GPT-5.4 and Gemini 3.1 Pro represent March 2026's fiercest AI rivalry. Released just two weeks apart — Gemini 3.1 Pro on February 19 and GPT-5.4 on March 5 — they split benchmarks almost evenly. Gemini leads in abstract reasoning (94.3% GPQA Diamond vs 92.8%) and costs up to 15x less than GPT-5.4 Pro. GPT-5.4 is the first AI to surpass human performance on desktop computer use (75% OSWorld). Neither model wins outright — the right choice depends on your use case and budget.
TL;DR
- GPT-5.4 wins on computer use automation (75% OSWorld, exceeds human baseline), professional knowledge work (83% GDPval), and terminal tasks (75.1% Terminal-Bench 2.0)
- Gemini 3.1 Pro wins on abstract reasoning (94.3% GPQA Diamond, 77.1% ARC-AGI-2), web research (85.9% BrowseComp), and coding (80.6% SWE-Bench Verified)
- Pricing gap is smaller than headlines suggest: Standard tiers differ by only ~20%. The 15x gap only applies when comparing GPT-5.4 Pro ($30/M) vs Gemini 3.1 Pro Standard ($2/M)
- Gemini 3.1 Pro is still in Preview (released Feb 19, GA expected Q2 2026) — factor this into production planning
- Latency warning: Gemini 3.1 Pro has a 44.5-second Time to First Token — real-time chat is not its strength
Quick Overview: What Are GPT-5.4 and Gemini 3.1 Pro?
Before diving into benchmarks and pricing, it is worth clarifying something that confuses many developers: GPT-5.4 is not one model — it is two products at very different price points, and conflating them leads to wildly inaccurate cost estimates that can derail architecture decisions.
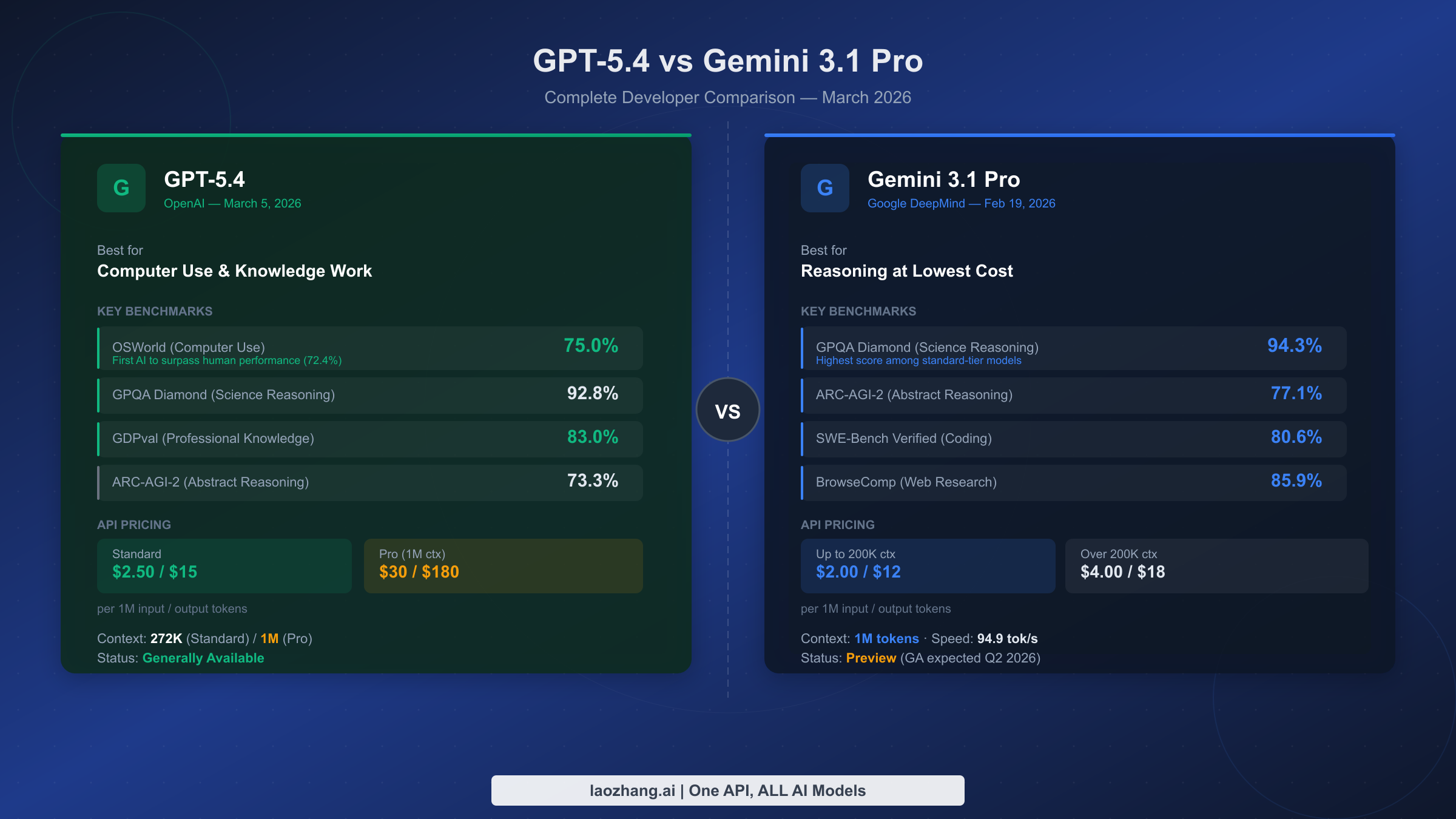
GPT-5.4 Standard is OpenAI's generally available flagship released on March 5, 2026. It comes with a 272K token context window and is priced at $2.50 per million input tokens and $15 per million output tokens. This is the tier you access via the standard API, and it is immediately available for production use with full SLA support and enterprise contracts. GPT-5.4 Pro is a separate, more expensive offering with a 1M token context window, priced at $30 per million input tokens and $180 per million output tokens — a 12x premium over Standard on inputs, and 12x on outputs. The Pro tier exists for workloads that genuinely need the expanded context window, not as a general upgrade. If you have seen headlines claiming "Gemini is 15x cheaper than GPT-5.4," those comparisons are almost always using GPT-5.4 Pro pricing. Against GPT-5.4 Standard, Gemini 3.1 Pro is only about 20% cheaper.
Gemini 3.1 Pro was released by Google DeepMind on February 19, 2026, and is currently in Preview status. It offers a 1M token context window natively at the standard tier — no premium required. Pricing is tiered by context length: $2 per million input tokens and $12 per million output tokens for requests under 200K tokens; $4 per million input tokens and $18 per million output tokens for requests exceeding 200K tokens. Preview status means the model is available for testing and development, but it does not yet carry the same GA stability guarantees that OpenAI's Generally Available GPT-5.4 does. Google has indicated GA is expected sometime in Q2 2026.
| Spec | GPT-5.4 Standard | GPT-5.4 Pro | Gemini 3.1 Pro |
|---|---|---|---|
| Released | March 5, 2026 | March 5, 2026 | Feb 19, 2026 |
| Status | Generally Available | Generally Available | Preview |
| Context window | 272K tokens | 1M tokens | 1M tokens |
| Input pricing | $2.50/M | $30/M | $2/M (≤200K) / $4/M (>200K) |
| Output pricing | $15/M | $180/M | $12/M (≤200K) / $18/M (>200K) |
| Provider | OpenAI | OpenAI | Google DeepMind |
Understanding this tier structure is the single most important context for everything that follows. When the comparison data below shows a 20% cost difference, it is Standard vs Standard. When it shows a 15x difference, it is GPT-5.4 Pro vs Gemini 3.1 Pro Standard — a comparison that is only relevant if you actually need the 1M context window and are choosing between paying OpenAI's premium versus using Google's native offering.
Benchmark Showdown: The Full Score Card
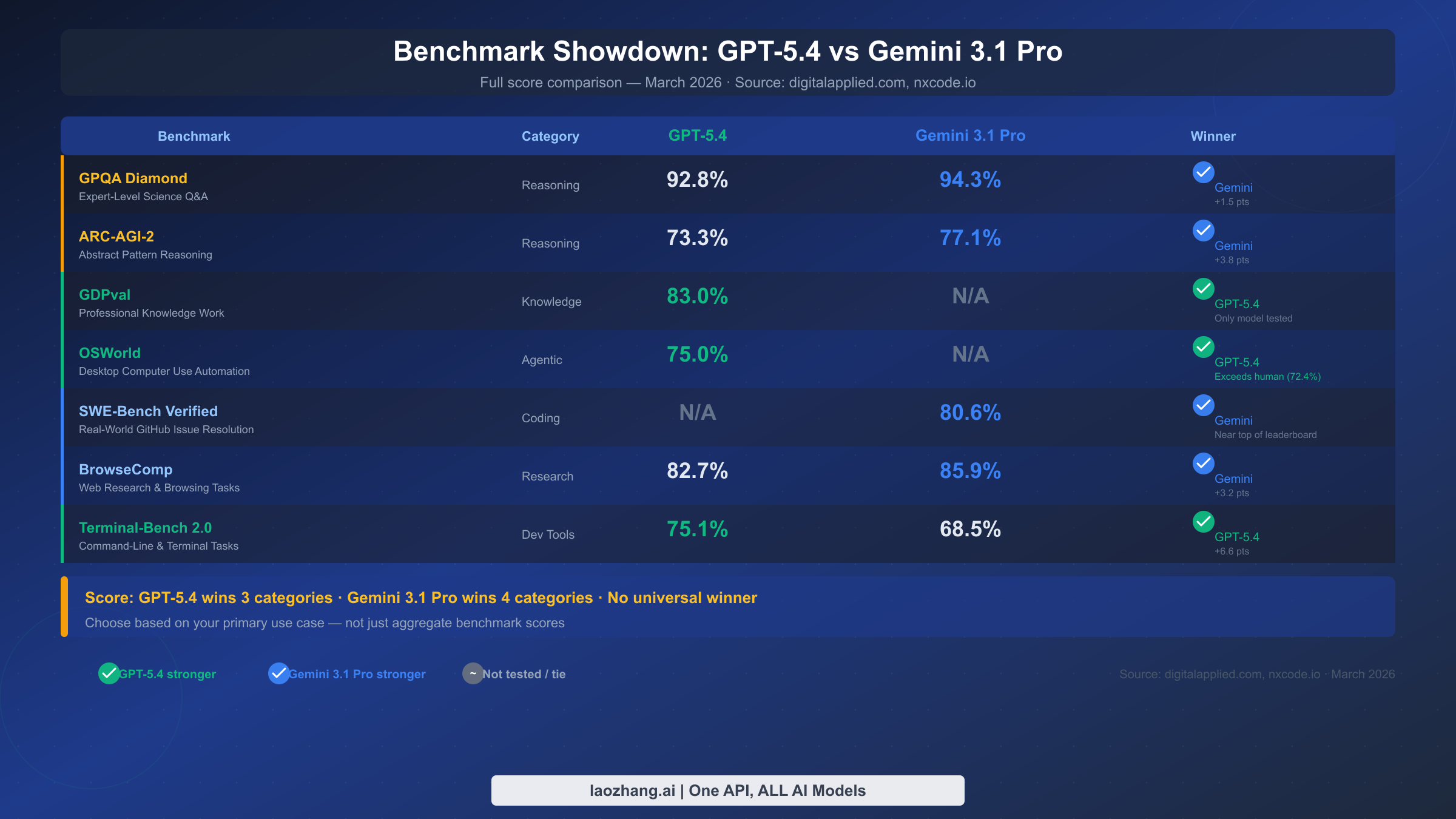
The headline result is that these two models genuinely split the benchmark categories, with neither achieving a clear overall dominance. GPT-5.4 takes three categories — GDPval (professional knowledge work), OSWorld (computer use automation), and Terminal-Bench 2.0 (command-line tasks). Gemini 3.1 Pro takes four — GPQA Diamond (expert science reasoning), ARC-AGI-2 (abstract pattern reasoning), SWE-Bench Verified (real-world coding), and BrowseComp (web research tasks). The split is almost perfectly even, which is why choosing between them requires understanding your actual workload rather than looking for a simple "best" label.
For a broader context on how these models compare against the full competitive landscape including Claude and other providers, see this broader API comparison across all major providers.
| Benchmark | Category | GPT-5.4 | Gemini 3.1 Pro | Winner |
|---|---|---|---|---|
| GPQA Diamond | Expert Science Reasoning | 92.8% | 94.3% | Gemini (+1.5 pts) |
| ARC-AGI-2 | Abstract Pattern Reasoning | 73.3% | 77.1% | Gemini (+3.8 pts) |
| GDPval | Professional Knowledge Work | 83.0% | N/A | GPT-5.4 (only model tested) |
| OSWorld | Desktop Computer Use | 75.0% | N/A | GPT-5.4 (exceeds human 72.4%) |
| SWE-Bench Verified | GitHub Issue Resolution | N/A | 80.6% | Gemini |
| BrowseComp | Web Research | 82.7% | 85.9% | Gemini (+3.2 pts) |
| Terminal-Bench 2.0 | CLI & Terminal Tasks | 75.1% | 68.5% | GPT-5.4 (+6.6 pts) |
Source: digitalapplied.com, nxcode.io — March 2026
The most striking individual result is GPT-5.4's OSWorld score. At 75%, GPT-5.4 is the first AI model in history to exceed human-level performance on desktop computer use, where the human baseline sits at 72.4%. This is not a marginal improvement — it represents a qualitative shift in what the model can do autonomously on a real desktop environment, controlling browsers, spreadsheets, and applications without browser plugins or special integrations. For teams building automation workflows, RPA replacements, or any agent that needs to interact with software interfaces, this single benchmark may be the deciding factor regardless of how the other scores compare.
Gemini 3.1 Pro's 94.3% on GPQA Diamond deserves equal attention. GPQA tests expert-level reasoning across biology, chemistry, and physics at a depth that requires genuine specialist knowledge to answer correctly. Hitting 94.3% puts Gemini 3.1 Pro at the top of standard-tier models on this benchmark — and the 1.5-point gap over GPT-5.4 is meaningful at this level of difficulty. For applications in research, scientific analysis, medical information systems, or any domain where the questions themselves require deep subject-matter expertise to evaluate, Gemini 3.1 Pro's edge here is substantive.
Reasoning and Knowledge Work
The reasoning category is where the two models diverge most sharply in character, even though they appear close in raw scores. GPT-5.4 excels at applied professional reasoning — the kind of structured analysis that appears in legal documents, financial models, and business intelligence workflows. Its 83% GDPval score measures performance on tasks drawn from real professional knowledge work, and it is currently the only frontier model tested on this benchmark, making it the default choice for enterprise applications where the questions are framed in professional rather than academic terms. Gemini 3.1 Pro, by contrast, dominates at the more abstract and academic end of reasoning, which includes the multi-step hypothesis formation and scientific deduction that GPQA Diamond and ARC-AGI-2 measure.
Gemini 3.1 Pro also features a dedicated thinking mode that allows the model to allocate additional compute to complex reasoning chains before generating a response. Gemini's thinking mode capabilities can significantly boost performance on hard mathematical and logical problems that benefit from extended deliberation, though this comes with additional latency overhead on top of the model's already high base TTFT. For workloads where answer quality is more important than response speed — long-form analysis, research synthesis, complex planning tasks — the thinking mode makes Gemini 3.1 Pro considerably more capable than the standard benchmark numbers suggest.
The practical implication for most development teams is this: if your application asks questions that look like professional business analysis — "summarize this contract's risk clauses," "build a financial model from these quarterly figures," "identify regulatory issues in this policy document" — GPT-5.4's GDPval advantage makes it the safer choice even without a direct Gemini comparison on that benchmark. If your application asks questions that look more like research or scientific reasoning — "evaluate this experimental design," "identify the flaw in this argument," "synthesize findings across these research papers" — Gemini 3.1 Pro's GPQA and ARC-AGI-2 advantage makes it more compelling. The distinction is between professional knowledge that is conventionally organized (GPT-5.4's strength) and abstract reasoning that requires scientific rigor (Gemini 3.1 Pro's strength).
Speed and Latency: The Hidden Dealbreaker
Latency data is consistently underreported in model comparison articles, yet it is often the most operationally significant factor for production applications. The benchmark headline numbers tell you what a model can do; latency tells you whether your users will wait long enough to find out.
GPT-5.4's latency profile has not been comprehensively published as of this writing, but its predecessor architecture suggests responsiveness broadly comparable to current frontier models. Gemini 3.1 Pro's latency, however, has been independently measured and the numbers are striking: a Time to First Token (TTFT) of approximately 44.5 seconds has been reported by artificialanalysis.ai, an independent benchmarking source. This is an extraordinarily high TTFT for a production API — most well-optimized frontier models deliver first tokens in 1 to 5 seconds, and user experience research consistently shows that response delays beyond 3 to 5 seconds significantly increase abandonment rates in interactive applications.
What 44.5 seconds TTFT means for your architecture:
The 44.5-second figure does not mean every Gemini 3.1 Pro request takes 44 seconds. TTFT is the delay before the first token arrives — after that, the model outputs at roughly 94.9 tokens per second, which is competitive. The practical consequence is that any application expecting a fast initial response — a chat interface, a real-time assistant, a copilot tool where users type a question and wait for the cursor to appear — will deliver a poor user experience with Gemini 3.1 Pro in its current Preview form. However, workloads where the TTFT is less visible to end users are largely unaffected. Batch processing pipelines, asynchronous document analysis, nightly data enrichment jobs, and any workflow where requests are queued and results are retrieved later can use Gemini 3.1 Pro without the latency being a practical concern.
The architectural split is therefore clear: use Gemini 3.1 Pro for batch and asynchronous workloads where latency is invisible or acceptable, and use GPT-5.4 (or wait for Gemini 3.1 Pro's GA release, which may address the latency profile) for interactive, real-time, or user-facing applications. Teams building both types of workloads may find that routing different request types to different models is the optimal approach — which brings us directly to the cost question.
Real Cost Calculator: What You'll Actually Pay
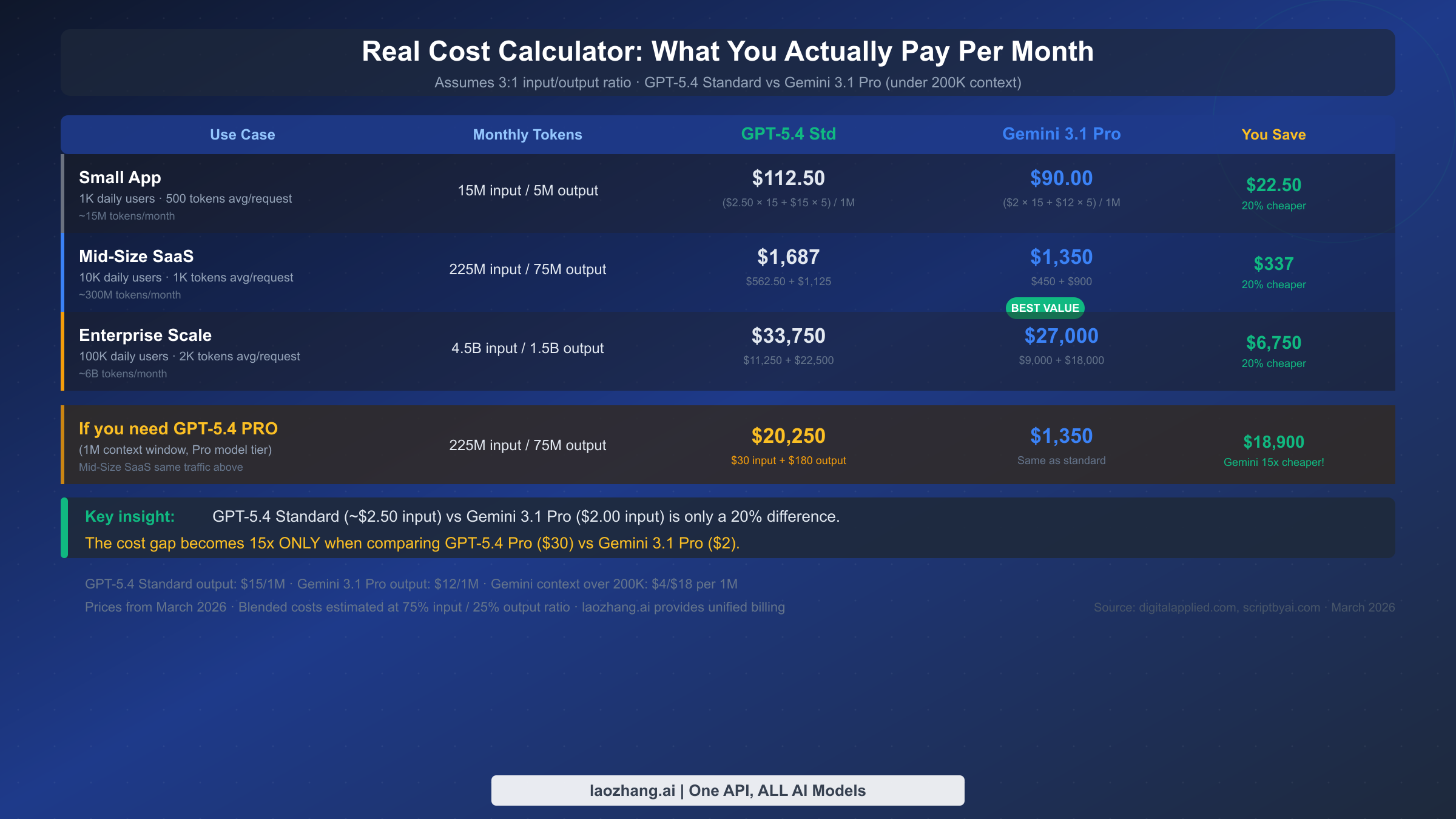
Token pricing per million is a useful reference point, but it rarely maps intuitively to actual monthly invoices. The following calculations use a 3:1 input-to-output ratio, which is typical for most production API workloads. For detailed Gemini pricing tiers, the complete breakdown is available in this Gemini API pricing guide.
Small App (1K daily users, ~500 tokens average per request)
At this scale, your workload generates approximately 15M input tokens and 5M output tokens per month. GPT-5.4 Standard costs $37.50 for inputs ($2.50 × 15M) plus $75.00 for outputs ($15 × 5M), totaling $112.50 per month. Gemini 3.1 Pro at the under-200K context tier costs $30.00 for inputs ($2 × 15M) plus $60.00 for outputs ($12 × 5M), totaling $90.00 per month. The difference is $22.50 — about 20% less with Gemini, and a modest absolute amount that would not be a primary driver for model selection at this scale.
Mid-Size SaaS (10K daily users, ~1K tokens average per request)
Monthly volume reaches approximately 225M input tokens and 75M output tokens. GPT-5.4 Standard: $562.50 inputs + $1,125 outputs = $1,687 per month. Gemini 3.1 Pro: $450 inputs + $900 outputs = $1,350 per month. The saving of $337 per month is more meaningful here, but the percentage gap remains around 20%. At this scale, reliability, latency, and integration simplicity often outweigh the pricing differential.
Enterprise Scale (100K daily users, ~2K tokens average per request)
Monthly volume reaches approximately 4.5B input tokens and 1.5B output tokens. GPT-5.4 Standard: $11,250 inputs + $22,500 outputs = $33,750 per month. Gemini 3.1 Pro: $9,000 inputs + $18,000 outputs = $27,000 per month. The $6,750 monthly saving is significant at this scale — over $80,000 per year — and may justify architectural complexity to accommodate Gemini 3.1 Pro for eligible workloads.
The Pro tier gap (when it actually applies)
The 15x headline only becomes relevant when you need a 1M context window through GPT-5.4. Running the same Mid-Size SaaS traffic through GPT-5.4 Pro costs $6,750 for inputs plus $13,500 for outputs, totaling $20,250 per month — versus $1,350 for Gemini 3.1 Pro. This $18,900 monthly difference is substantial and represents a genuine architectural decision point for teams processing very long documents, large codebases, or extended conversation histories. If you do not actually need the 1M context window, GPT-5.4 Standard's 272K window covers the vast majority of real-world use cases, and the cost comparison returns to the more modest 20% range.
For teams running both models across different workload types, unified API access through services like laozhang.ai can simplify billing by consolidating GPT-5.4 and Gemini 3.1 Pro under a single API key and account, which reduces the operational overhead of managing separate vendor relationships and rate limits.
Which Model Should You Choose?
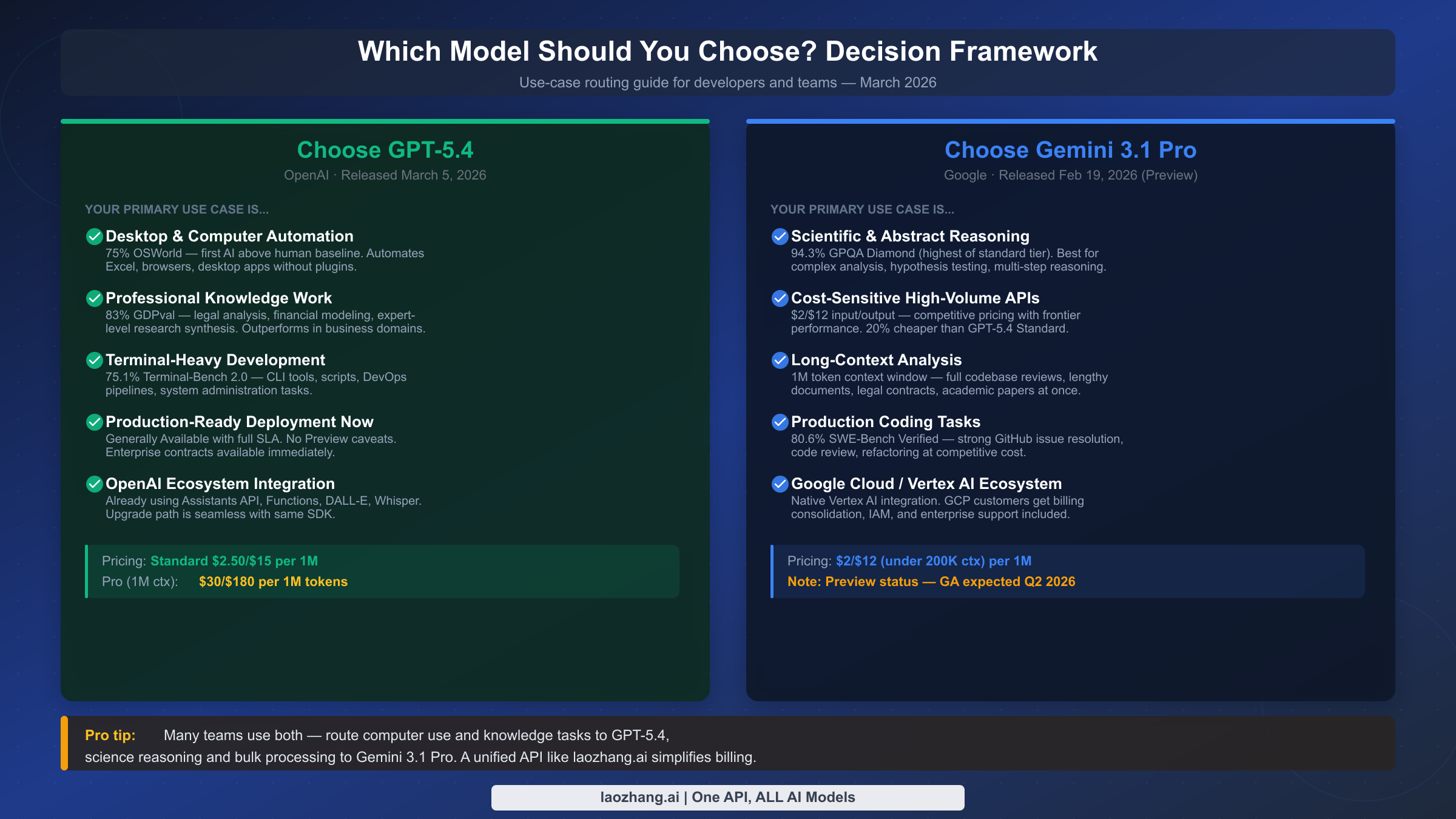
The benchmark data and cost calculations above point to a clear decision framework. Neither model is universally superior — the right choice depends almost entirely on what you are building and how you prioritize cost, latency, and specific capability requirements.
Choose GPT-5.4 when:
Computer use and desktop automation is your primary workload. At 75% OSWorld, GPT-5.4 is the only frontier model to exceed human-level performance on this benchmark, making it the obvious choice for RPA replacement, automated testing, and any agent that operates browser and desktop interfaces. No other model currently published has achieved this level on computer use.
You are working in professional knowledge domains where GDPval-type tasks predominate. Legal analysis, financial modeling, business intelligence, and structured professional reasoning are where GPT-5.4's 83% GDPval shows up in practice. If your users are asking questions that legal associates, financial analysts, or business consultants typically handle, GPT-5.4 has been specifically benchmarked on this territory.
Your application is user-facing and requires low latency. Until Gemini 3.1 Pro's latency profile improves post-GA, GPT-5.4 is the safer choice for interactive interfaces where users expect near-immediate responses. Terminal and CLI tool development, DevOps pipelines, and infrastructure automation also benefit from GPT-5.4's 75.1% Terminal-Bench 2.0 advantage.
You need production-ready deployment now. GPT-5.4 is Generally Available with full SLA support, enterprise contracts, and a stable API. For teams that cannot accept Preview-status risk in their production environment, this alone may be the deciding factor.
Choose Gemini 3.1 Pro when:
Scientific and abstract reasoning is central to your application. The 94.3% GPQA Diamond and 77.1% ARC-AGI-2 scores represent genuine capability advantages for research tools, scientific analysis platforms, hypothesis evaluation, and any domain where the reasoning required is more academic than professional in character. Combined with Gemini's thinking mode, the edge over GPT-5.4 on abstract reasoning tasks becomes even more pronounced.
Your workloads are batch or asynchronous and latency-insensitive. Document analysis pipelines, nightly enrichment jobs, research synthesis, and data processing workflows can fully exploit Gemini 3.1 Pro's capabilities without being penalized by the 44.5-second TTFT. For these workloads, the 20% cost advantage over GPT-5.4 Standard compounds meaningfully at scale.
Long-context analysis at scale is a core requirement. Processing entire codebases, lengthy contracts, or research paper collections benefits from Gemini 3.1 Pro's native 1M context window at standard pricing — compared to GPT-5.4's 272K standard window or the expensive Pro tier upgrade.
Your infrastructure is Google Cloud. Native Vertex AI integration provides billing consolidation, IAM integration, and enterprise support in a single GCP account — eliminating the overhead of a separate OpenAI vendor relationship for teams already standardized on Google Cloud.
The hybrid strategy
Many production teams ultimately run both models. Computer use, knowledge work, and real-time features route to GPT-5.4. Scientific reasoning, batch processing, and long-document analysis route to Gemini 3.1 Pro. This approach captures the best of both capability sets while managing cost efficiently. The operational complexity of maintaining two API relationships is real but manageable, especially through unified API gateway services that provide a single integration point for both models.
Production Readiness: Availability, SLA, and Stability
The GPT-5.4 vs Gemini 3.1 Pro decision is not purely a capability question — it is also an operational risk question, and the two models are in very different positions on that dimension.
GPT-5.4 is Generally Available. This means it has passed OpenAI's internal quality and stability thresholds for production use, it is backed by standard uptime SLAs, enterprise customers can negotiate committed throughput agreements, and the API behavior is stable enough to depend on for customer-facing workloads. OpenAI has a track record of maintaining backward compatibility for GA models, providing meaningful advance notice before deprecation, and responding to enterprise support tickets with appropriate SLA commitments. For teams where downtime is expensive or where customers depend on consistent behavior, GA status is not a bureaucratic checkbox — it is a meaningful guarantee about stability and support.
Gemini 3.1 Pro is in Preview. Google has been transparent that Preview status means the model is available for development and testing but has not yet been qualified for full production SLA commitments. Specifically, Preview models may see more frequent version updates (which can change model behavior), may not have the same rate limit guarantees as GA models, and may not be available under Google's enterprise support terms. None of this makes Gemini 3.1 Pro inappropriate for use — many teams run Preview models in production successfully — but it should be factored into risk assessments, particularly for regulated industries, customer-facing applications, and workloads where behavioral consistency is contractually required. For developers who want to begin working with Gemini 3.1 Pro immediately, Gemini 3.1 Pro Preview free API access is available through Google AI Studio, allowing evaluation at no cost before committing to production pricing.
The production readiness gap is likely temporary. Google has indicated GA for Gemini 3.1 Pro is expected in Q2 2026, which at time of writing is roughly one quarter away. For teams with a flexible timeline, evaluating Gemini 3.1 Pro now and planning for a production GA migration in Q2 is a reasonable strategy — particularly for use cases where Gemini's capability advantages (scientific reasoning, long context, SWE-Bench coding) make it the preferred technical choice. For teams that need to deploy immediately and cannot accept Preview-status risk, GPT-5.4 is the only viable option until Gemini 3.1 Pro achieves GA.
The broader operational question for both models involves context window stability and version management. Both providers offer some form of model versioning, but the mechanisms differ. GPT-5.4 follows OpenAI's standard versioning conventions, while Gemini Preview models may see more frequent capability updates. For applications where repeatable outputs are important — evaluations, auditing, or any use case where you need to reproduce historical responses — pinning to specific model versions and testing updates before deploying them is a non-negotiable practice regardless of which provider you choose.
API Integration Quick Start
Both models support OpenAI-compatible API conventions for basic completions, but there are meaningful differences in how they handle authentication, context configuration, and advanced features that affect integration design.
GPT-5.4 — Python (OpenAI SDK)
pythonfrom openai import OpenAI client = OpenAI(api_key="your-openai-api-key") response = client.chat.completions.create( model="gpt-5.4", # Standard tier, 272K context # model="gpt-5.4-pro", # Pro tier, 1M context ($30/$180 per 1M) messages=[ { "role": "system", "content": "You are a professional analyst specializing in financial modeling." }, { "role": "user", "content": "Analyze the following quarterly earnings data and identify key trends..." } ], max_tokens=2048, temperature=0.3, ) print(response.choices[0].message.content) print(f"Tokens used: {response.usage.total_tokens}")
Gemini 3.1 Pro — Python (google-genai SDK)
pythonimport google.generativeai as genai genai.configure(api_key="your-google-api-key") model = genai.GenerativeModel( model_name="gemini-3.1-pro", system_instruction="You are a research scientist specializing in computational biology." ) response = model.generate_content( contents="Evaluate the experimental design described in the following paper abstract...", generation_config=genai.GenerationConfig( max_output_tokens=2048, temperature=0.2, ) ) print(response.text)
OpenAI-compatible endpoint for Gemini (unified routing)
Gemini 3.1 Pro also supports an OpenAI-compatible endpoint, which allows you to route requests using the OpenAI SDK by simply changing the base URL:
pythonfrom openai import OpenAI client = OpenAI( api_key="your-unified-api-key", base_url="https://api.laozhang.ai/v1" ) # Switch between models by changing the model parameter response = client.chat.completions.create( model="gemini-3.1-pro", # or "gpt-5.4" — same SDK, same code messages=[ {"role": "user", "content": "Your prompt here"} ], )
This pattern is particularly useful for teams implementing model routing, where different request types are dispatched to different models based on rules. By using a unified endpoint like laozhang.ai, which provides a single API key for both GPT-5.4 and Gemini 3.1 Pro at official pricing, you avoid the overhead of maintaining separate authentication configurations and rate limit tracking for two providers. Full API documentation is available at docs.laozhang.ai.
Key integration differences to account for:
Streaming behavior differs slightly between the two models. GPT-5.4 begins streaming relatively quickly once the request is accepted. Gemini 3.1 Pro, with its 44.5-second TTFT, will appear unresponsive in stream mode for a significant delay before any tokens arrive — ensure your client-side timeout settings are configured to wait at least 60 seconds before treating a streaming response as failed. For interactive applications, consider implementing a "thinking" indicator that activates immediately on request submission and remains visible until the first token arrives, rather than relying on the standard streaming cursor behavior.
Context window management is another integration consideration. GPT-5.4 Standard's 272K context window requires active truncation logic for very long conversations or document-heavy workflows. Gemini 3.1 Pro's 1M window is more forgiving of context accumulation, but the pricing jump when crossing 200K means cost tracking should account for per-request context length rather than treating all requests as equal.
Frequently Asked Questions
Is GPT-5.4 really 15x more expensive than Gemini 3.1 Pro?
Only if you compare GPT-5.4 Pro ($30/M input) against Gemini 3.1 Pro Standard ($2/M input). The GPT-5.4 Standard tier at $2.50/M is roughly 20-25% more expensive than Gemini 3.1 Pro, not 15x. Most API use cases do not require the 1M context window of the Pro tier, so the standard-to-standard comparison is the relevant one for the majority of workloads.
Can I use Gemini 3.1 Pro in production today?
Yes, with caveats. Gemini 3.1 Pro Preview is available and functional, and many teams run it in non-customer-facing production workflows successfully. However, it does not carry full GA SLAs, may receive model updates that subtly change behavior, and is not available under Google's enterprise support terms. For regulated industries or applications where SLA guarantees are contractually required, wait for GA (expected Q2 2026) or use GPT-5.4 in the interim.
Which model is better for coding?
Gemini 3.1 Pro at 80.6% SWE-Bench Verified is competitive for real-world GitHub issue resolution. GPT-5.4 does not have a published SWE-Bench Verified score in available benchmarks, but scores 75.1% on Terminal-Bench 2.0 for CLI tasks. For general coding and code review, Gemini 3.1 Pro has the stronger benchmark evidence. For DevOps, scripting, and terminal automation specifically, GPT-5.4's Terminal-Bench advantage applies.
How does the 44.5-second TTFT affect Gemini 3.1 Pro usability?
For batch and asynchronous workloads, it does not affect usability at all — if users never see the latency, it does not matter. For interactive applications, 44.5 seconds of waiting before any response appears is a significant user experience problem. The 94.9 tokens per second throughput after the first token arrives means generation itself is fast — the delay is in getting the first token started. This profile makes Gemini 3.1 Pro well-suited for document analysis and research tasks, less suited for chat and real-time assistance.
Which model should a solo developer start with?
For most side projects and initial evaluations, Gemini 3.1 Pro's free API access through Google AI Studio provides a lower-cost entry point, and the 1M context window provides flexibility for experimentation. For projects specifically involving computer use automation or professional knowledge tasks, GPT-5.4's unique benchmark positions make it worth the Standard pricing. The practical answer is: start with Gemini 3.1 Pro Preview if your workload fits its strengths and cost-sensitivity matters; start with GPT-5.4 if you need production-grade SLAs or computer use capabilities immediately.
Conclusion
GPT-5.4 and Gemini 3.1 Pro are more complementary than competitive in practice. GPT-5.4 earns its position for computer use automation, professional knowledge work, terminal-heavy development, and any application where GA stability and low latency are non-negotiable. Gemini 3.1 Pro earns its position for scientific reasoning, long-context analysis, batch processing, and cost-sensitive high-volume workloads where its 1M native context window and ~20% pricing advantage (Standard tier) or 15x pricing advantage (versus GPT-5.4 Pro) compound significantly.
The key decisions reduce to three questions: Do you need computer use automation? (If yes, GPT-5.4 is the only realistic choice.) Is your application interactive and user-facing? (If yes, GPT-5.4 until Gemini 3.1 Pro's GA and latency profile improve.) Are your workloads batch-oriented, science-focused, or long-context? (If yes, Gemini 3.1 Pro offers genuine capability and cost advantages.) Most teams building at scale will find a hybrid routing strategy captures the best of both models across their portfolio of workloads.