
As of May 21, 2026, the safe answer is not "newer model wins." Use gemini-3.5-flash when stronger agentic, coding, tool-heavy, or long-context quality reduces retries and review time. Use gemini-3.1-flash-lite when the job is simple, high-volume, and price-sensitive enough that lower token cost matters more than extra reasoning margin.
Fast Answer
| Situation | Better first route | Why |
|---|---|---|
| Coding agents, tool loops, multi-step analysis, product assistants | Gemini 3.5 Flash | Pay for the stronger route when fewer retries and cleaner tool use can offset the higher token line. |
| Bulk extraction, translation, classification, moderation, short summaries | Gemini 3.1 Flash-Lite | The cheaper Standard and Batch/Flex rows matter when quality is already good enough. |
| Unsure or moving production traffic | Route both | Run the same workload, log quality, cost, latency, retries, and review time before changing defaults. |
| Image output, audio output, Live API, Computer Use | Neither row owns it | Use a Gemini route that explicitly supports that runtime. |
This is a workload-routing decision. The two models share a surprisingly similar public API contract, so the decision is mostly quality-per-task versus cost-per-task. If a Flash-Lite workflow is already accurate and cheap, replacing it globally can only raise cost. If Flash-Lite causes retries, tool failures, or human repair, Gemini 3.5 Flash may be cheaper for the full workflow even when the list price is higher.
Official Contract Snapshot

Google's current model pages list both gemini-3.5-flash and gemini-3.1-flash-lite as stable Gemini API models. Both accept text, image, video, audio, and PDF input, both produce text output, and both list a 1,048,576-token input window with a 65,536-token output window.
The shared capability surface is also close enough that a simple feature checklist will not choose for you. The official pages list Batch API, caching, code execution, file search, function calling, Google Search grounding, Google Maps grounding, structured outputs, thinking, URL context, Flex, and Priority for both rows in the May 21 snapshot. That means the important split is not "can Flash-Lite call tools?" but "does it perform well enough on this task class?"
| Contract item | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite |
|---|---|---|
| API model ID | gemini-3.5-flash | gemini-3.1-flash-lite |
| Status | Stable | Stable |
| Input and output | Multimodal input, text output | Multimodal input, text output |
| Token window | 1,048,576 input, 65,536 output | 1,048,576 input, 65,536 output |
| Good default read | Stronger quality route | Lower-cost volume route |
The stop rule is just as important: neither row should be sold as an image-generation, audio-generation, Live API, or Computer Use route unless the official model page changes. Those jobs belong to sibling Gemini runtimes.
Price And Workflow Cost
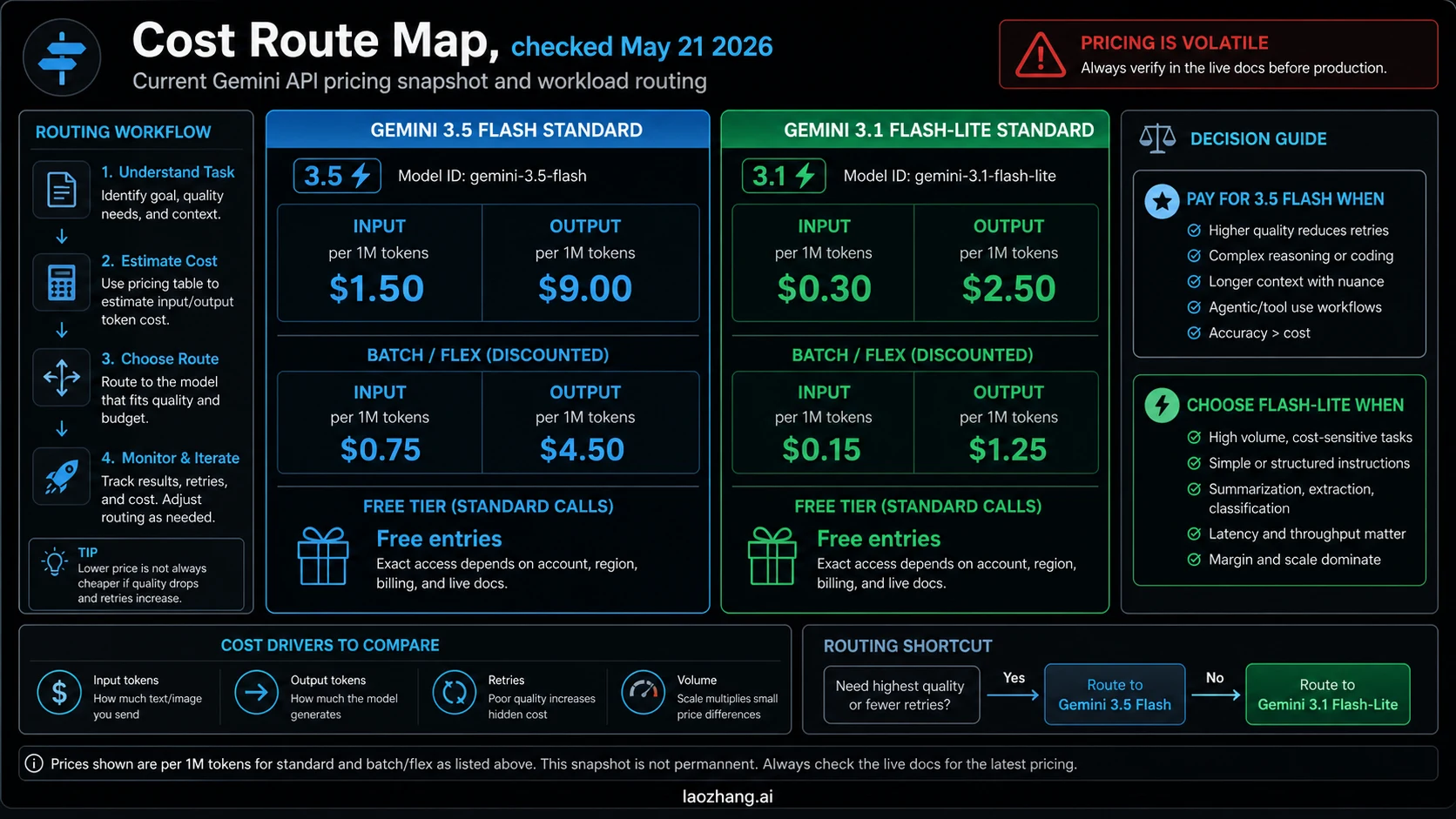
In the May 21, 2026 pricing snapshot, Gemini 3.5 Flash Standard paid pricing is $1.50 input and $9.00 output per 1M tokens. Gemini 3.1 Flash-Lite Standard paid pricing is $0.30 input and $2.50 output per 1M tokens. Batch/Flex is also cheaper for Flash-Lite: $0.75/$4.50 for 3.5 Flash versus $0.15/$1.25 for Flash-Lite. The pricing page also shows Free Tier rows for Standard usage, but exact access depends on account, billing, region, quota, and the current live docs.
Do not stop at the list price. For small requests, output token price may dominate. For agentic work, retry count, tool failure, and reviewer minutes often dominate. A model with a higher token price can still win if it avoids two failed tool loops or a manual repair pass. A model with a lower token price can still win if the task is deterministic enough that extra intelligence never changes the accepted result.
| Cost question | Use this measurement |
|---|---|
| Is Flash-Lite still good enough? | Accuracy, schema validity, missed fields, retry rate, human edits. |
| Is 3.5 Flash worth the premium? | Defect reduction, tool-call success, reviewer minutes saved, fewer fallback calls. |
| Does Batch/Flex change the answer? | Latency tolerance, queue behavior, batchable input size, output budget. |
| Can Free Tier decide production? | No. Treat free rows as evaluation help, not a durable operating contract. |
Workload Routing Matrix
The most useful split is by failure cost. Choose Gemini 3.5 Flash when a wrong answer creates debugging time, bad code, tool churn, or a support escalation. Choose Gemini 3.1 Flash-Lite when the output can be verified cheaply and the task is repeated at scale.
| Workload | First test | Keep the other route for |
|---|---|---|
| Coding-agent traces | 3.5 Flash | Flash-Lite can still handle cheap lint summaries or issue classification. |
| Multimodal support tickets | 3.5 Flash | Flash-Lite can route or tag tickets after the schema is simple. |
| Translation and rewrite variants | Flash-Lite | 3.5 Flash can rescue difficult source ambiguity or brand-sensitive copy. |
| Data extraction | Flash-Lite | 3.5 Flash can handle mixed PDFs, long evidence packs, or brittle validation. |
| Product-facing assistant | 3.5 Flash first | Flash-Lite can serve safe fallback or low-risk background summaries. |
The wrong move is replacing one global Gemini default with another global default. Keep two named routes in config: a quality route and a margin route. Then assign tasks to the route that actually earns the job.
Safe Switch Checklist
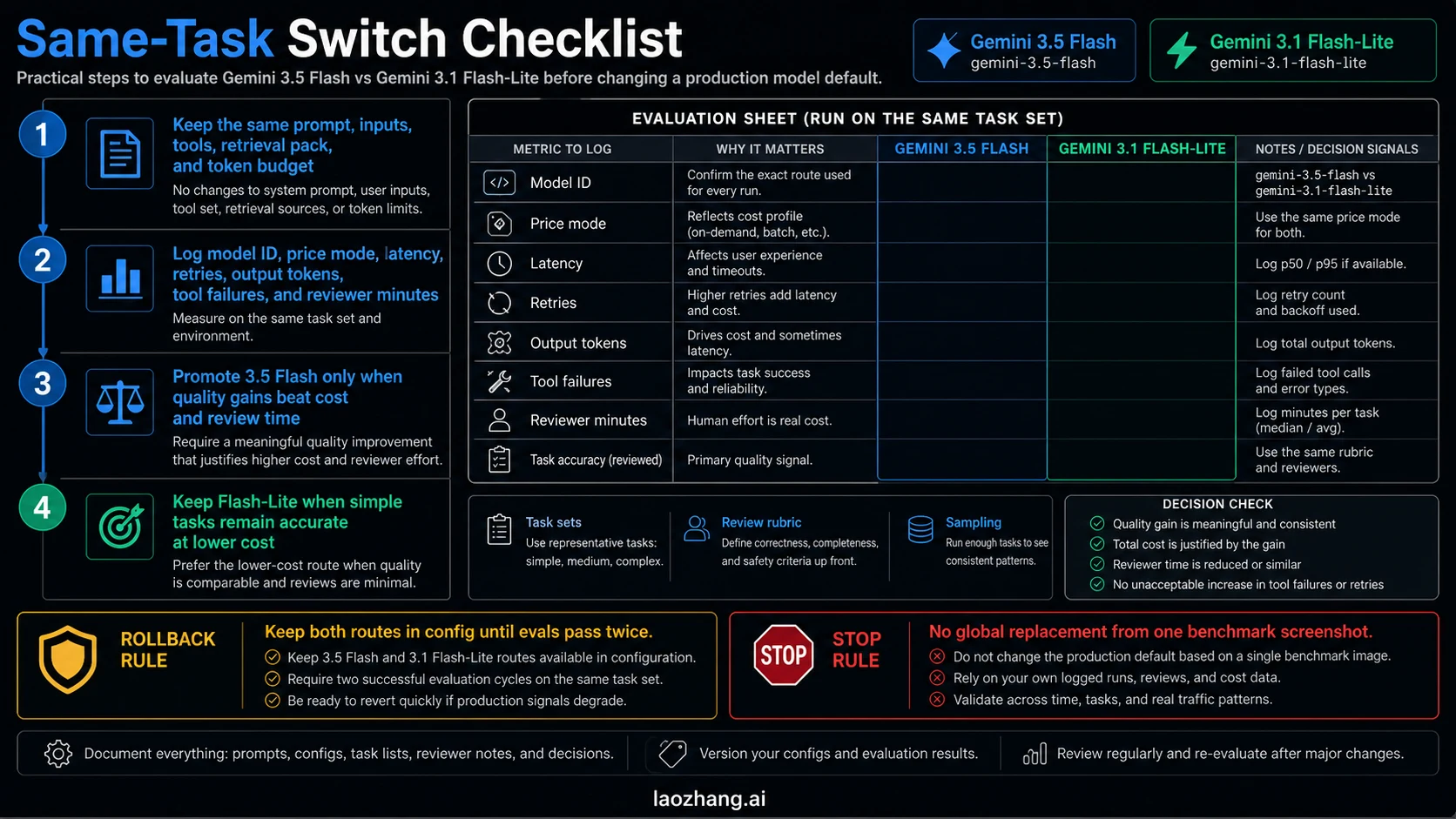
Before you change production defaults, run the same task through both routes. Use the same prompt, same inputs, same retrieval pack, same tools, same timeout, same token budget, and same validator. Log model ID, price mode, latency, retries, input tokens, output tokens, tool failures, schema failures, reviewer minutes, and accepted result.
Promote Gemini 3.5 Flash only when it lowers total workflow cost or materially improves accepted quality. Keep Flash-Lite when the task remains correct, cheap, and easy to verify. Keep both routes available until two rounds of real workload evaluation pass. A launch benchmark or social screenshot is not a migration plan.
Adjacent Gemini Decisions
For narrower Gemini follow-ups, use Gemini 3.5 Flash capabilities, Gemini API free tier, Gemini API vs Vertex AI, Flash-family runtime guide. Sources checked on May 21, 2026: Google AI model pages, Gemini API pricing, changelog, deprecations, and Google launch post. Pricing, free-tier access, model availability, and preview shutdown dates can change, so recheck the live official pages before changing production defaults.
FAQ
Is Gemini 3.5 Flash always better than Gemini 3.1 Flash-Lite?
No. It is the stronger route to test for complex agentic and coding work, but Flash-Lite can be the better production default for simple high-volume work.
Are both models stable?
In the May 21, 2026 official model snapshot, both gemini-3.5-flash and gemini-3.1-flash-lite are listed as stable models.
Is Flash-Lite preview still safe to use?
Use the stable gemini-3.1-flash-lite row for production. Google's deprecation page lists gemini-3.1-flash-lite-preview with a shutdown date of May 25, 2026.
Which one is cheaper?
Gemini 3.1 Flash-Lite is cheaper on the paid Standard and Batch/Flex rows in the May 21 pricing snapshot. Recheck the official pricing page before publishing hard numbers.
Should I put both in my router?
Yes for production teams. Keep a quality route and a margin route, then route by task class instead of model branding.