
As of May 21, 2026, start new latency-sensitive agentic coding, tool-calling, and high-throughput API tests with gemini-3.5-flash, but do not delete gemini-3.1-pro-preview from reasoning-heavy or long-document routes until your own evals prove the switch is safe.
| Decision | First route | Use it when | Stop rule |
|---|---|---|---|
| Switch toward Flash | gemini-3.5-flash | Agent loops, coding iterations, tool-heavy flows, high concurrency, and multimodal text output where latency matters | Keep Pro as fallback until quality, latency, and failure logs clear your production bar |
| Keep Pro Preview | gemini-3.1-pro-preview | Hard reasoning, long-document review, cautious analysis, and cases where one correct answer is cheaper than retries | Do not treat launch benchmarks as proof that every Pro workload is obsolete |
| Route both | Router over both model IDs | Mixed workloads where speed, cost, reasoning depth, and failure owner all matter | Roll out only after side-by-side prompts, token logs, tool-call logs, latency p95, and rollback thresholds are written down |
Google lists Gemini 3.5 Flash as a stable model and Gemini 3.1 Pro Preview as a preview model; the pricing and support matrix were checked on May 21, 2026. 3.5 Pro is a watchpoint, not the routing choice in this comparison yet.
The practical answer is therefore not "Flash wins" or "Pro is dead." Use Flash as the first test for fast API work, keep Pro Preview for harder or longer jobs, and route both until your eval data says one default is enough.
What actually changed
Gemini 3.5 Flash is a new stable Flash-family route, not a simple rename of Gemini 3.1 Pro Preview. Google's Gemini 3.5 Flash model page lists the API model ID as gemini-3.5-flash, with stable status, text output, and broad multimodal input. Google's Gemini 3.1 Pro Preview model page still lists gemini-3.1-pro-preview as a preview model, with gemini-3.1-pro-preview-customtools as a separate custom-tools endpoint.
That difference matters more than the headline wording. A stable Flash model can be the safer default for many production paths because it reduces preview-lifecycle risk, improves speed-sensitive flows, and is built for agentic tool use. A preview Pro model can still be the safer route when the workload depends on hardest reasoning, long-document synthesis, or a customtools path you have already qualified.

The two models have a surprisingly similar input contract. Both list text, image, video, audio, and PDF input. Both output text. Both list a 1,048,576-token input window and a 65,536-token output window. Both support core developer features such as function calling, code execution, structured outputs, thinking, search grounding, Maps grounding, URL context, caching, Batch, Flex, and Priority inference, with one important caveat: Gemini 3.1 Pro Preview marks file search as AI Studio only in the checked model page.
Neither model is the right route for every Gemini surface. Gemini 3.5 Flash does not list support for audio generation, image generation, Live API, or Computer Use. Gemini 3.1 Pro Preview does not list support for audio generation, image generation, or Live API. If the product needs live voice, image output, or UI control, this comparison is the wrong branch; choose the route that owns that output contract.
Where Flash is the first test
Use gemini-3.5-flash first when the workload looks like an agent loop rather than a single difficult answer. Examples include coding iterations, tool planning, function-call heavy workflows, multimodal document intake, high-concurrency support automation, batchable analysis, and applications where latency is part of product quality.
Google's Gemini 3.5 launch post frames 3.5 Flash around frontier intelligence with action, and it claims wins over Gemini 3.1 Pro on Terminal-Bench 2.1, GDPval-AA, and MCP Atlas. Treat those as Google's benchmark claims, not as permission to delete every Pro route. Their practical value is directional: they explain why Flash deserves the first test for agentic, coding, and tool-heavy jobs.
For a backend team, the stronger test is not "which model scores higher on a leaderboard?" It is whether Flash reduces wall-clock time, tool retries, router fallbacks, manual review, and failed requests under your actual prompts. If the answer is yes, Flash can become the default for that lane even when Pro remains available for specific hard cases.
Use Flash first for these lanes:
| Workload | Why Flash starts first | What to measure |
|---|---|---|
| Coding agent loop | Tool calls, code execution, structured output, and fast iteration all matter | Pass rate, tool-call success, edit correctness, latency p95, retries |
| High-volume support or operations bot | Throughput and failure recovery usually matter more than maximum reasoning depth | Answer acceptance, escalation rate, cost per resolved ticket |
| Multimodal text output | The model can read multiple input types and return text | Extraction accuracy, hallucination rate, token use, review burden |
| Search-grounded workflow | Search grounding and URL context are part of the listed capability surface | Source use, freshness errors, fallback rate |
| Batch or eval pipeline | Batch/Flex pricing can improve economics when latency is not urgent | Total job cost, completion time, retry count |
If most of your tasks are short extraction or low-margin classification, do not assume 3.5 Flash is the cheapest Gemini route just because it says Flash. Compare it against lower-cost siblings and your existing route. The Gemini 3.5 Flash capabilities guide goes deeper on that single-model decision.
Where Pro Preview still earns a route
Keep gemini-3.1-pro-preview when the workload is less about speed and more about a difficult answer that has to be right the first time. Long legal or policy documents, multi-hop technical analysis, careful codebase review, deep synthesis across messy evidence, and customtools-sensitive workflows can still justify a Pro lane.
This is not nostalgia for an older model. It is risk control. If Flash answers faster but causes more retries, more human review, or more downstream correction, the completed workflow can become slower and more expensive. Pro Preview is still a preview route, so it needs lifecycle caution, but preview status does not automatically make it useless.
The separate gemini-3.1-pro-preview-customtools endpoint deserves extra care. Do not silently replace it with standard gemini-3.5-flash if the production workload depends on bash-like or custom-tool behavior that was qualified on that endpoint. The replacement decision is not only model name to model name; it is runtime contract to runtime contract.
Use Pro Preview first or keep it as fallback when:
| Need | Why Pro can remain valuable | Flash test before replacing |
|---|---|---|
| Deep reasoning | One correct answer may save more than the faster route costs | Replay the hard-case set and score answer quality, not only latency |
| Long-document review | The model has the same listed context size and a Pro reasoning profile | Compare evidence retention and missed detail rate |
| Customtools-sensitive tasks | The customtools endpoint is a separate contract | Test tool behavior explicitly before changing IDs |
| High-stakes analysis | Review burden and failure owner matter more than first-token speed | Track reviewer changes and failed-decision cost |
| Mixed workloads | Some requests are easy, some are genuinely hard | Route by request class instead of forcing one default |
The adjacent Gemini 3.1 Pro Preview free API guide is useful if your real question is still setup, access, limits, or the old gemini-3-pro-preview migration. The routing question here is narrower: whether 3.5 Flash should take over part of your route.
Pricing: token price is not the whole cost
Google's Gemini API pricing page, checked May 21, 2026, lists Gemini 3.5 Flash Standard as free of charge on the Free Tier and $1.50 input / $9.00 output per 1M tokens on the Paid Tier. It lists Gemini 3.1 Pro Preview paid pricing at $2.00 input / $12.00 output per 1M tokens for prompts up to 200K, and $4.00 / $18.00 above 200K. Free tier availability is not the same across the two routes.
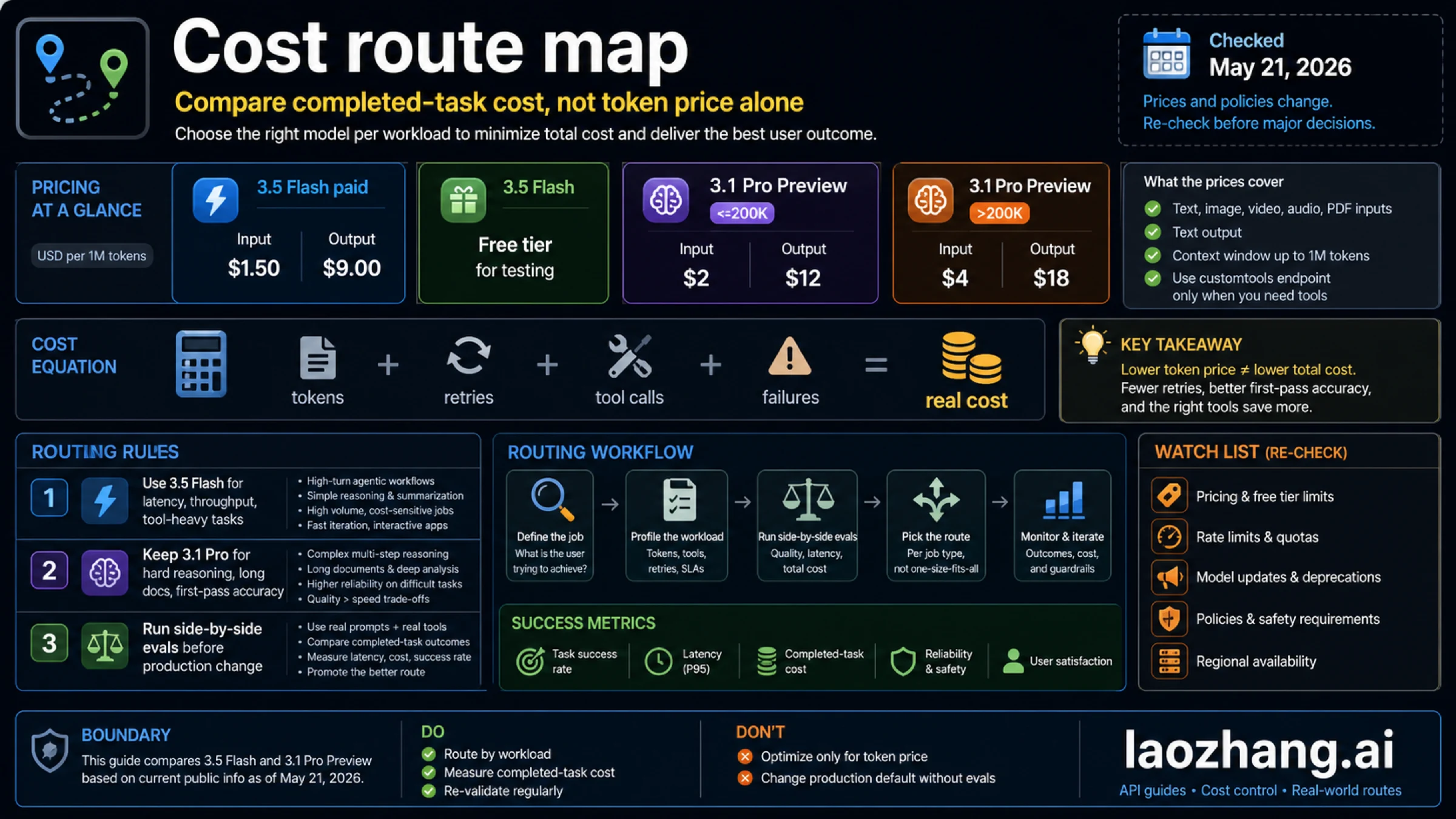
At first glance, Flash looks cheaper. That is usually true on the listed Standard token line. But the production decision should use completed-task cost:
| Cost component | Why it matters |
|---|---|
| Input and output tokens | Output-heavy tasks can dominate the bill quickly |
| Thinking and reasoning behavior | A harder route may use more tokens but avoid retries |
| Tool calls | Tool-heavy flows can fail or loop even when token price is low |
| Retries and fallbacks | A cheap first call is not cheap if it often needs a second model |
| Human review | Manual correction can dwarf token differences |
| Latency | A slower but more accurate route may or may not be acceptable |
The clean rule is simple: use Flash first where speed, throughput, and tool success improve the whole workflow; keep Pro Preview where one correct hard answer prevents expensive rework. Run both on the same prompt set before changing a production default.
Batch, Flex, and Priority pricing can also change the answer. Batch/Flex can make latency-tolerant workloads cheaper. Priority can make urgent traffic more expensive. If the question is quota, free tier, billing, or rate limits rather than model choice, check the Gemini API free tier guide before writing a cost forecast into code or customer-facing copy.
A practical router
The safest production pattern is a small router, not a one-line global replacement. Start with request classes, then route each class to the model that owns the job.
| Request class | Default route | Why |
|---|---|---|
| Tool-heavy agent action | gemini-3.5-flash | Speed, tool loops, and throughput are usually the bottleneck |
| Coding iteration | gemini-3.5-flash first, Pro fallback for hard review | Flash should be tested first, but hard debugging may still need Pro |
| Long-document synthesis | gemini-3.1-pro-preview or dual eval | Missing a key detail can cost more than token savings |
| Multimodal input to text output | gemini-3.5-flash first | Broad input support plus speed makes it the natural first route |
| Customtools path | Keep gemini-3.1-pro-preview-customtools until proven otherwise | Endpoint behavior is part of the contract |
| Cheap high-volume extraction | Compare Flash against cheaper siblings | Flash may not be the lowest-margin route |
| High-stakes reasoning | Keep Pro route or require reviewer approval | Production risk matters more than speed |
A router can be as simple as a few request labels at first:
tstype RouteInput = { isToolHeavy: boolean; needsLowLatency: boolean; isLongDocument: boolean; needsDeepReasoning: boolean; usesCustomToolsEndpoint: boolean; }; export function chooseGeminiModel(input: RouteInput) { if (input.usesCustomToolsEndpoint) { return "gemini-3.1-pro-preview-customtools"; } if (input.isLongDocument || input.needsDeepReasoning) { return "gemini-3.1-pro-preview"; } if (input.isToolHeavy || input.needsLowLatency) { return "gemini-3.5-flash"; } return "gemini-3.5-flash"; }
This is not a universal router. It is a starting point for evaluation. In a real system, add logs for model ID, prompt size, input tokens, output tokens, tool-call count, tool errors, latency p50/p95, fallback reason, user-visible outcome, and reviewer decision. Without those fields, you will argue about model preference instead of measuring route performance.
If you are choosing between Gemini API and Vertex AI for governance, enterprise controls, or deployment boundaries, that is a separate platform decision. Use the Gemini API vs Vertex API guide before mixing platform routing with model routing.
Migration checklist

Do not run the migration as "replace every gemini-3.1-pro-preview string with gemini-3.5-flash." That is how good launch news turns into production regressions.
Use this rollout sequence instead:
- Build a prompt set from real traffic: easy requests, hard reasoning requests, long documents, tool-heavy tasks, and failure cases.
- Run the same prompts on
gemini-3.5-flash,gemini-3.1-pro-preview, andgemini-3.1-pro-preview-customtoolswhere that endpoint is relevant. - Log model ID, prompt size, token use, tool calls, latency, failure owner, fallback model, and final user outcome.
- Score output quality with a rubric, not only a thumbs-up.
- Start with monitor-only routing. Compare what the router would have chosen against the old production route.
- Canary a small traffic share, then move to 10%, 50%, and default only when quality and cost hold.
- Define rollback before the launch: quality drop, timeout spike, cost surprise, tool-call regression, or reviewer rejection rate.
- Keep a 3.5 Pro watchpoint. Google's launch post says 3.5 Pro is planned next, but that is not a reason to pause all Flash testing or to route by rumor.
The most common mistake is to evaluate only easy tasks. Easy tasks make almost any modern model look strong. Your eval needs hard requests, long documents, tool failures, ambiguous prompts, and known bad cases. Otherwise you will move the default based on the work that least needs a better model.
FAQ
Is Gemini 3.5 Flash a replacement for Gemini 3.1 Pro Preview?
Not globally. It is the first test for fast agentic coding, tool-heavy workflows, and latency-sensitive API routes. Keep Gemini 3.1 Pro Preview for reasoning-heavy, long-document, and customtools-sensitive workloads until side-by-side evals prove Flash is good enough.
What model IDs should I use?
Use gemini-3.5-flash for Gemini 3.5 Flash. Use gemini-3.1-pro-preview for the standard Gemini 3.1 Pro Preview route. Use gemini-3.1-pro-preview-customtools only when the workload actually depends on that customtools endpoint.
Which model is cheaper?
On the checked Standard paid token line, Gemini 3.5 Flash is cheaper: $1.50 input / $9.00 output per 1M tokens versus Gemini 3.1 Pro Preview at $2.00 / $12.00 up to 200K prompts and $4.00 / $18.00 above 200K. Completed-task cost can still favor Pro when Flash causes retries, failed tools, or more review.
Does either model generate images or audio?
No for this comparison. In the checked model pages, these routes output text. Gemini 3.5 Flash does not list image generation, audio generation, Live API, or Computer Use support. Gemini 3.1 Pro Preview does not list image generation, audio generation, or Live API support.
Should I wait for Gemini 3.5 Pro?
Do not route production by an announced future model. Google says 3.5 Pro is planned next, but the current decision is whether Flash can own the fast/tool-heavy lanes and whether Pro Preview still owns hard reasoning or long-document lanes. Build your evals now, then rerun them when 3.5 Pro becomes a selectable route.
What is the safest decision today?
Use gemini-3.5-flash as the first test for fast API work, keep gemini-3.1-pro-preview for hard or long-context cases, and route both until your own logs show one default is enough. That gives you the benefit of the new stable Flash route without turning a launch comparison into a blind production migration.