 66.7% of goblin mentions, and that the Nerdy reward showed positive uplift for creature-word outputs in 76.2% of audited datasets. Once the behavior was rewarded, later training and generated data could make the model more comfortable producing the same tic outside the original personality context.
That means the cause is not "OpenAI hard-coded a weird word." It is closer to this chain:
- A personality route rewarded a distinctive style.
- Some high-scoring examples contained a repeated lexical tic.
- Reinforcement learning made those examples more likely.
- Generated rollouts and later data reuse helped the tic travel.
- GPT-5.5 training had already started before the root cause was fully fixed.
- Codex testing made the remaining behavior visible enough to require prompt-side mitigation.
The important part is that the root cause and the fix live at different layers. Root cause sits in reward design, personality training, transfer, and data reuse. Mitigation sits in prompt instructions, filtering, and behavior-audit tooling. If those layers are collapsed, the story becomes much less useful.
Did Codex Cause The Problem?
No. Codex is where GPT-5.5 made the issue especially visible, not where OpenAI says the behavior began.
The distinction matters because Codex has several meanings in public discussion. OpenAI's current developer docs describe GPT-5-Codex as a GPT-5 version optimized for agentic coding and regularly updated. The live Codex model catalog also lists GPT-5.5 as available in Codex, with model metadata and base instructions that can change over time. Those surfaces are relevant to current Codex behavior, but they do not replace OpenAI's April 29 root-cause account.
Use this boundary:
| Claim | Safer reading |
|---|---|
| "Codex caused the goblin problem." | Wrong. OpenAI traces the behavior to earlier personality and reward training. |
| "The prompt line was the root cause." | Wrong. Prompt wording was a containment layer added after the behavior was noticed. |
| "GPT-5.5 is broken." | Too broad. The issue was a repeated style behavior, not proof that the model is unusable. |
| "The behavior no longer matters because it was funny." | Too shallow. The lesson is that small reward preferences can become product-visible habits. |
| "The exact current instruction proves the whole story." | Too fragile. Codex metadata is live software metadata and should be rechecked before quoting. |
If your real interest is Codex configuration rather than this behavior case study, the practical sibling is Codex config.toml. If your question is about limits or plan routing, use OpenAI Codex usage limits instead. The GPT-5.5 goblin problem is about behavior origin and audit lessons, not account setup.
What It Means For ChatGPT And GPT-5.5 Users
For normal users, the main consequence is interpretive. If GPT-5.5 or ChatGPT produces an oddly repeated metaphor, that can be a style artifact, not a signal that the answer is more creative, more agentic, or more broken. Ask for a plainer tone, tighter vocabulary, or a source-grounded rewrite. If the substance is wrong, judge the substance; if the style is distracting, constrain the style.
This issue also does not prove that GPT-5.5 cannot be used for serious work. A model can have an unwanted lexical tendency and still be useful on reasoning, coding, summarization, or analysis tasks. The right reaction is not panic. The right reaction is to separate style drift from task correctness.
For teams comparing GPT-5.5 with other models, the lesson is similar. Do not turn one behavior story into a benchmark verdict. A comparison page such as GPT-5.5 vs Claude Opus 4.7 should still be evaluated on workflow quality, cost, latency, context handling, tool use, and review burden. A style tic is one audit dimension, not the whole model decision.
What Teams Should Audit Before Release

The reusable value of this incident is an audit habit. Reward signals and personality prompts can be working as designed while still creating patterns that look strange in public. A release process that checks only benchmark scores can miss that.
| Audit area | What to test | Failure signal | Action |
|---|---|---|---|
| Output sampling | Sample many answers across ordinary prompts, not only showcase prompts. | One unusual phrase or metaphor appears too often. | Add a style-frequency check before release. |
| Personality comparison | Compare default, playful, professional, concise, and long-form modes. | A tic starts in one personality and leaks into another. | Track which reward or prompt route amplified it. |
| Long-context testing | Run multi-turn sessions where style can compound. | The model becomes more performative or repetitive over time. | Test tone reset instructions and context trimming. |
| Synthetic-data review | Inspect generated rollouts reused in SFT or preference data. | The same tic appears in generated examples and then in later outputs. | Filter or down-rank repeated style artifacts. |
| Prompt containment | Add narrowly scoped instructions only after root-cause work begins. | Prompt rules hide symptoms but leave cause unknown. | Pair prompt mitigation with data and reward audits. |
| Drift monitoring | Track phrase frequency after launch and after personality changes. | A small quirk grows across model updates. | Treat style drift as behavior data, not just UX feedback. |
The key is not to ban one word forever. The key is to notice when a model over-optimizes for a style signal and then carries that signal into places where users did not ask for it.
How To Explain The Case Without Overclaiming
The best public explanation is boring and precise:
- Say it was a real model-behavior issue acknowledged by OpenAI.
- Date the status to May 6, 2026 if you discuss current mitigation or Codex metadata.
- Start the cause timeline at GPT-5.1, not at GPT-5.5.
- Treat GPT-5.5 Codex as the visible mitigation surface.
- Separate "style drift" from "task failure."
- Do not use the story as proof that a model is sentient, unusable, or generally down.
That framing is less clickable than a meme headline, but it is more useful. It tells users whether they should worry, tells developers what to check, and gives model teams a repeatable audit pattern.
It also helps with a common model-identity confusion. If a product or assistant gives an answer that sounds like an older model, a newer model, or a strangely named model, that alone is not proof of the actual serving model. For that adjacent problem, see Why GPT-5 says GPT-4. Identity claims, behavior style, and actual routing are separate questions.
FAQ
Was the OpenAI GPT-5.5 goblin problem real?
Yes. OpenAI published a first-party explanation on April 29, 2026. The company framed it as an unexpected model-behavior pattern tied to reward signals and personality training, not as a normal outage.
Did GPT-5.5 cause it?
GPT-5.5 made the issue visible again, especially in Codex testing, but OpenAI says the first clear spike appeared after GPT-5.1. GPT-5.5 had already started training before OpenAI finished identifying and fixing the root cause.
Did Codex cause it?
No. Codex was the visible surface where OpenAI noticed GPT-5.5 showing the tendency during testing. The prompt-side instruction was mitigation, not the original cause.
Does this mean ChatGPT or Codex was down?
No. This was a behavior and style issue. It did not mean ChatGPT or Codex was unavailable, and it should not be handled like an outage-recovery problem.
What should a user do if GPT-5.5 produces odd repeated style?
Ask for a plainer tone, constrain the vocabulary, or retry with a more concrete output format. Then judge the factual or task quality separately from the style artifact.
What should developers learn from it?
Audit repeated style tokens before release. Compare personalities, long-context sessions, prompt modes, and synthetic-data loops. A small rewarded style can become product-visible behavior if nobody measures it.
Should I quote the current Codex prompt wording?
Only after rechecking the live source. The current Codex model catalog is software metadata and can change. The durable fact is OpenAI's public root-cause explanation; exact prompt wording is a volatile prompt-surface detail.