
The Nano Banana 2 thought_signature error (400 INVALID_ARGUMENT) hits when your multi-turn API requests omit the thought_signature field that the model returned in its previous response. Nano Banana 2 (gemini-3.1-flash-image-preview) uses extended thinking that generates encrypted reasoning tokens, and every subsequent request in the same conversation must include these signatures unchanged. The fix is straightforward: extract the thoughtSignature field from each API response and pass it back in your next request's conversation history. If you are using the official Google Gen AI SDK's chat features, this is handled automatically — but if you are calling the REST API directly, using OpenAI-compatible endpoints, or working through platforms like Dify or n8n, you need to handle it manually.
What Is the Thought Signature Error and Why Does Nano Banana 2 Need It?
When you send a multi-turn request to Nano Banana 2 and the API responds with 400 INVALID_ARGUMENT: Unable to submit request because it has an invalid thought signature for content at index N, you are dealing with one of the most common — and most frustrating — errors in the Gemini 3 model family. This error does not mean your API key is wrong or your request is malformed in the traditional sense. It means the model's internal reasoning chain has been broken because a required piece of context is missing from your conversation history.
To understand why this happens, you need to know how Gemini 3 models handle "thinking." When Nano Banana 2 (model ID: gemini-3.1-flash-image-preview, Google AI documentation, March 2026) processes your request, it performs extended thinking — an internal reasoning step that helps the model plan its response before generating output. This thinking step produces an encrypted string called the thought_signature, which is essentially a compressed representation of the model's reasoning process. Think of it as a save state in a video game: the model needs this save state to continue the conversation coherently in the next turn. Without it, the model cannot verify that the conversation history it receives is consistent with what it actually generated, and it rejects the request with a 400 error.
The critical detail that trips up most developers is that this signature is generated even when you explicitly set thinkingConfig: { thinkingBudget: 0 } or set thinking to "off." The thinking process still runs under the hood, and the signature is still produced and required. Google's official documentation confirms that thinking tokens are always billed regardless of your thinking configuration (ai.google.dev/thought-signatures, March 2026). This catches many developers off guard — they assume turning off thinking means they can ignore the signature field, only to hit the 400 error on their second turn. If you have been struggling with this error while building conversational image editing workflows, you are not alone: GitHub issues across Dify (#2262), CherryStudio (#11391), n8n, OpenClaw (#5001), and Pipecat (#3557) all trace back to this same root cause. For a broader look at other NB2 errors beyond thought signatures, see our comprehensive Nano Banana 2 troubleshooting guide.
When Are Thought Signatures Required vs Optional?

Understanding when you must pass back thought signatures versus when you can safely ignore them is the key to preventing this error across your entire codebase. The rules differ between Gemini 3 and Gemini 2.5 models, and they differ again for Nano Banana 2's image generation use case. Getting this decision wrong means either unnecessary complexity in your code or unexpected 400 errors in production.
For Gemini 3 models (gemini-3-flash-preview, gemini-3-pro-preview), thought signatures are mandatory for all function calling scenarios. This means if your application uses tool use or function calls with Gemini 3, you must extract and return the thought signature in every subsequent turn — no exceptions. Sequential function calls are particularly tricky because each step in the sequence generates its own signature, and all of them must be included when you send the function results back. Parallel function calls have a different pattern: only the first functionCall part in the response carries a signature, so you only need to capture and return that one. For plain text multi-turn conversations without function calls, signatures are recommended but not enforced in Gemini 3 — meaning you will not get a 400 error if you omit them, but Google recommends including them for optimal response quality.
For Gemini 2.5 models, the rules are more relaxed. Thought signatures are optional across the board — function calls, text conversations, everything. The model will accept requests with or without signatures. However, if you are building code that needs to work across both Gemini 2.5 and Gemini 3 models, the safest approach is to always pass back whatever the model returns, including signatures.
Nano Banana 2 (gemini-3.1-flash-image-preview) falls into a special category because it is primarily used for multi-turn image generation and editing. When you generate an image and then ask the model to edit it in a follow-up turn, the thought signature is mandatory. This is the primary use case that brings most developers to this error, and it is less documented than the function calling scenario. The practical rule is simple: if you are building any multi-turn workflow with NB2 — whether it is generating an image and then refining it, having a conversation about visual content, or chaining image edits — you must handle thought signatures. For a detailed comparison of NB2 capabilities versus other models, see our Nano Banana Pro vs Nano Banana 2 comparison.
Fix the Error in Multi-Turn Image Generation
Multi-turn image editing is the primary use case for Nano Banana 2, and it is where most developers first encounter the thought signature error. The workflow is straightforward — generate an image, then ask the model to modify it — but the signature handling adds a critical step that is easy to miss. Here is the complete flow with signature extraction highlighted at every step.
Python implementation using the Google Gen AI SDK:
pythonimport google.generativeai as genai import base64 genai.configure(api_key="YOUR_API_KEY") model = genai.GenerativeModel("gemini-3.1-flash-image-preview") response = model.generate_content( "Generate a photo of a golden retriever playing in a park", generation_config=genai.GenerationConfig( response_modalities=["TEXT", "IMAGE"] ) ) # Step 2: Extract the thought signature and image from the response thought_signature = None image_data = None text_response = "" for part in response.candidates[0].content.parts: if hasattr(part, "thought_signature") and part.thought_signature: thought_signature = part.thought_signature if hasattr(part, "inline_data") and part.inline_data: image_data = part.inline_data if hasattr(part, "text") and part.text: text_response += part.text print(f"Signature captured: {thought_signature[:30]}...") # Step 3: Build the multi-turn history WITH the signature history = [ # Your original request {"role": "user", "parts": [{"text": "Generate a photo of a golden retriever playing in a park"}]}, # The model's response — MUST include thought_signature {"role": "model", "parts": []} ] # Reconstruct the model's response parts with the signature for part in response.candidates[0].content.parts: part_dict = {} if hasattr(part, "text"): part_dict["text"] = part.text if hasattr(part, "inline_data") and part.inline_data: part_dict["inline_data"] = { "mime_type": part.inline_data.mime_type, "data": part.inline_data.data } if hasattr(part, "thought_signature") and part.thought_signature: part_dict["thought_signature"] = part.thought_signature history[-1]["parts"].append(part_dict) # Step 4: Send the edit request with complete history edit_response = model.generate_content( contents=history + [ {"role": "user", "parts": [{"text": "Now add a red frisbee in the dog's mouth"}]} ], generation_config=genai.GenerationConfig( response_modalities=["TEXT", "IMAGE"] ) ) # Step 5: Extract the NEW signature for potential further edits new_signature = None for part in edit_response.candidates[0].content.parts: if hasattr(part, "thought_signature") and part.thought_signature: new_signature = part.thought_signature print(f"Edit successful! New signature: {new_signature[:30]}...")
The critical step is in Step 3: when you reconstruct the conversation history, the model's previous response must include the thought_signature field exactly as it was returned. If you strip it out, simplify the response to just text and image data, or forget to iterate through all parts, the next turn will fail with the 400 error. Every image generation response from NB2 will include a thought signature somewhere in its parts — your job is to preserve it faithfully.
TypeScript implementation:
typescriptimport { GoogleGenerativeAI } from "@google/generative-ai"; const genAI = new GoogleGenerativeAI("YOUR_API_KEY"); const model = genAI.getGenerativeModel({ model: "gemini-3.1-flash-image-preview" }); // The easiest approach: use the chat interface const chat = model.startChat({ generationConfig: { responseModalities: ["TEXT", "IMAGE"] } }); // Turn 1: Generate image (signature handled automatically by SDK) const result1 = await chat.sendMessage("Generate a photo of a sunset over mountains"); // Turn 2: Edit image (SDK passes signature automatically) const result2 = await chat.sendMessage("Add a silhouette of a person hiking"); // Turn 3: Refine further const result3 = await chat.sendMessage("Make the colors more vibrant and add lens flare");
The TypeScript example uses the SDK's chat interface, which handles signature management automatically. If you can use this approach, it eliminates the entire class of thought signature errors. The SDK internally tracks all signatures and includes them in subsequent requests without any manual intervention. This is by far the recommended approach for most applications. For pricing details on NB2 image generation, see our Nano Banana 2 API pricing breakdown.
Handle Streaming, Parallel Calls, and OpenAI Compatibility Mode
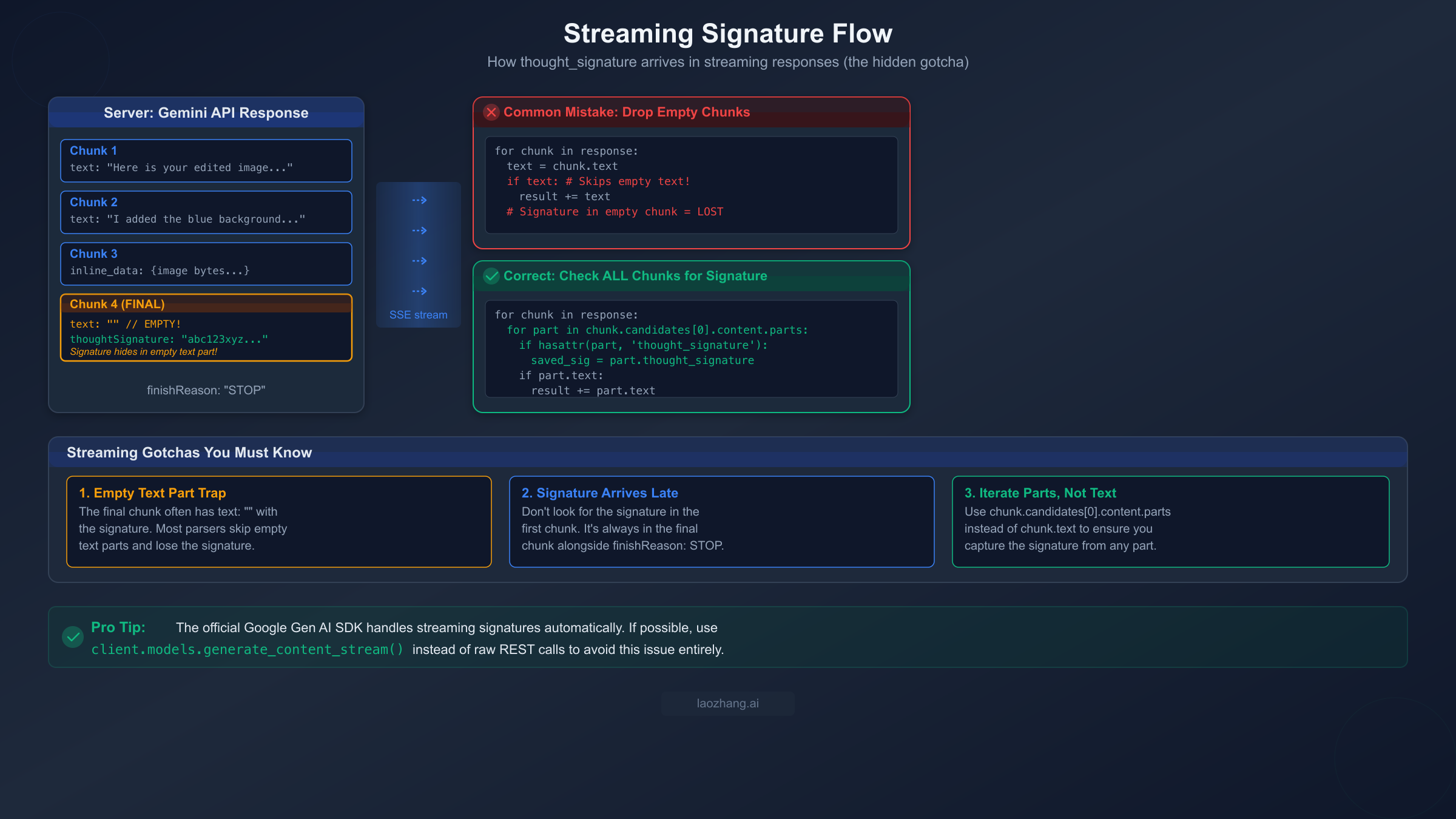
Streaming responses, parallel function calls, and OpenAI compatibility mode each introduce their own thought signature edge cases that can silently break your application. The streaming case is particularly insidious because it involves a subtle interaction between how stream parsers work and where the signature actually appears in the response stream.
Streaming: The Empty Text Part Trap
When you use streaming with NB2 or any Gemini 3 model, the thought signature does not arrive in the first chunk or even in a predictable middle chunk. It arrives in the final chunk of the stream, and here is the trap: the final chunk often contains a part with an empty text string (text: "") alongside the thought_signature field. Most streaming parsers check if chunk.text: to decide whether to process a chunk, and an empty string evaluates to false in most languages. This means your parser silently skips the one chunk that contains the signature, and your next turn fails with a 400 error.
The fix is to iterate through parts explicitly rather than relying on convenience properties:
python# WRONG: Loses signature in empty text chunks signature = None for chunk in response: if chunk.text: # Empty string = False = signature lost! result += chunk.text # CORRECT: Check all parts in every chunk signature = None full_text = "" for chunk in response: for part in chunk.candidates[0].content.parts: if hasattr(part, "thought_signature") and part.thought_signature: signature = part.thought_signature if hasattr(part, "text") and part.text: full_text += part.text
This pattern ensures you capture the signature regardless of which chunk it appears in and regardless of whether the accompanying text part is empty. The performance impact is negligible — you are simply iterating through parts you would already be processing — but the reliability improvement is significant.
Parallel Function Calls
When Gemini 3 returns multiple function calls in a single response (parallel function calling), only the first functionCall part carries a thought signature. The subsequent function call parts in the same response do not have their own signatures. When you return the function results, you need to include the signature from that first function call part in your response. This is documented in Google's official docs but easy to miss when you are focused on handling the function calls themselves. If you are processing function calls in a loop and extracting signatures from each one, you will find that only the first has a value — and that single signature is what you pass back.
OpenAI Compatibility Mode
If you are accessing Gemini models through an OpenAI-compatible endpoint (common when migrating from OpenAI or using gateway services), the thought signature lives in a completely different location in the response. Instead of thought_signature at the part level, it is nested under extra_content.google.thought_signature in the message object. This catches many developers who are migrating their OpenAI code to work with Gemini — they implement signature handling based on the native Gemini API documentation, but the OpenAI compatibility layer structures the response differently. The fix is to check for the alternative field path when using compatibility mode:
python# Native Gemini API signature = part.thought_signature # OpenAI Compatibility Mode signature = message.get("extra_content", {}).get("google", {}).get("thought_signature")
Both paths need to be handled if your application supports multiple API modes. For production applications that need to work with both native and compatible endpoints, we recommend abstracting the signature extraction into a helper function that checks both locations.
Advanced Workarounds — Dummy Signatures and Model Migration
There is a workaround hidden in Google's official documentation that no other article has surfaced prominently: dummy thought signatures. When you have conversation history that was not generated by Gemini 3 — for example, if you are migrating from another model, injecting synthetic conversation context, or reconstructing history from a database that did not store signatures — you can use a special placeholder string instead of a real signature.
Google provides two official dummy signature strings that bypass the signature validator (ai.google.dev/thought-signatures FAQ, March 2026):
python# Option 1: The recommended dummy signature dummy_signature = "context_engineering_is_the_way_to_go" # Option 2: Alternative dummy signature dummy_signature = "skip_thought_signature_validator"
When you include either of these strings as the thought_signature value in a model turn within your conversation history, the API will accept it without validation. This is incredibly useful for several scenarios: migrating existing conversation histories from GPT-4 or Claude to Gemini 3, restoring conversations from databases that were not designed to store thought signatures, injecting system-level context turns that never went through the model, and testing multi-turn workflows without needing real signatures.
However, there are important caveats to understand before relying on dummy signatures in production. The dummy signature tells the model that the associated turn's thinking context is unavailable, which means the model cannot verify the coherence of that turn's reasoning. For function calling workflows in Gemini 3, this may result in slightly degraded response quality because the model cannot reference its original reasoning chain. For NB2 image editing specifically, using a dummy signature on the image generation turn means the model may not perfectly "remember" the creative decisions it made, which could affect the quality of subsequent edits. The dummy signature approach works best as a migration tool or fallback, not as a permanent replacement for proper signature management.
The practical decision tree is clear: if you can extract and store real signatures, always do so. If you have legacy history without signatures, use dummy signatures to unblock your migration rather than rebuilding all conversation history from scratch. And if you are prototyping or testing, dummy signatures let you focus on the business logic without worrying about signature plumbing.
Platform-Specific Fixes for Dify, CherryStudio, n8n, and More
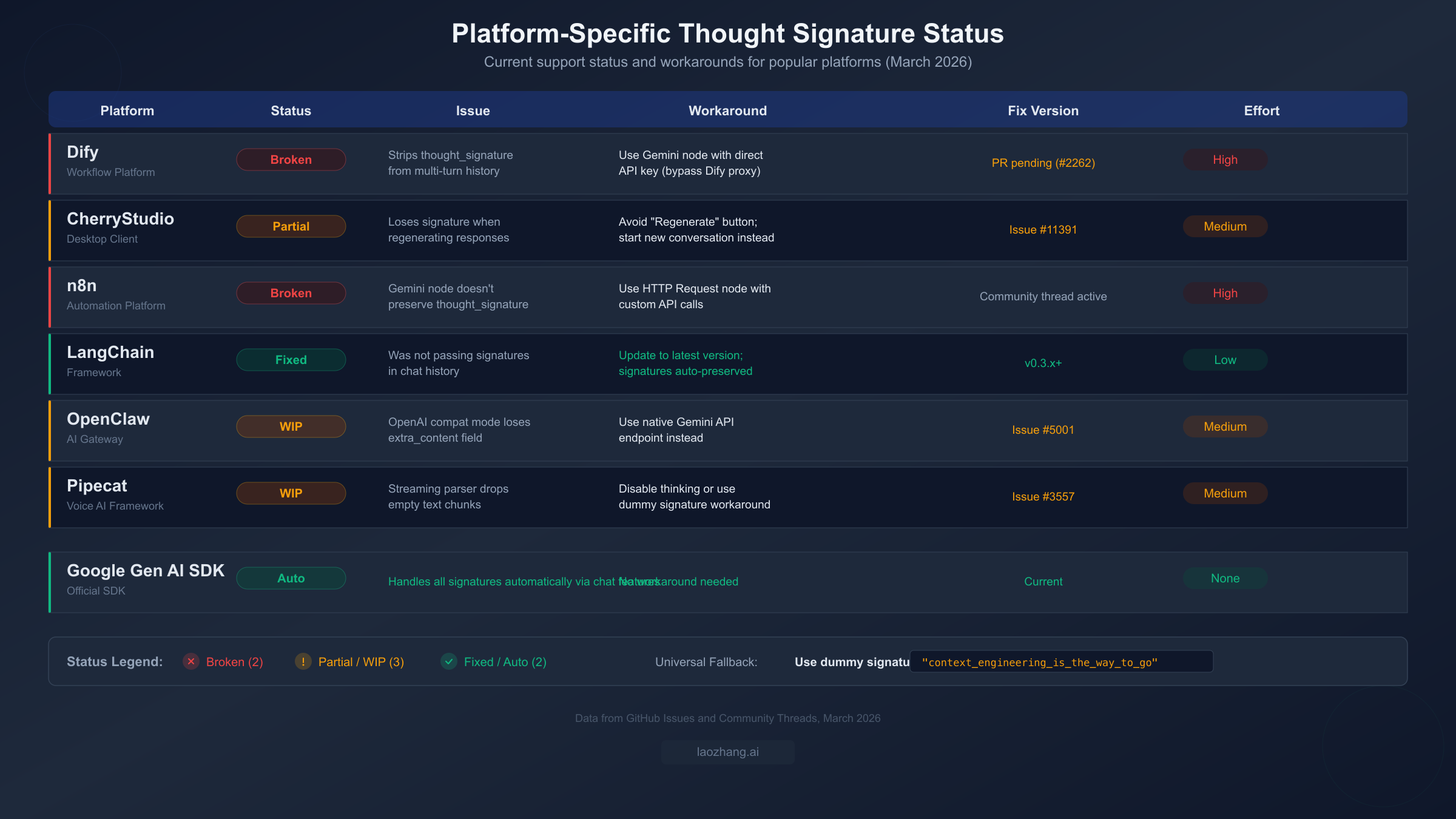
The thought signature error is not just a raw API problem — it is also a widespread issue across AI development platforms and tools. When you use Gemini 3 models through Dify, CherryStudio, n8n, or similar platforms, the platform's internal message handling often strips or loses the thought signature during conversation turn management. This means you can have perfectly correct API credentials and model configuration, yet still hit the 400 error because the platform is silently dropping a field it does not know about.
Dify is currently the most affected platform. Dify's message history management strips non-standard fields from model responses before storing them, and thought_signature is treated as a non-standard field. This means multi-turn conversations with Gemini 3 models consistently fail after the first turn. The issue is tracked in GitHub issue #2262, and a pull request to fix it is pending review. In the meantime, the workaround is to bypass Dify's built-in Gemini integration and use the HTTP Request node to call the Gemini API directly with your own conversation history management. This requires more setup but gives you full control over the request and response payload.
CherryStudio has a more subtle problem. The desktop client does preserve thought signatures during normal conversation flow, but it loses them when you use the "Regenerate" button. When CherryStudio regenerates a response, it reconstructs the conversation history without the original signature from the turn being regenerated, triggering the 400 error. The workaround is straightforward: avoid using Regenerate and instead start a new conversation or rephrase your message as a new turn. This issue is tracked in GitHub issue #11391.
n8n faces the same fundamental issue as Dify — its Gemini node does not preserve the thought signature field in the conversation state between workflow executions. For n8n users, the recommended approach is to use the HTTP Request node instead of the Gemini-specific node, giving you direct control over the API payload. You can store the full response (including signatures) in n8n's workflow data and reconstruct the conversation history manually in subsequent turns.
LangChain has already fixed this issue in version 0.3.x and later. If you are using an older version, updating to the latest release resolves the thought signature handling automatically. LangChain's ChatGoogleGenerativeAI class now preserves all response metadata including thought signatures when building conversation history.
OpenClaw and other API gateway services that offer OpenAI-compatible endpoints for Gemini models have a different problem: they may not forward the extra_content.google.thought_signature field from the OpenAI compatibility response. The workaround is to use the native Gemini API endpoint through the gateway instead of the OpenAI-compatible endpoint, or to configure the gateway to preserve all response fields.
For all platforms, the universal fallback is the dummy signature workaround described in the previous section. If a platform strips your real signature, you can inject "context_engineering_is_the_way_to_go" as the signature value in your conversation history to keep the conversation flowing, though with the quality caveats mentioned earlier.
Production-Ready Thought Signature Handler
For production applications that need robust thought signature handling across all scenarios — image editing, function calls, streaming, and multiple API modes — here is a reusable handler class that encapsulates all the edge cases covered in this guide.
pythonclass ThoughtSignatureHandler: """Manages thought signatures across multi-turn Gemini conversations.""" DUMMY_SIGNATURES = [ "context_engineering_is_the_way_to_go", "skip_thought_signature_validator" ] def __init__(self): self.signatures = {} # turn_index -> signature def extract_from_response(self, response, turn_index: int) -> str | None: """Extract thought signature from a Gemini API response.""" sig = None if hasattr(response, "candidates") and response.candidates: for part in response.candidates[0].content.parts: if hasattr(part, "thought_signature") and part.thought_signature: sig = part.thought_signature break if sig: self.signatures[turn_index] = sig return sig def extract_from_stream(self, stream, turn_index: int): """Extract signature from streaming response, yielding chunks.""" sig = None for chunk in stream: if hasattr(chunk, "candidates") and chunk.candidates: for part in chunk.candidates[0].content.parts: if hasattr(part, "thought_signature") and part.thought_signature: sig = part.thought_signature yield chunk if sig: self.signatures[turn_index] = sig def extract_from_openai_compat(self, message: dict, turn_index: int) -> str | None: """Extract signature from OpenAI-compatible response format.""" sig = (message.get("extra_content", {}) .get("google", {}) .get("thought_signature")) if sig: self.signatures[turn_index] = sig return sig def get_signature(self, turn_index: int, fallback_dummy: bool = False) -> str | None: """Get stored signature for a turn, with optional dummy fallback.""" sig = self.signatures.get(turn_index) if sig is None and fallback_dummy: return self.DUMMY_SIGNATURES[0] return sig def build_history_part(self, part_data: dict, turn_index: int) -> dict: """Ensure a model response part includes its thought signature.""" sig = self.signatures.get(turn_index) if sig and "thought_signature" not in part_data: part_data["thought_signature"] = sig return part_data
This handler covers the three main extraction scenarios (standard response, streaming, and OpenAI compatibility), stores signatures by turn index, and provides a fallback to dummy signatures when real ones are unavailable. The extract_from_stream method is a generator that yields chunks transparently while capturing the signature from whichever chunk contains it — you can drop it into existing streaming code without changing your processing logic.
For TypeScript applications, the equivalent pattern is even simpler because you can use the SDK's chat interface, which handles everything automatically. If you must use raw REST calls in TypeScript, apply the same extraction logic using optional chaining:
typescriptconst extractSignature = (response: any): string | undefined => { return response?.candidates?.[0]?.content?.parts ?.find((p: any) => p.thoughtSignature)?.thoughtSignature; };
When building production systems, consider also implementing rate limit handling alongside signature management, since NB2 has strict rate limits that can compound with signature errors to create confusing failure modes. See our complete Nano Banana 2 rate limits guide for details. For teams that need higher throughput or relaxed rate limits for NB2 image generation, services like laozhang.ai offer alternative API access at competitive pricing ($0.05/image versus the standard ~$0.067/image at 1K tokens).
FAQ — Common Thought Signature Questions
Does Nano Banana 2 always return a thought_signature in its response?
Yes. Every response from NB2 and other Gemini 3 models includes a thought signature, even when thinking is set to "off" or thinkingBudget is 0. The thinking process always runs internally, and the signature is always generated. You cannot opt out of signature generation — you can only choose whether to pass it back (which you should always do).
What happens if I use the wrong signature or a signature from a different conversation?
The API will reject the request with the same 400 INVALID_ARGUMENT error. Signatures are cryptographically tied to the specific conversation turn that generated them. You cannot swap signatures between conversations or between turns within the same conversation. Each turn's signature must be used exactly once, in exactly the position where it was generated.
Does the official Google Gen AI SDK handle thought signatures automatically?
Yes, when you use the SDK's chat interface (model.startChat() in TypeScript or model.start_chat() in Python). The SDK internally manages the entire conversation history including thought signatures. If you use model.generate_content() directly with manually constructed conversation history, you are responsible for signature management yourself.
Can I store thought signatures in a database for later use?
Yes, and you should if your application needs to resume conversations across sessions. Store the complete model response including the thought signature for each turn. When resuming, reconstruct the conversation history with all stored signatures. If you have turns where signatures were not stored (legacy data), use the dummy signature "context_engineering_is_the_way_to_go" as a placeholder.
Is the thought_signature field billed? Does it count toward my token usage?
The thinking tokens that generate the signature are always billed, regardless of your thinkingBudget setting (ai.google.dev, March 2026). However, the signature string itself is a compact encrypted representation and does not significantly increase request size when passed back. The billing impact is in the initial thinking computation, not in transmitting the signature.
Why does the error say "invalid thought signature" instead of "missing thought signature"?
The error message Unable to submit request because it has an invalid thought signature for content at index N covers both cases: missing signatures (where the field is absent entirely) and corrupted signatures (where the field exists but contains incorrect data). The "at index N" tells you which turn in your conversation history is problematic — check the model response at that index to ensure it includes the original thought signature.