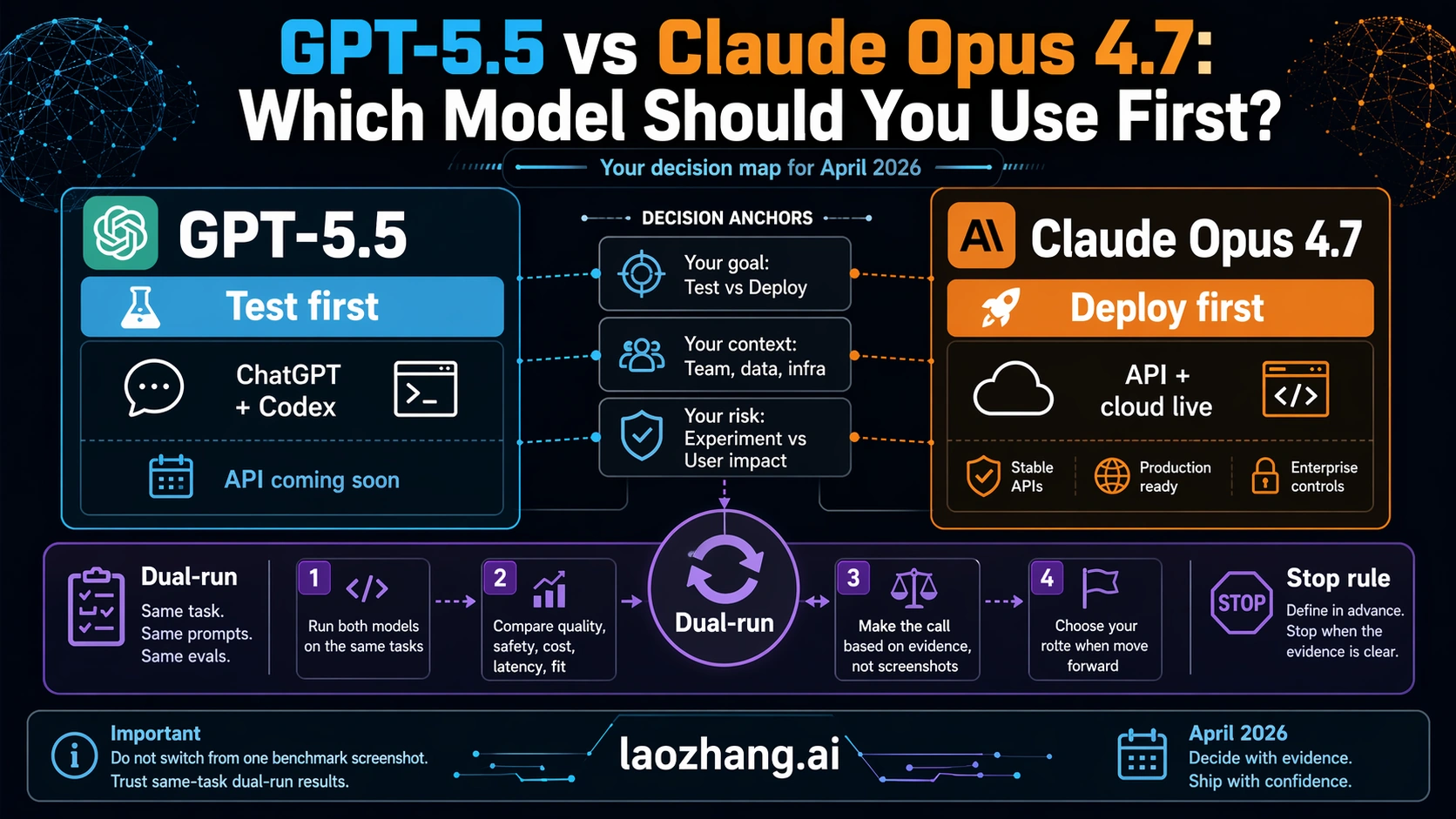
GPT-5.5 and Claude Opus 4.7 are not a symmetric API choice yet. As of Apr 24, 2026, GPT-5.5 is available in ChatGPT and Codex with API access coming soon, while Claude Opus 4.7 is already available through Anthropic and major cloud platforms.
The short version is simple: test GPT-5.5 first if your work is OpenAI-native and runs through ChatGPT or Codex; deploy Claude Opus 4.7 first if you need a production API or cloud endpoint today. If you are changing a paid workflow, dual-run both models on the same tasks before replacing your default.
| Route | Best first move | Why it fits | Stop rule |
|---|---|---|---|
| ChatGPT or Codex testing | Start with GPT-5.5. | It is OpenAI's newest frontier route for agentic coding and professional work inside OpenAI surfaces. | Do not plan a production API migration until official API access is live for your account. |
| Production API or cloud deployment | Start with Claude Opus 4.7. | It is already available through the Claude API, Amazon Bedrock, Google Vertex AI, and Microsoft Foundry. | Do not treat one benchmark table as proof that it is always worth the premium. |
| Output-heavy or budget-sensitive runs | Price both with real prompts. | GPT-5.5's listed API price is coming soon at $5 input and $30 output per million tokens; Opus 4.7 is live at $5 input and $25 output. | Recheck cache, batch, data-residency, and tokenization effects before approving spend. |
| Default model replacement | Dual-run before switching. | Replacement quality depends on failure rate, review load, and recovery cost, not launch-week rankings. | No default change without the same repo, same prompts, same tool budget, and same tests. |
The Fast Answer
If you need the operational answer before the details, use the model route rather than the model name.
| Need | Use first | Why | What to recheck |
|---|---|---|---|
| You work mainly in ChatGPT, Codex, or OpenAI-native coding flows. | GPT-5.5 | OpenAI's GPT-5.5 launch page presents it as the newest frontier route for professional and agentic work inside OpenAI surfaces. | API access, model ID, and production limits before you move server-side traffic. |
| You need a production API or cloud route today. | Claude Opus 4.7 | Anthropic's launch page says Opus 4.7 is available in the Claude API, Amazon Bedrock, Google Vertex AI, and Microsoft Foundry. | Your own latency, token use, and deployment-region constraints. |
| Your workload is output-heavy or budget-sensitive. | Claude Opus 4.7 as the live budget baseline. | Anthropic lists Opus 4.7 at $5 input and $25 output per million tokens; OpenAI lists GPT-5.5 API pricing as coming soon at $5 input and $30 output. | Cached-input behavior, batch discounts, US-only inference multipliers, and tokenization effects. |
| You want to plan a future GPT-5.5 API pilot. | Wait for the official API route, then test. | A coming-soon price is useful for planning, but it is not the same as a callable production endpoint. | The official OpenAI model docs and pricing page on the day you start. |
| You are replacing a working default. | Dual-run both on the same tasks. | Launch-week comparisons do not measure your failure modes, review load, or recovery cost. | Same prompts, same tools, same task budgets, same acceptance tests. |

The practical answer is therefore not "GPT-5.5 wins" or "Claude wins." GPT-5.5 is the first test when the work stays inside OpenAI's live surfaces. Claude Opus 4.7 is the first deploy route when you need an API endpoint or cloud provider today. A production migration should not be approved until both models have been tested on the exact workload that pays the bill.
Availability And Price Are The First Split
The cost comparison starts with availability. If one model is live in your deploy route and the other is still waiting for API access, the first decision is not a benchmark decision.
| Contract item | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| Current user surface | Rolling out in ChatGPT and Codex for paid OpenAI users, according to OpenAI's launch post. | Available across Claude products, according to Anthropic's Opus page. |
| API status as of Apr 24, 2026 | API access is coming soon. Do not treat the listed price as a live endpoint. | Live in the Anthropic API and major cloud platforms. |
| API model ID | Recheck OpenAI docs when the API route goes live; do not invent one. | claude-opus-4-7, listed in Anthropic's model overview. |
| Standard API price | OpenAI's pricing page lists GPT-5.5 as coming soon at $5 input, $0.50 cached input, and $30 output per million tokens. | Anthropic's pricing docs list $5 input and $25 output per million tokens, with cache and batch options. |
| Context and output | Recheck when GPT-5.5 API access is live for your account. | 1M context and 128k max output in the Messages API, per Anthropic's model docs. |
| High-end variant | GPT-5.5 Pro is a future high-accuracy route, not the default API comparison today. | Opus 4.7 is already the premium Opus route. |
That table changes the default move. A developer building a production integration today can put Opus 4.7 into a live evaluation path immediately. A developer who wants GPT-5.5 in the API should plan the test, save the evaluation harness, and wait for the official callable route instead of shipping against rumors or unofficial model IDs.
The output-price difference also matters. If GPT-5.5 launches at the currently listed API price, its output side is higher than Opus 4.7's live list price. That does not automatically make Opus cheaper for every job because cached input, batch pricing, prompt length, and tokenizer behavior can change the invoice. It does mean output-heavy use cases should not assume the new OpenAI model is the budget default.
How To Read The Benchmarks

The benchmark table only helps if you map it to the workload. Provider-published launch rows are useful evidence, but they are not a neutral universal crown.
OpenAI's GPT-5.5 launch materials report strong numbers against Claude Opus 4.7 and other current models on several agentic and professional-work evaluations. The most useful rows for this comparison are the ones that resemble coding agents, tool use, or paid professional work:
| Reported benchmark | OpenAI-reported GPT-5.5 result | OpenAI-reported Claude Opus 4.7 comparator | Practical reading |
|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | 69.4% | Strong reason to test GPT-5.5 first inside Codex or terminal-style OpenAI workflows. |
| GDPval-agentic | 84.9% | 80.3% | Useful for professional task quality, but still needs your domain-specific review loop. |
| OSWorld-Verified | 78.7% | 78.0% | Nearly tied enough that deployment route and harness quality matter more than the row. |
| BrowseComp | 84.4% | Anthropic comparator depends on the published table context. | Treat as a browsing/research signal, not a production API decision by itself. |
| FrontierMath Tier 4 | 35.4% | Use the source table, not summaries. | Hard-reasoning rows should inform pilots, not replace workload tests. |
| CyberGym | 81.8% | Use the source table, not summaries. | Security-style results are relevant only if your tasks resemble the benchmark. |
This is enough to justify taking GPT-5.5 seriously for agentic coding and professional task pilots. It is not enough to approve a blanket replacement. OpenAI owns the benchmark source, Anthropic owns the Opus API contract, and your workload owns the final decision.
The strongest benchmark-based mistake is to compare a live API model and a not-yet-live API model as if both were equally deployable. If you are choosing what to test in ChatGPT or Codex, GPT-5.5's reported rows are highly relevant. If you are choosing what to put behind an API route today, availability remains the first filter and Opus 4.7 has the cleaner deployability contract.
Which Model Fits Coding And Agents
Use GPT-5.5 first when your actual route is OpenAI-native: ChatGPT for analysis, Codex for code work, or an OpenAI-centered workflow where the operator experience matters as much as the model API. In that setting, the practical question is "does GPT-5.5 reduce review load and complete harder tasks inside the tools I already use?" That is a good question to answer immediately because the surface is live.
Use Claude Opus 4.7 first when your actual route is API-first, Claude-native, or cloud-provider-first. Anthropic's current Opus materials position it around coding, agents, long context, high-resolution images, and higher-effort control. More importantly, the route is already deployable through Anthropic and the major cloud platforms. If you need a model in a server workflow today, that contract matters more than launch-day excitement around a coming-soon API.
The fair engineering test is simple:
- Pick ten tasks that already cost real review time.
- Run GPT-5.5 in the OpenAI surface where it is live.
- Run Opus 4.7 through the API or cloud route you would actually deploy.
- Score first-pass correctness, tool recovery, format stability, token use, latency, and human review minutes.
- Promote the model only if it improves the task outcome, not just the benchmark story.
If the test is mostly repo edits, terminal tasks, and OpenAI-native coding, GPT-5.5 deserves the first seat. If the test is a production agent with explicit API budgets, cloud routing, long context, and controlled rollout needs, Opus 4.7 deserves the first seat.
Context, Output, And Migration Risk
Context and output limits matter most when the task is not a short chat. Claude Opus 4.7 has a clear live contract: Anthropic's docs list a 1M context window and 128k max output in the Messages API. Anthropic's pricing docs also say Opus 4.7 includes the full 1M context window at standard pricing, which is important because some secondary pages still describe older or different long-context premium assumptions.
GPT-5.5's API context and production limits should be rechecked when API access is live. Until then, the honest wording is "planned API route" or "coming-soon API pricing," not "deploy it today." This distinction is not pedantic. Context windows, rate limits, tool availability, model IDs, and billing behavior are exactly the details that change a production migration.
Opus 4.7 also has migration hazards that should be visible before anyone approves a switch. Anthropic's current "what's new" docs say non-default sampling parameters such as temperature, top_p, and top_k return a 400 error, old extended-thinking budget fields are removed, and the newer tokenizer can use up to about 35% more tokens for fixed text depending on content. Those are not reasons to avoid Opus. They are reasons to test the real harness instead of changing one model string and calling the migration done.
For long-form coding agents, document review, and production workflows, the deciding question is not just "which model has more context?" It is "which route can hold the needed context, produce the needed output, stay inside cost limits, and fail in ways my system can recover from?"
If You Already Use GPT-5.4 Or Opus 4.7
If you already use GPT-5.4 through the API, do not rip it out just because GPT-5.5 launched. GPT-5.5 is the right new OpenAI-native pilot, but GPT-5.4 remains the deployable OpenAI API baseline until the GPT-5.5 API route is live for your account. If your broader choice is still "OpenAI route, Anthropic route, or Google route," the existing Claude Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro comparison is the better adjacent page.
If you already use Claude Opus 4.7, the GPT-5.5 launch should trigger a pilot, not an automatic replacement. Keep Opus 4.7 as the deployable route when the API contract is the reason you chose it. Then compare GPT-5.5 inside OpenAI's live surfaces and decide whether its gains are large enough to revisit your production route once API access is official.
If your real question is Anthropic-side migration behavior, not OpenAI-vs-Anthropic route selection, use the narrower Claude Opus 4.7 vs Claude Opus 4.6 guide. That page owns the same-family upgrade question, prompt behavior, and cost drift more directly than this comparison should.
Practical Switch Plan
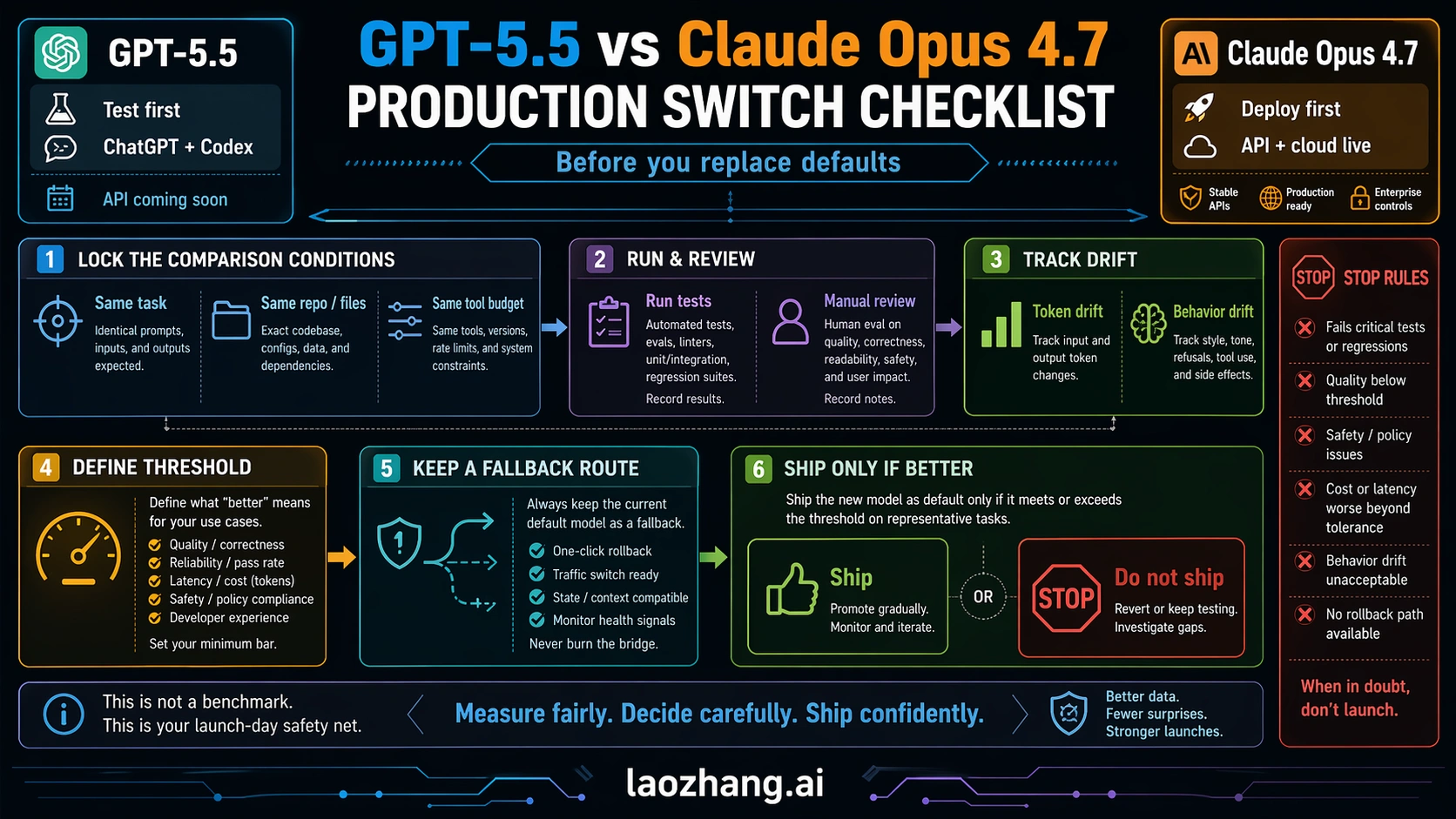
A model switch should have a release plan. The minimum useful plan has six checks:
| Check | What to do | Pass condition |
|---|---|---|
| Route check | Confirm whether the model is live in the surface you need: ChatGPT, Codex, API, or cloud. | No production plan depends on a coming-soon endpoint. |
| Task set | Choose representative tasks, not cherry-picked demos. | The set includes easy, hard, long-context, output-format, and failure-prone tasks. |
| Harness parity | Run both models with the same prompts, tools, files, and task budgets where the surfaces allow it. | Differences are caused by model behavior, not by a better test setup for one side. |
| Quality score | Track correctness, recovery, formatting, and human review minutes. | The winner reduces total work, not just first-impression quality. |
| Cost score | Measure input, cached input, output, retries, and task-level cost. | The chosen route is affordable under the real workload. |
| Rollback route | Keep the old model or fallback route available during rollout. | A failed migration can be reversed without rebuilding the pipeline. |
For a small team, this can be one afternoon of disciplined testing. For an enterprise workflow, it should become a staged rollout: private pilot, shadow run, limited production route, then default switch. Either way, the decision threshold is the same. Do not switch because the model is new. Switch because it reduces failure, time, or cost on the work you actually run.
FAQ
Is GPT-5.5 better than Claude Opus 4.7?
It depends on the route and workload. GPT-5.5 is the better first test for OpenAI-native ChatGPT and Codex work. Claude Opus 4.7 is the better first deploy route when you need a live API or cloud endpoint today.
Is GPT-5.5 available in the API?
As of Apr 24, 2026, OpenAI describes GPT-5.5 API access as coming soon. The pricing page is useful for planning, but it should not be treated as proof that the model is callable in production today.
Which model is cheaper?
For live API deployment today, Opus 4.7 has the clearer price: $5 input and $25 output per million tokens, before cache, batch, and regional adjustments. OpenAI lists GPT-5.5 as coming soon at $5 input and $30 output, so output-heavy work should price both with real prompts once GPT-5.5 API access is live.
Which model is better for coding agents?
GPT-5.5 should be tested first for Codex and OpenAI-native coding workflows. Opus 4.7 should be tested first for Claude API agents, cloud deployment, long-context agent loops, and teams that need a production endpoint now.
Does Opus 4.7 still win anywhere?
Yes. It wins the deployability question today for API and cloud routes, and it has a clear live contract around 1M context, 128k output, and production availability across multiple platforms.
Should I wait for GPT-5.5 API?
Wait if your goal is specifically an OpenAI API migration to GPT-5.5. Do not wait if your immediate need is a production API route and Opus 4.7 already fits the job. Keep GPT-5.5 in the pilot plan and recheck OpenAI docs when the API goes live.
What about GPT-5.5 Pro?
GPT-5.5 Pro is a future higher-accuracy route with much higher listed API pricing. It is not the default comparison for most teams deciding between GPT-5.5 and Claude Opus 4.7 today.
Use GPT-5.5 first when the work lives inside OpenAI's live surfaces. Use Claude Opus 4.7 first when the work needs a deployable API or cloud route now. If money or production reliability is involved, make both models earn the switch on the same tasks before you change the default.