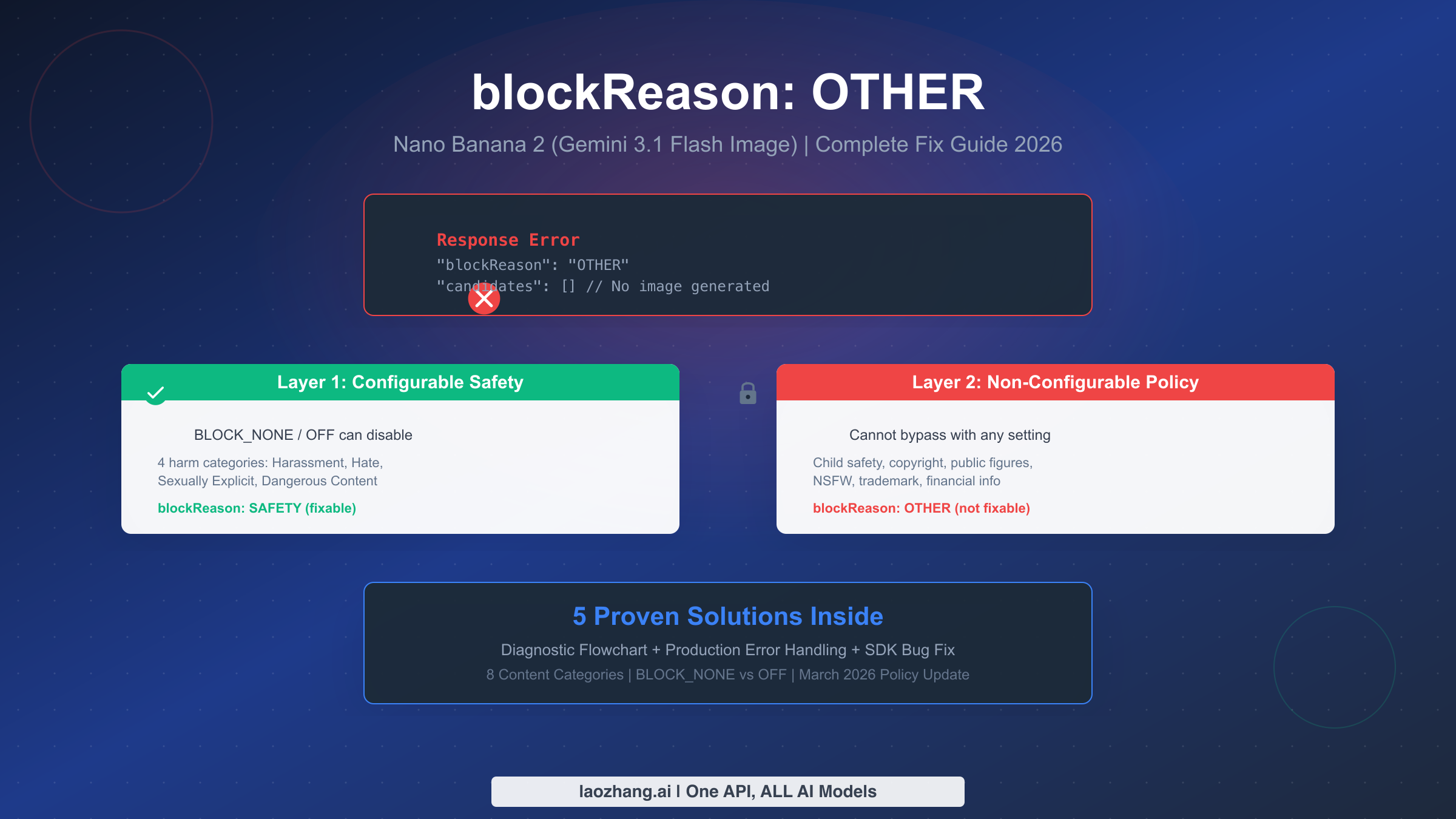
blockReason OTHER in Nano Banana 2 (Gemini 3.1 Flash Image, model ID gemini-3.1-flash-image-preview) means your request was blocked by Google's Layer 2 policy enforcement—a non-configurable server-side filter that cannot be bypassed by setting safety thresholds to BLOCK_NONE or OFF. As of March 2026, this filter covers 8 content categories including copyrighted characters, public figures, and NSFW content. This guide explains the complete blockReason vs finishReason mapping, the dual-layer safety architecture, and provides 5 proven solutions with production-ready code.
TL;DR
- blockReason OTHER ≠ blockReason SAFETY: OTHER comes from Layer 2 (non-configurable policy enforcement), while SAFETY comes from Layer 1 (adjustable via
harm_block_threshold). SettingBLOCK_NONEorOFFonly affects Layer 1 and will never fix a Layer 2 block. - 8 content categories trigger blockReason OTHER: NSFW content, copyrighted characters/famous IP, public figures, minor protection, watermark removal, financial info modification, outfit/face swapping, and implicit suggestive content. March 2026 tightened enforcement on 4 of these categories.
- blockReason vs finishReason are different fields:
blockReasonappears when the prompt is rejected before generation starts (zero tokens consumed).finishReasonappears when content is blocked during or after generation (tokens already consumed). Both can return OTHER-related values. - python-genai SDK bug: Accessing
response.candidates[0].finish_reasonon a blocked response hangs indefinitely because the candidates array is empty. Always checklen(response.candidates) > 0first. - 5 proven workarounds exist: Rephrase prompts, remove copyrighted references, split complex prompts, add timeout with model fallback, or use alternative image models (GPT Image, FLUX.2) as a fallback pipeline.
What Does blockReason OTHER Actually Mean?

When you send an image generation request to Nano Banana 2 and receive blockReason: "OTHER" in the API response, it means your prompt was intercepted by Google's second layer of content filtering before any image generation began. This is fundamentally different from a blockReason: "SAFETY" response, which comes from the first layer of filtering that you can control through safety settings. Understanding this distinction is the single most important step toward resolving the error, because it determines whether you can fix the problem through configuration changes or need to take a completely different approach.
The confusion between blockReason and finishReason is the second most common source of frustration among developers working with the Gemini image generation API. These two fields appear in different parts of the response, carry different implications for billing, and require different troubleshooting strategies. The table below provides the complete mapping that, until now, you would need to read five separate articles to piece together.
blockReason Values (Prompt-Level Blocking)
The blockReason field appears in the prompt_feedback section of the API response. When present, it means the prompt was rejected before any generation started, so no tokens were consumed and no partial image exists.
| blockReason Value | Source Layer | Configurable? | What It Means |
|---|---|---|---|
SAFETY | Layer 1 | Yes (via harm_block_threshold) | One of the 4 harm categories exceeded your configured threshold. Set BLOCK_NONE or OFF to resolve. |
OTHER | Layer 2 | No | Server-side policy enforcement detected prohibited content in your prompt. Cannot be bypassed. |
BLOCKED_REASON_UNSPECIFIED | Either | Varies | Rare catch-all. Check both safety ratings and prompt content. |
When you receive a blockReason OTHER response, the JSON structure looks like this:
json{ "promptFeedback": { "blockReason": "OTHER" }, "candidates": [] }
Notice that the candidates array is completely empty. There are no safety ratings to inspect, no partial content to recover, and no specific category telling you exactly what triggered the block. This is by design—Google's Layer 2 filter intentionally does not reveal which policy rule was violated, as doing so could help adversarial users craft prompts that narrowly avoid detection.
finishReason Values (Generation-Level Blocking)
The finishReason field appears inside each candidate object and indicates why generation stopped. Unlike blockReason, these blocks happen during generation, meaning tokens have already been consumed and you may see partial text output (though never a partial image).
| finishReason Value | Source Layer | What It Means |
|---|---|---|
STOP | N/A | Normal completion. Image generated successfully. |
SAFETY | Layer 1 | Generated content triggered a configurable safety filter. Adjustable via settings. |
IMAGE_SAFETY | Layer 2 | Image-specific safety violation detected during generation. Not configurable. |
OTHER | Layer 2 | Copyright, trademark, or famous IP detected in generated content. Not configurable. |
PROHIBITED_CONTENT | Layer 2 | Child safety or legally prohibited content. Strictest enforcement, not configurable. |
The critical distinction is timing: blockReason fires before generation (costs nothing), while finishReason fires during generation (costs tokens). If you are seeing finishReason: "OTHER" instead of blockReason: "OTHER", it means your prompt passed the initial filter but the generated image was caught by the second layer. This typically indicates copyright or trademark content that only becomes apparent during image synthesis—for example, a prompt like "a cartoon mouse with round ears" might pass the prompt filter but trigger finishReason: OTHER when the generated image resembles a copyrighted character.
As confirmed in GitHub Issue #276, Google has stated that mandatory filters including child safety protections cannot be disabled, and there is no programmatic workaround for Layer 2 blocks. This is a deliberate architectural decision, not a bug.
Why BLOCK_NONE Cannot Fix blockReason OTHER
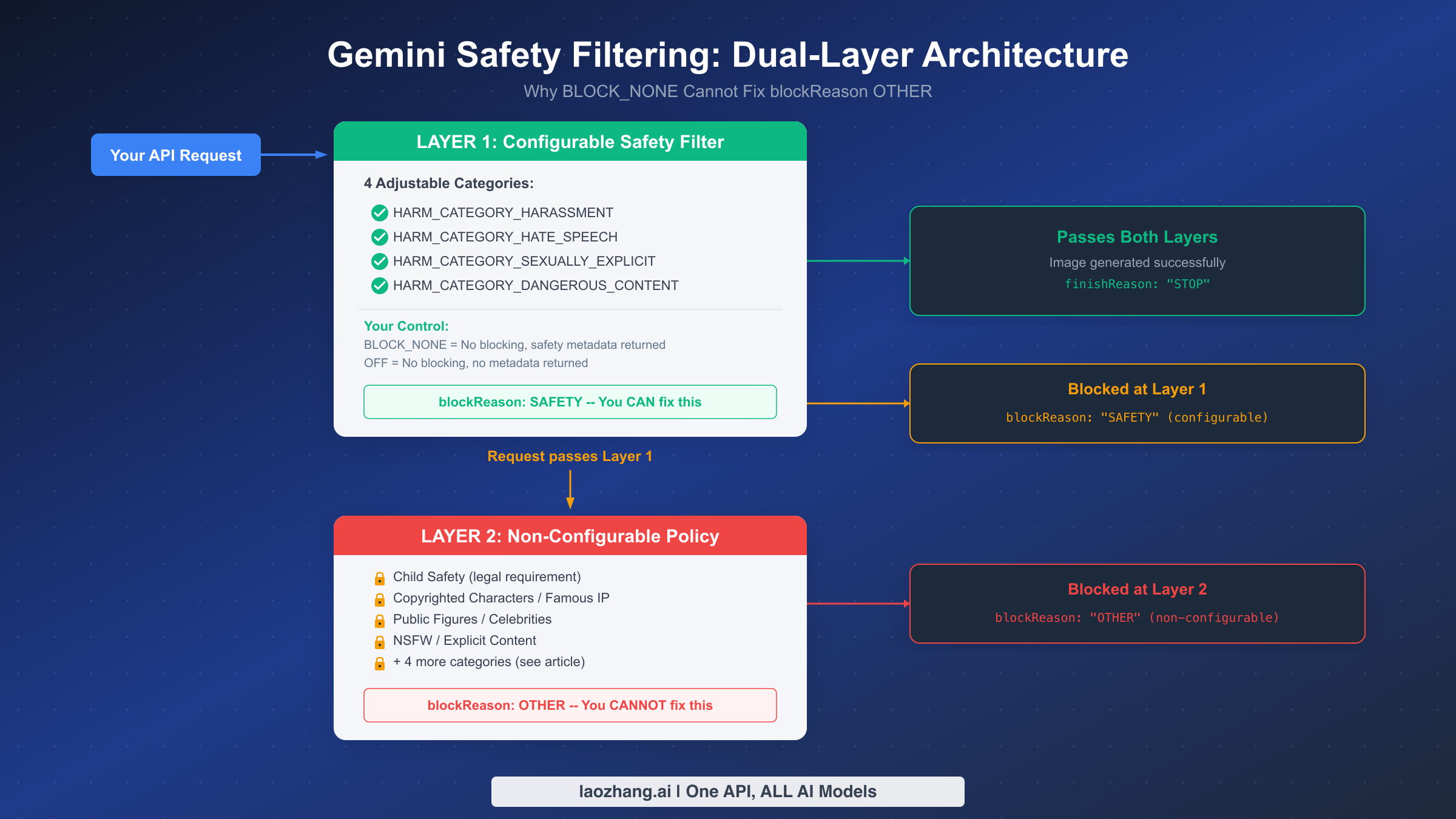
The most common mistake developers make when encountering blockReason OTHER is immediately trying to set all safety categories to BLOCK_NONE or OFF, expecting this to resolve the error. This approach fails because it fundamentally misunderstands how Gemini's safety filtering architecture works. The system operates on two completely independent layers, and your safety settings only control the first one. For a deeper understanding of all available safety configurations, see our detailed guide to Gemini safety settings.
Layer 1: Configurable Safety Filter
Layer 1 evaluates your prompt and generated content against four harm categories that you can individually configure: HARM_CATEGORY_HARASSMENT, HARM_CATEGORY_HATE_SPEECH, HARM_CATEGORY_SEXUALLY_EXPLICIT, and HARM_CATEGORY_DANGEROUS_CONTENT. For each category, you set a harm_block_threshold that determines how sensitive the filter should be. When a Layer 1 filter triggers, you receive blockReason: "SAFETY" with detailed safety ratings telling you exactly which category was triggered and at what confidence level.
You have two options for controlling Layer 1. Setting the threshold to BLOCK_NONE disables automatic blocking but still returns safety metadata in the response, which is useful for monitoring and logging. Setting the threshold to OFF (available since gemini-2.5-flash and newer models, according to Vertex AI documentation as of January 2026) disables both blocking and metadata collection entirely. For Nano Banana 2, which is built on Gemini 3.1 Flash, both options are available and either one completely eliminates Layer 1 blocks.
Here is how to configure Layer 1 to be maximally permissive:
pythonfrom google import genai from google.genai import types client = genai.Client(api_key="YOUR_API_KEY") safety_settings_block_none = [ types.SafetySetting( category="HARM_CATEGORY_HARASSMENT", threshold="BLOCK_NONE" ), types.SafetySetting( category="HARM_CATEGORY_HATE_SPEECH", threshold="BLOCK_NONE" ), types.SafetySetting( category="HARM_CATEGORY_SEXUALLY_EXPLICIT", threshold="BLOCK_NONE" ), types.SafetySetting( category="HARM_CATEGORY_DANGEROUS_CONTENT", threshold="BLOCK_NONE" ), ] # Option 2: OFF - no blocking AND no safety metadata safety_settings_off = [ types.SafetySetting( category="HARM_CATEGORY_HARASSMENT", threshold="OFF" ), # ... same for other categories ]
Layer 2: Non-Configurable Policy Enforcement
Layer 2 is a completely separate system that operates independently of your safety settings. It enforces Google's content policies, legal requirements, and terms of service through server-side filters that cannot be accessed, modified, or bypassed through any API parameter. When Layer 2 triggers, you receive blockReason: "OTHER" with no safety ratings, no category information, and no way to determine which specific policy was violated.
Layer 2 covers content categories that go beyond general safety concerns and into legal liability territory: child safety (a legal requirement in most jurisdictions), copyrighted characters and trademarked visual identities, identifiable public figures and celebrities, NSFW content that violates Google's terms of service, and several other categories detailed in the next section. These filters exist because Google faces direct legal liability if its image generation API produces certain types of content, regardless of what the developer's intended use case is.
The practical implication is straightforward: if you are receiving blockReason: "OTHER", no amount of safety setting configuration will help. You have confirmed this by setting all four categories to BLOCK_NONE or OFF and still getting blocked. The block is not coming from the system you control. It is coming from a system that sits behind it, and the only path forward is to modify your prompt or use an alternative approach, which we cover in the solutions section below.
Step-by-Step Diagnostic Flowchart
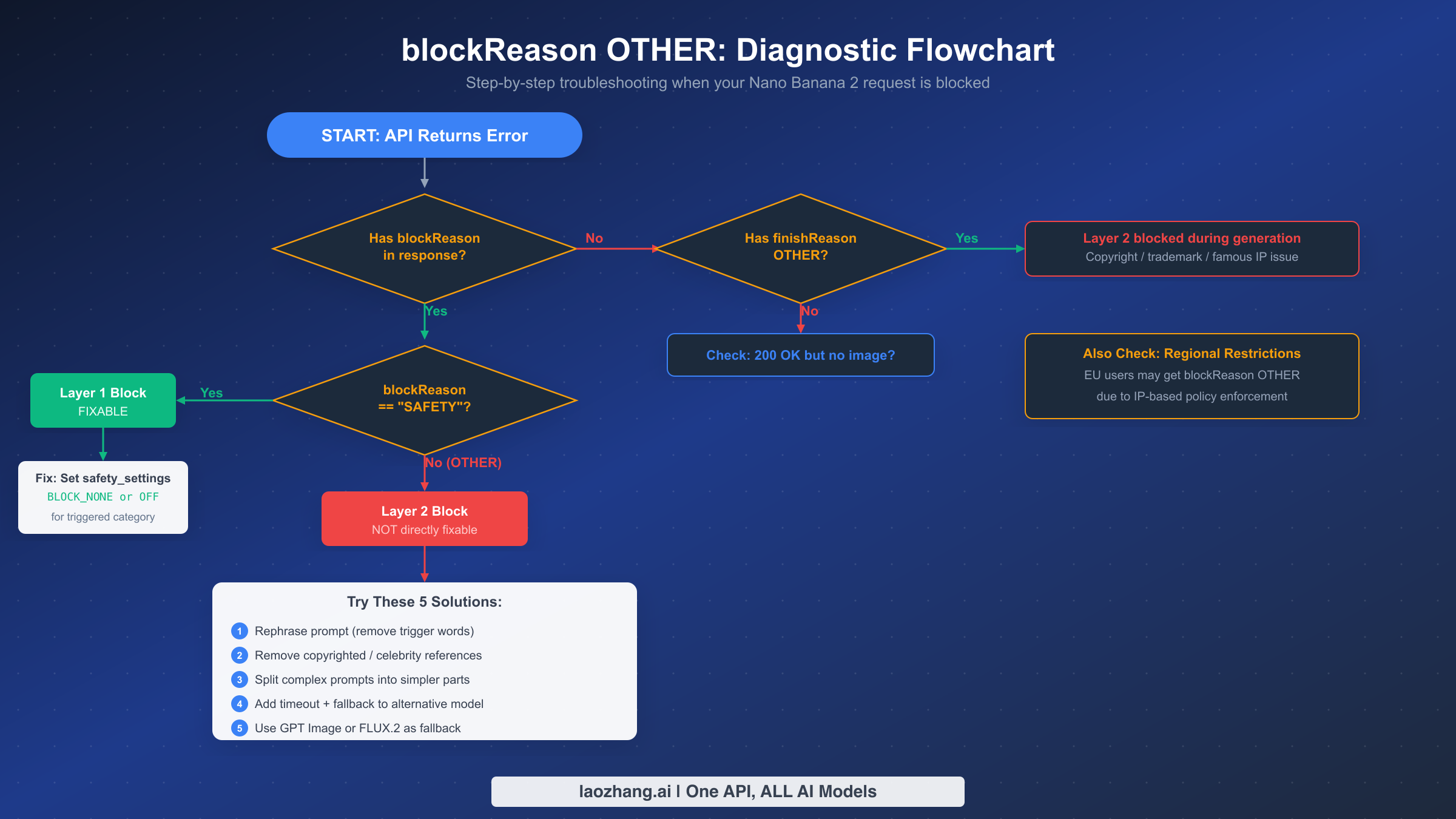
When your Nano Banana 2 API call returns an error, the first step is not to immediately change safety settings—it is to determine exactly what type of error you are dealing with. Different error types require completely different solutions, and applying the wrong fix wastes time and API quota. This diagnostic flowchart provides a systematic approach that eliminates guesswork.
Start by checking whether your response contains a blockReason field in the prompt_feedback section. If there is no blockReason present, the issue may be a different type of error entirely. Check for finishReason: "OTHER" in the candidates array, which indicates the prompt passed but the generated content was blocked mid-generation due to copyright or trademark issues. If neither blockReason nor finishReason OTHER is present, you may be dealing with a 200 OK but no image generated scenario or a 503 overloaded error, which require their own troubleshooting paths. For other common Nano Banana 2 errors, see our guide on the thought signature error.
If blockReason is present, check its value. If the value is SAFETY, you are dealing with a Layer 1 block that is fixable through safety settings configuration. Inspect the safety ratings in the response to identify which category was triggered, then set that category's threshold to BLOCK_NONE or OFF. If the value is OTHER, you have confirmed a Layer 2 block, and the solutions in this guide apply.
Here is the diagnostic code that automates this process:
pythondef diagnose_block(response): """Systematically diagnose why a Nano Banana 2 request was blocked.""" # Step 1: Check for prompt-level blocking if hasattr(response, 'prompt_feedback') and response.prompt_feedback: block_reason = getattr(response.prompt_feedback, 'block_reason', None) if block_reason == 'SAFETY': # Layer 1 block - fixable via safety settings ratings = response.prompt_feedback.safety_ratings triggered = [r for r in ratings if r.blocked] return { 'type': 'LAYER_1_BLOCK', 'fixable': True, 'categories': [r.category for r in triggered], 'action': 'Set triggered categories to BLOCK_NONE or OFF' } elif block_reason == 'OTHER': # Layer 2 block - not fixable via settings return { 'type': 'LAYER_2_BLOCK', 'fixable': False, 'action': 'Rephrase prompt or use alternative model' } # Step 2: Check for generation-level blocking if len(response.candidates) > 0: finish_reason = response.candidates[0].finish_reason if finish_reason == 'OTHER': return { 'type': 'LAYER_2_GENERATION_BLOCK', 'fixable': False, 'action': 'Copyright/trademark detected during generation' } if finish_reason == 'IMAGE_SAFETY': return { 'type': 'IMAGE_SAFETY_BLOCK', 'fixable': False, 'action': 'Image content violated safety policy' } # Step 3: No candidates and no block reason if len(response.candidates) == 0: return { 'type': 'EMPTY_RESPONSE', 'fixable': False, 'action': 'Check for 200 OK no-image scenario' } return {'type': 'UNKNOWN', 'action': 'Inspect full response JSON'}
One critical detail to note for Python developers using the google-genai SDK: attempting to access response.candidates[0].finish_reason when the candidates array is empty will cause the SDK to hang indefinitely rather than raising an exception. This is a known bug (as of March 2026) where the SDK attempts to lazily evaluate the candidate object and enters an infinite wait state. Always check len(response.candidates) > 0 before accessing any candidate properties. If you encounter this hang, the only recovery is to kill the process.
Regional Considerations
Developers in the EU should be aware that IP-based policy enforcement can trigger blockReason OTHER even for prompts that work fine from other regions. This is due to Google applying stricter content policies in jurisdictions with more restrictive regulations around AI-generated imagery. If you suspect regional blocking, testing the same prompt from a different geographic region can help confirm whether the block is content-based or region-based.
8 Content Categories That Trigger blockReason OTHER
Understanding exactly what content triggers Layer 2 blocking helps you craft prompts that avoid unnecessary rejections. Through cross-referencing Google's official documentation, community reports, and systematic testing documented across multiple sources, we have identified 8 distinct content categories that consistently trigger blockReason OTHER in Nano Banana 2. As of March 2026, Google has tightened enforcement on 4 of these categories, which explains why prompts that previously worked may now be blocked.
NSFW and Sexually Explicit Content is the broadest category and catches any prompt requesting nudity, sexual acts, or fetish content. Unlike Layer 1's HARM_CATEGORY_SEXUALLY_EXPLICIT which you can set to BLOCK_NONE, Layer 2's NSFW filter operates independently and cannot be disabled. This catches prompts that Layer 1 would have allowed at the BLOCK_NONE threshold, creating the confusing situation where your safety settings say "allow everything" but the request is still blocked.
Copyrighted Characters and Famous IP triggers when your prompt references characters owned by major intellectual property holders—think iconic animated characters, video game protagonists, or comic book superheroes. This is one of the categories where you are more likely to see finishReason: OTHER rather than blockReason: OTHER, because the copyright detection often happens during image synthesis when the generated image starts to resemble a protected character, even if your prompt text did not explicitly name one.
Public Figures and Celebrities was significantly tightened in March 2026. Previously, prompts referencing public figures in non-controversial contexts (such as "a person who looks like [celebrity] giving a speech") sometimes passed through. The March 2026 policy update expanded detection to catch more indirect references and artistic style imitations. If your prompts that previously generated images of recognizable public figures are now returning blockReason OTHER, this policy change is the most likely explanation.
Minor Protection is the strictest category with zero tolerance. Any prompt that could potentially generate images of minors in inappropriate or exploitative contexts is blocked immediately. As confirmed in GitHub Issue #276, this is a legal requirement that Google has stated will never have a workaround. This filter has the highest false-positive rate, sometimes catching innocent prompts about children's illustrations or family photos.
Watermark Removal targets prompts asking to remove, replace, or obscure watermarks in reference images. This applies specifically to image editing workflows where a reference image is provided and the prompt instructs the model to remove branding or copyright notices.
Financial Information Modification is a category added in the March 2026 policy update. Prompts requesting generation or modification of financial documents, currency, checks, bank statements, or official identification documents now trigger blockReason OTHER. This was previously handled with lower priority and often slipped through Layer 2.
Outfit and Face Swapping saw increased enforcement in March 2026. Prompts that ask to swap faces between images, place a person's likeness onto a different body, or change a person's clothing in a way that could create misleading imagery are now caught more aggressively. This overlaps with the public figures category when the subject is recognizable.
Implicit Suggestive Content is the most nuanced category and the hardest to predict. It catches prompts that do not explicitly request inappropriate content but use coded language, euphemisms, or contextual combinations that the model interprets as suggestive. This category was expanded in March 2026 to catch more indirect phrasing patterns, which is why previously innocuous-seeming prompts may now trigger blocks.
The practical takeaway is that Layer 2 operates on a content-level analysis rather than a keyword-level analysis. Simply avoiding certain words is not sufficient—the model evaluates the semantic meaning and likely visual output of your entire prompt. The solutions section below provides specific strategies for avoiding content filtering while still achieving your desired creative output.
5 Proven Solutions to Work Around blockReason OTHER
Since blockReason OTHER cannot be resolved through safety settings, the following solutions take a different approach: modifying your input, restructuring your workflow, or routing to alternative models. These solutions are ordered from simplest to most robust, and in production environments, you will likely want to implement multiple solutions as a layered fallback strategy.
Solution 1: Rephrase Your Prompt to Remove Trigger Patterns. The most direct approach is to identify and remove the specific language patterns that triggered the block. Since Layer 2 analyzes semantic meaning rather than just keywords, effective rephrasing goes beyond simple word substitution. Replace character names with generic descriptions ("a friendly cartoon animal" instead of a specific character name), replace celebrity references with attribute descriptions ("a professional woman with short dark hair giving a presentation" instead of naming someone), and break compound concepts into separate, simpler prompts. If a complex scene description triggers a block, try generating individual elements separately and composing them afterward.
Solution 2: Remove All Copyrighted and Celebrity References. This is a more aggressive version of Solution 1 that specifically targets the two categories responsible for most blockReason OTHER errors. Audit your prompt for any reference to branded characters, trademarked visual styles, recognizable art styles associated with specific artists, celebrity names or descriptions that could identify a public figure, and any brand logos or product designs. Even indirect references like "in the style of [famous artist]" can trigger blocks if the style is closely associated with copyrighted works.
Solution 3: Split Complex Prompts into Simpler Parts. Complex prompts that combine multiple concepts have a higher probability of triggering Layer 2 because each additional concept increases the chance that the combined semantic meaning crosses a policy boundary. Breaking a single complex prompt into 2-3 simpler generation requests, then composing the results, often succeeds where the combined prompt fails. For example, instead of "a person in a specific outfit at a specific landmark doing a specific action," generate the scene and the subject separately.
Solution 4: Add Timeout and Automatic Model Fallback. For production applications, the most reliable approach is to implement automatic fallback to an alternative image model when Nano Banana 2 returns blockReason OTHER. This acknowledges the reality that some prompts will always be blocked by Layer 2, and ensures your application remains functional. Some API proxy services like laozhang.ai aggregate multiple image models behind a unified endpoint, making it straightforward to implement fallback between Nano Banana 2 and alternative models without managing multiple API integrations.
pythonimport asyncio from google import genai async def generate_with_fallback(prompt, timeout_seconds=30): """Generate image with Nano Banana 2, falling back to alternatives.""" client = genai.Client(api_key="YOUR_GEMINI_KEY") try: # Attempt Nano Banana 2 with timeout response = await asyncio.wait_for( asyncio.to_thread( client.models.generate_content, model="gemini-3.1-flash-image-preview", contents=prompt, config=types.GenerateContentConfig( response_modalities=["IMAGE", "TEXT"], ) ), timeout=timeout_seconds ) # Check for blockReason OTHER if hasattr(response, 'prompt_feedback') and response.prompt_feedback: if getattr(response.prompt_feedback, 'block_reason', None) == 'OTHER': print("Layer 2 block detected, falling back...") return await fallback_generate(prompt) # Check for empty candidates (SDK hang prevention) if not response.candidates or len(response.candidates) == 0: print("Empty candidates, falling back...") return await fallback_generate(prompt) return response except asyncio.TimeoutError: print(f"Timeout after {timeout_seconds}s, falling back...") return await fallback_generate(prompt) async def fallback_generate(prompt): """Fallback to alternative image model.""" # Example: Use GPT Image or FLUX.2 via alternative API # Implementation depends on your fallback model choice pass
Solution 5: Use GPT Image or FLUX.2 as Primary Fallback. When your content requirements inherently conflict with Google's Layer 2 policies—for example, if you need to generate images of recognizable public figures for news or editorial purposes—the only reliable solution is to use a different image generation model with different content policies. OpenAI's GPT Image (DALL-E 4o) has different policy boundaries and may accept prompts that Nano Banana 2 rejects, and vice versa. FLUX.2 models available through various providers offer yet another set of content policies. In production, maintaining access to 2-3 different image generation APIs ensures that policy differences between providers become your safety net rather than your bottleneck.
Production-Grade Error Handling
Moving from development debugging to production reliability requires comprehensive error handling that accounts for all the failure modes we have discussed. The following implementation provides a complete error handling wrapper for Nano Banana 2 that prevents the python-genai SDK hang bug, correctly differentiates between Layer 1 and Layer 2 blocks, implements automatic retry with fallback, and provides structured logging for monitoring.
pythonimport time import logging from dataclasses import dataclass from enum import Enum from typing import Optional logger = logging.getLogger(__name__) class BlockType(Enum): NONE = "none" LAYER_1_SAFETY = "layer_1_safety" LAYER_2_OTHER = "layer_2_other" LAYER_2_IMAGE_SAFETY = "layer_2_image_safety" LAYER_2_COPYRIGHT = "layer_2_copyright" LAYER_2_PROHIBITED = "layer_2_prohibited" SDK_HANG = "sdk_hang" UNKNOWN = "unknown" @dataclass class GenerationResult: success: bool block_type: BlockType image_data: Optional[bytes] = None error_message: str = "" latency_ms: int = 0 model_used: str = "" def safe_generate_image(client, prompt: str, model: str = "gemini-3.1-flash-image-preview") -> GenerationResult: """Production-safe image generation with comprehensive error handling.""" start_time = time.time() try: response = client.models.generate_content( model=model, contents=prompt, config=types.GenerateContentConfig( response_modalities=["IMAGE", "TEXT"], safety_settings=[ types.SafetySetting(category=cat, threshold="BLOCK_NONE") for cat in [ "HARM_CATEGORY_HARASSMENT", "HARM_CATEGORY_HATE_SPEECH", "HARM_CATEGORY_SEXUALLY_EXPLICIT", "HARM_CATEGORY_DANGEROUS_CONTENT", ] ], ), ) latency = int((time.time() - start_time) * 1000) # Check 1: Prompt-level blocking (blockReason) if hasattr(response, 'prompt_feedback') and response.prompt_feedback: block_reason = getattr(response.prompt_feedback, 'block_reason', None) if block_reason == 'SAFETY': logger.warning(f"Layer 1 block: {prompt[:80]}...") return GenerationResult( success=False, block_type=BlockType.LAYER_1_SAFETY, error_message="Layer 1 safety filter triggered. Adjust safety_settings.", latency_ms=latency, model_used=model, ) if block_reason == 'OTHER': logger.warning(f"Layer 2 block: {prompt[:80]}...") return GenerationResult( success=False, block_type=BlockType.LAYER_2_OTHER, error_message="Layer 2 policy block. Cannot bypass via settings.", latency_ms=latency, model_used=model, ) # Check 2: Empty candidates (prevents SDK hang) if not response.candidates or len(response.candidates) == 0: logger.warning(f"Empty candidates for: {prompt[:80]}...") return GenerationResult( success=False, block_type=BlockType.SDK_HANG, error_message="Empty candidates array. Likely silent Layer 2 block.", latency_ms=latency, model_used=model, ) # Check 3: Generation-level blocking (finishReason) candidate = response.candidates[0] finish_reason = getattr(candidate, 'finish_reason', 'STOP') finish_reason_map = { 'SAFETY': BlockType.LAYER_1_SAFETY, 'IMAGE_SAFETY': BlockType.LAYER_2_IMAGE_SAFETY, 'OTHER': BlockType.LAYER_2_COPYRIGHT, 'PROHIBITED_CONTENT': BlockType.LAYER_2_PROHIBITED, } if finish_reason in finish_reason_map: return GenerationResult( success=False, block_type=finish_reason_map[finish_reason], error_message=f"Generation blocked: finishReason={finish_reason}", latency_ms=latency, model_used=model, ) # Check 4: Extract image data for part in candidate.content.parts: if hasattr(part, 'inline_data') and part.inline_data: return GenerationResult( success=True, block_type=BlockType.NONE, image_data=part.inline_data.data, latency_ms=latency, model_used=model, ) # No image found in response return GenerationResult( success=False, block_type=BlockType.UNKNOWN, error_message="Response contained no image data.", latency_ms=latency, model_used=model, ) except Exception as e: latency = int((time.time() - start_time) * 1000) logger.error(f"Exception during generation: {e}") return GenerationResult( success=False, block_type=BlockType.UNKNOWN, error_message=str(e), latency_ms=latency, model_used=model, )
The key defensive programming patterns in this implementation deserve highlighting. First, every access to response.candidates is guarded by a length check, which prevents the python-genai SDK hang bug that has caught many developers off guard. Second, the function returns a structured result object rather than raising exceptions, which makes it safe to use in async pipelines and retry logic. Third, the block type classification enables your monitoring system to track exactly which types of blocks are occurring and at what frequency, giving you the data you need to optimize your prompts over time.
For production deployments, platforms like laozhang.ai provide unified API endpoints across multiple image generation models, which simplifies implementing the fallback strategy described in Solution 4. Instead of managing separate API clients for each fallback model, you can route through a single endpoint and let the platform handle model selection and error recovery.
The logging in this implementation is intentionally structured to support monitoring dashboards. By tracking block_type, latency_ms, and model_used for every request, you can build alerts for unusual spikes in Layer 2 blocks (which may indicate a policy change), track the effectiveness of prompt rephrasing efforts, and identify which prompts need to be routed to alternative models.
Frequently Asked Questions
Can I completely disable safety filters in Nano Banana 2?
You can disable Layer 1 safety filters by setting all four harm categories (HARM_CATEGORY_HARASSMENT, HARM_CATEGORY_HATE_SPEECH, HARM_CATEGORY_SEXUALLY_EXPLICIT, HARM_CATEGORY_DANGEROUS_CONTENT) to either BLOCK_NONE or OFF. However, Layer 2 policy enforcement cannot be disabled through any API parameter, SDK configuration, or account setting. This means that even with all configurable safety settings removed, content that violates Google's terms of service, copyright law, or child safety requirements will still be blocked. The distinction is that Layer 1 protects users from potentially harmful AI outputs, while Layer 2 protects Google from legal liability. Both are necessary, but only the first is configurable.
What is the difference between BLOCK_NONE and OFF?
Both settings prevent automatic blocking at Layer 1, but they differ in metadata behavior. BLOCK_NONE disables blocking while still returning safety ratings in the response, which tells you what categories were detected and at what confidence level. This is useful for monitoring and auditing. OFF disables both blocking and metadata collection entirely, meaning you get no safety information in the response at all. For models starting from gemini-2.5-flash (according to Vertex AI documentation as of January 2026), OFF is the default setting. The practical recommendation is to use BLOCK_NONE during development (so you can see what triggers safety ratings) and OFF in production if you do not need safety metadata (for marginally faster responses).
Why did my previously working prompts start getting blocked?
If prompts that worked in January or February 2026 are now returning blockReason OTHER, the most likely explanation is Google's March 2026 policy update. This update tightened enforcement on four specific categories: public figures and celebrities (broader detection of indirect references), financial information modification (previously lower priority), outfit and face swapping (more aggressive detection), and implicit suggestive content (expanded pattern recognition). If your prompts touch any of these areas, they may now trigger blocks that they did not trigger before. The fix is to audit and rephrase the affected prompts, specifically removing any indirect references to recognizable individuals or financial documents.
Does the free tier API support image generation with Nano Banana 2?
The free tier of Google AI Studio provides access to Gemini models for text generation, but image generation via the API requires a paid plan. While you can experiment with image generation in the Google AI Studio web interface on the free tier, programmatic API access for image generation with Nano Banana 2 (gemini-3.1-flash-image-preview) requires billing to be enabled on your Google Cloud project. This is separate from the blockReason OTHER issue, which can occur on both free and paid tiers—the distinction is that free tier users may not reach the point where blockReason OTHER appears because image generation requests are rejected at the quota level first.
How can I tell if blockReason OTHER is caused by regional restrictions?
EU-based developers may encounter blockReason OTHER more frequently due to IP-based policy enforcement that applies stricter content filters in certain jurisdictions. To determine if your block is region-based rather than content-based, test the exact same prompt from a different geographic region (using a VPN or a cloud function deployed in a different region). If the prompt succeeds from another region but fails from yours, the block is regional. In this case, deploying your API calls from a server in a region with less restrictive policies (such as US-based cloud infrastructure) is a legitimate workaround, as long as your use case complies with the applicable terms of service in that region.