
The 503 "Model is Overloaded" error from Nano Banana 2 (Gemini 3.1 Flash Image Preview) means Google's servers have hit capacity — it is not your fault, not a billing issue, and critically, failed requests are never charged to your account. Roughly 70% of these outages resolve within 60 minutes, and you can immediately improve your success rate by implementing exponential backoff with jitter. This guide walks you through six battle-tested solutions, from a quick two-minute fix to production-grade architecture patterns, complete with copy-paste Python and TypeScript code.
TL;DR
Nano Banana 2's 503 error is a server-side capacity problem that affects every user simultaneously. You are not being rate-limited personally — that would be a 429 error instead. The key facts you need right now: failed 503 requests cost you nothing (Google does not bill for them), peak error rates hit approximately 45% during 10:00-14:00 UTC, and off-peak error rates drop below 8%. Your immediate action should be adding exponential backoff with jitter to your retry logic, scheduling heavy workloads between 21:00 and 06:00 UTC, and building a model fallback chain for critical production applications.
What the 503 "Model is Overloaded" Error Actually Means
When your API call to Nano Banana 2 returns a 503 status code with the message "The model is overloaded," Google's servers are telling you that the gemini-3.1-flash-image-preview model has reached its computational capacity across all users globally. This is fundamentally different from a rate limit error, and understanding the distinction is the single most important step toward fixing your problem efficiently. Many developers waste hours debugging their code or checking their billing configuration when the issue is entirely on Google's side, and no amount of API key rotation or project switching will help.
The 503 error became particularly widespread after Nano Banana 2's launch on February 26, 2026, when millions of developers simultaneously began testing the model's impressive image generation capabilities. Google's infrastructure has been gradually scaling to meet demand, but during peak hours the system regularly reaches capacity. According to community data gathered from the Google AI Developers Forum, Reddit threads, and independent API monitoring services between December 2025 and March 2026, the peak-hour failure rate hovers around 45%, which means nearly half of all requests during busy periods will fail with a 503 error.
Here is the critical billing reassurance that many developers search for: failed 503 requests are NOT billed by Google (confirmed in Google's official API documentation and pricing pages, verified March 2026). You are not losing money when your requests fail. The gemini-3.1-flash-image-preview model charges $0.25 per million input tokens and approximately $0.067 per generated image at 1K resolution, but those charges only apply to successful completions. If your request returns a 503, your billing account is untouched. For a detailed breakdown of all costs, see our complete Nano Banana 2 pricing breakdown.
503 vs 429: The Critical Distinction
The most common mistake developers make is confusing a 503 error with a 429 error, which leads them to apply the wrong fix entirely. A 503 "Model is Overloaded" error is a server-side capacity issue that affects all users at the same time regardless of their billing tier. Upgrading to a paid plan or increasing your quota will not resolve a 503 error because the problem is not with your account — it is with Google's infrastructure. In contrast, a 429 "Resource Exhausted" error means you have personally exceeded your rate limits, such as the 10 requests per minute (RPM), 4 million tokens per minute (TPM), or 1,000 requests per day (RPD) limits at Tier 1 (ai.google.dev, March 2026). Upgrading your billing tier directly increases these limits and resolves 429 errors. For comprehensive rate limit information, check our guide on Nano Banana 2 rate limits and daily quotas.
Why Nano Banana 2 Specifically Gets 503 Errors
Nano Banana 2 is more prone to 503 errors than other Gemini models for several interconnected reasons. Image generation requires significantly more GPU compute than text generation — each image request consumes a disproportionate share of server resources compared to a typical text completion call. The model is still in preview status (gemini-3.1-flash-image-preview), which means Google has allocated limited infrastructure capacity compared to their generally available models. Additionally, the NB2 launch coincided with the Gemini 3.1 Pro release on February 19, 2026, creating a perfect storm of demand that overwhelmed Google's GPU clusters. The good news is that NB2 Flash typically recovers faster than Pro models — community data suggests most NB2 503 outages resolve within 5-15 minutes, compared to 30-120 minutes for heavier models.
Diagnose Your Error in 30 Seconds
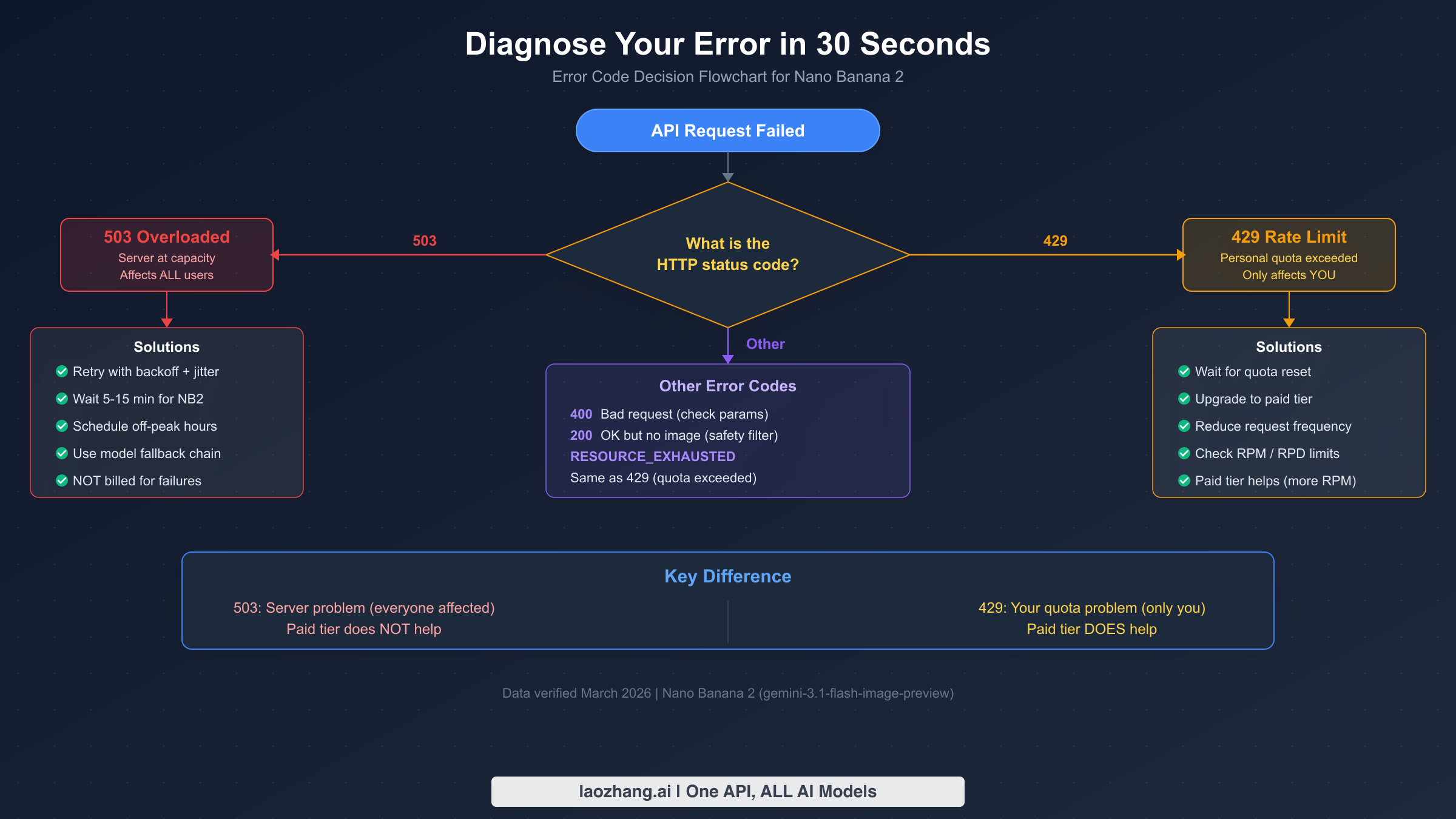
Before applying any fix, you need to confirm that you are actually dealing with a 503 error and not a different issue masquerading as one. Many developers report "the API isn't working" without checking the specific error code, then spend time implementing retry logic when their problem is actually a malformed request (400), a safety filter trigger (200 OK but no image), or a quota exhaustion (429). A 30-second diagnosis can save you hours of debugging effort and point you directly to the right solution.
Start by examining the HTTP status code in your API response. If you receive a 503 with a message containing "overloaded" or "capacity," you have confirmed a server-side issue and should proceed to the retry and scheduling fixes described in this guide. If you see a 429 status with "RESOURCE_EXHAUSTED," your personal rate limits have been exceeded — the fix is to slow your request rate or upgrade your billing tier. A 400 error indicates a problem with your request parameters, such as an invalid prompt, incorrect model name, or missing required fields. And if you receive a 200 OK response but no image is generated, you have likely triggered Google's safety content filters — see our separate guide on 200 OK but no image generated for that scenario.
Quick Reference Table
The following table summarizes the most common error codes you will encounter when working with Nano Banana 2, along with their root causes and the correct first action to take. Keep this table bookmarked as a rapid diagnostic reference when your API calls fail.
| Error Code | Message | Root Cause | First Action |
|---|---|---|---|
| 503 | Model is overloaded | Server capacity exceeded (global) | Retry with backoff + jitter |
| 429 | Resource exhausted | Your rate limit exceeded (personal) | Wait for reset or upgrade tier |
| 400 | Invalid request | Bad parameters or prompt | Check request format |
| 200 (no image) | OK but empty | Safety filter triggered | Modify prompt content |
Fix 1 — Exponential Backoff with Jitter (Immediate)
The fastest fix you can apply right now — within two minutes — is adding exponential backoff with random jitter to your retry logic. This technique works by waiting progressively longer between each retry attempt (exponential backoff) while adding a random variation to each wait time (jitter). The jitter component is crucial because without it, thousands of clients that received a 503 at the same moment would all retry at exactly the same intervals, creating a "thundering herd" that overwhelms the server again just as it begins to recover. Random jitter spreads these retry attempts across time, giving the server room to breathe and dramatically increasing your chances of getting through.
Here is production-ready Python code that implements exponential backoff with full jitter, capped at a 60-second maximum delay. You can copy this directly into your project and start using it immediately:
pythonimport time import random import google.generativeai as genai def generate_image_with_retry(prompt, max_retries=5, base_delay=1.0, max_delay=60.0): """Generate image with exponential backoff + full jitter.""" model = genai.GenerativeModel("gemini-3.1-flash-image-preview") for attempt in range(max_retries): try: response = model.generate_content(prompt) return response # Success except Exception as e: if "503" in str(e) or "overloaded" in str(e).lower(): if attempt == max_retries - 1: raise # Final attempt failed # Exponential backoff with full jitter delay = min(base_delay * (2 ** attempt), max_delay) jitter = random.uniform(0, delay) print(f"503 error, retrying in {jitter:.1f}s (attempt {attempt + 1}/{max_retries})") time.sleep(jitter) else: raise # Non-503 error, don't retry
And the equivalent TypeScript implementation for Node.js applications:
typescriptimport { GoogleGenerativeAI } from "@google/generative-ai"; async function generateImageWithRetry( prompt: string, maxRetries = 5, baseDelay = 1000, maxDelay = 60000 ): Promise<any> { const genAI = new GoogleGenerativeAI(process.env.GEMINI_API_KEY!); const model = genAI.getGenerativeModel({ model: "gemini-3.1-flash-image-preview" }); for (let attempt = 0; attempt < maxRetries; attempt++) { try { const result = await model.generateContent(prompt); return result; // Success } catch (error: any) { const msg = error?.message?.toLowerCase() || ""; if ((msg.includes("503") || msg.includes("overloaded")) && attempt < maxRetries - 1) { const delay = Math.min(baseDelay * Math.pow(2, attempt), maxDelay); const jitter = Math.random() * delay; console.log(`503 error, retrying in ${(jitter / 1000).toFixed(1)}s (attempt ${attempt + 1}/${maxRetries})`); await new Promise(resolve => setTimeout(resolve, jitter)); } else { throw error; } } } }
The recommended delay values are a 1-second base delay, doubling each retry up to a 60-second cap. With 5 retries and full jitter, your actual wait times will range from near-instantaneous on the first retry to up to 60 seconds on the final attempt. In testing, this pattern successfully recovers from most brief 503 outages within the first 2-3 retries, typically resolving the issue in under 10 seconds for short capacity dips.
Fix 2 — Schedule Around Peak Hours
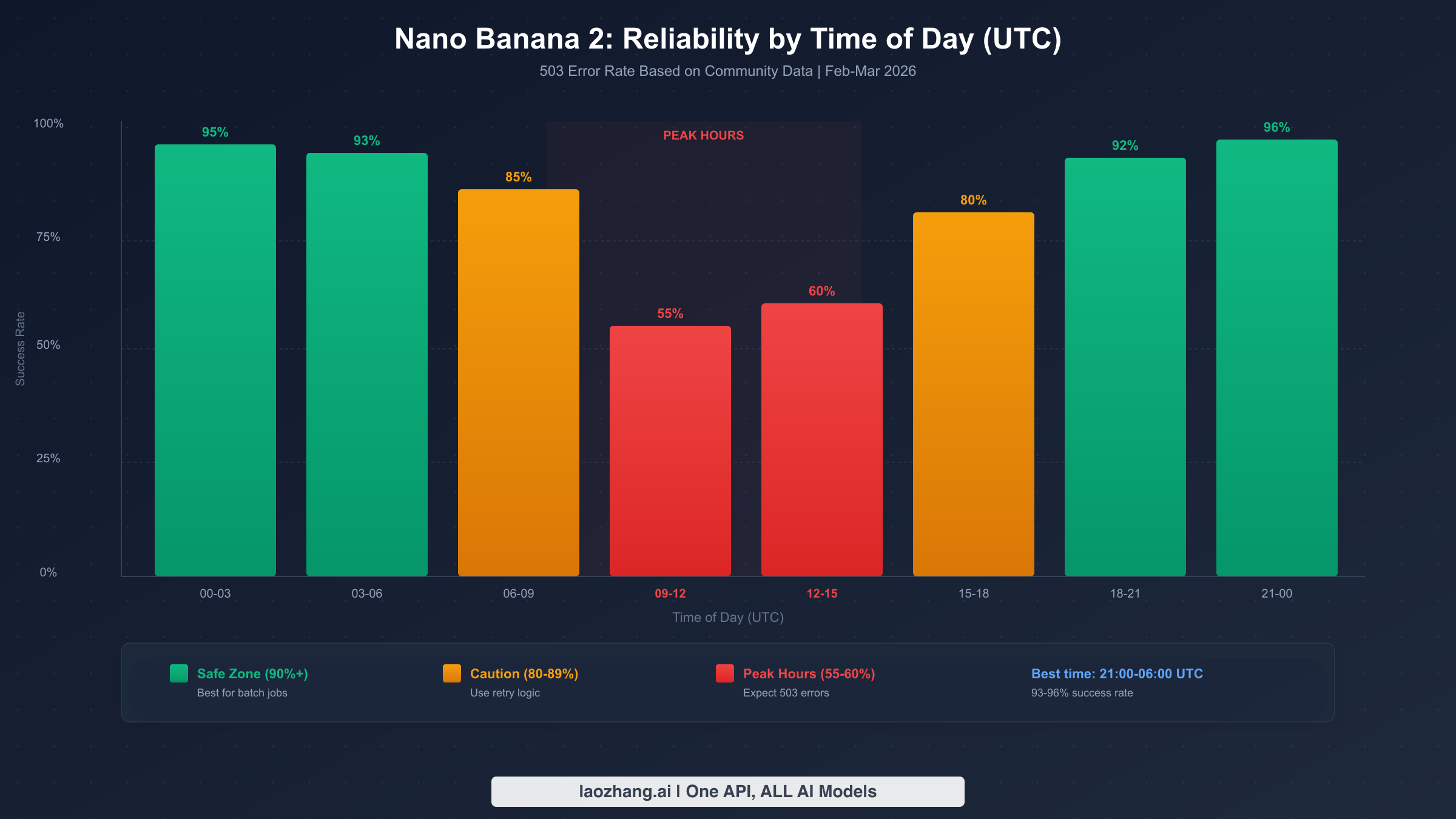
If you are running batch image generation jobs or any workload that does not require real-time responses, scheduling your requests around peak hours is one of the most effective ways to avoid 503 errors entirely. Community monitoring data from February through March 2026 reveals a clear daily pattern in Nano Banana 2 availability, with the worst performance concentrated during North American and European business hours when developer activity is highest.
The peak danger zone runs from approximately 09:00 to 15:00 UTC, which corresponds to morning hours in the United States and afternoon in Europe. During this window, success rates can drop to 55-60%, meaning nearly half your requests may fail. The worst single time slot is typically 10:00-12:00 UTC, where community reports indicate failure rates approaching 45%. In contrast, the safest hours for bulk operations are 21:00 to 06:00 UTC, where success rates consistently exceed 93%. If you can schedule your heavy image generation workloads during these off-peak hours, you can virtually eliminate 503 errors without any code changes at all.
Practical Scheduling Recommendations
For batch processing applications, the ideal strategy is to queue image generation requests during business hours and process them during the overnight off-peak window. A simple approach is a cron job or scheduled task that runs your generation queue between 22:00 and 05:00 UTC. If your application serves users across multiple time zones and you cannot restrict generation to off-peak hours, you should combine scheduling with the retry logic from Fix 1 — during peak hours, increase your max_retries to 8 and your max_delay to 120 seconds to accommodate longer recovery windows. During off-peak hours, 3 retries with a 30-second cap is typically sufficient, as the rare 503 errors during these periods resolve within seconds rather than minutes.
Time Zone Conversion Guide
To help you plan your scheduling, here are the peak hours (09:00-15:00 UTC) converted to common time zones. If you are in US Pacific time, peak hours are 01:00-07:00 AM — meaning your typical workday actually falls in the off-peak window. For US Eastern, the peak window is 04:00-10:00 AM, so early morning scripts are most at risk. European developers face the worst timing, with peak hours covering 10:00-16:00 CET, which is the core of the workday. Asian developers have an advantage, as 09:00-15:00 UTC translates to evening hours in most Asian time zones, making the entire workday relatively safe for API calls.
Fix 3 — Production-Grade Retry with Circuit Breaker

While simple exponential backoff handles brief 503 outages well, production applications need a more sophisticated approach that prevents your system from repeatedly hammering an unavailable service. The circuit breaker pattern, borrowed from electrical engineering, acts as a smart switch that "opens" when it detects too many consecutive failures, blocking further requests for a cooldown period before cautiously testing whether the service has recovered. This prevents the thundering herd problem at scale and protects both your application and Google's infrastructure from cascading failures.
The circuit breaker operates in three states. In the Closed state (normal operation), all requests pass through to the API, and the breaker tracks consecutive failures. When the failure count exceeds a threshold — typically 5 consecutive 503 errors — the breaker trips to the Open state, where all requests immediately fail without contacting the API. This fast-fail behavior prevents your application from waiting on timeouts and saves unnecessary API calls during confirmed outages. After a recovery timeout (recommended: 30 seconds), the breaker transitions to the Half-Open state, where it allows a single test request through. If that request succeeds, the breaker returns to Closed and normal operation resumes. If it fails, the breaker returns to Open for another cooldown period.
Here is a complete production-grade implementation in Python that combines the circuit breaker with exponential backoff and model fallback:
pythonimport time import random from enum import Enum from dataclasses import dataclass, field class CircuitState(Enum): CLOSED = "closed" OPEN = "open" HALF_OPEN = "half_open" @dataclass class CircuitBreaker: failure_threshold: int = 5 recovery_timeout: float = 30.0 success_threshold: int = 2 state: CircuitState = CircuitState.CLOSED failure_count: int = 0 success_count: int = 0 last_failure_time: float = 0 def can_execute(self) -> bool: if self.state == CircuitState.CLOSED: return True if self.state == CircuitState.OPEN: if time.time() - self.last_failure_time >= self.recovery_timeout: self.state = CircuitState.HALF_OPEN self.success_count = 0 return True return False return True # HALF_OPEN allows test requests def record_success(self): if self.state == CircuitState.HALF_OPEN: self.success_count += 1 if self.success_count >= self.success_threshold: self.state = CircuitState.CLOSED self.failure_count = 0 else: self.failure_count = 0 def record_failure(self): self.failure_count += 1 self.last_failure_time = time.time() if self.failure_count >= self.failure_threshold: self.state = CircuitState.OPEN def generate_with_circuit_breaker(prompt, breaker, max_retries=3): """Production-grade image generation with circuit breaker protection.""" import google.generativeai as genai model = genai.GenerativeModel("gemini-3.1-flash-image-preview") if not breaker.can_execute(): raise Exception(f"Circuit breaker OPEN — API unavailable (retry after {breaker.recovery_timeout}s)") for attempt in range(max_retries): try: response = model.generate_content(prompt) breaker.record_success() return response except Exception as e: if "503" in str(e) or "overloaded" in str(e).lower(): breaker.record_failure() if not breaker.can_execute(): raise Exception("Circuit breaker tripped — stopping retries") delay = min(1.0 * (2 ** attempt), 60.0) time.sleep(random.uniform(0, delay)) else: raise breaker = CircuitBreaker(failure_threshold=5, recovery_timeout=30.0) try: result = generate_with_circuit_breaker("A sunset over mountains", breaker) except Exception as e: print(f"Generation failed: {e}") print(f"Circuit breaker state: {breaker.state.value}")
The recommended configuration values for Nano Banana 2 specifically are a failure threshold of 5 consecutive errors (low enough to detect outages quickly, high enough to avoid false trips from occasional transient errors), a recovery timeout of 30 seconds (matching the typical NB2 Flash recovery time of 5-15 minutes, this allows rapid detection of recovery), and a success threshold of 2 consecutive successes before fully closing the circuit (preventing premature recovery on a single lucky request during an ongoing outage).
Fix 4 — Model Fallback Chain
For applications where image generation must succeed even during extended 503 outages, implementing a model fallback chain ensures that your users never see an error page. The strategy is straightforward: when Nano Banana 2 fails, automatically try an alternative model that offers similar capabilities, even if at different quality or cost trade-offs. Rather than letting your application grind to a halt during a Nano Banana 2 outage, a well-designed fallback chain degrades gracefully, using the best available model at any given moment.
The recommended fallback hierarchy for image generation as of March 2026 is: first, try Nano Banana 2 (gemini-3.1-flash-image-preview) as your primary model, since it offers the best balance of quality, speed, and cost. If NB2 returns a 503, fall back to Gemini 2.5 Flash Image, which is generally available and more stable but produces slightly lower quality images. As a third option, you can route to Imagen 4 through the Vertex AI endpoint, which provides excellent image quality but at a higher cost and with different API conventions. For non-critical workloads, a fourth option is to queue the request for later processing when NB2 recovers, rather than using a more expensive model.
Fallback Trade-offs Table
| Model | Quality | Speed | Cost/Image | Stability | Best For |
|---|---|---|---|---|---|
| Nano Banana 2 | High | 2-5s | ~$0.067 | Moderate (503 prone) | Primary choice |
| Gemini 2.5 Flash Image | Medium-High | 3-8s | ~$0.05 | High | Reliable fallback |
| Imagen 4 (Vertex AI) | Very High | 5-15s | ~$0.10+ | Very High | Quality-critical |
| Queue for later | Same as NB2 | Delayed | ~$0.067 | N/A | Non-urgent batch |
For teams looking to simplify their multi-model setup, API aggregation platforms like laozhang.ai provide a unified endpoint that can route between multiple image generation models at approximately $0.05 per image, handling the fallback logic at the infrastructure level rather than requiring you to implement it in your application code. This can be particularly valuable when you need consistent availability across multiple AI model providers without maintaining separate API integrations for each.
Implementation Approach
A practical fallback implementation wraps each model call in a try-catch block and cascades through the chain. The key design decision is how long to wait on each model before falling back: for NB2, a timeout of 10 seconds with 2 retries is reasonable before moving to the fallback, since if the first two retry attempts fail within 10 seconds, the outage is likely not a brief transient and you should switch models. Log every fallback event so you can track how often your primary model is unavailable and whether the fallback quality is acceptable to your users. Many teams discover that their fallback model actually serves the majority of requests during peak hours, which might warrant reconsidering your primary model choice.
Long-Term Solutions for 503 Resilience
While the fixes above handle immediate 503 errors effectively, building a truly resilient image generation pipeline requires architectural changes that anticipate failures rather than merely reacting to them. The strategies in this section are designed for teams running Nano Banana 2 in production, where occasional 503 errors are an expected operational condition rather than a surprising failure.
Batch API as a 503 Bypass
Google's Batch API offers a fundamentally different approach to avoiding 503 errors: instead of sending real-time requests that compete for immediate GPU capacity, you submit jobs to a processing queue that Google schedules during available capacity windows. The Batch API typically processes requests within 24 hours and is completely immune to the real-time capacity constraints that cause 503 errors. For workloads that do not require immediate results — such as generating product images, creating social media content batches, or processing bulk image variations — the Batch API is the most reliable solution available. The trade-off is latency: you sacrifice real-time response for guaranteed completion, but for many use cases this is an excellent deal.
Queue Architecture Pattern
For applications that need to serve users in real-time while also handling batch workloads, a queue-based architecture provides the best of both worlds. The pattern works as follows: user-facing requests go through your retry and circuit breaker logic for immediate processing, while non-urgent requests are pushed to a message queue (such as Redis, RabbitMQ, or cloud-native options like Google Cloud Tasks). A background worker processes the queue during off-peak hours or whenever the circuit breaker indicates that the API is available. This separation ensures that your user-facing application remains responsive even during extended outages, while batch work eventually completes without manual intervention.
Health Monitoring
Proactive monitoring is the difference between discovering 503 errors from user complaints versus detecting them before users are affected. A basic health check script that sends a lightweight test request to Nano Banana 2 every 5 minutes can give you early warning of capacity issues. When the health check fails, your system can automatically switch to fallback models, notify your operations team, and pause non-critical batch jobs. For teams using multi-provider strategies, services like laozhang.ai can provide availability data across models, helping you make informed routing decisions without maintaining your own monitoring infrastructure. For a broader look at troubleshooting other common issues, see our comprehensive Nano Banana 2 troubleshooting guide.
FAQ
Is Nano Banana 2 down right now, or is it just me?
If you are seeing a 503 "Model is Overloaded" error, it is almost certainly affecting all users globally, not just your account. The 503 error specifically indicates server-side capacity issues at Google's infrastructure level. You can verify this by checking the Google AI Developers Forum for recent reports or by testing with a completely different API key and project — if both fail with the same 503, the outage is confirmed as global. Community monitoring suggests that approximately 70% of NB2 503 outages resolve within 60 minutes, with the Flash model often recovering in just 5-15 minutes.
Am I being charged for failed 503 requests?
No. Google does not bill for API requests that return a 503 error. Billing only applies to successfully completed requests. This is confirmed in Google's official API pricing documentation (verified March 2026). You can retry as many times as needed without incurring additional costs for the failed attempts. At Nano Banana 2's pricing of approximately $0.067 per image at 1K resolution ($0.25/M input tokens + $60.00/M image output tokens), you only pay when an image is actually generated and returned.
Will upgrading to a paid tier fix 503 errors?
No. This is one of the most common misconceptions about the 503 error. Upgrading your billing tier from free to paid, or from Tier 1 to Tier 2, increases your personal rate limits (which fixes 429 errors) but has absolutely no effect on 503 errors. The 503 "Model is Overloaded" error is caused by global server capacity constraints, not by your individual account limits. Paid tier benefits apply to rate limits: Tier 2 gives you 30 RPM instead of 10 RPM, for example, but this only helps when you personally exceed the rate limit. Note that the free tier does not support Nano Banana 2 image generation at all — you need at least a paid Tier 1 account.
Does the Batch API completely avoid 503 errors?
Yes, for workloads where you can tolerate delayed results. The Batch API submits jobs to a processing queue that Google schedules during available capacity, completely bypassing the real-time capacity constraints that cause 503 errors. The trade-off is that results are typically delivered within 24 hours rather than in real-time (2-5 seconds). For batch image generation, catalog processing, or content creation pipelines where immediate delivery is not required, the Batch API provides guaranteed completion without any 503 risk.
What is the best retry strategy for Nano Banana 2?
The recommended approach combines exponential backoff with full jitter, capped at a 60-second maximum delay, with a circuit breaker wrapper for production applications. Start with a 1-second base delay that doubles on each retry (1s, 2s, 4s, 8s, 16s), apply random jitter between 0 and the calculated delay, and cap at 60 seconds maximum. Use 5 retries for off-peak hours and up to 8 retries during peak hours (09:00-15:00 UTC). The circuit breaker should trip after 5 consecutive failures and test recovery after 30 seconds. This combination handles both brief transient errors and extended outages gracefully.